はじめに
自己紹介
皆さん、こんにちは、斉藤賢哉と申します。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Advanced編』の一部の範囲をカバーしたものです。『Java Advanced編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをQiita内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの基本的なスキルを習得済みで、さらなるレベルアップを目指している方
- 将来的なキャリアとして、希少性の高い上級エンジニアやアーキテクトを志向している方
- フリーランスエンジニアとして付加価値の更なる向上を図っている方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
4.1 ラムダ式と関数型インタフェース
チャプターの概要
このチャプターでは、Javaにおける関数の概念や、それを実装するためのラムダ式について学びます。
ラムダ式や、次のチャプターで取り上げるストリームAPIは、非常に高度な仕組みを提供しますが、その反面、理解には相応のコストがかかります。『Java Advanced編』の中では、最大の「山場」です。難しいと感じた方は、チャプター5.1までスキップし、復習の中で改めて学んでも良いでしょう。
4.1.1 ラムダ式の概念と構文
ラムダ式と関数型プログラミング
関数型プログラミングとは、数学における関数を中心にプログラムを組み立てる手法です。従来はLispやSchemeといった言語を中心に、主に大学などの科学技術分野で利用されてきましたが、昨今では新しい言語も登場し、改めてその存在に注目が集まっています。
Javaは元来、本格的なオブジェクト指向型の言語ですが、ラムダ式によって、関数型プログラミングのパラダイム(考え方や記述方法)を取り入れることが可能になりました。ラムダ式が導入され、オブジェクト指向に関数型のパラダイムが融合されたことで、Javaはより複雑で多様なケースに応用が可能な、新しい言語に進化したと言えるでしょう。
Javaにおける関数とは
ラムダ式の前に、まずはJavaにおける「関数」の概念を理解する必要があります。
関数とメソッドは、文脈によっては同じように扱われることもありますが、厳密には異なります。
Javaにおける関数は、クラスと同じようにいわゆる「第一級オブジェクト」の一種です。「第一級オブジェクト」とは、変数に代入したり、メソッドの引数や戻り値に指定したりすることができる要素のことです。Javaにおける関数は、後述する関数型インタフェースのオブジェクトであり、ラムダ式によって実装されます。
ラムダ式とは
ラムダ式とは、引数や戻り値として受け渡しが可能なコードブロックで、Javaにおいて関数を実装するための手段として用意されています。
ラムダ式は以下の構文によって表されます。
(型1 引数名1, 型2 引数名2, ....) -> {
....ラムダ式本体の処理....
}
ラムダ式では、( )で囲って引数の型と名前を列挙します。引数の型は暗黙的に推論されるため、省略するのが一般的です。
カッコの後ろにはアロー演算子を記述し、さらにその後ろに{ }でブロックを記述します。ラムダ式の実行結果を呼び出し元に返す場合は、コードブロック内においてreturn文によって戻り値を指定します。
ラムダ式の様々な省略記法
ラムダ式の引数が1つの場合、カッコを省略することができます。
引数名 -> {
....ラムダ式本体の処理....
}
またラムダ式が引数を1つも取らない場合は( )は省略できないため、以下のような記法になります。
() -> {
....ラムダ式本体の処理....
}
またブロック内の命令文が一行の場合は、{ }を省略することも可能です。
(型1 引数名1, 型2 引数名2, ....) -> ....ラムダ式本体の処理....
さらにこの時、対象の命令文がreturn文の場合は、returnキーワードも合わせて省略が必要です。つまり以下の2つのコードは同義です。
x -> {return x * 2;}
x -> x * 2
4.1.2 ラムダ式の具体例
コレクションをソートするケース
それでは、ラムダ式の用途を具体的に見ていきましょう。
ラムダ式は「単一のメソッドを持つクラスのインスタンス」を置き換えることを可能にします。ここでは、Collectionsクラスのsort()メソッドによってコレクションをソートするケースを考えてみましょう。このメソッドは、コンパレータ(java.util.Comparatorインタフェースを実装したクラスのインスタンス)を引数に取り、その内容に応じてコレクションをソートします。
例えば文字列を長さに応じてソートする場合、まず以下のようなコンパレータ(MyComparatorクラス)を作成します。
public class MyComparator implements Comparator<String> {
@Override
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
}
このようにコンパレータは、Comparatorインタフェースのcompare()メソッドをオーバーライドして作成します。このコンパレータでは、文字列s1とs2を比較し、s1の方が長い場合は正の整数を返すことにより順序は大きくなる、という昇順のソートロジックを実装しています。
このロジックに従って文字列をソートするためには、以下のようにCollectionsクラスのsort()メソッドを呼び出します。
List<String> strList = Arrays.asList("Japan", "USA", "France");
Collections.sort(strList, new MyComparator());
このとき、もしMyComparatorクラスの再利用性が見込まれない場合は、MyComparatorクラスの代わりに匿名クラスを利用することができます。具体的には以下のようなコードになります。
List<String> strList = Arrays.asList("Japan", "USA", "France");
Collections.sort(strList, new Comparator<String>() { //【1】
@Override
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
});
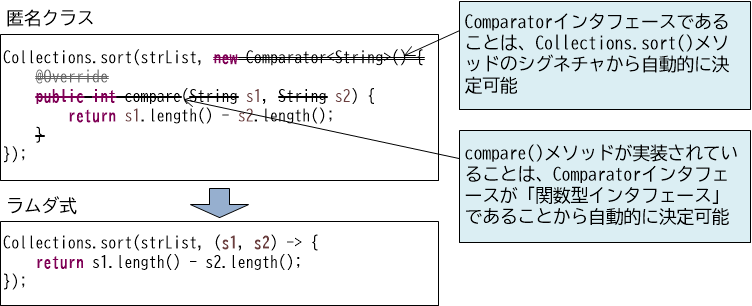
このようにsort()メソッドの第二引数に、匿名クラスのインスタンスを渡している【1】わけですが、この部分をよく見ると「単一のメソッドを持つクラスのインスタンス」であることが分かります。従ってこの部分は、以下のようにラムダ式に置き換えることができます。
