本記事では、Ant Financialが大規模なKubernetesクラスタを効率的かつ確実に管理する方法を紹介し、クラスタ管理システムの中核となるコンポーネントについて考察しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
序文
高度な設計コンセプトと優れた技術アーキテクチャを持つKubernetesは、コンテナオーケストレーションの分野で上位にランクされています。本番環境にKubernetesを導入し、実践している企業が増えています。特に、AlibabaやAnt Financialも本番環境にKubernetesを広く導入しています。Kubernetesはコンテナ化されたアプリケーションのデプロイを大幅に簡素化するため、開発者は複雑な分散システムを運用・保守することができます。しかし、本番環境のKubernetesクラスタを高可用性で維持管理することはまだ難しいです。本記事では、Ant Financialが大規模なKubernetesクラスタを効率的かつ確実に管理する方法を紹介し、クラスタ管理システムのコアコンポーネントを設計する方法を詳しく紹介します。
システム概要
Kubernetesクラスタ管理システムは、Kubernetesクラスタの作成とアップグレード、およびKubernetesクラスタ内の作業ノードの管理を簡単に行えるように、クラスタのライフサイクルを便利に管理するための機能を提供する必要があります。大規模なシナリオでは、クラスタの変更を制御できるかどうかがクラスタの安定性に直接影響します。そのため、管理システムの設計では、監視、カナリアリリース、ロールバックに対応しているかどうかを確認する必要があります。さらに、ノードのハードウェア障害やコンポーネントの例外などの問題は、数万ノードの超大規模クラスタではしばしば発生します。大規模クラスタ管理システムを設計する際には、これらの例外シナリオを考慮に入れて、システムが例外から自動的に回復できるようにしなければなりません。
設計パターン
このような背景から、最終状態を指向したクラスタ管理システムを設計しました。このシステムでは、クラスタの現在の状態が目標状態と一致しているかどうかを定期的にチェックします。状態が一致していない場合は、オペレータが一連の操作を開始し、クラスタを目標状態に到達させます。この設計では、制御理論における一般的な負帰還型閉ループ制御システムを参考にしています。このシステムは閉ループを実装しており、外乱に対して効果的に防御することができる。我々のシナリオでは、妨害とはノードのソフトウェアおよびハードウェアの障害を指します。
