この記事では、アリババのコアビジネスのシナリオの中で、ビッグデータ処理のためのストリームとバッチ統一の実践を分析しています。
Wang Feng(女性)著
リリース:Apache Flink Community China
※こちらは2020年の記事を翻訳しています。
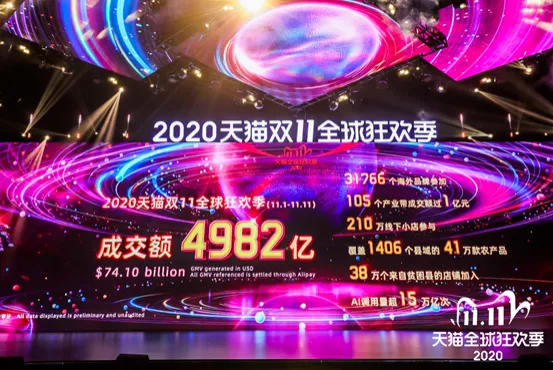
2020年のW11グローバル・ショッピング・フェスティバルの期間中、Alibaba Cloud Apache Flinkのリアルタイム・コンピューティングのピーク時のトラフィック処理速度は40億レコード/秒に達しました。また、データ量も毎秒7TBという驚異的な数値に達しました。これは、新進気鋭のFlinkベースのストリーム・バッチ・ユニファイドが、Alibabaのコアデータサービスのシナリオにおいて、安定性、パフォーマンス、効率性の面で厳しいテストに見事に耐えたことを意味します。この記事では、実践経験を共有し、Alibabaのコアデータサービス内でのストリームとバッチの統一の進化をレビューします。

11月12日午前0時にW11(独身の日)が終了し、2020年W11グローバル・ショッピング・フェスティバルのGMV(流通取引総額)は741億ドルとなりました。Flinkのサポートにより、GMVの数字はフェスティバル全体で非常に安定しています。また、AlibabaのFlinkベースのリアルタイム・コンピューティング・プラットフォームは、アリババ・エコノミーのリアルタイム・データ処理を成功させました。今回もAlibabaは無事に年次テストに合格しました。
GMVダッシュボードに加えて、Flinkは他の多くの重要なサービスをサポートしました。これらのサービスには、検索と推薦のためのリアルタイム機械学習、リアルタイム広告の不正防止、Cainiaoの注文状況のリアルタイム追跡とフィードバック、ECSのリアルタイム攻撃検知、巨大インフラの監視と警告などがあります。リアルタイムビジネスとデータ量は年々劇的に増加しています。今年、リアルタイム・コンピューティングのピーク時のレートは毎秒40億レコードに達し、データ量は毎秒7TBという驚異的な値に達しました。これは、新華社の辞書を1秒間に500万部読むのに相当します。
これまでのところ、Alibaba Cloudのリアルタイム・コンピューティング・ジョブの数は35,000以上に達しています。また、クラスター・コンピューティングの規模も150万CPUを超え、世界をリードしています。これまでに、FlinkはAlibaba経済のすべてのリアルタイム・コンピューティング・ニーズをサポートし、顧客、マーチャント、オペレーション・スタッフに素晴らしい洞察を提供してきました。
さらに、今年のW11(独身の日)では、ストリーム処理とバッチ処理の統合を初めて実践し、Alibabaのコアビジネスのシナリオにおいて、安定性、パフォーマンス、効率性の面で厳しいテストに耐えてきました。
Alibabaのコアデータのシナリオにおけるストリーム・バッチ・ユニフィケーションの最初の実践
