この記事では、Dockerを例に、コンテナログ処理の一般的な方法やベストプラクティスをいくつか紹介しています。
背景
Docker, Inc. 旧社名:dotCloud, Inc)は、2013年にDockerをオープンソースプロジェクトとしてリリースしました。その後、Dockerに代表されるコンテナ製品は、分離性能の良さ、移植性の高さ、リソース消費の少なさ、起動の早さなど複数の特徴から、瞬く間に世界中で人気を博しました。下図は2013年からのDockerとOpenStackの検索傾向を示しています。
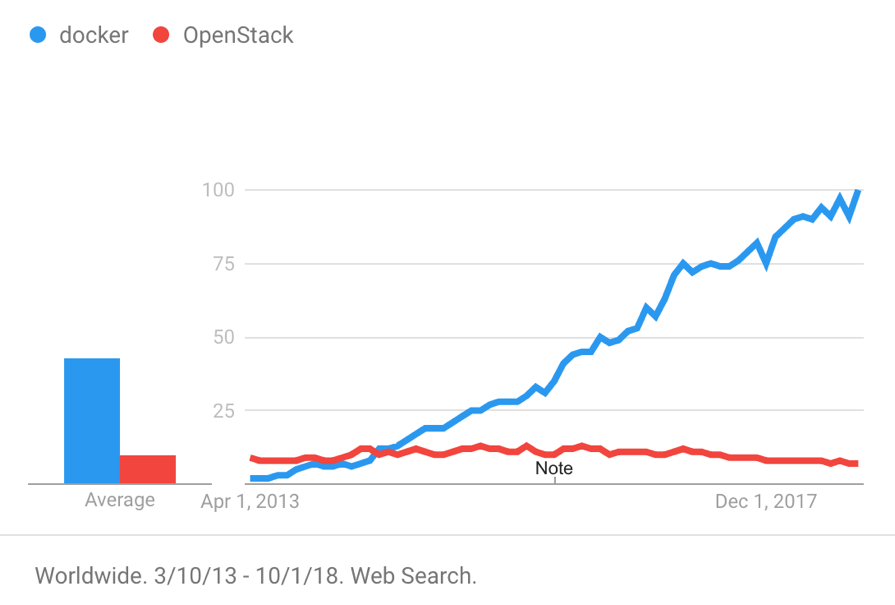
コンテナ技術は、アプリケーションの展開や配信など、多くの便利さをもたらします。また、以下のようなログ処理のための多くの課題ももたらします。
1、コンテナの中にログを保存した場合、コンテナが取り外されるとログは消えてしまいます。コンテナは頻繁に作成・削除されるため、コンテナのライフサイクルは仮想マシンよりもはるかに短いです。そのため、ログを永続的に保存する方法を見つける必要があります。
2、コンテナ時代に入ってからは、仮想マシンや物理マシンよりも管理すべきオブジェクトが増えます。対象となるコンテナにログオンして問題をトラブルシューティングすると、問題が複雑化し、コストが増大します。
3、コンテナ技術を使えば、マイクロサービスをより簡単に実装することができます。それはシステムをデカップリングすると、より多くのコンポーネントをもたらします。システムの稼働状況を総合的に把握し、問題を素早く見つけ、コンテキストを正確に復元するための技術が必要です。
ログ処理
この記事では、Dockerを例に、コンテナログ処理の一般的な方法とベストプラクティスをいくつか紹介します。Alibaba Cloud Log Serviceチームが長年のログ処理分野でのハードワークを経て結論付けたこれらの方法とベストプラクティスは以下の通りです。
1、コンテナログのリアルタイム収集
2、クエリ分析と可視化
3、ログのコンテキスト分析
4、LiveTail - LiveTail - クラウド上のtail-f
コンテナログのリアルタイム収集
コンテナのログタイプ
ログを収集するには、まずログがどこに保存されているかを把握する必要があります。この記事では、NGINXとTomcatコンテナのログを収集する方法を紹介します。
