1.中古マンション価格予測 2024秋の部
はじめに
中古マンションの価格予測において、データの可視化と分析手法の選択は重要な要素となります。本プロジェクトでは、AIツールを活用しながら以下のような分析フローで予測モデルを構築した。
データ分析フロー
使用ライブラリ
・データ処理・分析
import pandas as pd` # データフレーム操作
import numpy as np` # 数値計算処理
・可視化
`import matplotlib.pyplot as plt` # グラフ描画
`import seaborn as sns` # 統計的データ可視化
`import japanize_matplotlib` # 日本語フォント対応
・機械学習
`from sklearn.metrics import mean_absolute_error` # 評価指標
`from sklearn.model_selection import KFold` # 交差検証
・活用モデルクラス
・前処理・エンコーディング
`from sklearn.preprocessing import (`
`LabelEncoder,` # カテゴリカル変数の数値変換
`OrdinalEncoder,` # 順序性のあるカテゴリ変数の変換
`FunctionTransformer`# カスタム変換関数の適用
`)`
・モデル評価・検証
`from sklearn.metrics import mean_absolute_error` # 平均絶対誤差の計算
`from sklearn.model_selection import KFold` # 交差検証
`from sklearn.pipeline import make_pipeline` # 処理のパイプライン化
・予測モデル
`import lightgbm as lgb` # 勾配ブースティング
データ概要
本プロジェクトでは、NISHIKAの中古マンション価格予測コンペティションのデータを使用。
データの特徴
- 物件情報(面積、築年数、間取り等)
- 立地情報(最寄駅、地域等)
- 建物仕様(構造、階数等)
分析アプローチ
独自の視点でデータを解析し、特に間取りデータの数値化に重点を置いた予測モデルを構築。
前準備
データ概要確認
[ライブラリのimport]

[データの取り込み]

[取り込みデータの変換]

[データサイズ]

[データ上部、下部]

[カラムの種類]

[カラムの型]
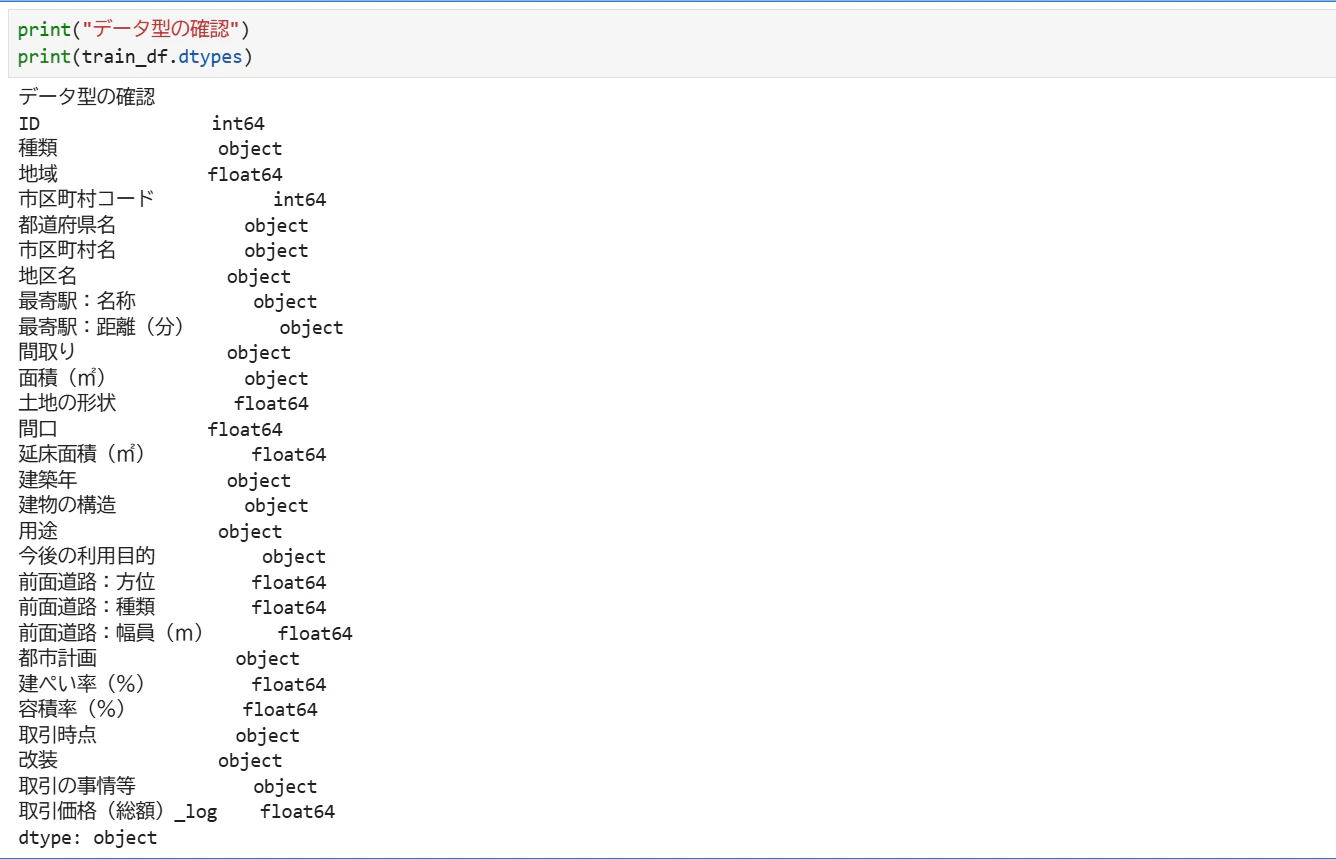
[欠損値]

[基本統計量]
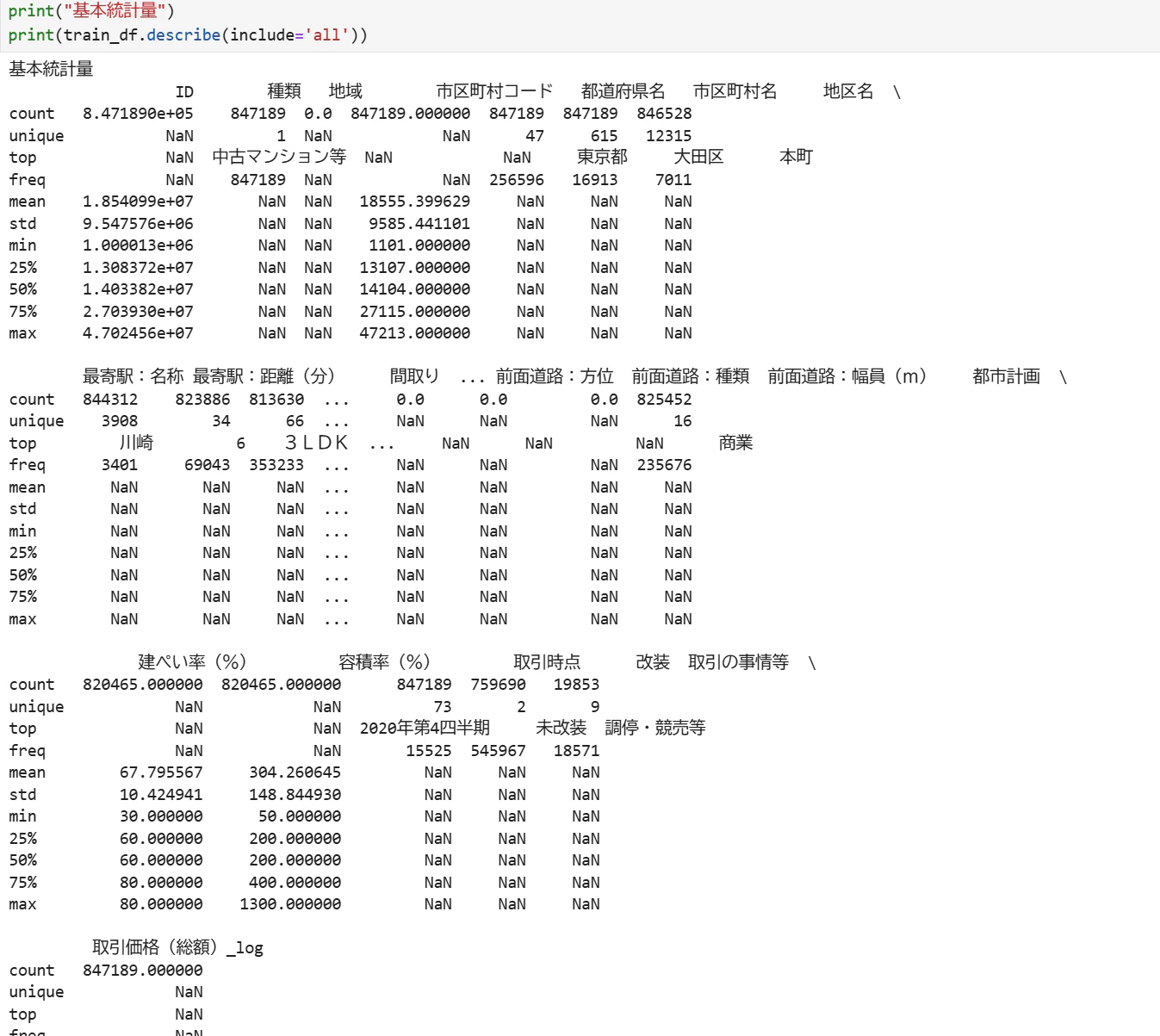
[重複行の有無]

