BlazingText
Word2vec とテキスト分類アルゴリズムの高度に最適化された実装を提供してくれて、そのWord2vec アルゴリズムは、単語を高品質の分散ベクトルにマッピングしてくれるものだそうです(よくわかっていません)。
要するに、似たような単語は似た値のベクトルを持っているので、それを分類しましょうていう感じ。これが出来ると、単語の分類とか文章の意味解析なんかが出来るようになる、と。
詳細はこちらBlazingText アルゴリズム
1.blazingtext_hosting_pretrained_fasttext.ipynb
BlazingTextが事前トレーニング済みのテキスト分類とWord2VecモデルのFastTextモデルのホスティングをサポートする方法を示します。
説明は英語で書いてあるので、随時Google翻訳で何をやっているのか確認。
基本はサンプルコードをそのまま実行していきます。
Introduction
パラメータの指定


Hosting the Language Idenfication model by FastText
言語識別のために、FastTextで利用可能な事前トレーニングモデルを活用する
FastText Webサイトから言語識別(テキスト分類)モデル[1]をダウンロードします。

次に、モデルをtarで圧縮し、Python SDKから利用可能なユーティリティを使用してS3にアップロードします。 データのローカルコピーは不要になったため、削除します。
 model.binができました。
model.binができました。
Creating SageMaker Inference Endpoint
推論用エンドポイントの作成を行います。
次に、さまざまな言語のエンドポイントにいくつかの文を渡して、言語の識別が期待どおりに機能することを確認します。
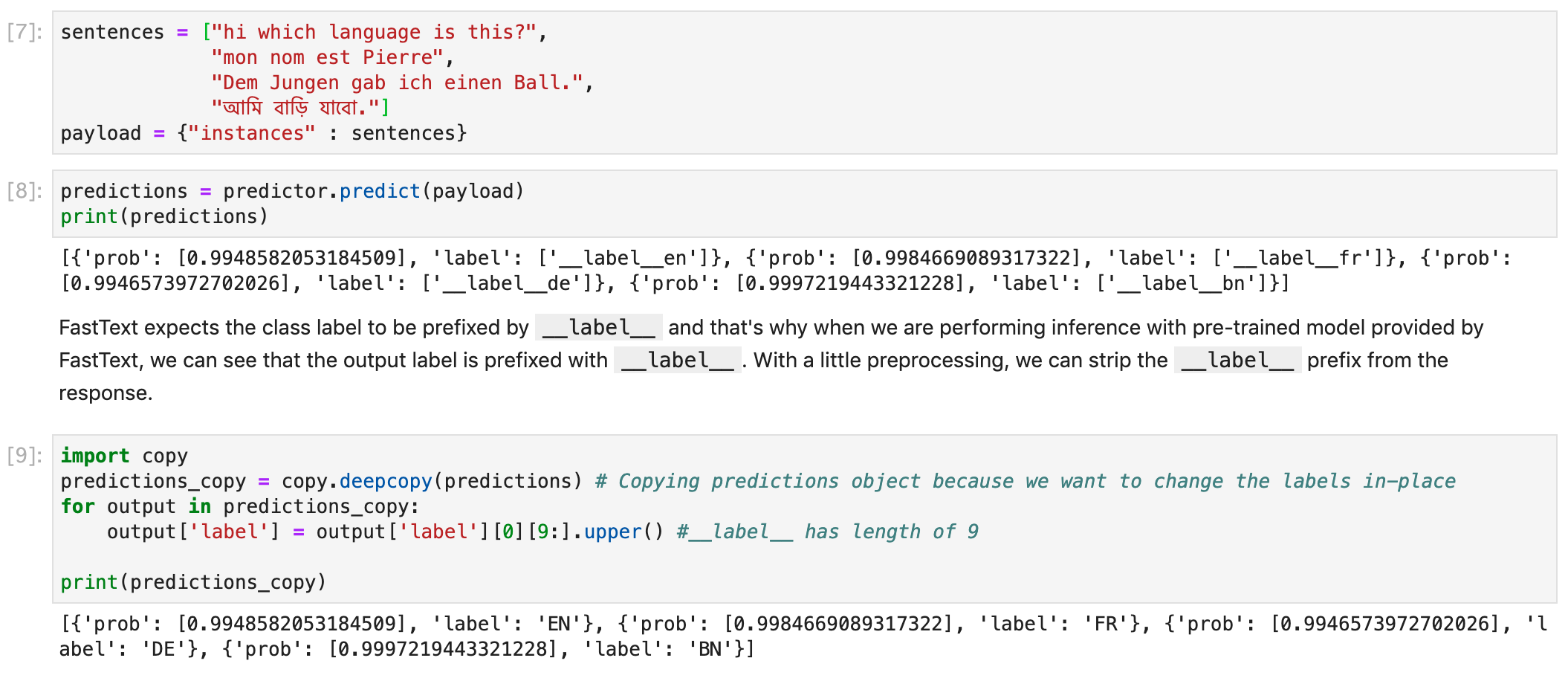
・・・・・・恐らく上手く行っているんだと思われます。
推論-エンドポイント設定やエンドポイントのページで、エンドポイントが無事作成されていることを確認しました。
Stop / Close the Endpoint (Optional)
リアルタイム予測を提供するためにエンドポイントを実行し続ける必要がない場合、ノートブックを閉じる前にエンドポイントを削除します。

同ページから、作成されていたものが消えていれば完了。