はじめに
自己紹介
皆さん、こんにちは、Udemy講師の斉藤賢哉です。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Basic編』の一部の範囲をカバーしたものです。『Java Basic編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをQiita内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの言語仕様や文法を正しく理解すると同時に、現場での実践的なスキル習得を目指している方
- 新卒でIT企業に入社、またはIT部門に配属になった、新米システムエンジニアの方
- 長年IT部門で活躍されてきた中堅層の方で、学び直し(リスキル)に挑戦しようとしている方
- 今後、フリーランスエンジニアとしてのキャリアを検討している方
- 「Chat GPT」のエンジニアリングへの活用に興味のある方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
- IT企業やIT部門の教育研修部門において、新人研修やリスキルのためのオンライン教材をお探しの方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
11.1 継承と多態性
チャプターの概要
このチャプターでは、オブジェクト指向言語の主要な特徴である継承と、多態性(継承によってクラスの振る舞いが変わること)について学びます。
継承と多態性は、Java言語の仕様全体の中でも最も理解が難しい仕組みの1つであり、最大の「山場」と言っても過言ではありません。難しいと感じた方は、いったんこのチャプターをスキップし、復習の中で改めて学んでもらっても良いでしょう。
11.1.1 継承の基本
継承とは
オブジェクト指向型言語の重要な仕組みの1つに「継承」があります。継承とは、すでに存在するクラスをベースにして新しいクラスを作成し、ベースになったクラスのメンバーを引き継いだり、上書きしたり、新しい機能を追加することです。この仕組みを使いこなすことで、クラスの再利用性を高め、開発効率を向上させることが可能になります。
継承において、ベースになるクラス(継承元)を親クラスと呼びます。また親クラスを継承して作られたクラスを、子クラスと呼びます。親クラスは基底クラスやスーパークラス、また子クラスは派生クラスやサブクラスと呼ばれることもありますが、本コースでは「親クラス」「子クラス」で統一します。
継承の考え方を以下の図に示します。
【図11-1-1】継承の考え方

このようなクラス間の継承関係をクラス図で表すと、以下のようになります。
【図11-1-2】クラス図(クラスの継承関係)

クラス図では継承関係は白抜き三角と実線で表します。
継承の宣言
親クラスを継承して子クラスを作成するためには、子クラスを以下のように宣言します。
class 子クラス名 extends 親クラス名 {
........
}
このように子クラスを作成するためには、class宣言をするとき、extendsキーワードによって親クラスを指定します。
継承におけるクラス間の関係
ここでは継承におけるクラス間の関係とルールを、図を用いて説明します。
【図11-1-3】Foo、Bar、Baz、Qux、Piyoの継承関係

この図にはFoo、Bar、Baz、Qux、Piyoという5つのクラスが登場しますが、継承におけるクラス間の関係は、このように階層構造で表すことができます。
まずFooクラスを継承し、BarクラスとQuxクラスを作成していますが、クラスの継承では、1つの親クラスを継承し、複数の子クラスを作ることが可能です。
またBarクラスを継承してBazクラスを作成していますが、子クラスを継承してさらに子クラスを作るといった、多段の継承も可能です。
ただし1つの子クラスが、複数の親クラスを持つこと(これを多重継承と呼ぶ)は、Javaでは認められていません。そのためQuxクラス(Fooクラスを継承)は、追加でPiyoクラスを継承することはできません。これは多重継承のメリットよりも、それによって生じる複雑さを回避する方が重要であるという、プログラミング言語としての設計上の判断です。
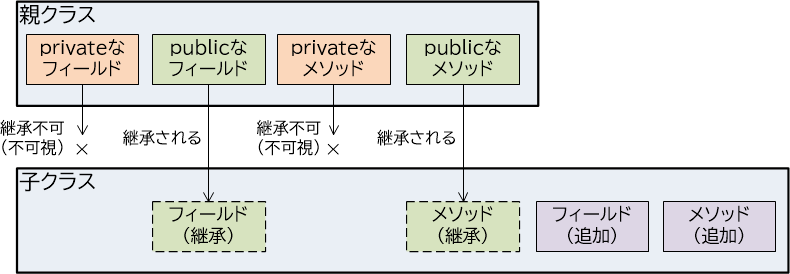
継承とフィールド・メソッド
親クラスのフィールドとメソッドが、子クラスにどのように引き継がれるのかは、フィールドおよびメソッドの可視性によります。すなわちprivateが付与されたフィールド、メソッドの場合は、子クラスであっても引き継がれません。またアクセス修飾子がない場合は、子クラスが親クラスと同一パッケージの場合は引き継がれますが、異なるパッケージの場合は引き継がれません。protectedが付与されたフィールド、メソッドの場合は、パッケージが異なっていたとしても、引き継がれます。最後にpublicが付与されたフィールド、メソッドの場合も、常に子クラスに引き継がれます。
【図11-1-4】継承とフィールド・メソッド
それではここで、このような継承の仕組みをコードで確認してみましょう。
親クラスであるFooと、Fooを継承した子クラスBar、それぞれのコードを次に示します。なおこれはあくまでも継承の仕組みを確認するためのコードなので、処理内容に必然性はありません。
public class Foo {
public int base = 100; //【1】
public int x; //【2】
public int add() { //【3】
return base + x;
}
}
public class Bar extends Foo { //【4】
public int y; //【5】追加
public int subtract() { //【6】追加
return base - x - y;
}
}
まずFooクラスは、初期値100のbaseフィールド【1】と、xフィールド【2】を持っています。またadd()メソッド【3】により、この2つのフィールドを加算した結果を返します。
次にBarクラスですが、extendsキーワードによってFooクラスを継承します【4】。