List<String> strList = Arrays.asList("Japan", "USA", "France");
Collections.sort(strList, (s1, s2) -> { //【1】
return s1.length() - s2.length();
});
sort()メソッドの第二引数に、ラムダ式を指定しています【1】。このラムダ式は、2つの引数を取り、その長さに応じてソートロジックを実装している点は既出のコードと同様です。
このコードを見ると、ラムダ式がComparatorインタフェースのcompare()メソッドを実装したものであるとはどこにも明示されていないため、不思議に感じるかもしれません。この点が、ラムダ式を理解するためのポイントです。まずComparatorインタフェースであることは、sort()メソッドのシグネチャがComparatorインタフェースを受け取ることになっているため、自動的に決定されます。そしてComparatorインタフェースは単一の抽象メソッドしか持たない「関数型インタフェース」(詳細は後述)ため、ラムダ式がこのメソッドを実装している点も、自動的に決定できるのです。
このようにラムダ式を利用すると、匿名クラスを利用したコードに比べて、大幅に記述量を削減することができます。
【図4-1-1】ラムダ式と匿名クラス
スレッドプログラミングのケース
チャプター2.1で取り上げたように、スレッドプログラミングでは、タスクはjava.lang.Runnableインタフェースをimplementsして作成します。そしてタスクのインスタンスをThreadクラスのコンストラクタに指定して、スレッドを生成します。
Runnableインタフェースには、単一のrun()メソッドが定義されており、タスクはこのメソッドをオーバーライドして作成するため、ここでもラムダ式が利用できます。具体的には以下のコードを見てください。
Thread t = new Thread(() -> {
// タスクの処理を実装
........
});
t.start();
このように、ラムダ式によってタスクを実装し、それをThreadクラスのコンストラクタに指定してスレッドを生成することができます。ここでもThreadクラスのコンストラクタのシグネチャから、このラムダ式が、Runnableインタフェースのrun()メソッドを実装したものであることが自動的に決定されます。
4.1.3 関数型インタフェースとラムダ式
関数型インタフェースとは
レッスン4.1.2では、java.util.Comparatorインタフェースや、java.lang.Runnableインタフェースを、簡潔に実装する手段としてラムダ式を利用しました。このようにラムダ式によって実装できるインタフェースを、関数型インタフェースと呼びます。
関数型インタフェースの条件は、単一の抽象メソッドを持つ、というのものです。ただしスタティックメソッドやデフォルトメソッドは含まれていても問題ありません。
インタフェースに対して、@java.lang.FunctionalInterfaceアノテーションを付与すると、関数型インタフェースであることを明示することができます。実際にComparatorインタフェースやRunnableインタフェースの「APIリファレンス」を参照すると、@FunctionalInterfaceが付与されていることを確認できます。このアノテーションをインタフェースに付与すると、「単一の抽象メソッドを持つ」という条件に違反する(例えば複数の抽象メソッドを定義)と、コンパイルエラーになります。このアノテーションの指定は必須ではなく、条件さえ満たしていれば自動的に関数型インタフェースと見なされます。ただしコンパイラによってエラーを検出するために、関数型インタフェースを作成する場合は、特別な事情がない限りは、このアノテーションを利用すると良いでしょう。
関数型インタフェースの具体例
ここでは、自作の関数型インタフェースを作成し、それをラムダ式によって実装するケースを見てきましょう。
まず、以下のように関数型インタフェース(CalcFunction)を作成します。
@FunctionalInterface //【1】
interface CalcFunction {
int calc(int x, int y); //【2】
}
このインタフェースは、2つのint型の値を引数として受け取り、何らかの計算を行ってその結果を返す処理を表します。calc()という単一のメソッド【2】を持つため、関数型インタフェースの条件を満たしています。またFunctionalInterfaceアノテーションを付与して、関数型であることを明示しています【1】。
次にこの関数型インタフェースをラムダ式によって実装し、そのメソッドを呼び出すためのコードを示します。
CalcFunction cf = (x, y) -> { //【1】
return x + y;
};
int answer = cf.calc(30, 10); //【2】
このように2つの引数に対して足し算を行うための処理をラムダ式によって実装し、CalcFunction型変数cfに代入します【1】。そして変数cfのcalc()メソッドを呼び出すと、ラムダ式に引数が渡され、計算結果が返されます【2】。ここでは引数に30と10を指定しているため、40が返されます。
関数型インタフェースとラムダ式の関係
前述したように、ラムダ式とは関数型インタフェースを実装するための手段です。ここでは関数型インタフェースとラムダ式が、プログラム上でどのような対応関係になるのかを整理します。
ラムダ式はJavaにおける「第一級オブジェクト」であり、変数に代入したり、メソッドの引数や戻り値に指定したりすることができます。従って、以下のようなパターンがあることになります。
(1)関数型インタフェース型の変数に、ラムダ式を代入する。
(2)関数型インタフェースを受け取るメソッドやコンストラクタに、ラムダ式を引数として渡す。
(3)関数型インタフェースを返すメソッドが、return文にラムダ式を指定して返す。
前項で取り上げたCalcFunctionの例は、(1)に相当します。またレッスン4.1.1の「コレクションをソートするケース」や「スレッドプログラミングのケース」は、(2)に相当します。
【図4-1-2】関数型インタフェースとラムダ式の関係(コレクションをソートするケース)

ラムダ式による再利用性向上
ラムダ式は非常に応用範囲が広く、この機能を有効活用すると、コードの再利用性を従来以上に高めることが可能になります。
例えば足し算を行うためのadd()メソッドと、引き算を行うためのsubtract()メソッドがあるものとします。この2つのメソッドには演算処理以外にエラー処理が施されており、第一引数が50超、または計算結果が100超の場合に、例外が送出されるものとします。具体的には以下のようなコードです。
