本記事は「Kubernetes入門」シリーズの一環として、Kubernetesを運用する上で欠かせないコンポーネントである「メタデータ」に焦点を当てています。
著者:アリババクラウドのシニアテクニカルエキスパート、Zhang Zhen
1) リソースメタデータ
i) Kubernetesリソースオブジェクト
すべてのKubernetesリソースオブジェクトは、オブジェクトの仕様とオブジェクトのステータスからなる2つのネストされたオブジェクトフィールドを含みます。仕様にはオブジェクトの望ましい状態が記述され、ステータスには実際の状態が記述されます。
この記事では、Kubernetesに不可欠なメタデータを紹介します。メタデータには、リソースを識別するためのラベル、リソースを記述するためのアノテーション、リソース間の関係を記述するためのOwnerReferencesなどがあります。メタデータはKubernetesの運用に欠かせないものです。
ii)ラベル
メタデータの最初で最も重要な項目は、リソースラベルです。リソースラベルは、オブジェクトを識別するために使用されるキーバリュー型のメタデータです。次の図は、いくつかの一般的なラベルを示しています。

最初の3つのラベルは、Kubernetesのオブジェクトの一種であるPodに付けられています。これらのラベルはそれぞれ、対応するアプリケーション環境、リリースの成熟度、アプリケーションのバージョンを識別します。また、アプリケーションのラベルの例で示したように、ラベル名にはドメイン名のプレフィックスが含まれており、ラベリングシステムやツールの説明になっています。一方、最後のラベルは、ノードに付けられたものです。このラベルでは、ドメイン名の前に、ベータ版の文字列であるバージョンIDが付加されています。
ラベルは、リソースのフィルタリングや結合に使用されます。SQLのselect文を実行して、ラベルでリソースを照会します。
iii) セレクタ
最も一般的なセレクタのタイプは、等値線ベースのセレクタです。簡単な例として、次の図を参照してください。
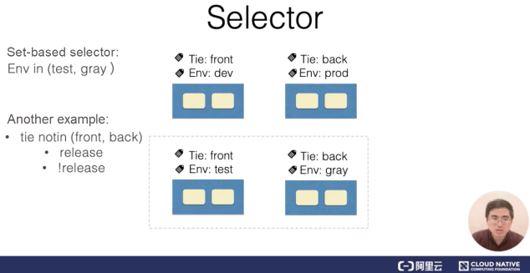
システムに4つのPodがあり、それぞれのPodにシステムの階層と環境を識別するラベルがあるとします。この場合、左サイドバーのPodと一致するように、タイ、フロントのラベルを使用します。等値性ベースのセレクタには、論理的に「AND」の関係にある複数の等値性ベースの要件が含まれます。
前述の例では、「Tie = front」および「Env = dev」の要件を持つセレクタがフィルタリングを行い、両方の要件を満たすすべてのPodを取得します。これらのPodは、図の左上に表示されています。もう1つのタイプのセレクタは,セットベースのセレクタです。この例では,セレクタは,「Env = test」または「Env = gray」の要件を満たすすべてのPodをフィルタリングして取り出します。
セレクタは、INSET操作に加えて、NOTINセット操作も行います。例えば、セレクタがtie NOTIN (front,back)の要件に基づいてPodをフィルタリングする場合、セレクタは、ティア(つまり、この記事では「tie」)がfrontでもbackでもないすべてのPodを取得します。また、セレクタは、特定のラベルを含むすべてのPodを取得するためにフィルタリングを実行しても良いです。例えば,ラベルに "release "が含まれている場合,セレクタは "release "とラベル付けされているすべてのPodを取得する.セットベースのセレクタとイコールベースのセレクタは、論理的な「AND」関係を識別するためにカンマ()を使用することもできます。
iv) アノテーション
アノテーションは、メタデータのもう一つの重要な項目です。一般的に、システムやツールはアノテーションを使ってリソースの非識別情報を保存し、リソースの仕様や状態の説明を拡張します。ここでは、アノテーションの例をいくつか挙げます。

