この記事では、Apache Flink Python APIの歴史を紹介し、そのアーキテクチャや開発環境、主要な演算子について解説しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Apache Flink Python APIの歴史、現状と今後の展開
Apache Flink が Python をサポートする理由
Apache Flinkは、統一されたストリームとバッチデータ処理機能を持つオープンソースのビッグデータコンピューティングエンジンです。Apache Flink 1.9.0では、機械学習(ML)APIと新しいPython APIが提供されています。次に、なぜApache FlinkがPythonをサポートしているのかについて詳しく説明します。
- Pythonは最もポピュラーな開発言語の一つ
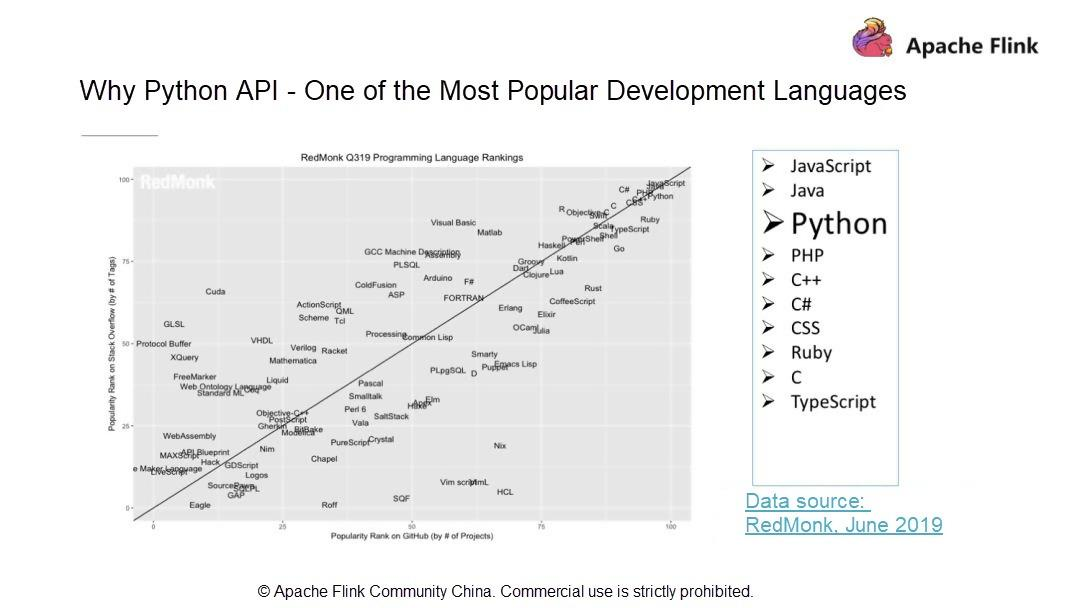
RedMonkの統計によると、PythonはJava、JavaScriptに次いで3番目に人気のある開発言語です。RedMonkは、ソフトウェア開発者に焦点を当てた業界アナリスト会社です。Apache Flinkは、ストリームおよびバッチデータ処理機能を持つビッグデータコンピューティングエンジンです。話題のPythonとApache Flinkの関係は?この疑問を踏まえて、現在有名なビッグデータ関連のオープンソースコンポーネントを見てみましょう。例えば、初期のバッチ処理フレームワークであるHadoop、ストリームコンピューティングプラットフォームであるSTORM、最近人気のSpark、データウェアハウスであるHive、KVストレージベースであるHBaseなどは、Python APIをサポートしている有名なオープンソースプロジェクトです。
- Pythonは多くのオープンソースプロジェクトでサポートされています。
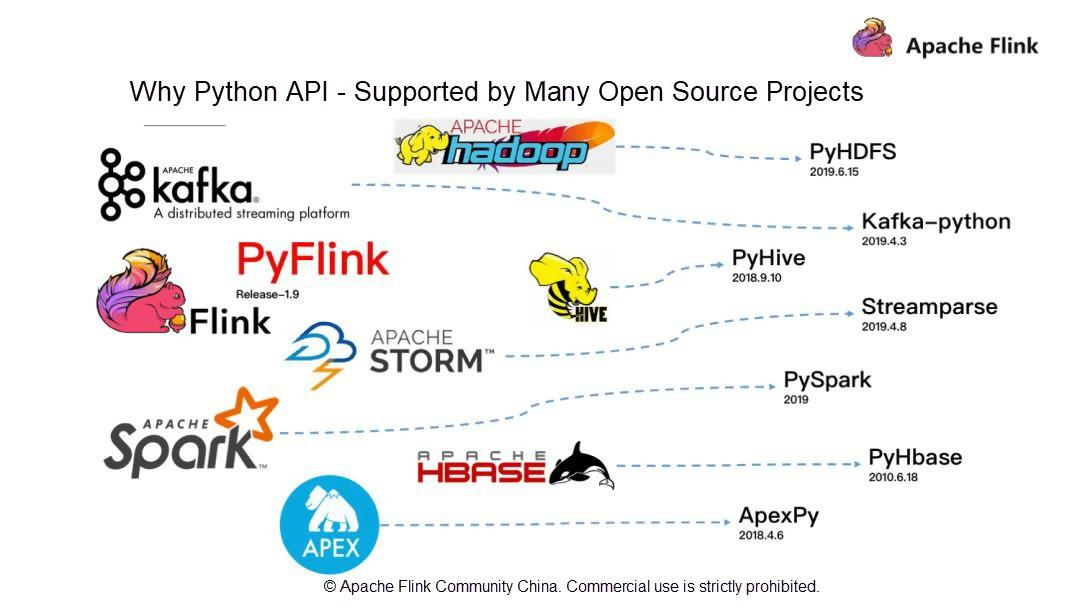
Pythonの完全なエコシステムを考えると、Apache Flinkはバージョン1.9に多額の投資をして、全く新しいPyFlinkを立ち上げました。ビッグデータとして、人工知能(AI)はPythonと密接な関係があります。
- Pythonは機械学習(ML)に支持されています。
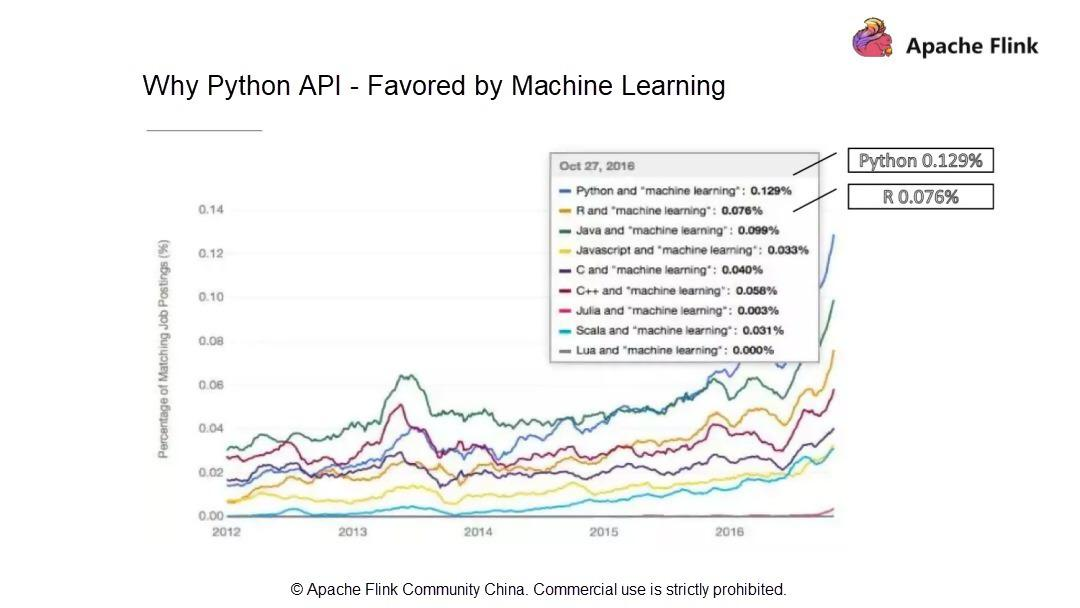