Barクラスの中を見ていくと、xフィールドとadd()メソッドは宣言がありませんが、Fooクラスから引き継がれているため、Barクラスはこれらのメンバーを保持していることになります。
yフィールド【5】は、Barクラスに新たに追加されたフィールドになります。
subtract()メソッド【6】も、Barクラスに新たに追加されたメソッドです。このメソッドはbaseフィールドからxフィールド、yフィールドを減算し、その結果を返します。
それではこのような継承関係を持ったFooクラス、Barクラスを対象に、それらのメンバーにアクセスしてみましょう。
まずはadd()メソッドです。以下のコードを見てください。
Bar bar = new Bar();
bar.x = 30;
int answer1 = bar.add();
このコードを実行するとBarインスタンスが生成され、xフィールドに30が代入されます。そしてFooクラスから継承されたadd()メソッドが呼び出され、変数answer1には130が格納されます。
次にsubtract()メソッドです。以下のコードを見てください。
bar.y = 10;
int answer2 = bar.subtract();
このコードを実行すると、Barクラスに追加されたsubtract()メソッドが呼び出され、「100 - 30 - 10」という演算により変数answer2には60が格納されます。
継承とコンストラクタ
親クラスのコンストラクタは、その可視性に関わらず子クラスには引き継がれません。従って子クラスでは、必要なコンストラクタを定義しなければなりません。ここで既出のFooクラスを、以下のように修正するものとします。
public class Foo {
public int base = 100;
private int x; //【1】
public Foo(int x) { //【2】
this.x = x;
}
public int getX() {
return x;
}
public int add() {
return base + x;
}
}
カプセル化の原則に則り、xフィールドをprivateにし【1】、その値を初期化するためのコンストラクタ【2】を定義しました。これに合わせる形で、Barクラスも以下のように修正します。
public class Bar extends Foo {
private int y; //【1】
public Bar(int x, int y) { //【2】
super(x); //【3】
this.y = y; //【4】
}
public int subtract() {
return base - getX() - y; //【5】
}
}
BarクラスもFooクラスと同様にyフィールドをprivateにし【1】、その値を初期化するためのコンストラクタ【2】を定義しました。コンストラクタを見ていくと、【4】によりyフィールドを初期化しています。
それではxフィールドは、どのように取り扱うべきでしょうか。BarクラスがFooクラスから引き継がれたadd()メソッドはxフィールドの値に依存するので、Barからは不可視ではある(privateのため)ものの、何らかの方法でxフィールドを初期化しなければなりません。そこでBarクラスのコンストラクタ内で、親であるFooクラスのコンストラクタを呼び出すことにより、xフィールドを初期化します【3】。
親クラスのコンストラクタは、以下の構文のように呼び出します。
super(引数1, 引数2, 引数3, ....);
このようにsuperキーワードに引数を指定することで、親クラスのコンストラクタを呼び出します。BarクラスのコンストラクタはBar bar = new Bar(30, 10)と呼び出しますが、その中でsuper(x)(xは30)と呼び出すことでFooクラスのxフィールドを初期化するのです。なおsuperキーワードによる親クラスのコンストラクタ呼び出しは、コンストラクタ内の先頭に記述しないとコンパイルエラーになるため、注意が必要です。
このコードではBarクラスからFooクラスのxフィールドは不可視になったため、subtract()メソッドも修正し、xフィールドの値はgetX()を経由して参照します【5】。
なお、今回の例では親クラスのフィールド(xフィールド)をprivateにしましたが、クラス間に継承関係がある場合に親クラスのフィールドをprotectedにする、という戦略があります。具体的には、Fooクラスのxフィールドをprotected int xと宣言します。アクセス修飾子protectedによって、公開範囲は同一パッケージ内に限定したまま、子クラスに限ってはパッケージに関わらず直接的なアクセスを可能にします。このようにすると子クラスにはフィールドが公開されるため、Barクラスのsubtract()メソッドはreturn base - x - yとすることができます。
11.1.2 メソッドのオーバーライド
オーバーライドとは
子クラスでは、親クラスから引き継いだメソッドを、上書きすることができます。
これをオーバーライドと呼びます。
オーバーライドするためには、子クラスのメソッドは、親クラスのメソッドに対して以下のような条件をすべて満たす必要があります。
- メソッド名が一致していること。
- 引数の数とデータ型が一致していること(引数名は不一致でも問題なし)。
- 戻り値のデータ型が一致しているか、またはその型の「下位方向の型」であること。
※下位方向の型 … 継承の場合は子クラスの型、インタフェースの場合は実装クラスの型 - アクセス修飾子が一致しているか、親クラスよりも可視性が広いこと
- throws句に指定可能なのは、親クラスのthrows句に指定された例外クラスと同じか、または、その型の「下位方向の型」であること。
この条件の説明の中にインタフェースや例外といった用語が出てきますが、インタフェースについてはチャプター12.1で、例外についてはチャプター19.1でそれぞれ取り上げるためここでは詳細は割愛します。
それでは、既出のBarクラスに以下のようなadd()メソッドを追加してみます。
@Override
public int add() { // オーバーライド
return base + getX() + y;
}
