はじめに
自己紹介
皆さん、こんにちは、Udemy講師の斉藤賢哉です。私はこれまで、25年以上に渡って企業システムの開発に携わってきました。特にアーキテクトとして、ミッションクリティカルなシステムの技術設計や、Javaフレームワーク開発などの豊富な経験を有しています。
様々なセミナーでの登壇や雑誌への技術記事寄稿の実績があり、また以下のような書籍も執筆しています。
いずれもJava EE(Jakarta EE)を中心にした企業システム開発のための書籍です。中でも 「アプリケーションアーキテクチャ設計パターン」は、(Javaに限定されない)比較的普遍的なテーマを扱っており、内容的にはまだまだ陳腐化していないため、興味のある方は是非手に取っていただけると幸いです(中級者向け)。
Udemy講座のご紹介
この記事の内容は、私が講師を務めるUdemy講座『Java Basic編』の一部の範囲をカバーしたものです。『Java Basic編』はこちらのリンクから購入できます(セールス対象外のためいつも同じ価格)。また定価の約30%OFFで購入可能なクーポンをQiita内で定期的に発行していますので、興味のある方は、ぜひ私の他の記事をチェックしてみてください。
この講座は、以下のような皆様にお薦めします。
- Javaの言語仕様や文法を正しく理解すると同時に、現場での実践的なスキル習得を目指している方
- 新卒でIT企業に入社、またはIT部門に配属になった、新米システムエンジニアの方
- 長年IT部門で活躍されてきた中堅層の方で、学び直し(リスキル)に挑戦しようとしている方
- 今後、フリーランスエンジニアとしてのキャリアを検討している方
- 「Chat GPT」のエンジニアリングへの活用に興味のある方
- 「Oracle認定Javaプログラマ」の資格取得を目指している方
- IT企業やIT部門の教育研修部門において、新人研修やリスキルのためのオンライン教材をお探しの方
この記事を含むシリーズ全体像
この記事はJava SEの一部の機能・仕様を取り上げたものですが、一連のシリーズになっており、シリーズ全体でJava SEを網羅しています。また認定資格である「Oracle認定Javaプログラマ」(Silver、Gold)の範囲もカバーしています。シリーズの全体像および「Oracle認定Javaプログラマ」の範囲との対応関係については、以下を参照ください。
18.1 コレクションフレームワーク
チャプターの概要
このチャプターでは、複数のデータを一括して処理するための仕組みであるコレクションフレームワークについて学びます。
なおこのチャプターの内容は、チャプター5.1で取り上げた配列の考え方が前提になります。
18.1.1 コレクションとは
コレクションとは
コレクションとは、配列と同じように、複数のデータをまとめて保持し、一括して処理するため仕組みです。
コレクションは、Java SEが提供するコレクションフレームワークと呼ばれるAPIグループによって提供されます。コレクションフレームワークの最大の特徴は、様々なデータ構造が用意されており、それらに対する共通的なインタフェースがAPIとして提供される、という点にあります。コレクションの種類によっては、内部実装に配列を使っているものがありますが、配列を拡張した様々な機能が追加されています(サイズが可変長である点など)。
このような理由から、実際のJavaアプリケーション開発では、データをまとめて管理する場合は、配列よりもコレクションを使うケースが大半です。
コレクションフレームワークの全体像
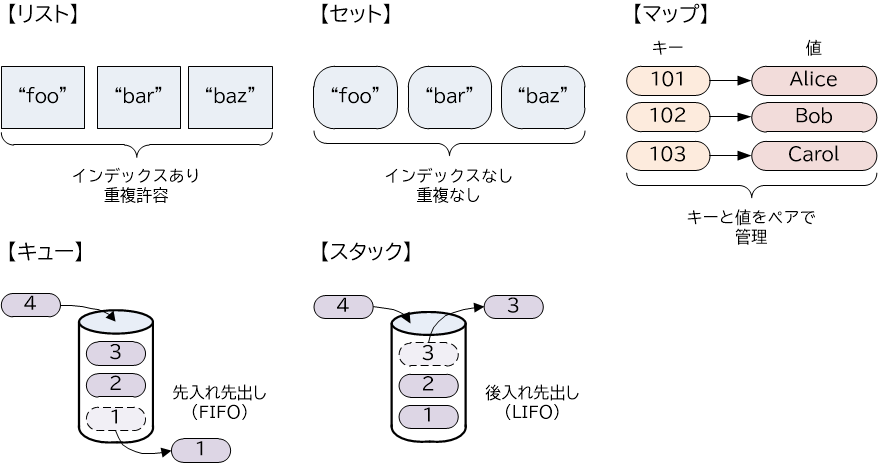
コレクションフレームワークのデータ構造には、リスト、セット、マップ、キュー、スタックなどがあります。
- リストとは、何らかの要素を格納するための汎用的なデータ構造で、配列と同じようにインデックスを持ちます。
- セットとは、数学の「集合」を抽象化したデータ構造で、インデックスを持たず、要素の重複は許容されません。
- マップとは、一意のキーと、そのキーに対応する値を、ペアとして管理するデータ構造です。
- キューとは、追加された要素を一列に並べ、先に追加された要素から順に取り出すデータ構造です。このような構造を先入れ先出し(FIFO:First In First Out)と呼びます。
- スタックとは、追加された要素を積み上げ、後に追加された要素から先に取り出すデータ構造です。このような構造を後入れ先出し(LIFO:Last In First Out)と呼びます。
【図18-1-1】コレクションフレームワークのデータ構造
以上のような様々なデータ構造は、コレクションフレームワークでは、以下のようなインタフェースとクラスによって提供されます。いずれもjava.utilパッケージに所属しています。
【表18-1-1】コレクションフレームワークの全体像
| データ構造 | 主なインタフェース | 実装クラス | 説明 |
|---|---|---|---|
| リスト | java.util.List | java.util.ArrayList | 配列を可変長に拡張したリストの実装 |
| java.util.LinkedList | 要素同士のリンクを相互に保持するリストの実装 | ||
| セット | java.util.Set | java.util.HashSet | 任意の順に要素が格納されるセットの実装 |
| java.util.LinkedHashSet | 追加順に要素が格納されるセットの実装 | ||
| マップ | java.util.Map | java.util.HashMap | 任意の順に要素が格納されるマップの実装 |
| java.util.LinkedHashMap | 追加順に要素が格納されるマップの実装 | ||
| キュー、スタック | java.util.Deque | java.util.ArrayDeque | キューとしてもスタックとしても使用できる両端キューの実装 |
これらの中でList、Set、Dequeは、いずれも親インタフェースとしてjava.util.Collectionを継承しています。一方MapのみがCollectionインタフェースを継承していないため、厳密にはコレクションではありませんが、文脈次第ではコレクションの1つと考えた方が分かりやすいでしょう。実際に「コレクションフレームワーク」という言い方をした場合、本コースでの定義のように、マップを含むのが一般的です。
またコレクションフレームワークを利用する場合、基本的に変数は上記表に記載のあるインタフェースの型で宣言しますが、どの実装クラスを使うのかは開発者が自身で選択します。いくつかの実装クラスの選択肢がある中で、特によく使われるのは、リストではArrayList、セットではHashSet、マップではHashMapであり、殆どのケースにおいて、これらのクラスだけで要件を充足できるでしょう。
なお上記以外に、似たようなデータ構造を表すクラスにVector、Hashtable、Stackなどがありますが、これらはコレクションフレームワーク以前からあるクラスであり、互換性維持のために残されているため本コースでは対象外とします。
18.1.2 リストの操作方法
リストとは
リストとは、何らかの要素を格納するための汎用的なデータ構造で、配列と同じようにインデックスを持ちます。格納される要素は、重複しても問題ありません。
リストの操作方法は、java.util.ListインタフェースのAPIによって定義されています。リストの実装クラスには、java.util.ArrayListやjava.util.LinkedListなどがあります。実装クラスの選択は開発者に委ねられますが、殆どのケースでArrayListが使われます。本コースでは、基本的にArrayListを使用して説明を進めます。
ArrayListクラスの特徴
ArrayListクラスは配列の拡張実装であり、サイズの拡大・縮小が可能な点が特徴です。内部的には、事前にある程度の大きさの配列を用意しておき、要素が追加されてサイズが不足するとより大きな配列を作成し、要素を新しい配列にコピーする、という処理が行われます。
