1. いきさつ
・機械学習を一通りざっと勉強したので実際に腕試しをしてみる。
・Kaggleの終了したコンペに挑戦して実践的に学ぼうという試み。
・初学者の方にもわかりやすく書くことを目指す。(日本語の記事があまりないので)
今回はとりあえずやってみる編、ということで余りいい精度は出ていません。続きの記事でより高度な分析に挑戦します。
github→ https://github.com/Kiro02/kaggle_ride_sharing/blob/master/bike_predict.ipynb
2. 取り組んだ課題
Bike Sharing Demand
https://www.kaggle.com/c/bike-sharing-demand
自転車乗るのが好きなのでこれにしました()
最近都内ではどこのステーションにも乗り捨てできる赤い自転車が目につきますね(僕は使ったことないですが)。
課題としては、与えられたデータから自転車の需要(台数)を予測しろ、ということですね。
なんでそんなことが予測できるかというと、実際に利用された台数と、その時の様々な条件(時刻、天気、曜日など)との間の関係性のモデルを作り、新しいデータをそこに当てはめて台数を予測するという感じです。
予測したいもの(ここでは自転車の需要台数)を目的変数、時刻や天気など、予測の材料となるものを説明変数と言います。
3. データの確認
・必要なライブラリの読み込み
import numpy as np
import pandas as pd
import random as rnd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline #Jupyter Notebookを使う方はこれを書く。
・データの読み込み
df = pd.read_csv("train.csv") #pd.read_csv("ファイル名")で読み込みます。
・データの確認
df.head() #初めから数えて5つのデータを表示します。
 【説明変数】
datetime:日時
season:1 =春、2 =夏、3 =秋、4 =冬
holiday:
workingday:
wether:天候 1=晴れ、2=曇り・霧、3=軽い雨や雪、4=雷雨、雪
temp:気温
atemp:体感気温
humidity:湿度
windspeed:風速
casual:初回利用者数
registered:会員の利用者数
【目的変数】
count:レンタル数
データの型や欠損値の有無も確認しましょう↓
【説明変数】
datetime:日時
season:1 =春、2 =夏、3 =秋、4 =冬
holiday:
workingday:
wether:天候 1=晴れ、2=曇り・霧、3=軽い雨や雪、4=雷雨、雪
temp:気温
atemp:体感気温
humidity:湿度
windspeed:風速
casual:初回利用者数
registered:会員の利用者数
【目的変数】
count:レンタル数
データの型や欠損値の有無も確認しましょう↓
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10886 entries, 0 to 10885
Data columns (total 12 columns):
datetime 10886 non-null object
season 10886 non-null int64
holiday 10886 non-null int64
workingday 10886 non-null int64
weather 10886 non-null int64
temp 10886 non-null float64
atemp 10886 non-null float64
humidity 10886 non-null int64
windspeed 10886 non-null float64
casual 10886 non-null int64
registered 10886 non-null int64
count 10886 non-null int64
dtypes: float64(3), int64(8), object(1)
memory usage: 1020.6+ KB
いずれもnon-nullとありますので、ひとまず欠損値はないようです。ただし、あとでもう少しちゃんと調べる必要があります。
天気や季節などのカテゴリデータはすでにint(整数)型に変換されているので、このまま使えそうです。
datetimeはobjectなのでこのままでは機械学習に使えません。月・日・時刻にわけてそれぞれint型に変換しましょう。
4.前処理
・datetimeの変換
df["date"] = df.datetime.apply(lambda x : x.split()[0])
df["hour"] = df.datetime.apply(lambda x : x.split()[1].split(":")[0])
df["weekday"] = df.date.apply(lambda dateString : calendar.day_name[datetime.strptime(dateString,"%Y-%m-%d").weekday()])
df["month"] = df.date.apply(lambda dateString : calendar.month_name[datetime.strptime(dateString,"%Y-%m-%d").month])
df["season"] = df.season.map({1: "Spring", 2 : "Summer", 3 : "Fall", 4 :"Winter" })
df["weather"] = df.weather.map({1: " Clear + Few clouds + Partly cloudy + Partly cloudy",\
2 : " Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist ", \
3 : " Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds", \
4 :" Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog " })
・hourはこのままではObjectのため学習に使えません。intに変換します。
# hourをintに変換する
size_mapping = {'00':0,"01":1, '02':2, '03':3, '04':4, '05':5, "06":6, "07":7, "08":8, "09":9, "10":10,"11":11, "12":12,
"13":13,"14":14,"15":15,"16":16,"17":17,"18":18,"19":19,"20":20,"21":21,"22":22,"23":23
}
df['hour'] = df['hour'].map(size_mapping)
df.head()

