はじめに
MicrosoftがOSSとしてPromptflowという生成AI開発ツールを出しています。
Azure Machine Learningや、つい最近発表されたAzure AI Studioでも利用できるようになっているのですが、業務で使ってみたところ予想以上に良かったので、Promptflowの紹介も兼ねて論文解説をしてくれるWebアプリを作ってみました。
業務環境を使うわけにもいかないので今回はMicrosoft公式から出ているVSCodeのPrompt flow拡張機能を使ってローカル環境で開発を行います。
Prompt flowとは
Prompt flowは生成AIを使った処理をローコード的に開発できるツールです。
グラフィカルに処理と処理のつながりを表示してくれるため、直感的に処理内容が理解可能です。
LLMへの接続はGUIで表示されている欄に必要事項を入力するだけで済むので、コーディングの手間も少なくなります。(Azure上のPrompt flowでは各種Azureサービスとの接続も用意されています。)
作った処理の評価もまたPrompt flowで作成した処理に沿って行うことができ、実験も行いやすいです。(今回は実施しませんが...)
さらに、簡単にAPIサーバーをデプロイすることが可能なので、クイックにLLMアプリケーションを開発することが可能です。
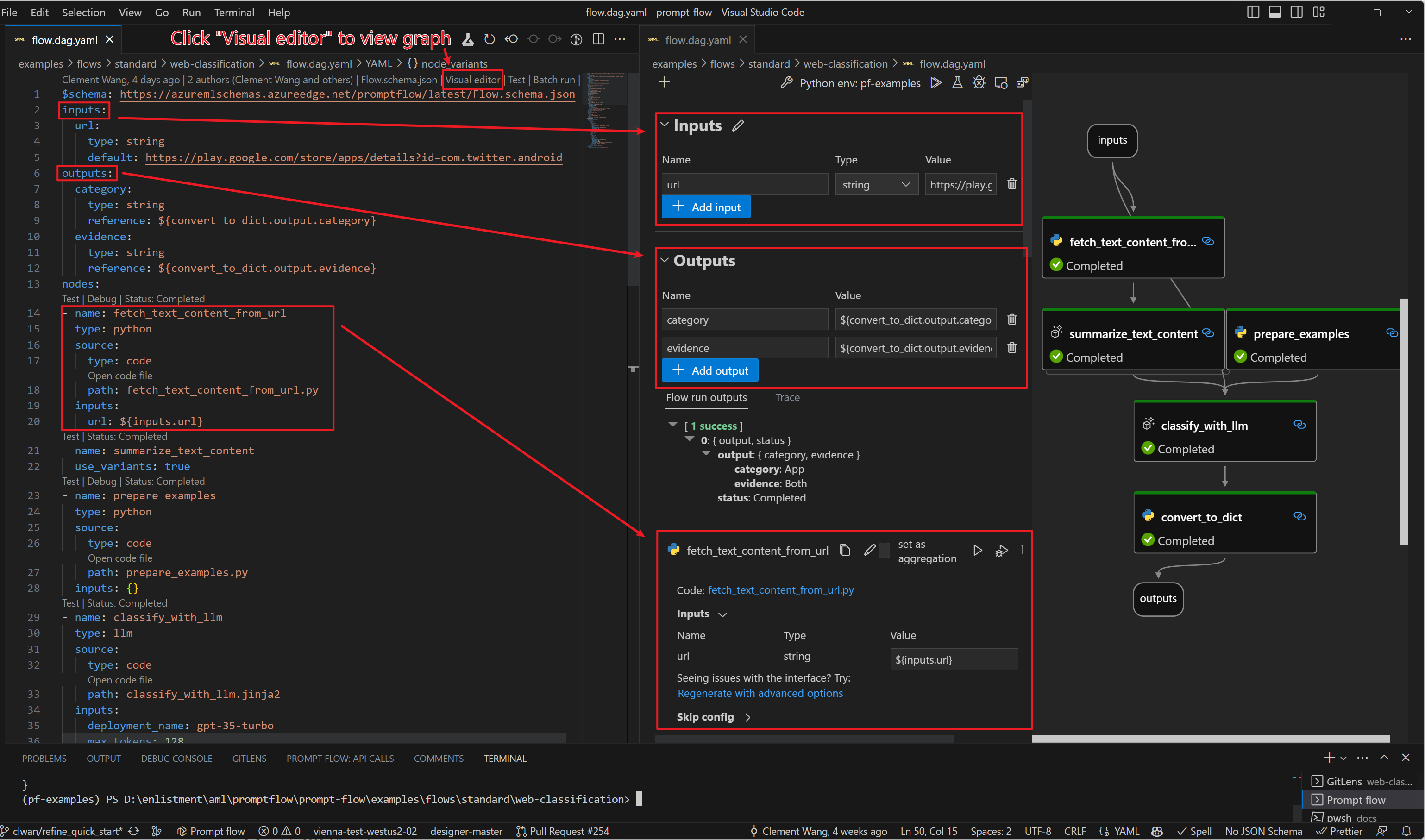
Prompt flowの利用イメージ(公式チュートリアルから引用)
フローの作成
それでは、論文解説をLLMにさせるフローを作成してみましょう。
Prompt flowの拡張機能メニューからCreate new flowを選択すると、どのようなフローを作成するかの選択肢が出てきます。