NGINXで生成されるログファイルはaccess.logとerror.logです。NGINXのDockerfileはaccess.logとerror.logをそれぞれSTDOUTとSTDERRにリダイレクトします。
Tomcat は catalina.log、access.log、manager.log、host-manager.log など複数のログファイルを生成しますが、tomcat Dockerfile はこれらのログを標準出力にリダイレクトしません。その代わりに、コンテナ内に保存されます。
ほとんどのコンテナログはNGINXやTomcatのコンテナログに似ています。コンテナログを2つのタイプに分類することができます。
| Container log types | Description |
|---|---|
| Standard output | Information output through STDOUT and STDERR, including text files redirected to the standard output. |
| Text log | Logs that are stored inside the containers and are not redirected to the standard output. |
標準出力
Logging Drivers
コンテナの標準出力は、Logging Driverの統一処理の対象となります。次の図に示すように、異なるロギングドライバは、異なる宛先に標準出力を書き込みます。
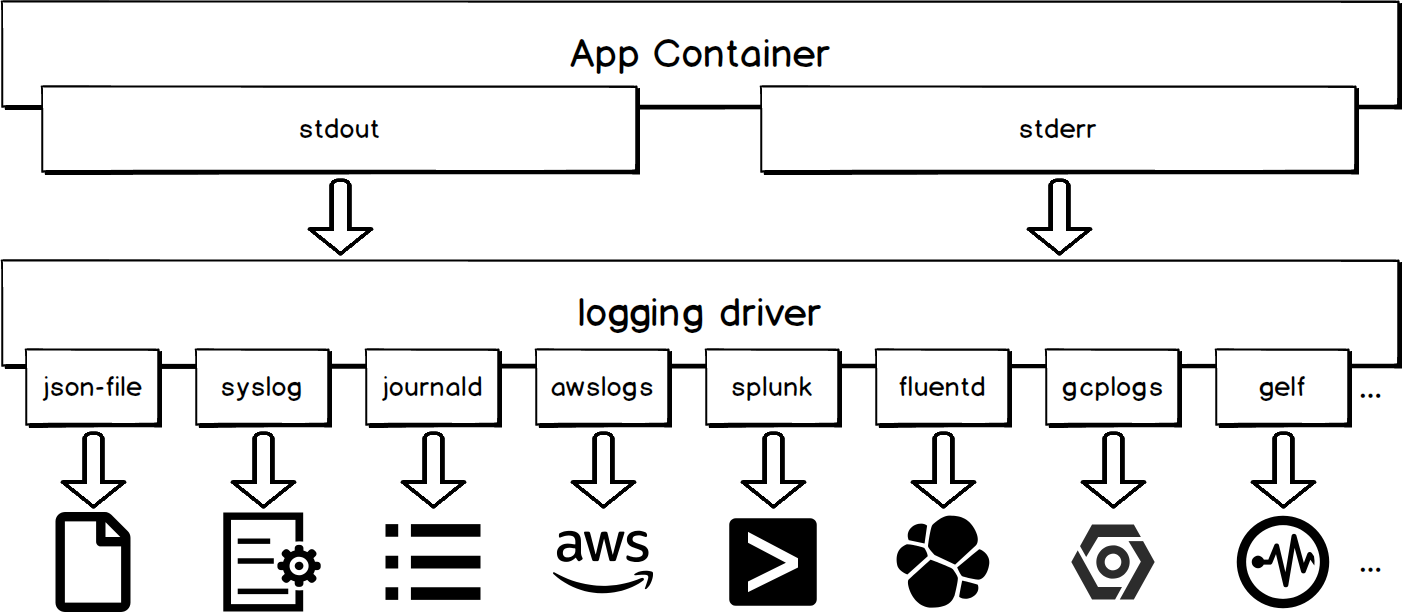
コンテナログの標準出力を集めるのは、使い勝手が良いのがメリットです。
# You can use the following command to configure a syslog logging driver for all containers at the level of docker daemon.
dockerd -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111
# You can use the following command to configure a syslog logging driver for the current container
docker run -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111 alpine echo hello world