int add(int x, int y) { // 足し算を行うメソッド
if (50 < x) {
throw new RuntimeException("引数不正");
}
int value = x + y; //【1】
if (100 < value) {
throw new RuntimeException("計算結果不正");
}
return value;
}
int subtract(int x, int y) { // 引き算を行うメソッド
if (50 < x) {
throw new RuntimeException("引数不正");
}
int value = x - y; //【2】
if (100 < value) {
throw new RuntimeException("計算結果不正");
}
return value;
}
両メソッドの違いは、足し算と引き算の部分【1、2】だけであり、それ以外のエラー処理はまったく同じです。
このとき足し算と引き算の違いのみを吸収し、それ以外のコードを共通化することは可能でしょうか。オブジェクト指向では、継承や多態性を利用することで再利用性を高めることは可能ですが、このように「メソッド内の特定のコードブロック」を再利用することはできません。ただし関数型インタフェースとラムダ式を利用すると、このような要件を実現することができます。
具体的には、上記2つのメソッド(add()とsubtract())を、以下のような1つのメソッドにまとめることができます。
int compute(int x, int y, CalcFunction cf) { //【1】
if (50 < x) {
throw new RuntimeException("引数不正");
}
int value = cf.calc(x, y); //【2】
if (100 < value) {
throw new RuntimeException("計算結果不正");
}
return value;
}
このコード(compute()メソッド)は、既出のadd()メソッドおよびsubtract()メソッドの中の、演算処理を行うコードブロックを関数型インタフェースに置き換え、それ以外のエラー処理を共通化したものです。
まず引数として、CalcFunctionという関数型インタフェースを受け取るようにします【1】。このインタフェースのコードは、既出のものと同様です。そして足し算および引き算を行う処理は、このインタフェースのcalc()メソッドを呼び出す処理に変わります【2】。「どのような計算処理が行われるかは分からないが、とにかく渡された関数型インタフェースのcalc()メソッドを呼び出す」ことで、計算を行うのです。
このメソッドを呼び出すためのコードは、以下のようになります。
int answer1 = compute(30, 10, (x, y) -> x + y); //【3】足し算
System.out.println(answer1);
int answer2 = compute(30, 10, (x, y) -> x - y); //【4】引き算
System.out.println(answer2);
まず足し算を行うためには「2つの引数を取り、それらの足し算を行うためのラムダ式」が必要です【3】。例えば30と10の足し算を行いたい場合は、compute()メソッドに「30、10、足し算を行うラムダ式」の3つを渡すと、計算結果として40が返されます。引き算についても同様です【4】。
このようにラムダ式を利用することによって、足し算と引き算の処理をコードブロックとしてメソッドの外側に切り出し、それ以外の処理を完全に共通化することが実現できた、という点がお分かりいただけたと思います。
4.1.4 遅延実行とクロージャ
遅延実行
ラムダ式を利用するメリットの1つに、遅延実行があります。
通常メソッドを呼び出すとその場で即座に処理が実行されますが、場合によっては、処理をいったんどこかに溜め込み必要に応じて後から実行したい、というケースがあります。そのような場合は「後から実行したい処理」をラムダ式として実装し、それを引数にして別のメソッドに渡します。別のメソッドに渡されたラムダ式は、その後任意のタイミングで実行することが可能です。このように「後から必要に応じて処理を行うこと」を、遅延実行と呼びます。
ラムダ式を利用すると、遅延実行を行うことが可能になります。
遅延実行の具体例
ここでは遅延実行の具体例として、ログの出力処理を取り上げます。
ログの出力処理は通常、出力対象のメッセージを、ロガーと呼ばれるログ出力ライブラリのAPIに渡します。
ロガーでは、定義されたログレベルに応じて、メッセージの出力可否を判定します。例えばINFOログであれば、ログレベルがinfoレベル以上に定義されている場合に限って、ログメッセージを生成し出力します。すなわち「後から必要に応じてログメッセージを生成し出力する」というわけです。
このようなロガーの処理を、関数型インタフェースとラムダ式によって簡易的に実装してみましょう。まず以下のようなログメッセージを提供するためのインタフェース(LogSupplier)を定義します。
@FunctionalInterface
interface LogSupplier {
String getLog();
}
次にロガーにおいて、INFOログを出力するためのAPI(info()メソッド)のコードを示します。
static void info(LogSupplier ls) { //【1】
if (infoLevel) { // infoレベル以上の場合にture
System.out.println("[ INFO ] " + ls.getLog()); //【2】
}
}
このメソッドは、LogSupplierインタフェースを受け取ります【1】。ログメッセージは直ちに出力するのではなく、ログレベルを判定した上で、LogSupplierインタフェースのgetLog()メソッドによって取得して出力します【2】。このメソッドを「文字列をログメッセージとして直接受け取るAPIにしたら良いのではないか」と感じるかもしれませんが、もちろんそのようにすることも可能です。ただしそうすると、ログが出力される、されないに関わらず、必ず文字列のオブジェクトが生成されてしまいます。その点関数型インタフェースを利用すると、ログレベルを判定した後、getLog()メソッド呼び出し時に初めて文字列が生成されるため、メモリの節約につながります。
このようにして作成されたロガーのinfo()メソッドは、次のように呼び出します。
Logger.info(() -> "THIS IS INFO LOG.");