配列を使う処理は、すべからくArrayListに置き換えることが可能です。ArrayListは要素に対してダイレクトにアクセスできるため、後述するLinkedListクラスよりもランダムアクセスは高速です。一方、要素を挿入・削除する場合は、その要素よりも後ろのすべての要素を1つずつずらす処理が発生するため、必ずしも効率的ではありません。
LinkedListクラスの特徴
LinkedListクラスは、1つ1つの要素が数珠つなぎのように、前後の要素に対するリンクを保持するデータ構造です。従って要素にダイレクトにアクセスしようとしても、リンクをたどっていく必要があるため、効率性は高くありません。一方、要素を挿入・削除する場合は、前後の要素のリンクを書き換えるだけで済むため、ArrayListよりも高速です。
リストの宣言と生成
ここではArrayListクラスを使い、リストを宣言および生成する方法を説明します。リストには任意のデータ型を格納することができますが、ここではString型を前提にします。
String型を格納するためのリストは、以下のように宣言および生成します。
List<String> list = new ArrayList<String>();
まず式の左辺から見ていきましょう。変数はList<String>型で宣言されていますが、これは「Stringを格納するためのList型」という意味です。もし「Integerを格納するためのList型」を宣言するのであれば、List<Integer>型になります。
<>はダイヤモンド演算子というもので、総称型において型パラメータを指定するための記法です。総称型1とは「ジェネリクス」と呼ばれることもありますが、コレクションフレームワークなどの汎用的な仕組みに対して、型をパラメータとして指定するための仕組みです。この仕組みのお陰で、このリストに対して型パラメータとして指定された型(ここではString型)以外の値を追加しようとすると、コンパイルエラーになります。またこのリストから値を取り出すときも、その値がString型であることがコンパイラによって保証されます。
このようにコレクションに総称型を適用することによって、Javaの大きな特徴の1つであるタイプセーフ(型安全)を実現しています。
次に式の右辺です。右辺では、リストの実装クラスのオブジェクトをnew演算子によって生成します。ここでは、最も代表的なリストの実装であるArrayListクラスを選択しています。ここでも型パラメータとしてString型を指定していますが、型パラメータに指定する型は、左辺と右辺で同一でないとコンパイルエラーが発生します。
なお型パラメータは、右辺では「型推論」によって自動的に決まるため、以下のように省略可能です。
List<String> list = new ArrayList<>();
この方がコードを簡潔に記述できるため、本コースではこの記述方法を基本形とします。
リストにおける変数宣言時の注意点
リストで変数を宣言するとき、実装クラスの型で変数を宣言することも可能です。
例えばArrayListの場合は、以下のようなコードです。
ArrayList<String> list = new ArrayList<>();
ただしこのコードは、変数listを実装クラスであるArrayList型で宣言しているため、後から別の実装クラスに差し替えることは困難です。その点インタフェースを利用すると、抽象化プログラミングの恩恵を受けることができます。コレクション(リストや後述するセットやマップなど)を使う場合は、特別な理由がない限りは、変数やメソッド引数はインタフェースの型で宣言するようにしましょう。
コレクションを使う場合は、変数(およびメソッド引数)は基本的にインタフェースの型で宣言するようにしましょう。
リストに型パラメータを適用する効果
前項までは、型パラメータによってコレクションに格納する型を指定していました。実は型パラメータを使わずに、以下のようにリストを宣言することも可能です。
List list = new ArrayList();
このようにリストを宣言すると、Object型を格納するためのリストが生成されるため、どのような型であっても追加は可能です。ただしこのリストからデータを取り出すときは、必要に応じてインスタンス判定をしながら、ダウンキャストをしなければなりません。要はこのリストにどのようなデータ型が格納されるのか、コンパイラで保証ができなくなり、型の安全性が損なわれるのです。
以上のような理由から、コレクション(リストや後述するセットやマップなど)を使う場合は、必ず型パラメータを指定するようにしましょう。
コレクションを使う場合は、必ず型パラメータを指定するようにしましょう。
ListインタフェースのAPI全体像
Listインタフェースには、リストを操作するための豊富なAPIが備わっています。このレッスンでは、その中から特に利用頻度の高いものをピックアップします。
以下の表は、このレッスンで取り上げるListインタフェースのAPI一覧です。なおこの表におけるEはElement(要素)の頭文字で、総称型の型パラメータを表す記号として、慣例的に使われているものの一種です。
| API(メソッド) | 説明 |
|---|---|
| boolean add(E) | このリストに、指定された要素を追加する(成否を返す)。 |
| void add(int, E) | このリストに、指定されたインデックスに要素を追加する。 |
| E get(int) | このリストから、指定されたインデックスの要素を返す。 |
| E set(int, E) | このリストに、指定されたインデックスの要素を置換する(置換された要素を返す)。 |
| Iterator<E> iterator() | このリストから、イテレータを返す。 |
| E remove(int) | このリストから、指定されたインデックスの要素を削除する(削除された要素を返す)。 |
| boolean remove(E) | このリストから、指定された要素を削除する(成否を返す)。 |
| void clear() | このリストから、要素を一括削除する。 |
| List<E> subList(int, int) | このリストから、指定されたインデックスの範囲に従って、サブリストを作って返す。 |
| boolean addAll(Collection<E>) | このリストに、指定された他のリストを統合する(成否を返す)。 |
| int size() | このリストのサイズを返す。 |
| boolean contains(E) | このリストに、指定された要素が含まれているかを判定して返す。 |
| boolean isEmpty() | このリストの要素が空かを判定して返す。 |
| static List<E> of(E...) | 指定された要素を含むイミュータブルなリストを生成して返す。 |
| T[] toArray(T[]) | このリスト内のすべての要素を、リスト内の並び順に従って配列にして返す。返される配列の型は、指定された配列の型と同じになる。 |
| Stream<E> stream() | このリスト内のすべての要素から、順次ストリームを生成して返す。※『Java Advanced編』参照 |
| Stream<E> parallelStream() | このリスト内のすべての要素から、並列ストリームを生成して返す。※『Java Advanced編』参照 |
次項からは、これらのAPIの使用方法について具体的に説明していきます。
要素の追加
リストに要素を追加するためには、add()メソッドを使用します。
List<String> list = new ArrayList<>(); //【1】
list.add("foo"); //【2】
list.add("bar"); //【3】
list.add("baz"); //【4】