ストリームとバッチ処理の統合は、Alibabaではかなり前から始まっていました。Flinkは、Alibabaの検索とレコメンデーションのシナリオで初めて使用されました。その際、インデックス構築と機能エンジニアリングは、Flinkのストリームとバッチ処理の統合の初期バージョンに基づいて行われました。今年のW11(独身の日)では、Flinkはストリームとバッチの統合機能をアピールし、アリババのデータプラットフォームが、リアルタイムとオフラインのデータを相互に検証することで、より正確なデータ分析とビジネス上の意思決定を実現できるようにしました。
Alibabaでは、リアルタイムレポートとオフラインレポートの2種類のデータレポートを提供しています。前者は、W11(独身の日)プロモーションのシナリオにおいて重要な役割を果たします。リアルタイムレポートは、マーチャント、オペレーションスタッフ、およびマネージャーにさまざまな次元のリアルタイム情報を提供することができます。また、プラットフォームやビジネスの効率を向上させるためのタイムリーな意思決定にも役立ちます。例えば、リアルタイムのマーケティングデータ分析を例にとると、運営スタッフや意思決定者は、大きなプロモーションの結果を異なる期間で比較する必要があります。例えば、プロモーション当日の午前10時の売上と昨日の同時刻の売上を比較します。比較することで、現在のマーケティング効果を判断し、規制やコントロールが必要かどうかを判断することができます。
前述のシナリオでは、2種類のデータ分析レポートが必要です。1つは、毎晩のバッチ処理に基づいて計算されたオフラインデータレポート。もう1つは、ストリーム処理によって生成されたリアルタイムデータのレポートです。リアルタイムデータとヒストリカルデータを比較・分析することで、意思決定を行うことができます。ストリームとバッチ処理の統合なしに、オフラインレポートとリアルタイムレポートは、バッチエンジンとストリーミングエンジンによって別々に生成されます。そのため、2倍の開発コストがかかります。また、2つの別々のエンジンで一貫したデータ処理ロジックを維持することは難しく、処理結果の一貫性を確保することができません。したがって、理想的な解決策は、データ解析のストリーム処理とバッチ処理を1つのエンジンで統一することで、オフラインとリアルタイムの解析結果が自然に一致するようになることです。Flinkは、ストリームとバッチの統一アーキテクチャを継続的に成熟させ、検索やレコメンデーションのシナリオに適用して成功を収めています。そのため、Alibabaのデータプラットフォームチームは、2020年のW11グローバルショッピングフェスティバルにおいて、確固たる自信と信頼を示しています。同チームは、Flinkチームと協力して、リアルタイム・コンピューティング・プラットフォームの技術的なアップグレードを推進しました。W11(独身の日)のコアデータシナリオにおいて、Flinkのストリームとバッチの統一に初めて成功しました。
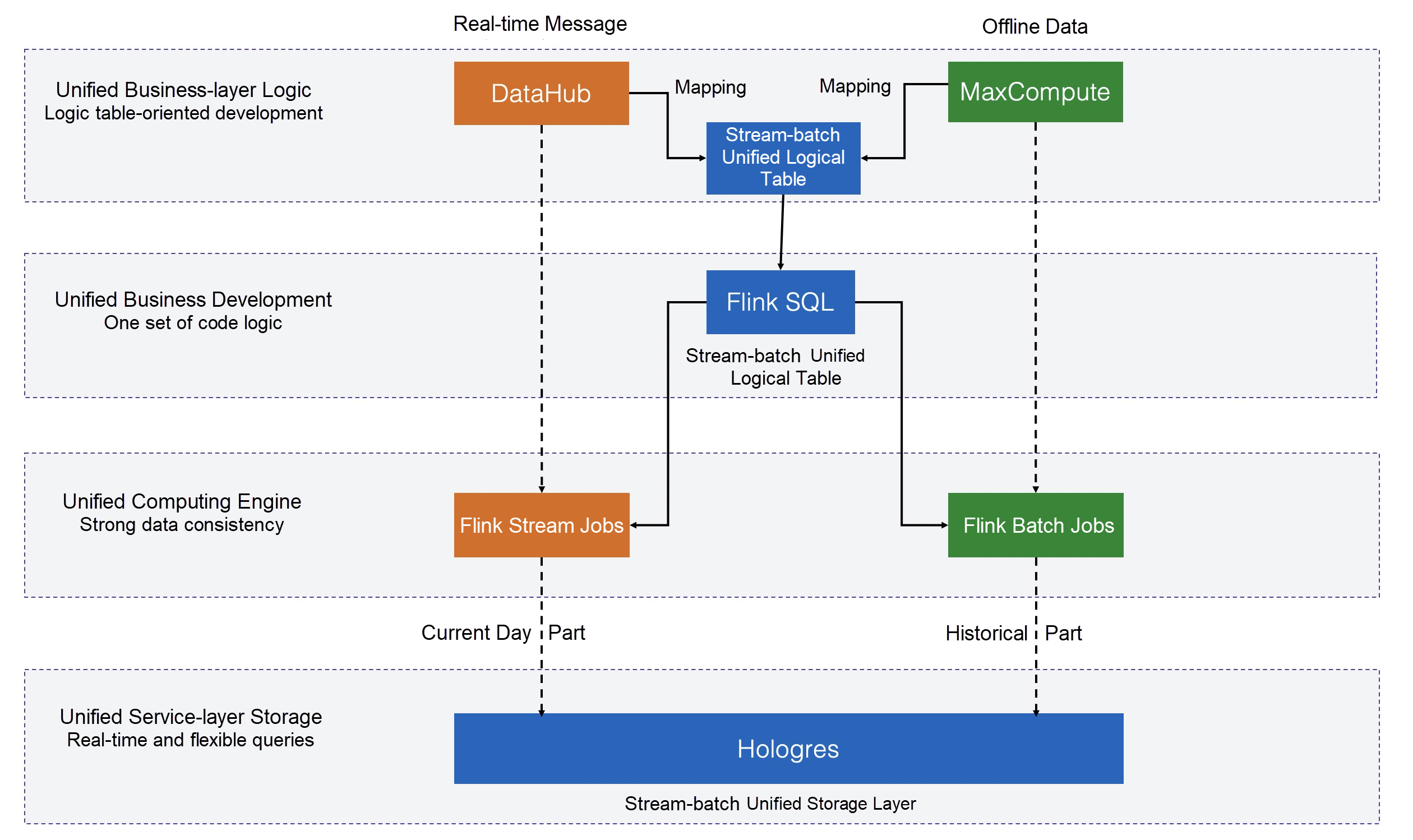
