サーバーいらずで無料でWebスクレイピングが出来ると聞いて試してみた。
題材が無いとどうしてもやる気が出ないので、少しでもやる気の出るように今回はロト6のデータを取得して
本当にランダムなの?って検証を行った。
colab
まずはcolabに登録して、ファイル→Python3のノートブックを選択
ハードウェアをGPUに変更
colabは毎回閉じると全部入れた物が無くなるので、毎回インストールが必要
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
!pip install selenium
!pip install beautifulsoup4
スクレイピング部分
いろいろ調べたけど、しっかり動かなかったので
ここを参考にしてコードを修正。
Chrome の自動操作で取得することにした。
import time
import random
import pandas as pd
from selenium import webdriver
+ from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# ロト6の当選番号が掲載されているみずほ銀行ページのURL
loto_url1 = 'https://www.mizuhobank.co.jp/retail/takarakuji/loto/backnumber/loto6' # 1~460回目
loto_url2 = 'https://www.mizuhobank.co.jp/retail/takarakuji/loto/backnumber/detail.html?fromto=' # 461回目以降
num = 1
main_num_list = [] # 本数字6桁を格納するリスト
bonus_num_list = [] # ボーナス数字を格納するリスト
- # PhantomJSをselenium経由で利用
- #driver = webdriver.PhantomJS()
+ # ブラウザをheadlessモード(バックグラウンドで動くモード)で立ち上げてwebsiteを表示、生成されたhtmlを取得し、BeautifulSoupで+ 綺麗にする。
+ options = webdriver.ChromeOptions()
+ # 必須
+ options.add_argument('--headless')
+ options.add_argument('--disable-gpu')
+ options.add_argument('--no-sandbox')
+ # エラーの許容
+ options.add_argument('--ignore-certificate-errors')
+ options.add_argument('--allow-running-insecure-content')
+ options.add_argument('--disable-web-security')
+ # headlessでは不要そうな機能
+ options.add_argument('--disable-desktop-notifications')
+ options.add_argument("--disable-extensions")
+ # 言語
+ options.add_argument('--lang=ja')
+ # 画像を読み込まないで軽くする
+ options.add_argument('--blink-settings=imagesEnabled=false')
+ driver = webdriver.Chrome('chromedriver',options=options)
while num <= 1341:
# 第1~460回目までの当選ページのURL
if num < 461:
url = loto_url1 + str(num).zfill(4) + '.html'
# 461回目以降当選ページのURL
else:
url = loto_url2 + str(num) + '_' + str(num+19) + '&type=loto6'
# PhntomJSで該当ページを取得
driver.get(url)
- #time.sleep(2) # javascriptのページを読み込む時間
+ # 途中から取得先のサイトが非同期になってるため、遅延時間を変更
+ time.sleep(5)
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
# ロト6の当選番号がのっているテーブルの取得
table = soup.find_all("table")
del table[0]
for i in table:
# 本数字の取得
main_num = i.find_all("tr")[2].find("td")
main_num_list.append(main_num.string.split(" "))
# ボーナス数字の取得
bonus_num = i.find_all("tr")[3].find("td")
bonus_num_list.append(bonus_num.string)
num += 20 # 次のページに移動するためにnumに20を追加
time.sleep(random.uniform(1, 3)) # 1~3秒Dos攻撃にならないようにするためにコードを止める
# csvで出力
df = pd.DataFrame(main_num_list, columns = ['main1', 'main2', 'main3', 'main4', 'main5', 'main6'])
df['bonus'] = bonus_num_list
df.index = df.index + 1
df.to_csv('loto6.csv')
この処理が終わるとファイルタブにloto6.csvが来てるはず、更新をすると出てくる。
グラフでデータを見てみる
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv('loto6.csv') #ヘッダーをヘッダーにしたまま取得
df = df.drop("Unnamed: 0", axis=1) #1列目を削除
nums_all = df[['main1','main2','main3','main4','main5','main6','bonus']]
plt.rcParams['figure.figsize'] = (8, 6)# 以降の図のデフォルトサイズ
plt.rcParams["font.size"] = 15
# tes = nums_all.values.flatten().size # 個数
tes = (nums_all.sum().sum())/(nums_all.size) # 平均
plt.hist(nums_all.values.flatten(), bins=43, normed=True)
plt.show()
tes
おわりに
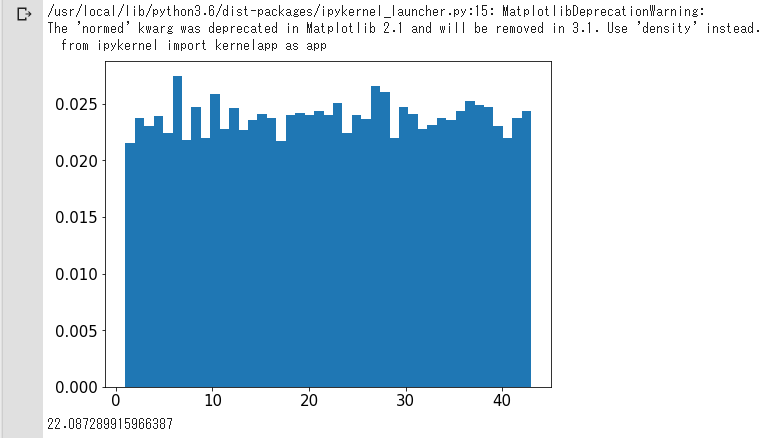
平均は22、ヒストグラムもあんまり、きれいにバラけてますね。
これは機械学習とかで色々やっても無駄かなと思ってしまった。