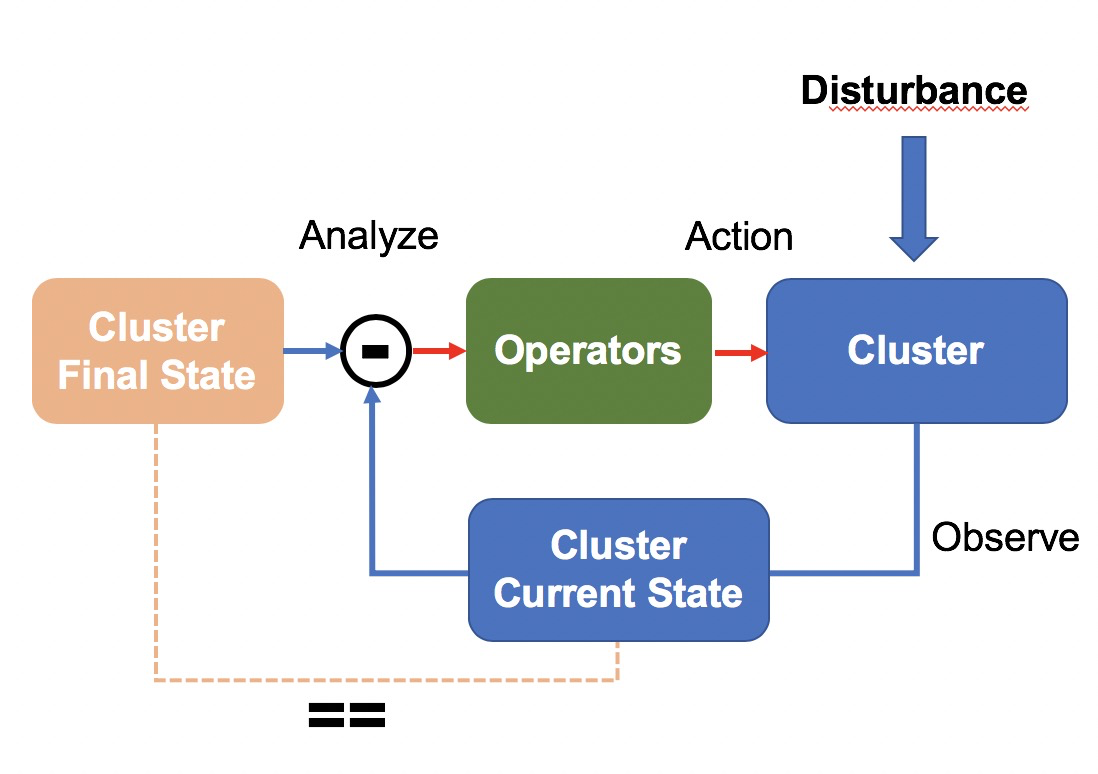
アーキテクチャ設計
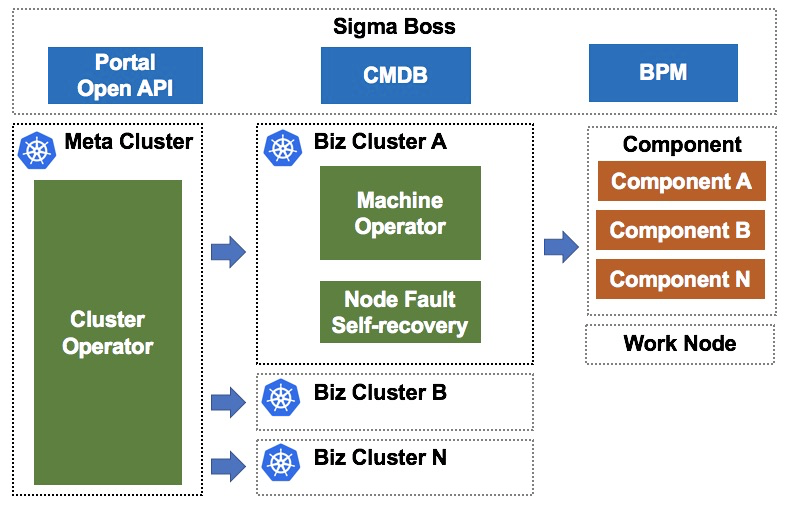
先ほどの図に示すように、メタクラスタとは、N個のビジネスクラスタでマスターノードを管理する高可用性のKubernetesクラスタのことです。ビジネスクラスタは、プロダクションにサービスを提供するKubernetesクラスタです。Sigma Bossはクラスタ管理のためのポータルであり、ユーザとの対話に便利なインターフェイスと制御可能な変更プロセスを提供します。
メタクラスタに配置されたクラスタオペレータは、ビジネスクラスタの作成、削除、アップグレードの機能を提供します。クラスタ演算子は最終状態を指向しています。ビジネスクラスタのマスターノードまたはコンポーネントに異常が発生した場合、クラスタオペレータは、ビジネスクラスタのマスターノードが安定した最終状態に到達するように、異常なマスターノードまたはコンポーネントを自動的に隔離して回復します。このソリューションでは、Kubernetesの管理にKubernetesを利用しており、Kube on Kube(KOK)と呼ばれています。
また、ビジネスクラスタ内の作業ノードを管理するために、マシンオペレータとノード障害自己回復コンポーネントをビジネスクラスタ内に配置します。これらのコンポーネントを使用して、作業ノードの追加、削除、アップグレード、ノード障害の処理を行うことができます。マシンオペレータが単一ノードの最終状態を保持する能力をベースに、Sigma Bossはクラスタのカナリアリリースとロールバックをサポートしています。
コアコンポーネント
クラスター最終状態保持
Kubernetesのカスタムリソース定義(CRD)に基づいて、ビジネスクラスタの最終的な状態を記述するために、メタクラスタにクラスタCRDを定義しました。各ビジネスクラスタは1つのクラスタリソースにマッピングされています。クラスタリソースを作成、削除、更新するということは、ビジネスクラスタを作成、削除、アップグレードしたことを意味します。クラスタオペレータは、クラスタリソースを監視し、ビジネスクラスタのマスターコンポーネントを駆動して、CRDで定義された最終状態に達するようにします。
