あらすじ
今の会社に就職する前、趣味でクソアプリの製作に励んでいたことがあります。ワンちゃんの犬種を当てるクイズアプリです。
https://dachs.herokuapp.com/
具体的にどのようにクソか説明しますと、
- JavaScriptを使って画像に対してonClickイベントで実装しており、正解でも不正解でも次の画像に送られない。(画像と問題が合っていない)
- 画像サイズの変更がされていないため犬種によって出題の画像サイズがまちまち。
- herokuの無料枠でデプロイされており動作が重い。
- 「サルーキ」と「ボルゾイ」、「フレンチブル」と「ボストンテリア」、「ラフコリー」と「シェルティ」のように画像からの判別が困難なものが含まれている。
過去の黒歴史と決別すべく、救済策を講じようと思い立ちました。
具体策
Pythonを使って正解になっている犬種のワンちゃんの画像をスクレイピングします。
クソアプリの方は誰からも見向きもされませんが、スクレイピングは多くの方の役に立ちます。
読んでくださった方の一助となれば幸いです。
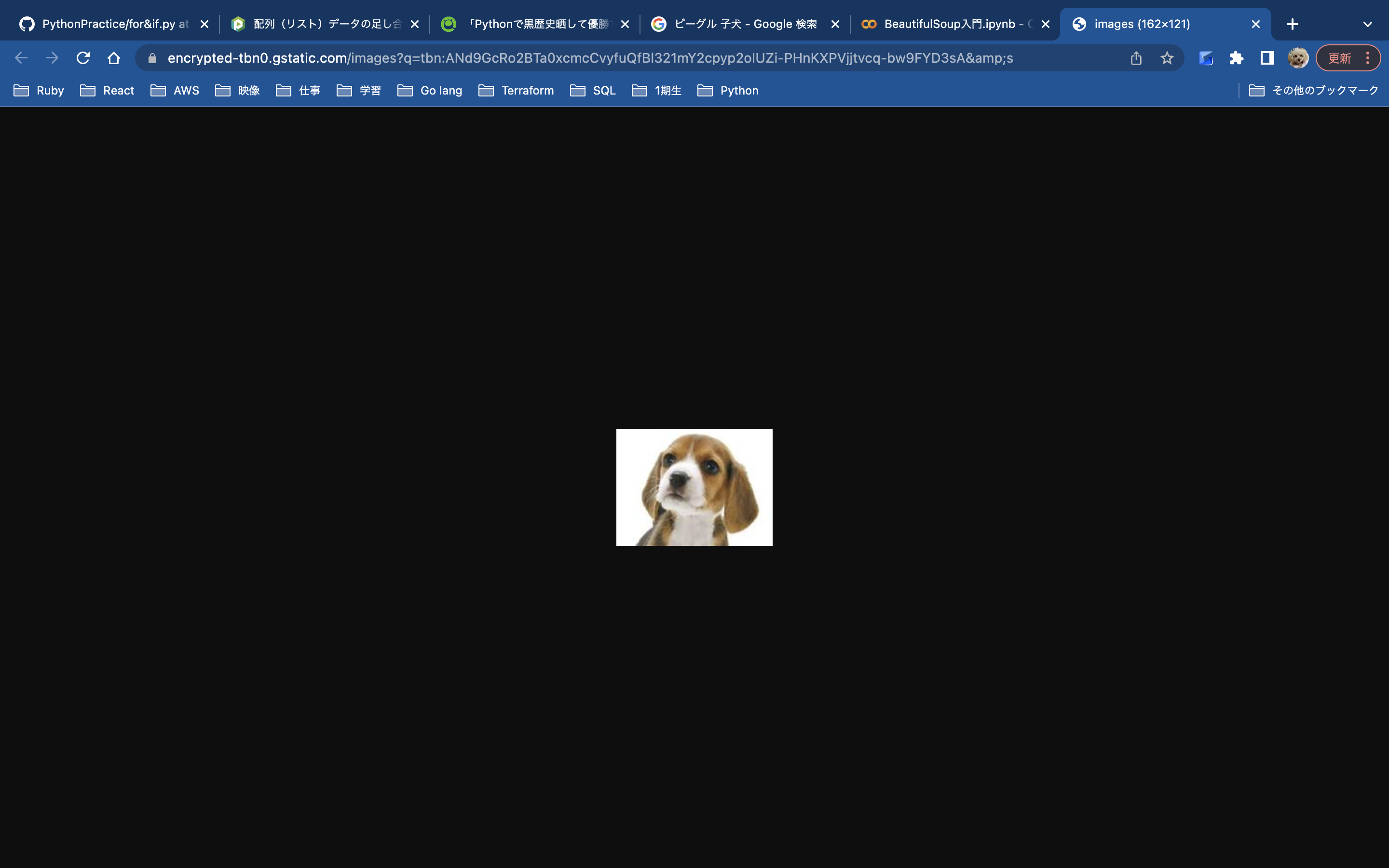
(今回はビーグルを例に挙げて説明します。)
実行環境は手軽なGoogle Colabを選定しました。
環境構築が不要な点が素晴らしい。
正解のワンちゃん
- ビーグル
- 柴犬
- スピッツ
- ビションフリーゼ
- ボーダーコリー
- レオンベルガー
- ボルゾイ
- アメリカンコッカースパニエル
- シャーペイ
- ボストンテリア
- ジャックラッセルテリア
- サモエド
- グレートピレネーズ
- アラスカンマラミュート
- シェルティ
- パグ
- ミニチュアブルテリア
- 狆(チン)
むしろ最終問題までたどり着くことが困難になっています。笑
今回はビーグルのうち一枚を取得します。
実際に書いたコード
beagle.py
import requests
from bs4 import BeautifulSoup