最初の例では、アノテーションはAlibaba Cloudロードバランサーの証明書IDを格納しています。アノテーションには、ドメイン名のプレフィックスやバージョン情報を含めることもできます。2つ目のアノテーションには、Nginxのイングレスレイヤーの構成情報が格納されています。このアノテーションには、ラベルでは許可されていないカンマ(,)などの特殊文字が含まれていることに注意してください。3つ目のアノテーションは、kubectl applyコマンドを実行した後のリソースでよく見られます。このアノテーションの値は構造化されており、実際にはJSON文字列で、以前にkubectlによって操作されたリソースのJSONベースの説明にアノテーションを付けます。
v)OwnerReferences
OwnerReferencesは、メタデータの最後の項目です。オーナーは通常、セットベースのリソースを参照します。たとえば、Podセットには、ReplicaSetsとStatefulSetsがありますが、これらについては以降の記事で説明します。
セットベースのリソースのコントローラは、対応する所有リソースを作成します。たとえば、ReplicaSetコントローラが操作中にPodを作成すると、作成されたポッドのOwnerReferenceは、Podを作成したReplicaSetコントローラを指します。OwnerReferenceを使用すると、ユーザーはリソースを作成したオブジェクトを簡単に見つけることができ、カスケード削除を実装することができます。
2)運用デモ
まず、kubectlコマンドを実行して、Alibaba Cloud Container Service for Kubernetes(ACK)で作成されたKubernetesクラスタに接続します。続いて、Kubernetesオブジェクトのメタデータを表示・修正する方法を見てみましょう。メタデータには、ラベル、アノテーション、ポッドの対応するOwnerReferenceなどがあります。
まずは、クラスターの現在の構成を確認することから始めましょう。
ステップ1)クラスタ内のポッドの構成を確認します。この出力は、Podが存在しないことを示しています。
kubectl get pods
ステップ2)2つのPodのプリセットのそれぞれのYAMLファイルを使用して、2つのPodを作成します。
kubectl apply -f pod1.yamlkubectl apply -f pod2.yaml
ステップ3)Podに付けられたラベルを確認します。--show-labelsオプションをつけると、2つのPodそれぞれに、デプロイメント環境とティアのラベルがつきます。
kubectl get pods --show-labels
ステップ4)別の方法で詳細なリソース情報を表示することもできます。まず、1つ目のPodであるnginx1の情報を表示します。次に、-o yamlを使って情報を出力します。このPodのメタデータには、値が2つのラベルを持つlabelsフィールドが含まれていることを確認します。
kubectl get pods nginx1 -o yaml | less
ステップ5)Podの既存のラベルを変更するには、まずPodのデプロイメント環境を開発環境からテスト環境に変更します。次に、Pod名を指定し、環境ラベルに「test」の値を追加して、修正が成功したかどうかを確認します。この場合、ラベルにすでに値が入っていることを示すエラーが報告されます。
kubectl label pods nginx1 env=test
ステップ6)既存のラベルの値を上書きするには、overwriteオプションを追加します。ラベル付けが成功すると、この追加を投稿します。
kubectl label pods nginx1 env=test -overwrite
ステップ7)クラスターの現在のラベル設定を確認します。nginx1にデプロイ環境「test」を示すラベルが追加されています。kubectl get pods --show-labels
ステップ8)Podからラベルを削除するには、(ステップ5)で示したラベル追加の操作と同様の操作を行います。ここでの違いは、env値の後に等号(=)がなく、ラベル名とマイナス記号(-)が続くことで、ラベルのキーと値(k:v)のペアを削除することを示しています。
-kubectl label pods nginx tie-
ステップ9)クラスターの現在のラベル設定を再度確認します。ラベルが完全に削除されていることを確認します。
kubectl get pods --show-labels
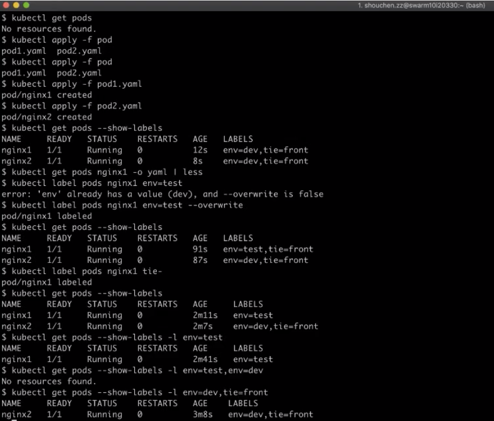