統計によると、ML業界の求人情報の0.129%とマッチングしており、Pythonが最も多く求められる言語となっています。R言語の0.076%と比較すると、ML業界ではPythonの方が好まれていることがわかります。解釈型言語であるPythonは、"物事を行うための方法は一つしかない "という設計理念を持っています。そのシンプルさと使いやすさから、世界で最も人気のある言語の1つであるPythonは、ビッグデータコンピューティングの分野では良いエコシステムとなっています。また、MLの分野でも有望な将来性を持っています。そこで、先日、Apache Flink 1.9で全く新しいアーキテクチャを採用したPython APIを発表しました。
Apache Flinkは、統一されたストリームとバッチデータ処理機能を持つコンピューティングエンジンです。コミュニティはFlinkユーザーを非常に重要視しており、JavaやScalaのようにFlinkへのアクセスやチャンネルをより多く提供したいと考えています。これにより、より多くのユーザーがFlinkをより便利に利用できるようになり、Flinkのビッグデータコンピューティング能力によってもたらされる価値から恩恵を受けることができるようになります。Apache Flink 1.9から、Apache Flinkコミュニティは、JOIN、AGG、WINDOWなどの最も一般的に使用されている演算子をサポートする全く新しい技術的なアーキテクチャを持つPython APIを開始します。
Python API - RoadMap
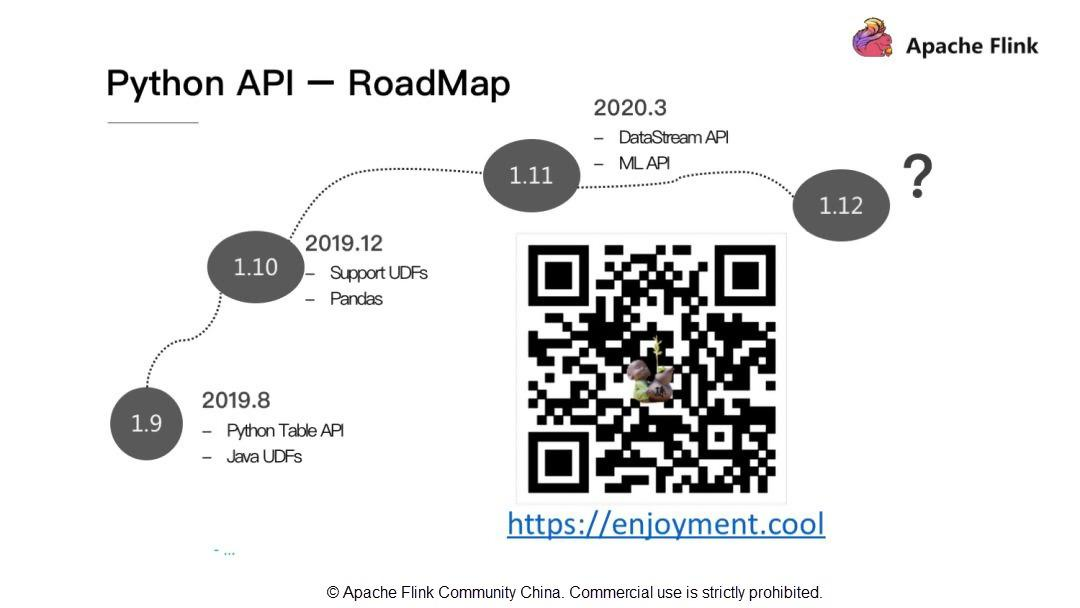
Apache Flink 1.9では、Pythonはユーザー定義のJava関数を利用することができますが、Pythonネイティブのユーザー定義関数の定義には対応していません。そのため、Apache Flink 1.10ではPythonのユーザー定義関数とPythonのデータ解析ライブラリPandasのサポートを行います。また、Apache Flink 1.11ではDataStream APIとML APIのサポートを追加します。
Apache Flink Python APIのアーキテクチャと開発環境
PythonのテーブルAPIアーキテクチャ
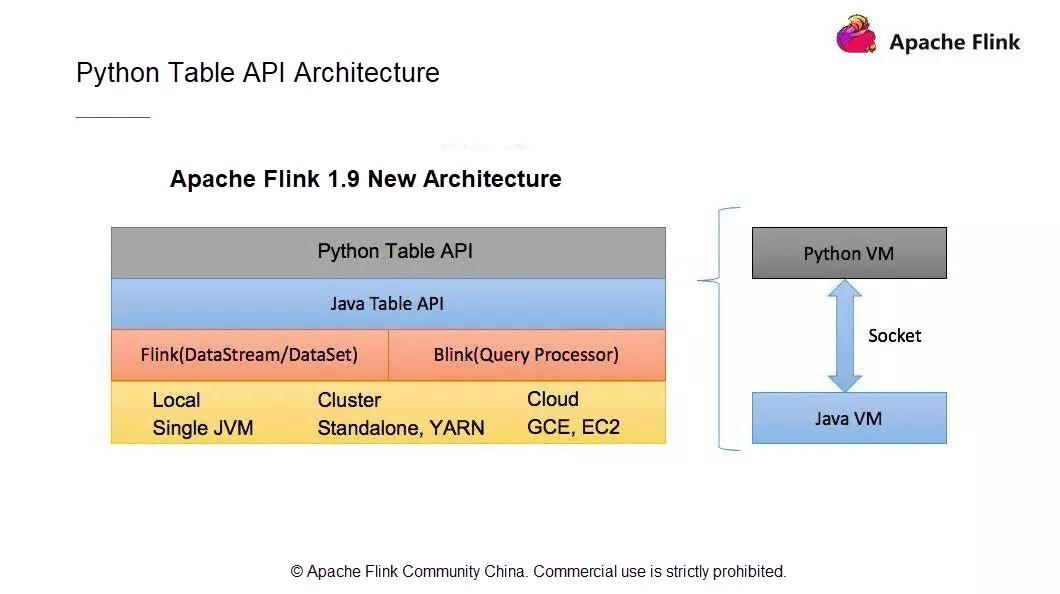
新しいPython APIアーキテクチャは、ユーザーAPIモジュール、Python仮想マシン(VM)とJava VM間の通信モジュール、Flinkクラスタにタスクを投入して運用するモジュールで構成されています。
