はじめに
"Pythonではじめる機械学習"の決定木のアンサンブル法(p82~90)の学習記録です。
・分からなかったコードやドキュメント
・自分にとって理解するのに時間がかかった内容
・用語の定義
に関する説明を主に記述しています。
参考書を読んでいて容易に理解できたことは記述していません。
2.3.6 決定木のアンサンブル法
アンサンブル法(Ensembles)とは、複数の機械学習モデルを組み合わせることで、より強力なモデルを構築する方法である。
主なアンサンブル法は、ランダンフォレストと勾配ブースティング決定木である。
2.3.6.1 ランダンフォレスト
ランダムフォレストとは少しずつ異なる決定木を集めたもの
✳︎p82~p83の説明が全体的に分からなかったので、再読する必要あり。
# In[66]
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
# stratifyで指定したデータの比率を均等に分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
# n_estimatorsで決定木の数を指定
forest = RandomForestClassifier(n_estimators=5, random_state=2)
forest.fit(X_train, y_train)
# In[67]:
# ravel関数は、多次元のリストを1次元のリストにして返す
# enumerateはforループの中でリストやタプルなどのイテラブルオブジェクトの要素と同時にインデックス番号(カウント、順番)を取得できる
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for i, (ax, tree) in enumerate(zip(axes.ravel(), forest.estimators_)):
ax.set_title("Tree {}".format(i))
mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)
# グラフの透過度の指定がalpha
mglearn.plots.plot_2d_separator(forest, X_train, fill=True, ax=axes[-1, -1], alpha=.4)
axes[-1, -1].set_title("Random Forest")
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
Out[67]:
5つのランダム化された決定木による決定境界と、それらを平均して得られた決定境界
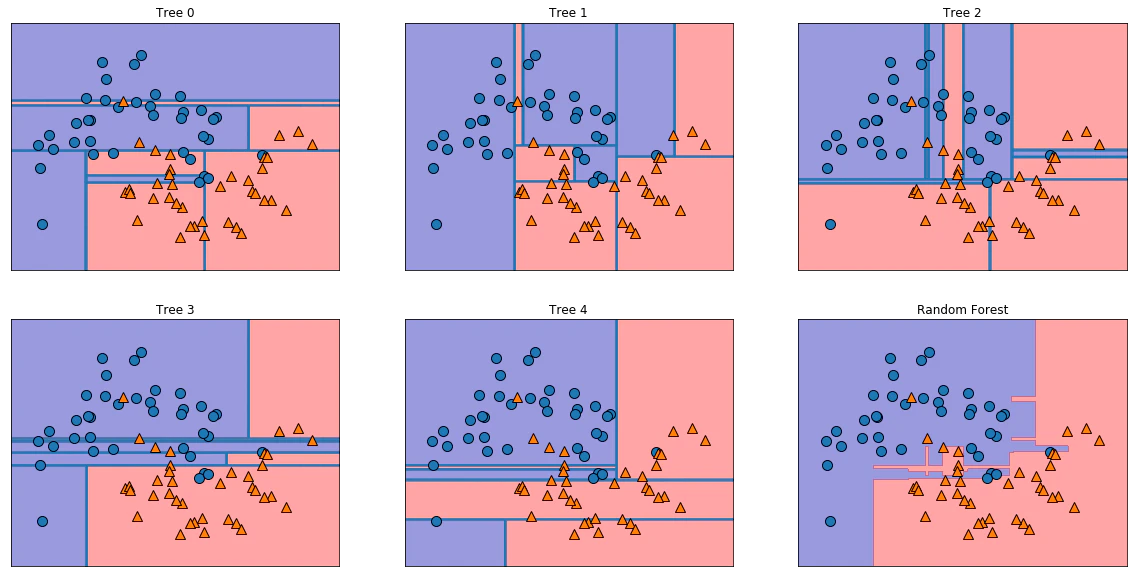
ランダムフォレストは個々のどの決定木よりも過剰適合が少なく、直感に合致した決定境界を描いている。
回帰でもクラス分類でも、ランダムフォレストが最も多く使われている機械学習手法である。
2.3.6.2 勾配ブースティング回帰木(勾配ブースティングマシン)
勾配ブースティング回帰木は、複数の決定木を組み合わせてより強力なモデルを構築するもう一つのアンサンブル手法である。
1つ前の決定木の誤りを次の決定木が修正するようにして、決定木を順番に作っていく。
ランダムフォレストの方が頑健だが、予測時間が重要な場合や、機械学習モデルから最後の1%まで性能を絞り出したい場合は勾配ブースティングを試す。
勾配ブースティングが教師あり学習の中で最も強力で広く使われているモデルである。
メモ:
jupyter notebookで何故か、定義した変数やインポートしたモジュールが定義されていないという表示が稀に起きる。その場合、jupyter notebookを終了して再起動した後、実行すれば直る。原因は不明。