このメソッドは前述した条件を満たしているため、オーバーライドが成立します。
見慣れない@Overrideについては、次項で説明します。
Fooクラスのadd()メソッドはbaseフィールドとxフィールドを加算するものでしたが、Barクラスのadd()メソッドはそれに加えてyフィールドも加算します。
このメソッドを以下のように呼び出すと、
Bar bar = new Bar(30, 10);
int answer = bar.add();
オーバーライドされたadd()メソッドが呼び出され、140が返されます。
オーバーライドと@Overrideアノテーション
子クラスにおいてメソッドをオーバーライドするためには、前述したような条件を満たす必要があります。例えばBarクラスにprivate int add()というメソッドを宣言しようとすると、メソッドがオーバーライドされようとしているにも関わらずアクセス範囲が狭くなっているため、コンパイルエラーになります。逆にint add2()やint add2(int z)というメソッドは、親クラスのメソッドとは別物と見なされる(Barクラスに追加されたと見なされる)ため、宣言することが可能です。
またオーバーライドでは、開発者自身がオーバーライドしたつもりになっているにも関わらず、メソッド名やデータ型の不一致から、オーバーライドになっていなかった(追加されてしまった)というケースがあります。このような事態を回避するために、@Overrideアノテーションを利用します。
アノテーションとは、クラス、メソッド、フィールドなどの要素に対して「注釈」として付与するメタデータ記法のことで、「注釈インタフェース」と呼ばれることもあります。アノテーションは、ソースコード上においてオブジェクトとして存在しているにも関わらず、プログラム本体の振る舞いには関係しません。何らかのツールや別のソフトウェアに解釈されることによって、はじめて機能します。アノテーションの仕組みについては、『Java Advanced編』にて説明します。
話を戻します。
この@Overrideアノテーションをメソッドに付与すると「このメソッドはオーバーライド対象である」ことを、開発者がコンパイラに示すことができます。逆に言うとこのアノテーションが付与されているにも関わらず、オーバーライドの条件を満たせていない場合は、コンパイルエラーが発生します。
例えばBarクラスにint add2(int z)というメソッドを宣言し、@Overrideアノテーションを付与すると、コンパイルエラーになります。これはコンパイラによって「あなたはオーバーライドしたつもりのようですが、条件が満たされていませんよ」と言われていることを意味します。
このように@Overrideを利用すると、思わぬ不具合を回避することが可能になります。メソッドをオーバーライドする場合、特別な事情がない限りはこのアノテーションを利用すると良いでしょう。
@Overrideアノテーションをメソッドに付与すると「このメソッドはオーバーライド対象である」ことを、開発者がコンパイラに示すことができます。メソッドをオーバーライドする場合は、基本的にはこのアノテーションを使用してください。
オーバーライドメソッドから親クラスへのアクセス
メソッドのオーバーライドは親クラスのメソッドを丸ごと上書きしますが、場合によっては親クラスの実装を再利用したいケースがあります。このような場合は、オーバーライドしたメソッドから親クラスのオーバーライド元メソッドを呼び出します。
以下の構文を見てください。
super.メソッド名(引数1, 引数2, 引数3, ....);
このようにsuperキーワードにメソッド名をドットで繋ぐことによって、親クラスのメソッドを呼び出すことができます。
ここで既出のBarクラスで、オーバーライドされたadd()メソッドを再び取り上げ、以下のように修正します。
@Override
public int add() { // オーバーライド
int tmp = super.add(); //【1】
return tmp + y; //【2】
}
まず親クラスのadd()メソッドを呼び出し、その結果を受け取ります【1】。そしてその結果をもとに、親クラスとの差分にあたる「yの加算処理」を実装します【2】。
finalによる継承・オーバーライドの禁止
クラスにfinalキーワードを付与すると、クラスが継承されることを禁止することができます。またメソッドにfinalキーワードを付与すると、メソッドが子クラスでオーバーライドされることを禁止することができます。
例えばFooクラスのadd()メソッドに、以下のようにfinalキーワードを付与します。
public final int add() {
return base + x;
}
子クラスであるBarにおいて、このメソッドをオーバーライドしようとすると、コンパイルエラーが発生します。
このようにfinalキーワードによって継承およびオーバーライドを制御することにより、当該クラスを後で修正したとき、思わぬ不具合が発生することを抑止します。
子クラスから親クラスのフィールドへのアクセス
親クラスのフィールドは、アクセス修飾子によって不可視にならない限り子クラスに引き継がれます。このとき、子クラスで当該フィールドを再度宣言した場合の挙動について説明します。
まず親クラスのFooでは、baseフィールドが以下のように宣言されています。
public int base = 100;
子クラスのBarでもbaseフィールドを宣言し、以下のように初期値200を代入します。
public int base = 200;
このようにすると、同じ名前のbaseフィールドに、Fooクラスでは100、Barクラスでは200という値を、それぞれ保持することになります。このときBarクラス内では、2つのbaseフィールド(自身が保持するbaseフィールドとFooクラスが保持するbaseフィールド)が見えていることになるので、この両者を呼び分ける必要があります。
具体的には以下の構文のようにすると、親クラスのフィールドにアクセスできます。
super.フィールド名
ただしこの例のように、そもそもフィールド値をコードに直接埋め込むケースは、必ずしも多くはありません。また親クラスのフィールドは、前述したようにコンストラクタからsuper呼び出しによって初期化するのが基本です。
