はじめに
始めまして、株式会社ジールの@KimiyukiMuramatsuです。
AWSを使ったデータ分析基盤の構築を業務としております。
その中で得たノウハウをQiitaを通して発信していきたいと思います。
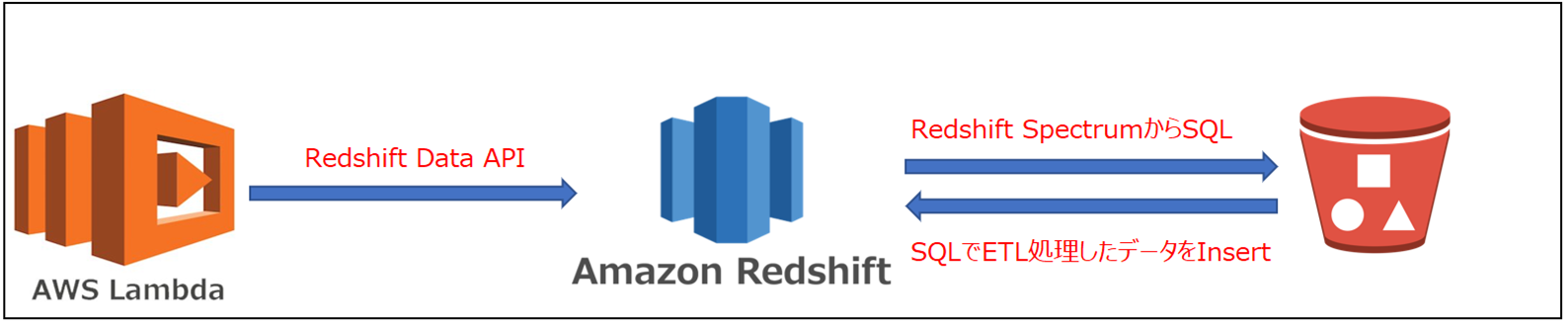
Lambdaを使って、S3上のファイルに対してETL処理を行い、Redshiftにロードする方法を検討しておりました。
Redshift Data APIを使って実現できると考え、検証してみました。
Redshift Data APIを使うことで、LambdaからRedshiftのSQLを呼び出すことができます。
SQLを使えれば、Redshift Spectrumにより、S3上のファイルをETL処理してからRedshiftのテーブルにロードできます。
(Insert Into Select From ~ )
検証したいこと
- Redshift Data APIを使って、LambdaからRedshift SpectrumのSQLを呼び出してS3上のファイルをETL処理し、RedshiftのテーブルにInsertする。
前準備
Redshift Spectrumを使ってS3上のファイルを参照するために以下1~3の前準備が必要になります。
- RedshiftにIAMロールを割り当てる。
- Redshiftで外部スキーマを作成する。
- RedshiftからS3上のファイルを外部テーブルとして定義する。
1. RedshiftにIAMロールを割り当てる。
Redshift Spectrumを使うには以下にアクセスする権限が必要になります。
- S3上のファイル
- Athena Data CatalogもしくはAWS Glue Data Catalog
そのため今回の検証では、以下①~③のAWS管理ポリシーを含めたIAMロールを割当てました。
① AmazonS3FullAccess
② AmazonAthenaFullAccess
③ AWSGlueConsoleFullAccess
2. Redshiftで外部スキーマを作成する。
Redshift Spectrumは外部テーブルとしてS3上のファイルを参照します。
その外部テーブルは、外部スキーマ内に作成します。
今回の検証では以下のデータベース名、外部スキーマ名で作成しました。
データベース名:spectrum_db
外部スキーマ名:spectrum_schema
Redshiftコンソールのクエリエディタから以下のSQLを実行してデータベースと外部スキーマを作成しました。
create external schema spectrum_schema from data catalog
database 'spectrum_db'
iam_role 'arn:aws:iam::<AWSアカウントNo>:role/<IAMロール名>'
create external database if not exists;
3. RedshiftからS3上のファイルを外部テーブルとして定義する。
今回の検証では、S3上の2つのCSVファイル(allusers, sales)をSelectして結合するため、Create External Tableを実行して外部テーブルを定義します。
以下はRedshiftコンソールのクエリエディタから実行したSQLです。
#####・allusers
