はじめに
まずはこちらをご覧ください。
【6秒クッキング】お好み焼き
https://www.youtube.com/watch?v=fQUT-nrfreo&list=PLcWVQwcFBzLeXwHjaK3Z1oGJjzoPYKxA7&index=8
動作環境
- Python 3.6.8
- YouTube Data API ※使用前に登録が必要。
- scikit-learn
- MeCab
- 単語感情極性対応表 ※コメントのネガポジ判定用
- seaborn
検証内容
- キッチンジローの「タダで見てんだから黙ってろ」発言で批判コメント数が減ったのかを検証する。
- 批判コメントの例:「キッチンジロー口悪すぎだし何もしてないじゃん」
実装内容
- 6秒クッキングの動画情報を取得する
- 全コメントを取得する
- Youtube Data APIを使用してコメントとそれに対するリプライコメントを取得する。
- コメント以外の情報(コメントした人のID等)は取得しない。
- 全コメントからキッチンジローへの批判コメントを抽出する
- 批判コメント数の推移を可視化する
ソースコード・出力結果
6秒クッキングの動画情報を取得する
import copy
import json
import re
import matplotlib.pyplot as plt
import MeCab
import pandas as pd
# markdown出力用
import pytablewriter
import requests
import seaborn as sns
from sklearn.feature_extraction.text import CountVectorizer
API_KEY = '自分のAPIキーを入力する'
VIDEO_ID = 'IEkLSfs1F68'
CHANNEL_ID = 'UCpCesuCH4UxIcy65gSrC0Pw'
BASE_URL = 'https://www.googleapis.com/youtube/v3/'
def get_video_info(api_key, channel_id, page_token):
url = BASE_URL + 'search'
param = {
'key': api_key,
'channelId': channel_id,
'part': 'snippet,id',
'order': 'date',
'maxResults': '100',
}
if page_token:
param['pageToken'] = page_token
response = requests.get(url, params=param)
return response.json()
def get_video_df(api_key, channel_id):
page_token = ''
info = []
while page_token != None:
resource = get_video_info(api_key, channel_id, page_token)
info.extend([
[item['id']['videoId'],
item['snippet']['title'],
item['snippet']['publishedAt']]
for item in resource['items'] if item['id']['kind'] == 'youtube#video'
])
if 'nextPageToken' in resource:
page_token = resource['nextPageToken']
else:
page_token = None
video_df = pd.DataFrame(
info, columns=['videoId', 'title', 'publishedAt'])
return video_df
def get_comment_info(api_key, video_id, page_token):
url = BASE_URL + 'commentThreads'