実際のJavaアプリケーションでは、親クラスと子クラスの間でフィールド値が異なるケースは殆どないため、この機能は参考程度に理解しておけば十分でしょう。
11.1.3 抽象クラスと抽象メソッド
抽象化プログラミングとは
抽象化プログラミングは、オブジェクト指向言語の重要な特徴の1つです。抽象化プログラミングの説明をする前に、まず抽象化および具体化という概念について整理します。
一般的に抽象化とは、「モノ」や「概念」の具体性を排除し、認識するべき特性のみを抽出することを指します。また具体化は抽象化の対義語です。
この概念をECサイトの「顧客モデル」を例に説明します。顧客には一般会員やゴールド会員といった種別があるものとすると、顧客が「抽象的なモノ」であり、一般会員やゴールド会員が「具体的なモノ」になります。このとき「ゴールド会員は顧客である」のように、「抽象的なモノ」と「具体的なモノ」の間には、「~である」という関係(is-a関係)が成り立ちます。
抽象化の考え方を取り入れることによって、複雑さが解消されたり効率化が促進されたりします。例えば「商品を発送する」という行為は顧客を対象にしますが、その顧客が一般会員であろうとゴールド会員であろうと、処理に影響は受けません。言い方を替えると「関心がない」のです。
逆に「ポイントを加算する」という行為は、加算されるポイントが顧客種別によって変わるとすると、顧客が一般会員なのかゴールド会員なのかを、具体的に知る必要があるでしょう。
【図11-1-5】抽象化プログラミングの考え方

抽象化プログラミングとは、このような考え方をソフトウェア開発に適用することを意味します。継承の仕組みによって「抽象的なモノ」を親クラスに、「具体的なモノ」を子クラスとして実装します。このようにすると外部から「顧客モデル」を見た時に、自身にとって関心のある情報のみに集中すればよくなる(不必要な情報は知らずに済む)ため、複雑さが取り除かれる、というわけです。
それではJavaで抽象化プログラミングをどのように実現するのか、次項から見ていきましょう。
抽象化プログラミングによって、複雑さが解消されたり効率化が促進されたりします。
抽象メソッドとは
Javaで抽象化プログラミングを実現するためには、抽象メソッドや抽象クラスといった機能を利用します。まず抽象メソッドとは、メソッド宣言はするものの、それ自体は中身を持たない空のメソッドです。
抽象メソッドは以下のように宣言します。
abstract 戻り値型 メソッド名(型1 引数名1, 型2 引数名2, 型3 引数名3, ....);
このようにメソッドの先頭に、abstractキーワードを付与します。ブロックは不要で、宣言のみ記述したらセミコロンで閉じます。
抽象クラスとは
抽象クラスとは、メンバーとして1つ以上の抽象メソッドを保持するクラスです。抽象クラスに対して、抽象メソッドを1つも持たないクラスを具象クラスと呼びます。
抽象クラスは以下のように宣言します。
abstract class クラス名 {
....フィールド....
....コンストラクタ....
....メソッド....
....抽象メソッド....
}
このようにクラス宣言の先頭に、abstractキーワードを付与します。
抽象クラスと具象クラスの関係をクラス図に表すと、以下のようになります。ここではFooが抽象クラス、BarとQuxが、それを継承した具象クラスです。
【図11-1-6】クラス図(抽象クラス)

抽象クラスは、new演算子によって直接インスタンスを生成することはできません。内包する抽象メソッドが具体的な実装を持たないため、これは自明です。
抽象クラスはあくまでも親クラスであり、様々な具象クラスに継承されることを前提にしています。そして抽象クラスを継承した具象クラスは、抽象クラスに宣言された抽象メソッドを、オーバーライドによって実装します。
このように抽象クラスは、様々な具象クラスにとっての共通実装を提供します。そして具象クラスの種類によって異なる振る舞いは抽象メソッドとして宣言し、その実装は具象クラスに任せます。
抽象クラスの存在意義
レッスン11.1.1~11.1.2では、親クラスが具象クラスとなるケースを取り上げました。親クラスが、具象クラスであろうとも、抽象クラスであろうとも、共通実装を提供できる点は、何ら変わりません。また子クラスで機能追加が必要なのであれば、それを差分として子クラスで実装すればよい点も同じです。
それでは、抽象クラスを利用する意義はどこにあるのでしょうか。実は抽象クラスを継承した具象クラスでは、抽象メソッドをオーバーライドすることが、コンパイラによって強制されます。このような仕様により、多態性(ポリモーフィズム)を実現できる点が抽象クラスの最大の恩恵です。
なお多態性については、レッスン11.1.5にて詳細を説明します。
抽象クラスの具体例
それではここで、先に取り上げたECサイトの「顧客モデル」をもとに、抽象クラスの挙動を説明します。「顧客モデル」における顧客には、一般会員とゴールド会員という2つの種別があったのを思い出してください。
これをクラス図に表すと以下のようになります。
【図11-1-7】クラス図(顧客モデル)

まず「抽象的なモノ」である顧客は、CustomerBaseクラスとして作成します。そして「具体的なモノ」である一般会員とゴールド会員は、それぞれGeneralCustomerクラス、GoldCustomerクラスとして作成します。CustomerBaseクラスは抽象クラスとし、GeneralCustomerクラスとGoldCustomerクラスは、それを継承します。
それではコードを見ていきましょう。CustomerBaseクラスは以下のようになります。
public abstract class CustomerBase {
protected int id; // ID
protected String name; // 名前
protected int point; // ポイント
// コンストラクタ
public CustomerBase(int id, String name) {
this.id = id;
this.name = name;
}
// アクセサメソッド
........
