はじめに
自己紹介
皆さん、こんにちは、斉藤賢哉と申します。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Advanced編』の一部の範囲をカバーしたものです。『Java Advanced編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをQiita内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの基本的なスキルを習得済みで、さらなるレベルアップを目指している方
- 将来的なキャリアとして、希少性の高い上級エンジニアやアーキテクトを志向している方
- フリーランスエンジニアとして付加価値の更なる向上を図っている方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
4.2 ストリームAPI
チャプターの概要
このチャプターでは、データに対してパイプライン処理を行うためのストリームAPIについて学びます。
ストリームAPIには、ラムダ式がふんだんに取り入れられています。
4.2.1 ストリームAPIの基本
ストリームAPIとパイプライン処理
ストリームAPIとは、データに対してパイプライン処理を行うためのAPIです。パイプライン処理とは、ある処理の出力が次の処理の入力となるように処理を連結し、入力元のデータから目的とするデータを出力するための仕組みです。
ストリームAPIには、ストリームの生成、中間操作、終端操作という3つの段階があります。
それぞれの説明を行う前に、具体的なコードのイメージをつかんでもらうために簡単な例を示します。このコードは、いくつかの数値から構成されるリストに対して、偶数に絞り込んだ上で重複を排除し、その上で要素の個数を算出するためのものです。
public static void main(String[] args) {
List<Integer> list = Arrays.asList(8, 4, 1, 10, 4, 2, 5, 6, 9, 4);
long count = list.stream() //ストリーム生成
.filter(x -> x % 2 == 0) // 中間操作その1
.distinct() // 中間操作その2
.count(); // 終端操作
System.out.println(count);
}
このコードを実行すると、コンソールに「5」が表示されます。
中間操作や終端操作のためのAPIには、操作内容をラムダ式やメソッド参照として渡します。このようにAPIを連結することで、入力元となるデータから、目的となるデータを得ることがストリームAPIの特徴です。
それでは、3つの段階について順番に説明します。
【図4-2-1】ストリームAPIのパイプライン処理

1つ目は入力元となるストリームの生成です。ストリームとは、パイプライン処理の入力元となる要素の集合です。ストリームはコレクションから生成するケースが大半ですが、ストリームAPIによって直接生成することも可能です。
次に中間操作です。中間操作とは、ストリームの各要素に対して何らかの処理を実行し、その結果をストリームで受け取る、という操作です。中間操作には様々な種類があり詳細は後述しますが、その中でも代表的なものはフィルタ操作とマップ操作です。フィルタ操作とは、ストリームの各要素を特定の条件で絞り込む操作です。またマップ操作とは、ストリームの各要素を変換する操作です。中間操作はいくつでも連結して実行することができますが、場合によっては省略することも可能です。
最後に終端操作です。終端操作とは、ストリームから目的とするデータを取り出す操作です。終端操作によってストリーム以外の型が返されるため、一連のパイプラインは終了になります。終端操作ではリダクションを行います。リダクションとはストリームの各要素の個数、合計値、最大値、最小値、平均値などを計算したり、値を特定のキーによって集約したりする操作を表します。終端操作は、最終的に必ず一度だけ実行する必要があります。
ストリームAPIの全体像
ストリームAPIは前述したように、3つの段階があります。それぞれのAPIは以下のようなクラスによって提供され、またそれぞれに対応する戻り値があります。ストリームAPIの基本的な流れは、入力元データからストリームを生成し、中間操作、終端操作を経て、最終的には目的となるデータを出力する、というものです。
【表4-2-1】ストリームAPIの全体像
| APIの種類 | 対象クラス | 戻り値 |
|---|---|---|
| ストリーム生成 | コレクションやStreamクラス | Stream<T> |
| 中間操作 | Stream<T> | Stream<T> |
| 終端操作 | Stream<T> | プリミティブ型やコレクションなど |
まずストリーム生成では、入力元となるデータからストリームを生成します。ストリームは、コレクションのAPIや、java.util.stream.Streamクラスのファクトリメソッドから生成します。生成されるストリームの型は、java.util.stream.Stream<T>です。
中間操作はStream<T>型に対して実行し、その結果としてStream<T>型を返します。
最後に終端操作はStream<T>型に対して実行し、その結果としてストリーム以外の型、具体的にはプリミティブ型やコレクションなどを取得します。
ストリームAPIでは通常、ストリーム生成、中間操作、終端操作と、流れるようにメソッドをチェーンして実装します。
なお中間操作や終端操作のためのAPIは、ほとんどが関数型インタフェースを引数に取るため、それに応じたラムダ式やメソッド参照を渡します。またこのチャプターでは、以降の内容において、中間操作や終端操作のためのAPIを説明していきます。その中で「ラムダ式を渡す」という表現がたびたび登場しますが、ここで言うラムダ式にはメソッド参照が含まれると理解ください。
順次ストリームと並列ストリーム
ストリームには、順次ストリームと並列ストリームの二種類があります。
順次ストリームとは、要素を1つずつ順番に取り出して処理するストリームです。順次ストリームでは、ストリーム内の各要素は、ストリームが生成された時点で順序付けがなされています。例えばリストから順次ストリームを生成する場合は、その順序がそのまま反映されます。
一方で並列ストリームは、マルチスレッドによって各要素を暗黙的に並列処理するためのストリームです。並列ストリームでは、ストリーム内の各要素がどのような順番で処理されるか保証されません。
なおこのチャプターでは、レッスン4.2.5までは順次ストリームを扱うものとし、並列ストリームについてはレッスン4.2.6で取り上げます。
遅延実行
前述したようにストリームAPIには、ストリーム生成、中間操作、終端操作という3つの段階があり、それぞれをメソッドチェーンでつなぎ合わせて実装します。
