はじめに
iOSの機械学習フレームワークCoreMLではKerasで訓練済みの機械学習モデルを利用することができます。
本記事ではKerasによる回帰モデルをCoreML上で動くように変換し、実際に予測を行うまでの流れについて解説します。
大まかな流れとしては以下のようになります。
- 1: Kerasで回帰モデルを作成/学習し、.h5ファイルとして出力する
- 2: coremltoolsを用いて出力した.h5ファイルを.mlmodelファイルに変換する
- 3: iOSのCoreML上で回帰モデルとして使用する
本記事における実行環境
- Python: 3.7.7
- Keras: 2.3.1
- Swift: 5
- iOS: 13.5
- Xcode: 11.5
1: 回帰モデルを.h5ファイルとして出力
https://www.tensorflow.org/tutorials/keras/regression
今回は上記チュートリアルに基づいて自動車の燃費を予測する回帰モデルを作成し、.h5ファイルとして出力します。
ただし、チュートリアルのコードをそのまま実行してできたモデルをCoreMLで使用できる形式に変換しようとするとエラーが発生します。KerasをTensorflow経由でimportしていることが関係しているようです。
そのためKerasを直接importする形に書き直して実行します。下記コードをご参照ください。
from __future__ import absolute_import, division, print_function, unicode_literals
import pathlib
import pandas as pd
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras import optimizers
dataset_path = keras.utils.get_file("auto-mpg.data", "https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
dataset = dataset.dropna()
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
def build_model():
model = Sequential([
Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
Dense(64, activation='relu'),
Dense(1)
])
optimizer = optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])
# これでモデルを.h5ファイルに出力します。
model.save("SampleReg.h5")
2: .h5ファイルを.mlmodelファイルに変換
先ほど作成した.h5ファイルをCoreMLで扱える.mlmodelファイルに変換します。
まずは変換に必要なcoremltoolsをPythonにインストールします。
$ pip install -U coremltools
また、TensorflowやKerasが手元のPython環境にインストールされていない場合は改めてインストールしておいてください。
インストールが完了したら、下記のコードを実行することで.h5ファイルを.mlmodelファイルに変換することができます。
import coremltools
coreml_model = coremltools.converters.keras.convert('SampleReg.h5')
coreml_model.save('SampleRegonCoreML.mlmodel')
3: CoreMLでモデルを使う
Xcodeを起動しiOSプロジェクトを新規に作成し、ファイル一覧に先ほど作成した.mlmodelファイルを追加します。
この.mlmodelファイルをクリックすると、以下の図のようにモデルの概要が表示されます。
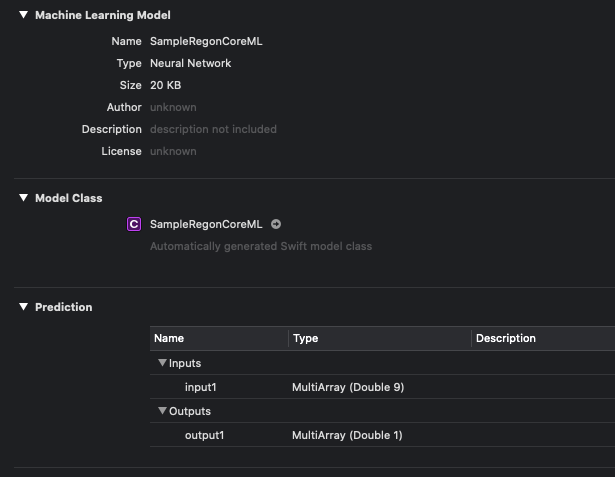
入力(Inputs)として9つの変数を取り、出力(Outputs)として1つの変数を出すモデルであることが確認できます。
MultiArrayというのはMLMultiArrayというCoreMLのクラスを指すようで、これはモデルの入出力を扱うための多次元配列のクラスになります。形状(Shape)やデータ型を指定して配列を作ることができます。
それではこのモデルを使って実際に予測を行います。下記のコードをご参照ください。
import CoreML
// .mlmodelファイルを追加した時点でモデルと同じ名前のクラスが自動的に生成され、
// さらにそれらの入力データ/出力データを扱うクラスも作られます(名前は「モデル名+Input/Output」)。
let model = SampleRegonCoreML()
// MLMultiArrayはこのように配列形状とデータ型を指定して初期化することができます。
// let inputArray = try! MLMultiArray(shape: [9], dataType: MLMultiArrayDataType.double)
// 一方で従来の配列から直接作ることもできます。今回は元のデータセットから抜き出した1データについて直打ちしてみました。
let inputArray = try! MLMultiArray([1.483887,1.578444,2.890853,1.925289,-0.559020,-1.604642,0.774676,-0.465148,-0.495225])
// 上の配列を用意したモデルの入力としてあてがいます。
let inputToModel: SampleRegonCoreMLInput = try! SampleRegonCoreMLInput(input1: inputArray)
// 予測を行い、その結果を出力します。
if let prediction = try? model.prediction(input: inputToModel) {
print(prediction.output1)
}
Keras側で同データについてmodel.predict()した結果と、上記コードによって出力される結果が一致することを確認します。