ステップ10)設定したラベルの値を確認します。nginx1のPodでは、tie = frontのラベルが除外されていることに注意してください。このPodのラベルを外した後、ラベルセレクタがPodとどのようにマッチしているかを見てみましょう。ラベルセレクタは、-lオプションで指定します。ここでは、デプロイメント環境がtestであるPodを取得するためのフィルタリングを行うために、等号ベースのラベルを指定します。フィルタリングの結果、Podが1つ表示されています。
kubectl get pods --show-labels -l env=test
ステップ11)複数のイコールベースの要件を指定する必要がある場合は、「and」の関係になります。envがdevと等しい場合、Podは1つも取得できません。
kubectl get pods --show-labels -l env=test,env=dev
ステップ12)envがdevに等しく、tieがfrontに等しい場合、別のPodドがヒットします。このPodはnginx2です。
kubectl get pods --show-labels -l env=dev,tie=front
ステップ13)セットベースのラベルセレクタを使って、Podをフィルタリングしてみます。このケースでも、デプロイメント環境がtestまたはdevであるすべてのPodにマッチすることを意図しています。そのため、ここでシングルクォーテーションマーク(' ' )を追加し、すべてのデプロイメント環境を括弧内に指定します。このようにして、フィルタリングの結果、作成された両方のPodが表示されます。
kubectl get pods --show-labels -l 'env in (dev,test)
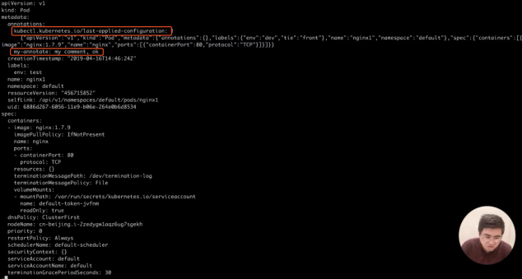
ステップ14)Podにアノテーションを追加してみましょう。アノテーションの追加は、labelコマンドがannotateコマンドに置き換えられていることを除けば、ラベルの追加と似ています。タイプと名前も同じように指定します。最終的には、ラベルのk:vペアがアノテーションのそれに置き換えられます。ここで、k:vのvパラメータには、スペースやカンマなどの任意の文字列を設定します。kubectl annotate pods nginx1 my-annotate='my annotate,ok
ステップ15)次に、このPodのメタデータを確認してみましょう。なお、このPodのメタデータには、my-annotateアノテーションが含まれています。kubectl get pods nging1 -o yaml | less
また、kubectl applyコマンドを実行すると、kubectlツールがアノテーションを追加しますが、これもJSON文字列であることに注目してください。
ステップ16)次に、PodのOwnerReferenceの生成方法を見てみましょう。オリジナルのPodは、すべてポッドリソースの作成によって直接作成されていました。ここでは、ReplicaSetオブジェクトを作成してPodを作成する別の方法を採用しています。ReplicaSetオブジェクトを作成したら、以下のコマンドを実行して、このReplicaSetオブジェクトを以下のファイルで表示します。
kubectl apply -f rs.yamlkubectl get replicasets nginx-replicasets -o yaml |less
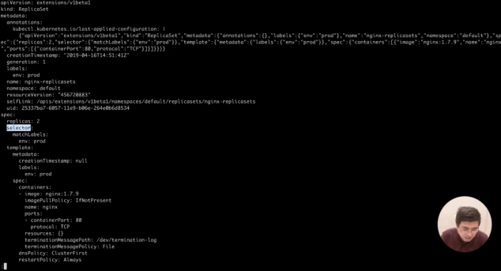
ステップ17)このReplicaSetの仕様には、2つのPodを作成することが記載されており、その後、セレクタは、デプロイ環境が本番環境であることを示すラベルを使用してPodを照合します。そこで、以下のコマンドでクラスタ内のPodの状態を確認してみましょう。
kubectl get pods
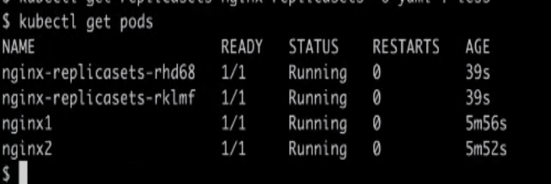
ステップ18)さらに2つのPodが作成されていることに注意してください。両方のPodを詳しく見てみると、ReplicaSetによって作成されたPodにはOwnerReferencesが含まれており、これはnginx-replica setsというReplicaSetタイプを指していることがわかります。
