はじめに
自己紹介
皆さん、こんにちは、斉藤賢哉と申します。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Advanced編』の一部の範囲をカバーしたものです。『Java Advanced編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをQiita内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの基本的なスキルを習得済みで、さらなるレベルアップを目指している方
- 将来的なキャリアとして、希少性の高い上級エンジニアやアーキテクトを志向している方
- フリーランスエンジニアとして付加価値の更なる向上を図っている方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
3.2 並行処理ユーティリティとExecutorフレームワーク
チャプターの概要
このチャプターでは、マルチスレッドを効率化するため並行処理ユーティリティと、その中でも最も代表的なExecutorフレームワークについて学びます。
3.2.1 並行処理ユーティリティとExecutorフレームワークの概要
並行処理ユーティリティとは
並行処理ユーティリティ(Concurrency Utilities)とは、マルチスレッドによる並列処理を、効率的かつ安全に実現するための仕組みです。広義の「並行」は「並列」の上位概念に当たりますが(前チャプター参照)が、並行処理ユーティリティはマルチスレッドのための仕組みなので、「並列」と読み替えても差し支えはないでしょう。
並行処理ユーティリティはJava SEのクラスライブラリによって提供され、そのクラスやインタフェースはすべてjava.util.concurrentパッケージに所属しています。
並行処理ユーティリティの機能は多岐に渡り、本チャプターで取り上げるExecutorフレームワークや、Fork/Joinフレームワーク、並行処理コレクションなどが含まれます。
Executorフレームワークとは
チャプター3.1で取り上げたThreadクラスによるマルチスレッドプログラミングは、仕様が複雑で規模が大きなアプリケーションに適用すると、実装の難易度が高まったり、リソースへの影響が大きくなったりする可能性があります。Executorフレームワークを利用すると、マルチスレッドを実現するための高度な機能が提供されるため、こういった課題を解消できます。
Executorフレームワークには、主に2つの機能があります。1つ目はスレッドプールです。スレッドプールとは、ある一定数のスレッドをあらかじめ生成してプーリングし、必要に応じてタスクを割り当てたり、使い回したりする機能です。
【図3-2-1】スレッドプールの仕組み
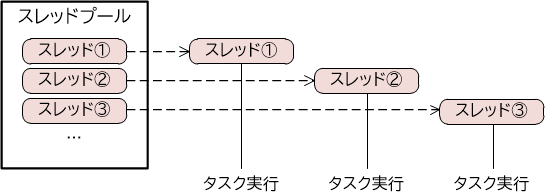
スレッドの生成には一定のコストがかかりるため、この機能によってリソースの使用効率を高めることができます。またスレッド自体がリソースを消費するため、プール化して生成数の管理することで、リソースを節約できるという利点もあります。Executorフレームワークを利用すると、容易にスレッドプールを生成し、プールされたスレッドにタスクを割り当てることが可能になります。
もう1つの機能は、スレッド同士の効率的な協調を行うための高度なスレッド管理です。Threadクラスによるマルチスレッドでは、スレッド終了の通知を受けたり、実行結果を取得しようとすると、非常に難易度の高い実装が必要になります。Executorフレームワークを利用すると、こういった処理を比較的容易に実現可能です。
Executorフレームワークの全体像
Executorフレームワークを構成する主要なクラス・インタフェースを、次に示します。
【図3-2-2】クラス図(Executorフレームワークの主要なクラス・インタフェース)
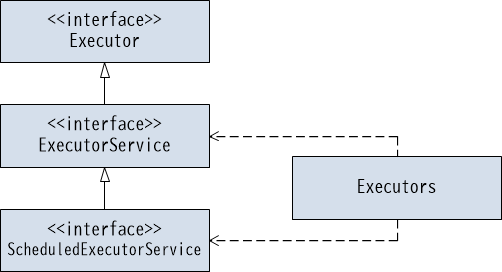
この中で開発者が特に意識するのは、インタフェースであるExecutorServiceとScheduledExecutorServiceの2つです。これらは継承関係になっています。またExecutorServiceインタフェースの主な実装クラスに、ThreadPoolExecutorクラスがあります。ScheduledExecutorServiceインタフェースの主な実装クラスに、ScheduledThreadPoolExecutorクラスがあります。ScheduledThreadPoolExecutorクラスは、ThreadPoolExecutorクラスを継承しています。
3.2.2 ExecutorServiceの操作方法
ExecutorServiceのAPI
ここではまず、Executorフレームワークにおいて最も基本的なインタフェースであるExecutorServiceについて説明します。
ExecutorServiceインタフェースの主要なAPIには、以下のようなものがあります。
| API(メソッド) | 説明 |
|---|---|
| Future<?> submit(Runnable) | 指定されたタスク(Runnable)を投入する。取得したFutureのget()メソッド正常に処理が完了した時点でnull値を返す。 |
| Future<T> submit(Callable<T>) | 指定されたタスク(Callable)を投入する。取得したFutureのget()メソッド正常に処理が完了した時点でタスクの実行結果を返す。 |
| <T> List<Future> invokeAll(Collection<? extends Callable<T>>) | 指定された複数のタスクを一括で起動する。すべて完了すると、実行結果を含むFutureのリストを返す。 |