Python VMとJava VMはどのように通信するのでしょうか?Python VM には、Python VM からの呼び出しを受け取る GateWayServer を持つ Java VM との接続を維持する Python ゲートウェイがあります。
1.9以前のApache Flinkのバージョンでは、すでにDataSetとDataStreamモジュールでPython APIをサポートしています。しかし、それぞれ2つの異なるAPIを使用しています。DataSet API と DataStream API です。Flinkのようにストリームとバッチデータ処理機能を統一したストリームコンピューティングエンジンにとって、統一されたアーキテクチャは極めて重要です。既存のPythonのDataSet APIとDataStream APIはJPythonの技術アーキテクチャを使用しています。しかし、JPythonはPython 3.Xシリーズを適切にサポートすることができません。そのため、既存のPython APIアーキテクチャは放棄し、Flink 1.9からは全く新しい技術アーキテクチャが採用されています。この新しいPython APIはTable APIをベースに実装されています。
Table APIとPython APIの通信は、Python VMとJava VM間の通信で実装されています。Python APIはJava APIと通信し、Python APIは書き込みや呼び出しを行います。Python APIの操作は、JavaのTable APIの操作と似ています。新しいアーキテクチャには次のような利点があります。
- 演算子を新たに作成する必要がなく、代わりにJava Table APIの機能との整合性を簡単に維持することができます。
- Java Table APIの最適化モデルを使用してPython APIを最適化します。これにより、Python APIを使用して書かれたジョブが最適なパフォーマンスを提供することが保証されます。
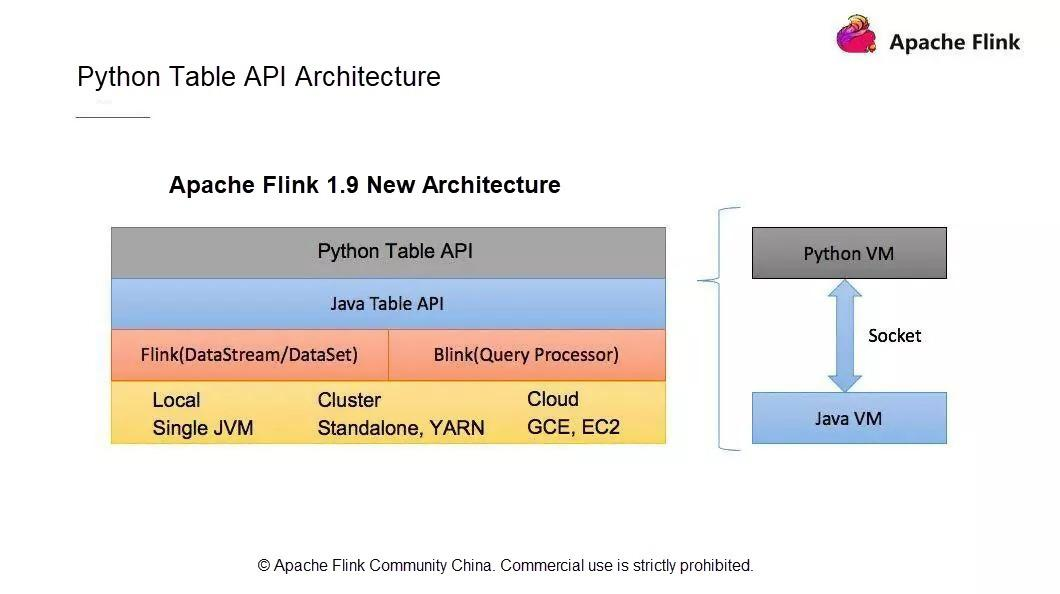
Python VMがJavaオブジェクトに対してリクエストを開始すると、Java VMはオブジェクトを作成し、ストレージ構造体に保存し、オブジェクトにIDを割り当てます。そして、そのIDをPython VMに送信し、Python VMは対応するオブジェクトIDを持つオブジェクトを操作します。Python VMはJava VMのすべてのオブジェクトを操作できるため、Python Table APIがJava Table APIと同一の機能を持ち、既存のパフォーマンス最適化モデルを利用できることが保証されます。
