はじめに
自己紹介
皆さん、こんにちは、Udemy講師の斉藤賢哉です。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Basic編』の一部の範囲をカバーしたものです。『Java Basic編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをQiita内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの言語仕様や文法を正しく理解すると同時に、現場での実践的なスキル習得を目指している方
- 新卒でIT企業に入社、またはIT部門に配属になった、新米システムエンジニアの方
- 長年IT部門で活躍されてきた中堅層の方で、学び直し(リスキル)に挑戦しようとしている方
- 今後、フリーランスエンジニアとしてのキャリアを検討している方
- 「Chat GPT」のエンジニアリングへの活用に興味のある方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
- IT企業やIT部門の教育研修部門において、新人研修やリスキルのためのオンライン教材をお探しの方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
19.1 例外処理の基本
チャプターの概要
このチャプターでは、Java言語においてエラーを表す概念である例外と、例外をハンドリングするための仕組みについて学びます。
19.1.1 例外とは
例外とは
Javaはコンパイル型言語のため、文法や変数の型に不具合があるとコンパイラによって検出されますが、実行したときに初めて検出される類のエラーがあります。このように、Javaプログラム実行中に発生するエラーのことを「例外」と呼びます。
Javaでは、例外はプログラムを構成する要素の1つとしてクラスで表現します。例外という概念がない古典的なプログラミング言語では、エラーが発生した場合、その種類を表すために「エラーコード」を用いていましたが、Javaではエラーの種類は例外クラスによって表します。
例外の様々なパターン
一口に例外といっても様々なパターンがあります。
- プログラム不良に起因する例外
null参照やゼロ除算のようなシステム的な例外のことです。これらの例外は不具合の一種なので、プログラムを修正する必要があります。 - 環境に起因する例外
サーバやネットワークといったシステム基盤に起因する例外や、読み込もうとしたファイルが存在しないといった類の例外のことです。これらは、プログラム不良ではありませんが、そういったケースを想定した上で適切な措置が必要です。 - 業務に起因する例外
業務に起因する例外には、想定するものと想定しえないものがあります。例えば「残高不足により引き落としができないエラー」は発生に備えて対応が必要なエラーですが、「存在するはずのマスターデータがないエラー」は業務上想定しえないものなので対応は必須ではありません。
このように例外には様々なパターンがあり、その特性に応じた適切な対応が必要です。
例外ハンドリングとは
例外が発生すると処理は中断され、プログラムは停止してしまいます。発生した例外は放置するのではなく、適切に対処することで、ログを出力したり、トランザクションをロールバックしたり、業務的なリカバリーを行ったりする必要があります。このように発生した例外に対して何らかの措置を施すことを、本コースでは「例外ハンドリング」と呼びます。
本コースにおける例外クラス
ここでは、これまでのレッスンの中で取り上げたものも含めて、本コースで登場する例外クラスを、まとめて掲載します。
これらはいずれも、Java SEのクラスライブラリによって提供されるものです。
| 例外クラス | 説明 |
|---|---|
| java.lang.ArithmeticException | ゼロ除算等、算術演算における不具合(チャプター4.1、17.1) |
| java.lang.ArrayIndexOutOfBoundsException | 配列の範囲を超えたインデックス指定(チャプター5.1) |
| java.lang.NullPointerException | null値を持つ変数へのアクセス(チャプター5.2) |
| java.lang.ClassCastException | 互換性のない型へのキャスト(チャプター11.1) |
| java.lang.CloneNotSupportedException | cloneメソッド対象クラスがClonableインタフェースを未実装(チャプター13.1) |
| java.lang.NumberFormatException | ラッパークラスのparse〇〇()メソッド等で文字列を解析できない場合など(チャプター17.1) |
| java.util.ConcurrentModificationException | 拡張for文によるリスト変更など並行処理によるデータ書き換え(チャプター18.1) |
| java.text.ParseException | SimpleDateFormatクラスのparseメソッドで日時文字列を解析できない場合など(チャプター20.1) |
| java.time.format.DateTimeParseException | LocalDateTimeクラスのparseメソッドで日時文字列を解析できない場合など(チャプター20.2) |
なお本コースでは、これらの例外を「Java SE例外」と呼称します。
try-catch文による例外ハンドリング
Javaには、例外の発生を検出し、検出した例外をハンドリングするための仕組みが、言語仕様として備わっています。このような例外ハンドリングを実現するためには、try-catch文を使用します。
try-catch文の構文は以下のとおりです。
try {
....例外が発生する可能性のある処理....
} catch (例外クラス1 変数1) {
....例外クラス1発生時の処理....
} catch (例外クラス2 変数2) {
....例外クラス2発生時の処理....
}
....catchブロックを必要な分だけ記述....
