はじめに
この記事は、AMBL株式会社 Advent Calendar 2022の16日目の記事になります。是非、他の記事も読んで見て下さい〜![]()
私は業務で画像分類のモデル開発を行っております。
ただ、動画分類について気になったのでどんな手法があるのか調査すると、「TimeSformer」と呼ばれるTransformerを用いた動画を理解するための最初のアーキテクチャがあることを知りました。
色々調査したので、今回はこの「TimeSformer」について記事を書きます。
アーキテクチャの細かい部分は全部なし!概要とイメージを掴んでいただけたらと思います。
説明をわかりやすくするために一部誤解があるような表現を用いている部分もありますがご留意ください。
TimeSformerの概要
- TimeSformerの提案前までは2D, 3DのCNNモデルを用いて時空間特徴学習を行うことが一般的だった
- self-atteintionの構造を画像空間から、時空間の3次元に拡張することで画像モデルのVision Transformerを動画に適応させている
TimeSformerについて知るには、まず自然言語処理で話題となったTransformerの理解、続いてTransformerを画像処理に適応させたVision Transformerについて知る必要があります。
そもそもTransformerってなんぞ??
Transformerというモデルは2017年にAttention Is All You Needというタイトルで発表されました。
現在では自然言語処理の様々なタスクでTransformerが使用されています。
TransformerはEncoder-Decoder構造を採用しており、翻訳ではEncoderによって入力画像をベクトル化し、Decoderでそのベクトルを与えると文章を生成します。当時、Trnsformerは翻訳タスクにてsota(最高精度)を達成したため、かなり注目を浴びました。
じゃあ結局Transformerってなにやるの?
それは、単語の関連度を予測します。
例えば、「私は男です」という文をTransformerに入力します。
すると文章を単語に分割し、単語間の類似度を算出します。
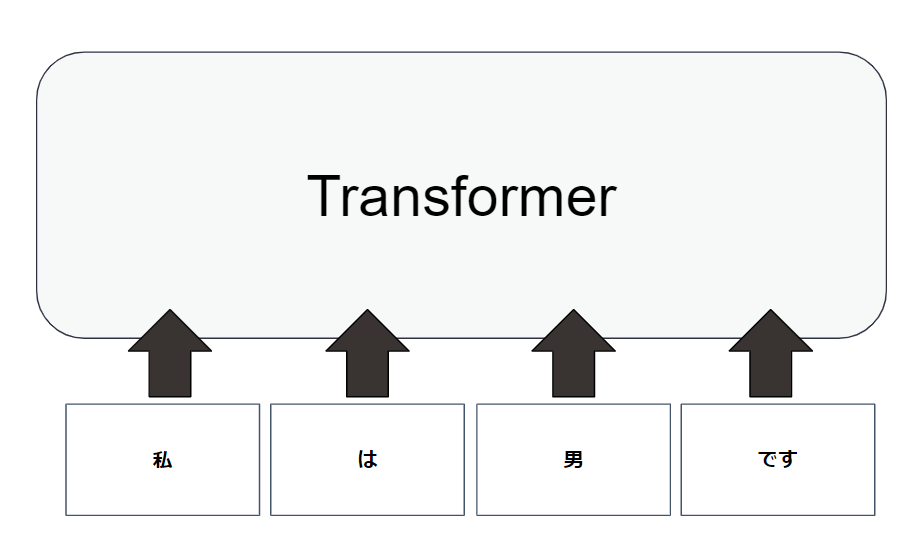
この単語間の類似度を用いて入力から応答文を予測しています。
では、Vision Transformerってなんぞ??
Transformerは自然言語処理を扱うモデルですが、それを画像に適応させたのがVision Transformerです。
2020年10月に、An Image is Worth 16x16 Words: Transformers for Image Recognition at Scaleのタイトルで論文が発表されました。
Vision Transformerは画像分類のモデルです。
- 入力画像をパッチに分割します。(自然言語処理の単語に分割する部分)
- パッチ中のピクセル値を並べてベクトルとみなし、これを線形変換したものを各トークンのベクトル表現として扱います。


Transformerの単語に対応する部分を画像のパッチに対応させたものがVision Transformerになります。
TimeSformerはどのように動画を認識するの??
TimeSformerは入力動画を個々のフレームから抽出された画像パッチの時空間シーケンスとして解釈します。
具体的には動画のフレームに対して、時間軸アテンションと空間軸アテンションと呼ばれる2つのパッチを別々に適応して動画を認識させます。
2つのパッチに対し、これらを別々に適応するDivided Space-Time Attention (T+S)と呼ばれるものをTimeSformerでは提案されています。
この2つのパッチが何なのか
- 時間軸アテンションが適応される際は、同じ場所にある別フレーム(青と緑)のパッチとのみで比較される
- 空間軸アテンションが適応される際は、同じフレーム内(赤)でパッチの比較がされる

このようにフレームごとに時間軸アテンションと空間軸アテンションを用いることで動画分類を行っています。
TimeSformerを実装してみた。
このGithubレポジトリーの中にTimeSformerのモデルが存在するのでありがたく使わせていただきました。

ここを見ると、train方法やtest方法も記載があるので、興味がある方はぜひ試してみてください。
実際にこのような動画を入力させました。

すると、ボクシングである確率が約98%となりました。

punching person (boxing): 0.98202145
high kick: 0.01032652
side kick: 0.0034671444
punching bag: 0.0026613032
headbutting: 0.00073588744
うまく認識できてそうですね。
最後に
しっかりボクシングを認識していました。
ボクシングの中でも「ジャブ」「ストレート」「アッパー」「フック」の4つの行動に対してうまく分類できると色々活用できそうですね。