| void shutdown() | シャットダウンする(新規タスクは受け付けない)。実行中のすべてのタスクは処理を継続する。 |
| List<Runnable> shutdownNow() | シャットダウンする(新規タスクは受け付けない)。実行中のすべてのタスクは強制的に終了する。 |
| boolean awaitTermination(long, TimeUnit) | 実行中のすべてのスレッドの終了を指定された時間だけ待機し、終了しなかった場合はfalseが返る。 |
| boolean isShutdown() | シャットダウン済みの場合、trueを返す。 |
この中でも特に重要なのかsubmit()メソッドで、このメソッドによってタスクを起動します。指定できるタスクには、既出のRunnableインタフェースを実装したものと、後述するCallableインタフェースを実装したものがあります。なおこのメソッドの戻り値であるFutureインタフェースについても、詳細はCallableインタフェースと一緒に、以降のレッスンで説明します。
またawaitTermination()メソッドの引数にTimeUnitがありますが、これは時間の単位を表す列挙型で、ミリ秒、秒、分、時などの値が定義されています。様々なAPIの中で引数として登場するので、覚えておくと良いでしょう。
次にExecutorServiceのオブジェクトを生成する方法です。ExecutorServiceのオブジェクトは、ThreadPoolExecutorクラスから直接生成することもできますが、ほとんどの場合はExecutorsクラスというユーティリティクラスから取得します。
ExecutorServiceを生成するためのExecutorsクラスのAPIを、次に示します。
| API(メソッド) | 説明 |
|---|---|
| static ExecutorService newSingleThreadExecutor() | 単一のスレッドによるExecutorServiceを返す(スレッドは使い回される) |
| static ExecutorService newCachedThreadPool() | 必要に応じて新規スレッドを追加可能なプールを作り、そのスレッドをタスクに割り当てるためのExecutorServiceを返す |
| static ExecutorService newFixedThreadPool(int) | 指定された個数のスレッドを持つ固定長のプールを作り、そのスレッドをタスクに割り当てるためのExecutorServiceを返す |
これら3つのAPIの中から1つを選択し、使用したいスレッドプールを持つExecutorServiceを取得します。
ExecutorServiceによるタスク実行(1)~単一のスレッド
それではここで、ExecutorServiceによってタスクを実行する処理を具体的に見てきましょう。まず以下に、このレッスンで共通的に実行するタスク(RunnableTaskクラス)のコードを示します。
public class RunnableTask implements Runnable {
private String name; // 名前
private int count; // カウント
public RunnableTask(String name, int count) {
this.name = name;
this.count = count;
}
@Override
public void run() {
long threadId = Thread.currentThread().getId(); // スレッドID
System.out.println("[ RunnableTask = " + name + " ] start, "
+ "threadId => " + threadId);
int value = 1;
for (int i = 0; i < count; i++) { // カウント分ループする
System.out.println("[ RunnableTask = " + name + " ] processing...");
value = value * 3; // 値を3倍する
sleepAWhile(1000); // 意図的に1秒停止する
}
System.out.println("[ RunnableTask = " + name + " ] finish, "
+ "value => " + value);
}
}
タスクは、既出のとおりRunnableインタフェースをimplementsして作成します。処理内容は、指定されたカウント分ループしてその中で掛け算を行い、最終的な結果をコンソールに出力するだけのシンプルなものです。各ループでは毎回1秒停止するため、例えばカウントが4の場合は約4秒の時間を要することになります。
次にExecutorServiceによって、このRunnableTaskを非同期に起動するためのコードを示します。ここではまず、単一のスレッドを持つExecutorServiceを取り上げます。ExecutorServiceからタスクを起動するためのメインスレッドは、このようになります。
ExecutorService executor = Executors.newSingleThreadExecutor(); //【1】
RunnableTask fooTask = new RunnableTask("foo", 4); //【2】
RunnableTask barTask = new RunnableTask("bar", 4);
RunnableTask bazTask = new RunnableTask("baz", 4);