kubectl get pods nginx-replicasets-rhd68 -o yaml | less
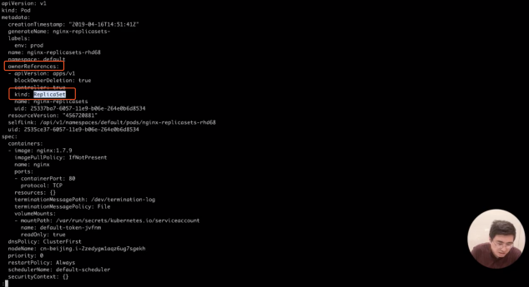
3)コントローラーモード
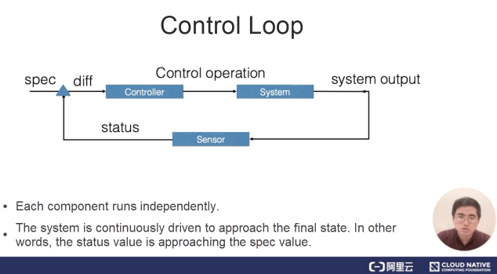
i) コントロールループ
コントローラーモードの中心となるのは、コントロールループという概念です。コントロールループは、「コントローラー」「被制御システム」「システムを監視するセンサー」という3つの論理的な構成要素で成り立っています。
もちろん、これらの構成要素は論理的なものです。外部コンポーネントは、リソースオブジェクトの仕様を変更することで制御し、コントローラは、このリソースオブジェクトの仕様とステータス値を比較して差分値を算出します。そして、この差分値を用いて、システムに対して制御操作を行う必要があるかどうかを判断します。制御操作は、システムに新しい出力を生成させ、その出力はセンサーによってリソースオブジェクトのステータスとして報告されます。コントローラの各コンポーネントは独立して動作し、システムの現在の状態を継続的に駆動して、仕様で示された最終状態に近づけます。
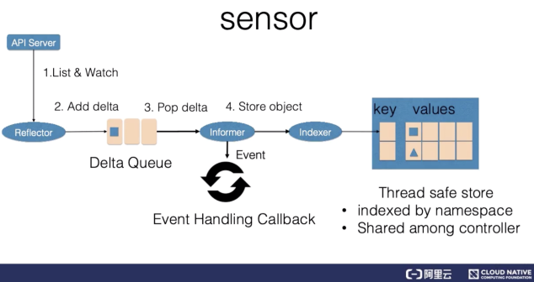
ii)センサー
制御ループにおける論理的なセンサーには、リフレクター、インフォーマー、インデクサーの3つのコンポーネントがあります。
リフレクタは,Kubernetes APIサーバのリストとウォッチの仕組みを使ってリソースデータを取得します。具体的には、リストは、対応するコントローラが再起動したときやウォッチが中断したときに、システムリソースのフルアップデートを行うために使用されます。一方、ウォッチは、リスト操作の合間にリソースの増分更新を行うために使用します。次に、新しいリソースデータを取得した後、リフレクタはデルタレコードをデルタキューに挿入します。デルタレコードには、リソースオブジェクトの情報とイベントタイプが含まれています。デルタキューは、リフレクタがリスト操作やウォッチ操作を繰り返す際に、同じオブジェクトがキュー内に1つのレコードしか持たないようにして、レコードが繰り返されないようにします。
informerコンポーネントは、deltaキューから常にdeltaレコードを出力し、リソースオブジェクトをindexerに引き渡し、indexerがリソースオブジェクトをキャッシュに記録するようにします。デフォルトでは、キャッシュはリソースの名前空間を使用してインデックス化され、コントローラマネージャや複数のコントローラで共有することができます。最後に、このイベントはイベントのコールバック関数に送られます。
制御ループ内のコントローラコンポーネントは、イベントハンドラ機能とワーカーで構成されています。イベントハンドラ関数は、リソースの追加、更新、削除に着目し、コントローラのロジックに従って、これらのイベントを処理するかどうかを判断します。処理すべきイベントについては、コントローラが、そのイベントに関連するリソースの名前空間と名前をワークキューに挿入し、後続のワーカープールのワーカーがそのイベントを処理します。ワークキューは、同じリソースが複数のワーカーによって処理されることを防ぐために、保存されたオブジェクトの重複を削除します。
リソースオブジェクトを扱う際、ワーカーは通常、リソースオブジェクトの再作成や更新、他の外部サービスの呼び出しのために、リソース名を用いて最新のリソースデータを取得する必要があります。処理に失敗した場合、ワーカーはリソース名を作業キューに再追加し、リソースオブジェクトが再び便利に処理されるようにします。
iii) 例 - 制御ループ - スケールアップ
次の簡単な例は、制御ループがどのように機能するかを示しています。
ReplicaSetsは、ステートレスアプリケーションのスケーリングを説明するリソースを表しています。ReplicaSetコントローラは、ReplicaSetsをリッスンして、アプリケーションに必要な状態数を維持します。さらに、ReplicaSetsは、セレクタを使用して関連するPodをマッチングします。この例では、ReplicaSet rsAのレプリカの数が2から3に変更されています。