それではこの一連のパイプライン処理は、いつ実行されるのでしょうか。実は各中間操作のAPIを呼び出したタイミングでは処理は何も行われず、最終的に終端操作を行ったタイミングで、一連のパイプラインが実行されます。このように必要なタイミングまで実行を遅らせることを、遅延実行と呼びます。
中間操作のAPIにはその操作内容をラムダ式(またはメソッド参照)として渡しますが、ラムダ式自体が遅延実行という特性を持っているため、それを活かしています。遅延実行によりストリームやコレクションの生成コストを最小限に留めることができ、リソースの使用効率を高めることを可能にします。
4.2.2 ストリームの生成
コレクションからのストリーム生成
大半のケースにおいて、ストリームはコレクションから生成します。
リスト(java.util.Listインタフェース)やセット(java.util.Setインタフェース)には、以下のようなstream()メソッドが定義されており、これを呼び出すと順次ストリームを生成することができます。
- Stream<E> stream()
それでは、このメソッドによってストリームを生成するコードを見ていきましょう。ただしストリームは生成しただけでは意味をなさないため、ここでは終端操作としてforEach()メソッドを呼び出し、メソッド参照System.out::printlnを指定することにします。
forEach()メソッドはStreamクラスが持つメソッドで、コレクションにおけるforEach()メソッドと同様に、繰り返し何らかの処理を実行するためのものです。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
list.stream()
.forEach(System.out::println);
このコードを実行すると、1、2、3といった順序で、コンソールに1から10までの数値が表示されます。
Streamクラスからのストリーム生成
java.util.stream.Streamクラスには、以下のようなストリーム(ここでは順次ストリーム)を生成するためのファクトリメソッドが用意されています。
| API(メソッド) | 説明 |
|---|---|
| static Stream<T> of(T...) | 指定された値を要素に持つ、順序付けされた順次ストリームを返す。 |
| static Stream<T> generate(Supplier<? extends T> s) | 指定されたラムダ式によって生成される要素を持つ、順序付けされていない無限順次ストリームを返す。 |
| static Stream<T> iterate(T, UnaryOperator<T>) | 第一引数を初期値として、それに第二引数のラムダ式を繰り返し適用することで生成される、順序付けされた無限順次ストリームを返す。 |
| static Stream<T> concat(Stream<? extends T>, Stream<? extends T>) | 第一引数と第二引数のストリームを連結して返す。 |
この中で、まずof()メソッドは以下のように使用します。
Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
.forEach(System.out::println);
このように、可変長配列を引数に与えることでストリームを生成します。
次にiterate()メソッドです。
Stream.iterate(10, x -> {return x * 2;})
.limit(20)
.forEach(System.out::println);
iterate()メソッドは第一引数には初期値、第二引数にはUnaryOperator型の関数型インタフェース、すなわち「引数T、戻り値T」のラムダ式を取ります。第一引数の初期値に対して、第二引数に指定したラムダ式を繰り返し適用することで、ストリームを生成します。
なお、iterate()メソッドやgenerate()メソッドによって生成されるストリームは無限ストリームになり、永遠に処理が繰り返されてしまいます。従って、中間操作として後述するlimit()メソッドにより上限を設定する、という用途が一般的です。
プリミティブ型ストリームによるストリーム生成
ストリームには、特定のプリミティブ型に特化したストリームクラスがあります。
- java.util.stream.IntStream … int型の処理に特化したストリーム
- java.util.stream.LongStream … long型の処理に特化したストリーム
- java.util.stream.DoubleStream … double型の処理に特化したストリーム
これらのクラスにはStreamクラスと同様に、終端操作(リダクション)のためのメソッドや、ストリームを生成するためのファクトリメソッドが定義されています。
また、各プリミティブ型に固有のAPIも用意されています。例えばIntStreamやLongStreamでは、range()メソッドやrangeClosed()メソッドによって、範囲を指定してストリームを生成することができます。
- static IntStream range(int, int)
- static IntStream rangeClosed(int, int)
それぞれのメソッドの第一引数は初期値、第二引数は上限値になりますが、range()メソッドが上限値を含まないのに対して、rangeClosed()メソッドは上限値を含みます。
例えば、range()メソッドは以下のように使用します。
IntStream.range(1, 11)
.forEach(System.out::println);
このコードでは、1から10までのIntStreamが生成されます。
配列からのストリーム生成
ストリームは、配列から生成することができます。配列からストリームを生成するためには、java.util.Arraysクラスのstream()メソッドを使用します。
- static Stream<T> stream(T[])
このメソッドに任意の型の配列を渡すことで、以下のようにしてストリームを生成します。
String[] strArray = {"foo", "bar", "baz"};
Arrays.stream(strArray) // ここでStream<String>が返される
.forEach(System.out::println);
このメソッドにはオーバーロードされたメソッドがあり、引数の配列がプリミティブ型の場合は、それぞれの型に対応したプリミティブ型ストリームが返されます。
- static IntStream stream(int[])
- static LongStream stream(long[])