executor.submit(fooTask); //【3】
executor.submit(barTask);
executor.submit(bazTask);
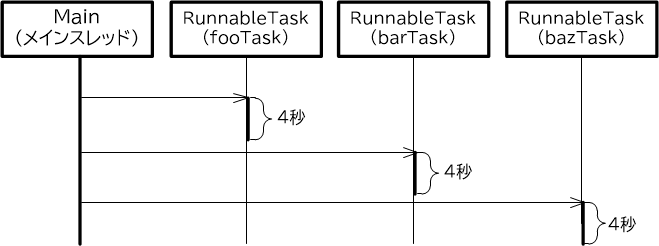
単一のスレッドを持つExecutorServiceは、ExecutorsクラスのnewSingleThreadExecutorメソッドによって取得します【1】。
次にfoo、bar、bazという名前を持つタスクをそれぞれ生成します【2】
そしてExecutorServiceのsubmit()メソッドに、生成したタスクを投入します【3】。
メインスレッドを実行すると、単一のスレッドに、fooTask、barTask、bazTaskが順番に割り当てられ、実行されます。なおコンソールに表示されるスレッドIDを見ると分かりますが、各タスクに割り当てられるスレッドは、同一のものが使い回されます。
【図3-2-3】ExecutorServiceによるタスク実行(単一のスレッド)
ExecutorServiceによるタスク実行(2)~動的なスレッドプール
前項と同じタスクを、「動的なスレッドプール」を持つExecutorServiceによって実行する方法を説明します。「動的なスレッドプール」を持つExecutorServiceは、ExecutorsクラスのnewCachedThreadPool()メソッドによって取得します。
ExecutorService executor = Executors.newCachedThreadPool();
メインスレッドのそれ以外の部分は、前項と同じコードになります。メインスレッドを実行すると、3つのスレッドが動的に生成され、それぞれにfooTask、barTask、bazTaskが割り当てられて並列に実行されます。
ExecutorServiceによるタスク実行(3)~固定的なスレッドプール
次に前項と同じタスクを、「固定的なスレッドプール」を持つExecutorServiceによって実行する方法を説明します。「固定的なスレッドプール」を持つExecutorServiceは、ExecutorsクラスのnewFixedThreadPool()メソッドによって取得します。
ExecutorService executor = Executors.newFixedThreadPool(2);
RunnableTask fooTask = new RunnableTask("foo", 8);
RunnableTask barTask = new RunnableTask("bar", 15);
RunnableTask bazTask = new RunnableTask("baz", 5);
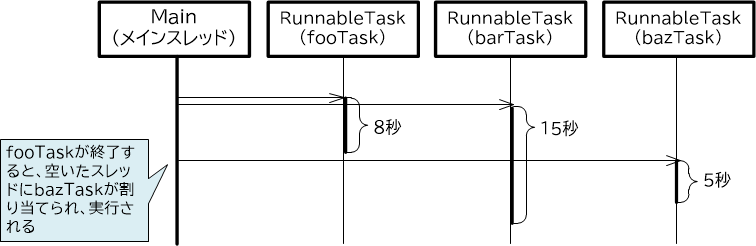
ここでは、スレッドプール内におけるスレッドの個数を、あえて2つにしています。メインスレッドのそれ以外の部分は、前項と同じコードになります。メインスレッドを実行すると2つのスレッドが固定的に生成され、まずfooTask(8秒かかる)、barTask(15秒かかる)が割り当てられて、並列に実行されます。当初bazTaskにはスレッドが割り当てられないため、しばらく待機します。約8秒後にfooTaskが終了してスレッドがプールに戻ると、空いたスレッドにbazTaskが割り当てられ、実行されます。
【図3-2-4】ExecutorServiceによるタスク実行(固定的なスレッドプール)
さて「固定的なスレッドプール」と前項の「動的なスレッドプール」を比較した場合、どちらに優位性があると一概に言うことはできません。
「動的なスレッドプール」の方が投入されるタスク数に応じて並列度が決まるため、柔軟性の面では優位です。その一方でスレッドの生成はリソースを消費するため、ある一定のリソース制約の中でスレッドプールを使いたい場合は「固定的なスレッドプール」の方が適していると言えます。
スレッドプールにおけるスレッドの生成方法には、固定的なものと動的なものがありますが、一概にどちらが優位とは言えません。トレードオフを理解した上で、適材適所で選択してください。
タスクの終了待機とシャットダウン
ExecutorServiceにひとたびタスクが投入されると、その後もExecutorServiceはタスクの投入を待ち続けます。ExecutorServiceを終了させるためには、shutdown()メソッド、またはshutdownNow()メソッドを呼び出す必要があります。shutdown()メソッドを呼び出すと新規タスクの投入はできなくなり、実行中のタスク終了を待ってから、ExecutorServiceが終了します。一方shutdownNow()メソッドを呼び出すと、直ちにExecutorServiceが終了します。
またshutdown()メソッドを呼び出し、実行中のタスクがなかなか終了しない場合、一定期間でタイムアウトさせ、shutdownNow()メソッドで強制的に終了させたい、というケースがあります。このようなケースでは、awaitTermination()メソッドを利用します。awaitTermination()メソッドは、実行中のすべてのスレッドの終了を指定された時間だけ待機し、終了しなかった場合にはfalseが返されます。具体的には、以下のようにします。
public class Main_Await {
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
RunnableTask fooTask = new RunnableTask("foo", 8);
RunnableTask barTask = new RunnableTask("bar", 15);