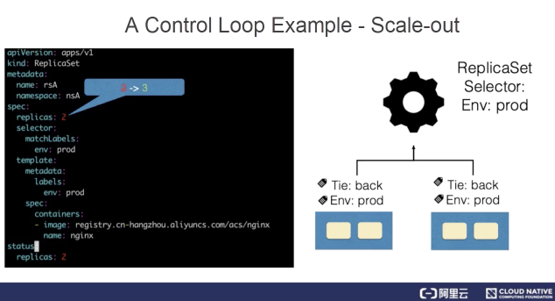
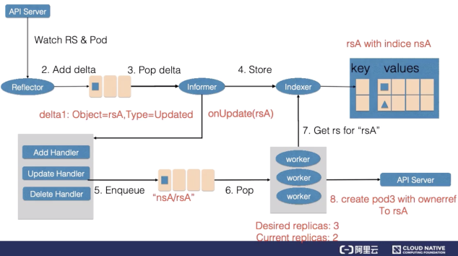
まず、リフレクターはReplicaSetとPodリソースの変更を監視します。Podへの変更を監視する理由は、後で説明します。ReplicaSetの変更が検出されると、rsAオブジェクトと更新タイプを示すレコードがデルタキューに挿入されます。
情報提供者は、新しいReplicaSetをキャッシュに更新し、ReplicaSetのnamespaceフィールドにインデックスを作成し、キーをnsAに設定します。その後、情報提供者は、更新コールバック関数を呼び出します。ReplicaSetへの変更を検出した後、ReplicaSetコントローラは、nsA/rsAの文字列を作業キューに挿入します。作業待ち行列の最後のワーカーは、作業待ち行列からnsA/rsA文字列のキーを取得し、キャッシュから最新のReplicaSetデータを取得します。
ワーカーはReplicaSetのspecificationとstatusの値を比較して、ReplicaSetをスケールアップする必要があります。ReplicaSetのワーカーはPodを作成し、このPodのOwnerReferenceはReplicaSet rsAを指しています。
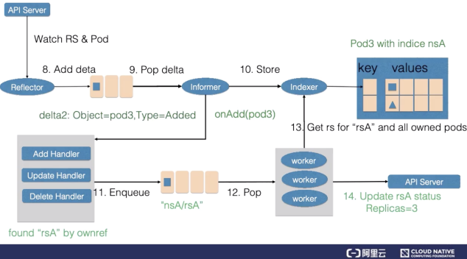
次に、リフレクタはPodの追加イベントを監視し、追加型のデルタレコードをデルタキューに追加します。このようにして、新しいPodレコードがインデクサを介してキャッシュに格納され、ReplicaSetコントローラのaddコールバック関数が呼び出されます。addコールバック関数は、PodのOwnerReferencesをチェックして対応するReplicaSetを見つけ、ReplicaSetの名前空間と名前を含む文字列をワークキューに挿入します。
新しいワークアイテムを取得した後、ReplicaSetのワーカーは、キャッシュから新しいReplicaSetのレコードを取得し、ReplicaSetが作成したすべてのPodを取得します。ReplicaSetのステータスは最新ではないので、作成されたPodの数も最新ではないことになります。そこで、ReplicaSetはステータスを更新し、仕様とステータスを一致させます。
4) コントローラーモード - まとめ
i) 2つのAPI設計手法
Kubernetesのコントローラモードは、宣言型APIに依存しています。もう一つの一般的なAPIのタイプは、命令型APIです。ここで生じる重要な疑問は、なぜKubernetesはコントローラ全体の設計に、命令型APIではなく宣言型APIを使用するのか、ということです。
まず、この2種類のAPIの違いをインタラクションの観点から比較してみましょう。私たちの日常生活において、一般的な命令型のインタラクションモードは、親が子供とコミュニケーションをとる方法と同じです。しかし、子供は親の意図を知らないため、親の期待を理解することができません。このような場合、親は子供に食事や睡眠などの特定の行動を指示するコマンドを与えるのが一般的です。コンテナオーケストレーションシステムでは、特定の操作をシステムに送ることで命令型APIを実行します。
一般的な宣言型インタラクションモードは、上司が従業員とコミュニケーションをとる方法です。一般的に、上司は社員に具体的な命令や決定を下しません。むしろ、上司の方が社員よりも実行すべき業務について明確でない場合もあります。そこで、上司は、社員が主観的な主体性を発揮できるように、定量的な業務目標を設定します。例えば、ある製品の市場シェアを80%にすることを要求しますが、そのための具体的な操作手順は上司が指示します。
同様に、コンテナオーケストレーションシステムでは、アプリケーションインスタンスのレプリカ数を3に維持するために、Podをスケールアップするか、既存のPodを削除するかを指定するのではなく、レプリカ数を3に維持することがあります。

ii) 命令型APIの問題点
両者の対話型APIの違いを理解した上で、今度は命令型APIの問題点を見ていきましょう。
命令型APIの最大の問題点は、エラー処理にある。