ビジネス・クラスタ内のマスター・コンポーネントのバージョンは、ClusterPackageVersion CRDで一元的に管理されます。ClusterPackageVersionリソースは、APIサーバ、コントローラマネージャ、スケジューラ、オペレータなどのマスターコンポーネントのイメージやデフォルトの起動パラメータなどの情報を記録します。クラスタ リソースは、一意の ClusterPackageVersion に関連付けられます。クラスタ CRD に記録されている ClusterPackageVersion のバージョンを変更することで、ビジネス クラスタのマスター コンポーネントをリリースしたりロールバックしたりすることができます。
ノード最終状態保持
Kubernetes クラスタで作業ノードを管理するには、次のことを行う必要があります。
- ノードシステムを構成し、カーネルパッチを管理する。
- DockerやKubeletなどのコンポーネントのインストール、アップグレード、アンインストールを行う。
- ノードの最終状態とスケジューリングモードを管理する。例えば、主要なDaemonSetsがデプロイされた後にのみスケジューリングを有効にする。
- ノードが障害から自動的に回復するようにする。
前述の管理ジョブを完了するために、作業ノードの最終状態を記述するためのマシンCRDをビジネスクラスタで定義しました。各作業ノードは、1つのマシンリソースにマッピングされます。マシンリソースを変更することで、作業ノードを管理することができます。
次の図はマシンCRDを示しており、specにはノードにインストールするコンポーネントの名前とバージョンが記述され、statusには現在のワークノードにおける各コンポーネントのインストール状態と実行状態が記録されています。また、マシンCRDは、他のノードの管理オペレータと連携して動作するプラグイン型の最終状態管理にも対応している。この部分については後ほど詳しく説明します。
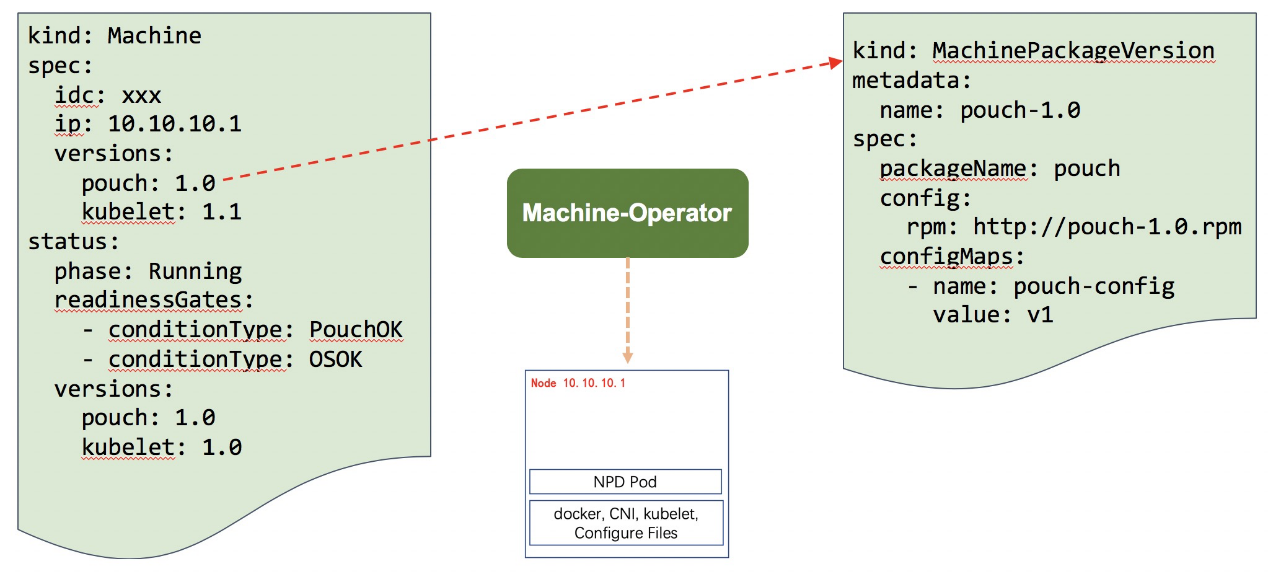