//【1】購入金額の上限をチェックする(共通実装)
public boolean overTotalPrice(int totalPrice) {
if (1_000_000 < totalPrice) {
return true;
}
return false;
}
//【2】ポイントを加算する(抽象メソッド)
public abstract void addPoint(int value);
}
このクラスでは、顧客の共通的な属性として、ID、名前、そしてポイントをフィールドとして宣言しています。これらのフィールドは子クラスから直接アクセスできるように、アクセス修飾子はprotectedにしています。そして外部のクラスからメソッド経由でアクセスできるように、アクセサメソッドを実装しています。顧客としての振る舞いには、購入金額の上限チェック【1】やポイント加算【2】といったものがあるとします。これらのうち、購入金額の上限チェック(100万円を超えると上限オーバー)は顧客種別に関わらず同じのため、このクラスに直接実装しています。またポイント加算の方は、一般会員とゴールド会員とで仕様が異なるため、抽象メソッドとして宣言しています。
次にGeneralCustomerクラスのコードを示します。
public class GeneralCustomer extends CustomerBase {
// コンストラクタ
public GeneralCustomer(int id, String name) {
super(id, name);
}
// ポイントを加算する(オーバーライド)
@Override
public void addPoint(int totalPrice) {
int point = (int) (totalPrice * 0.05); // 購入金額の5%
this.point = this.point + point;
}
}
このように具象クラスであるGeneralCustomerクラスは、抽象クラスであるCustomerBaseクラスを継承して作成します。一般会員ではポイントは「購入金額の5%が加算される仕様」だとすると、その仕様に則りaddPoint()メソッドをオーバーライドして、ポイント加算処理を実装します。前述したように、このクラスでaddPoint()メソッドをオーバーライドしないとコンパイルエラーが発生します。
次にGoldCustomerクラスのコードを示します。
public class GoldCustomer extends CustomerBase {
// コンストラクタ
public GoldCustomer(int id, String name) {
super(id, name);
}
// ポイントを加算する(オーバーライド)
@Override
public void addPoint(int totalPrice) {
int point = (int) (totalPrice * 0.1); // 購入金額の10%
this.point = this.point + point;
}
}
GoldCustomerクラスも同様に、抽象クラスであるCustomerBaseクラスを継承して作成します。ゴールド会員ではポイントは「購入金額の10%が加算される仕様」だとすると、その仕様に則り、addPoint()メソッドをオーバーライドして、ポイント加算処理を実装します。やはりこのクラスでも、addPoint()メソッドをオーバーライドしないと、コンパイルエラーが発生します。
これで「顧客モデル」を表す3つのクラスの実装は完成です。
それではここで、これらのクラスの振る舞いを具体的に見ていきましょう。まずはGeneralCustomerクラスです。
CustomerBase alice = new GeneralCustomer(1, "Alice");
int totalPrice = 100_000; //購入金額
if (alice.overTotalPrice(totalPrice)) { //【1】
// 上限チェック違反だった場合の処理
}
alice.addPoint(totalPrice); //【2】
GeneralCustomerクラスのインスタンスを生成し、overTotalPrice()メソッドを呼び出す【1】と、CustomerBaseクラスの共通実装が呼び出され、上限チェックが行われます。このコードでは100万円の上限に対して、購入金額が10万円だったため、上限チェック違反は発生しません。またaddPoint()メソッドを呼び出す【2】と、一般会員の仕様に応じて、購入金額の5%がポイントとして加算されます。
次にGoldCustomerクラスです。
CustomerBase bob = new GoldCustomer(2, "Bob");
int totalPrice = 200_000; //購入金額
if (bob.overTotalPrice(totalPrice)) { //【1】
// 上限チェック違反だった場合の処理
}
bob.addPoint(totalPrice); //【2】
GoldCustomerクラスのインスタンスを生成し、overTotalPrice()メソッドを呼び出す【1】と、CustomerBaseクラスの共通実装が呼び出され、上限チェックが行われます。またaddPoint()メソッドを呼び出す【2】と、ゴールド会員の仕様に応じて、購入金額の10%がポイントとして加算されます。
このように抽象クラスを利用すると、共通的な機能を、親クラスである抽象クラスに、まとめて実装することができます。また子クラスごとに異なる振る舞いは、抽象メソッドとして宣言することで、それを子クラスでオーバーライドすることを強制することができます。
11.1.4 クラス型変数のキャスト
キャストとは
レッスン3.4.2でも触れたとおり、Javaでは、型と型の間に互換性がある場合に限り、型を変換することが可能です。このような型変換のことをキャストと呼びます。
レッスン3.4.2で取り上げたのは、プリミティブ型のキャストでしたが、ここでの対象はクラス型(参照型)です。クラスのキャストは、次のレッスンで取り上げる多態性を理解する上で前提になるため、先に説明します。
クラス型の場合、クラスとクラスが継承関係にある場合に限り、型を変換することができます。このとき階層の上位(親クラスの方向)にキャストすることを、アップキャスト、または単にキャストと呼びます。上位へのキャストは、暗黙的に行われます。