}
try-catch文は、1つのtryブロックと、複数のcatchブロックから構成されます。
まずtryブロックは、tryキーワードの後ろのブロックに、例外が発生する可能性のある処理を記述します。tryブロックの中で何らかの例外が発生すると、ブロック内の処理はその時点で中断され、catchブロックへと進みます。tryブロック内で条件分岐やループをしたり、return文を記述することも可能です。
次にcatchブロックです。catchキーワードの後ろに( )を記述し、そのブロックが対応する例外クラスと、例外オブジェクトを格納するための変数を指定します。tryブロック内でいくつかの種類の例外が発生する可能性がある場合は、その種類に合わせてcatchブロックを複数記述することができます。複数のcatchブロックが記述されている場合、上から順に発生した例外クラスとcatchブロックに指定した例外クラスのマッチングが行われ、マッチしたブロックに処理進みます。例えばtryブロック内でArithmeticException例外が発生した場合は、catch (ArithmeticException)と記述したブロックが選択されます。なおこのようにcatchブロックによって特定の例外を捉えることを、「例外を捕捉する」と言います。catchブロックでは、捕捉した例外のオブジェクトが変数として渡されるので、その変数を利用して適切なハンドリングを行います。
例外クラスの種類と分類
例外クラスの階層構造は、大まかに以下の図のようになっています。
【図19-1-1】例外クラスの階層構造
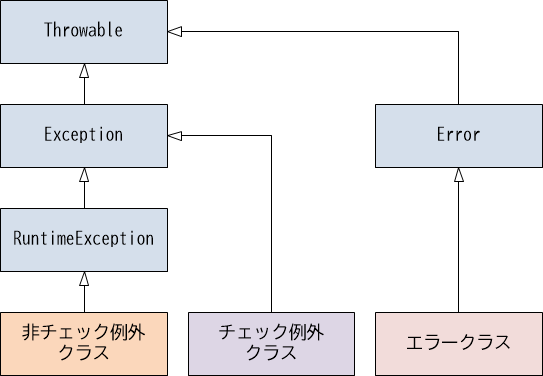
この中で最上位に位置するのがjava.lang.Throwableであり、あらゆる例外クラスの親になります。
例外クラスは以下のように分類されます。
- エラークラス
- 例外クラス
2.1 非チェック例外クラス
2.2 チェック例外クラス
エラークラス
まずエラークラスとは、メモリ不足など環境に起因する致命的な不具合を表す例外です。階層構造的には、java.lang.Errorの子クラスに当たります。通常これらの例外が発生した場合、プログラムでの復旧は困難であり、JVMが強制終了されることも多いため、try-catch文による例外ハンドリングは行いません。
例外クラス
次に例外クラスですが、非チェック例外とチェック例外の2つに分類されます。非チェック例外は非検査例外、チェック例外は検査例外とも呼ばれます。
非チェック例外
非チェック例外とは、try-catch文による例外ハンドリングが任意の例外です。階層構造的には、java.lang.RuntimeExceptionの子クラスに当たります。これまで登場してきたNullPointerExceptionなどの例外クラスは、いずれも非チェック例外に分類されます。
チェック例外
チェック例外とは、try-catch文による例外ハンドリングがコンパイラによって強制される例外です。階層構造的には、java.lang.Exceptionの子クラス(ただしRuntimeExceptionの子クラスを除く)に当たります。チェック例外の大半がファイル入出力、ネットワーク入出力、データベースアクセスなど、システム基盤や環境に起因する例外です。この類の例外に関する詳細は別コースにて取り上げますが、いずれにしてもチェック例外の目的は、発生の可能性がある問題に対して、その適切なハンドリングを強制するために使用します。
例外クラスのAPI
例外クラスの最上位に位置するjava.lang.Throwableには、以下のようなAPIが定義されています。
| API(メソッド) | 説明 |
|---|---|
| String getMessage() | メッセージを取得する |
| Throwable getCause() | 根本原因を取得する |
| void printStackTrace() | スタックトレースを(標準出力に)出力する |
あらゆる例外クラスは、これらのAPIを保持しています。
catchブロックで例外を捕捉したら、これらのAPIを呼び出すことによって、様々な処理を行うことができます。中でもデバッグを容易にするために、例外クラスが持つメッセージを取得したり、スタックトレースを出力したりする処理は、高い頻度で登場します。なお根本原因やスタックトレースついては、詳細は次のレッスン以降で説明します。
19.1.2 例外発生時の挙動と例外ハンドリング
例外発生時の挙動
このレッスンでは、例外発生時の具体的な挙動について見ていきましょう。ここでは非チェック例外を前提に説明します。前述したように非チェック例外の場合は、例外ハンドリングを実施してもしなくても、どちらでも構いません。
以下のコードは、例外ハンドリングを行わないケースです。
public class Main_1 {
public static void main(String[] args) {
int val1 = Integer.parseInt(args[0]); // 第1引数をint型に変換
int val2 = Integer.parseInt(args[1]); // 第2引数をint型に変換
int answer = val1 / val2; //【1】除算→例外発生の可能性
System.out.println(answer); // 答えを表示
}
}
このメインクラスは2つのコマンドライン引数をint型に変換した後、それらの除算を行い、答えをコンソールに表示します。このコードの第2引数に0を与えて実行すると、ゼロ除算【1】によってArithmeticException例外が発生して処理が中断されるため、コンソールには答えは表示されません。