ワークノード内のコンポーネントのバージョンは、MachinePackageVersion CRD によって管理されます。MachinePackageVersion は、各コンポーネントの Redhat Package Manager (RPM) バージョン、構成、インストール方法などの情報を保持します。1 つのマシン・リソースは、複数のコンポーネントをインストールできるように、N 個の MachinePackageVersion に関連付けられています。
マシンリソースとMachinePackageVersion CRDを基に、ノードの最終状態コントローラであるマシンオペレータを設計し、実装しました。マシンオペレータは、マシンリソースの監視、MachinePackageVersionの解析、ノードのO&M操作を行い、ノードを最終状態に到達させ、最終状態を継続的に保持します。
ノード最終状態管理
ビジネス要件が変化し続ける中で、ノード管理はDockerやKubeletなどのコンポーネントのインストールに限定されなくなりました。ログ収集DaemonSetがデプロイされた後にスケジューリングを開始するなどの要件を満たす必要があります。さらに、同様の要件も増えてきています。すべての最終状態を機械オペレータが管理すると、機械オペレータと他のコンポーネントとの結合が増え、システムの拡張性が低下します。そこで、機械オペレータと他ノードのO&Mオペレータを連携させてノードの最終状態を管理する仕組みを設計しました。設計の様子を下図に示します。
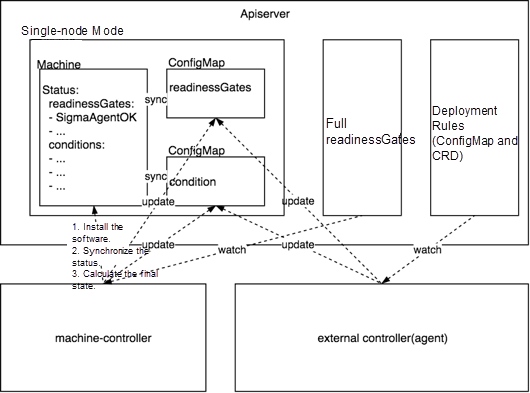
- Full ReadinessGatesは、ノードをスケジュールできるようにするためにチェックする必要がある条件のリストを記録する。
- Condition ConfigMapは、各ノードのO&Mオペレータの最終的な状態をConfigMapに報告する。
機械オペレータと他ノードのO&Mオペレータとの協調関係は次のようになります。
1、外部ノードのO&Mオペレータは、自身のサブ最終状態を検出し、対応するCondition ConfigMapに報告する。
2、機械オペレータは、ラベルを用いてCondition ConfigMapからそのノードの全てのサブファイナル状態を取得し、機械内のStatusの下の条件に同期させる。