欠点
json-fileやjournald以外のロギングドライバを使用すると、docker logs APIが利用できなくなります。ホスト上のコンテナの管理に portainer を使用し、コンテナログの収集に json-file と journald 以外のロギングドライバを使用したとします。コンテナログの標準出力をユーザーインターフェイスから見ることができなくなります。
Docker Logs API
デフォルトでロギングドライバーを使用しているコンテナの場合、docker logsコマンドをdockerデーモンに送信することで、コンテナログの標準出力を取得することができます。この方法を使用するログ収集ツールには、logspout や sematext-agent-docker などがあります。2018-01-01T15:00:00から始まる最新の5つのコンテナログを取得するには、以下のコマンドを使用します。
docker logs --since "2018-01-01T15:00:00" --tail 5 <container-id>
欠点
ログが多いときにこの方法を適用すると、docker デーモンにかなりの負担がかかります。その結果、dockerデーモンはコンテナの作成や削除のためのコマンドに迅速に対応できなくなります。
jsonファイルのファイル
ロギングドライバはデフォルトでコンテナログをJson形式で/var/lib/docker/containers/<container-id>/<container-id>-json.logにあるホストファイルに書き出します。これにより、ホストファイルを直接収集することで、コンテナログの標準出力を取得することができます。
コンテナログは、JSONファイルを収集して収集することをお勧めします。これにより、docker logs APIが利用できなくなったり、dockerデーモンに影響が出たりすることはありません。また、多くのツールがホストファイルを収集するためのネイティブサポートを提供しています。Filebeat と Logtail はこれらのツールの代表的なものです。
テキストログ
ホストファイルディレクトリのマウント
コンテナでテキストログファイルを収集する最も簡単な方法は、ホストファイルのディレクトリをコンテナのログのディレクトリにマウントすることです。これは、次の図のようにコンテナを起動したときにバインドマウントまたはボリュームメソッドを使用することで行うことができます。