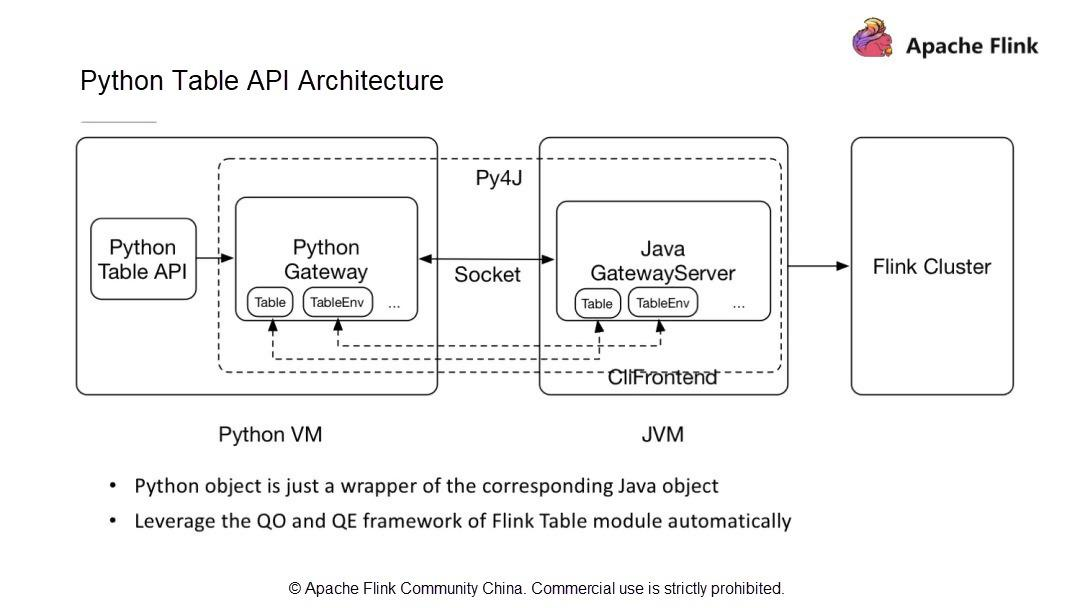
新しいアーキテクチャと通信モデルでは、Python VMは対応するJavaオブジェクトIDを取得し、呼び出しメソッドの名前とパラメータをJava VMに渡すだけでJava Table APIを呼び出します。したがって、Python Table APIの開発は、Java Table APIの開発と同じ手順に従います。次に、簡単なPython APIのジョブを開発する方法を探ってみましょう。
Python Table API - ジョブ開発
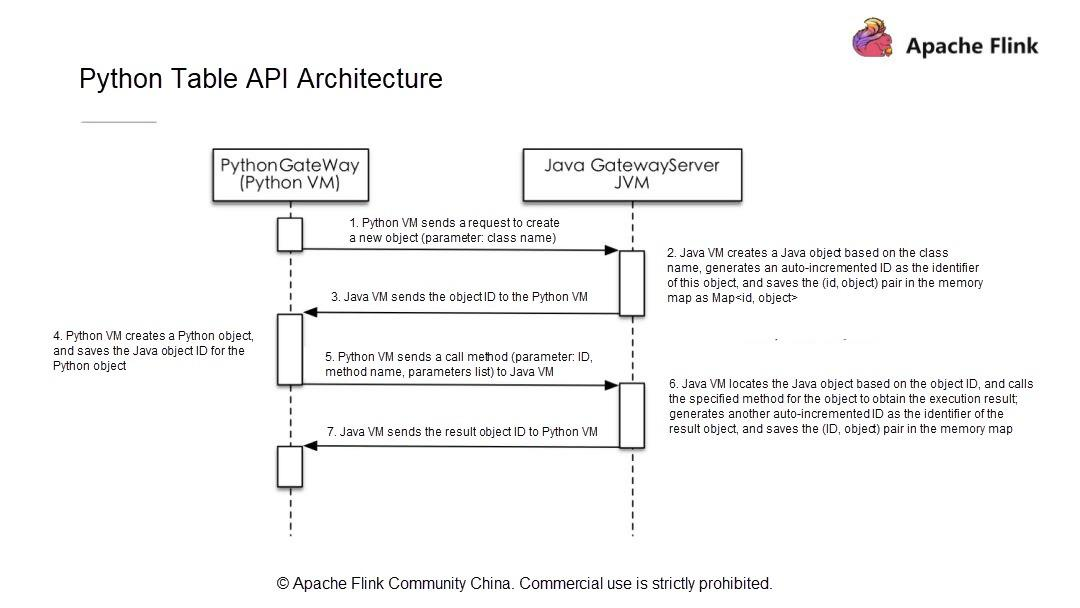
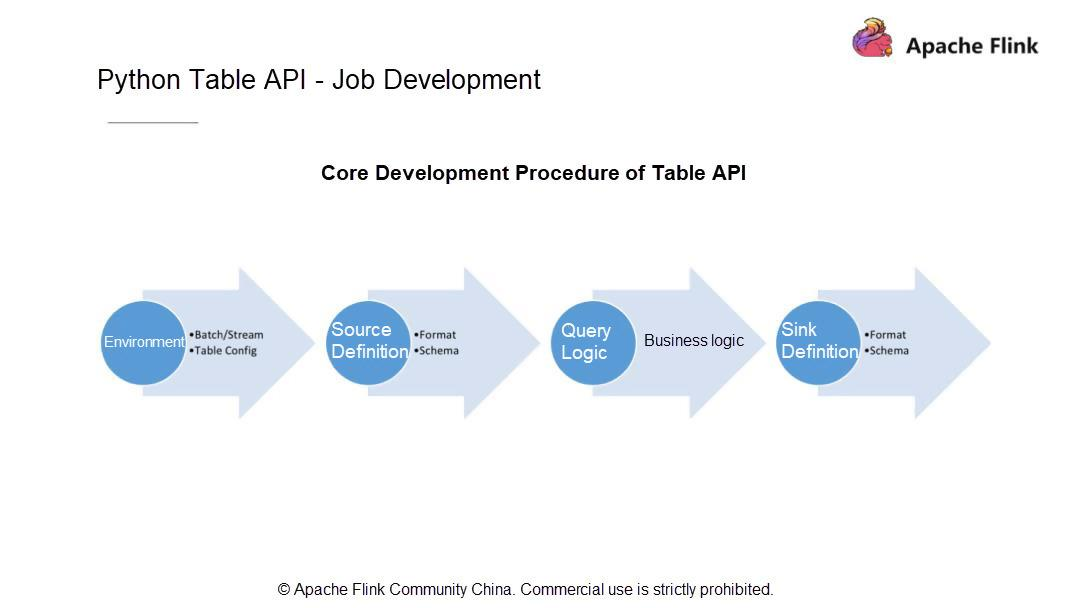
一般的にPythonのテーブルジョブは4つのステップに分かれています。現在の状況を考慮して、まず、ジョブをバッチモードで実行するかストリーミングモードで実行するかを決めます。それ以降のバージョンのユーザはこのステップをスキップすることができますが、Apache Flink 1.9のユーザはこの決定をしなければなりません。
ジョブの実行モードを決めたら、データがどこから来ているのか、データソース、スキーマ、データタイプをどのように定義するかを知っておきます。次に、計算ロジック (データに対して実行される計算操作) を書き、最終的な計算結果を指定したシステムに永続化します。次に、シンクを定義します。データソースを定義するのと同じように、シンクのスキーマとその中のすべてのフィールド型を定義します。
次に、上記の各ステップをPython APIを使ってコーディングする方法を理解しましょう。まず、実行環境を作成しますが、これは最終的にはテーブル環境でなければなりません。このテーブル環境には、実行プロセス中にRunTimeレイヤーに渡されるいくつかの設定パラメータを持つTable Configモジュールが存在しなければなりません。また、このモジュールは、実際のサービス開発段階で使用できるいくつかのカスタム設定項目を提供しなければなりません。
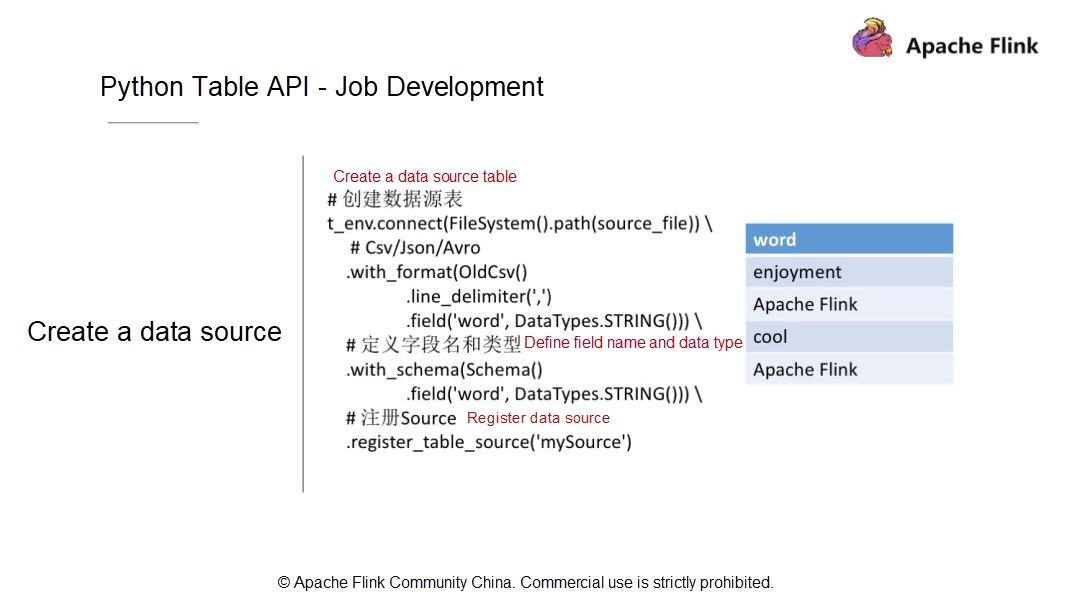
実行環境を作成したら、データソースのテーブルを定義する必要があります。例として、CSVファイル内のデータレコードはカンマ(,)で区切られ、フィールドはフィールド列にリストされています。このテーブルにはワードという1つのフィールドのみが含まれており、このフィールドの型はStringとなっています。