[メモリ使用量]

[特定のカラムのみ]

[ランダムな指定行]

[インデックス指定行]

データ加工
[最初の取り込み]
paths = glob(BASE_PATH + 'input/train/*')
train_dfs = []
for path in paths:
train_df = pd.read_csv(path, low_memory=False)
train_dfs.append(train_df)
train_df = pd.concat(train_dfs)
train_df.reset_index(drop=True, inplace=True)
test_df = pd.read_csv(BASE_PATH + 'input/test.csv')
[Pickle化による高速化]
#pickleファイルとして保存
train_df.to_pickle('processed_train_df.pkl')
test_df.to_pickle('processed_test_df.pkl')
[表記ゆらぎ修正のためのtrain, test結合]
# データ結合
joined_df = pd.concat([train_df, test_df], axis=0)
joined_df.reset_index(drop=True, inplace=True)
[安全のための複製]
# 新しい変数に複製
merged_df = joined_df.copy(deep=True)
[処理負荷軽減のための列選択]
# 選択する特徴量えn選択したvariable'selected_columns作成
selected_columns = [
'地方','都道府県名', '市区町村名', '地区名',
'最寄駅:名称', '最寄駅:距離(分)',
'建築年', '改装', '間取り','layout_count',
'面積(㎡)', '用途', '都市計画',
'建物の構造', 'DB種別', '価格'
]
新しいデータフレームの作成
merged_df_selected = merged_df[selected_columns]
[可読性を上げるために価格関連カラムを追加]
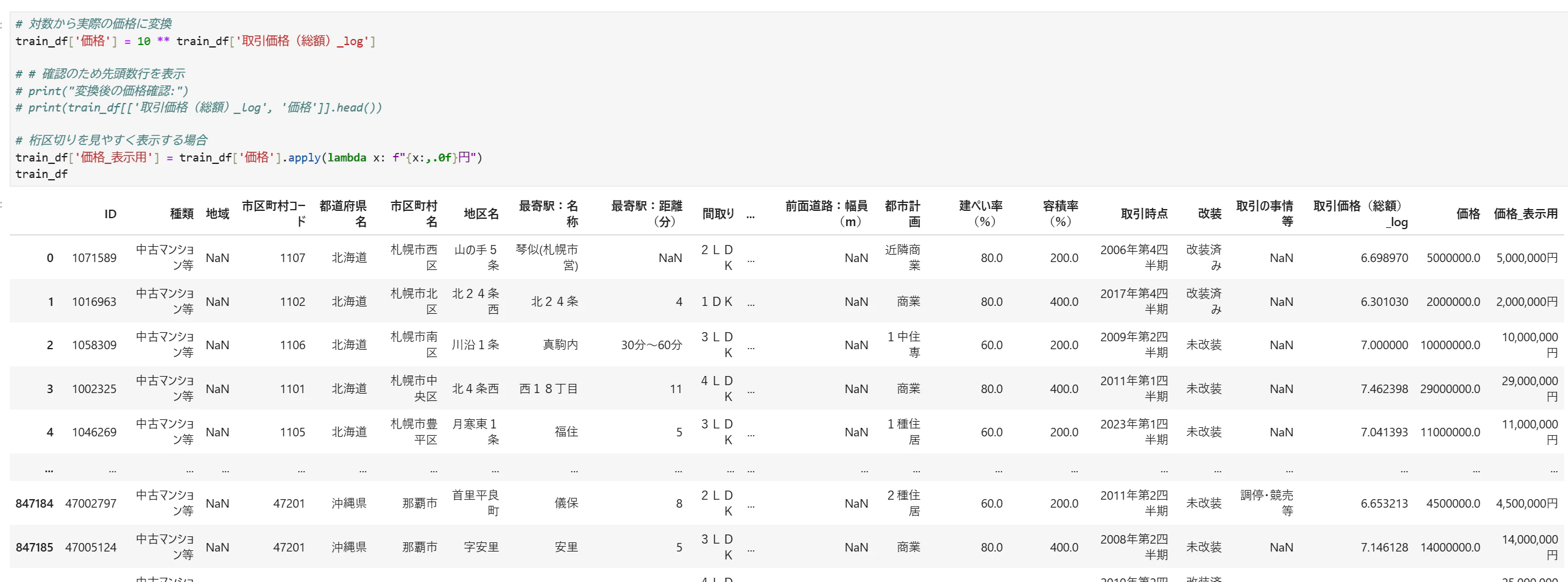
[全体の価格帯把握]
最高額に対する平均価格の差が驚いたが、最低価格に450円というのも意外性を感じた。

欠損値処理
[無効カラム削除]
全ての要素が欠損しているカラムを除外

[建物特定]
<アプローチの概要>
同一建物の物件データを活用し、高精度な欠損値補完を目指した。
<実施内容>
- 位置情報、建物関連カラムの完全一致による建物特定
- 地区名、最寄駅、建物特徴による物件グループ化
- グループ内データによる欠損値補完を検討
<結果と考察>
- 314,166グループが生成(平均2.94件/グループ)
- グループ化が過度に細分化
- 欠損値行と完全一致する建物データなし


<推測される要因>
- 同一建物からの掲載物件数が限定的
- 建物特定条件が過度に厳密
表記揺れ修正
[最寄駅距離]
カラム内の不要な文字列を削除し、時間幅のある値は中央値として適用。続けてfloatに型変換処理を実施。
画面はすでに修正が終わった後なのでカウントが⁰になっている。