・ヒートマップの表示
ヒートマップとは、各変数間の相関係数(関係性の強さ)を色を使って示してくれる表です。
数字が1に近いほど関係性が強いことを表しています。
plt.figure(figsize=(12, 9))
sns.heatmap(df.corr(), annot=True, square=True, fmt='.2f')
plt.show()
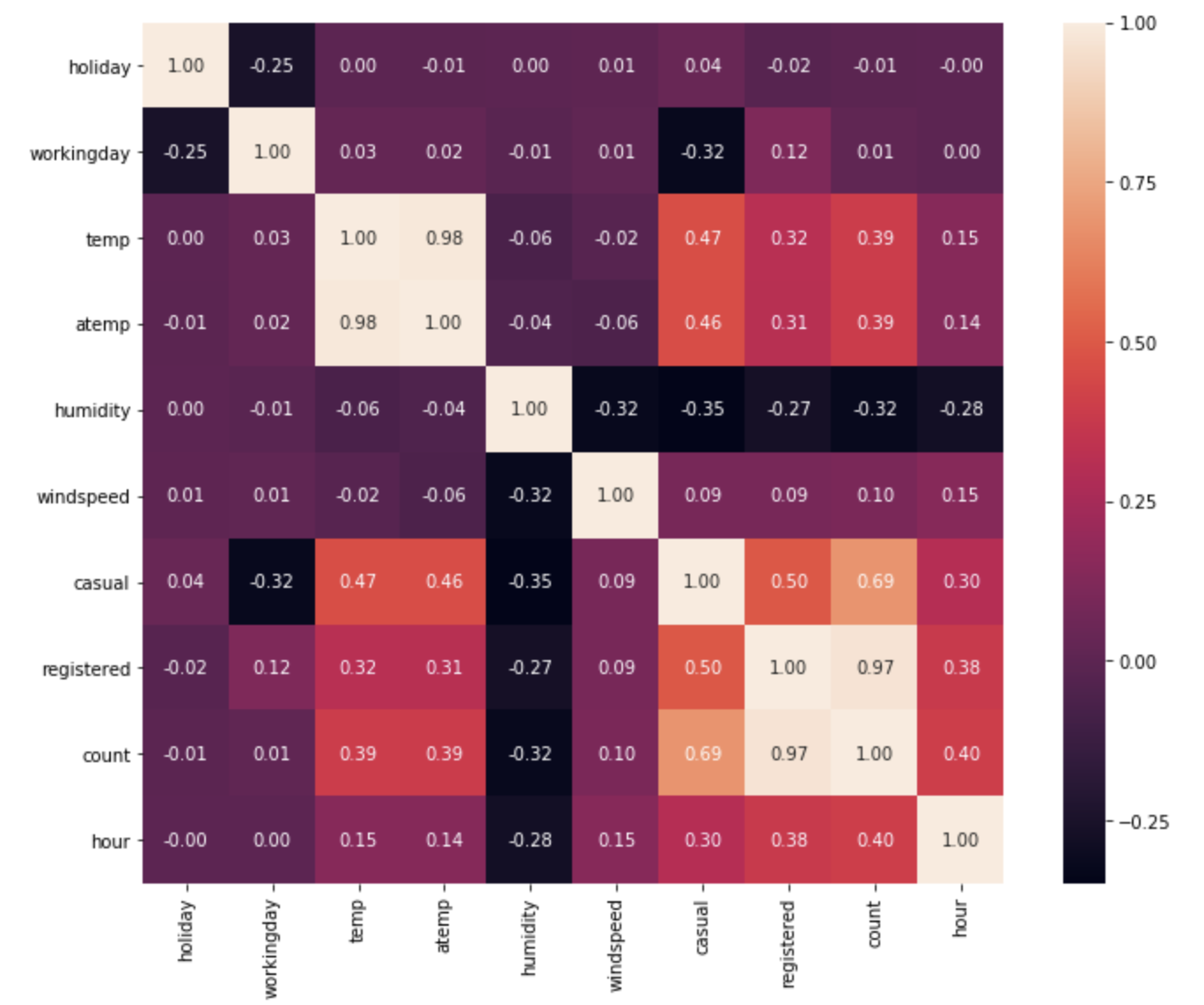 目的変数はcountなので、それに注目すると…
temp,humidity,hourは比較的強い相関を持っていることがわかります。とりあえずこれらを説明変数に採用します。
目的変数はcountなので、それに注目すると…
temp,humidity,hourは比較的強い相関を持っていることがわかります。とりあえずこれらを説明変数に採用します。
ちなみにここでcasualとregistreredを無視しているのは、これらはcountの内訳なので、相関係数が高いのは当たり前で、しかも説明変数として使えないからです。
5. 重回帰分析にかけてみる
では説明変数temp,humidity,hourを使って重回帰分析を行なってみましょう。
重回帰分析という手法の詳しい説明は今回は省略します。
・説明変数Xと目的変数yを設定
X = df.loc[:,["temp","humidity","hour"]].values
y = df.loc[:,["count"]].values
・訓練データとテストデータの分割
元のデータをモデルを作るための訓練データと、モデルを実際に当てはめて評価するためのテストデータに分割します。
ここで分割に使っている手法をホールド・アウト法と言いますが、説明は省略します。
今回は訓練:テストの比率は7:3としました。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
・重回帰分析の実行
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
・正則化(LASSO回帰)の実行
正則化とは、モデルの過学習を抑えて性能を上げるプロセスです。
from sklearn.linear_model import Lasso # LASSO回帰のクラスを読み込み
model_lasso = Lasso(alpha=10) # LASSO回帰のインスタンスを生成
model_lasso.fit(X_train, y_train) # データを学習させる
これで重回帰分析による予測モデルができました。
・モデルの評価を行う
今回のコンペでは、モデルの評価はRMSLE(Rooted Mean Squared Log Error)の数値で行われます。これは誤差関数の一種で、値が低い(0に近い)ほど性能の高いモデルと言えます。

RMSLEを出力する関数を定義します。
def rmsle(real, predicted):
sum=0.0
for x in range(len(predicted)):
if predicted[x]<0 or real[x]<0: #check for negative values
continue
p = np.log(predicted[x]+1)
r = np.log(real[x]+1)
sum = sum + (p - r)**2
return (sum/len(predicted))**0.5
train/testのRMSLEをそれぞれ出力してみましょう。
print("test: ",rmsle(y_test, lr.predict(X_test)))
print("train: ",rmsle(y_train, lr.predict(X_train)))
結果↓

スコアは1.18くらいでした。これはどれくらいの成績なんでしょう。
KaggleのPublic Leaderbordをみてみると、どうやら上から45%くらいの性能のようです。
あまり良いスコアとは言えません。何がいけなかったのでしょうか。
次回は、より精度を上げるために何が必要なのかを考えていきます。