- static DoubleStream stream(double[])
これらのメソッドによってプリミティブ型ストリームを生成しますが、以下のように中間操作をチェーンする場合は、プリミティブ型ストリームであることを意識する必要はありません。
int[] intArray = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
Arrays.stream(intArray) // ここでIntStreamが返される
.forEach(System.out::println);
4.2.3 中間操作
このレッスンでは、ストリームAPIにおける様々な中間操作の方法について説明します。
中間操作のための主要なAPI
java.util.stream.Streamクラスにおいて、中間操作を実行するための主要なAPIには、以下のようなものがあります。
| API(メソッド) | 説明 |
|---|---|
| Stream<T> filter(Predicate<? super T>) | このストリームの各要素を、指定されたラムダ式による条件で絞り込み、その結果をストリームで返す。 |
| Stream<R> map(Function<? super T,? extends R>) | このストリームの各要素を、指定されたラムダ式による処理で変換し、その結果をストリームで返す。 |
| Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>>) | このストリームの各要素を、指定されたラムダ式による処理で分解・増幅し、新たなストリームを生成する。このメソッドからは、ラムダ式内で戻り値として返されるストリームが、すべて結合されたストリームが返される。 |
| Stream<T> peek(Consumer<? super T>) | このストリームの各要素に対して、指定されたラムダ式による処理を実行する。ただしラムダ式は戻り値を持たないConsumerインタフェースのため、ストリームに変化は発生せず、同じストリームを受け取る。 |
| Stream<T> distinct() | このストリームの各要素から、(equalsメソッドによって)重複を取り除き、ストリームで返す。 |
| Stream<T> sorted() | このストリームの各要素を、「自然順序付け」に従ってソートし、ストリームで返す。 |
| Stream<T> sorted(Comparator<? super T>) | このストリームの各要素を、指定されたコンパレータに従ってソートし、ストリームで返す。 |
| Stream<T> skip(long) | このストリームの各要素から、最初の指定された個数分を廃棄し、残りの要素で構成されるストリームを返す。 |
| Stream<T> limit(long) | このストリームの各要素を、指定された長さの上限値に収まるように切り詰め、ストリームで返します。 |
フィルタ操作
ここでは、代表的な中間操作の1つであるフィルタ操作について説明します。
ストリームに対してfilter()メソッドを呼び出し、Predicateインタフェースを渡します。このインタフェースはboolean型を返すラムダ式で実装されますので、その内容に従って、特定の条件で要素を絞り込むことができます。具体的には、以下のコードを見てください。
List<Integer> list = Arrays.asList(8, 4, 1, 10, 4, 2, 5, 6, 9, 4);
list.stream()
.filter(x -> x % 2 == 0) //【1】
.distinct() //【2】
.forEach(System.out::println);
このコードではまず第一の中間操作として、filter()メソッドにラムダ式を渡し、「偶数」という条件で要素を絞り込みます【1】。そのままメソッドをチェーンさせて、第二の中間操作としてdistinct()メソッドを呼び出し、重複を排除します【2】。
このコードを実行すると、結果として、8、4、10、2、6という数値が表示されます。
【図4-2-2】絞り込みと重複排除

マップ操作
ここでは、もう1つの代表的な中間操作であるマップ操作について説明します。
ストリームに対してmap()メソッドを呼び出し、Functionインタフェースを渡します。このインタフェースは「引数と戻り値を持つ」ラムダ式で実装されるので、その内容に従って、特定の条件で要素を変換することができます。
なおマップと聞くと、コレクションフレームワークにおけるマップ(キーと値の組み合わせ)を連想する方も多いと思います。どちらも「何かに何かを割り当てる」という意味ですが、ここでは別の用語として理解してください。
それではマップ操作の具体例を以下に示します。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
list.stream()
.map(x -> x * 2) //【1】
.forEach(System.out::println);
このコードでは、中間操作としてmap()メソッドにラムダ式を渡し、個々の数値を2倍にして返しています【1】。このメソッドはFunctionインタフェースを受け取るため、渡すのは「引数が1つで戻り値を持つ」ラムダ式になります。このコードを実行すると、結果として、2、4、6、8、10…といった数値が表示されます。
次に以下のコードを見てください。
List<String> strList = Arrays.asList("Japan", "USA", "France");
strList.stream()
.map(str -> str.toUpperCase()) //【1】
.sorted() //【2】
.forEach(System.out::println);
今度は文字列のリストからストリームを生成しています。具体的には"Japan", "USA", "France"という3つの文字列からなるリストを生成します。まず第一の中間操作として、map()メソッドにラムダ式を渡し、個々の文字列を大文字化して返しています【1】。そのままメソッドをチェーンさせて、第二の中間操作としてsorted()メソッドを呼び出し、「自然順序付け」に従ってソートします【2】。
このコードを実行すると、結果として"FRANCE"、"JAPAN"、"USA"という文字列が表示されます。
【図4-2-3】変換とソート

プリミティブ型ストリームを返すマップ操作
マップ操作では、特定のプリミティブ型ストリームを返すメソッドが用意されています。
- IntStream mapToInt(ToIntFunction<? super T>)
- LongStream mapToLong(ToLongFunction<? super T>)