階層の下位(子クラスの方向)にキャストすることを、ダウンキャストと呼びます。下位へのキャストは、プリミティブ型と同様に、キャスト演算子を指定して明示的に行う必要があります。
またこのように型変換が可能な場合、クラス間に「互換性がある」という言い方をします。
キャストのルール
クラス型のキャストは、以下のようなルールに基づきます。なお説明に出てくる「インスタンス生成元クラス」とは、new演算子によってインスタンスを生成したクラスのことを表します。
- インスタンス生成元クラスよりも、上位のクラス型にキャストすることはできる(互換性がある)。
- 一度上位のクラスにキャストされた後、下位のクラス型にダウンキャストすることはできる(互換性がある)。
ただしそれは、当該上位クラスからインスタンス生成元クラスの間に位置するクラスに限定される。 - インスタンス生成元クラスよりも下位のクラス型にキャストしようとすると、エラーが発生する(互換性がない)。
※コンパイルはとおるが、実行時にClassCastException例外が発生する(チャプター19.1参照)。 - インスタンス生成元クラスと継承関係のないクラス型にキャストしようとすると、エラーが発生する(互換性がない)。
※コンパイルはとおるが、実行時にClassCastException例外が発生する(チャプター19.1参照)。
次項以降の前提として、5つのクラスFooクラス、Barクラス、Bazクラス、Quxクラス、Hogeクラスが、以下の図のような継承関係にあるものとします。そしてQuxクラスのインスタンスを題材に、キャストの仕組みを具体的に見ていきます。
【図11-1-8】前提となるクラスの継承関係

キャストの具体例
まず前項のルール(1)にように、QuxクラスのインスタンスはFooクラスにキャストすることができます。すなわち以下のコードのようなことが可能です。
Foo foo = new Qux();
このコードにおける変数fooは、宣言された型はFoo、インスタンス生成元の型がQuxになるため、両者は外形的には不一致ですが、互換性がある場合はこのような代入が成り立ちます。
なおこのようなキャストは、変数の代入文だけで発生するとは限りません。以下のコードのように、Foo型の引数を受け取るメソッドがあった場合、Foo型変数への代入が行われます。
void doSomething(Foo foo) {
// このメソッド呼び出しで、Foo型変数への代入が行われる
}
従って外部からこのメソッドに対して、Quxクラスのインスタンスを渡すことが可能です。
ダウンキャストの具体例
今度はFoo foo = new Qux()によって初期化された変数fooに対して、様々なダウンキャストを試みます。まずルール(2)のように、一度Fooクラス型にキャストした変数を、Bar型やQux型にダウンキャストすることが可能です。
Bar bar = (Bar) foo;
Qux qux = (Qux) foo;
このようにダウンキャストの場合は、キャスト演算子が必要です。
次にルール(3)のように、この変数をHoge型にキャストしようとすると、実行時にClassCastException例外が発生します。
Hoge hoge = (Hoge) foo; // 実行時例外
変数fooはQux型としてインスタンス生成されており、それよりも下位のHoge型とは互換性がないため、キャストはできません。このように構造的に継承関係にあったとしても、常に互換性がある(キャスト可能である)とは限らないため、注意が必要です。
次にルール(4)のように、この変数をBaz型にキャストしようとすると、実行時にClassCastException例外が発生します。
Baz baz = (Baz) foo; // 実行時例外
インスタンス生成対象であるQux型とキャスト対象であるBaz型は、同じFooクラスの子クラス同士ではありますが、両者に互換性はないためキャストはできません。
インスタンス判定
前項で説明したように、クラス型(参照型)の変数は、宣言の型とインスタンス生成元の型が常に一致しているとは限りません。
Foo foo = new Qux()によって初期化された変数fooは、宣言の型はFooですが、インスタンス生成元の型はQuxです。開発者自身が「Quxクラスでインスタンスを生成した」ことを分かっている場合は特に問題ありませんが、例えば以下のコードのように、メソッドでクラス型変数を受け取る場合は、宣言の型は分かっても、インスタンス生成元となった型は分かりません。
void doSomething(Foo foo) {
// 引数fooの型は分かるが、インスタンス生成元は分からない
}
通常は宣言の型(上記の例ではFoo型)のみを意識すれば良いケースが大半ですが、ダウンキャストする場合や、インスタンス生成元の型によって分岐する場合など、互換性の判定が必要なケースがあります。
このように変数の互換性判定が必要な場合は、instanceof演算子を使います。
変数名 instanceof クラス名
instanceof演算子に変数名とクラス名を指定すると、当該の変数がクラスと互換性がある場合にtrue、互換性がない場合にfalseが返ります。
ここで再び、前項で例として用いたクラスの継承関係を示します。
【図11-1-8】前提となるクラスの継承関係

Foo foo = new Qux()によって初期化された変数fooについて、instanceof演算子で互換性を判定すると以下のようになります。
if (foo instanceof Foo) // true
if (foo instanceof Bar) // true
if (foo instanceof Baz) // false
if (foo instanceof Qux) // true
if (foo instanceof Hoge) // false
instanceof演算子を使って互換性を判定できれば、その結果に応じたダウンキャストが可能です。
void doSomething(Foo foo) {
if (foo instanceof Qux) {
Qux qux = (Qux) foo;
// 変数quxに対する処理
}
}
互換性判定を行わずにダウンキャストしてもコンパイルはとおりますが、互換性がない型(この例ではBaz型やHoge型)が渡されると、実行時に例外が発生してしまいます。
このコードのようにinstanceof演算子によって互換性を判定すれば、問題なくダウンキャストが可能です。
instanceofのパターン・マッチング