選択肢はそれぞれ
- Empty flow
- 空のフロー作成
- Standard flow with a Template
- 会話履歴が必要ないフローのテンプレート
- Chat flow with a Template
- 会話履歴が必要なフローのテンプレート
- Evaluation with a Template
- フロー評価用のフロー
となっています。
今回は対話的に論文を解説してほしいので、Chat flow with a Templateを選択し、適当な保存場所の選択とフローの命名をします。(今回は「chat-with-pdf」としました。)
- フロー評価用のフロー
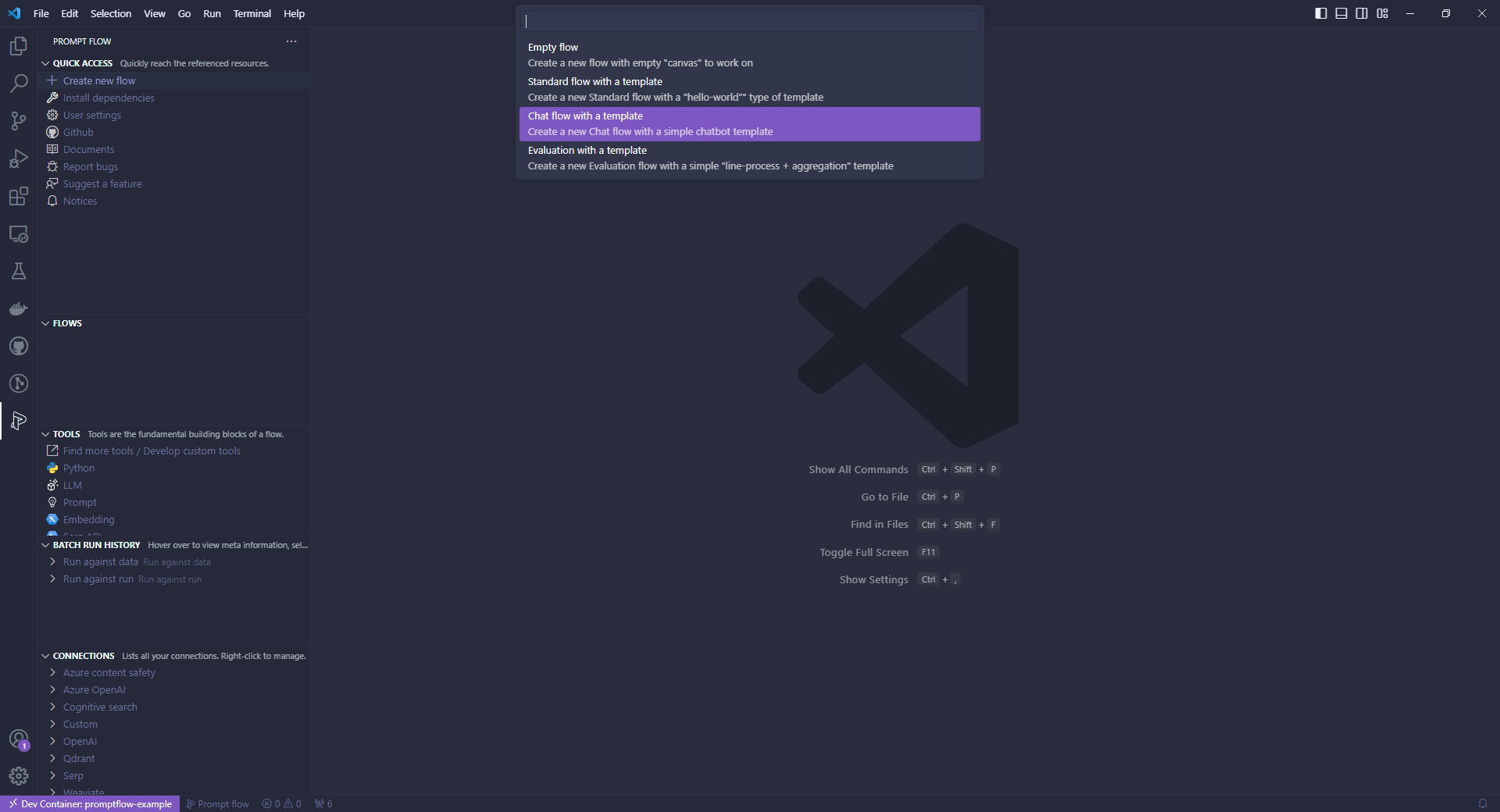
Create new Flowを選択した場面
作成が完了すると、フローの名前のディレクトリ内にflow.dag.yamlというファイルができています。
これがフローの構成を管理するyamlファイルとなります。
ファイルを開くと上の方にVisual editorという項目があるので、それをクリックすると、グラフィカルにフローを編集できるUIが開きます。
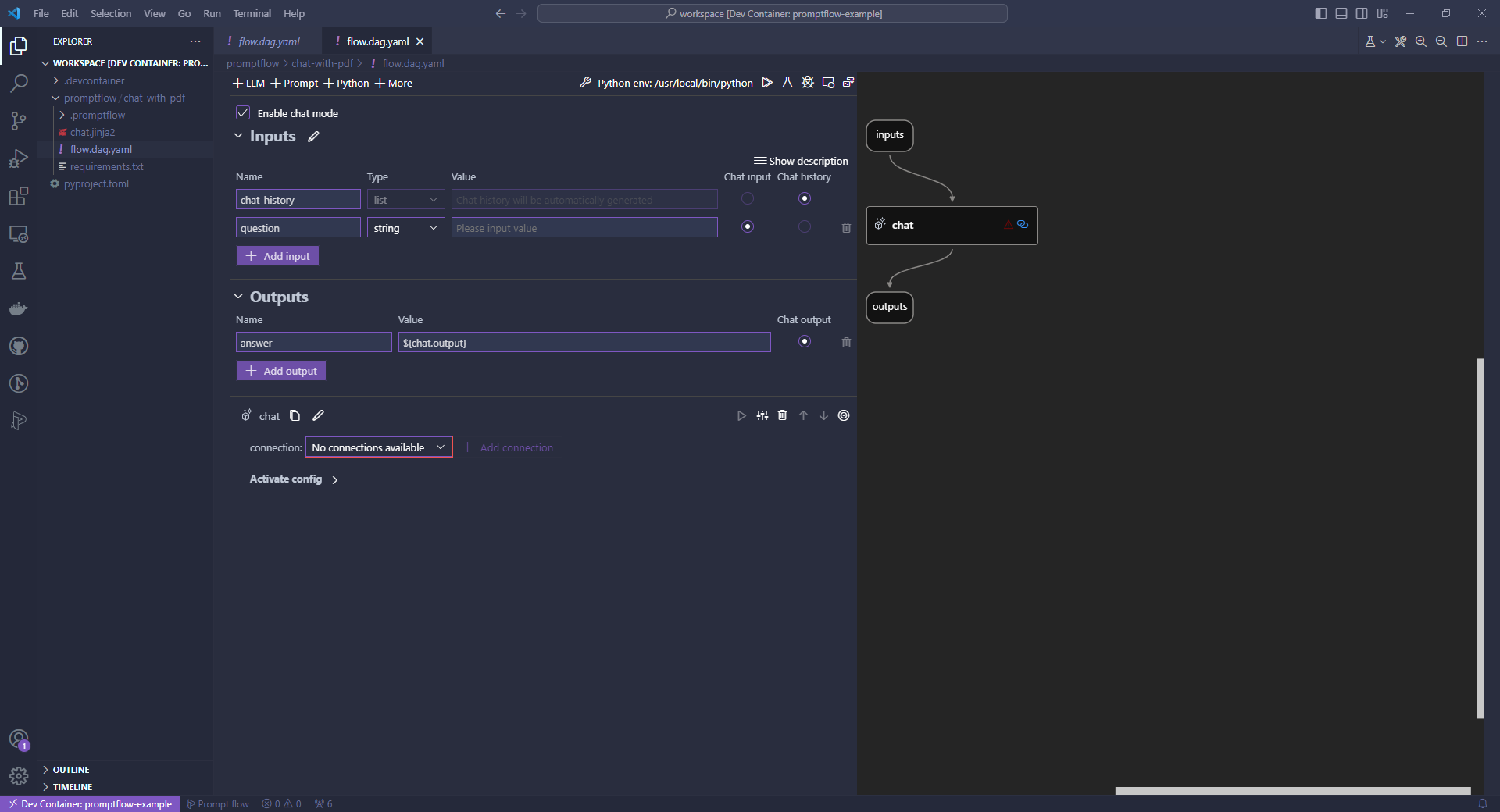
作成したフローをGUIで表示した場面
Prompt flowはノードベースで記述でき、下記のような種類のノードがあります。
- Inputs
- フローへの入力を指定
- Outputs
- フローの出力を指定
- LLM
- OpenAI互換のAPIを呼び出す
- Prompt
- LLMへ渡すプロンプトを定義
- Python
- Pythonによる処理
- その他ノード
