この記事では、Kubernetesアプリケーションの観測性を向上させ、そのLiveness と Readinessを確認する方法を学びます。
著者:アリババテクニカルエキスパート、Liu Zhongwei (Moyuan)
1)必要条件
まず初めに、Kubernetesに移行するアプリケーションの健全性と安定性を確保するための要件について説明します。この要件は、以下のような対策を講じることで満たされます。
- アプリケーションの観測性の向上
- アプリケーションの回復性の向上
アプリケーションの観測性の向上は以下のように行います。
- アプリケーションの健全性をリアルタイムで確認
- アプリケーションのリソース使用状況を把握
- アプリケーションのリアルタイムログをもとに、問題のトラブルシューティングや分析を行う
問題が発生した場合、その影響範囲を縮小し、トラブルを解決することが最優先されます。このような状況では、Kubernetesに統合されたセルフリカバリーの仕組みを使って、アプリケーションを完全に復旧させることが理想的な結果となります。
2) Liveness Probe と Readiness Probe
アプリケーションのヘルスステータス - Liveness Probe と Readiness Probeの紹介
Readiness Probeは、Podの準備ができているかどうかを確認するために使用します。準備完了状態のPodのみが外部サービスを提供し、アクセスレイヤーからのトラフィックを受信します。PodがReady状態でない場合、アクセスレイヤーはそのPodからのトラフィックをバイパスします。
簡単な例を見てみましょう。
次の図は、Readiness Probeの簡単な模式図です。
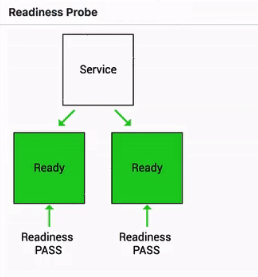
Readiness ProbeでPodが「Failed」状態であると判断された場合、アクセスレイヤーからのトラフィックはPodに向けられません。
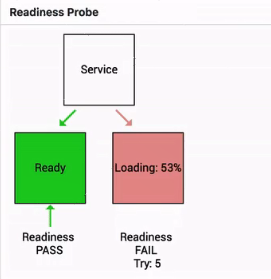
Podは,状態がFailedからSucceededに変化した後にのみ,アクセス層からのトラフィックを受信します。
Podが生存しているかどうかを確認するには、Liveness Probeを使用します。Podが生存していない場合はどうなるでしょうか?
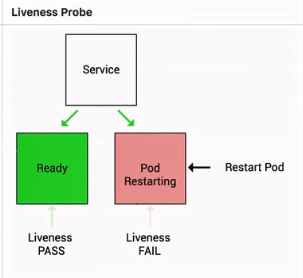
高レベルのメカニズムは、Podを再起動するかどうかを決定します。設定されたハイレベルポリシーが「restart always」の場合、Podは直接再起動されます。
アプリケーションの健全性 - 使用方法
このセクションでは、Liveness Probe と Readiness Probeの使用方法について説明します。
チェック方法
Liveness ProbeおよびReadiness Probeは、3つのチェック方法をサポートしています。
- HTTP GET:アプリケーションの健全性をチェックするために、HTTP GETリクエストを送信します。リターンコードが200~399の範囲であれば、アプリケーションは正常であると考えられます。
- exec: コンテナ内でコマンドを実行することで、サービスが正常かどうかをチェックします。コマンドに対して0が返された場合、コンテナは健全と考えられます。