データソースを定義して記述し、データソースの構造をテーブルに変換した後、Table API層ではどのようなデータ構造とデータ型になるのでしょうか。次に、with_SCHEMAを使ってフィールドとフィールド型を追加する方法を見てみましょう。ここでは、フィールドは1つだけで、データ型はStringです。データソースは、その後のクエリや計算のためにカタログにテーブルとして登録されています。
そして、結果テーブルを作成します。計算が終わったら、計算結果を永続的なシステムに保存します。例えば、WordCountジョブを書くには、まず、ワードとカウントの2つのフィールドを持つストレージテーブルがあります。そして、このテーブルをシンクとして登録します。

テーブルシンクを登録したら、計算ロジックの書き方を見てみましょう。実はPython APIでWordCountを書くのは、Table APIで書くのと同じくらい簡単です。DataStreamとは異なり、Python APIではWordCountのジョブを書くのに必要なのは1行のステートメントだけです。例えば、まずソーステーブルをスキャンし、GROUP BY文を使用してワードごとに行をグループ化します。次にSELECT文を使って単語を選択し、集約関数を使って各単語のカウントを計算します。最後に計算結果を結果テーブルに挿入します。
Python Table API - 開発環境

致命的な問題は、具体的にどのようにWordCountジョブを実行するのかということです。まず、開発環境を設定します。異なるバージョンのソフトウェアが異なるマシンにインストールされている場合があります。ここでは、ソフトウェアのバージョンに必要な要件をいくつか紹介します。

