はじめに
きっかけはおしごと
「インデックスを見直してください」
「どうやるんですか」
「まぁ、調べればわかるから……」
「あ、わかりましたー(わからなきゃ)」
ということで、インデックスについて調べてまとめてみました。
インデックスとは?
検索のパフォーマンスを向上させるための機能のこと。
といってもイメージが沸かない人のために、アラサー女子の婚活に例えて説明します。
今まで仕事一筋、自らキャリアウーマンの道を歩んできたけど、周囲の結婚ラッシュに
婚活サイト登録を決意。年下が好みなので20代男性にフォーカスしたいところ。
早速、サイト内の男性会員リストを眺め始めましたが……。

「なんなの? この会員リスト、20代だけ探したいのにバラバラで、時間がかかるわ。
最初から年齢順に並ばせときなさいよ~、まったく気が利かないわねっ! 」
婚活女子が怒るのも無理はありません。このリストで20代を全て抽出するには、
上から下まで全て見なければいけません。(これを全表検索と呼びます)
もし年齢を昇順で並べてあれば、30才以降は探す手間が省け、効率的です。
はてさて、データベースに話を戻します。インデックスを作成することの意味は、
あらかじめ特定の列で並び替えを想定し、検索を効率化することにあります。
以下のような表 D_MemberList があるとき
| No | Name | Age | Income |
|---|---|---|---|
| 1 | A | 23 | 3,200,000 |
| 2 | B | 47 | 6,500,000 |
| 3 | C | 52 | 5,200,000 |
| 4 | D | 38 | 2,500,000 |
| 5 | E | 24 | 23,000,000 |
Ageが30未満のメンバを選択するSQLはこのように書けます。
SELECT Name, Age FROM D_MemberList WHERE Age < 30;
このとき D_MemberList の Age列にインデックスがあれば良い、
という認識でいいかと思います。実際にはもっとゴニョッとしてます。
インデックスの種類
SQLServerのインデックスは、大きく分けると「クラスター化インデックス」、
「非クラスター化インデックス」に分類されます。
クラスター化インデックス
- テーブル内に1つまで作成可能
- PRIMARY KEY 制約を設定すると自動的に作成
非クラスター化インデックス
- テーブル内に999個まで作成可能
- UNIQUE 制約を設定すると自動的に作成
クラスター化インデックスを作成すると、テーブル内のデータが並び替えられるため、
テーブル内で1つしか作成できませんが、そのパフォーマンスは強力です。
大体はどのテーブルにもクラスター化インデックスが1つ存在していて、
必要に応じて別途、非クラスター化インデックスを追加するイメージです。
インデックスの内部構造
SQLServerのインデックスは、Bツリーの構造をしています。
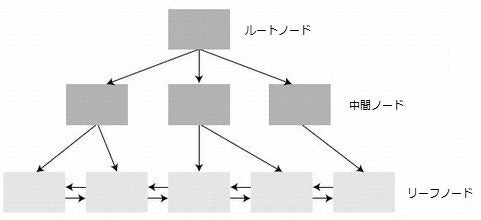
Bツリーは、木を逆さまにした構造で、最上位がルート(根っこ)で、
最下位がリーフ(葉っぱ)、その間が中間です。データは昇順に並び替えられ、
データの範囲によって枝分かれします。またインデックスの種類によって、
リーフノードに違いがあります。
クラスター化インデックス
- リーフノードに実際のデータを格納
非クラスター化インデックス
- クラスター化インデックスがある場合、リーフノードにそのキーが格納される
- クラスター化インデックスがない場合、リーフノードに行識別子(RID)を格納する
非クラスター化インデックスは、テーブル内のデータが順番に並んでいないため、
クラスター化インデックスのキーを使用したり(キー参照)、行識別子を取得した情報を
元に(RID Lookup)、実際のテーブルにアクセスします。
データ数が巨大で、キー参照や RID Lookup のパフォーマンスですら気になる場合、
複合インデックス(カバリングインデックス)の作成を考えましょう。
複合インデックスと付加列インデックス
複数の列を組み合わせて作成したインデックスのことを、複合インデックスといいます。
効果的に用いれば、インデックスのみで検索することができます。
以前に使用した D_MemberList、再び。
| No | Name | Age | Income |
|---|---|---|---|
| 1 | A | 23 | 3,200,000 |
| 2 | B | 47 | 6,500,000 |
| 3 | C | 52 | 5,200,000 |
| 4 | D | 38 | 2,500,000 |
| 5 | E | 24 | 23,000,000 |
SELECT Name, Age FROM D_MemberList WHERE Age < 30;
この検索処理をインデックスのみで行いたい場合、
検索条件 Age に加え Name を複合インデックスとして作成します。
作成方法は以下の通り。
CREATE INDEX nc_AgeName
ON D_MemberList(Age, Name)
ただし複合インデックスは、ルート・中間・リーフレベルに列データを格納するため、
インデックスサイズが大きくなり、パフォーマンスが低下するおそれがあります。
この問題を解消するのが付加列インデックスで、列の付加をリーフレベルのみに
収めることができます。
CREATE INDEX nc_Age
ON D_MemberList(Age)
INCLUDE(Name)
インデックス戦略
ここまで単純な例を扱いましたが、実際にはもっと複雑で大量のクエリが流れています。
特定のクエリには有効なインデックスが、他方では悪影響を及ぼすこともあるため、
戦略的にインデックスを構成することが求められます。
理想は、最小のインデックスで最大のアクセス形態を満足させることです。
インデックスの結合順序
インデックス戦略を考える上で、結合順序の選定は重要なポイントです。
適切な列順序を選定することで、処理範囲を効果的に狭めることができます。
インデックス結合順序の決定基準
- 検索条件に多く使用する列
- 常に「=」で使用する列
- 「=」以外で使用する列
例えばこんなクエリがある場合のインデックス結合順序は
SELECT * FROM D_Hoge WHERE A = 'a' AND B = 0 AND C > 0; // query1
SELECT * FROM D_Hoge WHERE A = 'b' AND B IN (0,1,2) AND D = 1; // query2
SELECT * FROM D_Hoge WHERE A = 'e' AND B = 1 AND D <= 5 ; // query3
A列+B列+D列+C列、ということになります。ただし、query1のアクセスが
非常に頻繁に使用されるために重要である場合、A列+B列+C列、A列+B列+D列、
のように2つのインデックスを作成することも検討します。
おわりに
今回インデックスについて色々調べてみてわかったことがあります。それは、
DBパフォーマンスを向上させるために必要な知識は、複雑多岐に渡るということ。
オプティマイザの仕組みから、SQLと実行計画の最適化、インデックスの選定に、
クラスタリング、統計情報の管理など、知らないことが星の数ほどあるなぁと。
まだ俺たちの戦いはこれからだ。
そんなかんじ。