3、マシンオペレータは、フルReadinessGatesに記録された条件リストに基づいて、ノードが最終状態に到達したかどうかを確認する。ノードが最終状態に達していない場合、マシンオペレータはスケジューリングを有効にしない。
ノード障害セルフリカバリー
ご存知のように、物理機械のハードウェアは、一定の確率で障害が発生することがあります。クラスタ内のノードが増加するにつれて、障害ノードがクラスタ内で一般的に見られるようになります。クラスタ内のノードが増えてくると、クラスタ内に故障したノードが存在することが多くなります。
この問題を解決するために、私たちは、障害の発見、隔離、修正のための閉ループ自己回復システムを設計しました。
下図に示すように、エージェントによる報告と故障検出器による自動検出によって故障を発見することで、故障発見の適時性と信頼性を確保しています。具体的には、エージェントによる報告はより高い適時性を確保し、故障検出器による自動検出は、エージェントによって報告されなかった例外的なケースをカバーすることができます。すべての障害情報はイベントセンターに保存されます。クラスタフォルトの影響を受ける可能性のあるコンポーネントやシステムは、イベントセンターのイベントをサブスクライブすることで、フォルト情報を取得できます。
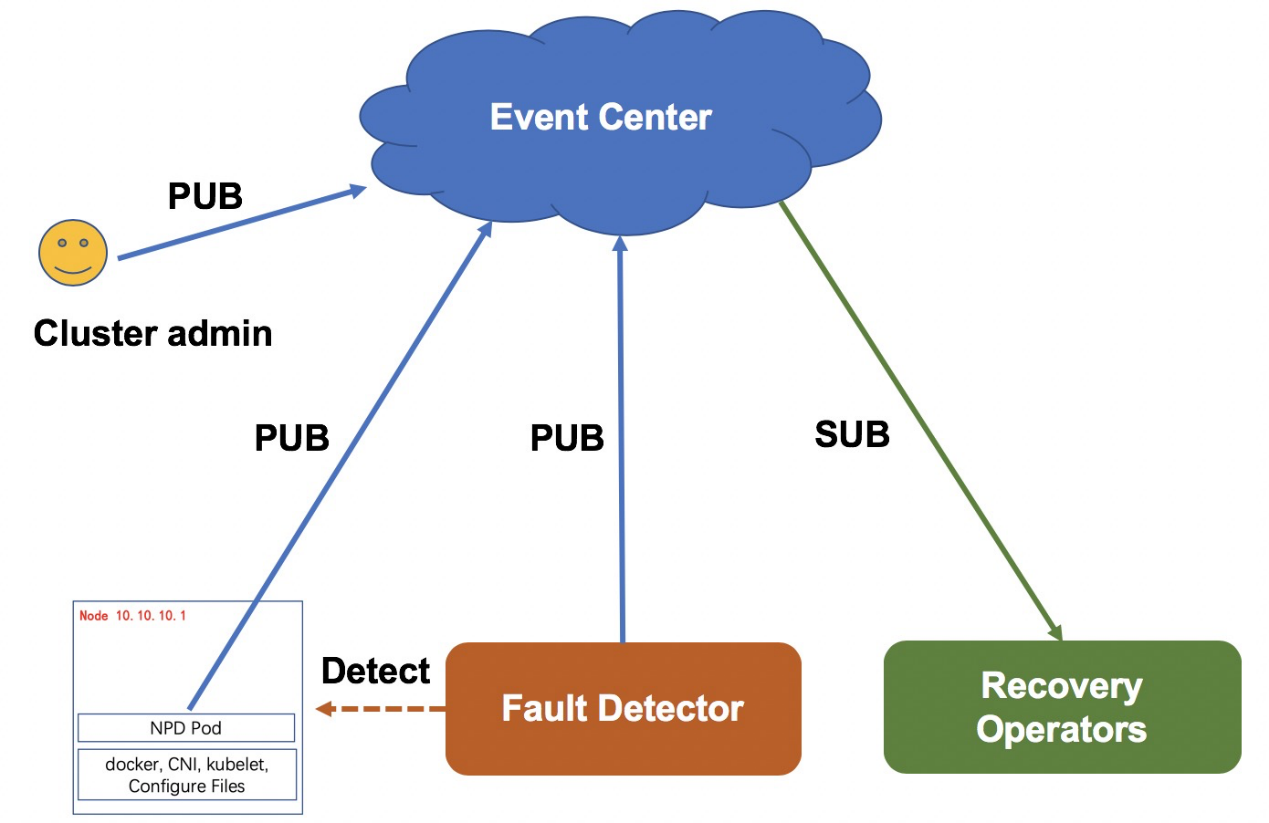
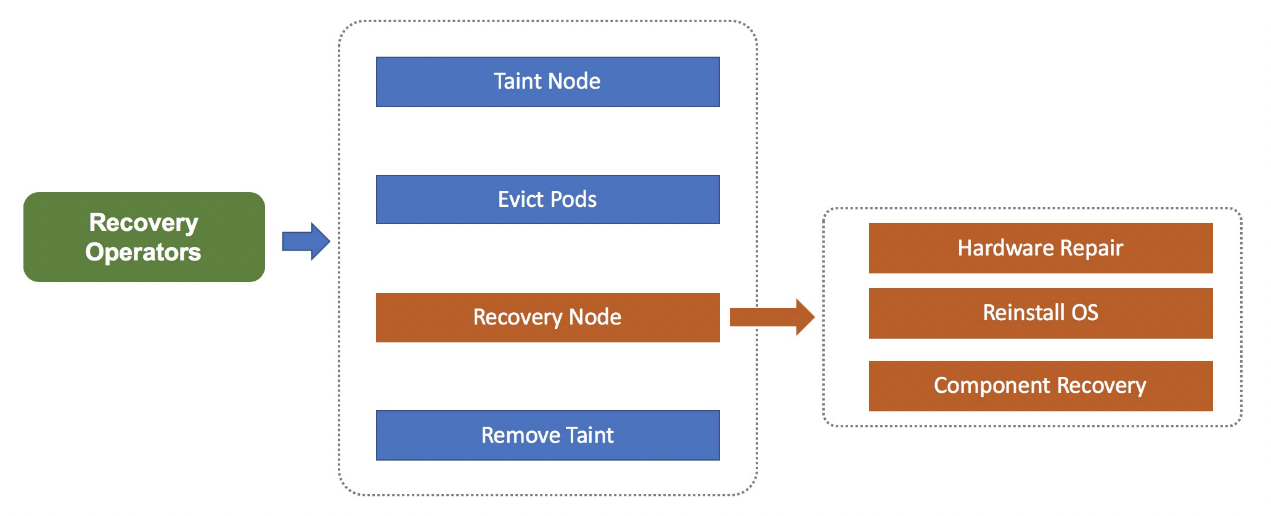
ノード障害自己回復システムは、障害の種類に応じて異なるメンテナンスプロセス、例えば、ハードウェアメンテナンスプロセスとシステム再インストールプロセスを作成します。メンテナンスプロセスでは、システムは、ノードのスケジューリングを停止することで障害のあるノードを隔離し、ノード上のポッドに "to be migrated "とラベルを付けて、プラットフォーム・アズ・ア・サービス(PAAS)またはMigrateControllerにポッドの移行を通知する。これらの準備が完了すると、システムはハードウェアの修復やオペレーティングシステムの再インストールなど、ノードの復旧を試みます。ノードが復旧すると、システムはノードのスケジューリングを再開します。システムが長時間にわたってノードの自動回復に失敗した場合は、手動でノードの回復を試みることができます。
リスク防止