[建築年]
建築年には、'年'や'戦前'などの文字が含まれstr型だったため全てint型に変換した。

変換後

[面積(㎡)]
カラム内の不要な単位やカンマを削除し、続けてfloatに型変換処理を実施。
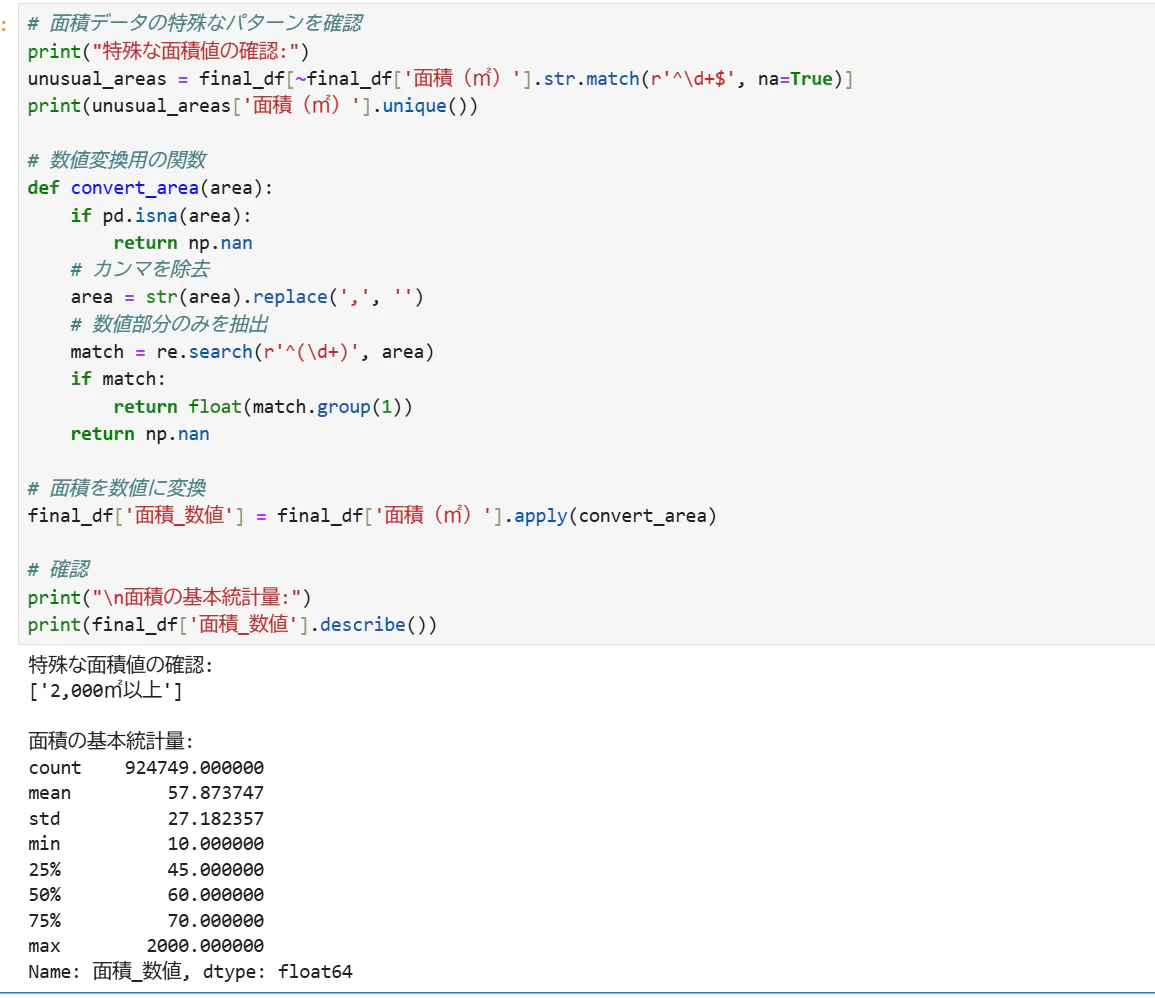

特徴量エンジニアリング
['住所'カラム追加]
'都道府県名','市区町村名','地区名'を結合したカラム。
住所は目的量に大きく影響すると考えており、全国には同じ市区町村名や地区名が存在するので、それらを予め結合しておくことで他の市区町村との間違えることやカラムを一つにすることで計算コストを抑えられることを目的とした。

['住所_駅'カラム追加]
住所と最寄駅名称を結合することで、物件エリアをより狭域に特定することを目的とした。
これも価格に大きく影響することが考えられ、住所作成目的同様に計算コスを抑えることを目的としている。

['layout_count'カラム追加]
部屋数を表す値。'間取り'を基に計算。
目的量に大きく影響する間取りを、よりわかりやすい形で表現できると考えた。

['築年数'カラム追加]
現在(2024年) - 建築年にて算出。
目的量に大きく影響すると考え、新たにカラムを追加。

・特徴量選定プロセス
マンション価格に影響する項目と実際にデータにて相関係数などにより影響が確認されたものを最終的に選定カラムとした。
(特徴量選定)
初期特徴量候補
目的変数との関連性が予測される説明変数を選定:
- 地理的特徴(都道府県名、市区町村名、地区名)
- 交通利便性(最寄駅、駅距離)
- 物件特性(建築年、築年数、間取り、面積)
- 建物属性(構造、改装、都市計画)
- 価格情報(価格、対数変換価格)
最終特徴量
計算効率と予測精度のバランスを考慮し、以下の基準で選定:
- 目的変数との相関分析
- 多重共線性の考慮
- 処理コストの最適化
選定された特徴量:
- 地理情報(都道府県名、市区町村名、地区名)
- アクセス(最寄駅、駅距離)
- 物件基本情報(建築年、築年数、間取り、layout_count、面積)
- 価格関連(価格、対数変換価格)

特徴量概要
選定した特徴量のデータ概要をチェック
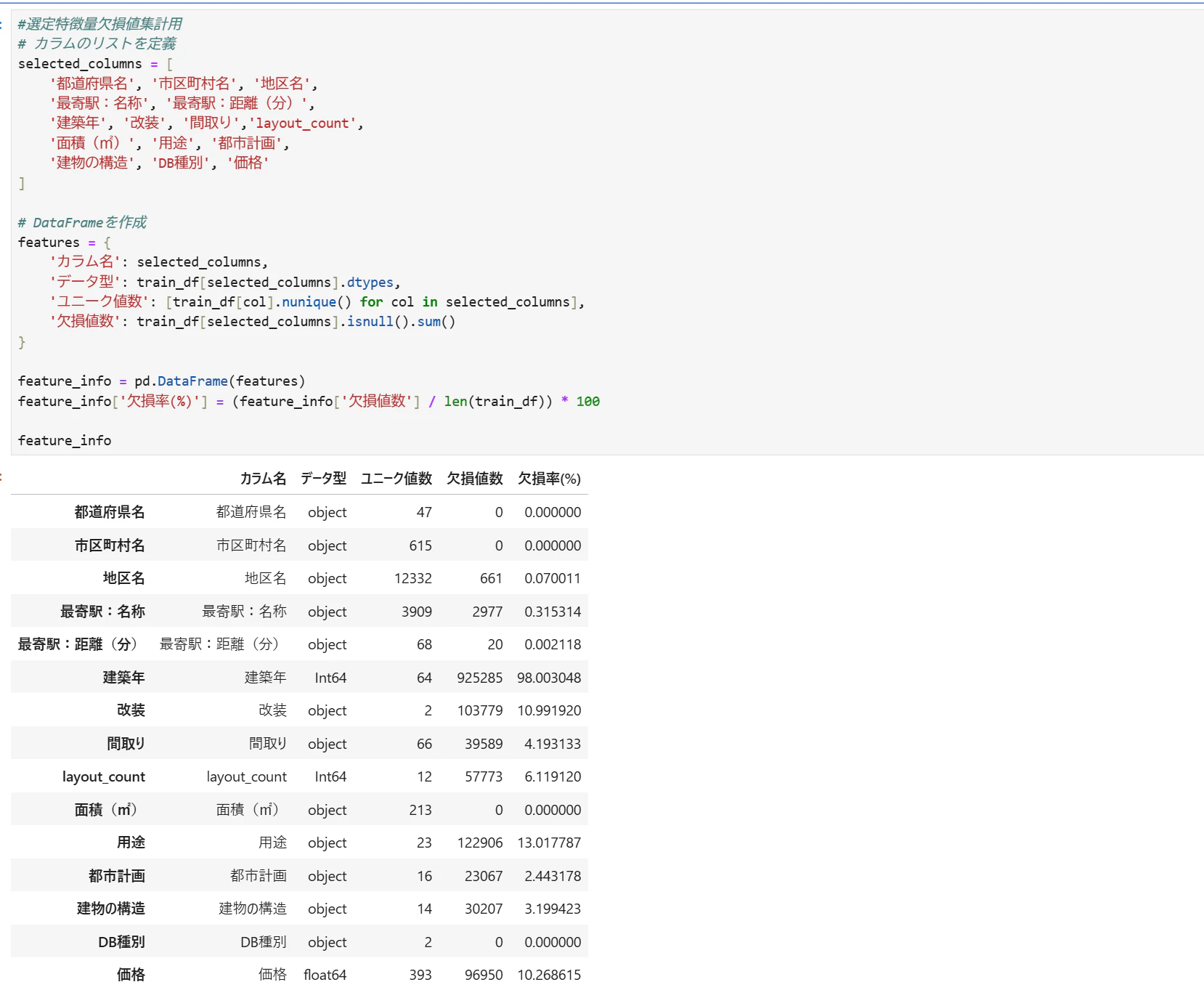
[データ型変換]
選定した特徴量の型を確認