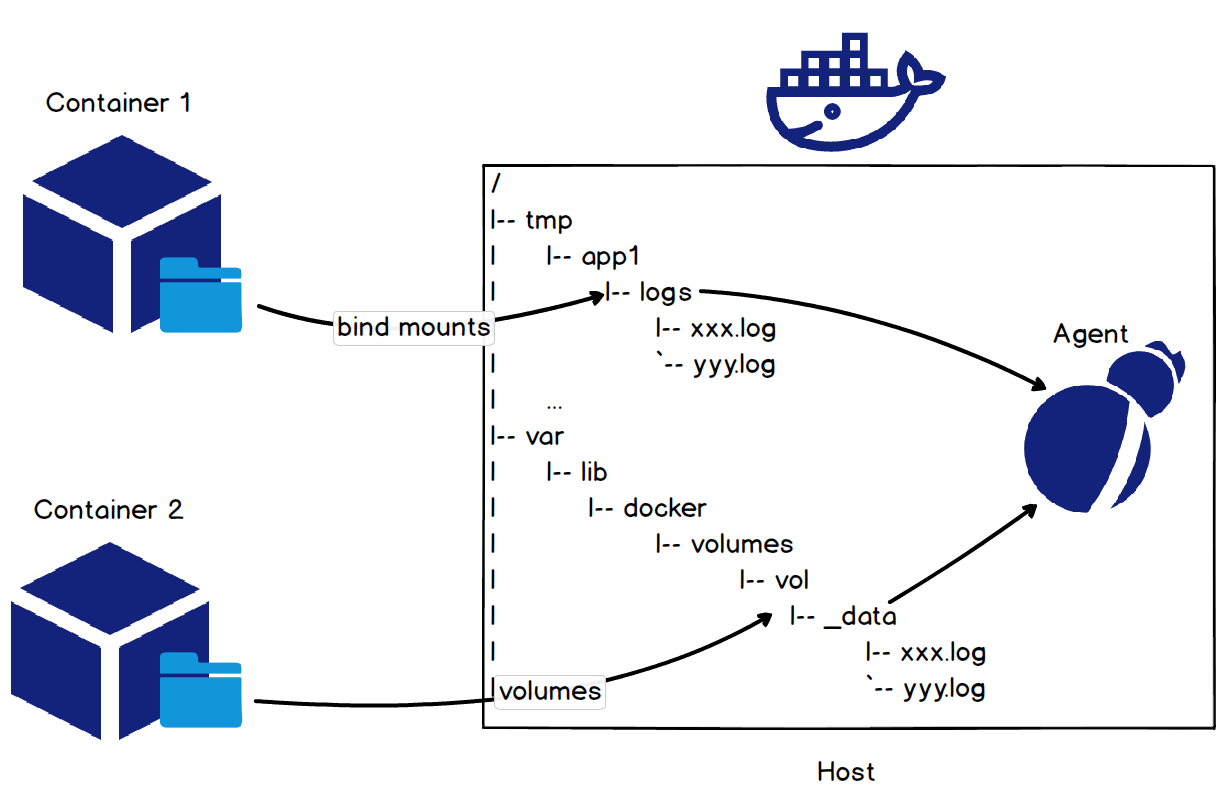
Tomcatコンテナのアクセスログについては、docker run -it -v /tmp/app/vol1:/usr/local/tomcat/logs tomcatというコマンドで、ホストファイルディレクトリ/tmp/app/vol1をコンテナのアクセスログディレクトリ/usr/local/tomcat/logsにマウントします。これにより、ホストファイルディレクトリ/tmp/app/vol1の下にログを収集することで、Tomcatコンテナのアクセスログを収集することができます。
コンテナのマウントポイントを計算する Rootfs
ホストファイルディレクトリをマウントしてコンテナのログを収集するのは、コンテナの起動時にマウントコマンドを実行する必要があるため、アプリケーションにとっては少し押し付けがましいです。ログ収集プロセスがユーザから透過的であれば、それは完璧です。実際、これはコンテナのrootfsのマウントポイントを計算することで実現できます。
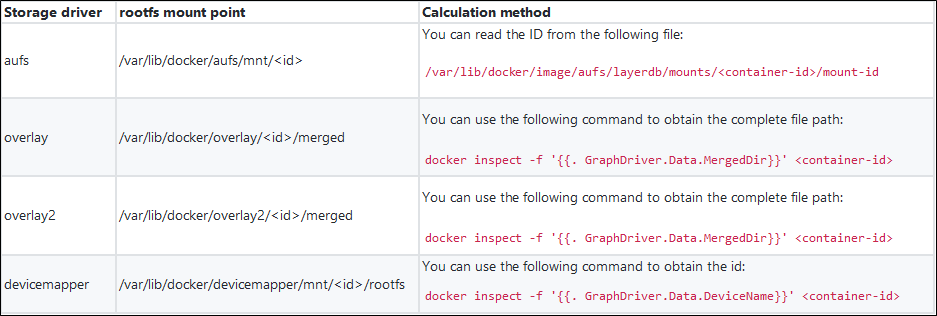
ストレージドライバは、コンテナrootfsのマウントポイントと密接に関係する概念です。実際に使用する際には、Linuxのバージョンやファイルシステムの種類、コンテナのI/Oなど様々な要素を考慮して、最適なストレージドライバを選択することになります。ストレージドライバの種類からコンテナrootfsのマウントポイントを算出し、コンテナ内のログを収集することができます。以下の表に、いくつかのストレージドライバのrootfsのマウントポイントと計算方法を示します。
ログテールソリューション
ログサービスチームは、様々なコンテナログの収集方法を総合的に比較し、ユーザーの声や訴えをまとめて整理した上で、コンテナログを処理するためのオールインワンソリューションを開発しています。
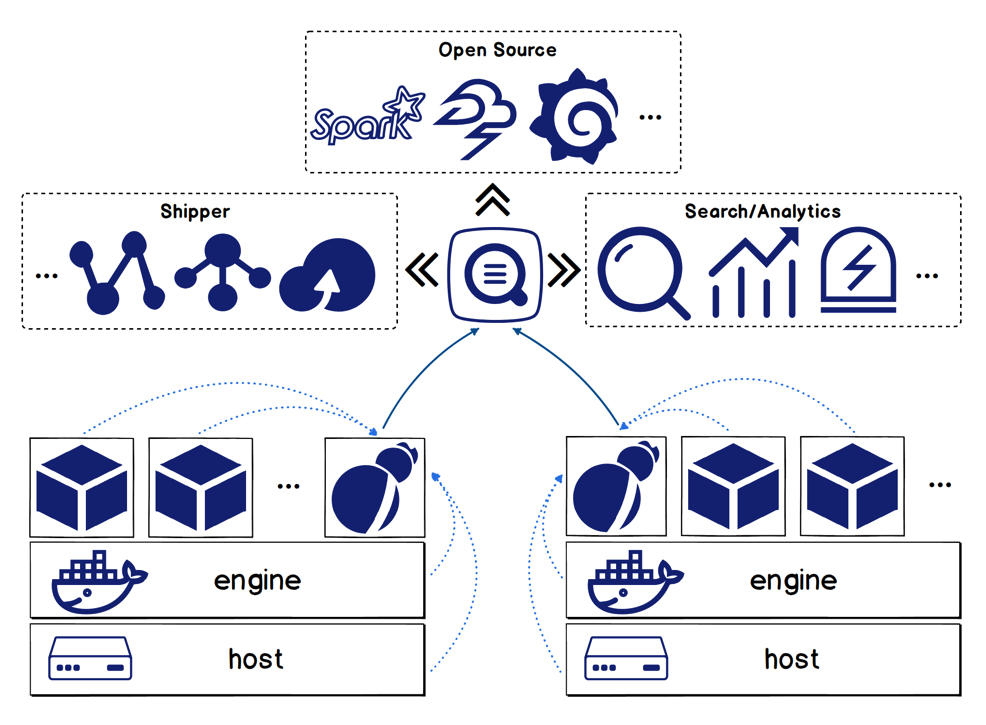
特徴
Logtailソリューションには以下のような機能があります。
1、ホスト上のホストファイルとコンテナログの収集をサポートします(標準出力とログファイルを含む)。
2、コンテナの自動検出をサポートします。つまり、収集対象のログを設定した後、条件を満たすコンテナが作成されると、そのコンテナのターゲットログが自動的に収集されます。