- TCPソケット:コンテナのIPアドレスとポートを確認することで、コンテナのTCPヘルスチェックを行います。TCP接続が確立されていれば、コンテナは健全です。
チェック結果
チェック結果は3つの状態に分かれています。
- Succeeded(成功):コンテナがヘルスチェックに合格し、Liveness ProbeやReadiness Probeで正常と判断されたことを示す。
- Failed(失敗):コンテナがヘルスチェックに合格しなかったことを示します。Readiness ProbeがPodの異常を判断した場合、Podはサービスレイヤから削除されます。Liveness Probeでpodが異常であると判断された場合、podは再起動または削除されます。
- Unknown: メカニズムがタイムアウトしたり、スクリプト実行後すぐに応答が返されないなど、現在のメカニズムが完全には実行されていないことを示します。この場合、Readiness ProbeまたはLiveness Probeは、何の操作も行わずに次のチェックメカニズムを待ちます。
kubelet には、pod 診断によってアプリケーションの健全性をチェックする liveness probe または readiness probe を提供する ProbeManager コンポーネントが含まれています。
アプリケーションヘルスステータス - Pod Probe Spec
以下では、上記のチェックメソッドで使用するYAMLファイルについて説明します。
最初に exec チェックメソッドについて説明します。次の図は、exec ベースの診断と、現在のプローブのステータスをチェックするために cat の特定のファイルが使用されるコマンドフィールドで構成された Liveness Probeです。Liveness Probeは、ファイル内の戻り値(またはコマンドの戻り値)が0の場合、Podが健全であると判断します。

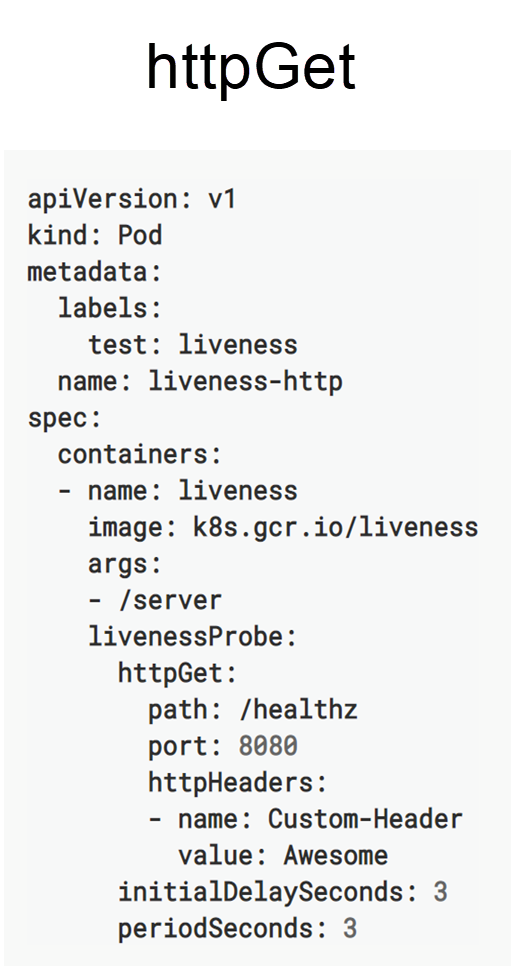
次の図は、「path」「port」「headers」の3つのフィールドで構成されるHTTP GETメソッドです。「headers」フィールドは、ヘッダー値に基づいて健康状態を判断する場合に必要です。それ以外の場合は、「health」と「port」のフィールドのみが必要です。
もう一つの簡単な方法は、監視ポートだけを必要とするTCPソケット方式です。次の図では、ポート8080が監視ポートとなっています。TCPソケット方式のヘルスチェックで使用されるプローブは、レビュー後にポート8080を介してTCP接続が確立されると、Podが健全であると判断します。
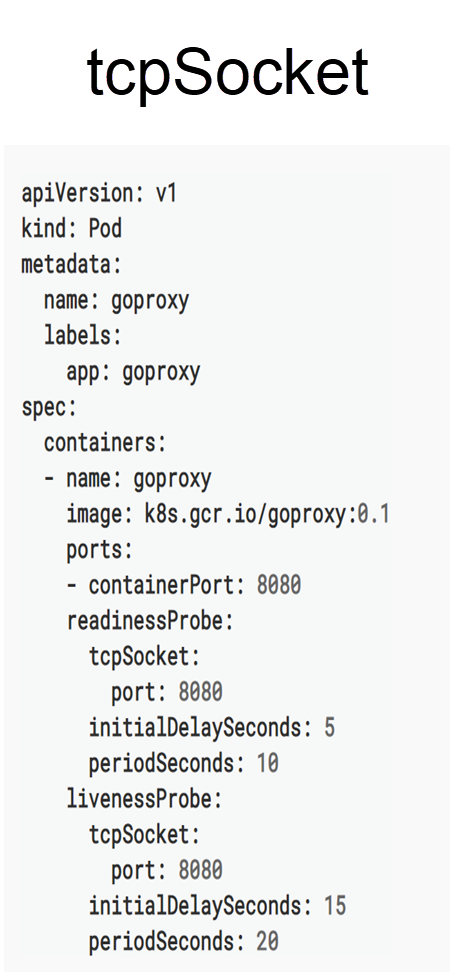
ヘルスチェックで使用されるグローバルパラメーターは以下の5つです。
- initialDelaySecondsパラメータは、チェックが実行される後の起動遅延時間を示します。例えば、Javaアプリケーションの起動には、JVMの起動やJARのロードが必要なため、長い時間がかかる場合があります。そのため、ある期間はJavaアプリケーションのチェックが行われない可能性がありますが、これは予測可能であり、initialDelaySecondsパラメータの設定によって指定されます。