- DoubleStream mapToDouble(ToDoubleFunction<? super T>)
これらのメソッドの引数は、例えばmapToInt()メソッドの場合は、ToIntFunction型です。従って「引数を持ち、戻り値としてint型を返すラムダ式」を指定します。
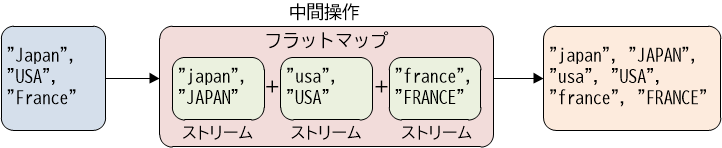
フラットマップ操作
前項で説明したマップ操作は、ストリームの各要素を特定のロジックで変換する、というものでした。マップ操作では、1つの要素に対する操作で、1つの要素が返されます。それに対してフラットマップ操作とは、各要素を何らかのロジックで分解したり増幅したりするための操作です。従ってフラットマップ操作では、1つの要素に対する操作で、複数の要素が返されます。
フラットマップ操作を行うために、flatMap()メソッドを使用します。このメソッドに渡すラムダ式では各要素を分解・増幅し、それをストリームの形にして返します。そしてflatMap()メソッドでは、それらのストリームを最終的には1つのストリームに結合して返します。若干難しく聞こえるかもしれませんので、具体的に見ていきましょう。
List<String> strList = Arrays.asList("Japan", "USA", "France");
strList.stream()
.flatMap(str -> Stream.of(str.toLowerCase(), str.toUpperCase())) //【1】
.forEach(System.out::println);
最初に"Japan", "USA", "France"という3つの文字列からなるリストを生成します。stream()メソッドでストリームを生成したら、次にflatMap()メソッドによってストリームを生成します【1】。ここの挙動を詳しく見ていきます。このflatMap()メソッドに渡されたラムダ式を見ると、Streamクラスのof()メソッドによって、ストリームを生成しています。生成されるストリームは、2つの要素からなるものです。具体的には、ストリームの要素の一つ目が変数strを小文字化した文字列で、二つ目が大文字化した文字列です。そして最終的には、これらのストリームがすべて結合されて返されます。従ってこのコードを実行すると、結果として、"japan"、"JAPAN"、"usa"、"USA"、"france"、"FRANCE"という6つの文字列が表示されます。
【図4-2-4】フラットマップ操作
要素のソートと範囲指定での切り出し
Streamクラスに定義されたsorted()メソッド、skip()メソッド、limit()メソッドなどを使うと、要素を並べ替え、指定された範囲で切り出すことができます。次のコードを見てください。
List<Integer> list = Arrays.asList(6, 9, 2, 10, 3, 1, 5, 8, 7, 4); //【1】
list.stream() //【2】
.sorted() //【3】
.skip(3) //【4】
.limit(5) //【5】
.forEach(System.out::println);
この例では、まず1から10までの数値がランダムに格納されているリストがあるものとします【1】。そのリストに対してストリームを生成し【2】、sorted()メソッドによってソートします【3】。このメソッドは「自然順序付け」、すなわち数値の場合は昇順にソートされますが、特定のコンパレータを引数に指定することも可能です。
次にskip()メソッドによって、最初の3つの要素を廃棄します【4】。そしてlimit()メソッドによって、要素の個数の上限を5に設定します【5】。
このコードを実行すると、結果として、4、5、6、7、8という数値が順に表示されます。
4.2.4 終端操作
このレッスンでは、ストリームAPIにおける様々な終端操作の方法について説明します。
終端操作のための主要なAPI
終端操作ではリダクションを行います。リダクションとは、ストリームの各要素の個数、合計値、最大値、最小値、平均値などを計算したり、値を特定のキーによって集約したりする操作を表します。
java.util.stream.Streamクラスにおいて、終端操作を実行するための主要なAPIには、以下のようなものがあります。
| API(メソッド) | 説明 |
|---|---|
| void forEach(Consumer<? super T>) | このストリームの各要素に対して、指定されたラムダ式の処理を実行する。 |
| void forEachOrdered(Consumer<? super T> ) | このストリームの各要素に対して、指定されたラムダ式の処理を実行する。ストリームの種類(順次・並列)に関わらず、ストリームの順序付けに従って実行される。 |
| long count() | このストリームの要素の個数を返す。 |
| boolean allMatch(Predicate<? super T>) | このストリームのすべての要素が、指定されたラムダ式による条件に一致するかどうかを判定し、その結果を返す。 |
| boolean anyMatch(Predicate<? super T>) | このストリームのいずれかの要素が、指定されたラムダ式による条件に一致するかどうかを判定し、その結果を返す。 |
| boolean noneMatch(Predicate<? super T>) | このストリームのすべての要素が、指定されたラムダ式による条件に一致しないことを判定し、その結果を返す。 |
| Optional<T> max(Comparator<? super T>) | このストリームの要素のうち、指定されたコンパレータに従って最大となる要素を返す。 |
| Optional<T> min(Comparator<? super T>) | このストリームの要素のうち、指定されたコンパレータに従って最小となる要素を返す。 |
| Optional<T> findFirst() | このストリームの要素のうち、最初の要素を返す。ストリームの種類(順次・並列)に関わらず最初の要素が返される。 |
| Optional<T> findAny() | このストリームの要素のうち、最初の要素を返す。ストリームの種類(順次・並列)によって返される要素が変わる可能性がある。 |
| Optional<T> reduce(BinaryOperator<T>) | このストリームの各要素に対して、指定されたラムダ式による汎用的なリダクション操作を実行し、単一の値を得る。そして、その結果を含むOptionalを返す。 |
| R collect(Collector<? super T,A,R>) | このストリームの各要素に対して、指定されたコレクタによる可変リダクション操作を実行。その結果を、リストやマップといった何らかのデータ構造として返す。 |