- OSSモデルやSerp API、AzureであればAzure AI Searchなど上記以外のノードも利用できます。
- 自作することも可能なようです。(参考)
今回はこれらのノードを使って下記のようなシンプルなRAGによる論文解説フローを実装してみましょう。
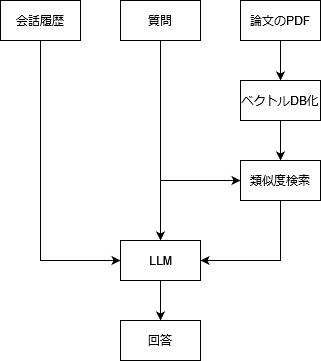
作りたいフローのイメージ
入力
イメージ図の通り入力には会話履歴・質問・論文のPDFを設定します。
ラジオボタンで会話履歴やチャットの入力を選択できます。
PDFに関してはファイルそのものではなくURLを渡す形にしました。
Value欄を入力しておくとテスト作動時などに入力した値を使ってくれます。
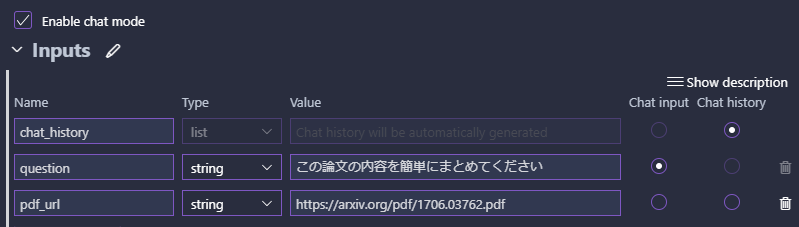
入力の設定
ベクトルDB化
論文のPDFをRAGで利用するベクトルDB化します。
今回はこちらのページを参考にLangChainのFaissのベクトルストアを利用してみます。
Pythonノードを作成すると自動的にPythonファイルが作成されるので、そちらに下記のようなコードを記入していきます。
import hashlib
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
from promptflow import tool
@tool
def get_or_create_vector_db(url: str) -> str:
url_hash = hashlib.sha256(url.encode()).hexdigest()
db_path = f"db/{url_hash}"
embeddings = OpenAIEmbeddings() # 環境変数の設定が必要