- periodSecondsパラメータはチェックの間隔を示し、デフォルトでは10秒です。
- timeoutSecondsパラメータは、ヘルスチェックのタイムアウト期間を示します。タイムアウト期間内にヘルスチェックが失敗した場合、アプリケーションは「失敗」と見なされます。
- successThresholdパラメータは、再試行されるヘルスチェックの最大回数を示します。このパラメータのデフォルト値は「1」で、最初にヘルスチェックに失敗した後、2回目のヘルスチェックが成功した場合、Podは健全であるとみなされることを示しています。
- failureThreshold パラメーターは、Podが「失敗」であるかどうかを判断するためのヘルスチェック再試行の最大回数を示します。このパラメータのデフォルト値は「3」で、健康な状態でヘルスチェックに3回連続して失敗した場合に、Podが「故障」と判断されることを示しています。
アプリケーションのヘルスステータス - Liveness and Readiness Probesの概要
次の表は、livenessおよびreadyiness probeの概要です。

3)問題の診断
それでは、Kubernetesにおける一般的な問題のトラブルシューティング方法を理解しましょう。
アプリケーションのトラブルシューティング - ステートメカニズム
Kubernetesの設計思想として、ステートメカニズムがあります。Kubernetesはステートマシンに特化して設計されており、YAMLファイルを使って期待される状態を定義します。YAMLファイルが実行されると、コントローラによって状態の遷移が管理されます。
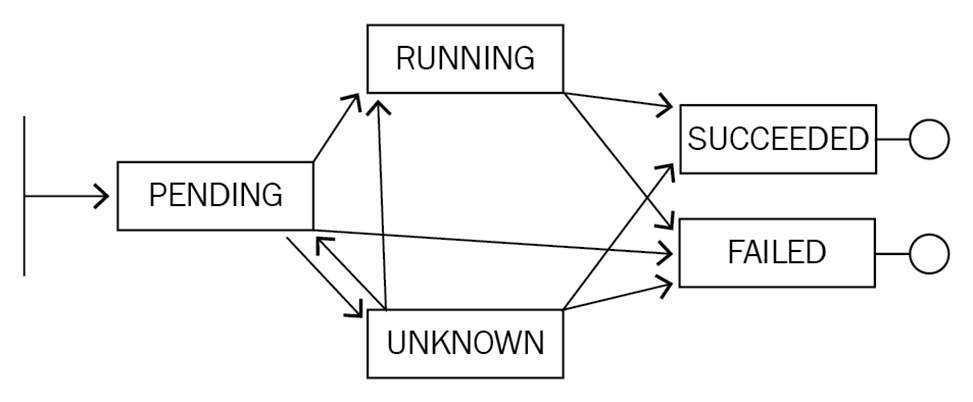

前述の図は、Podのライフサイクルを示しています。Podは,最初の「Pending」状態から「Running」,「Unknown」,「Failed」のいずれかの状態になることがあります。Podは,しばらく動作した後に,SucceededまたはFailedの状態に変化することがあります。また、リカバリーによって、Unknown状態からRunning、Succeeded、Failed状態になることもあります。
Kubernetesのシステムは、ステートマシンに似た方法で状態遷移を実装しています。特定の状態遷移は、対応するKubernetesオブジェクトの「Status」および「Conditions」フィールドによって示されます。
次のスクリーンショットは、Podの状態を示しています。
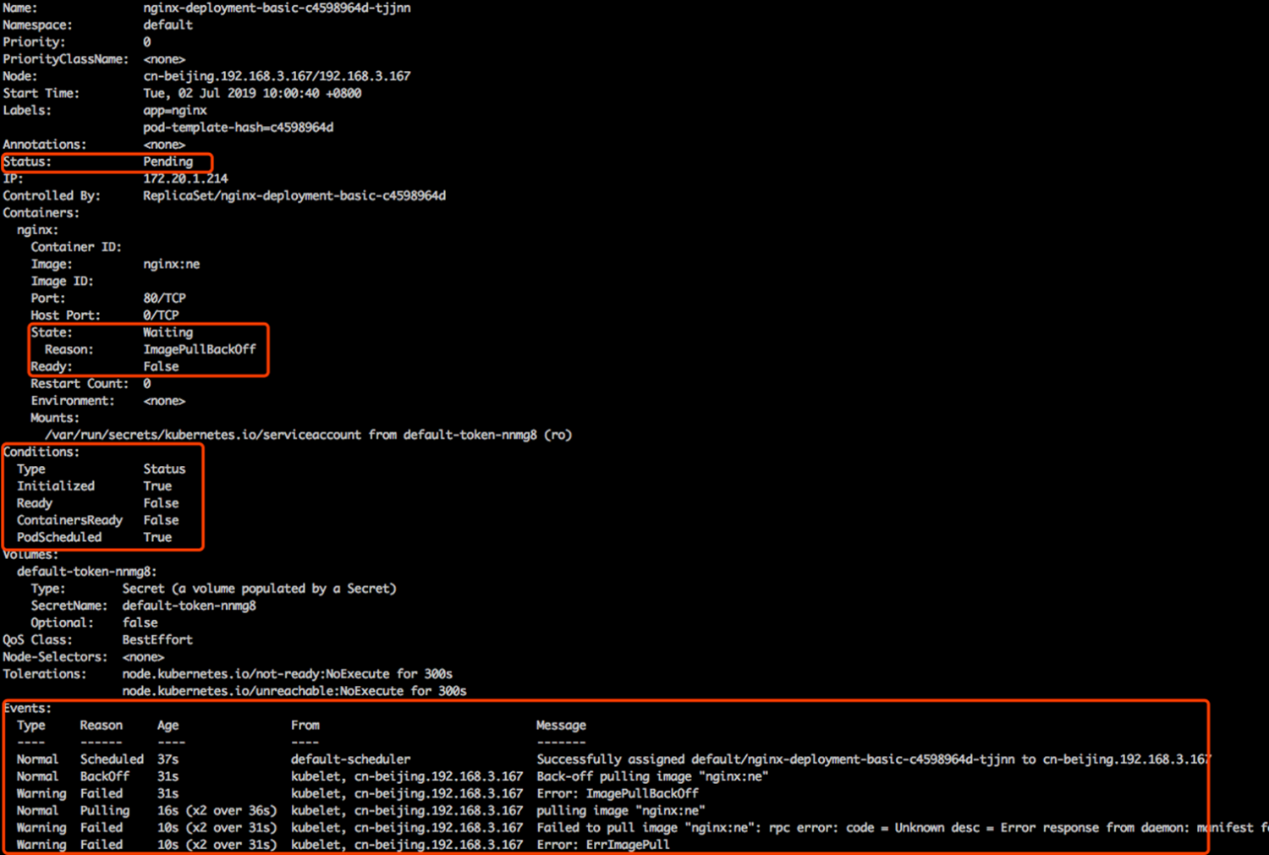
「Status」フィールドは、Podの集約されたステータスを示し、この場合は「Pending」になります。
「State」フィールドは、Pod内の特定のコンテナの集約されたステータスを示しており、この場合はコンテナイメージがまだプルされていないため「Waiting」となっています。Ready は False に設定されていますが、これはコンテナ・イメージがpullされるまでPodが外部サービスを提供できないためです。Podが外部サービスを提供するのは、高レベルエンドポイントがReadyの値をTrueと判断した場合のみです。