RunnableTask bazTask = new RunnableTask("baz", 5);
System.out.println("[ Main ] starting all threads...");
executor.submit(fooTask);
executor.submit(barTask);
executor.submit(bazTask);
System.out.println("[ Main ] shutdown");
executor.shutdown(); //【1】
try {
if (! executor.awaitTermination(12L, TimeUnit.SECONDS)) { //【2】
System.out.println("[ Main ] shutdown now");
executor.shutdownNow(); //【3】
}
} catch(InterruptedException ie) {
executor.shutdownNow();
}
System.out.println("[ Main ] finish");
}
}
まずshutdown()メソッドを呼び出し、新規タスクの受け付けを閉じます【1】。
次にif文の条件式の中でawaitTermination()メソッドを呼び出し、スレッドの終了を待機します【2】。
指定された時間(ここでは12秒)以内にすべてのスレッドが終了すればtrueが返されるため、処理はブロックに入りません。逆に指定された時間を超えた場合はfalseが返されるため、処理はブロック内に進み、shutdownNow()メソッドですべてのタスクが強制終了されます【3】。
3.2.3 ScheduledExecutorServiceの操作方法
ScheduledExecutorServiceのAPI
ScheduledExecutorServiceとは、ExecutorServiceの一環で、タスクの開始タイミングや実行間隔を、柔軟に調整することを可能にします。
ScheduledExecutorServiceインタフェースの主要なAPIには、以下のようなものがあります。
| API(メソッド) | 説明 |
|---|---|
| ScheduledFuture<?> schedule(Runnable, long, TimeUnit unit) | 指定された時間分遅延した上で、一回だけ実行されるタスク(Runnable)を投入する。 |
| ScheduledFuture<V> schedule(Callable<V>, long, TimeUnit) | 指定された時間分遅延した上で、一回だけ実行されるタスク(Callable)を投入する。 |
| ScheduledFuture<?> scheduleAtFixedRate(Runnable, long, long, TimeUnit) |
指定された時間分遅延した上で、繰り返し実行されるタスク(Runnable)を投入する。タスクの実行は、なるべく指定されたピリオド(期間)に収まるように調整される。 |
| ScheduledFuture<?> scheduleWithFixedDelay(Runnable, long, long , TimeUnit) |
指定された時間分遅延した上で、繰り返し実行されるタスク(Runnable)を投入する。タスクは一度終了すると、次回まで、指定された時間分の間隔が設けられる。 |
次にScheduledExecutorServiceのインスタンスを生成する方法です。ScheduledExecutorServiceのインスタンスもExecutorServiceと同様に、Executorsクラスから取得します。以下にそのAPIを示します。
| API(メソッド) | 説明 |
|---|---|
| static ScheduledExecutorService newSingleThreadScheduledExecutor() | 単一のスレッドによるScheduledExecutorServiceを返す |
| static ScheduledExecutorService newScheduledThreadPool(int) | 指定された個数のスレッドを持つ固定長のプールを作り、そのスレッドをタスクに割り当てるためのScheduledExecutorServiceを返す |
ScheduledExecutorServiceによるタスク実行(1)~実行フレームの自動調整
ScheduledExecutorServiceのscheduleAtFixedRate()メソッドは、実行時間にばらつきのある1つのタスクを、なるべく指定されたピリオド(期間)に収まるように間隔を調整しながら、繰り返し実行するためのものです。例えば、以下のようにこのメソッドを呼び出すものとします。
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
RunnableTask2 task = new RunnableTask2();
executor.scheduleAtFixedRate(task, 2L, 10L, TimeUnit.SECONDS);
scheduleAtFixedRate()メソッドは、第1引数が投入されるタスク、第2引数が開始までの遅延時間、第3引数がピリオドを表します。ここでは10秒というピリオドが指定されているため、仮に1回目のタスクが7秒で終わったとしたら、2回目のタスクは3秒待ってから実行されます。2回目のタスクが14秒かかってしまったら、2回目終了の基準時間である20秒(10秒*2)を超過しているため、3回目のタスクは即時に実行されます。そして、3回目のタスクが4秒で終わったら、3回目終了の基準時間である30秒(10秒*3)を2秒下回っているため、4回目のタスクは2秒待ってから実行されます。