3、Dockerラベルや環境変数のフィルタリングによるコンテナの指定に対応しています。ホワイトリスト、ブラックリストの仕組みをサポートしています。
4、データの自動タグ付けに対応しています。つまり、収集したログにコンテナ名、コンテナIPアドレス、ファイルパスなどのデータソース識別情報を付加します。
5、K8sコンテナログの収集に対応しています。
コア競争力
1、チェックポイント機構を使用し、追加の監視プロセスを展開することで、アットリーストワンスのセマンティクスを確実にします。
2、Logtailは、複数のダブル11とダブル12のショッピングフェスティバルに耐え、アリババグループ内の100万以上のクライアントに導入されています。安定性とパフォーマンスが保証されています。
K8sコンテナログ集
LogtailはK8sのエコシステムと深く連携しており、K8sのコンテナログを便利に収集することができます。これもLogtailの特徴です。
コレクション構成管理:
1、Webコンソールを介したコレクション構成管理をサポートします。
2、CustomResourceDefinition(CRD)によるコレクション構成管理をサポートします。この方法は、K8sのデプロイ・公開手順と容易に統合することができます。
コレクションモード:
1、DaemonSetモードを利用したK8のコンテナログの収集をサポートします。このモードでは、すべてのノードが収集クライアントLogtailを実行します。このモードは単一機能クラスタに適しています。
2、SidecarモードによるK8sコンテナのログ収集をサポートします。このモードでは、各ノードの各コンテナがコレクションクライアントLogtailを実行します。このモードは、大規模、ハイブリッド、PaaSクラスタに適しています。
Logtailソリューションの詳細については、https://www.alibabacloud.com/help/doc-detail/44259.htm を参照してください。
クエリ分析と可視化
ログを収集した後は、これらのログに対してクエリ分析や可視化を行う必要があります。ここではTomcatコンテナのログを例に、Log Serviceが提供する強力なクエリ、分析、可視化機能について説明します。
保存された検索
コンテナログが収集されると、コンテナ名、コンテナIP、ターゲットファイルディレクトリなどのログ識別情報がこれらのログに添付されます。これにより、クエリを実行する際に、この情報に基づいてターゲット コンテナとファイルをすばやく見つけることができます。クエリ機能の詳細については、「クエリの構文」を参照してください。