S3上のalluserのCSVファイルが保存されるフォルダをlocationで指定します。また、CSVファイルであるため、fields terminated byでカンマを指定します。
CREATE EXTERNAL TABLE spectrum_schema.allusers(
userid int,
username varchar(8),
firstname varchar(30),
lastname varchar(30),
city varchar(30),
state varchar(30),
email varchar(100),
phone varchar(14),
likesports varchar(8),
liketheatre varchar(8),
likeconcerts varchar(8),
likejazz varchar(8),
likeclassical varchar(8),
likeopera varchar(8),
likerock varchar(8),
likevegas varchar(8),
likebroadway varchar(8),
likemusicals varchar(8))
row format delimited
fields terminated by ','
stored as textfile
LOCATION
's3://<バケット名>/allusers/';
#####・sales
salesについては、以下のように年別(year)、月別(month)で分けられたフォルダにCSVファイルが保存されます。
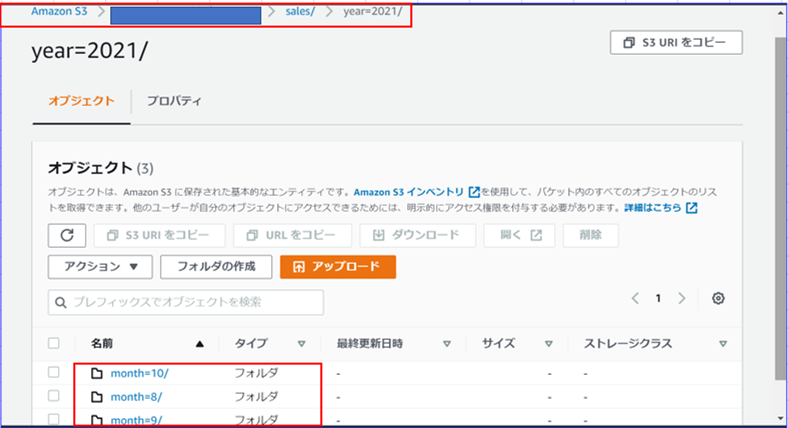
Redshift SpectrumからSelectする時、Where句に指定した年(year)と月(month)に一致するフォルダのみスキャンするようPartiton Byでパーティションキーを指定します。
さらに、パーティションとなるフォルダもAlter Table Add Partitionで指定します。
CREATE EXTERNAL TABLE spectrum_schema.sales(
salesid integer,
listid integer,
sellerid integer,
buyerid integer,
eventid integer,
dateid integer,
qtysold integer,
pricepaid decimal(8,2),
commission decimal(8,2),
saletime timestamp)
PARTITIONED BY (year integer,month integer)
row format delimited
fields terminated by ','
stored as textfile
LOCATION
's3://<バケット名>/sales/'
table properties ('numRows'='172000');
alter table spectrum_schema.sales add
partition(year=2021,month=8)
location 's3://<バケット名>/sales/year=2021/month=8/';
alter table spectrum_schema.sales add
partition(year=2021,month=9)
location 's3://<バケット名>/sales/year=2021/month=9/';