try:
FAISS.load_local(db_path, embeddings)
except:
loader = PyPDFLoader(url)
documents = loader.load_and_split()
db = FAISS.from_documents(documents, embeddings)
db.save_local(db_path)
return db_path
tryとか適当なのは許してください。
Prompt flowでは@toolというデコレータを付けた関数を認識します。
今回作成した関数ではPDFのURLを受け取ってハッシュ化してDBの格納先パスを作成します。
そのパスからDBが読み込めたら何もせず、読み込めなかった場合は新たにDBを作成するといった処理を行っています。
最後に、後続の処理でこのDBを読み込めるようにDBのパスを出力します。
GUIではこの関数の引数に固定値や他ノードの出力を設定することができます。
今回はURLは入力で指定しているため、下記の画像のように入力ノードから値を持ってくるようにします。
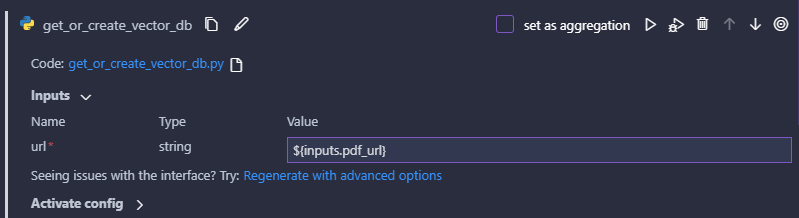
ベクトルDB化の設定
類似度検索
作成したベクトルDBからユーザの質問をクエリとして類似した文を抽出します。
こちらも同じくPythonノードで作成します。
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
from promptflow import tool
@tool
def similarity_search(db_path: str, query: str, k: int) -> str:
embeddings = OpenAIEmbeddings() # 環境変数の設定が必要
db = FAISS.load_local(db_path, embeddings)
documents = db.similarity_search(query, k)
results = [x.page_content for x in documents]
return results
この処理ではベクトルDBを読み込んだ後、クエリの類似度上位k個の文をDBから抽出してリストとして返します。
GUIでは先ほどのベクトルDB化ノードから出力されるDBのパスと入力ノードの質問文を指定し、kについては固定値で3にします。
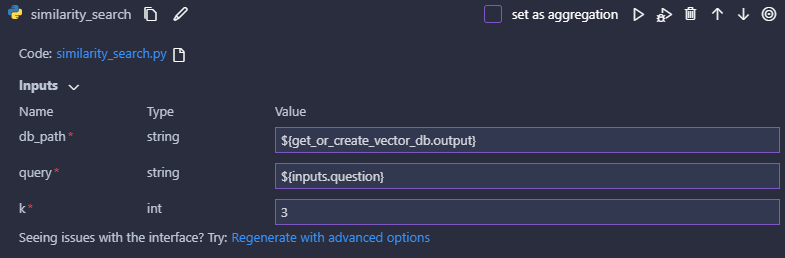
類似度検索の設定
システムプロンプト
LLMに入力するシステムプロンプトをPromptノードで作成します。
PromptノードはJinja2の形式でテンプレートを記載できます。
You are a helpful assistant.
Please use the following reference information to answer the questions.
-----
{{reference}}
今回はシンプルに類似度検索の出力をそのまま利用します。
類似度検索の出力は文字列のリストでしたが、Prompt flow側で勝手に文字列に変換してくれるようです。
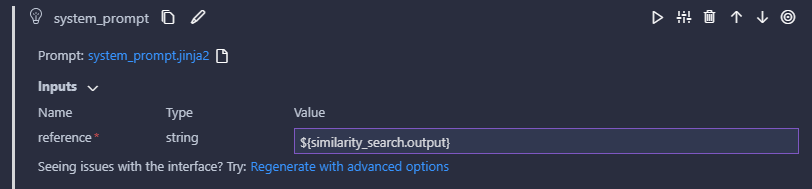
システムプロンプトの設定
LLM
さて、いよいよLLM部分の作成です。
といっても、APIへの接続設定をすませたらどのAPIにつなぐか選択して各種パラメータを入力するだけです。