第二に、ソースコードを元にバイナリJavaリリースパッケージを構築します。そのため、マスターブランチのコードをクローンして、1.9ブランチを取得します。もちろん、マスターコードを使っても構いません。しかし、マスターコードは安定性に欠けるので、1.9ブランチコードを使うことをお勧めします。では、手順を進めていきましょう。まず、コードをコンパイルします。例えば、以下のようにします。
//下载源代码
git clone https://github.com/apache/flink.git
// 拉取1.9分支
cd flink; git fetch origin release-1.9
git checkout -b release-1.9 origin/release-1.9
//构建二进制发布包
mvn clean install -DskipTests -Dfast
コンパイル後、対応するディレクトリにリリースパッケージを配置してください。
cd flink-dist/target/flink-1.9.0-bin/flink-1.9.0
tar -zcvf flink-1.9.0.tar.gz flink-1.9.0
Java APIをビルドしたら、APIを検証してPythonのリリースパッケージをビルドします。

すべてのPythonユーザーは、pip installを通じてパッケージをインストールするためには、依存ライブラリをローカルのPython環境と統合するか、これらの依存ライブラリをローカル環境にインストールしなければならないことを知っています。
これはFlinkにも当てはまります。PyFlinkをPypipによって認識されたリソースパッケージにパッケージ化してインストールします。以下のコマンドを使って、パッケージをコピーして自分の環境にインストールします。
cd flink-Python;Python setup.py sdist
この処理は、Java リリースパッケージを、いくつかの Java パッケージといくつかの PyFlink モジュールの Python パッケージと一緒に単純にラップします。新しい apache-link-1.9.dev0.tar.gz パッケージを dist ディレクトリから探してください。
cd dist/
distディレクトリにあるapache-flink-1.9.dev0.tar.gzファイルは、pip installでインストールに使えるPyFlinkパッケージです。Apache Flink 1.9 のインストールパッケージには、Flink Table と Flink Table Blink の両方が含まれています。Flinkは同時に2つのプランナーをサポートしています。デフォルトのFlinkプランナーとBlinkプランナーを自由に切り替えることができます。それぞれを自分で試してみることをお勧めします。パッケージ化後、私たちの環境にインストールしてみます。