例外ハンドリングの挙動
ここでは例外の挙動を確認するために、ゼロ除算によって例外を発生させ、そのハンドリングを行うケースを取り上げます。
前項のコード(Main_1クラス)にtry-catch文を追加すると、以下のようなコードになります。
public class Main_2 {
public static void main(String[] args) {
int val1 = Integer.parseInt(args[0]); // 第1引数をint型に変換
int val2 = Integer.parseInt(args[1]); // 第2引数をint型に変換
try { //【1】
int answer = val1 / val2; //【2】除算→例外発生の可能性
System.out.println(answer);
} catch (ArithmeticException ae) { //【3】
System.out.println("ゼロ除算発生, msg => " + ae.getMessage()); //【4】
}
}
}
このようにtryブロック【1】の中に、例外が発生する可能性のある処理を記述します。ゼロ除算が行われると【2】ArithmeticException例外が発生し、処理が中断されて対応するcatchブロック【3】に処理が進みます。catchブロックでは、ArithmeticExceptionのオブジェクトが変数aeに格納されて渡されるため、変数aeからメッセージを取得し、それをコンソールに表示しています【4】。
【図19-1-2】例外ハンドリングの挙動

このコードの第2引数に0を与えて実行すると、以下のようなテキストがコンソールに表示されます。
ゼロ除算発生, msg => / by zero
なおここでは便宜上ArithmeticExceptionをハンドリングする例を取り上げましたが、ゼロ除算に対応するための正しい方法は、除算を行う前にif文でチェックする、というものです。NullPointerExceptionについても同様で、null値の可能性がある変数にアクセスする場合は、例外ハンドリングではなくif文によるnullチェックを行います。つまりArithmeticExceptionやNullPointerExceptionは、例外としてハンドリングするべきものというよりは、プログラムの不具合に起因して発生してしまうもの、と考えるのが良いでしょう。
19.1.3 例外の生成と送出
例外生成と送出のパターン別挙動
ここでは例外の生成や送出を、パターン別に説明します。
例外クラスを「誰が提供するものか」という観点で分類すると、Java SE例外(Java SEのクラスライブラリとして提供される例外)と、ユーザー定義例外(開発者自身が作成する例外)に分けられます。Java SE例外発生のパターンには、これまで見てきたように(ゼロ除算など)Javaランタイム内の処理で発生するケースもあれば、開発者がJava SE例外を明示的に生成して発生させるケースもあります。ユーザー定義例外については次のチャプターで説明しますが、開発者自身が例外を生成し発生させます。
つまりパターンを整理すると、以下のようになります。
- パターン1:Javaランタイム内の処理で、Java SE例外が発生する
- パターン2:開発者が明示的にJava SE例外を生成し、送出する
- パターン3:開発者がユーザー定義例外を生成し、送出する
このように例外を明示的に発生させることを「送出する」と言います。
パターン2や3では、通常のクラスと同じように、new演算子によって例外クラスのオブジェクトを生成します。このとき例外クラスのコンストラクタが呼び出されます。例外クラスのコンストラクタはクラスの種類によってまちまちですが、最上位のjava.lang.Throwableと同じコンストラクタを定義し、superキーワードによって呼び出すケースが一般的です。Throwableクラスにはメッセージ、根本原因という2つの属性があり、それらを初期化するために以下のようなコンストラクタが用意されています。
- Throwable(String) … メッセージを初期化する
- Throwable(Throwable) … 根本原因を初期化する
- Throwable(String, Throwable) … メッセージと根本原因を初期化する
パターン2や3では、これらのコンストラクタによって例外を生成したら、その例外を送出します。
例外を送出するためには、以下の構文のようにします。
throw 例外オブジェクト
このようにthrowキーワードに例外オブジェクトを指定することによって、例外を送出します。
例外生成と送出の具体例
前項におけるパターン2、すなわち開発者が明示的にJava SE例外を生成し送出するケースを具体例で説明します。
以下のコードを見てください。
public class Main {
public static void main(String[] args) {
int param = Integer.parseInt(args[0]); // 第1引数をint型に変換
if (param < 0) { // 引数が0未満のときに例外を送出
throw new IllegalArgumentException("引数が0未満"); //【1】
}
int answer = param * 2;
System.out.println(answer);