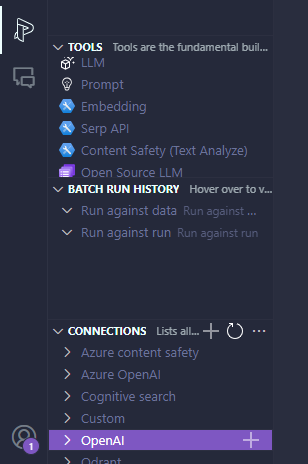
Prompt flow拡張機能の接続設定メニュー
LLMノードでもプロンプトのテンプレートを設定できるので、下記のように記載します。
system:
{{system_prompt}}
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
user:
{{question}}
今回はデフォルトで設定されていたプロンプトのsystem部分だけ先ほどのシステムプロンプトに置き換えられるようにしました。
これまでと同じようにGUIで各ノードの出力をプロンプトの置き換え元として指定します。
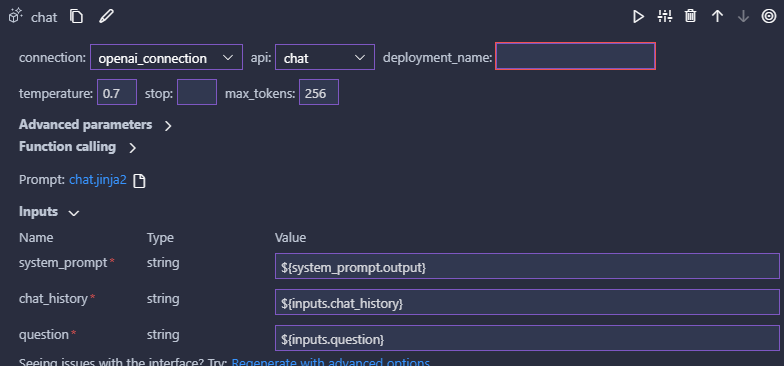
LLMの設定
出力
最後に出力の設定です。
LLMからの回答があればいいので、LLMノードの出力を指定して終わりです。

完成 & テスト
最終的に、次の画像のようなフローが作成できました。
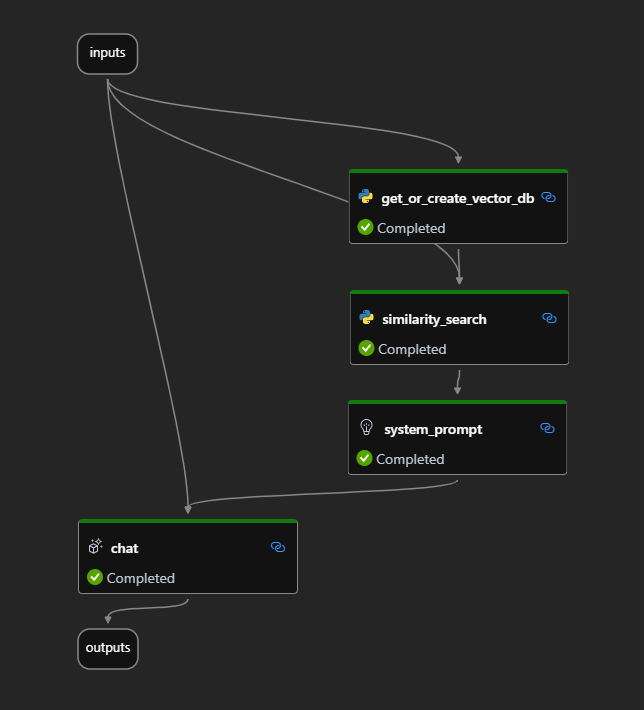
フローのグラフ
テストとして、Attention Is All You Needを簡単に説明してもらいましょう。
入力
質問: この論文の内容を簡単にまとめてください
論文URL: https://arxiv.org/pdf/1706.03762.pdf
LLMからの回答
この論文では、複雑な再帰型や畳み込み型のニューラルネットワークを用いた従来のシーケンス変換モデルに代わる新しいネットワークアーキテクチャであるTransformerが提案されています。
Transformerは、注意メカニズムのみを使用し、再帰や畳み込みを完全に排除しています。