リアルタイム分析
ログサービスのリアルタイム分析機能は、SQL構文に対応しており、200以上の集計機能を提供しています。SQL文の書き方を知っていれば、ビジネスニーズに合った分析文を簡単に書くことができます。例えば、以下のようになります。
1、以下のステートメントを使用して、アクセス回数の多いリクエストURIの上位10件をクエリすることができます。
* | SELECT request_uri, COUNT(*) as c GROUP by request_uri ORDER by c DESC LIMIT 10
- 以下のステートメントを使用して、最後の15分と最後の1時間の間のネットワークトラフィックの違いをクエリすることができます。
* | SELECT diff[1] AS c1, diff[2] AS c2, round(diff[1] * 100.0 / diff[2] - 100.0, 2) AS c3 FROM (select compare( flow, 3600) AS diff from (select sum(body_bytes_sent) as flow from log))
本明細書では、対前年比較関数と対期間比較関数を用いて、異なる期間のデータ量を計算しています。
可視化
データを可視化するには、Log Serviceの複数の内蔵チャートを使用して、SQLの計算結果を視覚的に表示したり、複数のチャートを組み合わせてダッシュボードにしたりすることができます。
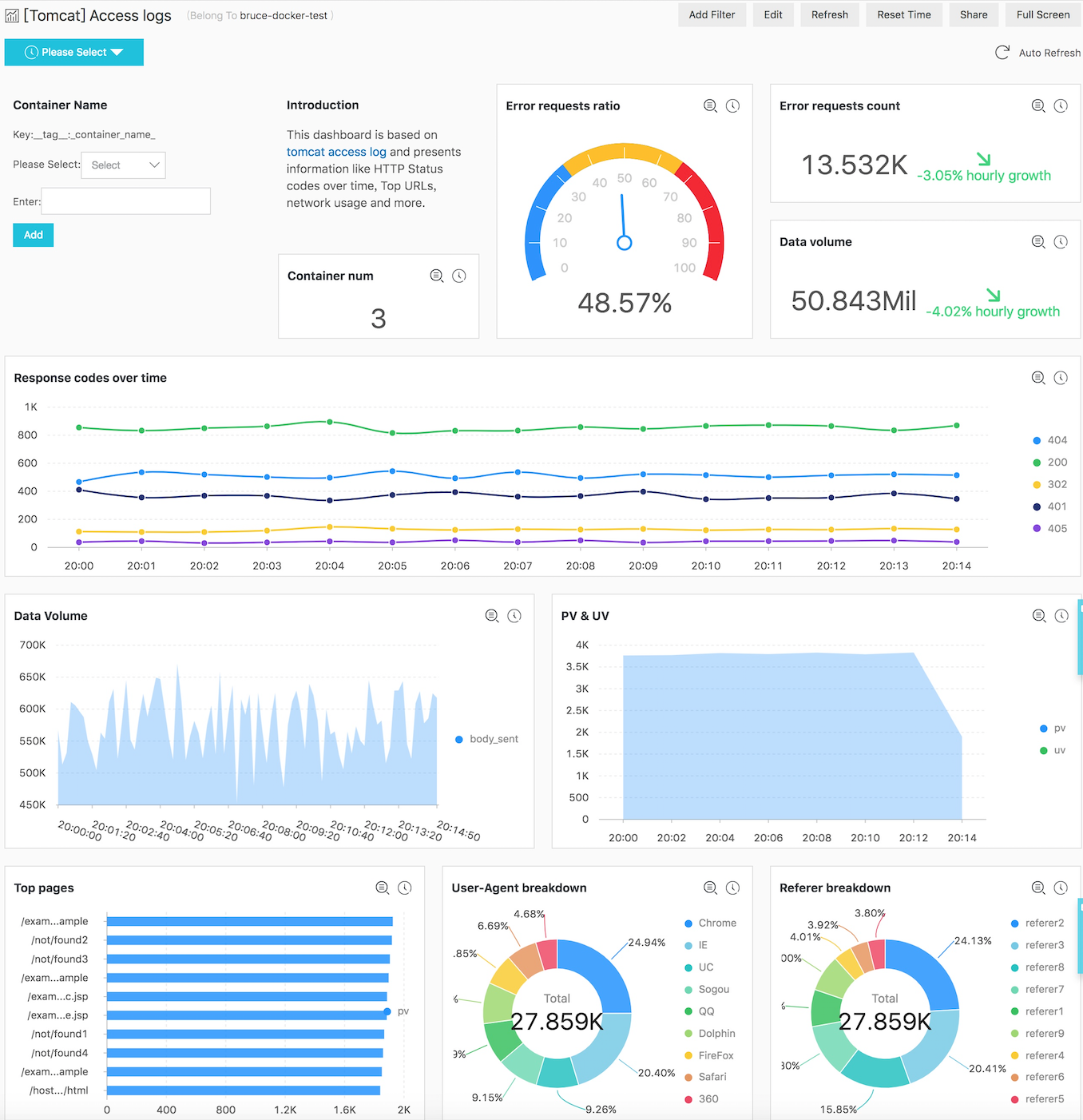
次の図は、Tomcatのアクセスログのダッシュボードです。このダッシュボードからは、エラーリクエストの割合やデータ量、レスポンスコードの経時変化など、様々な情報を見ることができます。このダッシュボードでは、複数のTomcatコンテナのデータを集計した結果を表示しています。また、ダッシュボードのフィルタ機能を利用してコンテナ名を指定することで、個別のコンテナのデータを表示することもできます。
ログの文脈分析
クエリ分析やダッシュボードなどの機能は、グローバルな情報を表示し、システム全体の運用状況を把握するのに役立ちます。しかし、特定の問題を特定するためには、通常、ログからコンテキスト情報が必要になります。
コンテキストの定義