[各カラムのユニーク値(カテゴリ数)確認]
カテゴリデータのエンコード
One Hot Encoding
[都道府県名]

[建物の構造]

[都市計画]
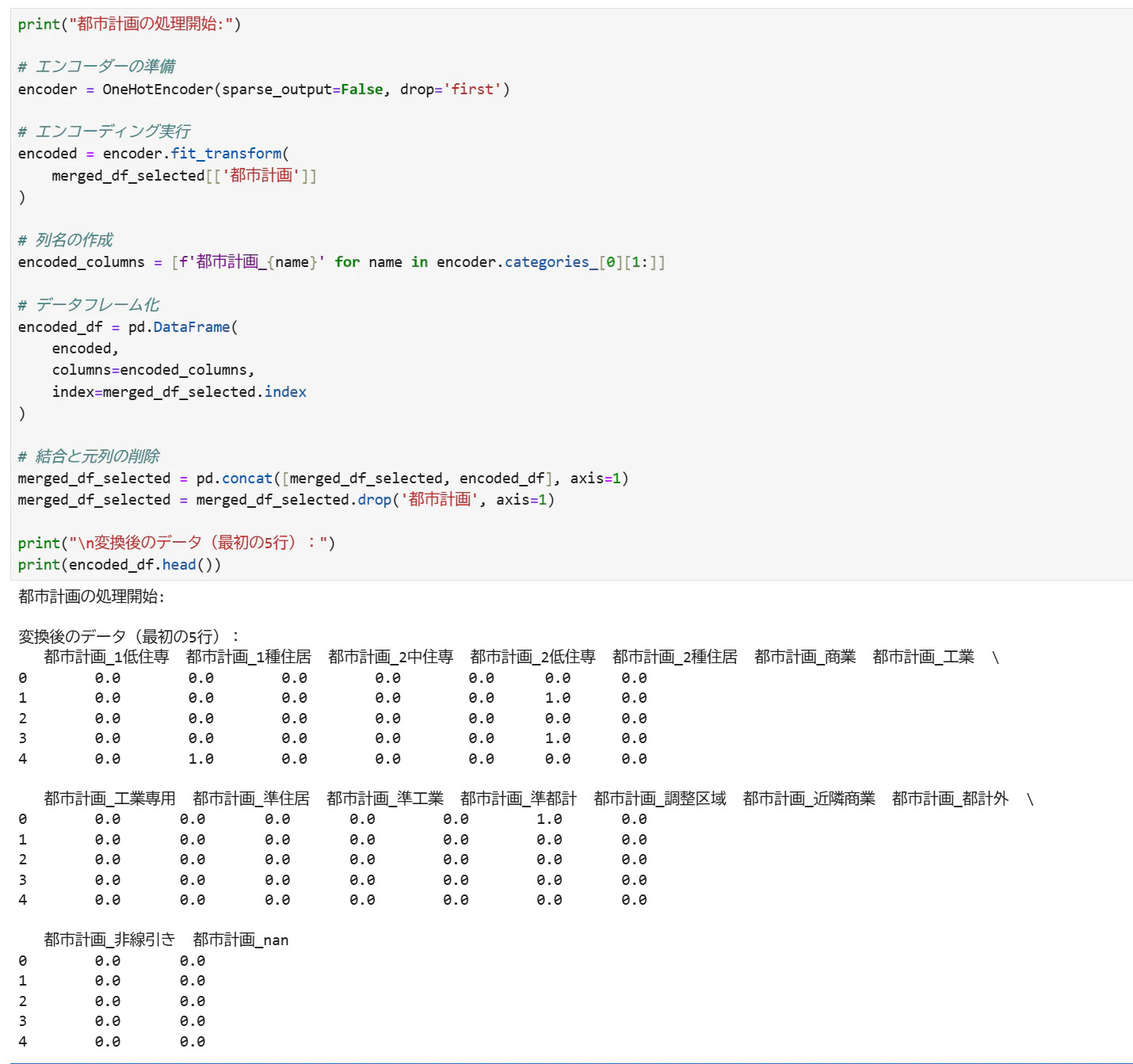
[用途]