マシンオペレータが提供するアトミックな能力をベースに、カナリアリリースやクラスタのロールバックをサポートするように設計されています。さらに、変更のリスクをさらに低減するために、オペレータは実際の変更を開始する前にリスクを評価します。次の図にアーキテクチャを示します。
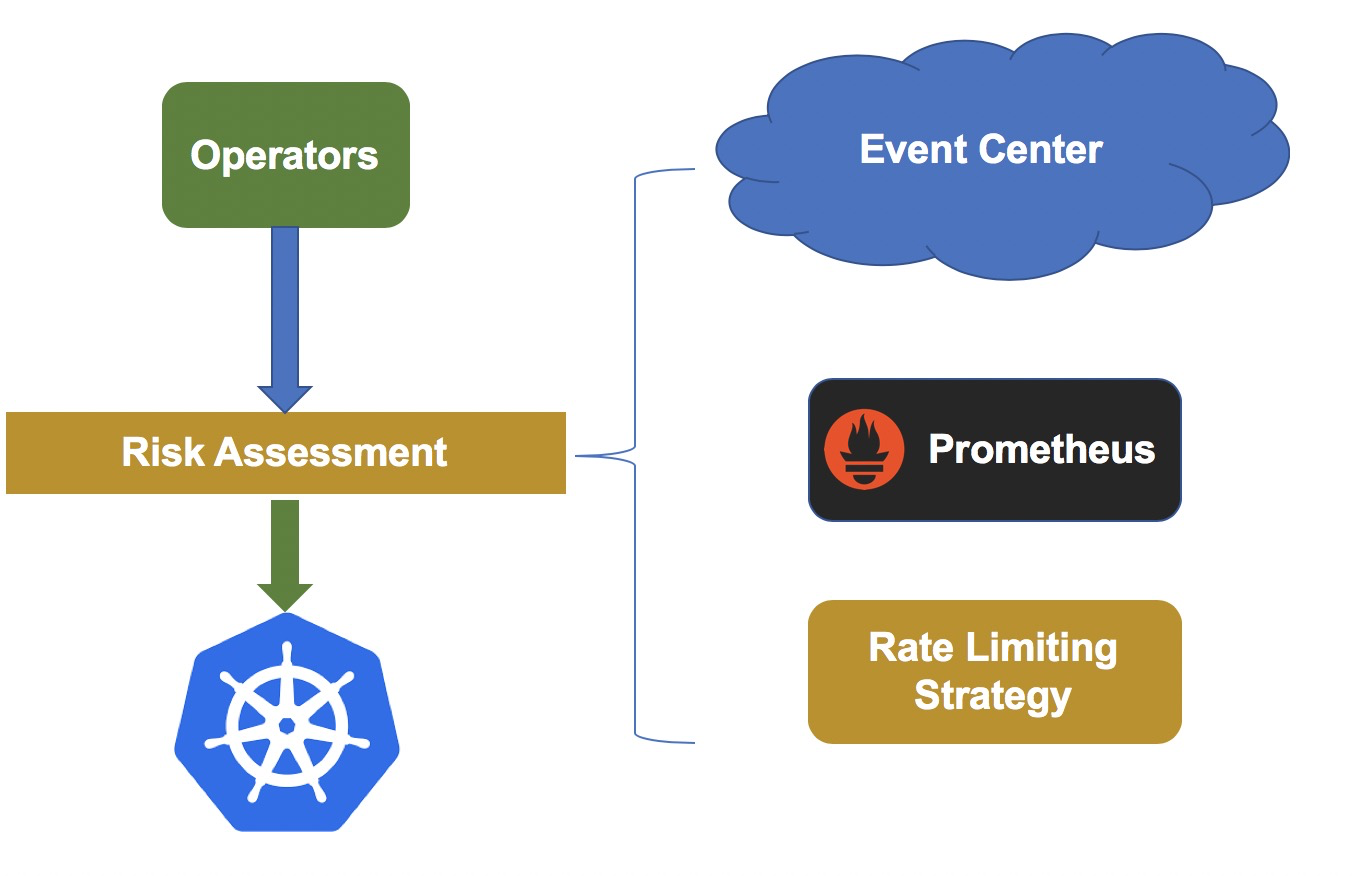
ノードの削除やシステムの再インストールなど、リスクの高い変更操作は、統一された料金制限センターに記録されます。レート制限センターでは、さまざまな種類の操作に対してレート制限ポリシーを管理しています。変更がレート制限のトリガーとなった場合、システムは変更を停止します。
変更プロセスが正常かどうかを評価するために、変更の前後に各コンポーネントのヘルスチェックを行います。コンポーネントのヘルスチェックでは、ほとんどの例外を発見することができますが、特定の例外シナリオがカバーされていない場合があります。この弱点を克服するために、システムはリスクアセスメント時にイベントセンターや障害検出器からポッド作成成功率などのクラスタビジネスメトリクスを取得しています。メトリクスが異常であれば、システムは自動的に変更を停止します。
概要
本記事では、Ant Financial社が現在使用しているKubernetesクラスタ管理システムのコア設計を共有しました。コアコンポーネントは、最終状態を管理するために多くの演算子を使用していました。このファイナルステート指向のクラスタ管理システムは、今年のダブルイレブンに向けた準備の中で、性能と安定性のテストに見事に合格しました。
完全なクラスタ管理システムは、クラスタの安定性とO&M効率を確保するだけでなく、クラスタの全体的なリソース利用率を高める必要があります。今後は、オンラインノードの割合を増やし、アイドルノードの割合を減らすことで、Ant Financialの生産グレードのクラスタのリソース利用率を向上させていきます。また、Ant Financialのシステム部リソーススケジューリンググループでは、優秀な人材を募集しています。私たちと一緒に世界に通用する課題を解決していきましょう
よくあるご質問
Q1: 現在、弊社のアプリケーションのほとんどがDockerでデプロイされています。Kubernetesに移行するにはどうしたらよいでしょうか?また、そこから学べる事例はありますか?