今年は、Flinkチームとデータプラットフォームチームが共同で開発したストリームとバッチの統一コンピューティングフレームワークが、W11(独身の日)のコアデータシナリオでデビューしました。また、ビジネスレイヤーでのパフォーマンスが評価され、アリババのデータプラットフォーム責任者であるPeng Xinyu氏にも認められました。技術的には、ストリームとバッチを統一した結果、複数の演算処理モードに対して1つのコードしか必要ありません。また、統一後の演算速度は他のフレームワークと比較して2倍、クエリは4倍となっています。このように、データレポートの開発や生成のスピードが4倍から10倍に向上します。さらに、統一することで、リアルタイムデータとオフラインデータの完全な整合性を実現しています。

ビジネス展開の効率化とコンピューティングパフォーマンスの向上に加え、ストリームとバッチを統合したコンピューティングアーキテクチャにより、クラスターのリソース利用率が向上します。近年急速に拡大したAlibabaのFlinkリアルタイムクラスターには数百万のCPUが搭載され、数万のリアルタイムコンピューティングタスクが稼働しています。日中、コンピューティングリソースはリアルタイムデータ処理のために占有されています。夜間はアイドル状態のコンピューティングリソースをオフラインのバッチ処理に無料で使用することができます。バッチ処理とストリーム処理は同じエンジンとリソースを使用するため、開発費、O&M費、リソース費を大幅に削減できます。今年のW11(独身の日)では、Flinkベースのバッチ処理とストリーミング処理のアプリケーションは、追加のリソースを必要としませんでした。バッチモードでは、Flinkのリアルタイム・コンピューティング・クラスターを再利用することで、クラスターの利用率を大幅に向上させ、リソースのオーバーヘッドを大幅に削減しました。この効率的なリソース利用モードは、その後のさらなるビジネス・イノベーションの基礎にもなりました。
多額の投資と労力をかけたFlinkのストリーム・バッチの統一
次に、技術的な観点から「ストリーム・バッチ・ユニフィケーション」の開発を振り返ってみましょう。今から10年以上前、オープンソースのビッグデータ技術の第一世代としてHadoopが登場しました。第一世代のバッチ処理技術であるMapReduceは大規模データ処理の問題を解決し、Hiveは大規模データ処理にSQLを使えるようにしました。しかし、ビッグデータのビジネスシナリオが徐々に進化するにつれ、ソーシャルメディア、電子商取引、金融リスク管理など、多くのアプリケーションでリアルタイムデータへの要求が高まっていました。そんな中、第一世代のビッグデータ・ストリーム処理技術として登場したのがStormです。Stormは、HadoopやHiveとはアーキテクチャが全く異なり、Stormのコンピューティングモデルはメッセージに基づいており、ミリ秒レベルのレイテンシーで大量のデータを同時に処理することができます。Stormは、MapReduceやhiveのレイテンシーの問題を解決しています。このように、ビッグデータコンピューティングのバッチ処理とストリーム処理では、全く異なるパターンの2つの主流エンジンが存在します。これをビッグデータ処理技術の第一期と呼びます。