KubernetesシステムのConditionsフィールドが集約され、Statusフィールドが決定されます。InitializedはTrueに設定され、Podが初期化されたことを示します。Ready は False に設定され、コンテナイメージがまだ引き出されていないことを示します。
ContainersReady は False に設定されています。PodScheduled は、Podがスケジュールされ、ノードにバインドされていることを示すために True に設定されます。
Podの状態は、Conditionsフィールドの値(TrueまたはFalse)に基づいて決定されます。Kubernetesの状態遷移では、通常イベントと警告イベントの2種類のイベントが発生します。最初の通常イベントの理由は「Scheduled」で、Podがデフォルトのスケジューラによって cn-beijing192.168.3.167 というノードにスケジュールされていることを示しています。
別の正常なイベントの理由は「Pulling」で、画像が引き出されていることを示しています。警告イベントの理由は「Failed」で、イメージの引き抜きに失敗したことを示しています。
正常イベントと警告イベントは、それぞれKubernetesの状態遷移の発生を示しています。開発者は、状態遷移の際に発生するイベントだけでなく、「Status」と「Conditions」のフィールドに基づいて、アプリケーションの状態を判断し、診断を行います。
アプリケーションのトラブルシューティング - 一般的なアプリケーションの例外
このセクションでは、一般的なアプリケーションの例外について説明します。Podは特定の状態に留まることがあります。
Podが保留状態のまま
Podは、スケジューラーによってスケジュールされるまで保留状態にとどまります。kubectl describe podコマンドを実行して、特定のイベントを表示します。イベントが、リソースまたはポートの占有、またはノードセレクタエラーのためにPodをスケジュールできないことを示している場合は、イベントの結果を表示します。イベント結果には、CPU容量不足、ノードエラー、タグ付けエラーによる不適合ノードの数がそれぞれ表示されます。
Podが待機状態のまま
Podが待機状態になるのは、ほとんどの場合、イメージが引き出せないためです。イメージの引き抜きができないのは、以下のような原因が考えられます。
(1)イメージがプライベートイメージであり、Pod Secretが設定されていない
(2) イメージのアドレスが存在しない
(3)イメージがパブリックイメージである
Podが何度も再起動して反応しなくなる
Podの再起動が繰り返され、バックオフが発生する場合は、Podがスケジュールされているが起動できないことを示しています。この場合、設定や権限を確認するのではなく、Podログを確認してアプリケーションの状態を判断してください。
Podは実行状態にあるが、異常が発生している
実行状態のPodが外部サービスを提供できない場合、設定を詳細に確認します。例えば、YAMLファイルの一部が、フィールドのスペルミスにより配信後に有効にならない場合があります。この場合、apply-validate-f pod.yamlコマンドを実行してYAMLファイルを確認します。YAMLファイルが正しい場合は、設定されているポートが正常かどうか、livenessまたはreadyiness probeが正しく設定されているかどうかを確認してください。