このように、引数を取らないラムダ式をinfo()メソッドに渡します。
ラムダ式とローカル変数
ラムダ式では、その実装において外部に位置するローカル変数を参照することができます。その挙動を確認するために既出のコードを再び取り上げます。
まず、以下のような関数型インタフェース(CalcFunction)があるものとします。
@FunctionalInterface
interface CalcFunction {
int calc(int x, int y);
}
この関数型インタフェースを、以下のようにラムダ式で実装していました。
CalcFunction cf = (x, y) -> {
return x + y;
};
int answer = cf.calc(30, 10);
このコードを以下のように修正します。
int base = 100; //【1】ローカル変数を宣言
CalcFunction cf = (x, y) -> {
return base + x + y; //【2】ローカル変数を参照
};
int answer = cf.calc(30, 10); //【3】
今度はローカル変数としてbase(初期値100)を宣言しています【1】。そしてラムダ式の実装において、それを参照しています【2】。このとき変数cfのcalc()メソッドに30と10を渡すと、変数baseの値100が加算されるため、140が返されます【3】。
ラムダ式とクロージャ
前項で説明したようにラムダ式の中からローカル変数を参照することができますが、ラムダ式を遅延実行する場合であっても、果たしてローカル変数の値は参照できるのでしょうか。その答えはYESです。
それでは遅延実行の挙動を確認するために、以下のようなProcessorクラスを用意します。
public class Processor {
public void process(CalcFunction cf) {
System.out.println(cf.calc(30, 10));
}
}
このクラスのprocess()メソッドは、CalcFunctionインスタンスを受け取ります。CalcFunctionインスタンスを受け取った後、どういったタイミングや条件でこのインスタンスを利用するかは実装次第です。ここでは直ちにcalc()メソッドを呼び出し、その結果をコンソールに表示していますが、要件に応じて遅延実行が可能です。
次にこのメソッドに、ラムダ式を渡してみましょう。
int base = 100;
CalcFunction cf = (x, y) -> {
return base + x + y;
};
Processor p = new Processor();
p.process(cf);
このコードを実行すると、どのような計算が行われるでしょうか。
ラムダ式の実装から、calc()メソッド内の計算処理はbase + x + yになります。ただし変数baseは、CalcFunctionインスタンスに内包されているわけではなく、ローカル変数としてCalcFunctionインスタンスの外側に位置しています。そう考えると、ラムダ式がprocess()メソッドに渡された後、process()メソッド内で後からcalc()メソッドを呼び出しても、もはや変数baseを参照することはできないのでは、と感じるかもしれません。ところが実際には、変数baseの値は100として認識され、コンソールには計算結果として140が表示されるのです。
なぜこのようなことが実現できるのでしょうか。それはこのラムダ式の実装でローカル変数baseを参照した時点で、その変数baseがキャプチャされ、CalcFunctionインスタンスの中に閉じ込められたためです。
このように、ラムダ式の中にローカル変数の値を閉じ込めてしまう仕組みを、クロージャと呼びます。なおラムダ式内からローカル変数にアクセスがあると、その変数は暗黙的にfinalになり、値を更新しようとするとコンパイルエラーになります。これは、ローカル変数の値を後から更新されると、クロージャを実現できないためです。
4.1.5 Java SEの関数型インタフェース
クラスライブラリとしての関数型インタフェース
関数型インタフェースの宣言は、比較的シンプルになるケースが大半です。例えば先に取り上げたCalcFunctionは、「2つのint型引数を受け取り(計算結果として)1つのint型を返す」といったものでしたが、引数と戻り値に総称型の型パラメータを使えば、このインタフェースを汎用的に使用できる点は想像に難くないでしょう。
このような考え方からJava SEでは、いくつかの汎用性の高い関数型インタフェースがクラスライブラリとしてあらかじめ用意されています。これらのインタフェースを利用すれば、カバーされない複雑なものを除いて、開発者自身で関数型インタフェースを定義する必要がなくなります。
以下に、Java SEのクラスライブラリとして提供される関数型インタフェースの中でも、特に主要なものを示します。一番上のRunnableはスレッドプログラミングではタスクを実装するために使いましたが、スレッドプログラミングに限らず「引数なし、戻り値なし」という宣言を持つ汎用的な関数型インタフェースとして利用できます。それ以外のインタフェースは、すべてjava.util.functionパッケージに所属しています。
【表4-1-1】クラスライブラリとして提供される関数型インタフェース
| 分類 | 関数型インタフェース | 抽象メソッド | 説明 |
|---|---|---|---|
| 引数なし、戻り値なし | Runnable | void run() | 任意の処理を実行する |
| 引数なし、戻り値あり | Supplier<T> | T get() | 任意の処理を実行し、結果を返す |
| 引数あり、戻り値なし | Consumer<T> | void accept(T) | 指定された引数で、任意の処理を実行する(戻り値なし) |
| BiConsumer<T,U> | void accept(T, U) | 指定された2つの引数で、任意の処理を実行する(戻り値なし) | |
| 引数あり、戻り値あり | Function<T,R> | R apply(T) | 指定された引数で、任意の処理を実行し、結果を返す |
| BiFunction<T,U,R> | R apply(T, U) | 指定された2つの引数で、任意の処理を実行し、結果を返す | |
| Predicate<T> | boolean test(T) | 指定された引数で、任意の判定処理を行い、結果をboolean型で返す | |
| BiPredicate<T,U> | boolean test(T, U) | 指定された2つの引数で、任意の判定処理を行い、結果をboolean型で返す | |