【図3-2-5】ScheduledExecutorServiceのscheduleAtFixedRate()メソッド

ScheduledExecutorServiceによるタスク実行(2)~実行間隔の自動調整
ScheduledExecutorServiceのscheduleWithFixedDelay()メソッドは、タスクの終了から次回開始まで、一定の間隔を空けて、繰り返しタスクを実行するためのものです。例えば、以下のようにこのメソッドを呼び出すものとします。
ScheduledExecutorService executor = Executors.newScheduledThreadPool(1);
RunnableTask task = new RunnableTask();
executor.scheduleWithFixedDelay(task, 2L, 5L, TimeUnit.SECONDS);
scheduleWithFixedDelay()メソッドは、第一引数が投入されるタスク、第二引数が開始までの遅延時間、第三引数が間隔を表します。ここでは5秒というピリオドが指定されているため、1回目のタスクが終了後、5秒の間隔を空けて2回目のタスクが開始され、2回目のタスクが終了後、5秒の間隔を空けて3回目のタスクが開始されます。
【図3-2-6】ScheduledExecutorServiceのscheduleWithFixedDelay()メソッド

3.2.4 FutureとCallable
Futureインタフェースの特徴とAPI
Executorフレームワークでは、非同期に起動したスレッドの実行結果を、後から戻り値として受け取ることができます。
この機能を実現するための仕組みが、FutureインタフェースとCallableインタフェースです。まずFuture(java.util.concurrent.Future)とは、スレッドの実行結果を後から受け取るためのインタフェースです。Futureは、ExecutorServiceのsubmit()メソッドの戻り値として即座に返されます。
Futureインタフェースの主要なAPIには、以下のようなものがあります。
| API(メソッド) | 説明 |
|---|---|
| V get() | タスクが完了するまで待機し、その実行結果を返す。待機中に割り込みが発生するとInterruptedExceptionが発生する。またタスクの実行中に例外が発生すると、ExecutionExceptionにラップされて送出される。 |
| V get(long, TimeUnit) | get()と同じだが、指定された時間を超えるとタイムアウトが発生し、TimeOutExceptionが送出される。 |
| boolean isDone() | タスクが完了した場合にtrueを返す。 |
| boolean cancel(boolean) | タスクの実行を取り消す。 |
| boolean isCancelled() | タスクが取り消された場合にtrueを返す。 |
RunnableタスクとFutureインタフェース
既出のとおりExecutorServiceのsubmit()メソッドには、Runnableインタフェースを実装したタスクと、Callableインタフェースを実装したタスクを指定することができますが、まずは前者(Runnable)を指定した場合の挙動について説明します。以下のコードを見てください。
try {
Future<?> fooFuture = executor.submit(fooTask); //【1】Runnableタスクを投入
fooFuture.get(); //【2】
System.out.println("[ Main ] foo finish ");
doSomething(5); // 5秒間、何らかの処理を行う
System.out.println("[ Main ] finish");
} catch(InterruptedException | ExecutionException ex) {
throw new RuntimeException(ex);
}
submit()メソッドにRunnableを指定した場合の戻り値は、Future<?>です【1】。この<?>は総称型のワイルドカードと呼ばれているもので、詳細はチャプター7.1で説明しますが、現時点では「任意の型を格納するためのFuture」と理解しておけば問題ありません。
次に取得したFutureインタフェースのget()メソッドを呼び出すと、非同期に起動したタスクの実行結果を受け取ることができます【2】。ただしRunnableインタフェースを実装したタスクは、run()メソッドは戻り値をvoid型のため、そもそも結果を返すことができません。従ってget()メソッド呼び出しの結果は、null値になります。
ではこのメソッドには意味がないのかというと、そんなことはありません。get()メソッド呼び出しにより、タスクの実行が終わるまで処理がブロックされます。タスクが終了するとget()メソッドにnull値が返され、後続に処理が進みます。つまりこのメソッドは、Executorフレームワークにおいて、非同期に起動されたRunnableタスクの終了を起動元で待ち合わるために使用します。
Callableインタフェースの特徴とAPI
Callableインタフェース(java.util.concurrent.Callable)は、Runnableインタフェースと同様に、非同期に起動するためのタスクを表すものです。ただしCallableはRunnableとは異なり、任意の型で結果を返したり、任意の例外を送出することができる点が大きな特徴です。Callableインタフェースによるタスクは、class CallableTask implements Callable<Integer> { .... }といった具合にクラス宣言します。