前項で説明したinstanceof演算子は、互換性の判定をした後に変数をダウンキャストする、という処理で利用されるケースが大半です。このような処理は、Java 16でサポートされたinstanceofのパターン・マッチングを使用すると、簡潔にコードを記述することができます。
instanceofのパターン・マッチングの構文を、以下に示します。
キャスト前変数名 instanceof クラス名 キャスト後変数名
このように記述すると、互換性判定が真の場合に指定した変数へのキャストが行われ、その結果が「キャスト後変数」に代入されます。
この機能を使うと、前項で取り上げたdoSomething()メソッドは、以下のように書き換えることができます。
void doSomething(Foo foo) {
if (foo instanceof Qux qux) {
// 変数quxに対する処理
}
}
11.1.5 多態性(ポリモーフィズム)
多態性とは
多態性とは、クラスの振る舞いが、インスタンス生成元になったクラスの種類によって変わることを意味します。多態性は、ポリモーフィズムとも呼ばれます。
ここでは前項と同じように、Foo、Bar、Bazという3つのクラスを用いて、多態性について説明します。
【図11-1-9】前提となるクラスの継承関係

Fooクラスは抽象クラスで、抽象メソッドとしてdoSomething()メソッドが定義されているものとします。
Fooクラスのコードを、次に示します。
public abstract class Foo {
public abstract void doSomething();
}
このとき、Fooクラスを継承したBarクラス、Bazクラスは、前述したように、doSomething()メソッドをオーバーライドしなければなりません。
Barクラス、Bazクラスのコードを、次に示します。
public class Bar extends Foo {
@Override
public void doSomething() {
System.out.println("これはBarです");
}
}
public class Baz extends Foo {
@Override
public void doSomething() {
System.out.println("これはBazです");
}
}
このような3つのクラスを前提に、多態性の挙動を説明します。以下のコードを見てください。
Foo foo1 = new Bar(); //【1】
Foo foo2 = new Baz(); //【2】
foo1.doSomething(); //【3】"これはBarです"
foo2.doSomething(); //【4】"これはBazです"
まずBarクラスのインスタンスを生成し、キャストによってFooクラス型で保持します【1】。また同じように、Bazクラスのインスタンスを生成し、キャストによってFooクラス型で保持します【2】。このとき、変数foo1と変数foo2は、外形的にはいずれもFooクラス型です。
ここでFooクラスには、doSomething()メソッドが宣言されていたことを思い出してください。つまりfoo1とfoo2は、メンバーとしてdoSomething()メソッドを持っています。ただし同じdoSomething()メソッドであっても、foo1とfoo2とでは、振る舞いが異なります。具体的にはfoo1のdoSomething()メソッドを呼び出すと、インスタンス生成元クラスであるBarクラスのdoSomething()メソッドが呼び出されます【3】。一方でfoo2のdoSomething()メソッドを呼び出すと、インスタンス生成元クラスであるBazクラスのdoSomething()メソッドが呼び出されます【4】。要は、変数の型がキャストによってどのように変わろうとも、あくまでも呼び出されるのは、インスタンス生成元になったクラスのメソッドなのです。
このように、変数の外形的には同じクラス型であるにもかかわらず、生成元になったインスタンスの実装に応じて、メソッドの振る舞いが変わります。同じ型でありながら、それが多様な形態を持つことから、多態性と呼ばれるわけです。
多態性と抽象クラス
前項では、多態性の挙動について説明しました。説明の中ではFooクラスを抽象クラスにしていましたが、これを具象クラスにしてdoSomething()メソッドをFooの中に定義しても、この例では同じような挙動になります。
では、Fooクラスを抽象クラスにする必然性はどこにあるのでしょうか。それは、親であるFooクラスではdoSomething()メソッドを実装する必要がなく、逆にそれを継承したBarクラス、Bazクラスでは、doSomething()メソッドの実装が強制される、という点にあります。
抽象化プログラミングでは、「抽象的なモノ」には「何が実装されているか知る必要がない」わけですが、裏を返すと「具体的なモノ」には「必ず何かが実装されていなければならない」ことになります。このような考え方がコンパイラによって保証される点が、抽象クラスを利用する最大の目的と言えるでしょう。
多態性の具体例
ここではレッスン11.1.3でも登場したECサイトの「顧客モデル」をもとに、多態性のメリットについて説明します。
「顧客モデル」における顧客には、一般会員とゴールド会員という2つの種別があったのを思い出してください。まず「抽象的なモノ」である顧客は、CustomerBaseクラスとして定義します。そして「具体的なモノ」である一般会員とゴールド会員は、それぞれGeneralCustomerクラス、GoldCustomerクラスとして定義します。CustomerBaseクラスは抽象クラスとし、GeneralCustomerクラスとGoldCustomerクラスは、それを継承します。
クラス図は既に登場済みですが、ここに再掲載します。
【図11-1-7】クラス図(顧客モデル)

ここで改めて、CustomerBaseクラス、GeneralCustomerクラス、GoldCustomerクラスの順に、コードを示します。
public abstract class CustomerBase {
protected int id; // ID
protected String name; // 名前
protected int point; // ポイント
// コンストラクタ
public CustomerBase(int id, String name) {
this.id = id;
this.name = name;
}
// アクセサメソッド
........