}
}
このメインクラスは、コマンドライン引数が0未満だった場合に明示的にIllegalArgumentExceptionのオブジェクトを生成し、送出しています【1】。IllegalArgumentExceptionは「引数が不正」という意味を表すJava SE例外です。IllegalArgumentExceptionには、Exceptionクラスと同じくメッセージを引数にとるコンストラクタが定義されているため、それを呼び出してオブジェクトを生成しています。そして生成したオブジェクトを、throwキーワードに指定して送出します。このクラスに0未満の値を引数に与えて実行すると、IllegalArgumentExceptionが発生し、処理が異常終了します。
19.1.4 例外の伝播とハンドリング
例外の伝播
例外が発生すると、その例外は呼び出し元へ、さらにはその呼び出し元へと伝播していきます。ここでは、例外の伝播の挙動を具体例に基づいて見ていきましょう。
以下のようにMain、Foo、Barという3つのクラスを作成します。
public class Main {
public static void main(String[] args) {
Foo foo = new Foo();
int length = foo.process(args[0]); //【1】
System.out.println(length); //【2】
}
}
public class Foo {
public int process(String param) {
Bar bar = new Bar();
int length = bar.process(param); //【3】
return length; //【4】
}
}
public class Bar {
public int process(String param) {
int length = param.length();
if (10 < length) {
throw new IllegalArgumentException("文字列長が過大"); //【5】
}
return length; //【6】
}
}
処理の流れとしては、Mainクラスのコマンドライン引数をMain→Foo→Barへと順に渡し、Barクラスで文字列長を計算して返す、というシンプルなものです。
ここでMainクラスに10文字超の文字列を引数に与えて実行すると、どのような挙動になるでしょうか。まずMainクラスから、Fooクラスのprocess()メソッドが呼び出され、続いてBarクラスのprocess()メソッドが呼び出されます。Barクラスのprocess()メソッドでは渡された引数が10文字超なので、IllegalArgumentExceptionのオブジェクトが生成され、送出されます【5】。ここでこのメソッドの処理は中断されるため、後続の処理【6】は実行されません。
例外は呼び出し元であるFooクラスのprocess()メソッド【3】に伝播します。ここでもメソッドの処理は中断されるため、後続の処理【4】は実行されません。さらに例外は呼び出し元であるMainクラスのmain()メソッド【1】に伝播します。やはりここでもメソッドの処理は中断されるため、後続の処理【2】は実行されず、プログラムが異常終了します。
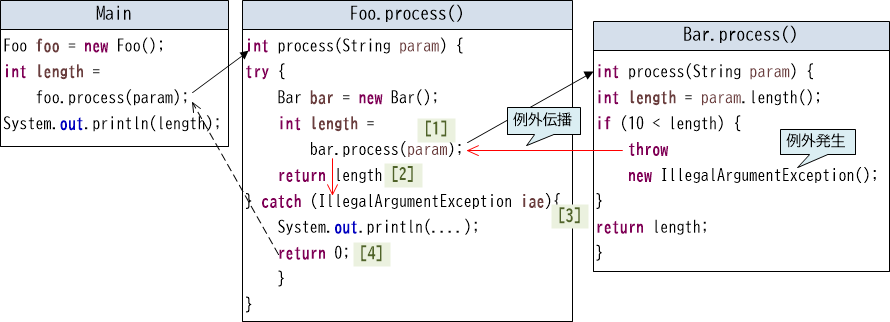
このときのMain、Foo、Barにおける例外の挙動を図に表すと、以下のようになります。
【図19-1-3】例外の伝播

伝播中の例外ハンドリング
伝播中の例外はtry-catch文によって捕捉することができます。
前項のFooクラスにtry-catch文を追加し、以下のように修正します。
public class Foo {
public int process(String param) {
try {
Bar bar = new Bar();
int length = bar.process(param); //【1】
return length; //【2】
} catch (IllegalArgumentException iae) { //【3】
System.out.println("計算不可, msg => " + iae.getMessage());
return 0; //【4】
}
}
}
Bar呼び出し【1】で例外が発生してこのクラスに伝播されると、後続の処理【2】は行われず、catchブロック【3】へと処理が進みます。catchブロックでは例外を捕捉したらその内容を表示し、リカバリーの措置として0を返すように実装しています【4】。このtry-catch文によって、Mainクラスには例外は伝播されなくなります。
このときのMain、Foo、Barにおける例外の挙動を図に表すと、以下のようになります。
【図19-1-4】例外の伝播
チェック例外の送出とthrows句
前項までは非チェック例外のケースを見てきましたが、ここではチェック例外の送出について取り上げます。
チェック例外の目的は、前述したように発生の可能性がある問題に対して、その適切なハンドリングを強制することにあります。従ってメソッド内の処理において、例えば外部的な問題に起因して例外が発生する可能性がある場合は、チェック例外を送出し呼び出し元に例外ハンドリングを強制します。
チェック例外を送出する場合、メソッドは以下のように宣言します。
戻り値型 メソッド名(....) throws 例外クラス {
....チェック例外が送出される処理....