| UnaryOperator<T> | T apply(T) | 指定された引数に対して何らかの演算処理を行い、その結果を返す。 ※引数と戻り値が同一のFunctionインタフェースと同様 |
|
| BinaryOperator<T> | T apply(T, T) | 指定された2つの引数に対して何らかの演算処理を行い、その結果を返す。 ※2つの引数と戻り値がすべて同一のBiFunctionインタフェースと同様 |
上記以外にも、java.util.functionパッケージには様々な関数型インタフェースが用意されていますが、実際のアプリケーション開発での用途を考えると、ひとまずこのくらいを押さえておけば十分でしょう。これらはあくまでも、利用頻度の高いと考えられる汎用的なインタフェースをクラスライブラリとして用意したものであり、これ以上に複雑なインタフェースが必要な場合は、開発者自身で関数型インタフェースを作成すれば問題ありません。
BiFunctionインタフェースの具体例
クラスライブラリとして提供される関数型インタフェースのうち、まずBiFunctionインタフェースの使用方法を具体的に説明します。このインタフェースは、引数を2つとり、任意の処理を実行し、その結果を返すためのものです。
レッスン4.1.2で取り上げたcompute()メソッドは、自作のCalcFunctionインタフェースを引数として受け取り、定義されたcalc()メソッドを呼び出して計算処理を行っていました。
int compute(int x, int y, CalcFunction cf) {
........
int value = cf.calc(x, y);
........
return value;
}
このCalcFunctionは「2つの引数を取り、1つの結果を返す」インタフェースのため、以下のようにBiFunctionインタフェースに置き換えることができます。
int compute(int x, int y, BiFunction<Integer, Integer, Integer> bf) { //【1】
........
int value = bf.apply(x, y); //【2】
........
return value;
}
BiFunctionには、引数1、引数2、戻り値という順番で、型パラメータで型を指定します。従ってここは、BiFunction型になります【1】。また計算処理は、BiFunction型変数bfのapply()メソッドを呼び出す【2】ことで実行します。
Predicateインタフェースの具体例
ここでは、クラスライブラリとして提供される関数型インタフェースのうち、Predicateインタフェースの使用方法を、具体的に説明します。このインタフェースは、引数を1つとり、何らかの判定処理を行い、その結果を返すためのものです。
例として、ユーザーがある特定の条件を満たしているかをチェックするための、汎用的なメソッドを取り上げます。まずユーザーは以下のUserクラスで表します。
public class User {
private int id;
private int age;
// コンストラクタ
........
// アクセサメソッド
........
public boolean isAdult() {
return 20 <= age;
}
}
このクラスは、idとageという2つのプロパティと、「大人かどうか」を判定するisAdult()メソッドを持つシンプルなクラスです。
次にユーザーの条件をチェックするためのメソッド(checkUserSpecメソッド)を、Predicateインタフェースを利用して実装します。
static boolean checkUserSpeck(User user, Predicate<User> userSpec) { //【1】
return userSpec.test(user); //【2】
}
このメソッドは、UserクラスとPredicateインタフェースという2つの引数を持ちます【1】。メソッド内では、受け取ったPredicateのtest()メソッドにUserを渡し、条件を満たしているかどうかを判定して、その結果をbooleanで返します【2】。
上記checkUserSpec()メソッドを、以下のようにして呼び出すと、ラムダ式の実装に従って「大人かどうか」という判定処理が行われ、その結果が返されます。
User alice = new User(1, 25);
boolean flag = checkUserSpeck(alice, user -> user.isAdult());
Supplierインタフェースの具体例
ここでは、クラスライブラリとして提供される関数型インタフェースのうち、Supplierインタフェースの使用方法を具体的に説明します。このインタフェースは、引数を取らず、任意の処理を実行し、その結果を返すためのものです。
レッスン4.1.3では、ロガーの処理を関数型インタフェースとラムダ式によって実装する例を取り上げましたが、そこで登場したLogSupplierは、Supplierインタフェースと同じ宣言を持つため、置き換えが可能です。既出のロガーにおいて、INFOログを出力するためのAPI(info()メソッド)を、Supplierインタフェースを利用して実装すると以下のようになります。
static void info(Supplier<String> s) { //【1】
if (infoLevel) {
System.out.println("[ INFO ] " + s.get()); //【2】
}
}
Supplierには、返す値の型を型パラメータで指定します。ここではログメッセージを返すインタフェースになるため、Supplier型になります【1】。またログメッセージの出力処理では、Supplier型変数sのget()メソッドを呼び出す【2】ことにより、メッセージを取り出して出力します。
このようにして作成したロガーのinfo()メソッドは、次のように呼び出します。
Logger.info(() -> "THIS IS INFO LOG.");
このように引数を取らないラムダ式を、info()メソッドに渡します。
Consumerインタフェースの具体例(1)
ここでは、クラスライブラリとして提供される関数型インタフェースのうち、Consumerインタフェースの使用方法を具体的に説明します。このインタフェースは、引数を1つ取り、任意の処理を実行するためのものです。このインタフェースは戻り値を持たないため、実現できることは「何らかの副作用を発生させること」に限られます。
以下はリストに対してループ処理を行い「何らかの副作用を発生させる」ためのメソッドです。
void doList(Consumer<String> c) { //【1】
List<String> strList = Arrays.asList("foo", "bar", "baz");