この中で、forEach()メソッドについてはすでに登場していますが、コレクションに対するforEach()メソッドと同様に、ラムダ式やメソッド参照によってループ処理を実現するためのものです。また、この中で特に重要であり比較的難解なのがcollect()メソッドですが、これについては次のレッスンで詳細に説明します。
プリミティブ型ストリームによる終端操作
既出のようにプリミティブ型ストリームには、IntStream、LongStream、そしてDoubleStreamといった種類があります。これらクラスには、汎用的なStreamクラスにはない、そのプリミティブに特化した終端操作が定義されています。
この中から代表的なIntStreamを取り上げます。このストリームは、中間操作でmapToInt()メソッドを呼び出すことにより生成します。生成したIntStreamには、以下のようにint型固有の集約演算を行うためのAPIがあります。
| API(メソッド) | 説明 |
|---|---|
| int sum() | このストリームの各要素の合計値を返す。 |
| OptionalInt max() | このストリームの最大値をOptionalInt型で返す。 |
| OptionalInt min() | このストリームの最小値をOptionalInt型で返す。 |
| OptionalDouble average() | このストリームの各要素の平均値を、OptionalDouble型で返す。 |
これらのAPIや、Streamクラスの終端操作の多くのメソッドには、Optional型やまたはOptional〇〇型を返すものがあります。これは、中間操作の過程において、フィルタ操作などでストリームが空になった場合、適切な値を返すことができないためです。例えば空のストリームに対してmax()メソッドを呼び出すと、値が空のOptionalInt型が返されます。OptionalIntのorElse()メソッドを呼び出せば、OptionalIntが空の場合に返される値を決めることが可能です。
集約演算
ここでは、ストリームの各要素に対する集約演算、具体的には要素の個数を数えたり、合計値、最大値、最小値、平均値などを計算する方法について説明します。
まずは個数を数える処理です。以下のコードを見てください。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
long count = list.stream()
.filter(x -> x % 2 == 0)
.count();
このコードでは、まず中間操作の中でfilter()メソッドによって偶数に絞り込みます【1】。そして終端操作としてcount()メソッドを呼び出し、ストリームの各要素の個数を取得します【2】。
次に合計値です。以下のコードを見てください。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
long sum = list.stream()
.mapToInt(x -> x * 10) //【1】
.sum(); //【2】
このコードでは、まず中間操作の中でmapToInt()メソッドを呼び出して各要素の値を10倍し、IntStreamを生成します【1】。
そして終端操作としてsum()メソッドを呼び出し、ストリームの各要素の合計値を取得します【2】。
最後に平均値です。次のコードを見てください。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
OptionalDouble opt = list.stream()
.filter(x -> 5 < x)
.mapToInt(x -> x)
.average(); //【1】
double avg = opt.orElse(0.0d); //【2】
このコードでは、リストの要素を5より大きいという条件で絞り込み、IntStreamを生成した後、average()メソッドによって平均値を算出しています【1】。このメソッドの戻り値はOptionalDouble型ですが、途中のフィルタ操作でストリームが空になった場合は、OptionalDoubleも空になります。そのためここでは平均値を取り出すだけでなく、空だった場合に返される値をorElse()メソッドによって設定しています【2】。
要はこのコードでは、例えば対象リストの中に5よりも大きい要素が一つも含まれていなかったとすると、
一連のパイプラインの結果として得られるOptionalDoubleは空になります。そして【2】で平均値を取り出すとOptionalDoubleは空のため、orElse()メソッドに指定されたdouble型の0が返される、というわけです。
汎用的なリダクション操作
リダクションによって単一の値を得たいケースの大半は、既出の集合演算によって対応することができるでしょう。
ストリームの各要素に対して、集合演算以外の、何らかの汎用的なリダクションを行い、その結果を単一の値として取得したい場合は、reduce()メソッドを使用します。reduce()メソッドには、BinaryOperatorインタフェースを渡します。このインタフェースは「2つの引数と戻り値を持ち、すべての型が同じ」ラムダ式で実装されますので、その内容に従ってリダクションが行われます。
具体的に見ていきましょう。まず以下のコードは、リスト内の各文字列を"/"を区切り文字にして連結するためのものです。
List<String> strList = Arrays.asList("Alice", "Bob", "Carol", "Dave");
String concatedString = strList.stream()
.reduce((result, param) -> result + "/" + param) //【1】
.orElse(""); //【2】
reduce()メソッドに渡されるラムダ式は2つの引数を取りますが、まず第一引数(ここではresult)はラムダ式による演算結果を格納するための変数です。また第二引数(ここではparam)は、ストリームから渡される各要素です。一番最初に限り、第一引数にはストリームの最初の要素が、第二引数には二番目の要素が渡されます。そしてそれ以降は、演算された結果に対して、三番目以降の要素が新たに演算対象になります。このラムダ式では、変数resultに対して、区切り文字"/"と渡される要素(変数param)を連結しています【1】。終端操作が終わると、Optional<String>型が返されるため、値を取り出すだけではなく、空だった場合に返される値を設定しています【2】。
このコードを実行すると、結果として文字列"Alice/Bob/Carol/Dave"が返されます。