Callableインタフェースには唯一call()メソッドが定義されており、その宣言は以下のとおりです。
- V call() throws Exception
Vは受け取る実行結果を表す型パラメータで、Callable<Integer>と宣言した場合はInteger型になります。
CallableタスクとFutureインタフェース
それでは、CallableインタフェースとFutureインタフェースを用いた処理を具体的に見ていきましょう。まずCallableインタフェースによるタスクのコードを、次に示します。
public class CallableTask implements Callable<Integer> { //【1】
private String name; // 名前
private int count; // カウント
public CallableTask(String name, int count) {
this.name = name;
this.count = count;
}
@Override
public Integer call() throws Exception { //【2】
long threadId = Thread.currentThread().getId(); // スレッドID
System.out.println("[ CallableTask = " + name + " ] start, "
+ "threadId => " + threadId);
int value = 1;
for (int i = 0; i < count; i++) { // カウント分ループする
System.out.println("[ CallableTask = " + name + " ] processing...");
value = value * 3; // 値を3倍する
sleepAWhile(1000); // 意図的に1秒停止する
}
System.out.println("[ CallableTask = " + name + " ] finish, "
+ "value => " + value);
return value; //【3】実行結果を返す
}
}
このようにタスクは、java.lang.Callableインタフェースをimplementsして作成します【1】。
タスクの中身はcall()メソッドをオーバーライドして実装しますが、【1】におけるCallable<Integer>と連動する形で、戻り値はInteger型を返すように宣言します【2】。
具体的な処理は既出のRunnableTaskクラスと同様ですが、最後に実行結果を返している点【3】が異なります。
次にこのタスクを非同期に起動し、結果を受け取るためのコードを示します。
ExecutorService executor = Executors.newSingleThreadExecutor();
CallableTask task = new CallableTask("foo", 8);
try {
System.out.println("[ Main ] starting task...");
Future<Integer> future = executor.submit(task); //【1】
Integer result = future.get(); //【2】
System.out.println("result => " + result);
System.out.println("[ Main ] finish");
} catch(InterruptedException | ExecutionException ex) { //【3】
throw new RuntimeException(ex);
}
タスクのインスタンスを生成したら、ExecutorServiceのsubmit()メソッドに渡すと、渡されたタスクが非同期に起動され、即座にFutureが返されます【1】。
次にFutureのget()メソッドを呼び出すと、起動したタスクの終了を待機し、その実行結果を受け取ることができます【2】。
なおget()メソッド呼び出しでは、InterruptedExceptionとExecutionExceptionという2つのチェック例外が送出されるため、例外ハンドリングが必要です【3】。InterruptedExceptionは、タスク実行中に割り込みが発生した場合に送出されます。またcall()メソッドは任意の例外を送出することができますが、送出された例外はExecutionExceptionにラップされます。
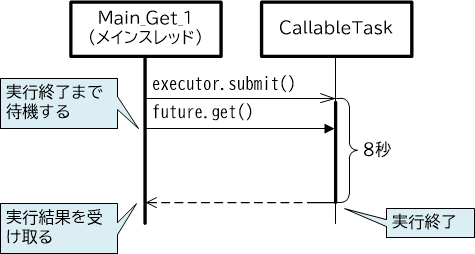
【図3-2-7】Callableによる非同期タスクの起動
なおタスクは、Callableをimplementsしたクラスとして個別に作成するのではなく、インナークラスやラムダ式(チャプター4.1参照)に実装することもできます。ラムダ式を使うと以下のようなコードになります。
String name = "foo"; // 名前
int count = 8; // カウント
try {
System.out.println("[ Main ] starting task...");
Future<Integer> future = executor.submit(() -> {
long threadId = Thread.currentThread().getId(); // スレッドID
// 既出のコードと同じ
........