まず【1】でString型リスト(変数list)を生成し、それに対して【2】~【4】のようにして文字列"foo"、"bar"、"baz"を追加します。なおこのリストに対してString型以外のデータを追加しようとすると、コンパイルエラーが発生します。
また以下のように、add()メソッドにインデックスを指定することもできます。
list.add(1, "qux");
このようにすると、指定されたインデックスに要素が挿入され、以降の要素は1つずつ後ろにスライドします。
要素の置換
リストの要素を置換するためには、set()メソッドに対象要素のインデックスを指定します。
例えばインデックスが1の要素を置換する場合は、以下のようなコードになります。
list.set(1, "qux");
要素の取得
ここでは、リストから要素を取得する方法を説明します。リストも配列と同じように、要素が追加された順にインデックスが自動的に割り当てられます。インデックスはリスト内の位置を表す整数で、0から始まります。リストから要素を取得するためには、get()メソッドに対象要素のインデックスを指定します。
例えばList型の変数listから、インデックスが0の要素を取り出す場合は、以下のようなコードになります。
String str = list.get(0);
なおリストの要素はString型であることが型パラメータで指定されているため、変数にString型以外を指定すると、コンパイルエラーが発生します。
拡張for文によるループ処理
リストはjava.lang.Iterableインタフェースを実装しているため、拡張for文によるループ処理が可能です。リストを一括で処理する場合、通常はインデックスを意識するケースは殆どないため、「古典的なfor文」よりも拡張for文を使うケースが一般的です。
例えばList型の変数listに対するループ処理は、以下のようになります。
for (String str : list) {
// 変数strに対して何らかの処理を行う
........
}
このように拡張for文を使用すると、リストの要素が順に変数strに代入されて、ループ処理が行われます(get()メソッドで取り出す必要はありません)。ループ内では、変数strに対して何らかの処理を行います。
なおこのリストの要素はString型であることが総称型で指定されているため、for文の変数にString型以外を指定すると、コンパイルエラーが発生します。
イテレータによるループ処理
拡張for文と同じように、リストでループ処理を行うための仕組みにイテレータ(Iteratorインタフェース)があります。イテレータは、java.util.Listインタフェースのiterator()メソッドによって取得します。
イテレータを利用したループ処理は、以下のようなコードになります。
Iterator<String> iter = list.iterator(); //【1】
while (iter.hasNext()) { //【2】
String str = iter.next(); //【3】
// 変数strに対して何らかの処理を行う
........
}
まずリストからIteratorを取得します【1】。イテレータによるループ処理には通常while文を使いますが、条件式にはIteratorのhasNext()メソッド呼び出しを指定します【2】。このメソッドは、リストから取り出すべき次の要素がなくなるとfalseを返す、という仕様になっています。
ループの中では、Iteratorのnext()メソッドによって要素を順に取り出し、処理を行います【3】。next()メソッドによってリストから要素が取り出されますが、このとき残りの要素が無くなるとhasNext()メソッドがfalseを返すため、ループが終了します。
さて、リストに対してループ処理を行う場合、拡張for文とイテレータのどちらを選択するべきでしょうか。基本的にはシンプルにコードを記述できるという観点から、拡張for文を利用するケースが大半でしょう。ただし拡張for文は、ループの中でのリストの変更(要素の削除など)には対応しておらず、実施するとConcurrentModificationExceptionという例外が発生します。従ってループの中でリストの変更が必要な場合はイテレータを利用するか、またはそもそもリストを変更するのではなく、新しいリストを作りループの中で必要な要素を追加し直すか、どちらかの方法を採用してください。
要素の削除
リストから要素を削除するためには、remove()メソッドにインデックスを指定します。
list.remove(1);
このようにすると指定されたインデックスから要素が削除され、以降の要素は1つずつ前にスライドします。
また以下のように、remove()メソッドに要素そのものを指定することも可能です。
boolean flag = list.remove("foo");
このremove()メソッドは、削除が成功したのか(true)、空振りしたのか(false)を、boolean型の戻り値で返します。
また以下のように、clear()メソッドを呼び出すと、すべての要素を削除することができます。
list.clear();
サブリストの作成
リストから新しいサブリスト(部分リスト)を作ることができます。以下のコードを見てください。
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 10; i++) {
list.add(i + 1); // 【1】1から10までの数値が格納されたリストを作る
}
List<Integer> subList = list.subList(3, 7); //【2】サブリストを作る
ここではまず、for文によって1から10までの数値が格納されたリストを作成します【1】。次に、作成したリストのsubList()メソッドを呼び出すと、指定されたインデックスの範囲から、新しいサブリストを作ることができます【2】。2つの引数は、サブリストの始点となるインデックス(これを含む)と、終点となるインデックス(これを含まない)です。従ってこのコードを実行すると、変数subListには、値4(インデックス3)から値7(インデックス6)までが格納されます。なおこのメソッドを呼び出しても、元のリストは変更されません。
リストの結合
リストとリストを結合するためには、addAll()メソッドを使用します。
List<String> list1 = new ArrayList<>();
.... // 上のリストに"foo"、"bar"を追加する
List<String> list2 = new ArrayList<>();
.... // 上のリストに"baz"、"qux"を追加する
list1.addAll(list2); //【1】
このコードでは、文字列"foo"、"bar"を持つlist1と、文字列"baz"、"qux"を持つlist2を結合しています。具体的には【1】のように、リストに対してaddAll()メソッドを呼び出すと、引数に指定されたリストの全要素が一番後ろに追加されます。
従ってこのコードを実行すると、変数list1には4つの要素、"foo"、"bar"、"baz"、"qux"が格納されます。
リストの様々な作成方法
リストを作成する手順は、実装クラスのインスタンスを生成し、add()メソッドによって要素を追加する、というのが基本です。ただし、その他にもいくつかの方法があります。
まず、java.util.ArraysクラスのasList()メソッドを使う方法です。
List<String> list = Arrays.asList("foo", "bar", "baz");
このようにすると、要素として文字列"foo"、"bar"、"baz"を持つリストを簡単に作成することができます。ただしこのようにして作成したリストは固定長リストのため、後から要素を追加したり削除したりすることはできません(置換は可能)。
またListインタフェースに定義されたof()メソッド(スタティックメソッド)を使う方法もあります。
List<String> list = List.of("foo", "bar", "baz");