その後、SparkやFlinkが登場したことで、ビッグデータ処理技術は第2の時代へと踏み出しました。SparkはHadoopやHiveに比べて、バッチ処理能力が高く、パフォーマンスも優れていました。これにより、Sparkコミュニティは急速に発展し、徐々にHadoopやHiveを上回るようになりました。こうしてSparkはバッチ処理の分野で主流の技術となりました。しかし、Sparkはバッチ処理技術にとどまりませんでした。すぐにSpark Streamingと呼ばれるストリーム・コンピューティング・ソリューションを発表し、継続的に改良を重ねました。しかし、Sparkエンジンは純粋なストリーム・コンピューティング・エンジンではなく、「バッチ処理指向」と呼ばれています。そのため、ストリームとバッチを融合させたような、極端に短いレイテンシーを実現することはできません。とはいえ、一連のコアエンジン技術をベースに、ストリームとバッチの両方のセマンティクスを実現するというのは、先進的なアイデアです。Flinkもまた、ストリームとバッチの統一という同じコンセプトを持った新しいエンジンです。FlinkはSparkよりも少し遅れて正式にリリースされました。その前身は、2009年にベルリン工科大学で行われた研究プロジェクト「Stratosphere」です。Flinkもまた、1つの計算エンジンでバッチ処理とストリーム処理の両方をサポートすることを目指していました。しかし、Flinkは異なるモデルを選択しました。Flinkは「ストリーム処理」を目的としたエンジンアーキテクチャを採用し、「バッチ」は一種の「拘束されたトラフィック」であると考えました。そのため、アーキテクチャのボトルネックがないストリーム指向のエンジンをベースに、ストリーム処理とバッチ処理を統一する方が自然だったのです。つまり、Sparkの「ストリーミング・オン・バッチ」アーキテクチャとは異なる「バッチ・オン・ストリーミング」アーキテクチャをFlinkは選択したのです。
Flinkのストリームとバッチのアーキテクチャの完全な統一は、一夜にして構築されたものではありません。初期のFlinkバージョンでは、Flinkのストリーム処理とバッチ処理は、APIやランタイムの面で完全には統一されていませんでした。Flink 1.9以降、Flinkはストリームとバッチの統一の改善とアップグレードを加速させています。ユーザーにとって最も主要なAPIであるFlink SQLは、ストリームとバッチの統一セマンティクスを率先して実現しました。これにより、ユーザーはストリームとバッチのパイプライン開発において、1つのSQL文のセットのみを使用することができ、開発コストを大幅に削減することができます。

しかし、SQLはすべてのユーザーの要求を満たすことはできません。状態を細かく操作するなど、高度なカスタマイズが必要なタスクでは、DataStream APIを使用する必要があります。一般的なビジネスシナリオでは、ストリーミングジョブを送信した後に、ユーザーは過去のデータを再生するために別のバッチジョブを作成することがよくあります。DataStreamは、ストリーム・コンピューティング・シナリオの様々な要件を効果的に満たすことができますが、バッチ処理の効率的なサポートは提供していません。