alter table spectrum_schema.sales add
partition(year=2021,month=10)
location 's3://<バケット名>/sales/year=2021/month=10/';
Redshift SpectrumによるETL
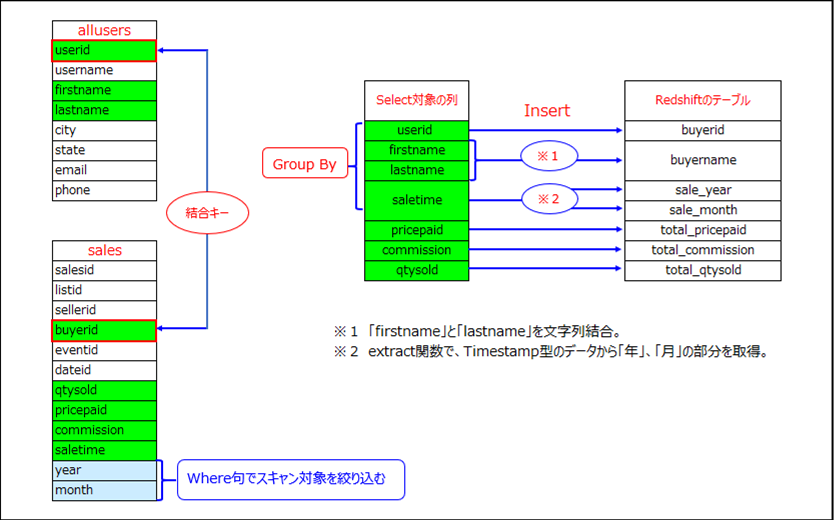
- 以下2つのCSVファイルを結合し、Group Byで集約した上でRedshiftのテーブルにInsertします。
Lambdaファンクションを作成する
次にRedshift APIを実行するLambdaファンクションを作成します。
以下は今回の検証での設定内容になります。
#####1. ランタイム
⇒ Python3.9
#####2. Lambdaファンクションに割り当てるIAMロール
Lambdaファンクション作成時にデフォルトで割当てられるポリシーの他にRedshift Data APIにアクセスする権限が必要になるため以下のAWS管理ポリシーを含めました。
- lambda_basic_execution ロール
- AmazonRedshiftFullAccess
以下はPythonでコーディングしたプログラムです。
import json
import time
import boto3
# Redshiftに対する接続情報(クラスター名、データベース名、ユーザー名)
CLUSTER_NAME='redshift-cluster-1'
DATABASE_NAME='dev'
DB_USER='awsuser'
# RedshiftSpectrumで実行するSQL
SQL_TEXT = """Insert Into public.tutorial_buyer_total
Select sales.buyerid,
allusers.firstname + allusers.lastname as buyer_name,
sum(sales.qtysold) as qtysold_total,
sum(sales.pricepaid) as pricepaid_total,
sum(sales.commission) as commission_total,
extract(year from sales.saletime) as sale_year,
extract(month from sales.saletime) as sale_month
From spectrum_schema.sales, spectrum_schema.allusers
where sales.buyerid = allusers.userid
And sales.year = extract(year from TIMEZONE ('Asia/Tokyo', sysdate))
And sales.month = extract(month from TIMEZONE ('Asia/Tokyo', sysdate))
Group By sales.buyerid, allusers.firstname + allusers.lastname,sale_year,sale_month
Order By sales.buyerid;"""
def lambda_handler(event, context):
data_client = boto3.client('redshift-data')