for (String str : strList) {
c.accept(str); //【2】
}
}
このメソッドは、Consumerを引数として受け取ります【1】。そしてループ処理の中でリストの要素を取り出し、Consumerインタフェースのaccept()メソッドを呼び出す【2】ことで、何らかの処理(副作用)を行います。副作用の最も分かりやすい例は、コンソールへの表示でしょう。
上記doList()メソッドを、以下のようにしてラムダ式を指定して呼び出すと、リスト内の個々の要素がコンソールに表示されます。
doList(str -> System.out.println(str));
Consumerインタフェースの具体例(2)
Consumerは戻り値を持たないインタフェースのため、その目的は「何らかの副作用を発生させること」ですが、典型的な副作用の1つにインスタンスの状態更新があります。
ここで、書籍『Javaによる関数型プログラミング』で紹介されている、Builderパターンというデザインパターンを紹介します。Builderパターンと一口に言っても、出典元によって内容はまちまちですが、この書籍で紹介されているのは、Consumerインタフェースを利用したインスタンス生成の実装パターンです。このパターンによって、コンストラクタの諸問題、例えば引数が増えた場合にどのフィールドに対応するかが分かりにくい点や、フィールドの組み合わせに応じて多数のオーバーロードが必要な点などを、解決することができます。
それでは具体的に見ていきましょう。まず「人物」を表すPersonクラスに、このパターンを適用すると以下のようになります。
public class Person {
// フィールド
private String name;
private int age;
private String gender;
//【1】コンストラクタ
private Person() {}
// ゲッター
........
//【2】フィールド値の設定用メソッド
public Person withName(String name) {
this.name = name;
return this;
}
public Person withAge(int age) {
this.age = age;
return this;
}
public Person withGender(String gender) {
this.gender = gender;
return this;
}
// ビルダーメソッド
public static Person build(Consumer<Person> builder) { //【3】
Person person = new Person();
builder.accept(person); //【4】
return person;
}
}
特徴的な点として、まず外部で直接インスタンスを生成できないように、コンストラクタの可視性をprivateにします【1】。またフィールド値の設定用メソッドは、セッターではなくwith〇〇という名前にし、戻り値としてPerson型をthisで返すようにします【2】。さらにインスタンス生成のためのスタティックメソッド(ここではbuild()メソッド)を定義し、Consumerを受け取るようにします【3】。このbuild()メソッドでは、Consumerのaccept()メソッドによってPersonインスタンスのフィールドを更新し【4】、フィールド更新後のPersonインスタンスを返却します。
このようなPersonクラスを、外部からインスタンス生成するためのコードは、以下のようになります。
Person alice = Person.build(person -> {
person.withName("Alice").withAge(25).withGender("female");
});
ラムダ式によってPersonインスタンスの各フィールドに値を設定する処理を実装し、それをbuild()メソッドに渡すことによってインスタンスを生成します。この例ではフィールド設定用メソッド(withName()メソッドなど)がthisを返すため.で区切ってメソッドをチェーンさせていますが、必要に応じて間に条件分岐を挟むようにすれば、きめの細かいインスタンス生成ロジックを構築することができます。
プリミティブ型に特化した関数型インタフェース
既出の関数型インタフェースは、引数および戻り値の型を型パラメータとして指定が可能な、汎用性の高いものばかりでした。
java.util.functionパッケージには、引数や戻り値を、特定のプリミティブ型に特化した専用インタフェースが用意されています。以下にその代表的なものを示します。
Supplierインタフェースの特化型
| 引数 | 戻り値 | インタフェース |
|---|---|---|
| なし | int型 | IntSupplier |
| なし | long型 | LongSupplier |
| なし | double型 | DoubleSupplier |
Consumerインタフェースの特化型
| 引数 | 戻り値 | インタフェース |
|---|---|---|
| int型 | なし | IntConsumer |
| long型 | なし | LongConsumer |
| double型 | なし | DoubleConsumer |
Functionインタフェースの特化型
| 引数 | 戻り値 | インタフェース |
|---|---|---|
| int型 | 総称型 | IntFunction<R> |
| long型 | 総称型 | LongFunction<R> |
| double型 | 総称型 | DoubleFunction<R> |
| 総称型 | int型 | ToIntFunction<T> |
| 総称型 | long型 | ToLongFunction<T> |
| 総称型 | double型 | ToDoubleFunction<T> |
Predicateインタフェースの特化型
| 引数 | 戻り値 | インタフェース |
|---|---|---|
| int型 | boolean型 | IntPredicate |
| long型 | boolean型 | LongPredicate |
| double型 | boolean型 | DoublePredicate |
ストリームAPI(チャプター4.2参照)ではこれらのインタフェースを引数や戻り値に持つものがあります。ただしこれらのインタフェースをすべて理解する必要はなく、インタフェースの名前からどういった特性を持つものかを判断できるようになっておけば十分です。例えば、汎用的なFunction<T,R>という関数型インタフェースの派生としてToIntFunction<T>というものがありますが、これは「戻り値がint型に固定化された関数型インタフェースである」と名前から判断が可能です。