param = {
'key': api_key,
'videoId': video_id,
'part': 'replies, snippet',
'maxResults': '100',
}
if page_token:
param['pageToken'] = page_token
response = requests.get(url, params=param)
return response.json()
def get_video_comments(api_key, video_id):
comments = []
page_token = ''
while page_token != None:
resource = get_comment_info(api_key, video_id, page_token)
for comment_thread in resource['items']:
# コメント取得
comment = comment_thread['snippet']['topLevelComment']['snippet']['textDisplay']
comments.append(comment)
if ('replies' in comment_thread) and ('comments' in comment_thread['replies']):
for replies in comment_thread['replies']['comments']:
# コメント取得
reply_comment = replies['snippet']['textDisplay']
comments.append(reply_comment)
if 'nextPageToken' in resource:
page_token = resource['nextPageToken']
else:
page_token = None
return comments
# チャンネル内の全動画の情報を取得する(投稿日降順)
video_df = get_video_df(API_KEY, CHANNEL_ID)
# 6秒クッキング動画の情報だけを取得する
cook_video_df = video_df.query(
"title.str.contains('[66]+秒クッキング')", engine='python')
# インデックスを振りなおす
cook_video_df = cook_video_df.reset_index(drop=True)
# 出力する
writer = pytablewriter.MarkdownTableWriter()
writer.from_dataframe(cook_video_df)
writer.write_table()
| videoId | title | publishedAt |
|---|---|---|
| oZSKPVOq0nI | 6秒クッキング「パフェ」 | 2020-09-14T10:30:14Z |
| isnpFUkLr04 | 6秒クッキング「かき氷」 | 2020-08-10T10:30:02Z |
| 70zBLpnJ9y0 | 6秒クッキング「冷やし中華」 | 2020-07-06T10:30:01Z |
| BkbbC_3zZAY | 6秒クッキング「コーンスープ」 | 2020-04-06T10:30:02Z |
| LcBy4SsNC7c | 6秒クッキング「ポトフ」 | 2020-02-10T13:00:06Z |
| yn-4sWu91Lw | 6秒クッキング「フライドチキン」 | 2019-12-23T13:00:12Z |
動画情報が取得できました。全部で29本あります。
なんかお腹空いてきたな。
各動画のコメントを取得し、批判コメント数を集計する
# 単語感情極性対応表の読み込み
df_pn = pd.read_csv('./pn_ja.dic', delimiter=':',
encoding='cp932', names=['単語', '読み', '品詞', '感情値'])
def parse_text(text):