A1: 私はAnt Financialで5年近く働いています。Ant Financialのサービスは、最初はXen仮想マシンで動作していましたが、現在はDockerで動作し、Kubernetesでスケジューリングされています。ほぼ毎年インターベーションが行われていることがわかります。KubernetesはオープンなPlatform as a Service(PaaS)フレームワークです。DockerでKubernetesをデプロイしていれば、アプリケーションは「クラウドネイティブ」であり、理論上はKubernetesへの移行もスムーズに行えます。Ant Financialの過去の重いワークロードを考慮し、実際にはサービス要件に基づいてKubernetesを強化し、サービスがスムーズにKubernetesに移行できるようにしています。
Q2:アプリケーションをKubernetesとDockerでデプロイした場合、パフォーマンスは低下しますか?例えば、ビッグデータ処理に関連するジョブをKubernetesにデプロイすることは推奨されていますか?
A2: 私の知る限り、Dockerはコンテナであり、仮想マシンではありません。そのため、パフォーマンスへの影響は限定的です。Ant Financialのビッグデータや人工知能(AI)などのサービスは、Kubernetesに移行し、オンラインアプリケーションと一緒にハイブリッドでデプロイされています。ビッグデータサービスは時間的な制約があり、アイドル状態のクラスタリソースをフルに活用することができます。さらに、ハイブリッドなデプロイは、データセンターのコストを大幅に削減します。
Q3: Kubernetesクラスタは、従来のO&M環境でどのようにうまく機能するのでしょうか?現在のところ、Kubernetesクラスタだけをデプロイすることは間違いなくありません。
A3:異なるインフラを使用している場合、リソースを集中的にスケジューリングすることができません。また、比較的独立した2つのO&Mシステムを維持するのは非常にコストがかかります。Ant Financialでは移行時に、従来のコンテナ作成やリリースの指示をKubernetesのリソース変更指示に変換することで「ブリッジ」を形成する「アダプタ」を実装しました。
Q4:ノードはどのように監視されていますか?ノードに障害が発生した場合、ポッドは移行されますか?サービスの自動移行に対応していない場合はどうすればいいのでしょうか?