4.1.6 メソッド参照
メソッド参照とは
メソッド参照とは、ラムダ式と同様に、関数型インタフェースを実装するための手段の1つです。
関数型インタフェースには、メソッド参照を直接代入することができます。
メソッド参照は以下のような記法で表されます。
クラス名::メソッド名
または
参照型変数名::メソッド名
この両者の使い分けは後述しますが、まずスタティックメソッドのメソッド参照は「クラス名::メソッド名」と記述します。
例えばSystem.out.println()メソッドのメソッド参照であれば、System.out::printlnになります。
このメソッド参照は、関数型インタフェースに代入することが可能です。ただしこのとき、代入対象となる関数型インタフェースの抽象メソッドとメソッド参照におけるメソッドは、対応していなかればなりません。対応と言っているのは、具体的には、引数の個数および型と、戻り値の型が、すべて一致している必要がある、という意味です。例えばConsumerであれば、引数が1つで戻り値はないインタフェースのため、同じく引数が1つで、戻り値がないSystem.out.println()メソッドのメソッド参照を代入することができます。
ただしメソッド参照はあくまでも、コードブロックが「引数をそのまま渡すだけの単一のメソッド呼び出し」の場合に限り、ラムダ式を簡易的に置き換えるためのものです。コードブロックが「引数をそのまま渡すだけの単一のメソッド呼び出し」の範疇を超える場合は、ラムダ式を実装する必要があります。
スタティックメソッドのメソッド参照(1)
ここではまず、スタティックメソッドのメソッド参照について取り上げます。
以下のコードは、System.out.println()メソッドのメソッド参照をConsumer型変数に代入し、accept()メソッドを呼び出してその処理を実行しています。
Consumer<String> c = System.out::println;
c.accept("Hello, World!"); // コンソールに"Hello, World!"と表示される
これは、ラムダ式による以下のコードと同義です。
Consumer<String> c = (str) -> { System.out.println(str); };
c.accept("Hello, World!");
スタティックメソッドのメソッド参照(2)
次にメソッド参照の別の例として、既出の以下のメソッドを改めて取り上げます。このメソッドは関数型インタフェースConsumerを受け取り、ループ処理によって「何らかの副作用を発生させる」ためのメソッドです。
void doList(Consumer<String> c) {
List<String> strList = Arrays.asList("foo", "bar", "baz");
for (String str : strList) {
c.accept(str);
}
}
このメソッドには、以下のようにメソッド参照を渡すことができます。
doList(System.out::println);
これは、ラムダ式による以下のコードと同義です。
doList(str -> System.out.println(str));
ただし、以下のようにコードブロックが「引数をそのまま渡すだけの単一のメソッド呼び出し」の範疇を超える場合は、メソッド参照は使えません。
// 引数を文字列連結し、その結果をコンソール表示する
doList(str -> System.out.println(str + str));
// 引数の文字列長を判定した上でコンソール表示する
doList(str -> {
if (3 < str.length()) System.out.println(str);
});
スタティックメソッドのメソッド参照(3)
既出の例は、「System.out.println()のメソッド参照をConsumerに代入する」というものでしたが、メソッド参照は自作のメソッドであっても問題ありません。またメソッド参照は、Consumerに限らず、様々な関数型インタフェースに代入することができます。
例えば、以下のような足し算の機能を持ったStaticCalculatorクラスがあるものとします。
class StaticCalculator {
static int add(int x, int y) {
int result = x + y;
return result;
}
}
StaticCalculatorクラスのスタティックなadd()メソッド呼び出しを、ラムダ式で実装すれば、レッスン4.1.3で既出の関数型インタフェースであるCalcFunctionに代入可能です。
CalcFunction addFunc = (x, y) -> {return StaticCalculator.add(x, y);};
int answer = addFunc.calc(30, 10);
さらに上記コードのラムダ式は、「引数をそのまま渡すだけの単一のメソッド呼び出し」のため、以下のようにメソッド参照に置き換えることができます。
CalcFunction addFunc = StaticCalculator::add;
int answer = addFunc.calc(30, 10);
もちろん、CalcFunctionインタフェースは「引数を2つとり、任意の処理を実行し、その結果を返す」インタフェースのため、以下のようにBiFunctionに置き換えることも可能です。
BiFunction<Integer, Integer, Integer> addFunc = StaticCalculator::add;
int answer = addFunc.apply(30, 10);
この3つのコード(snippet_1~3)は、すべて同じ意味になります。
インスタンスメソッドのメソッド参照(1)
次に、インスタンスメソッドに対するメソッド参照を取り上げます。インスタンスメソッドに対するメソッド参照には以下の2つのケースがあり、それぞれ記述方法が異なります。
(1)ラムダ式の引数として渡された参照型変数に対するメソッド呼び出し
(2)ラムダ式の外部にローカル変数として置かれた参照型変数に対するメソッド呼び出し
まずは(1)です。レッスン4.1.5のPredicateインタフェースの具体例で登場した「ユーザーがある特定の条件を満たしているかをチェックするための、汎用的なメソッド」は、次のように呼び出していました。
boolean flag = checkUserSpec(alice, user -> user.isAdult());