そのため、Flink 1.11以降、Flinkコミュニティは、DataStream APIにバッチ処理セマンティクスを追加することで、DataStream上でのストリームとバッチの統一機能の向上に注力するようになりました。バッチとストリームの統一の概念をコネクターの設計に適用することで、FlinkはDataStream APIをKafkaやHDFSなどの様々なタイプのストリームおよびバッチデータソースと接続することができます。将来的には、機械学習のシナリオのために、統一された反復APIをDataStream APIにも導入する予定です。
機能面では、やはりFlinkはSQLとDataStream APIの両方を使ったストリームコンピューティングとバッチコンピューティングの組み合わせとなっています。ユーザーのコードは、ストリームモードまたはバッチモードで実行されます。しかし、ビジネス・シナリオによっては、ストリーム・コンピューティングとバッチ・コンピューティングを自動的に切り替えることで、ストリームとバッチの統一性をより高く要求するものもあります。例えば、データ統合やデータレイクのシナリオでは、まずデータベース内の全データをHDFSやクラウドストレージサービスに同期させる必要があります。その後、データベース内の増分データを自動的に同期させる必要があります。このような同期の際には、統一されたストリームとバッチETL処理が行われます。Flinkは将来的に、よりインテリジェントなストリームとバッチの統一シナリオをサポートする予定です。
AlibabaにおけるFlinkベースのStream-Batch Unificationの開発について
Alibabaは、中国で初めてFlinkを選択した企業です。2015年、検索・推薦チームは、今後5年から10年の課題に対応するため、新しいビッグデータ・コンピューティング・エンジンを選びたいと考えていました。新しいコンピューティングエンジンは、検索・推薦バックエンドにおける膨大なアイテムやユーザーデータの処理を支援します。また、電子商取引では短いレイテンシーが要求されることから、大規模なバッチ処理とミリ秒レベルのリアルタイム処理の両方に対応できることが期待されています。つまり、ストリーム・バッチを統合したエンジンであることが求められました。当時、Sparkのエコシステムは成熟しており、ストリームとバッチの統合機能はSpark Streamingによって提供されていました。Flinkはその1年前にApacheのトップレベルのプロジェクトとされていました。新興のプロジェクトだったのです。SparkとFlinkについて調査・議論した結果、当時Flinkのエコシステムは成熟していなかったものの、ストリーム処理をベースにしたアーキテクチャの方がストリーム・バッチ統一に適しているということでチームは合意しました。そこでチームは、Alibaba社内でのFlinkの改良と最適化をもとに、検索とレコメンデーションのためのリアルタイム・コンピューティング・プラットフォームを構築することを即決しました。
チームによる1年間の努力の末、Flinkをベースとした検索・推薦用のリアルタイム・コンピューティング・プラットフォームは、2016年の「Double 11 Global Shopping Festival」のサポートに成功しました。アリババは、コアビジネスシナリオでの実践を通じて、Flinkベースのリアルタイムコンピューティングエンジンに対する理解を深めました。その結果、アリババのすべてのリアルタイムデータサービスがこのプラットフォームに移行されました。さらに1年間のハードワークの後、Flinkは2017年のW11 グローバルショッピングフェスティバルにおいて、GMVダッシュボードやその他のコアデータサービスのシナリオを含む、アリババのサポートされたリアルタイムデータサービスを成功させました。