サービスが異常な場合
サービスが異常な場合、正しく使われているかどうかを確認します。サービスとPodの関連付けは、セレクタによって行われます。サービスは、Podに設定されているラベルと一致することで、Podとの関連付けを行います。ラベルの設定が間違っていると、サービスが後続のエンドポイントを見つけることができず、サービス提供に失敗することがあります。サービスの異常時には、エンドポイントがサービスに追従して外部サービスを適切に提供しているかを確認します。
4) アプリケーションのリモートデバッグ
ここでは、KubernetesのPodやサービスをリモートでデバッグする方法と、リモートデバッグによるパフォーマンスの最適化について説明します。
Podのリモートデバッグ
コンテナにログオンして、クラスタ内の問題のあるアプリケーションを診断、検証、または修正します。

例えば、execコマンドを実行してPodにログオンします。Pod上でインタラクティブなbashを起動するには、kubectl exec-it pod-nameコマンドに/bin/bashを追加します。このbashでは、コマンドを実行することで、再設定などの操作を行うことができます。その後、Supervisorを通じてアプリケーションを再起動します。
マルチコンテナのPodをリモートでデバッグするには、前図の2番目のコマンドのように、pod-name -cの後のcontainer-nameに対象のコンテナ名を設定し、kubectl exec-it pod-nameコマンドにサフィックスを追加します。
リモートサービスのデバッグ
サービスをリモートでデバッグするには、次の2つの方法のいずれかを導入します。
- リバース・デバッグ:サービスをリモート・クラスターに公開し、クラスター内のアプリケーションがサービスを呼び出すようにします。
- フォワードデバッギング:ローカルサービスがリモートサービスを呼び出すようにします。
リバースデバッグでは、オープンソースのコンポーネントであるTelepresenceを使用して、リモートクラスタのサービスをローカルアプリケーションのプロキシとして構成します。

TelepresenceのプロキシアプリケーションをリモートのKubernetesクラスタにデプロイし、DEPLOYMENT_NAMEを定義してTelepresence-swap-deploymentコマンドを実行することで、単一のリモートデプロイメントをローカルアプリケーションにスワップします。これにより、リモートサービスをローカルアプリケーションのプロキシとして設定し、リモートクラスタでアプリケーションをローカルにデバッグすることができます。Telepresenceの使用方法については、GitHubを参照してください。
ローカルアプリケーションがリモートクラスタ内のサービスを呼び出す必要がある場合、ポートフォワードモードでローカルポートを介してリモートサービスを呼び出します。たとえば、ポートフォワードモードでリモートクラスターのポートを提供するAPIサーバーを直接呼び出して、ローカルでコードをデバッグします。

リモートサービスの名前と名前空間を付加したkubectl port-forwardコマンドを実行することで、ローカルポートをリモートアプリケーションのプロキシとして設定します。これにより、ローカルポートからリモートサービスへのアクセスが可能になります。