# RedshiftSpectrumでのSQLを実行。 S3上のファイルを読み込み、テーブルにINSERT。
result = data_client.execute_statement(ClusterIdentifier=CLUSTER_NAME,
Database=DATABASE_NAME,
DbUser=DB_USER,
Sql=SQL_TEXT)
# RedshiftSpectrumで実行したSQLのIDを取得
QueryId = result["Id"]
completed = False
# SQLの実行結果を取得
while completed == False:
description = data_client.describe_statement(Id = QueryId)
if description["Status"] in ("FINISHED", "FAILED", "ABORTED"):
print("status :".format(status))
completed = True
return QueryId
検証結果
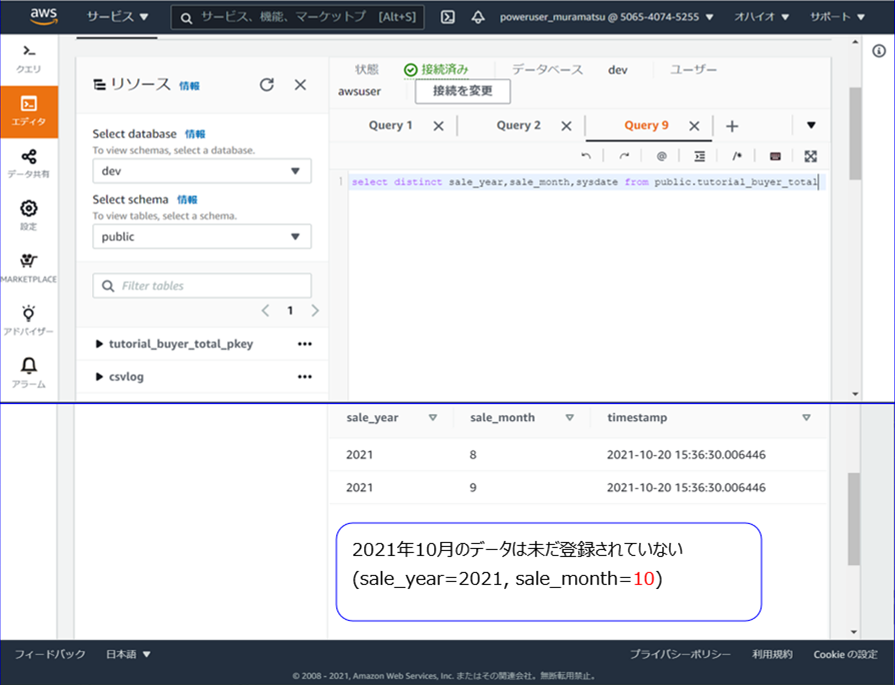
月次でS3上のCSVファイルをETL処理してからRedshiftのテーブルに登録するシナリオで検証しました。
Redshiftのテーブルには、 2021年8月~9月分のデータが登録済みです。
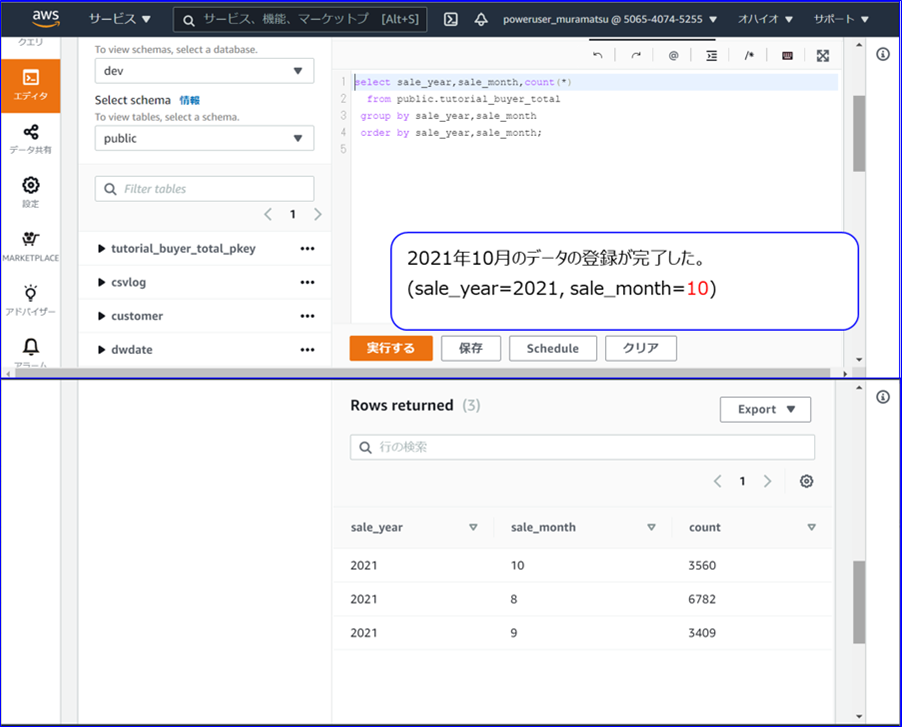
S3上にアップロードした2021年10月分の月次ファイルのデータをテーブルに追加登録しました。
以下は、Lambdaをテスト実行した結果になります。
-
Redshiftのテーブル (Lambda実行前)
-
Redshiftのテーブル (Lambda実行後)
おわりに
Lambdaを使って、S3上のファイルをETL処理してRedshiftにロードできることが確認できました。
さらに、Redshift Data APIには、非同期で実行できるという特徴があります。
つまり、LambdaファンクションからAPIが発行され、Redshiftでリクエストを受け取るとすぐにSQL発行のレスポンスが返されます。(成功、失敗、異常のいづれか)
Lambdaには15分という実行時間の制約がありますが、Redshift Data APIであればこの制約を回避できます。
一方で非同期であるがゆえの課題もございます。
今回の検証の場合、Redshift SpectrumによるSQLが正常に開始されたことまでは確認できますが、SelectしたデータをテーブルへInsertした時に発生するエラーを検知するには別の仕組みが必要です。
Redshift Data APIには、「get-statement-result」というメソッドが用意され、APIで実行したクエリの結果を取得できます。このメソッドを使って、Insertしたデータに対してクエリを実行することでInsertの正常終了を確認できそうです。
次回はこの検証結果をご紹介させていただきたいと思います。
ご案内
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください:
https://www.zdh.co.jp/products-services/cloud-data/zeuscloud/?utm_source=qiita&utm_medium=referral&utm_campaign=qiita_zeuscloud_content-area