スケーリング
[データの概要]
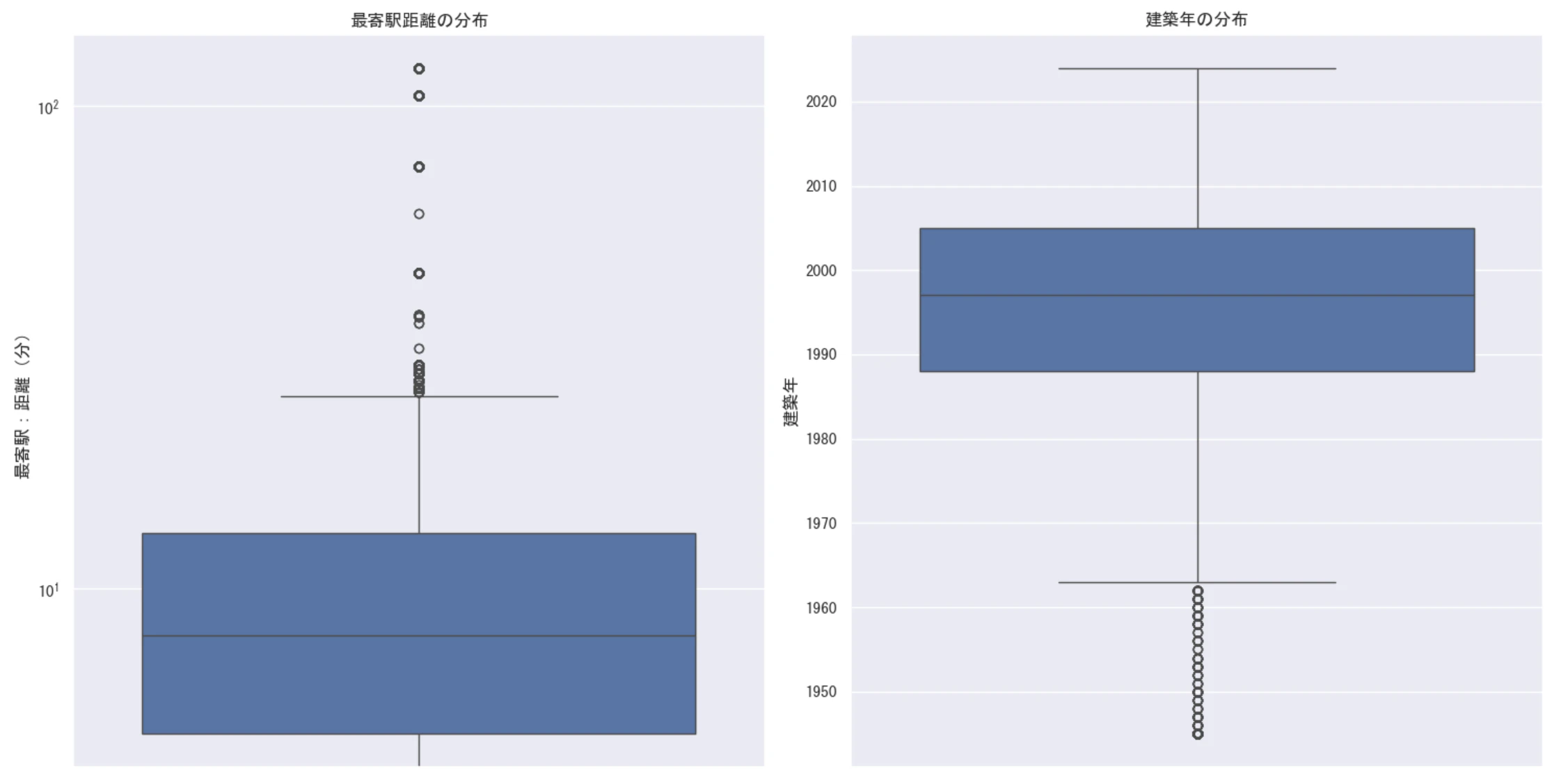
最寄駅距離の分布分析:
第1四分位数(Q1): 5.00分
第3四分位数(Q3): 13.00分
IQR: 8.00分
外れ値の基準: 25.00分以上
[考察]
IQRを用いた分析により、一般的な通勤圏内の物件と郊外型の物件の境界を統計的に定義することができた。これは不動産価格予測において重要な指標となります。
建築年の分布分析:
第1四分位数(Q1): 1988年
第3四分位数(Q3): 2005年
IQR: 17年
外れ値の基準: 1962年以前
[考察]
IQRを用いた分析により、1988年以降2005年以前の建築物件に多くの物件が見られることがわかった。これにより一般的な中古物件と築年数の経過した物件の境界を統計的に定義することができました。
これは不動産価格予測において重要な指標となります。
カラムコピー時にエラー発生
表記ゆらぎ修正及び欠損値補完のため、一時的に結合していたtrain_df, test_dfだったが、その段階を終え、元のtrain, testの2つのデータに分離した。
その後、表記ゆらぎ修正などをしたデータにはないカラムをtrain_df, test_dfからコピーすることで、(値が全て欠損しているカラムを除き)全てのカラムがtrain, testそれぞれのデータに整う予定だった。
しかし、train_dfは問題なくコピーできたが、test_dfのカラムコピーに不具合が発生し、コピーしたいずれのカラムも100%欠損値となる事象が発生した。
[testデータのみ欠損値が100%となる事象]
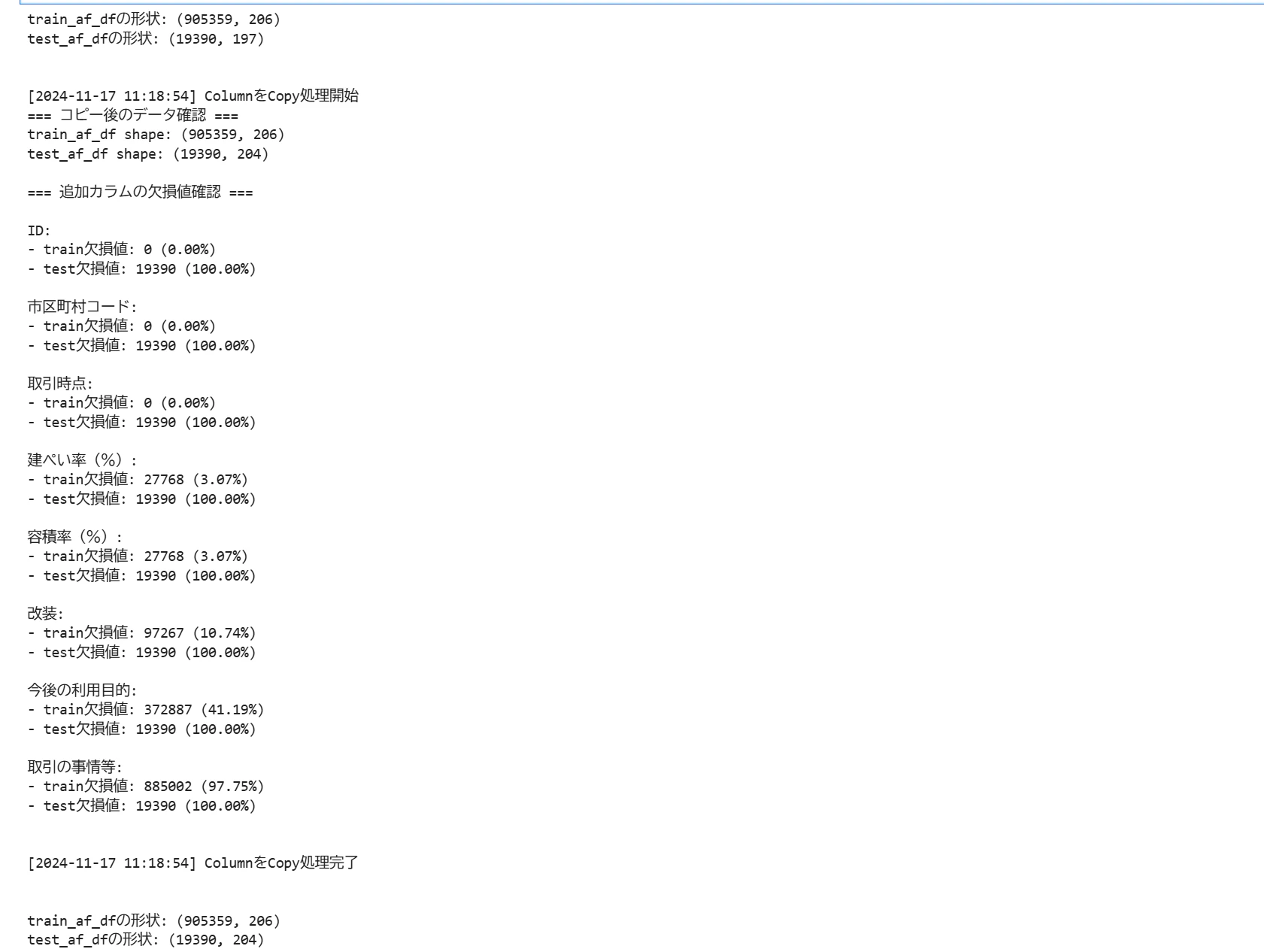
過去のコードに遡り、ステップごとにデータ形状や型の比較などを行ったが、いずれもデータサイズは一致しており、問題切り分け調査に時間を要した。
[コピーが成功するtrainデータと失敗するtestデータの比較などを実施]
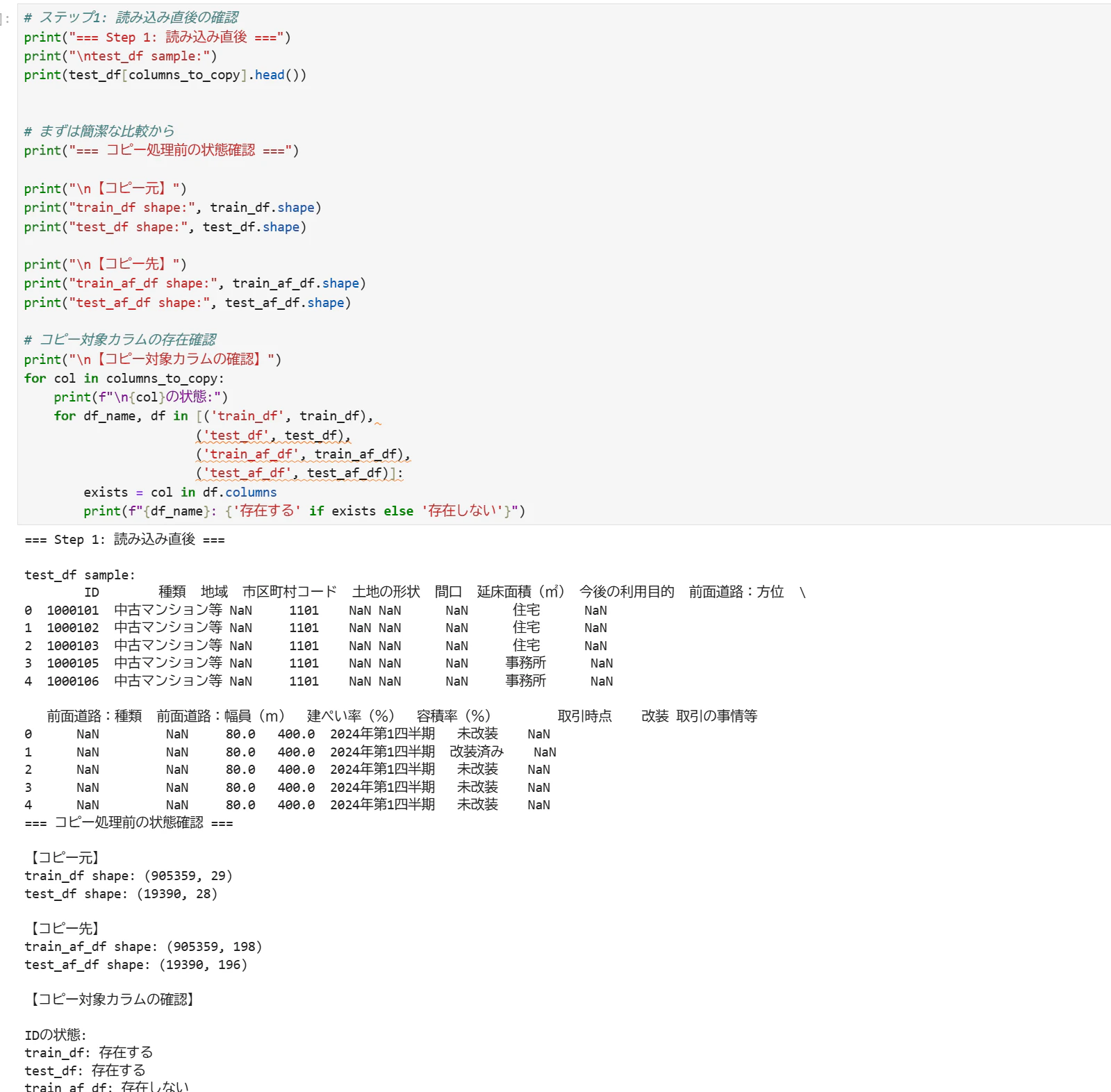
最終的にtestデータのみindexがコピー元とコピー先で一致していなかったことが判明した。
これは、一時的にデータを縦に結合していた際に割り当てられたindexがそのまま残っていたことが原因だと判明した。
[testデータ100%欠損不具合解消後]

