2017年5月31日現在の情報です
Caffeの導入手順について。CPUモード編。
Dockerの初心者にとって、Caffeを実装することがとても面倒になります。
環境:MacOS Sierra,Docker version 17.03
色んな参考サイトがありますが、今回はDocker環境での実装手順になります。
参考:Ubuntu 14.04 上での Caffe の導入手順メモ
Caffeとは
ディープラーニングフレームワーク
非常に高速かつ開発が活発で人気の高いフレームワークです
詳しくは公式を見ましょう
http://caffe.berkeleyvision.org/
- ディープラーニングの手法を実装し、画像認識系の用途で便利に使えるCaffeというツールの使い方を消化します。
- Caffeは、カリフォルニア大学バークレー校のコンピュータビジョン及び機械学習に関する研究センターであるBVLCが中心となって開発しました。
ubuntu14.04のコンテナーを作る
$ sudo docker run -v /Users/Kenta/Desktop/Docker_file/ubuntu_14.04:/root --name ubuntu14.04 -i -t ubuntu:14.04 /bin/bash
パッケージリストの更新
:/# apt-get update
パッケージvimとgitのインストール/更新
:/# apt-get install -y vim git
BLASのインストール
:/# apt-get install libatlas-base-dev
他の依存関係
- g++はこのバージョンじゃなきゃならない。
:/# apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler g++-4.6
※ 約158M(get397)
Caffeのダウンロード
- home直下に置きます。ubuntu_14.04の下
:/# cd
:~# git clone https://github.com/BVLC/caffe.git
Makefile.configの設定
:~# cd caffe
:~/caffe# cp Makefile.config.example Makefile.config
:~/caffe# vim Makefile.config
Makefile.config
# 8行目をアンコメントアウト(行数変わる場合があります)
# CPU_ONLY := 1のコマンド記号削除
↓
CPU_ONLY := 1
# 12行目をアンコメントアウト(行数変わる場合があります)
# CUSTOM_CXX := g++ バージョン指定
↓
CUSTOM_CXX := g++-4.6
コンバイル
:~/caffe# make all
:~/caffe# make test
:~/caffe# make runtest
- テストが全部パスできればcaffeの環境構築は終了
- 失敗した時は、問題を解決してから make cleanをしてmake allからやり直し。
Python でCaffe を使うための環境構築
python用のパッケージマネージャ
:~# apt-get install python-pip
:~# apt-get install gfortran
pipで必要なライブラリのインストール
:~# for req in $(cat ~/caffe/python/requirements.txt); do sudo pip install $req; done
コンパイル
:~# apt-get install python-dev python-numpy python-skimage
パスを通す
:~# vi ~/.bashrc
~/.bashrc内で書く
~/.bashrc
:~# export PYTHONPATH=~/caffe/python/:$PYTHONPATH
反映させる
:~# source ~/.bashrc
Pythonを実行しCaffeが読み込めばOK
:~# python
>>> import caffe
Libdc1394のエラーの時下のコマンド入力
# エラーが表示する場合
>>> import caffe
libdc1394 error: Failed to initialize libdc1394
>>> exit()
:~# ln /dev/null /dev/raw1394
Caffeのテスト
- 今回は、学習が完了した状態で、評価を行います。データセットとは、学習(訓練)用、評価用の2種から構成されるデータ群です。
- 通常、学習する際に使用したデータを、検証用に使うことはできません。
- 回のテストはあらかじめ用意されているものを使います。
モデルの取得
-
モデルとは、どういう手順、経路、方法でデータの学習を行うかを定義した多層ニューラルネットワークを指す。
-
モデルは、Caffe Model ZooというCaffeの学習済モデルを公開したWikiがあり、そこで有力なモデルが公開されている。
:~# cd caffe
:~/caffe# python scripts/download_model_binary.py models/bvlc_reference_caffenet
※ 約232MBのデータがダンンロード
画像データの取得
:~# cd caffe
:~/caffe# mkdir dataset
:~/caffe# cd dataset
:~/caffedataset# mkdir caltech101
画像分類のサンプルとして、物体認識のデータセットの一つであるCaltech101をダウンロード
zipファイルを解凍し、先で作った /caffe/dataset/caltech101/の下にフォルダを移動します。
- 約126MB
分類
出力はnumpy標準のファイル形式です。
--raw_scale 255 は、前処理の前にこのスケール値だけ乗算するとあります。
:~# cd caffe/python
:~/caffe/python# python classify.py --raw_scale 255 ../dataset/caltech101/101_ObjectCategories/airplanes/image_0001.jpg ./result.npy
結果は……
残念ながらErrorが出ました。
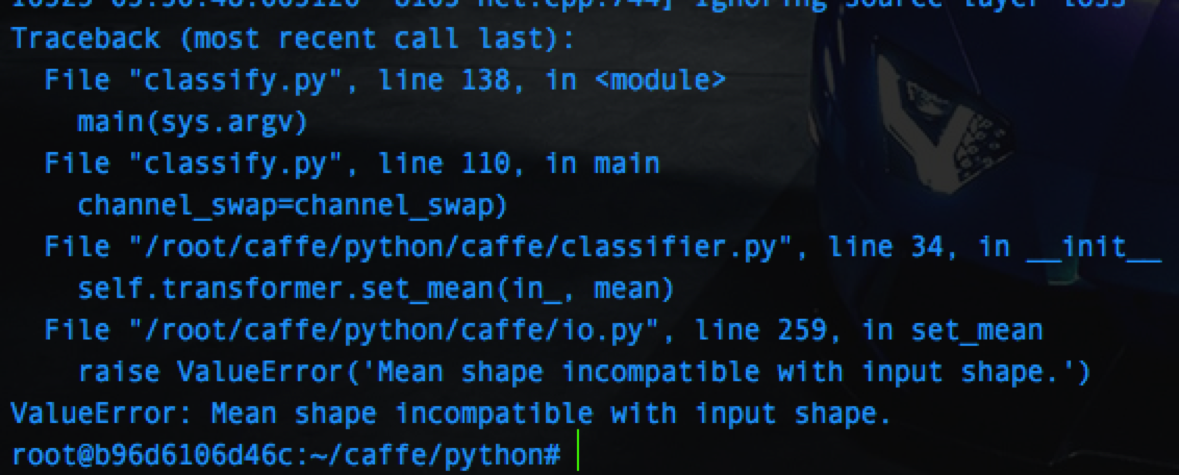
/caffe/python/caffe/io.py の259行目が例外を投げているように見えます。
/caffe/python/caffe/io.py を修正
/caffe/python/caffe/io.py
# 修正前
if ms != self.inputs[in_][1:]:
raise ValueError('Mean shape incompatible with input shape.')