このようにしても、指定された要素を持つリストを作成可能です。ただしこのようにして作成したリストはイミュータブル(不変)のため、後から要素の追加・置換・削除などの操作はできません。
リストに対する様々な操作
ここでは、リストに対するその他の様々な操作を紹介します。
まずリストのサイズは、以下のようにsize()メソッドを呼び出すことによって取得します。
int s = list.size();
contains()メソッドは、指定された要素がリストに含まれているかどうかを判定し、その結果をboolean型で返します。
boolean flag = list.contains("foo");
isEmpty()メソッドは、要素が空であるかどうかを判定し、その結果をboolean型で返します。
boolean flag = list.isEmpty();
リストと配列との相互変換
リストと配列は、相互に変換することが可能です。Stringクラスのformat()メソッドなど、配列や可変引数を引数に取るAPIを呼び出す場合は、リストから配列への変換が必要です。
リストから配列への変換は、以下のようにtoArray()メソッドによって行います。
String[] strArray = list.toArray(new String[0]);
このメソッドの引数には、戻り値として受け取りたい型で、新しい配列のインスタンスを指定します。ここで指定する配列のサイズは、返される配列のサイズに関わらず、0で問題ありません。
次に配列からリストへの変換は、以下のように既出のArraysクラスのasList()メソッドによって行います。
List<String> list = Arrays.asList(strArray);
開発者が作成したクラスを格納するためのリスト
これまではString型やint型などを格納するためのリストを取り上げましたが、開発者が独自に作成したクラスを格納するリストを作成することも可能です。
例えば「人物」を表すPersonクラスがあるものとして、Personインスタンスを格納するためのリストは、以下のようにして作成します。
List<Person> personList = new ArrayList<>(); //【1】
Person alice = new Person("Alice", 25, "female");
Person bob = new Person("Bob", 35, "male");
personList.add(alice);
personList.add(bob);
Personを格納するためのリスト(変数personList)を、【1】のように生成します。そしてAlice、Bobのインスタンスを生成し、生成したリストに追加します。このようにして作成したリストに拡張for文を適用すれば、格納された人物に対する処理を一括で行うことができます。
このように開発者が作成したクラスの複数インスタンスを、リストとfor文で一括処理するパターンは、実際のJavaアプリケーション開発では、非常に高い頻度で登場します。
多次元配列のリストへの置き換え
配列ではインデックスが二種類以上の多次元配列を作ることができます(レッスン5.1.4)が、リストでも同様のことができます。
ここで、Alice、Bob、Carolの3人が、国語、算数、理科、社会の4科目について、以下のようなスコアを持っているものとします。
| 国語 | 算数 | 理科 | 社会 | |
|---|---|---|---|---|
| Alice | 80 | 90 | 100 | 85 |
| Bob | 75 | 70 | 75 | 60 |
| Carol | 95 | 65 | 75 | 90 |
まず3人のスコアを、List<Integer>型のリストで表現します。
List<Integer> aliceScore = Arrays.asList(80, 90, 100, 85);
List<Integer> bobScore = Arrays.asList(75, 70, 75, 60);
List<Integer> carolScore = Arrays.asList(95, 65, 75, 90);
次にこれらのリストを格納するためのリストを作り、データを格納します。List<Integer>型を格納するためのListなので、以下のようなコードになります。
List<List<Integer>> scores = new ArrayList<>();
scores.add(aliceScore);
scores.add(bobScore);
scores.add(carolScore);
このように「リストを格納するためのリスト」を作ることで、多次元配列と同じように表形式のデータ構造を表すことが可能です。
18.1.3 セットの操作方法
このレッスンでは、セットの基本的な操作方法を、リストの操作方法を踏まえてその差分を中心に説明します。
セットとは
セットとは、数学の「集合」を抽象化したデータ構造で、リストと同じように、何らかの要素を格納するために使用します。ただしリストとは異なり「位置」の概念がないため、インデックスを指定して要素を取得・追加・削除する方法はありません。
セットの操作方法は、java.util.SetインタフェースのAPIによって定義されています。セットの実装クラスには、java.util.HashSet、java.util.LinkedHashSetなどがあります。両者の違いは、格納される要素の並び順にあります。HashSetクラスは任意の順番で並ぶのに対して、LinkedHashSetクラスは追加された順に並びます。実装クラスの選択は開発者に委ねられますが、殆どのケースでHashSetが使われます。本コースでは、基本的にHashSetを使用して説明を進めます。
セットにおける要素の重複
セットは、要素の重複が許容されない点が大きな特徴です。「要素の重複」とは「インスタンスが等価になる」という意味なので、格納されるインスタンスのequals()メソッドの実装に依存します。
セットでは要素を追加するとき、以下のような手順で「要素の重複」をチェックします。
- まずhashCode()メソッドによってハッシュ値を求め、既に存在するすべての要素と、ハッシュ値の重複チェックをする。ここでハッシュ値の重複がなかった場合は、重複はないと見なして要素を追加する。ハッシュ値が重複した場合は2へ進む。
- ハッシュ値が重複した場合、equals()メソッドによって等価性を判定し、falseの場合は重複はない(ハッシュ値がたまたま衝突)ものとして要素を追加する。trueの場合は要素の重複と見なし、追加は行われない。
このようにセットの要件を実現するためには、格納されるクラスに、equals()メソッドとhashCode()メソッドが適切に実装されていることが必要条件になります。
セットの宣言と生成
ここではHashSetクラスを使い、セットを宣言および生成する方法を説明します。セットには任意のデータ型を格納することができますが、ここではString型を前提にします。String型を格納するためのセットは、以下のように宣言および生成します。
Set<String> set = new HashSet<>();
変数はSetインタフェースの型で宣言します。リストと同じように、型パラメータによって格納できる型を指定します。セットの実装クラスには、最も代表的なHashSetクラスを選択しています。
SetインタフェースのAPI全体像
Setインタフェースには、セットを操作するための豊富なAPIが備わっています。このレッスンでは、その中から特に利用頻度の高いものをピックアップします。
以下の表は、このレッスンで取り上げるSetインタフェースのAPI一覧です。なおこの表におけるEはElement(要素)の頭文字で、総称型の型パラメータを表す記号として、慣例的に使われているものの一種です。
| API(メソッド) | 説明 |
|---|---|
| boolean add(E) | このセットに、指定された要素を追加する(成否を返す)。 |