次に別の例を示します。以下のコードは、リスト内の各文字列の長さを数え、それを合計するためのものです。
List<String> strList = Arrays.asList("Alice", "Bob", "Carol", "Dave");
int strLength = strList.stream()
.mapToInt(str -> str.length())
.reduce((result, param) -> result + param) //【1】
.orElse(0); //【2】
このラムダ式では、変数resultに対して、各文字列の長さ(変数param)を足し込んでいます【1】。終端操作が終わるとOptionalInt型が返されるため、空かどうかを判定した上で値を取り出します【2】。このコードを実行すると、結果として数値17が返されます。
4.2.5 コレクタによる可変リダクション
可変リダクションとコレクタ
可変リダクションとは、終端操作によって、ストリームからコレクションを生成したり、また値を特定のキーで集約したり、連結したりすることを意味します。
この操作は、まさにストリームAPIの機能が、最も効果的に発揮されるケースの1つと言うことができます。可変リダクションは、ストリーム(java.util.stream.Streamクラス)のcollect()メソッドに、コレクタを渡すことによって実行します。コレクタとは、可変リダクションの操作を抽象化した概念で、java.util.stream.Collectorインタフェースによって表されます。
Collectorインタフェースのオブジェクトは、後述するCollectorsクラスのファクトリメソッドによって生成します。生成されるCollectorオブジェクトは、3つの型パラメータを取り、幾つかのメソッドも定義されていますが、このオブジェクトはcollect()メソッドにそのまま渡して終端操作を終えるため、通常、開発者がCollectorクラスの型パラメータやメソッドを意識する必要はありません。
コレクタの生成方法
Collectorインタフェースのオブジェクトは、java.util.stream.Collectorsクラスによって提供されるファクトリメソッドによって生成します。
Collectorsクラスには数多くのファクトリメソッドが定義されていますが、特に代表的なものを以下に示します。いずれもCollectorオブジェクトが返されます。
| API(メソッド) | 説明 |
|---|---|
| static Collector<T,?,List<T>> toList() | ストリームの各要素を、新しいリストに格納するためのコレクタを返す。 |
| static Collector<T,?,Set<T>> toSet() | ストリームの各要素を、新しいセットに格納するためのコレクタを返す。 |
| static Collector<T,?,Map<K,U>> toMap((Function<? super T,? extends K>, Function<? super T,? extends U>, BinaryOperator<U>) |
ストリームの各要素を、新しいマップに格納するためのコレクタを返す。第一引数にはキーを生成するためのラムダ式、第二引数には値を生成するためのラムダ式、第三引数にはキーが競合した場合にマージするためのラムダ式を、それぞれ指定する。 |
| static Collector<T,?,Map<K,List<T>>> groupingBy(Function<? super T,? extends K>) |
指定されたラムダ式(Functionインタフェース)をキーに、ストリームの各要素をグループ化し、結果をマップに格納するためのコレクタを返す。 |
| static Collector<T,?,Map<K,D>> groupingBy(Function<? super T,? extends K>, Collector<? super T,A,D>) |
指定されたラムダ式(Functionインタフェース)をキーに、ストリームの各要素をグループ化し、結果をマップに格納するためのコレクタを返す。第二引数には、値を集約するためのコレクタを指定する。 |
| static Collector<T,?,Map<Boolean,List<T>>> partitioningBy(Predicate<? super T>) |
指定されたラムダ式(Predicateインタフェース)に従って、ストリームの各要素を2つにグループ化し、結果をマップに格納するためのコレクタを返す。 |
| static Collector<CharSequence,?,String> joining(CharSequence) |
指定された区切り文字で、ストリームの各要素を連結するコレクタを返す。 |
| static Collector<T,?,Long> counting() |
ストリーム要素の個数を数えるためのコレクタを返す。 |
| static Collector<T,?,Integer> summingInt(ToIntFunction<? super T>) |
指定されたラムダ式に従って、ストリームの各要素の合計値を算出するコレクタを返す。同様のAPIに、summingLong、summingDoubleがある。 |
| static Collector<T,?,Double> averagingInt(ToIntFunction<? super T> mapper) |
指定されたラムダ式に従って、ストリームの各要素の平均値を算出するコレクタを返す。同様のAPIに、averagingLong、averagingDoubleがある。 |
売上明細リストについて
このレッスンでは「売上明細データから構成されるリスト」を題材として取り上げます。個々の売上明細を表すSalesクラスは、以下のようなコードです。
public class Sales {
private final Integer id; // 売上明細ID
private final String productName; // 商品名
private final Integer count; // 売上個数
// コンストラクタ
........
// ゲッター
........
}
個々の売上明細のキーとなるのが売上明細IDで、属性として、売上対象の商品名と、売れた個数を持つものとします。また商品名は、商品のカテゴリーに応じて"A-XX"、"B-XX"、"C-XX"という文字列で表されるものとします。
このような売上明細リストのデータは、以下のようなCSVファイルで表すことができます。第一フィールドが売上明細ID、第二フィールドが商品名、第三フィールドが売上個数を表します。
1,A-51,2
2,A-18,3
3,B-09,1
4,B-06,1
5,A-44,3
....