# 修正後
if ms != self.inputs[in_][1:]:
print(self.inputs[in_])
in_shape = self.inputs[in_][1:]
m_min, m_max = mean.min(), mean.max()
normal_mean = (mean - m_min) / (m_max - m_min)
mean = resize_image(normal_mean.transpose((1,2,0)),in_shape[1:]).transpose((2,0,1)) * (m_max - m_min) + m_min
#raise ValueError('Mean shape incompatible with input shape.')
もう一回先ほどのコードを実行
:~# cd caffe/python
:~/caffe/python# python classify.py --raw_scale 255 ../dataset/caltech101/101_ObjectCategories/airplanes/image_0001.jpg ./result.npy
すると
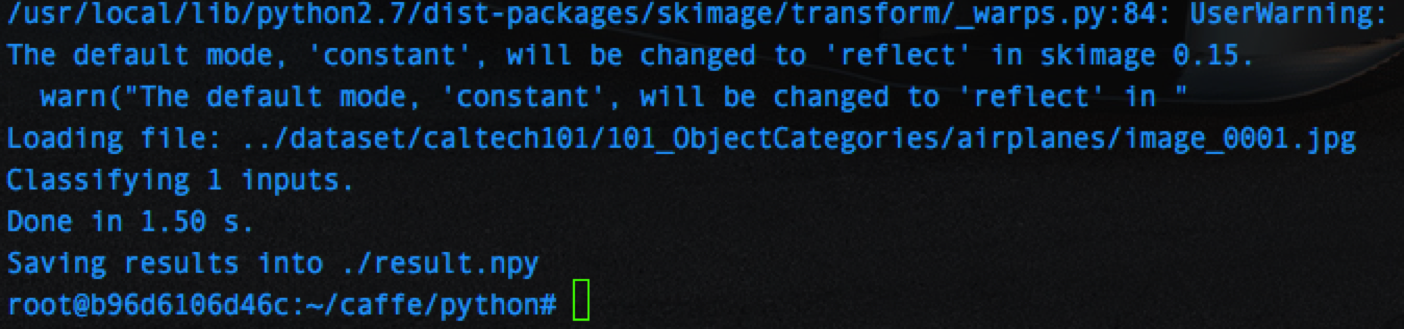
になります。
default modeにまた問題がありますが、ほぼ影響しない、解決策は
/caffe/python/caffe/io.pyの334行あたりにmode=’constant’を追加する
/caffe/python/caffe/io.py
# 修正前
if im_max > im_min:
# skimage is fast but only understands {1,3} channel images
# in [0, 1].
im_std = (im - im_min) / (im_max - im_min)
resized_std = resize(im_std, new_dims,order=interp_order)
resized_im = resized_std * (im_max - im_min) + im_min
# 修正後
if im_max > im_min:
# skimage is fast but only understands {1,3} channel images
# in [0, 1].
im_std = (im - im_min) / (im_max - im_min)
resized_std = resize(im_std, new_dims,mode='constant',order=interp_order)
resized_im = resized_std * (im_max - im_min) + im_min
結果
result.npyはバイナリファイルのため読めません。
- この結果は人間の目で読めるようにスクリプトを作ってください。
- ファイル名show_result.pyにする
- 保存場所/caffe/python/の中
- show_result.pyの中身は以下になります
/caffe/python/show_result.py
# ! /usr/bin/env python
# -*- coding: utf-8 -*-
import sys, numpy
categories = numpy.loadtxt(sys.argv[1], str, delimiter="\t")
scores = numpy.load(sys.argv[2])
top_k = 3
prediction = zip(scores[0].tolist(), categories)
prediction.sort(cmp=lambda x, y: cmp(x[0], y[0]), reverse=True)
for rank, (score, name) in enumerate(prediction[:top_k], start=1):
print('#%d | %s | %4.1f%%' % (rank, name, score * 100))
学習したキーワードを入手する
https://github.com/HoldenCaulfieldRye/caffe/tree/master/data/ilsvrc12
からsynset_words.txtの内容をローカルに保存してください。
- 保存したファイルは/caffe/data/ilsvrc121/ の中に入れてください
画像の判定結果を表示
:~/caffe/python# python show_result.py ../data/ilsvrc12/synset_words.txt result.npy
を実行して表示結果は