| Iterator<E> iterator() | このセットから、イテレータを返す。 |
| boolean remove(E) | このセットから、指定された要素を削除する(成否を返す)。 |
| void clear() | このセットから、要素を一括削除する。 |
| boolean addAll(Collection<E>) | このセットに、指定された他のリストを統合する(成否を返す)。 |
| int size() | このセットのサイズを返す。 |
| boolean contains(E) | このセットに、指定された要素が含まれているかを判定して返す。 |
| boolean isEmpty() | このセットの要素が空かを判定して返す。 |
| static Set<E> of(E...) | 指定された要素を含むイミュータブルなセットを生成して返す。 |
| T[] toArray(T[]) | このセット内のすべての要素を、セット内の並び順に従って配列にして返す。返される配列の型は、指定された配列の型と同じになる。 |
| Stream<E> stream() | このセット内のすべての要素から、順次ストリームを生成して返す。※『Java Advanced編』参照 |
| Stream<E> parallelStream() | このセット内のすべての要素から、並列ストリームを生成して返す。※『Java Advanced編』参照 |
次項からは、これらのAPIの使用方法について具体的に説明していきます。
要素の追加
セットに要素を追加するためには、add()メソッドを使用します。
Set<String> set = new HashSet<>(); //【1】
set.add("foo"); //【2】
set.add("bar"); //【3】
set.add("baz"); //【4】
まず【1】でString型セット(変数set)を生成し、それに対して【2】~【4】のようにして文字列"foo"、"bar"、"baz"を追加します。なおこのセットに対してString型以外のデータを追加しようとすると、コンパイルエラーが発生します。また、インデックスを指定した要素の追加はできません。
要素が重複した場合の挙動
add()メソッドで要素を追加するとき、追加が成功したか否かはboolean型によって返されます。仮にすでに存在する要素と重複があると、追加は行われずfalseが返されます。重複の判定は、前述したように追加されるクラスのequals()メソッドとhashCode()メソッドによって行われます。
ここで「人物」を表すPersonクラスを題材に、セットにおける重複とは何か、もう少し考えてみましょう。Personクラスには、name(名前)、age(年齢)、gender(性別)という3つのフィールドがあり、コンストラクタとアクセサメソッドも定義されているものとします。以下のコードを見てください。
Set<Person> personSet = new HashSet<>();
Person alice = new Person("Alice", 25, "female");
Person bob = new Person("Bob", 35, "male");
personSet.add(alice);
personSet.add(bob);
Person alice2 = new Person("Alice", 26, "female");
personSet.add(alice2); // どうなる?
このようにPerson型を格納するためのセットを用意し、Alice(年齢25歳)とBob、2人のPersonインスタンスが格納されているものとします。このとき、このセットに「年齢26歳のAliceインスタンス」を追加しようとすると、成功するでしょうか。
【図18-1-2】セットへの要素の追加

成功するか否かは、Personクラスのequals()メソッドおよびhashCode()メソッドの実装次第です。もしこのクラスの等価性がすべてのフィールド値によって判定されるのであれば、年齢が異なるため「重複はしていない」と見なされ、追加は成功します。逆に等価性がnameフィールドの値のみによって判定されるのであれば、名前が同じのため「重複している」と見なされ、追加は行われません。
要素の取得とループ処理
セットはインデックスを持たないデータ構造のため、個々の要素を取得することはできません。セットに格納された要素はあくまでも「集合」なので、リストと同じように拡張for文またはイテレータによって要素を順に取り出し、ループ処理を行うのが基本です。拡張for文またはイテレータによるループ処理については、前のレッスンで説明済みなのでここでは割愛します。
要素の削除
セットから要素を削除するためには、remove()メソッドに要素そのものを指定します。
boolean flag = set.remove("foo");
remove()メソッドは、削除が成功したのか(true)空振りしたのか(false)を、boolean型の戻り値で返します。
また以下のようにclear()メソッドを呼び出すと、すべての要素を削除することができます。
set.clear();
CollectionインタフェースとListおよびSetとの関係
前述したようにjava.util.Collectionは、ListインタフェースおよびSetインタフェースの共通の親インタフェースです。Collectionインタフェースには、ListインタフェースやSetインタフェースと同じようなAPIが定義されていますが、Listとは異なりインデックスを指定した要素の操作はできません。
またSetとは異なり、要素の重複が認められます。実はCollectionそのものをAPIで操作するケースはあまりないのですが、Java SEによって提供されるAPIの中には、Collectionインタフェースを引数に取るものがあります。Collectionは、ListおよびSetの親インタフェースのため、どちらでも渡すことが可能です。次のチャプターで取り上げるjava.util.Collectionsというユーティリティクラスには、こういったAPIが多数あります。
またこのチャプターで後述するマップでは、values()メソッドを呼び出すと値がCollectionインタフェースとして返されます。このときCollectionのままでは(他のAPIとの兼ね合いで)使い勝手が悪いため、必要に応じてListやSetへの変換を行うと良いでしょう。ArrayListクラスやHashSetクラスには、Collectionを引数に持つコンストラクタがあるため、それを使用してCollectionからListおよびSetへの変換を行います。
- ArrayList(Collection)
- HashSet(Collection)
具体的には以下のコードのようになります。
Collection<String> values = map.values();
List<String> list = new ArrayList<>(values);
Set<String> set = new HashSet<>(values);
リストとセットの相互変換
リストとセットは、相互に変換することが可能です。
まずリストからセットへの変換は、例えば作成済みのリストに対して、後から何らかの理由で重複を排除する必要が生じた場合などに行います。代表的な方法は、HashSetクラスのCollectionインタフェースを引数に持つコンストラクタ(既出のもの)を使用するものです。
以下のようにすると、指定されたリスト(変数list)から重複が排除された新しいセットが生成されます。
Set<String> set = new HashSet<>(list);
次にセットからリストへの変換は、例えば作成済みのセットに対して、後から何らかの理由でインデックスによる操作が必要になった場合などに行います。代表的な方法は、ArrayListクラスのCollectionインタフェースを引数に持つコンストラクタ(既出のもの)を使用するものです。