2018年、Alibaba CloudはFlinkをベースにしたリアルタイムコンピューティング製品を発表し、中小企業向けのクラウドコンピューティングサービスを提供しました。アリババは、自社のビジネス課題を解決するためにFlinkを利用するだけでなく、Flinkのオープンソースコミュニティの発展を促進し、より多くの貢献をしたいと考えていました。アリババは2019年初頭にFlinkの創業企業であるVervericaを買収し、Flinkのエコシステムとコミュニティに多くのリソースを投入し始めました。2020年までには、世界の主流テクノロジー企業のほとんどが、リアルタイム・コンピューティングにFlinkを採用しています。Flinkは、ビッグデータ業界におけるリアルタイムコンピューティングのデファクトスタンダードとなりました。
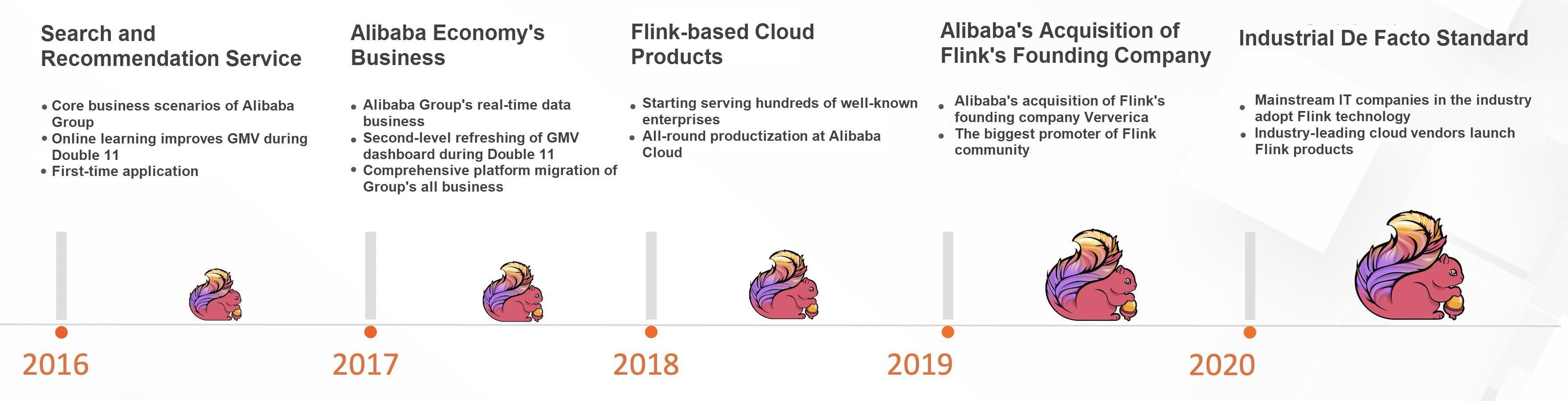
Flinkコミュニティは技術革新を続けています。2020 W11の期間中、Flinkベースのストリーム・バッチ・ユニフィケーションは、Tmallのコア・マーケティング意思決定システムにおいて顕著なパフォーマンスを発揮しました。さらに、Flinkベースのストリーム・バッチ・ユニフィケーションは、検索やレコメンデーションのシナリオにおいて、ストリーム・バッチ・インデックス作成と機械学習プロセスを成功させました。これらの事実は、5年前にFlinkを選択した判断が正しかったことを証明しています。今後は、より多くの企業がFlinkベースのストリーム・バッチユニフィケーションを採用すると思われます。
ストリーム・バッチ統一の技術革新がFlinkオープンソース・コミュニティの発展を促進
Flinkベースのストリーム・バッチ・ユニフィケーションの継続的な技術革新は、Flinkオープンソース・コミュニティとFlinkエコシステムの急速な発展を促進しました。中国の多くの企業がFlinkを採用するにつれ、中国のFlinkコミュニティは成長し、世界の主要なコミュニティになりつつあります。
最もわかりやすい兆候は、ユーザー数の増加です。2020年6月以降、Flinkの中国版メールリストは英語版メールリストよりも活発になっています。Flinkコミュニティにユーザーや開発者が流入することで、より質の高いコードライターが誕生し、Flinkエンジンの開発と反復が効果的に促進されています。
Apache Flink 1.8.0以降、Flinkの各バージョンにおけるコントリビューターの数は増加しています。ほとんどのコントリビューターは、中国の大手企業から来ています。間違いなく、中国の開発者とユーザーがFlink開発のバックボーンになりつつあります。
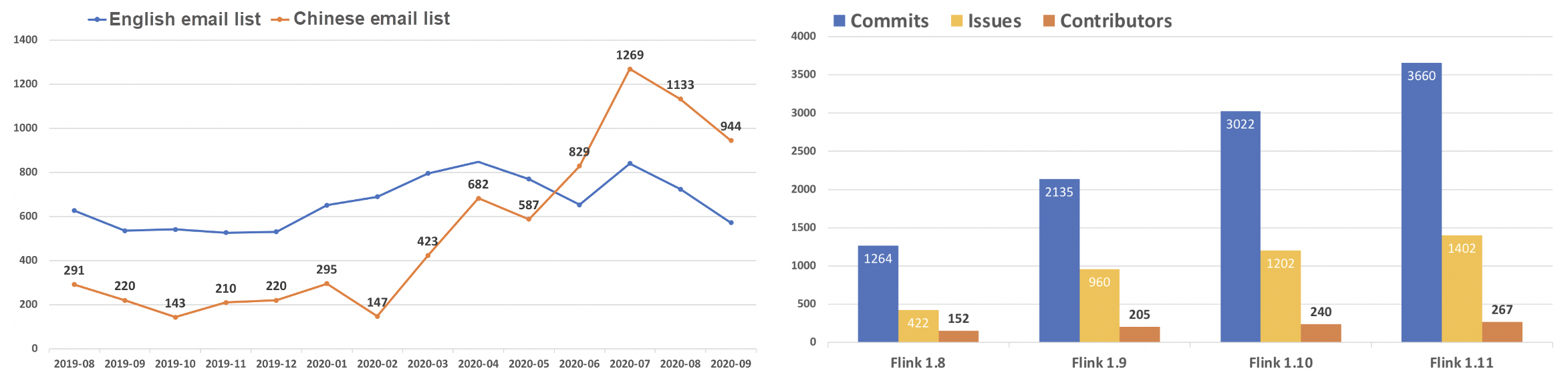