オープンソースデバッガー - kubectl-debug
ここでは、kubectlが使用するオープンソースのデバッガーであるkubectl-debugについて説明します。Dockerとcontainerは、Kubernetesにおける共通のコンテナランタイムです。これらは、Linuxの名前空間に基づいて仮想化され、分離されています。
通常、アプリケーションをスリムに保つために、NetstatやTelnetなどの少数のデバッガーのみがイメージに埋め込まれます。デバッグにはkubectl-debugを使用します。
kubectl-debugツールは、Linux名前空間を直接デバッグするのと同じように、追加のコンテナに適用してデバッグを行います。以下に簡単な例を示します。
kubectl-debug(kubectlのプラグイン)をインストールしたら、「kubectl-debug」コマンドを実行してリモートPodを診断します。このコマンドは、診断ツールがデフォルトで含まれているイメージを引き出すために実行され、イメージの起動時にデバッグコンテナを起動します。一方、このコマンドはデバッグコンテナを診断対象のコンテナがあるネームスペースに接続します。このようにして、デバッグコンテナは診断対象のコンテナと同じネームスペースになります。これにより、デバッグコンテナでWebサイトの情報やカーネルのパラメータをリアルタイムで見ることができます。
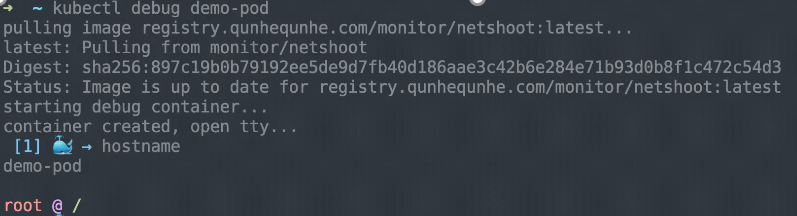
ホスト名、プロセス、netstatなどの情報を含むデバッグコンテナは、デバッグ対象のPodと同じ環境にあります。そのため、前のセクションで説明した3つのコマンドを実行することで、これらの情報を簡単に見ることができます。
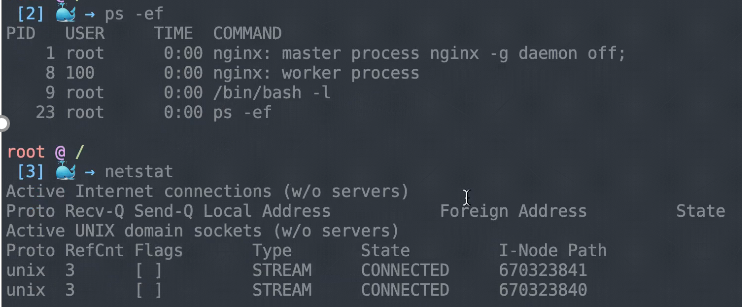
kubectl-debugコマンドは、ユーザーがログアウトしたときにデバッグPodをシャットダウンしますが、これはアプリケーションには影響しません。これにより、実際にコンテナにログオンすることなく、コンテナを診断することができます。

また、htopでイメージを構成してコマンドラインツール(CLI)をカスタマイズし、リモートでPodをデバッグすることもできます。
概要
この記事では、liveness probeとreadyiness probeについて説明しました。liveness probeは、podが生存しているかどうかをチェックし、readiness probeは、podが外部サービスを提供する準備ができているかどうかをチェックします。また、アプリケーションを診断するための手順を紹介します。
(1) アプリケーションの状態を説明
(2) アプリケーションの状態に応じて、診断プランを決定
(3) オブジェクトイベントに基づいて詳細情報を取得
さらに、リモートデバッグ戦略の実施方法を提案しています。Telepresenceを使用して、ローカルアプリケーションのためにリモートクラスタにプロキシを構成したり、ポートフォワードモードを使用して、ローカル通話やデバッグのためにリモートアプリケーションにローカルプロキシを構成する方法を説明しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