2つの機械翻訳タスクでの実験結果から、Transformerモデルは品質が優れており、並列化が可能で訓練時間も大幅に短縮できることが示されています。
また、他のタスクにも適用可能であり、英語の構文解析においても高い汎化性能を示すことが示されています。
なんだか良さそうです。
Webアプリとしてデプロイ
なんとPrompt flowではワンボタンでフローをデプロイできてしまいます。
GUIの上の方にあるbuildボタンを押すと選択肢が出るので、Build as local appを選択し、ローカルアプリとしてデプロイしてみます。
(Dockerイメージとしてデプロイも可能です。)
作成されたjsonファイルに表示されるStart local appをクリックすると画像のようなWebアプリが起動します。
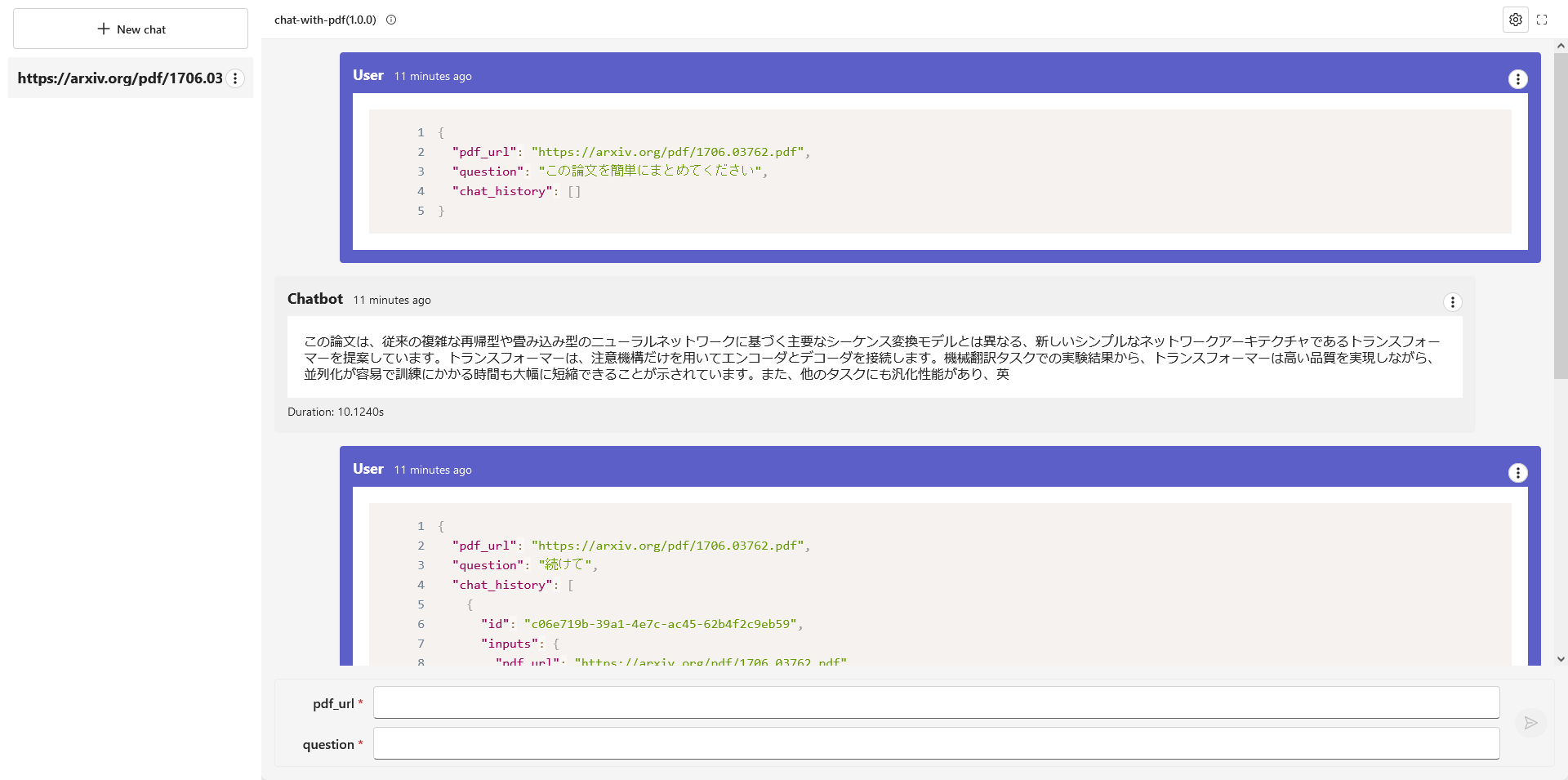
毎回PDFのURLを入力する必要があって面倒ではありますが、見事にWebアプリを作成することができました。
作成したアプリはAPIサーバーとしても利用可能なので、好きなUIフレームワークと組み合わせてより本格的なWebアプリを作成することが可能です。
APIサーバーとしての使い方は公式ドキュメントをご覧ください。
(本当はStreamlitとかでUI作る予定でしたが力尽きました。ごめんなさい。)
まとめ
今回はMicrosoftが出しているPrompt flowについてご紹介しました。
まだまだ発展途上ではありますが、LangChainなどと組み合わせて手早くLLMアプリケーションを開発することができ、非常に将来性がありそうです。
何かしらのデモの作成くらいであれば現状でも十分実用に耐えると思うので、皆さんも使ってみてはいかがでしょうか?