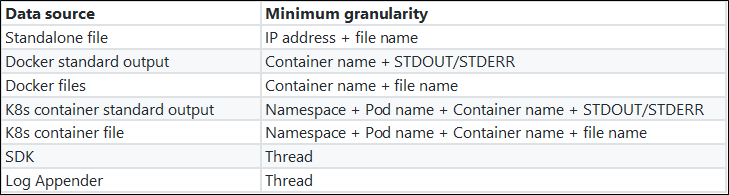
コンテキストとは、ログのエラーの前後の情報など、問題の手がかりとなるものを指します。コンテキストには2つの要素が含まれます。
- 微分化の最小粒度:同じスレッドや同じファイルなど、コンテキストを区別するために使用される最小単位。この最小微分粒度は、調査中に集中できるため、問題の所在を特定する上で非常に重要です。
- オーダーの保証:同じ最小微分粒度であれば、毎秒何万もの操作が行われていても、情報は厳密な順序で提示されなければなりません。
次の表は、異なるデータソースの最小微分粒度を示しています。
コンテキストクエリの課題
ログの集中保管の背景には、ログ収集端末もサーバも元のログの順番を保つことができません。
1、クライアントレベルでは、同一ホスト上で複数のコンテナが稼働しており、各コンテナには収集対象のログファイルが複数存在します。ログ収集ソフトは、ログの解析や前処理に複数の CPU コアを使用しなければなりません。また、ネットワークデータを送信する際の遅いI/O問題に対処するために、マルチスレッド同時実行またはシングルスレッド非同期コールバックモードを使用しなければなりません。その結果、ログデータは、マシン上のイベント生成シーケンスに従ってサーバに到着することができません。
2、サーバ上では、水平拡張マルチノード負荷分散アーキテクチャのため、同じクライアントマシン上のログが複数のストレージノードに分散されてしまいます。複数のストレージノードに分散したログを元のシーケンスに戻すことは困難です。
仕組み
ログ サービスは、各ログ レコードに追加情報を追加したり、サーバーのキーワード クエリ機能を使用したりすることで、これらの課題を効果的に解決します。次の図は、ログサービスがこれらの問題にどのように対処しているかを示しています。
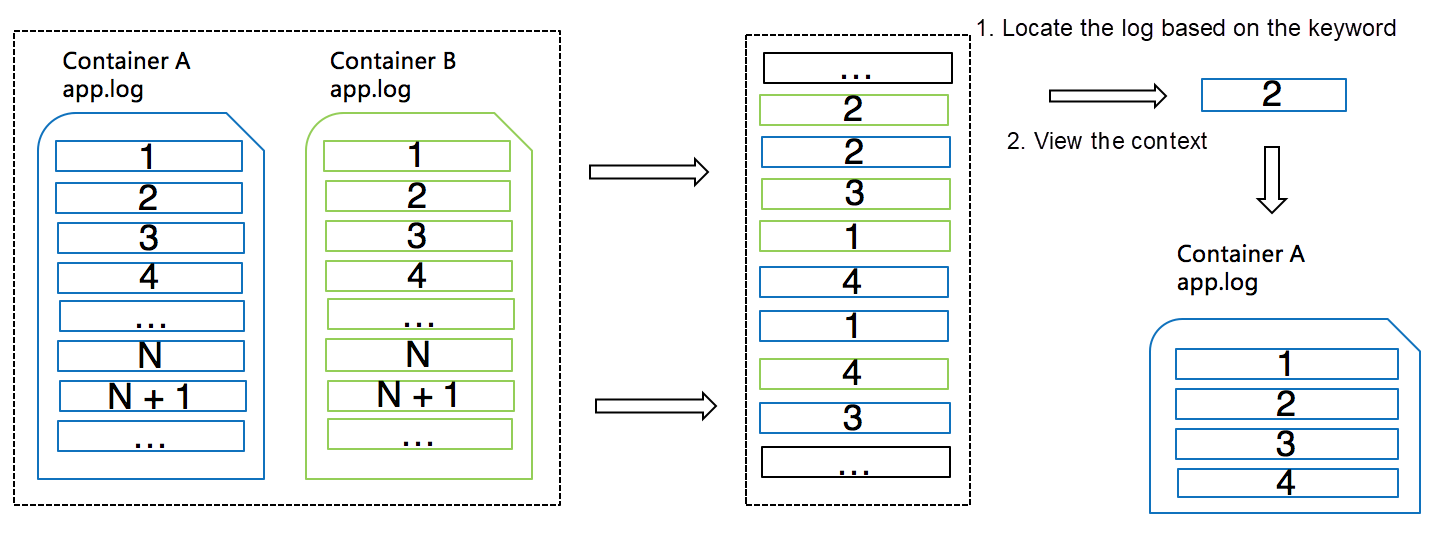
1、ログレコードが収集されると、ログサービスは自動的にログのソース情報(前述の最小粒度)をsource_idとして追加します。コンテナの場合、そのような情報はコンテナ名とファイルパスになります。
2、ログサービスのログ収集クライアントは通常、ログパッケージとして複数のログを一度にアップロードします。クライアントは、これらのログパッケージのそれぞれに単調に増加するpackage_idを書き込み、ログパッケージの各ログレコードはパッケージベースのオフセットを持つ。