return value; // 実行結果を返す
});
Integer result = future.get();
System.out.println("result => " + result);
System.out.println("[ Main ] finish");
} catch(InterruptedException | ExecutionException ex) {
throw new RuntimeException(ex);
}
Callableを利用したタスクの並列実行
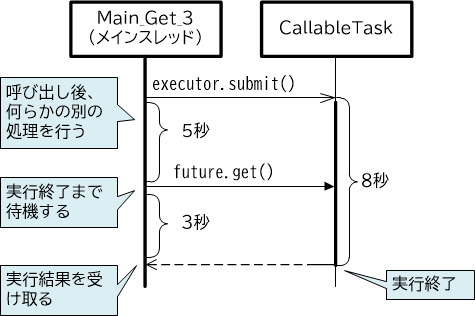
前項の例ではタスクを非同期に起動した後、直ちにget()メソッドを呼び、タスクの実行を待機しました。get()メソッドを呼び出すまでの間に、別の処理を並列して行うことが可能です。以下は、非同期タスクを実行するメインスレッドのコードです。
Future<Integer> future = executor.submit(task); //【1】8秒かかる処理を起動
doSomething(5); //【2】5秒間、何らかの処理を行う
Integer result = future.get(); //【3】待機してから結果を取得する(3秒待機)
まず非同期にタスクを起動【1】しますが、この処理には8秒を要するものとします。
続いてget()メソッドを呼び出すまでの間に、5秒間程度、別の何らかの処理を行います【2】。
get()メソッドでは待機が発生しますが、非同期タスクは8秒で終了するため、3秒間の待機の後に実行結果を取得します【3】。
【図3-2-8】Callableを利用したタスクの並列実行
完了待機のタイムアウト
非同期に起動したタスクの処理が長時間化する可能性がある場合、その完了を待たずにタイムアウトさせることができます。以下は、非同期タスクを実行するメインスレッドのコードです。
Future<Integer> future = executor.submit(task); //【1】8秒かかる処理を起動
Integer result = future.get(4, TimeUnit.SECONDS); //【2】4秒でタイムアウト
まず非同期にタスクを起動【1】しますが、この処理には8秒を要するものとします。
次にget()メソッドを呼び出しますが、このメソッドは、引数としてタイムアウト時間を指定(このコードでは4秒)することができます【2】。非同期タスクは8秒を要するため、4秒経過した時点で、実行結果を受け取ることなくタイムアウトします。このときjava.util.concurrent.TimeoutExceptionが発生し、処理が中断されます。なおメインスレッド側では処理が中断されますが、非同期タスク側の処理は継続されます。
Callableを利用したタスクの完了待機
同じようにFutureのisDone()メソッドを利用すると、さらに効率的に並列処理を行うことが可能です。
ExecutorService executor = Executors.newSingleThreadExecutor();
CallableTask task = new CallableTask("foo", 8);
try {
System.out.println("[ Main ] starting task...");
Future<Integer> future = executor.submit(task);
while (! future.isDone()) { //【1】
System.out.println("[ Main ] do something..."); // 何か別の処理を行う
sleepAWhile(1000);
}
Integer result = future.get(); //【2】
System.out.println("result => " + result);
System.out.println("[ Main ] finish");
} catch (InterruptedException | ExecutionException ex) {
throw new RuntimeException(ex);
}
FutureのisDone()メソッドを呼び出すと、タスクが完了した場合にtrueが返ります。従ってwhile文の条件式に! future.isDone()と指定すると、起動したタスクが終了するまで繰り返されるループを実装することが可能です【1】。
そしてタスクが終了しループを抜けたらget()メソッドを呼び出します【2】が、この時点ではすでにタスクが終了してため、待機することなく直ちに実行結果を受け取ることができます。
3.2.5 CallableとFutureによる一括処理
Callableタスクの一括起動と待ち合わせ
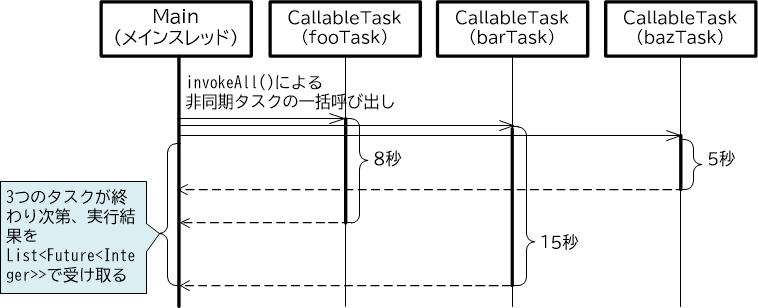
ExecutorServiceクラスのinvokeAll()メソッドを使用すると、複数のCallableタスクを一括で起動し、すべての終了を待機した後、実行結果を含むFutureのリストを受け取ることができます。具体的には、以下のコードを見てください。
public class Main {
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
CallableTask fooTask = new CallableTask("foo", 8);
CallableTask barTask = new CallableTask("bar", 15);
CallableTask bazTask = new CallableTask("baz", 5);
List<CallableTask> taskList = new ArrayList<CallableTask>(); //【1】
taskList.add(fooTask);
taskList.add(barTask);
taskList.add(bazTask);
try {
System.out.println("[ Main ] starting all tasks...");
List<Future<Integer>> futureList = executor.invokeAll(taskList); //【2】
for (Future<Integer> future : futureList) { //【3】
Integer result = future.get();
System.out.println("result => " + result);
}
System.out.println("[ Main ] finish");