}
これは呼び出し元から見ると「throws句があるメソッドを呼び出す場合は、送出される例外を自身でハンドリングしなければならない」ということを意味します。
なおthrows句には、例外クラスをカンマで区切って複数指定することができます。その場合呼び出し元では、指定された複数の例外クラスを(catchブロックを列挙するなどして)ハンドリングしなければなりません。
またthrows句に非チェック例外を指定することも可能ですが、このような記述をする必然性はなく、指定されたとしても呼び出し元での例外ハンドリングはあくまでも任意です。
チェック例外ハンドリングの具体例
それではチェック例外がどのように送出され、ハンドリングされるのか、具体的な挙動を見ていきましょう。
既出のBarクラスを修正し、引数から生成されたURLの文字列長を返すようにします。具体的には以下のようなコードになります。
public class Bar {
public int process(String param) {
try {
URL url = new URL(param); //【1】
return url.toString().length();
} catch (MalformedURLException mue) { //【2】
System.out.println("URL生成不可, msg => " + mue.getMessage());
return 0; //【3】
}
}
}
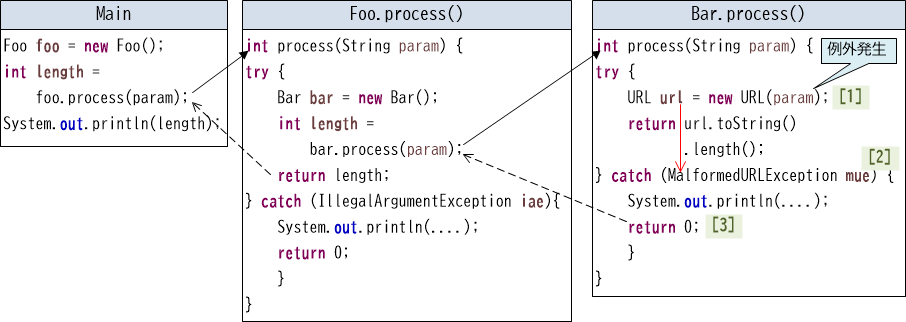
ここではまずURLクラス(java.net.URL)を使い、文字列からURLを生成します【1】。URLクラスのコンストラクタはURL(String) throws MalformedURLExceptionという宣言になっており、指定された文字列がURLの要件を満たさないとMalformedURLException例外(チェック例外)が送出される仕様です。例えば"foo://"という文字列を指定すると、「未知のプロトコル」としてこの例外が発生します。
この例外はチェック例外のため、URLクラスを生成するときは例外ハンドリングが必要です。ここではcatchブロック【2】でこの例外を捕捉し、リカバリーの措置として0を返すように実装しています【3】。
このときのMain、Foo、Barにおける例外の挙動を図に表すと、以下のようになります。
【図19-1-5】チェック例外のハンドリング
チェック例外の伝播
前項ではURLクラスから送出される例外をBarクラスにてハンドリングする例を取り上げましたが、Barにて例外ハンドリングを行わず、その処理を呼び出し元であるFooに任せることも可能です。
以下のコードを見てください。
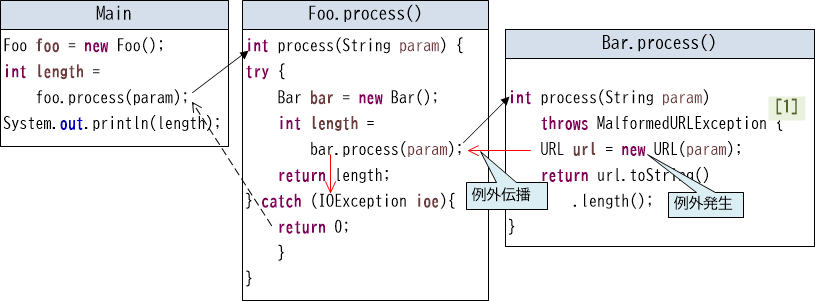
public class Bar {
public int process(String param) throws MalformedURLException { //【1】
URL url = new URL(param);
return url.toString().length();
}
}
throws句に例外クラスを指定すると、メソッド内で発生する例外を呼び出し元に伝播させることができます。従ってthrows句にMalformedURLExceptionを指定すれば【1】、Barでこの例外をハンドリングしなくてもコンパイルはとおります。逆にこのようにすると、呼び出し元であるFooでは、伝播されたMalformedURLExceptionをハンドリングしないと、コンパイルエラーになります。
このとき、"foo://"などURLの要件を満たさない文字列が渡されると、MalformedURLException例外が発生し、以下図のような挙動をします。
【図19-1-6】チェック例外の伝播
仮にFooでも同じようにthrows句を使えば、さらにその呼び出し元に例外ハンドリングを委譲させることができます。このようにメソッドにthrows句を付与すると、メソッド内で発生するチェック例外を伝播させ、そのハンドリングを呼び出し元に委譲することが可能です。
19.1.5 例外クラスの継承とハンドリング
継承関係にある例外クラスの捕捉
ここでは継承関係にある例外クラスを捕捉するときのルールについて、説明します。
catchブロックには捕捉対象の例外クラスを指定しますが、捕捉されるのはその例外クラスか、またはその子クラスが対象です。
従って、例えば以下のコードのようにjava.lang.Exceptionを指定すると、その子であるすべての例外クラスが捕捉対象になります。
try {
// 例外が発生する可能性のある処理
........