データ概要把握
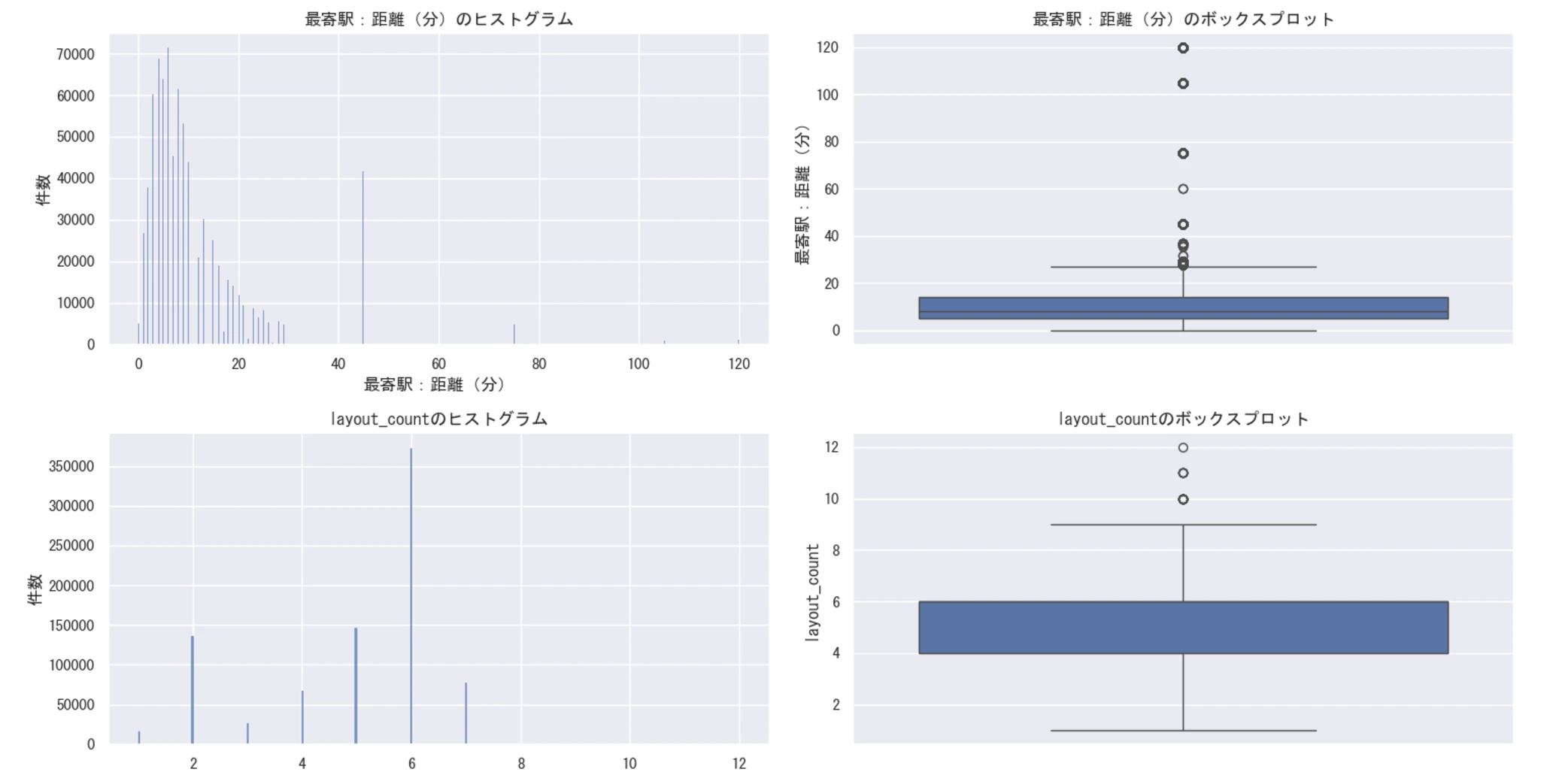
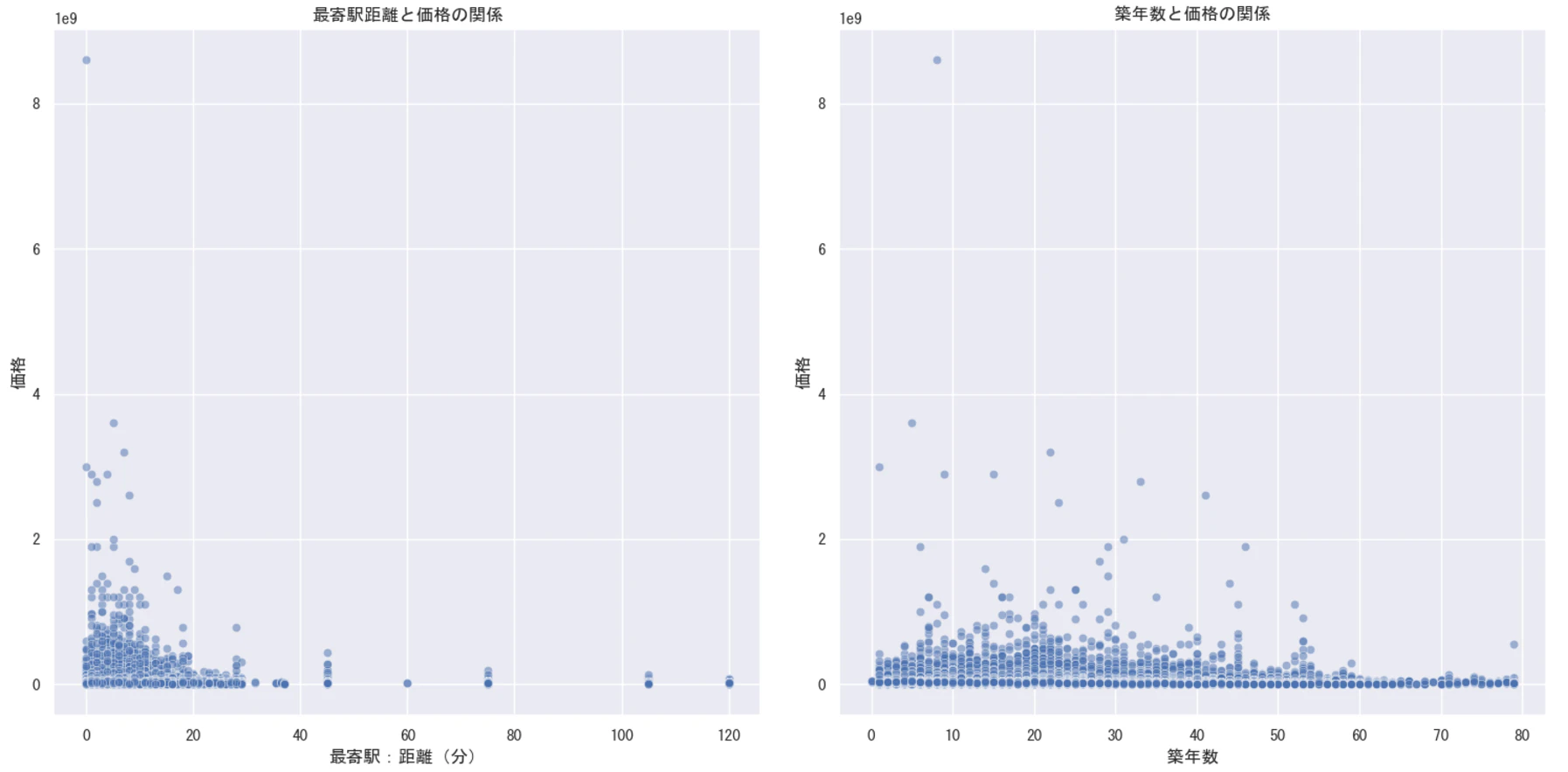
[最寄駅:距離(分)]
ヒストグラムより駅から10分以内の物件が多いことが分かる。
但し、箱ひげ図から外れ値に該当する物件も数多く含まれていることも示唆している。