3、サーバは、source_id、package_id、オフセットをフィールドに結合し、このフィールドのインデックスを作成します。これにより、異なるタイプのログが混在してサーバーに保存されている場合でも、source_id、package_id、オフセットに基づいて正確にログエントリを見つけることができます。
LiveTail - クラウド上のtail-f
ログコンテキストを見ることとは別に、コンテナの出力を継続的に監視したい場合もあります。
従来の方法
以下の表は、従来の方法でコンテナのログをリアルタイムに監視する方法を示しています。

問題点
コンテナのログを監視するために従来の方法を使用すると、以下のような問題点があります。
1、多数のコンテナの中から目的のコンテナを探すのは時間がかかる。
2、異なる種類のコンテナログを表示するために異なる観測方法を使用しなければならず、コストが増加する。
3、キー情報のクエリ結果の表示がシンプルで直感的ではない。
新機能と仕組み
これらの問題を解決するために、ログサービスはLiveTail機能を提供しています。従来の方法と比較して、LiveTailには次のような利点があります。
1、1つのログエントリに基づいて、またはログサービスのクエリ分析機能を使用して、ターゲットコンテナを迅速に見つけることができます。
2、統一された方法を使用して、ターゲットコンテナに飛び込むことなく、異なるタイプのコンテナログを表示することができます。
3、キーワードベースのフィルタリングに対応しています。
4、キーカラムの設定をサポートしています。
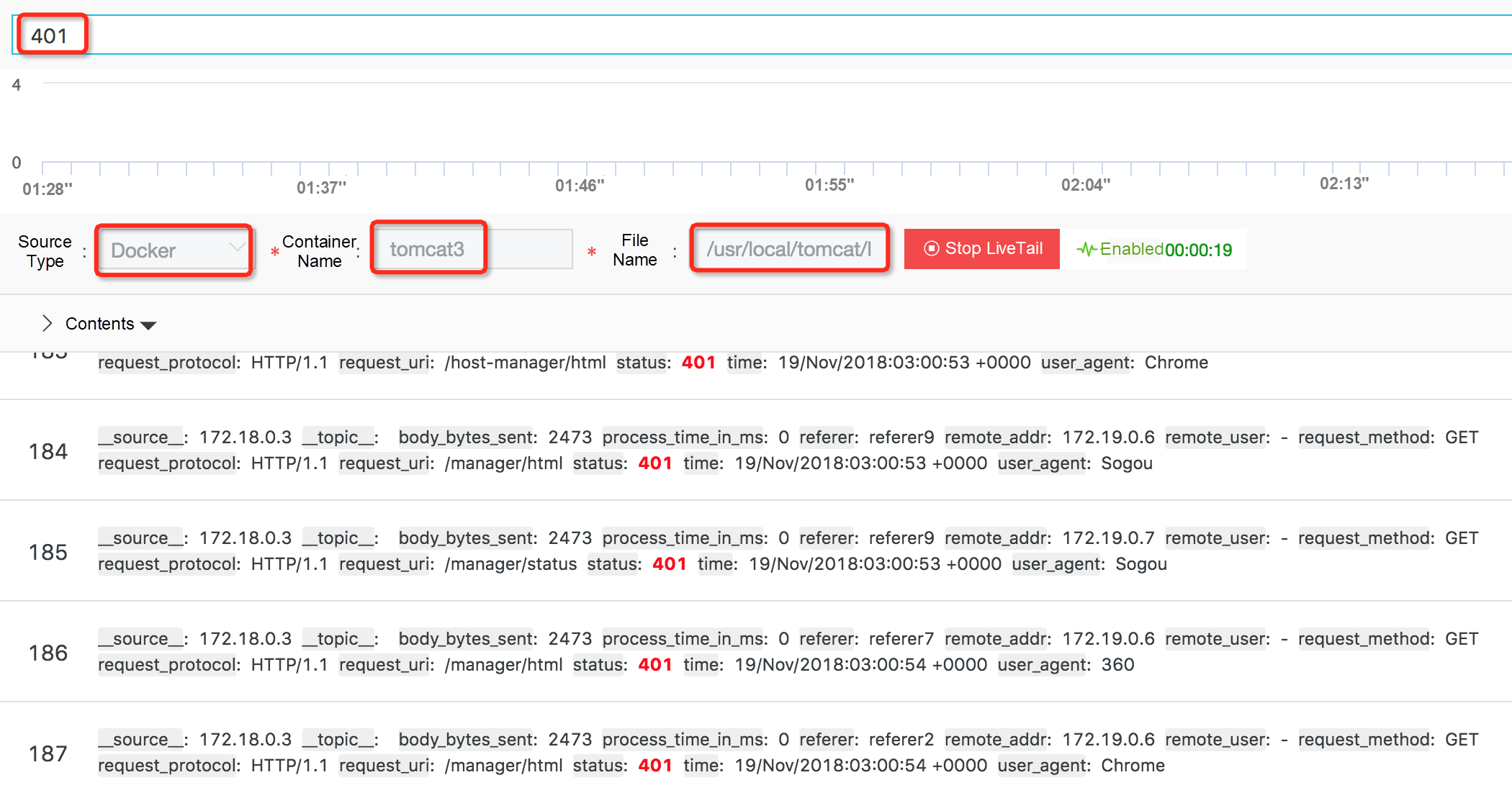
LiveTailは、前のセクションで述べたようにコンテキストクエリのメカニズムを使用して、ターゲットコンテナとターゲットファイルを素早く見つけることができます。そして、クライアントは定期的にサーバーにリクエストを送り、最新のデータを引き出します。
参考文献
- https://www.alibabacloud.com/blog/trends-and-challenges-of-kubernetes-log-processing-for-serverless-kubernetes_593961
- https://www.alibabacloud.com/help/doc-detail/44259.htm
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