大規模な分散システムでは、エラーはつきものです。コマンドを実行しても応答がない場合、呼び出し側はリトライを繰り返してエラーから回復しようとするしかありません。しかし、やみくもなリトライは、さらに大きな問題を引き起こす可能性があります。例えば、元のコマンドがバックエンドで実行されたにもかかわらず、1回リトライした後に、リトライのためのコマンド操作が追加で実行された場合などです。リトライを避けるためには、通常、システムは実行前に実行すべきコマンドを記録し、再起動などの場面では実行すべきコマンドをやり直す必要があります。また、実行時には、複数のコマンドの順番や上書きの関係など、複雑な論理条件を考慮する必要があります。多くの命令型対話システムでは、コマンド処理のタイムアウトやリトライなどのシナリオでデータの不整合を修正するために、バックエンドに検査システムが用意されていることが多い。
しかし、検査ロジックは定型的な操作ロジックとは異なるため、通常はテストで十分にカバーできません。その結果、エラー処理のメカニズムが十分に厳密ではなく、大きな運用リスクにつながります。そのため、多くの検査システムでは検査のトリガーは手動で行われています。命令型APIでは、複数の同時アクセス要求を処理する際にエラーが発生しやすい。
複数のユーザーが同じリソースに対して同時に操作を要求し、そのうちの1つの操作中にエラーが発生した場合、再試行が必要となります。その結果、効果のある操作を正確に判断することが困難になります。そのため、多くの命令型システムでは、操作が実行される前にシステムをロックし、システム全体における最終的な有効動作が予測できるようにしています。しかし、ロックをかけると、システム全体の運用効率が低下します。これに対して、宣言型APIでは、システムの現在の状態と最終的な状態を自然に記録することができる。
追加の操作データは必要ありません。また、状態には冪等性があるため、いつでも操作を繰り返すことができます。宣言型システムの実行中、通常の操作は実際にはリソースの状態を検査することであり、したがって追加の検査システムは必要ありません。このようにして、日々の運用の中で、システムの操作ロジックもテストされ、改善され、運用全体の安定性が確保されます。
最後に、リソースの最終的な状態が確定しているため、複数の変更をマージすることができます。このようにして、システムをロックすることなく、複数のユーザーからの同時アクセスをサポートしています。

iii) コントローラーモード - まとめ
最後に、コントローラモードに関する情報をまとめておきます。
1) Kubernetesが採用しているコントローラモードは、宣言型APIによって駆動されます。具体的には、Kubernetes内のリソースオブジェクトに加えられる変更によって駆動されます。
2)Kubernetesのリソースについて説明した後、リソースのコントローラに注目してみましょう。これらのコントローラは、指定された最終状態に近づくようにシステムを非同期的に制御します。
3) これらのコントローラは独立して動作するため、システムの自動化や無人化が可能となります。
4) Kubernetesでは、コントローラとリソースはカスタマイズ可能であるため、コントローラモードを柔軟に拡張することができる。リソースやコントローラをカスタマイズすることで、ステートフルなアプリケーションのメンテナンスを自動化することができます。これは後に紹介するオペレーターのシナリオでもあります。

結論
本稿では、Kubernetesによるアプリケーションのオーケストレーションと管理に関連する以下の点について包括的に説明しました。
- Kubernetesのリソースオブジェクトのメタデータには、リソースを識別するためのラベル、リソースを記述するためのアノテーション、リソース間の関係を記述するためのOwnerReferencesなど、さまざまな要素が含まれています。メタデータはKubernetesを動かす上で非常に重要です。
- コントローラモードの核となるのは、制御ループです。
- APIの設計方法としては、宣言型APIとコマンド型APIの2種類があります。Kubernetesが採用しているコントローラモードは、宣言型APIによって駆動されています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