} catch(InterruptedException | ExecutionException ex) {
throw new RuntimeException(ex);
}
executor.shutdown();
}
}
まず、複数のCallableタスクを格納するためのリスト(変数taskList)を作ります【1】。
そして変数taskListを引数に指定してinvokeAll()メソッドを呼び出すと、リストに格納されたタスクが一括で起動され、すべてが終了するまで待機します【2】。このCallableタスクの戻り値はInteger型なので、個々のタスクの実行結果はFuture<Integer>型となり、それらを一括で受け取るため、invokeAll()メソッドの戻り値はList<Future<Integer>>型になります。
受け取ったFutureのリストに対して、このコードではfor文によるループ処理を行い、個々の結果をコンソールに表示しています。
これをシーケンス図に表すと、以下の図のようになります。3つのCallableタスク(fooTask、barTask、bazTask)を一括で起動し、すべてのタスクが終了するまで待機し、そしてすべてのタスクが終了したらその実行結果を一括で受け取る、というわけです。
【図3-2-9】invokeAll()メソッドによる非同期タスクの一括起動
コレクションの分割処理
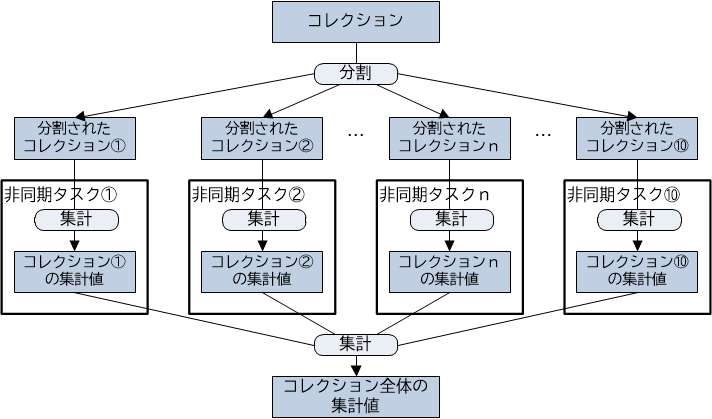
invokeAll()メソッドの主な用途の1つに、コレクションの分割処理があります。巨大なコレクションに対して何らかの集計処理を行いたい場合、コレクションを分割し、それぞれの集計を複数のタスクで分担することで、スループットを高めることができます。
ここでは1から10万までの数値が格納されたリストに対し、すべての値を合計する処理を考えてみましょう。リストを分割し、並列度10として、各リストを10個のCallableなタスクに分散して集計するものとします。
まずリストの集計を行うCallableなタスク(SumTaskクラス)のコードを、以下に示します。
public class SumTask implements Callable<Integer> {
private List<Integer> intList;
public SumTask(List<Integer> intList) {
this.intList = intList;
}
@Override
public Integer call() throws Exception {
int result = 0;
for (int value : intList) {
result += value;
}
return result;
}
}
このタスクは、リストに格納された個々の値をfor文のループによって足し込み、合計値を返すというシンプルな処理を行っています。
次に、このタスクを並列で起動するメインスレッドです。
public class Main {
public static void main(String[] args) {
//【1】1から10万までのInteger型リストを作る
List<Integer> intList = new ArrayList<>();
for (int i = 0; i < 100_000_000; i++) {
intList.add(i + 1);
}
//【2】並列度を10と設定し、リストを10個に分割する
int paraCount = 10;
List<List<Integer>> splitedListList =
splitIntegerList(intList, paraCount); // リスト分割のためのユーティリティ
//【3】分割された個々のリストを担当するSumTaskを作り、リストに格納する
List<Callable<Integer>> taskList = new ArrayList<>();
for (List<Integer> splitedList : splitedListList) {
taskList.add(new SumTask(splitedList));
}
//【4】invokeAllで10個のタスクを同時に起動して待機する
ExecutorService executor = Executors.newFixedThreadPool(paraCount);
try {
List<Future<Integer>> futureList = executor.invokeAll(taskList);
//【5】10個のタスクがすべて終了したら、それぞれの結果を集計する
int sum = 0;
for (Future<Integer> future : futureList) {
sum += future.get();
}
System.out.println("sum => " + sum);
} catch(InterruptedException | ExecutionException ex) {
throw new RuntimeException(ex);
}
executor.shutdown();
}
}
まず【1】のように、1から10万までの数値を格納するためのリストを作ります。
次にこのリストを自作のユーティリティによって、並列度である10に分割します【2】。
そして分割された個々のリストを処理するための10個のSumTaskを作り、それをリスト(変数taskList)に格納します【3】。
これで準備が整いました。この変数taskListを引数に指定して、invokeAll()メソッドを呼び出します【4】。すると10個のタスクが並列に処理され、すべてが終了すると、個々のタスクの実行結果を含むFutureのリストが返されます。
最後に【5】で、Futureのリストから取り出した値を集計することで、1から10万までの数値の合計値を算出しています。
【図3-2-10】コレクションの分割処理
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- 並行処理ユーティリティとExecutorフレームワークの概要について。
- ExecutorServiceクラスの特徴やAPIについて。
- ScheduledExecutorServiceクラスの特徴やAPIについて。
- Futureインタフェースの特徴やAPIについて。
- CallableとFutureによる非同期タスクの完了待機方法について。
- Callableタスクの一括起動と待ち合わせ方法について。
- Callableによるコレクションの分割処理について。