非常に簡単なコマンドを使って、まず、コマンドが正しいかどうかを確認します。コマンドを実行する前に、pipを使ってリストを確認し、パッケージが既にインストールされているかどうかを確認します。そして、前のステップで用意したパッケージをインストールしてみてください。実際のシナリオでは、アップグレードをインストールするために、新しいパッケージをインストールします。
pip install dist/*.tar.gz
pip list|grep flink

パッケージをインストールしたら、先に書いたWordCountジョブを使って環境が正しいかどうかを確認します。環境が正しいかどうかを確認するには、以下のコマンドを実行して、環境コードリポジトリを直接クローンします。
git clone https://github.com/sunjincheng121/enjoyment.code.git
cd enjoyment.code; Python word_count.py
次に、試してみましょう。このディレクトリに以前作成したwordCountのジョブファイルを探します。直接python word_count.pyを使って環境に問題がないか確認してみましょう。Apache Flink Python APIを使うと、WordCountジョブを実行するためのミニクラスタが起動するはずです。さて、すでにミニクラスタ上ではジョブが実行されています。
この処理では、コードはまずソースファイルを読み込み、その結果をCSVファイルに書き出します。このディレクトリの中に、sink.csvファイルを見つけます。操作手順の詳細については、Apache Flink Community Chinaに投稿された「The Status Quo and Planning of Apache Flink Python API」というタイトルの動画を参照してください。

では、統合開発環境(IDE)の設定について説明します。Python関連のロジックやジョブの開発にはPyCharmを使うことをお勧めします。
IDEのセットアップの詳細については、QRコードをスキャンするか、ブログ(https://enjoyment.cool)に直接アクセスしてください。 Python環境はたくさんあると思いますが、pipインストールで使用したものを選択する必要があります。これは非常に重要です。操作手順の詳細については、「Apache Flink Python APIの現状と計画」というタイトルの動画を参照してください。
Python Table API - ジョブの投入

ジョブの投入にはどのような方法があるのでしょうか?まず、既存のクラスタにジョブを投入するCLIメソッドを使用します。この方法を使用するには、クラスタを起動する必要があります。ビルドのディレクトリは通常 build-target の下にあります。このコマンドを直接実行してクラスタを起動します。このプロセスでは、外部の Web ポートを使用することに注意してください。flink-conf.yamlファイルでポート番号を設定します。次に、PPT内のコマンドを使用してクラスタを起動します。クラスタが正常に起動したことを確認するには、ログを確認するか、ブラウザでサイトにアクセスします。クラスタが正常に起動した場合は、ジョブの投入方法を見てみましょう。

Flink runを使用して、以下のコードを実行してジョブを投入します。
./bin/flink run -py ~/training/0806/enjoyment.code/myPyFlink/enjoyment/word_count_cli.py
Pythonファイルを指定するにはpyを、Pythonモジュールを指定するにはpymを、Pythonリソースファイルを指定するにはpyfsを、JARパッケージを指定するにはjを使用します。