url = 'https://www.google.com/search?q=%E3%83%93%E3%83%BC%E3%82%B0%E3%83%AB+%E5%AD%90%E7%8A%AC&tbm=isch&ved=2ahUKEwjui_2Nne34AhURUN4KHWVcDWYQ2-cCegQIABAA&oq=%E3%83%93%E3%83%BC%E3%82%B0%E3%83%AB&gs_lcp=CgNpbWcQARgCMgQIIxAnMgsIABCABBCxAxCxAzIFCAAQgAQyBQgAEIAEMgUIABCABDIFCAAQgAQyBQgAEIAEMgUIABCABDIFCAAQgAQyBwgAEIAEEARQAFgAYKMKaABwAHgAgAFhiAFhkgEBMZgBAKoBC2d3cy13aXotaW1nwAEB&sclient=img&ei=ETPKYq6_JJGg-QbluLWwBg&bih=658&biw=1440&rlz=1C5CHFA_enJP815JP815'
res = requests.get(url)
res
soup = BeautifulSoup(res.text, 'html.parser')
img_tags = soup.find_all('img')
img_tags[10]
コードの解説
1,2行目
beagle.py
import requests
from bs4 import BeautifulSoup
Pythonのライブラリである「Besautiful Soup」を読み込んでいます。
4行目
beagle.py
url = 'https://www.google.com/search?q=%E3%83%93%E3%83%BC%E3%82%B0%E3%83%AB+%E5%AD%90%E7%8A%AC&tbm=isch&ved=2ahUKEwjui_2Nne34AhURUN4KHWVcDWYQ2-cCegQIABAA&oq=%E3%83%93%E3%83%BC%E3%82%B0%E3%83%AB&gs_lcp=CgNpbWcQARgCMgQIIxAnMgsIABCABBCxAxCxAzIFCAAQgAQyBQgAEIAEMgUIABCABDIFCAAQgAQyBQgAEIAEMgUIABCABDIFCAAQgAQyBwgAEIAEEARQAFgAYKMKaABwAHgAgAFhiAFhkgEBMZgBAKoBC2d3cy13aXotaW1nwAEB&sclient=img&ei=ETPKYq6_JJGg-QbluLWwBg&bih=658&biw=1440&rlz=1C5CHFA_enJP815JP815'
Googleで画像検索した「ビーグル 子犬」の検索結果URLを指定して、変数urlに格納しています。
6行目
beagle.py
res = requests.get(url)
URLを取得するよう命令を出します。
8行目
beagle.py
res
ここまでの処理がうまくいっているかどうか確認します。
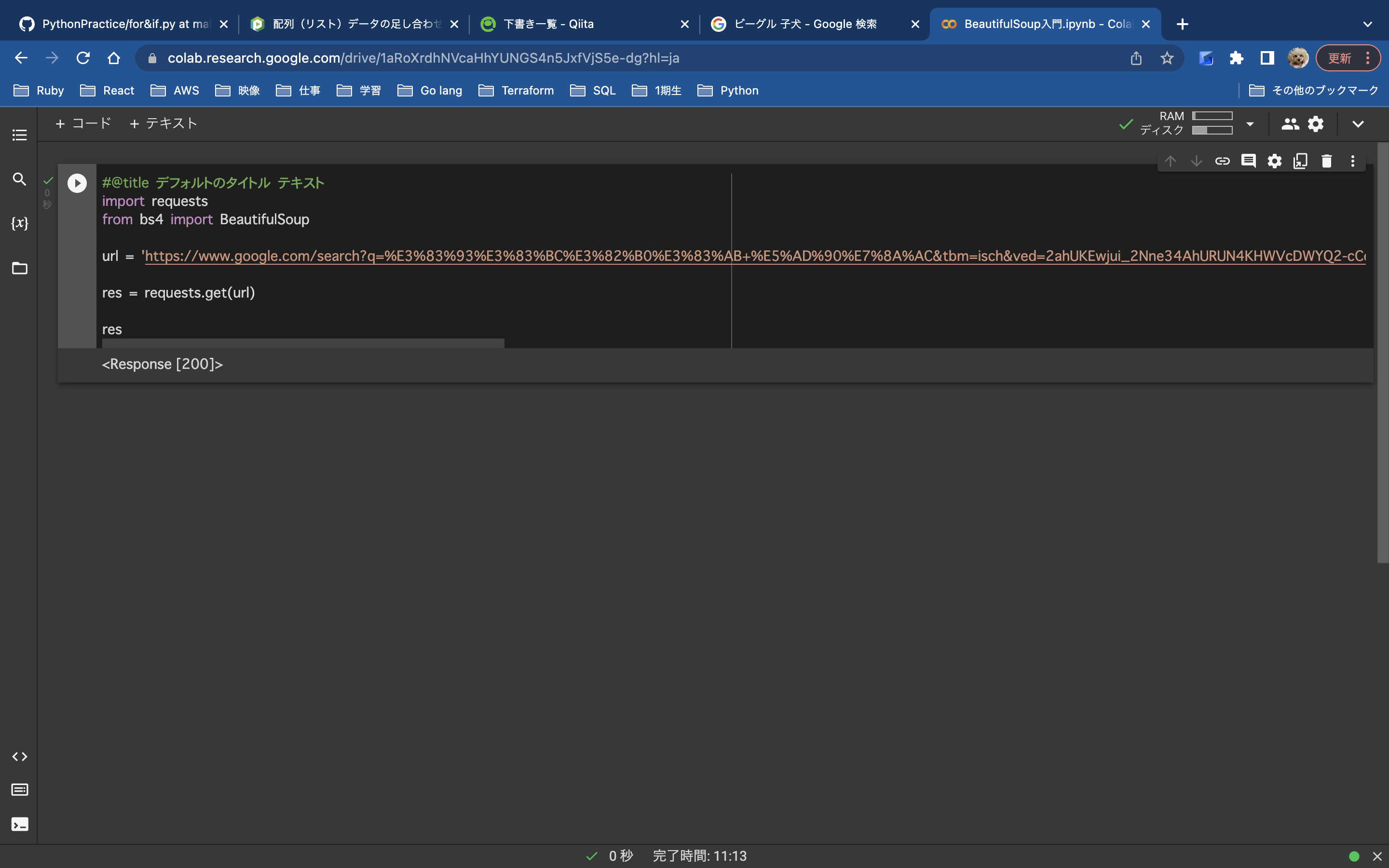
Response[200]が返ってきました。処理はうまくいっています!
10~12行目 を追記します。
beagle.py
soup = BeautifulSoup(res.text, 'html.parser')
img_tags = soup.find_all('img')
img_tags[10]
Beautiful Soupで対象ページのhtml要素を取り出し、soupという変数の格納します。
格納したhtml要素を確認しています。
定義した変数img_tagsの中から11番目を表示します。
実行結果
beagle.py
<img alt="" class="yWs4tf" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRo2BTa0xcmcCvyfuQfBl321mY2cpyp2oIUZi-PHnKXPVjjtvcq-bw9FYD3sA&s"/>
無事画像データのリンクが返ってきました。処理はうまくいっています!