//【1】購入金額の上限をチェックする(共通実装)
public boolean overTotalPrice(int totalPrice) {
if (1_000_000 < totalPrice) {
return true;
}
return false;
}
//【2】ポイントを加算する(抽象メソッド)
public abstract void addPoint(int value);
}
public class GeneralCustomer extends CustomerBase {
// コンストラクタ
public GeneralCustomer(int id, String name) {
super(id, name);
}
// ポイントを加算する(オーバーライド)
@Override
public void addPoint(int totalPrice) {
int point = (int) (totalPrice * 0.05); // 購入金額の5%
this.point = this.point + point;
}
}
public class GoldCustomer extends CustomerBase {
// コンストラクタ
public GoldCustomer(int id, String name) {
super(id, name);
}
// ポイントを加算する(オーバーライド)
@Override
public void addPoint(int totalPrice) {
int point = (int) (totalPrice * 0.1); // 購入金額の10%
this.point = this.point + point;
}
}
さてこのような顧客モデルを対象に、ECサイトとしての取引を表すクラスを作成します。
以下のコードを見てください。
public class Transaction {
// 注文する
public void order(CustomerBase customer, int totalPrice) {
if (customer.overTotalPrice(totalPrice)) {
return; // ここでは便宜上、何もしないでリターンする
}
customer.addPoint(totalPrice);
........
}
}
このTransactionクラスのorder()メソッドは、引数として処理対象の顧客(CustomerBase型)と購入金額を受け取ります。そして購入金額の上限チェックをした後、購入金額に応じたポイント加算処理を行います。前述したようにポイントは、一般会員の場合は購入金額の5%が加算され、ゴールド会員の場合は購入金額の10%が加算されるという仕様でした。ポイントの加算処理は、GeneralCustomerクラス、GoldCustomerクラスのaddPoint()メソッドに実装されていますが、同じCustomerBaseクラスであっても、インスタンス生成の元になったクラスの実装に応じて振る舞いが変わります。つまり引数として渡されたCustomerBase型が、GeneralCustomerクラスとしてインスタンス生成された場合は購入金額の5%が加算され、GoldCustomerクラスとしてインスタンス生成された場合は購入金額の10%が加算される、というわけです。
ここで注目していただきたいのが、このorder()メソッドの中には、顧客種別(一般会員かゴールド会員か)によって処理を切り替えるための条件分岐が一切ない、ということです。このメソッドの処理は「抽象的なモノ」としての顧客を対象としており、それがどんな顧客なのかについて関心がありません。顧客種別を知る必要がないわけですから、必然的に条件分岐も不要ということになります。
このように多態性を利用すると、振る舞い方が自動的に切り替わるため、条件分岐が必要なくなります。
それではこのTransactionクラスによって、ポイントがどのように加算されるのかを確認してみましょう。以下のコードを見てください。
CustomerBase alice = new GeneralCustomer(1, "Alice"); // Aliceは一般会員
CustomerBase bob = new GoldCustomer(2, "Bob"); // Bobはゴールド会員
Transaction tran = new Transaction();
tran.order(alice, 100_000); // Aliceに10万円分の購入あり
tran.order(bob, 200_000); // Bobに20万円分の購入あり
このコードを実行すると、一般会員であるAliceには5000ポイントが加算され、ゴールド会員であるBobには20000ポイントが加算されます。
さて、多態性のメリットはこれだけには留まりません。真の恩恵は、アプリケーションとしての拡張性にあります。
ここで仮にこの「顧客モデル」に、新たにプラチナ会員という種別が増えたとき、どのような対応が必要になるかを考えてみましょう。プラチナ会員はゴールド会員の上位の位置付けとなるため、ポイントは「購入金額の15%が加算される仕様」だとします。このときorder()メソッドの中で、顧客種別に応じた条件分岐を行っていたとしたら、新たにプラチナ会員に対する分岐を追加する必要がありますが、多態性を利用するとその必要はありません。このクラスに限っては影響は局所的かもしれませんが、実際の開発ではアプリケーション全体の中から同じように「顧客種別に応じて条件分岐しているロジック」を注意深く見つけ出し、それぞれ対応する必要があります。
このように多態性を利用すると、処理の凝集性が高まり、仕様変更時の影響を極小化することができるため、アプリケーションとしての拡張性が高まるのです。
多態性とダウンキャスト
これまで説明してきたように、多態性では、外形的には上位クラスの型であっても、その振る舞いがインスタンス生成元に応じて変わります。ただし場合によっては、上位クラスから、インスタンス生成元になった下位クラスに、ダウンキャストしなければならないケースがあります。それは当該の下位クラスで何らかの機能が追加されており、それを呼び出す必要があるケースです。処理としてはレッスン11.1.4で見てきたように、インスタンス判定を行ってからダウンキャストし、下位クラスに追加されたメソッドを呼び出します。
このような呼び出しは、本質的には多態性の思想に反しているため、設計上好ましいことではありません。ただし実際のアプリケーション開発では、常に完璧な設計ができるとは限りません。また時には設計を歪めてでも、現実的な解決が求められることもあります。そのような場合は、ダウンキャストによる呼び出しが必要なケースもある、という点を認識しておく必要があるでしょう。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- 継承とは、親クラスのメンバーを引き継いだり、上書きしたり、新しい機能を追加すること。
- 親クラスのフィールドとメソッドが、子クラスにどのように引き継がれるかは可視性によること。
- コンストラクタは継承されないが、superキーワードによって親クラスのコンストラクタを呼び出すことができること。
- 親クラスから引き継いだメソッドを上書きすることをオーバーライドと呼び、様々な条件があること。
-
@Overrideアノテーションは「オーバーライド対象である」ことを表すこと。 - finalキーワードによって、継承・オーバーライドが禁止されること。
- 継承では、親と子の間に「~である」という関係(is-a関係)が成り立つこと。
- 抽象化プログラミングの考え方や目的について。
- 抽象クラスや抽象メソッドの特徴や存在意義について。
- クラス型変数をキャストしたり、インスタンス判定したりする方法について。
- 多態性(ポリモーフィズム)の概念や目的について。