token = []
tagger = MeCab.Tagger()
node = tagger.parseToNode(text)
while node:
if node.feature.split(',')[0] != 'BOS/EOS':
token.append(node.feature.split(',')[6])
node = node.next
return token
def calc_polarity(token_list):
polarity = 0
for token in token_list:
token_pol_series = df_pn[df_pn['単語'] == token]['感情値']
token_pol_sum = token_pol_series.sum()
polarity += token_pol_sum
return polarity
# %% ある動画に対するコメントを取得、解析する
for index, row in cook_video_df.iterrows():
comments = get_video_comments(API_KEY, row['videoId'])
# 改行タグの削除
comments = list(map(lambda x: re.sub('<br />', '', x), comments))
# コメント数
n_comments = len(comments)
# 批判コメント候補を取得する
filtered_comments = list(filter(lambda x: len(
re.findall('キッチンジロー', x)) > 0, comments))
# 批判コメント候補を分かち書きする
parsed_comments = list(map(parse_text, filtered_comments))
# 感情値を計算する
polarity_list = list(map(calc_polarity, parsed_comments))
df_comment_pol = pd.DataFrame(
{'comment': filtered_comments, 'polarity': polarity_list})
# 感情値が負になっているコメントを批判コメントとする
df_comment_pol = df_comment_pol.query('polarity<-1.0')
writer.from_dataframe(df_comment_pol)
writer.write_table()
# 批判コメント数と総コメント数をセットする
cook_video_df.loc[index, 'total_comment'] = n_comments
cook_video_df.loc[index, 'negative_comment'] = df_comment_pol.shape[0]
批判コメントとして判定されたものはこちら(一部抜粋)。絶対みんな高評価押してる。
精度はそこまでよくなさそうですが、とりあえず抽出できました。
| comment | polarity |
|---|---|
| キッチンジローなんにもしてないのに食べる時咳き込むのわざとらしいです。長田さんが一生懸命6秒で作ってるのにキッチンがめんつゆのキャップ開けないで(仕事しない)食うだけ、半裸エプロン、美味しいと言うだけ、でクッキング助手失格。咳き込むなんて言語道断。次回に期待して高評価は押しましたが次からキッチンは、気をつけて下さい! | -20.352 |
| キッチンジローって何者なん?だいぶ長田さんに馴れ馴れしくしてるけどさ、彼をテレビで見たことないよ?今日も蓋開け忘れた自分のミスを棚に上げて味に文句ばっかつけてるし。まあ高評価押したけどさあ | -12.298 |
| 6秒クッキングを見続けて自分なりに解釈した事ですが、あまり深く考えない性格なので…クッキング始まるまでにいかに小癪な方法で作業を少しずつ減らすか→6秒始まればスピーディにやれるまで全力でやる→足りない作業はさりげなく?仕上げる→なんやかんやでキッチンジローさんの美味しい!リアクションを楽しむ(たまにちと違いますが)と、楽しませていただいてます! | -16.730 |