} catch (Exception ex) {
System.out.println("例外発生, msg => " + ex.getMessage());
}
例外ハンドリングは個々の例外クラスの種類ごとに行うのが原則ですが、このように大きな器を用意してすべての例外を捕捉し、共通的な処理(ログ出力など)を行うケースもあります。
また1つのtry-catch文の中で、例外クラスの粒度に応じて複数のcatchブロックを記述することもできます。以下のコードを見てください。
try {
// 例外が発生する可能性のある処理
........
} catch (IllegalArgumentException iae) {//【1】
System.out.println("引数不正, msg => " + iae.getMessage());
} catch (RuntimeException re) {//【2】
System.out.println("非チェック例外発生, msg => " + re.getMessage());
} catch (Exception ex) { //【3】
System.out.println("例外発生, msg => " + ex.getMessage());
}
これら3つの例外クラスは、親から順にException【3】、RuntimeException【2】、IllegalArgumentException【1】という関係になります。
このコードではまずIllegalArgumentExceptionが【1】で捕捉され、次にそこからこぼれた非チェック例外が【2】で捕捉され、最後にすべての例外が【3】で捕捉されます。このようにtry-catch文では、例外クラスの継承関係において、子から親の方向へと段階的に捕捉する範囲を広げていくことが可能です。
なおcatchブロックの記述において、広い範囲(親クラス)を先に記述し、狭い範囲(子クラス)を後ろに記述することはできません。例えばこのコードを、以下のように【1】と【2】の記述を逆転させて先にRuntimeExceptionを捕捉すると、後ろのブロックに進む可能性がないためコンパイルエラーになります。
} catch (RuntimeException re) {
System.out.println("非チェック例外発生, msg => " + re.getMessage());
} catch (IllegalArgumentException iae) { // コンパイルエラー
System.out.println("引数不正, msg => " + iae.getMessage());
}
マルチキャッチ
例外ハンドリングは例外の種類ごとに行うのが基本ですが、1つのcatchブロックに複数の例外クラスを指定することができます。
これをマルチキャッチと呼びます。マルチキャッチでは、|(バーティカルバー)で区切って複数の例外クラスを指定します。
捕捉対象の例外クラスが複数あり、それらの間に継承関係がない場合には、この機能を利用するとコードを簡潔に記述することができます。
以下のコードを見てください。
try {
// FileNotFoundExceptionが発生する可能性のある処理
// MalformedURLExceptionが発生する可能性のある処理
........
} catch (FileNotFoundException | MalformedURLException ex) { //【1】
System.out.println("例外発生, msg => " + ex.getMessage()); //【2】
}
捕捉対象であるFileNotFoundExceptionとMalformedURLExceptionについて、詳細はここでは割愛しますが、両者はいずれもIOExceptionクラスの子クラスです。ただし両者に継承関係はありません。このようにcatchブロックに継承関係がない複数の例外クラスを列挙する【1】と、それらを同時に捕捉することができます。
なお列挙されたクラス間に継承関係がある場合、親クラス1つで捕捉すれば事足りるため、コンパイルエラーになります。
捕捉した例外オブジェクトは変数exに格納されますが、exのメンバーは、必然的に捕捉対象クラスにとっての共通的な親クラスのメンバーに限定されます。このコードでは変数exのgetMessage()メソッドを呼び出しています【2】が、アクセス可能なのは両クラスにとっての共通的な親であるIOExceptionクラスのメンバーです。
例外クラスの抽象化
メソッドにthrows句を付与するとき、当該メソッドから送出される例外クラスの親を指定することができます。例えば前項の例にも登場したFileNotFoundExceptionとMalformedURLExceptionが発生する可能性があり、それを呼び出し元に送出するメソッドでは、両者の共通的な親クラスであるIOExceptionをthrows句に指定することができます。
public void process() throws IOException {
// FileNotFoundExceptionが発生する可能性のある処理
// MalformedURLExceptionが発生する可能性のある処理
........