以下のようにすると、指定されたセット(変数set)からインデックスを持つ新しいリストが生成されます。
List<String> list = new ArrayList<>(set);
ListインタフェースとSetインタフェースのAPIまとめ
既出のListインタフェースとSetインタフェースのAPIを比較すると、同じ名前で、同じ操作を行うAPIが提供されていることが分かります。
以下の表は、両者を比較したものです。「〇」は操作可能、「-」は操作不可を表します。
| API(メソッド) | List | Set |
|---|---|---|
| boolean add(E) | 〇 | 〇 |
| void add(int, E) | 〇 | - |
| E get(int) | 〇 | - |
| E set(int, E) | 〇 | - |
| Iterator<E> iterator() | 〇 | 〇 |
| E remove(int) | 〇 | - |
| boolean remove(E) | 〇 | 〇 |
| void clear() | 〇 | 〇 |
| List<E> subList(int, int) | 〇 | - |
| boolean addAll(Collection<E>) | 〇 | 〇 |
| int size() | 〇 | 〇 |
| boolean contains(E) | 〇 | 〇 |
| boolean isEmpty() | 〇 | 〇 |
| static List<E> of(E...) | 〇 | - |
| static Set<E> of(E...) | - | 〇 |
| T[] toArray(T[]) | 〇 | 〇 |
このようにListとSetには、データに対して同じような操作を行うためのAPIが数多くありますが、Setには「インデックスがない」という特性から、対応していない操作が幾つかあります。
18.1.4 マップの操作方法
マップとは
マップとは、一意のキーとそのキーに対応する値を、ペアとして管理するデータ構造です。マップにおける要素とは「キーと値のペア」であり、キーから値を取得できる点がマップの最大の特徴です。マップにおけるキーは重複が許容されず、一意性が保証されている必要があります。
マップの操作方法は、java.util.MapインタフェースのAPIによって定義されています。マップの実装クラスには、java.util.HashMap、java.util.LinkedHashMapなどがあります。両者の違いは、格納される値の並び順にあります。HashMapクラスは任意の順番で並ぶのに対して、LinkedHashMapクラスは追加された順に並びます。
実装クラスの選択は開発者に委ねられますが、殆どのケースでHashMapが使われます。本コースでは、基本的にHashMapを使用して説明を進めます。
マップの宣言と生成
ここではHashMapクラスを使い、マップを宣言および生成する方法を説明します。マップのキーと値には任意の型を指定できますが、ここではキーをInteger型、値をString型にするものとします。このようなマップは、以下のように宣言および生成します。
Map<Integer, String> map = new HashMap<>();
変数はMapインタフェースの型で宣言します。リストやセットと同じように型パラメータを使うことができますが、マップの場合はキーと値があるため、ダイヤモンド演算子の中に、キー、値の順に、カンマで区切って記述します。ここでは、マップの実装クラスに最も代表的なHashMapクラスを選択しています。
MapインタフェースのAPI全体像
Mapインタフェースには、マップを操作するための豊富なAPIが備わっています。このレッスンでは、その中から特に利用頻度の高いものをピックアップします。
以下の表は、このレッスンで取り上げるMapインタフェースのAPI一覧です。なおこの表におけるK、VはKey、Valueの頭文字で、総称型の型パラメータを表す記号として、慣例的に使われているものの一種です。
| API(メソッド) | 説明 |
|---|---|
| V put(K, V) | このマップに、指定されたキーと値のペアを追加する(追加された値を返す)。 |
| V get(K) | このマップから、指定されたキーに対応する値を返す。 |
| Set<K> keySet() | このマップから、すべてのキーをセットとして抽出する。 |
| Collection<V> values() | このマップから、すべての値をコレクションとして抽出する。 |
| Set<Map.Entry<K,V>> entrySet() | このマップから、すべてのキーと値のペアをMap.Entryのセットとして抽出する。 |
| V remove(K) | このマップから、指定されたキーに対応する値を削除する(削除した要素を返す)。 |
| boolean remove(Object, Object) | このマップから、指定されたキーと値のペアを削除する(削除に成功した場合にtrueを返す)。 |
| void clear() | このマップから、要素を一括削除する。 |
| void putAll(Map<K, V>) | このマップを、指定された他のマップと結合する。 |
| int size() | このマップのサイズを返す。 |
| boolean containsKey(K) | このマップに、指定されたキーが含まれているかを判定して返す。 |
| boolean containsValue(V) | このマップに、指定された値が含まれているかを判定して返す。 |
| boolean isEmpty() | このマップの要素が空かを判定して返す。 |
| static Map<K, V> of(K, V, K, V ...) | 指定されたキーと値を含むイミュータブルなマップを生成して返す(最大10要素まで)。 |
次項からは、これらのAPIの使用方法について具体的に説明していきます。
キーと値の追加
マップに対して要素を追加するためには、put()メソッドにキーと値のペアを指定します。
Map<Integer, String> map = new HashMap<>();
map.put(101, "Alice");
map.put(102, "Bob");
map.put(103, "Carol");
ここでは、型パラメータによってキーにInteger型、値にString型を持つマップを宣言しているため、追加が可能なのは2行目にあるようにキーが101、値が"Alice"といった要素になります。この要素は、「キーが101で値が"Alice"」というペアを表しています。仮に指定されたデータ型以外のデータを追加しようとすると、コンパイルエラーが発生します。
また以下のように、一度追加した要素に対して、同一のキーを指定してput()メソッドを呼び出すと、値を書き換えることができます。
map.put(102, "Dave");
値の取得
マップから値を取得するためには、get()メソッドに対象要素のキーを指定します。
例えばキーが101の値を取得する場合は、以下のようなコードになります。
String name = map.get(101); // "Alice"
ここではキーが101と指定されているので、事前に生成済みのマップから値として文字列"Alice"が返されます。
なおこのマップは、キーにInteger型、値にString型であることが、事前に型パラメータで指定されています。
よってget()メソッドの引数にInteger型以外を指定したり、値を受け取る変数の型にString型以外を指定すると、コンパイルエラーが発生します。
キーと値の抽出
ここでは、マップからキーと値をコレクションとして抽出する方法を説明します。
まずキーについては、keySet()メソッドを呼び出すと、すべてのキーをセットとして抽出することができます。