このような膨大な売上明細リストがあるという前提を置いた上で、この後、ストリームAPIとコレクタの挙動を説明していきます。
終端操作によるコレクションの生成
ここではまず終端操作として、ストリームからリストを生成する処理を取り上げます。以下のコードを見てください。
List<Sales> salesList = SalesHolder.getSalesList(); // 売上明細リストを取得
List<Sales> resultList = salesList.stream() //【1】
.filter(s -> s.getProductName().startsWith("A")) //【2】
.collect(Collectors.toList()); //【3】
まず独自のユーティリティによって売上明細リスト(変数salesList)を取得します。このユーティリティによって、前述したCSVファイルの各行のデータが、それぞれSalesクラスのインスタンスとして生成され、それらのSalesインスタンスを要素として持つリストが取得された、と考えてください。
準備が出来たところでストリームを生成します【1】。ここでは、1つ1つの売上明細(Salesインスタンス)が、ストリーム内の要素になります。次にフィルタ操作としてfilter()メソッドを呼び出し、商品名を"A-〇〇"に絞り込みます【2】。最後に終端操作としてcollect()メソッドを呼び出し、CollectorsクラスのtoList()メソッドによって生成されるコレクタを渡します【3】。このようにすると、ストリームの中間操作を経由して、終端操作によって新しいリストを生成することができます。
次に、ストリームからマップを生成する処理です。以下のコードを見てください。
List<Sales> salesList = SalesHolder.getSalesList(); // 売上明細リストを取得
Map<Integer, Integer> resultMap = salesList.stream()
.filter(sales -> sales.getProductName().startsWith("A"))
.collect(Collectors.toMap( //【1】
Sales::getId, //【2】
Sales::getCount, //【3】
(oldVal, newVal) -> newVal)); //【4】
独自のユーティリティによって売上明細リストを取得したら、フィルタ操作によって商品名を"A-〇〇"に絞り込む点までは、既出のコードと同様です。
終端操作としてcollect()メソッドを呼び出し、CollectorsクラスのtoMap()メソッドによって生成されるコレクタを渡します【1】。
toMap()メソッドは3つの引数を取ります。第一引数にはキーを生成するためのラムダ式を、第二引数には値を生成するためのラムダ式を、それぞれ指定します。このコードでは、ラムダ式の代わりにメソッド参照を指定しています【2、3】。このように指定すると、キーが売上明細ID、値が売上個数となるマップが生成されます。第三引数にはキーが競合した場合に値をマージするためのラムダ式を指定しますが、このコードでは常に新しい値で上書きするようにしています【4】。
キーによるグルーピング
CollectorsクラスのgroupingBy()メソッドによって、特定のキーで各要素をグルーピングし、キーと「そのキーでグルーピングされた要素から構成されるリスト」を値として持つ、マップを生成することができます。売上明細リストの例では、生成されるマップの型は、商品名をキーにグルーピングするのであれば、Map<String, List<Sales>>という型になります。具体的には以下のコードを見てください。
List<Sales> salesList = SalesHolder.getSalesList(); // 売上明細リストを取得
Map<String, List<Sales>> resultMap = salesList.stream()
.filter(sales -> sales.getProductName().startsWith("A"))
.collect(Collectors.groupingBy( //【1】
Sales::getProductName)); //【2】
売上明細リストを取得したら、フィルタ操作によって商品名を"A-〇〇"に絞り込む点までは、既出のコードと同様です。終端操作としてcollect()メソッドを呼び出し、CollectorsクラスのgroupingBy()メソッドによって生成されるコレクタを渡します【1】。groupingBy()メソッドには、キーを生成するためのラムダ式を渡しますが、ここではSalesクラスのgetProductName()メソッドのメソッド参照を渡すことで、商品名をキーに設定しています【2】。このコードを実行すると「キーは商品名、値はその商品名による売上明細リスト」というマップが生成され、変数resultMapに格納されます。
生成されたマップをダンプ出力すると、このようなイメージです。
A-16 => [
Sales [id=58, productName=A-16, count=3],
Sales [id=77, productName=A-16, count=1],
....
],
A-13 => [
Sales [id=200, productName=A-13, count=2],
Sales [id=203, productName=A-13, count=1],
....
],
A-36 => [
Sales [id=271, productName=A-36, count=2],
Sales [id=489, productName=A-36, count=3],
....
],
....
キーによる集約演算~個数を数える
CollectorsクラスのgroupingBy()メソッドを使うと、特定のキーでグルーピングするだけではなく、グルーピングされたリストに対する集約演算を行うことができます。そのためにはgroupingBy()メソッドの第二引数に、集約演算を行うためのコレクタを指定します。例えば、代表的な集約演算である「個数を数える処理」の場合は、以下のようなコードになります。
List<Sales> salesList = SalesHolder.getSalesList(); // 売上明細リストを取得
Map<String, Long> resultMap = salesList.stream()
.filter(sales -> sales.getProductName().startsWith("A"))
.collect(Collectors.groupingBy(
Sales::getProductName,
Collectors.counting())); //【1】
groupingBy()メソッドの第二引数【1】以外の部分は、前項のコードとほとんど同様です。このようにCollectorsクラスのcounting()メソッド呼び出し【2】により、要素の個数を数えるためのコレクタを生成し、それを第二引数に指定します。このコードを実行すると、「キーは商品名、値はその商品による売上明細数」というマップが生成され、変数resultMapに格納されます。
生成されたマップをダンプ出力すると、このようなイメージです。
A-16 => 226
A-13 => 92
A-36 => 88
....
キーによる集約演算~合計値を算出する
次に集約演算の1つである「合計値を算出する処理」の場合は、以下のようなコードになります。
List<Sales> salesList = SalesHolder.getSalesList(); // 売上明細リストを取得
Map<String, Integer> resultMap = salesList.stream()
.filter(sales -> sales.getProductName().startsWith("A"))
.collect(Collectors.groupingBy(
Sales::getProductName,
Collectors.summingInt(Sales::getCount))); //【1】
groupingBy()メソッドの第二引数【1】以外の部分は、既出のコードとほとんど同様です。今度は、CollectorsクラスのsummingInt()メソッドを呼び出します。summingInt()メソッドにより、指定されたラムダ式またはメソッド参照に従って、それらが返す値の合計値を算出するためのコレクタを生成することができます。ここではSalesクラスのgetCount()メソッドへのメソッド参照を渡しているため、個々の売上明細における売上個数の合計値が算出されます。このコードを実行すると「キーは商品名、値はその商品名による売上個数の合計」というマップが生成され、変数resultMapに格納されます。
生成されたマップをダンプ出力すると、このようなイメージです。
A-16 => 370
A-13 => 147
A-36 => 141
....