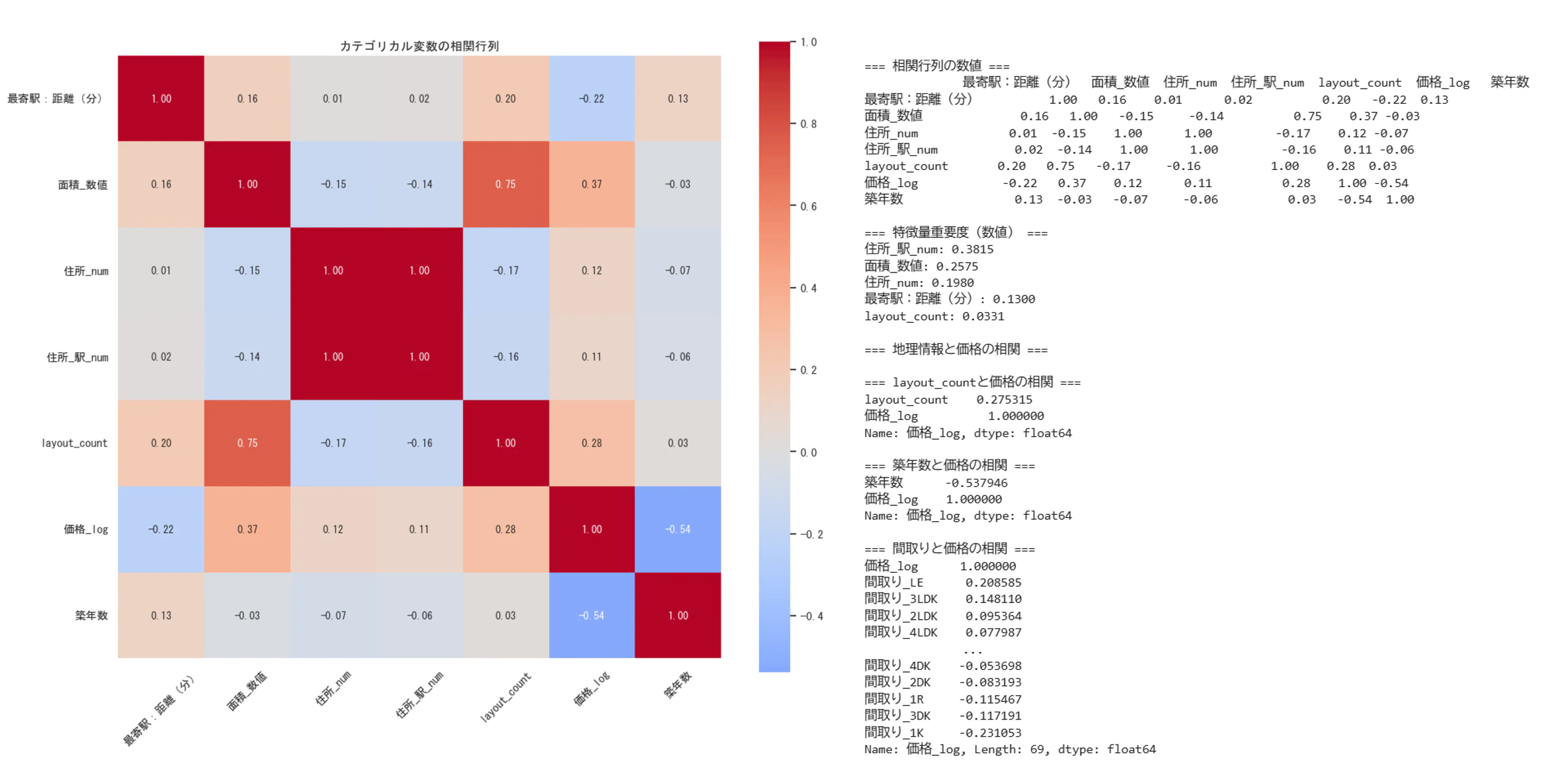
相関ヒートマップや相関係数などを参考にしながら特徴量選定を実施。
[model構築後予測計算]