Set<Integer> keySet = map.keySet();
キーは重複が許容されないため、データ構造は必然的にセットになります。
次に値の抽出です。
Collection<String> values = map.values(); //【1】
List<String> list = new ArrayList<>(values); //【2】
Set<String> set = new HashSet<>(values); //【3】
マップのvalues()メソッドを呼び出すと、すべての値がコレクション(java.util.Collectionインタフェース)として返されます【1】。コレクションのままでは(他のAPIとの兼ね合いで)使い勝手が悪いため、必要に応じてリストやセットに変換を行います【2、3】。
キーによるループ処理
マップもリストやセットと同じように、拡張for文やイテレータによるループ処理が可能ですが、ここでは拡張for文を取り上げます。
典型的なマップによるループ処理のコードを、次に示します。
Set<Integer> keySet = map.keySet(); //【1】
for (Integer key : keySet) { //【2】
String value = map.get(key); //【3】
// キーと値によって何らかの処理を行う
}
まずkeySet()メソッドによって、マップからキーだけをセットとして抽出します【1】。そして拡張for文に抽出したキーを指定して、ループ処理を行います【2】。ループではキーが順に取り出されるため、そのキーを使って値を取得します【3】。
キーと値のペアの抽出
マップでは、キーと値のペアはMapのスタティックメンバーインタフェースであるMap.Entryによって表されます。スタティックメンバーインタフェースは、入れ子クラスの一種ですが、ここではMap.Entryという名前のインタフェースと理解しておけば問題ありません。Map.Entryはキーと値のペアを表すため、総称型によって2つの型パラメータを指定します。例えばキーがInteger型、値がString型の場合は、個々の要素(キーと値のペア)を表す型はMap.Entry<Integer, String>になります。
それでは、マップからキーと値のペアを取り出してみましょう。
Set<Map.Entry<Integer, String>> entrySet = map.entrySet(); //【1】
for (Map.Entry<Integer, String> entry : entrySet) { //【2】
System.out.println(entry.getKey() + " => " +
entry.getValue()); //【3】
}
Map.Entryは、マップのentrySet()メソッドによってセットとして抽出されます【1】。抽出したMap.Entryのセットには、ループ処理を行うことによって個々のMap.Entryにアクセスします【2】。そして個々のMap.EntryのgetKey()メソッドによってキーを、getValue()メソッドによって値を、それぞれ取得することができます【3】。
キーと値の削除
マップから要素を削除するためには、remove()メソッドにキーを指定します。
String value = map.remove(101);
このようにすると、削除したキーに対応する値が返されますが、戻り値を受け取らなくても問題はありません。
マップから要素を削除する別の方法として、remove()メソッドにキーと値のペアを指定するというものもあります。
boolean flag = map.remove(101, "Alice");
remove()メソッドは、削除が成功したのか(true)、空振りしたのか(false)を、boolean型の戻り値で返します。
また以下のようにclear()メソッドを呼び出すと、すべての要素を削除することができます。
map.clear();
マップの簡易的な作成方法
マップを作成する手順は、実装クラスのオブジェクトを生成し、put()メソッドによって要素を追加する、というのが基本です。ただし簡易的な方法として、Mapインタフェースに定義されたof()メソッド(スタティックメソッド)を使う方法もあります。
Map<Integer, String> map = Map.of(101, "Alice", 102, "Bob", 103, "Carol");
このようにスタティックなof()メソッドに、キー、値、キー、値といった具合に、繰り返しキーと値を指定することで、マップを生成することができます。ただしこの方法では、要素(キーと値のペア)を最大で10個までしか格納できません。また、このようにして作成したマップはイミュータブル(不変)のため、後から要素の追加・置換・削除などの操作はできません。
マップの用途
マップの最大の特徴は、キーから値を取得できる点にあります。この機能により、リストにおけるインデックスとは異なり、業務的に意味のあるデータをキーに特定の値を取り出すことができます。表構造のデータでは、特定の列をキーにして行を特定したいケースがありますが、マップはまさにそういった用途で使います。
ここで「人物」を題材に表構造のデータを考えてみましょう。「人物」には、ID、名前、年齢、性別という4つの属性があるものとし、Alice、Bob、Carolの3人が、以下のような属性値を持っているものとします。
| ID | 名前 | 年齢 | 性別 |
|---|---|---|---|
| 101 | Alice | 25 | female |
| 102 | Bob | 35 | male |
| 103 | Carol | 30 | female |
ここで「人物」を表すPersonクラスを作成し、id、name(名前)、age(年齢)、gender(性別)という4つのフィールドと、コンストラクタ、アクセサメソッドを定義するものとします。このようなデータ構造はリストで表すこともできますが、リストでは業務上のキーであるIDから「人物」を特定することはできません。IDから「人物」を一意に特定したい場合は、マップを使います。
この場合はキーはID(Integer型)、値は「人物」(Person型)になります。このようなマップは、以下のように作成します。
Person alice = new Person(101, "Alice", 25, "female");
Person bob = new Person(102, "Bob", 35, "male");
Person carol = new Person(103, "Carol", 30, "female");
Map<Integer, Person> personMap = new HashMap<>(); //【1】
personMap.put(alice.getId(), alice);
personMap.put(bob.getId(), bob);
personMap.put(carol.getId(), carol);
マップのキーはInteger型、値はPerson型なので、このマップの型はMap<Integer, Person>になります【1】。このようにしてマップを作成すると、以下のようにIDから「人物」を特定することができます。
Person person = personMap.get(102);
get()メソッドにキーとして102を指定しているため、BobのPersonインスタンスが返されます。
18.1.5 キューとスタックの操作方法
キューおよびスタックとは
キューとは、追加された要素を一列に並べ、先に追加された要素から順に取り出すデータ構造です。またスタックとは、追加された要素を積み上げ、後に追加された要素から先に取り出すデータ構造です。
キューおよびスタックを表すインタフェースには様々な種類がありますが、最も応用範囲が広いのがjava.util.Dequeです。このインタフェースは、キューおよびスタック、両者の機能を併せ持つ「両端キュー」を操作するためのAPIを提供します。