ストリームAPIによる売上明細リストの一括処理
それではこのレッスンの集大成です。ここでは売上明細リストに対してフィルタ、マップといった中間操作を行い、終端操作として特定キーによる集合演算を行う、という例を取り上げます。以下のコードを見てください。
List<Sales> salesList = SalesHolder.getSalesList();
Map<String, Integer> resultMap = salesList.stream() //【1】
.filter(sales -> sales.getProductName().startsWith("A")) //【2】
.map(sales -> { //【3】
String newName = sales.getProductName().replace("-", "");
return new Sales(sales.getId(), newName, sales.getCount());
})
.collect(Collectors.groupingBy( //【4】
Sales::getProductName,
Collectors.summingInt(Sales::getCount)));
売上明細リストを取得したら、まずストリームを生成します【1】。次にフィルタ操作によって、商品名を"A-〇〇"に絞り込みます【2】。次にマップ操作によって、商品名から"-"を取り除き、新しいSalesインスタンスを生成して返します【3】。最後に終端操作としてcollect()メソッドを呼び出し、CollectorsクラスのsummingInt()メソッドによって、商品名ごとの売上合計数を算出します【4】。
このコードにおける一連のパイプライン処理を図に示すと、以下のようになります。
【図4-2-5】ストリームAPIによる売上明細リストの一括処理
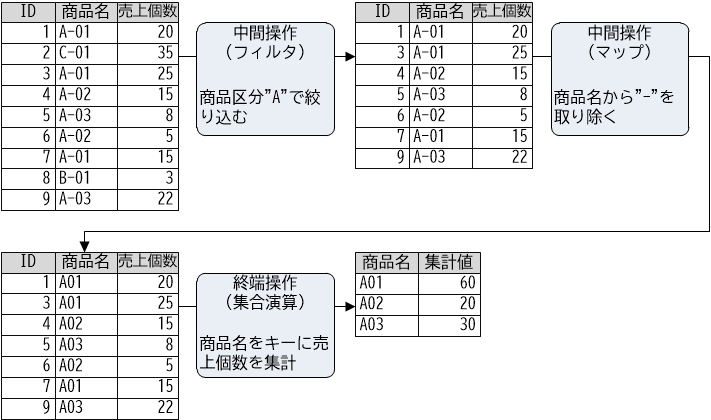
この図を見ると、売上明細リストに対して、フィルタ操作で商品名を"A-〇〇"に絞り込み、次にマップ操作によって商品名から"-"を取り除き、最後に終端操作で商品名をキーに売上個数を集計する、という一連のパイプラインを、イメージしていただけたのではないでしょうか。
4.2.6 並列ストリーム
並列ストリームとは
既出のとおり、ストリームには順次ストリームと並列ストリームがあります。
これまでのレッスンで取り上げたストリームはすべて順次ストリームでしたが、ここでは並列ストリームについて説明します。並列ストリームとは、並列処理を行うためのストリームです。並列ストリームによるパイプライン処理では、暗黙的にスレッドが生成され、マルチスレッドによって各要素が並列に処理されます。必然的に並列ストリームでは、ストリーム内の各要素がどのような順番で処理されるかは保証されません。また並列処理によってパフォーマンスの向上が見込めますが、スレッド生成には一定のオーバーヘッドがかかるため、一概にどちらに優位性があると決めることはできません。
コレクションからの並列ストリーム生成
リスト(java.util.Listインタフェース)やセット(java.util.Setインタフェース)には、以下のようなparallelStream()メソッドが定義されており、これを呼び出すと並列ストリームを生成することができます。
- Stream<E> parallelStream()
それでは、このメソッドによって並列ストリームを生成するコードを見ていきましょう。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
list.parallelStream()
.forEach(System.out::println);
順次ストリームの場合は、1、2、3といった順序で数字が表示されました。一方このコードは並列ストリームのため、順序は保証されず、毎回異なる順序になります。
試しに2回実行したところ、以下のようにコンソールに表示されました。
1回目 … 7, 6, 5, 9, 1, 4, 2, 10, 3, 8
2回目 … 7, 6, 9, 10, 8, 3, 1, 2, 4, 5
並列ストリームによる売上明細リストの一括処理
1つ前のレッスンで取り上げた、売上明細リストに対する一括処理は、並列ストリームでも実現することができます。以下のコードを見てください。
List<Sales> salesList = SalesHolder.getSalesList();
Map<String, Integer> resultMap = salesList.parallelStream() //【1】
.filter(sales -> sales.getProductName().startsWith("A"))
.map(sales -> {
String newName = sales.getProductName().replace("-", "");
return new Sales(sales.getId(), newName, sales.getCount());
})
.collect(Collectors.groupingBy(
Sales::getProductName,
Collectors.summingInt(Sales::getCount)));
既出のコードとの違いは、parallelStream()メソッド呼び出しだけであり、それ以外は完全に同様です。
これはあくまでも参考ですが、試しに講師の環境で、マップ操作の中で意図的に1ミリ秒停止する処理を加えた上で、10000件の売上明細リストに対して順次、並列、それぞれの方式で一括処理を行いました。順次ストリームでは処理に約11秒要したのに対して、並列ストリームでは約3秒という結果になりました。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- ストリームAPIによるパイプライン処理には、ストリームの生成、中間操作、終端操作という3つの段階があること。
- ストリームAPIの全体像について。
- ストリームを生成するための様々な方法について。
- 中間操作のための様々なAPIとその用法について。
- 終端操作のための様々なAPIとその用法について。
- コレクタによる可変リダクションや集約演算について。
- 並列ストリームの仕組みやその特性について。