}
この機能はコードを簡潔に記述するためのものではなく、抽象化プログラミングのための戦略の一環です。
このメソッドの呼び出し元に対して、FileNotFoundExceptionやMalformedURLExceptionを個別にハンドリングさせたいのであれば、両クラスをthrows句に指定すれば良いでしょう。逆に呼び出し元は例外を個別にハンドリングする必要はなく、とにかくIOExceptionをハンドリングすれば十分である、という仕様にするのであれば、IOExceptionのみをthrows句に指定します。
オーバーライドされたメソッドの例外
レッスン11.1.2で取り上げたオーバーライドのルールに『親クラスにthrows句がある場合、オーバーライドメソッドのthrows句に指定可能なのは、親の例外クラスと同じか、または、その型の「下位方向の型」であること』というものがありました。
この点をもう少し具体的に説明します。まずHogeクラスと、その子クラスとしてPiyoクラスがあるものとします。また例外クラスとしてA_Exception、B_Exception、C_Exceptionがあり、親から順にA、B、Cという継承関係があるものとします。
Hogeクラスのprocess()メソッドでthrows句にB_Exceptionを指定しているものとすると、Piyoクラスのprocess()メソッドのthrows句における例外の指定可否は、以下のように決まります。
- void process() … OK(指定なし)
- void process() throws B_Exception … OK(同じ例外クラス)
- void process() throws C_Exception … OK(子となる例外クラス)
- void process() throws B_Exception, C_Exception … OK(子となる例外クラスの追加)
- void process() throws A_Exception … NG(親となる例外クラス)
- void process() throws D_Exception … NG(継承関係にない例外クラス)
19.1.6 finallyブロック
finallyブロック
try-catch文による例外ハンドリングにおいて、例外が発生する・しないに関わらず共通的な処理を行いたい、というケースがあります。その典型が、ファイルやネットワークといったリソースのクローズです。try-catch文にfinallyブロックを追加すると、このような要件を実現することができます。
finallyブロックは、以下の構文のように、catchブロックの最後に追加します。
try {
....例外が発生する可能性のある処理....
} catch (例外クラス1 変数1) {
....例外クラス1発生時の処理....
....catchブロックを必要な分だけ記述....
} finally {
....例外発生有無に関わらず行う共通処理....
}
このようにfinallyブロックを追加すると、例外が発生しない場合(正常時)はtryブロックが終了した直後に、例外が発生した場合(異常時)はcatchブロックが終了した直後に、ブロックの内容が実行されます。
なおtryブロック内のreturn文で処理を終える場合は、その直後(呼び出し元に処理が返る直前)に、finallyブロックが実行されます。
finallyブロックの具体例
ここではfinallyブロックの具体例として、ファイル入出力においてファイルをクローズする処理を取り上げます。なおファイル入出力に関する詳細は『Java Advanced編』で取り上げるため、ここではfinallyブロックの使い方にのみ注目してください。
以下のメインメソッドを見てください。
public static void main(String[] args) {
Path path = Paths.get("foo.txt");
BufferedReader br = null; //【1】
try {
// ファイルをオープンし、読み込みのためのBufferedReaderを取得
br = Files.newBufferedReader(path);
String line;
// 一行ずつ読み込み、コンソールに表示
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException ioe) {
System.out.println("ERROR, msg => " + ioe.getMessage());
} finally { //【2】
if (br != null) {
try {
br.close(); //【3】
} catch(IOException ioe) {
System.out.println("ERROR, msg => " + ioe.getMessage());
}
}
}
}
このコードは"foo.txt"というファイルを読み込んで、その内容を一行ずつコンソールに表示する、という処理を行うものです。
ファイルを読み込むためには最初にファイルをオープンする必要がありますが、読み込み中に何らかの異常が発生して処理が中断すると、オープンされた状態のまま残ってしまう可能性があります。このような事象を「リソースリーク」と呼びます。リソースリークが発生すると、他のプログラムから当該ファイルを入出力できなくなったり、OSのリソースが枯渇したりするといった諸問題を引き起こすため、ファイルは確実にクローズしなければなりません。
Java SEによるファイルIOのAPIではjava.io.IOExceptionというチェック例外が送出されるため、try-catch文で適切にハンドリングします。そしてfinallyブロックを記述【2】し、ファイルをクローズする処理を実装します【3】。このようにすると正常終了・異常終了に関わらず、最終的にはファイルが必ずクローズされるためリソースリークは発生しません。
なおfinallyブロックでファイルをクローズするためには、変数brはtry-catch文の外側で宣言する【1】必要があります。
try-catch文における各ブロックの登場回数
try-catch文では、必ずしもcatchブロックは必須ではありません。例えば例外の発生有無に関わらず、ログ出力などの共通処理は必ず行いたいというようなケースでは、tryブロックとfinallyブロックのみになります。
このような点を踏まえると、try-catch文における各ブロックの登場回数には、以下のようなパターンがあることになります。
- tryブロックが1回、catchブロックが1~複数回(finallyブロックなし)
- tryブロックが1回、catchブロックが1~複数回、finallyブロックが1回
- tryブロックが1回、finallyブロックが1回(catchブロックなし)