UserクラスのisAdult()メソッドは、「大人かどうか」を判定するインスタンスメソッドです。このコードは、以下のようにメソッド参照を使って書き換えることができます。
boolean flag = checkUserSpec(alice, User::isAdult);
このようにインスタンスメソッドであっても、ラムダ式の引数(この例では変数user)に該当する参照型変数に対するメソッド呼び出しは、スタティックメソッドと同じように「クラス名::メソッド名」と記述します。
インスタンスメソッドのメソッド参照(2)
次に、「ラムダ式の外部にローカル変数として置かれた参照型変数に対するメソッド呼び出し」のためのメソッド参照を見ていきます。
以下のコードを見てください。
Printer printer = new Printer();
Consumer<String> c = msg -> printer.print(msg); // ラムダ式
c.accept("Hello, World!");
Printerクラスは、受け取った文字列をコンソールに表示するだけの、単一のprint()メソッドを持つクラスです。まずPrinterクラスのインスタンスを生成し、ラムダ式の中でそのprint()メソッドを呼び出しています。この例は、ラムダ式の引数に対するメソッド呼び出しではなく、ラムダ式の外部に位置するローカル変数に対するメソッド呼び出しを行っている点が、前項までとの違いです。
このようなラムダ式を、メソッド参照に置き換えると以下のようになります。
Printer printer = new Printer();
Consumer<String> c = printer::print; // メソッド参照
c.accept("Hello, World!");
このケースでは、メソッド参照は「参照型変数::メソッド名」と記述します。
メソッド参照まとめ
本レッスンでは、スタティックメソッドとインスタンスメソッド、それぞれのメソッド参照について見てきましたが、整理すると以下の表のようになります。
【表4-1-2】メソッド参照まとめ
| メソッドの種類 | 関数型インタフェースの引数 | ラムダ式の例 | メソッド参照の記法 |
|---|---|---|---|
| スタティックメソッド | 引数が0個 | () -> クラス名.メソッド名() | クラス名::メソッド名 |
| 引数が1個 | (引数1) -> クラス名.メソッド名(引数1) | ||
| 引数が2個 | (引数1, 引数2) -> クラス名.メソッド名(引数1, 引数2) | ||
| インスタンスメソッド ※ラムダ式の引数に対するメソッド呼び出し |
引数が1個 | (引数1) -> 引数1.メソッド名() | |
| 引数が2個 | (引数1, 引数2) -> 引数1.メソッド名(引数2) | ||
| インスタンスメソッド ※ラムダ式の外部ローカル変数に対するメソッド呼び出し |
引数が0個 | () -> 参照型変数名.メソッド名() | 参照型変数名::メソッド名 |
| 引数が1個 | (引数1) -> 参照型変数名.メソッド名(引数1) | ||
| 引数が2個 | (引数1, 引数2) -> 参照型変数名.メソッド名(引数1, 引数2) |
4.1.7 コレクションとラムダ式
forEach()メソッド
Java SEのコレクションフレームワークには、ラムダ式や関数型インタフェースを利用した数多くのAPIがあります。その中でも特に代表的なのが、ストリームAPIと呼ばれる一連の機能群です。ストリームAPIについては、チャプター4.2で詳細を説明しますが、このレッスンではそれ以外のAPIについて説明します。
まずリストやセットは、java.lang.Iterableインタフェースを実装しており、拡張for文によるループ処理が可能です。
またIterableインタフェースには、以下のようなforEach()メソッドが定義されており、繰り返し何らかの処理を実行することができます。
- void forEach(Consumer<? super T>)
このメソッドは、関数型インタフェースとしてConsumerを受け取るので、ラムダ式やメソッド参照を渡すことができます。リストやセットに対してこのメソッドを呼び出すと、各要素を順番に取り出しながら、受け取ったラムダ式またはメソッド参照を実行します。
例えばリストの場合は、以下のようなコードになります。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//【1】ラムダ式を渡す
list.forEach(x -> System.out.println(x));
//【2】メソッド参照を渡す
list.forEach(System.out::println);
このように、forEach()メソッドにラムダ式を渡したり【1】、メソッド参照を渡したり【2】することが可能です。
replaceAll()メソッド
リスト(java.util.Listインタフェース)には、以下のようなreplaceAll()メソッドが定義されています。
- void replaceAll(UnaryOperator<E>)
このメソッドは、関数型インタフェースとしてUnaryOperatorを受け取るので、ラムダ式を渡すことができます。UnaryOperatorは、T apply(T)という、引数と戻り値が同じ型になる関数型インタフェースです。
このメソッドを呼び出すと、リストの各要素を、その要素にラムダ式を適用した結果で置換することができます。ラムダ式により、複雑な置換ロジックであっても効率的に適用することができます。具体的には以下のコードを見てください。
List<String> strList = Arrays.asList("foo", "bar", "baz");
strList.replaceAll(str -> { // ラムダ式を渡す
return str.toUpperCase();
});
System.out.println(strList);
このようにreplaceAll()メソッドには、引数の型、戻り値の型が同一となるラムダ式を指定します。このコードを実行すると、リストの各要素が大文字に置換されます。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- 関数型プログラミングの手法や概念について。
- ラムダ式の記述方法について。
- 匿名クラスをラムダ式によって置き換える方法について。
- 関数型インタフェースの定義やラムダ式との関係について。
- ラムダ式による遅延実行やクロージャの仕組みについて。
- Java SEによって提供される様々な関数型インタフェースについて。
- メソッド参照の記述方法や関数型インタフェースとの関係について。
- コレクションへのラムダ式の適用について。