中国のコミュニティが成長を続ける中、2020年のFlinkはこれまで以上に活発な活動を行っています。Apache Software Foundationの2020年度報告書では、ユーザーや開発者の電子メールリストの活動において、Flinkはその年で最も活発なプロジェクトとなっています。また、コードコミットメント数やGitHubホームページのトラフィックにおいても、Flinkは第2位となっています。Apache Software Foundationの350近いトッププロジェクトの中で、このような結果を出すのは容易ではありません。
Flink Forward Asia 2020:ストリーム・バッチの統一を支える技術を公開
Flink Forwardは、Apacheが認定するFlinkの技術カンファレンスです。今年のFlink Forward Asia (FFA) Conferenceでは、開発者がオープンソースのビッグデータ技術を無料で学べるよう、オンラインでのライブ放送を採用しています。Alibaba、Ant Group、Tencent、ByteDance、Meituan、Kuaishou、Bilibili、NetEase、Weibo、Intel、DellEMC、Linkedinなど、世界を代表する多くのインターネット企業が、Flinkを使った技術的な実践やイノベーションを共有します。開発者はこれらの企業から直接学ぶことができます。
また、2020年のFFAカンファレンスでは、ストリーム・バッチ・ユニフィケーションが話題になります。Tmallのデータ技術責任者が、AlibabaにおけるFlinkベースのストリーム・バッチ・ユニフィケーションの実践と実装を紹介し、W11(独身の日)の中核となるシナリオにおいて、ストリーム・バッチ・ユニフィケーションがどのようにビジネス価値を生み出すのかをご紹介します。Alibaba社とByteDance社のFlink PMCおよびCommitterの専門家が、Flinkベースのストリーム・バッチ・ユニフィケーションのSQLおよびRuntimeについて、詳細な技術解説を行います。また、Flinkコミュニティの最新の技術動向についてもご紹介します。Tencent社のゲーム技術専門家は、ゲーム「Honor of Kings」におけるFlinkの適用事例を紹介します。Meituan社のリアルタイム・ビッグデータ担当ディレクターは、Flinkがライフサービスのシナリオをリアルタイムで機能させるのに役立つことを説明します。KuaishouのBig Fataの責任者は、KuaishouにおけるFlinkの開発について紹介します。Weiboの機械学習技術の専門家は、Flinkを使った情報推薦の方法を紹介します。このほか、金融、銀行、物流、自動車製造、旅行など、さまざまな業界のFlink関連トピックが紹介され、充実したエコシステムが展開されます。オープンソースのビッグデータ技術に興味のある熱心な開発者の方は、ぜひFFAカンファレンスにご参加ください。このカンファレンスでは、Flinkコミュニティにおける最新の技術開発やイノベーションについて学ぶことができます。
カンファレンスの公式サイト:https://www.flink-forward.org/

本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