- tryブロックが1回のみ
なお4は「リソースの自動クローズ機能」を使った場合にのみ、このようなパターンになります。この機能については、次のチャプターで説明します。
19.1.7 スタックトレース
コールスタックとは
スタックトレースを説明する前に、まず前提として、コールスタックの考え方を理解する必要があります。コールスタックとは、メソッド呼び出しの履歴がスタックとして積み上がった情報です。
ここではMainクラス→Hogeクラス→Piyoクラスへのメソッド呼び出しが、以下の図のようなフローになっているケースを考えます。
【図19-1-7】Mainクラス→Hogeクラス→Piyoクラスへのメソッド呼び出し関係(シーケンス図)

コールスタックは「Mainクラスのmain()メソッド」から始まり、次に「Hogeクラスのhoge()メソッド」が積まれます。その後「Piyoクラスのpiyo1()メソッド」が積まれますが、このメソッドの処理が終了して制御がHogeクラスに戻ると、この履歴はスタックからは削除されます。そして次に「Piyoクラスのpiyo2()メソッド」が積まれます。
以上から★マークの時点(piyo2()メソッド)において、スタックに積まれたメソッドの呼び出し履歴は「Mainクラスのmain()メソッド」、「Hogeクラスのhoge()メソッド」「Piyoクラスのpiyo2()メソッド」の3つ、ということになります。
スタックトレースとは
ここではコールスタックの考え方を前提に、スタックトレースについて説明します。スタックトレースとは、例外発生時のコールスタックを、人間に分かりやすい形式に整えたものです。例外ハンドリングによって例外を捕捉したら、捕捉した例外オブジェクトのprintStackTrace()メソッドを呼び出すことにより、スタックトレースを出力することができます。
スタックトレースに含まれている例外の種類やそのメッセージ、例外が発生した場所(クラス名およびメソッド名)や、そこに至るメソッドの呼び出し履歴といった情報を確認することで、原因調査やデバッグを行います。printStackTrace()の出力先は標準出力ため、Eclipse上ではコンソールに表示されます。
スタックトレースの具体例
ここではスタックトレースにどのような情報が出力されるのか、具体例に基づいて見ていきましょう。
以下のように、Main、Foo、Barという3つのクラスを作成します。これらは既出のコードとほとんど同じですが、Mainクラスにて例外ハンドリングを行い、スタックトレースを出力する点が異なります。
public class Main {
public static void main(String[] args) {
Foo foo = new Foo();
try {
int length = foo.process(args[0]);
System.out.println(length);
} catch(IllegalArgumentException iae) {
iae.printStackTrace(); //【1】
}
}
}
public class Foo {
public int process(String param) {
Bar bar = new Bar();
int length = bar.process(param);
return length;
}
}
public class Bar {
public int process(String param) {
int length = param.length();
if (10 < length) {
throw new IllegalArgumentException("文字列長が過大");
}
return length;
}
}
処理の流れとしては、Mainクラスでコマンドライン引数として受け取った文字列をMain→Foo→Barへと順に渡し、文字列長を計算して返す、というものです。ここでMainクラスに10文字超の文字列を引数に与えて実行すると、BarクラスにてIllegalArgumentExceptionが発生し、それがMainクラスまで伝播します。そしてMainクラスのcatchブロックにて当該の例外を捕捉し、受け取った例外オブジェクトのprintStackTrace()メソッドを呼び出し、スタックトレースを出力しています【1】。
具体的には、以下のような情報が出力されます。
java.lang.IllegalArgumentException: 文字列長が過大
at pro.kensait.java.basic.lsn_19_1_7.Bar.process(Bar.java:7)
at pro.kensait.java.basic.lsn_19_1_7.Foo.process(Foo.java:6)
at pro.kensait.java.basic.lsn_19_1_7.Main.main(Main.java:13)
スタックトレースには、コールスタック(メソッドの呼び出し履歴)が例外が発生した箇所に向かって、下から上に積み上がって表示されます。各行には、クラスのFQCNとメソッド名が、右端の( )にはソースファイル名とその行数が表示されています。Javaのプログラムは必ずメインメソッドから起動されますので、最下行には必ずメインメソッドが来ます。
この例では、まずMainクラスのメインメソッドが呼び出され、同クラスの13行目で次のメソッド(Fooクラスのprocess()メソッド)が呼び出され、Fooクラスの6行目で次のメソッド(Barクラスのprocess()メソッド)が呼び出され、さらにBarクラスの7行目でIllegalArgumentExceptionが発生した、とスタックトレースを読み取ります。
コールスタックの一番上に表示されているメソッド(ここではBarクラスのprocess()メソッド)が、例外発生場所です。Javaアプリケーションをテスト中もしくは本番稼働中に意図せぬ例外が発生し、原因調査やデバッグを行う場合は、まさにこの部分(コールスタックの一番上)を確認することで、例外の発生個所を突き止めます。
またスタックトレースの最上段には、発生した例外クラス名とそのメッセージが表示されます。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- 例外の概念や種類について。
- try-catch文による例外ハンドリングの方法について。
- 例外クラスの階層構造やそれぞれの特徴について。
- 例外の生成と送出のパターン別の挙動について。
- 例外の伝播とハンドリングについて。
- チェック例外の送出とthrows句について。
- 継承関係にある例外クラスの捕捉やマルチキャストについて。
- finallyブロックの目的について。
- スタックトレースの出力内容と例外発生時の原因調査方法について。