Apache Flink 1.9では、もっと便利な方法があります。Python Shellを使うと、Python APIで得られた結果を対話的に書き込むことができます。Python Shellはローカルとリモートの2つのモードで実行されますが、大きな違いはありません。まずは、以下のコマンドを実行してローカルモードを試してみましょう。
bin/pyflink-shell.sh local
このコマンドはミニクラスタを起動します。コードを実行すると、FLINK - PYTHON - SHELLというテキスト付きのFlinkロゴと、この機能を示すいくつかのサンプルスクリプトが返されます。これらのスクリプトを入力すると、正しい出力と結果が返されます。ここでは、ストリーミングまたはバッチのいずれかを記述することができます。操作手順の詳細については、ビデオを参照してください。
これで、Apache Flink 1.9のPython Table APIのアーキテクチャと、Python Table APIの環境設定方法についての基本的な理解ができました。IDEでジョブを実行する方法や、Flink runとPython Shellを使ってジョブを投入する方法を見るために、簡単なWordCountの例を考えてみました。また、FlinkのPython APIを利用するためのインタラクティブな方法をいくつか体験しました。Flinkの環境設定と簡単な例のデモを紹介した後、Apache Flink 1.9のキー演算子について説明します。
Flink Python APIのキー演算子の紹介と応用
Python のテーブル API 演算子
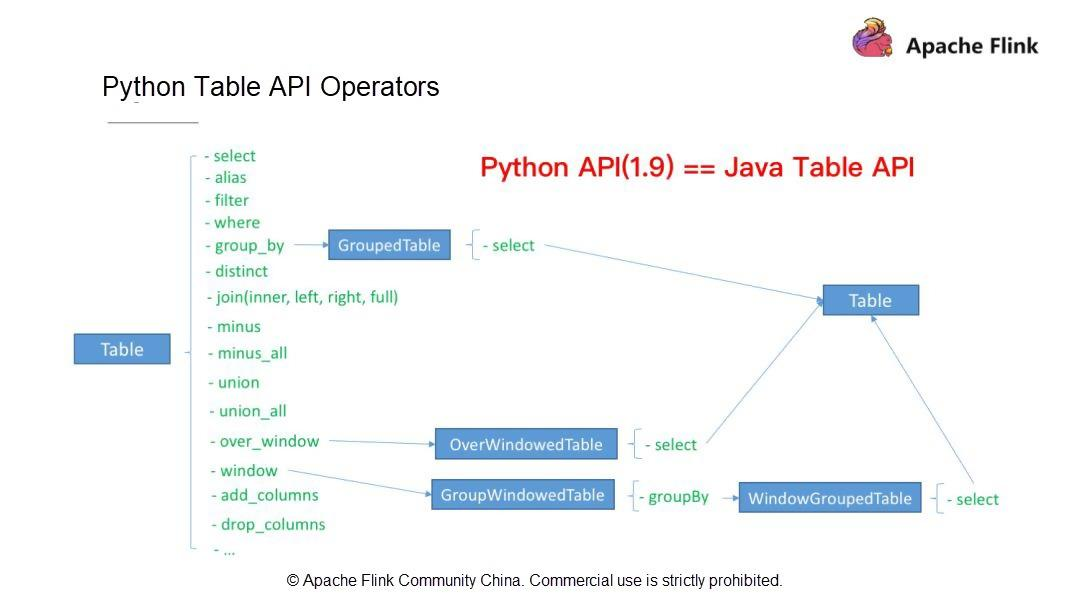
ジョブを作成する方法についてはすでに説明しました。まず、実行モードを選択します: ストリーミングかバッチかを選択します。次に、使用するテーブル(ソーステーブルと結果テーブル)、スキーマ、データ型を定義します。その後、計算ロジックを記述します。最後に、Python APIの組み込みの集計関数であるCount, Sum, Max, Minを利用します。例えば、WordCountジョブを書いたときは、Count関数を使いました。
Apache Flink 1.9は、ユーザの通常のニーズのほとんどを満たしています。では、これまでに見てきたものとは別に、Apache Flink 1.9でサポートされているFlink Table API演算子を見てみましょう。Flink Table API オペレータ(Python Table API オペレータと Java Table API オペレータ)は、以下のような操作をサポートしています。
第一に、SELECT、FILTER、集約演算、ウィンドウ演算、カラム演算(add_columns、drop_columns)などのシングルストリーム演算。
第二に、JOIN、MINUS、UNIONなどのデュアルストリーム演算。
これらの演算子はすべて Python Table API でサポートされています。Apache Flink 1.9では、Python Table APIは機能的にはJava Table APIとほぼ同じです。次に、上記の演算子の書き方とPython演算子の開発方法を理解していきましょう。
Python Table APIの演算子 - 透かしの定義

この記事を読んでお気づきの方もいるかもしれませんが、データストリームの属性である時系列については触れていません。データストリームの客観的な状態としては、データストリームがアウトオブオーダーになっている可能性があります。Apache Flinkでは、Watermarkの仕組みを利用して、アウトオブオーダーのデータストリームを処理しています。
Python APIでWatermarkを定義するには?
a と DateTime の 2 つのフィールドを含む JSON 形式のデータファイルがあるとします。透かしを定義するには、Schema作成時にrowtimeカラムを追加し、rowtimeデータ型はTimestampにする必要があります。
様々な方法で透かしを定義します。watermarks_periodic_boundedを使用して、定期的に透かしを送信します。60000という数字は60000msを指しており、これは60秒または1分に相当します。この定義により、プログラムは1分間の期間内に順番外のデータストリームを処理することができます。したがって、値が大きいほど、順序外データに対する耐性が高く、待ち時間が長いことを示します。透かしの仕組みの詳細については、こちらののブログ http://1t.click/7dM を参照してください。
PythonテーブルAPI - Java UDF

最後に、Apache Flink 1.9でのJavaユーザ定義関数(UDF)の応用について紹介します。Apache Flink 1.9はPythonのUDFをサポートしていませんが、PythonでJavaのUDFを利用することができます。Apache Flink 1.9では、Tableモジュールを最適化して再構築しています。Java UDFを開発するには、簡単な依存関係をインポートしてPython APIを開発します。Flink-table-commonをインポートします。

次に、JavaのUDFを使ってPythonのAPIを開発する方法に注目します。文字列の長さを計算するUDFを開発する必要があるとします。t_env.register_java_functionを使って、Java関数の名前とフルパスを渡して、Java関数をPythonに登録する必要があります。その後、登録された名前を使ってUDFを呼び出すことができます。詳しくは、私のブログ http://1t.click/HQF

Java UDFを実行するには?Flinkのrunコマンドを使って実行します。前述したように、UDFのJARパッケージをインクルードするために-jを使用しています。
Java UDFはスカラー関数だけをサポートしていますか?Java UDFはスカラー関数だけでなく,テーブル関数や集約関数もサポートしています.

Python Table APIのリファレンスリンク
よく使われる資料と私のブログのリンクを掲載しています。うまくいけば、それらがあなたの役に立つことを願っています。

概要
本記事では、Apache Flink Python APIの歴史と開発ロードマップを紹介しました。次に、Apache Flink Python APIのアーキテクチャを変更する理由と、利用可能な最新のアーキテクチャについて説明しました。また、Apache Flink Python APIの今後の計画や新機能についても記載されていました。あなたの提案や考えを共有することをお勧めします。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