本コースでは、「両端キュー」のことをインタフェースの名前に合わせて「デック」と呼称します。デックの実装クラスとしては、java.util.ArrayDequeクラスがその代表です。ArrayDequeクラスは内部実装としては配列を拡張したものであり、領域は自動拡張されるので容量制限はありません。
キューとしての操作
デックは、キューとスタック、両者の機能を併せ持ちますが、まずはキューとしての操作方法を説明します。
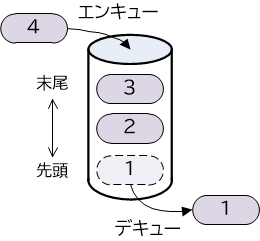
キューのデータ構造は、先入れ先出し(FIFO)の考え方に基づいています。キューへの要素の追加は末尾から行われ、追加された順に並びます。キューからの要素の取り出しは先頭から順に行われ、取り出された要素はキューから削除されます。なお一般的にキューの操作において、要素の追加をエンキュー、要素の取り出しをデキューと呼びます。
【図18-1-3】キュー
スタックとしての操作
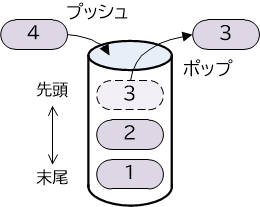
次に、スタックとしての操作方法です。スタックのデータ構造は後入れ先出し(LIFO)の考え方に基づいています。スタックへの要素の追加は先頭から行われ、追加された順に積み上がります。スタックからの要素の取り出しは先頭(最上位)から順に行われ、取り出された要素はスタックから削除されます。なお一般的にスタックの操作において、要素の追加をプッシュ、要素の取り出しをポップと呼びます。
【図18-1-4】スタック
デックの宣言と生成
ここではArrayDequeクラスを使い、デックを宣言および生成する方法を説明します。デックには任意のデータ型を格納することができますが、ここではString型を前提にします。
String型を格納するためのデックは、以下のように宣言および生成します。
Deque<String> deque = new ArrayDeque<>();
変数dequeは、Dequeインタフェースの型で宣言します。他のコレクションと同じように、型パラメータによって格納できる型を指定します。デックの実装クラスには、最も代表的なArrayDequeクラスを選択しています。
DequeインタフェースのAPI全体像
Dequeインタフェースには、デックを操作するための豊富なAPIが備わっています。このレッスンでは、その中から特に利用頻度の高いものをピックアップします。
以下の表は、このレッスンで取り上げるDequeインタフェースのAPI一覧です。なおこの表におけるEは、Element(要素)の頭文字で、総称型の型パラメータを表す記号として、慣例的に使われているものの一種です。
| API(メソッド) | 説明 |
|---|---|
| boolean offerFirst(E) | このデックの先頭に、指定された要素を追加する(容量オーバー時はfalseを返す2)。 |
| boolean offerLast(E) | このデックの末尾に、指定された要素を追加する(容量オーバー時はfalseを返す2)。 |
| void addFirst(E) | このデックの先頭に、指定された要素を追加する(容量オーバー時は例外発生2)。 |
| void addLast(E) | このデックの末尾に、指定された要素を追加する(容量オーバー時は例外発生2)。 |
| E pollFirst() | このデックの先頭から要素を取り出す(同時に削除する)。 |
| E pollLast() | このデックの末尾から要素を取り出す(同時に削除する)。 |
| E peekFirst() | このデックの先頭から要素を取得する(空の場合はnull値を返す)。 |
| E peekLast() | このデックの末尾から要素を取得する(空の場合はnull値を返す)。 |
| E getFirst() | このデックの先頭から要素を取得する(空の場合は例外発生)。 |
| E getLast() | このデックの末尾から要素を取得する(空の場合は例外発生)。 |
| E removeFirst() | このデックの先頭から要素を削除する(空の場合は例外発生)。 |
| E removeLast() | このデックの末尾から要素を削除する(空の場合は例外発生)。 |
| void clear() | このデックから要素を一括削除する。 |
| int size() | このデックのサイズを返す。 |
| boolean contains(E) | このデックに、指定された要素が含まれているかを判定して返す。 |
| boolean isEmpty() | このデックの要素が空かを判定して返す。 |
この中でも、キューの場合はofferLast()メソッドとpollFirst()メソッドを使い、またスタックの場合はofferFirst()メソッドとpollFirst()メソッドを使う、というのが基本パターンです。次項からは、これらのAPIの使用方法について具体的に説明していきます。
キューとしての使用
デックへの要素の追加は、キューとして使う場合とスタックとして使う場合とで、位置が異なります。要はキューの場合は末尾に、スタックの場合は先頭に、それぞれ要素を追加することになるため、それに合わせて使用するAPIも異なります。
末尾への要素の追加には、offerLast()メソッドを使用します。
Deque<String> deque = new ArrayDeque<>();
deque.offerLast("foo");
deque.offerLast("bar");
deque.offerLast("baz");
このようにすると、デックの末尾に対して"foo"、"bar"、"baz"が順に追加されます。よってこの処理が終わるとデックには、先頭から"foo"、"bar"、"baz"の順に要素が格納されていることになります。
【図18-1-5】デックのキューとしての使用

デックからの要素の取り出しは、キューとして使う場合も、スタックとして使う場合も、先頭から取り出す点は同様です。
デックの先頭から要素を取り出すためには、pollFirst()メソッドを使用します。
String element = deque.pollFirst();
このメソッドを呼び出すたびに、デックの先頭から"foo"、"bar"、"baz"の順に要素が取り出されます。
スタックとしての追加と取り出し
デックをスタックとして使う場合、要素はデックの先頭に追加(プッシュ)する必要があります。要素をプッシュするためには、offerFirst()メソッドを使用します。
Deque<String> deque = new ArrayDeque<>();
deque.offerFirst("foo");
deque.offerFirst("bar");
deque.offerFirst("baz");
このようにすると、デックの先頭に対して"foo"、"bar"、"baz"が順に追加されます。よってこの処理が終わるとデックには、先頭から"baz"、"bar"、"foo"の順に要素が格納されていることになります。
【図18-1-6】デックのスタックとしての使用
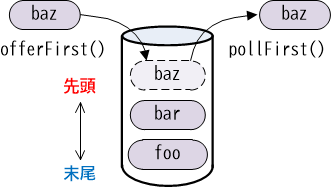
デックをスタックとして使う場合、要素は先頭から取り出します(ポップ)。要素をポップするためには、キューと同様にpollFirst()メソッドを使用します。
String element = deque.pollFirst();
このメソッドを呼び出すたびに、デックの先頭から"baz"、"bar"、"foo"の順に要素が取り出されます。
このチャプターで学んだこと
このチャプターでは、以下のことを学びました。
- コレクションの仕組みやコレクションフレームワークの全体像について。
- リスト(Listインタフェース)の特徴やAPIについて。
- セット(Setインタフェース)の特徴やAPIについて。
- マップ(Mapインタフェース)の特徴やAPIについて。
- キューおよびスタック(Dequeインタフェース)の特徴やAPIについて。