A4: ノードは、ハードウェアレベル、システムレベル、コンポーネントレベルでそれぞれ監視されます。ハードウェアレベルの監視データは、インターネットデータセンター(IDC)から取得します。システムレベルの監視は、Alibaba Cloudの内部監視プラットフォームによって行われます。KubeletやPouchなどのコンポーネントを監視するために、ノード問題検出器(NPD)を拡張して、監視システムがデータを収集するためのエクスポータインターフェースを提供します。ノードに障害が発生した場合、システムはノード内のポッドを自動的に移行します。ステートフルサービスの場合、サービスプロバイダは、ポッドを自動的に移行するオペレータをカスタマイズすることができます。自動移行できないポッドはシステムが破棄します。
Q5: 将来的には、コンテナに基づいてアプリケーションを開発してデプロイするのではなく、開発者がコードを使ってクラスタのデプロイファイルをプログラムしたりコンパイルしたりできるようにすることで、Kubernetesクラスタ全体を開発者にとって透過的なものにする計画はありますか?
A5: Kubernetesは、PaaSプラットフォームを構築するための多くの拡張機能を提供しています。しかし、現在、Kubernetesクラスタに直接アプリケーションをデプロイするのは本当に難しいです。今後は特定のドメイン固有言語(DSL)を使ってアプリケーションをデプロイすることがトレンドになり、Kubernetesがこれらのインフラストラクチャの中核になるのではないかと思います。
Q6: 現在、クラスターの管理はkube-to-kube方式で行っています。kube-to-kubeと比較して、kube-on-kubeのメリットは何ですか?また、Kubernetesクラスタを大規模に展開した場合、Kubernetesクラスタのノードをスケーリングしたときのパフォーマンスのボトルネックは何ですか?また、この問題を解決するにはどうすればよいでしょうか?
A6: 現在、多くの継続的インテグレーションや継続的デリバリー(CI/CD)プロセスがKubernetesクラスタで実行されています。kube-on-kubeを利用することで、業務クラスタを共通の業務アプリケーションとして管理することができます。KubeletやPouch以外にも、多くのDaemonSetsやpodもノード内で動作しています。ノードが大量に追加されると、ノード内のコンポーネントがAPIサーバに対して多くのリスト操作やウォッチ操作を開始します。弊社の最適化では、APIサーバーのパフォーマンスを向上させ、APIサーバーと連携してノードのリスト操作とウォッチ操作の合計数を減らすことに重点を置いています。
Q7:当社はKubernetesクラスタをデプロイしていません。いくつか質問したいことがあります。Kubernetesのメリットは何ですか?Kubernetesで解決できる既存の問題点は何ですか?Kubernetesを利用できるビジネスシナリオやプロセスはどのようなものが望ましいですか?既存のインフラストラクチャのデータをスムーズにKubernetesに移行できるでしょうか?
A7: 私の考えでは、KubernetesはO&Mアクションではなく、最終的な状態指向の設計コンセプトが異なります。これは複雑なO&Mシナリオでは有用です。Ant Financialのアップグレード実践によると、既存インフラのデータをKubernetesにスムーズに移行することができます。
Q8: クラスタ事業者はポッドで稼働していますか?業務クラスタのマスターノードはポッドで動作しますか?マシンオペレータは物理マシンで実行しますか?
A8: すべてのオペレータはポッドで実行します。クラスタオペレータは、ビジネスクラスタ内のマシンオペレータを引き上げます。
Q9: ハイ! Double Elevenのような高カレンシーシナリオに対応するために、メタクラスターの推奨サイズと、メタクラスターで管理する各ビジネスクラスターの推奨サイズを教えてください。私が知っている限りでは、クラスタ演算子はリソースのリスト化やウォッチに使用されます。大規模な高カレンシーシナリオでは、どのような改善がなされているのでしょうか?
A9: クラスタは数万のノードを管理することができます。したがって、メタクラスタは理論的には3,000以上の業務クラスタを管理することができます。
Q10: ノード内のシステムカーネル、Docker、Kubernetesに異常がある場合、ソフトウェアを利用してシステムの正常な性能を最大化するにはどうすればよいですか?
A10: システムがノードのヘルスチェックを行うことができます。障害のあるノードが自動的に終了した後、Kubernetesがそのノードを発見し、別のノードに引き上げます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