| キッチンジローさん、あなたアシスタントですよね?あげてと言われたのになぜあげないんですか?6秒クッキングのアシスタントとして最高ですよ | -3.602 |
| 長田さんはきっちり6秒で終わらせたがってるのにキッチンジローさんが早く取らないのかわいそう😢 | -2.774 |
| アシスタントのキッチンジローのせいで6秒が成立してない。更迭すべき。 | -3.553 |
| キッチンジローあいっかわらず何もしてなくて 草 | -4.226 |
総コメント数(total_comment)と批判コメント数(negative_comment)が集計できたので、可視化してみます。
| videoId | title | publishedAt | total_comment | negative_comment |
|---|---|---|---|---|
| oZSKPVOq0nI | 6秒クッキング「パフェ」 | 2020-09-14T10:30:14Z | 648 | 37 |
| isnpFUkLr04 | 6秒クッキング「かき氷」 | 2020-08-10T10:30:02Z | 307 | 18 |
| 70zBLpnJ9y0 | 6秒クッキング「冷やし中華」 | 2020-07-06T10:30:01Z | 618 | 48 |
| BkbbC_3zZAY | 6秒クッキング「コーンスープ」 | 2020-04-06T10:30:02Z | 311 | 17 |
| LcBy4SsNC7c | 6秒クッキング「ポトフ」 | 2020-02-10T13:00:06Z | 325 | 14 |
| yn-4sWu91Lw | 6秒クッキング「フライドチキン」 | 2019-12-23T13:00:12Z | 237 | 20 |
批判コメント数の推移を可視化する
# %% 批判コメント数推移の可視化
# 総コメント数における批判コメントの割合
cook_video_df['negative_comment_ratio'] = cook_video_df['negative_comment'] / \
cook_video_df['total_comment']
# 集計用のDataFrameを作成
df_agg = cook_video_df.sort_values('publishedAt')
# %% インデックスを投稿日に変更
plt.rcParams["font.family"] = "Meiryo"
for y_name in ['total_comment', 'negative_comment', 'negative_comment_ratio']:
plt.figure(figsize=(18, 5))
sns.barplot(x='title', y=y_name, data=df_agg)
plt.xticks(rotation=90)
plt.tight_layout()
plt.savefig('./boxplot_' + y_name + '.png')
総コメント数の推移
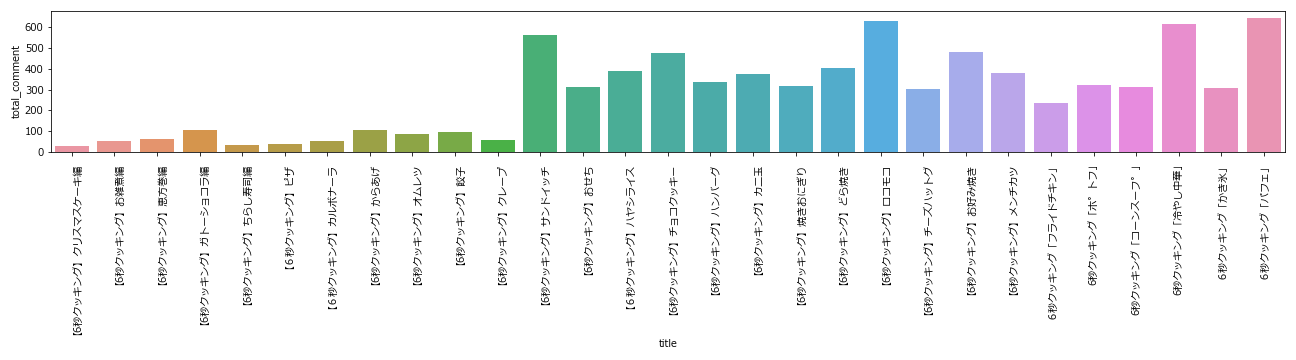
サンドイッチ回以降、コメント数がグンと伸びています。
批判コメント数の推移
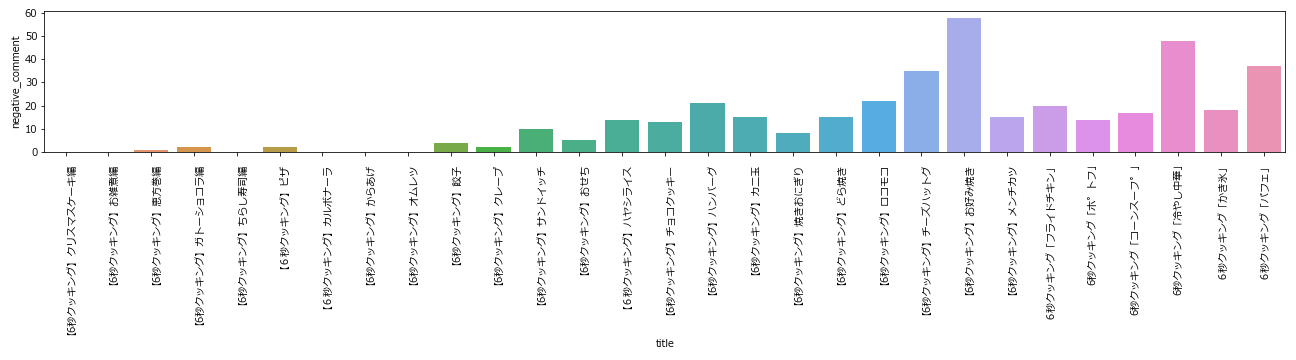
批判コメント数の推移を見ると、お好み焼き回で批判が殺到していることが分かります。
つまり「タダで見てんだから黙ってろ」は火に油だったわけですね。
総コメント数に対する批判コメント数の比率
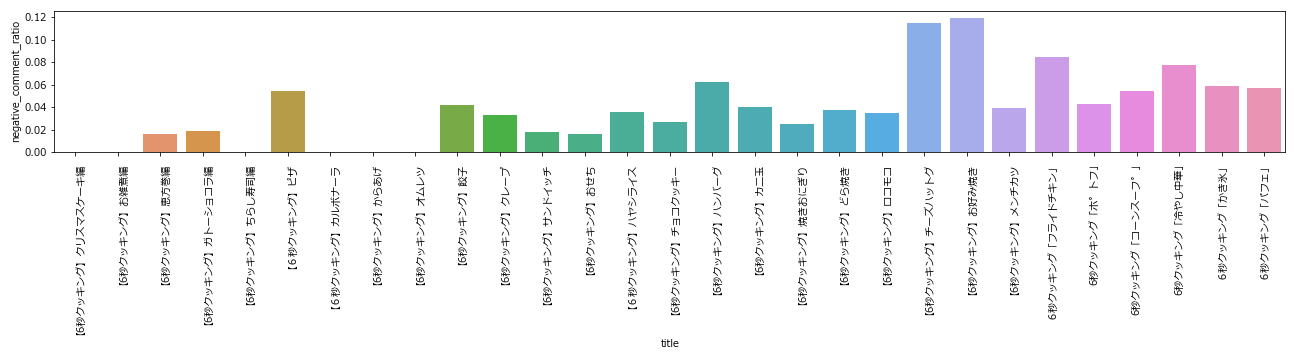
こちらも批判コメント数の推移と大体同じような傾向が出ています。
まとめ
キッチンジローほんとに見てるだけで仕事しないよな。高評価押してきます。
参考リンク
参考にさせていただきました。ありがとうございました。
【自然言語処理】テキストデータを極性辞書で感情分析してみる
極性辞書を用いたネガポジ分析|実践的自然言語処理入門 #5
チョコレートプラネットチャンネル