[評価指標の計算]


予測値出力までの処理が整ったので、現在のモデル精度を確認するために実際にコンペに投稿を実施。
[Nishikaに投稿]
コンペティション結果と対応策の検討
分析の傾向と知見
LightGBMを活用した分析では、Feature Importanceの結果から、中古マンション価格に対する主要な影響因子として以下の項目が挙げられました。
建築年
市区町村名
面積
築年数
これらの項目が価格に与える影響が特に大きいことが判明し、モデルの精度向上に向けて重要な知見を得ることができました。
[傾向]
Feature Importanceから、中古マンション価格に対して強い影響力項目は建築年、市区町村名、面積、そして築年数だった。
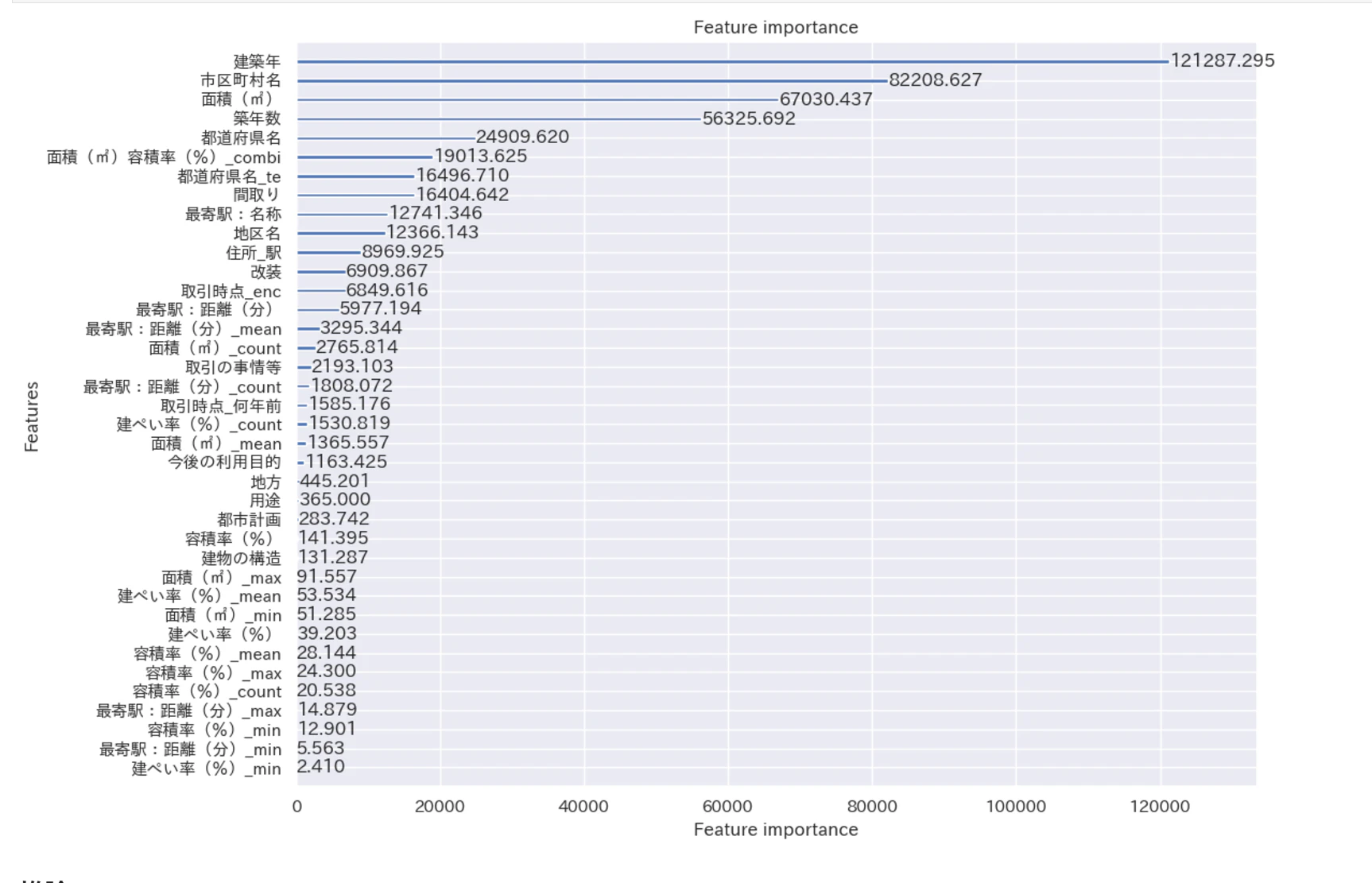
LightGBMに切り替え後、初回の投稿でスコアは0.1068まで伸ばすことが出来ました。

順位も最下位から23位に上がりました。

まとめ
[AIデータサイエンスにおける分析プロセスと業務での応用経験]
AIデータサイエンスにおける分析工程
AIデータサイエンスの分析プロセスは多岐にわたり、以下のような工程が含まれます。
データ前処理:
Data Cleansing
欠損値補完
表記ゆらぎ修正
カテゴリ変数のエンコーディング
変数変換(例: 対数変換)
データ制御:
データの分割・結合、スケーリング、データ構造の把握
特徴量エンジニアリング:
新しい特徴量の作成や選定
モデル構築・評価:
モデル構築、性能評価、ハイパーパラメーター調整
結果の可視化と報告:
データの可視化、分析結果の解釈、レポート作成
これらの工程では、それぞれのステップが分析結果の精度に大きく影響します。例えば、データの概要を見誤ったり、ノイズを適切に除去できなかった場合、分析の正確性が損なわれる可能性があります。また、モデルの選定やハイパーパラメーター調整も重要で、選択により出力結果が大きく異なるのが特徴です。
業務経験との比較とAIデータサイエンスでの学び
これまでの業務においては、チームのパフォーマンス向上や問題定義を目的に、日常的にデータ分析を行ってきました。この中で、迅速に数値を算出し、多角的な視点で業務改善に必要な要素を抽出する経験を積んでおり、特にスピード感が求められる傾向分析に注力してきました。
一方で、AIデータサイエンスにおける分析では、じっくりとデータを精査し、多角的な視点で高精度の結果を得ることが求められます。同じデータ分析でも、これまでの業務で経験してきた短期的・即応的な分析とは異なり、長期的で慎重なアプローチが必要である点が大きな違いだと感じています。
私が目指しているのは、今までの業務で培った「迅速なデータ処理」や「多角的な視点での洞察」にこのAI Data Scienceの技術を導入することで、多くの時間を費やしてきたチームパフォーマンス管理や潜在的問題提議などに関しても、より短時間で高い精度の分析が可能になると考えています。
引き続き、AI Data Scienceスキル習得を続け、業務効率化などのより細かい分野においてもAI Data Scienceのスキルが全面に活用できるようにしていきたいと考えています。
参考にした資料、文献
Hugging Face
Hakky Handbook