この記事では、PyFlinkのアーキテクチャを紹介し、PyFlinkを使ってCDNのログを解析するクイックデモを提供します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
なぜ PyFlink が必要なのか?
Flink on PythonとPython on Flink
では、PyFlink とは一体何なのでしょうか?その名の通り、PyFlinkは単純にApache FlinkとPython、というかPython上のFlinkを組み合わせたものです。しかし、PythonのFlinkは何を意味しているのでしょうか?まず、この2つを組み合わせることで、PythonでFlinkの機能をすべて使えるようになります。さらに重要なことに、PyFlinkはPythonの広範なエコシステムの計算能力をFlink上で利用することができ、そのエコシステムの開発をさらに促進することができます。つまり、双方にとってWin-Winなのです。このトピックをもう少し深く掘り下げてみると、FlinkフレームワークとPython言語の統合は決して偶然ではないことがわかります。
Pythonとビッグデータエコシステム
python言語はビッグデータと密接な関係があります。それを理解するために、Pythonを使って人々が実践的に解決している問題をいくつか見てみましょう。ユーザー調査によると、ほとんどの人がデータ分析や機械学習のアプリケーションにPythonを使っているという結果が出ています。このような種類のシナリオのために、いくつかの望ましいソリューションがビッグデータ空間でも対処されています。ビッグデータ製品のオーディエンスの拡大とは別に、Pythonとビッグデータの統合は、スタンドアロンアーキテクチャを分散アーキテクチャに拡張することで、Pythonエコシステムの機能を大幅に強化します。大量のデータを分析する上で、Pythonに強い需要があることも説明されています。

なぜFlinkとPythonなのか?
Pythonとビッグデータの統合は、他のいくつかの最近の傾向と一致しています。しかし、繰り返しになりますが、なぜFlinkは今、GoやRや他の言語ではなく、Pythonをサポートしているのでしょうか?また、なぜほとんどのユーザが PySpark や PyHive よりも PyFlink を選ぶのか?
その理由を理解するために、まずFlinkフレームワークを使うメリットを考えてみましょう。
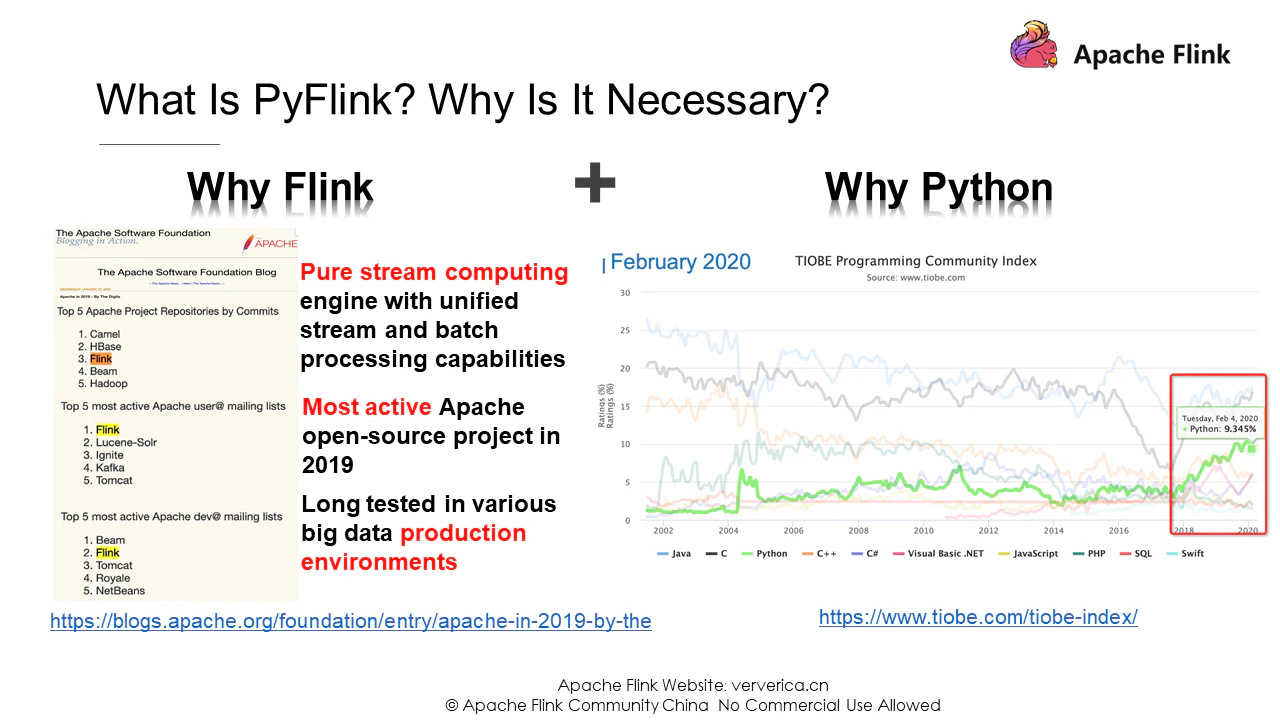
- 有利なアーキテクチャ:Flinkは、統一されたストリームとバッチ処理機能を備えたピュアストリームコンピューティングエンジンです。
- 爽やかなバイタリティ:ASFの客観的な統計によると、Flinkは2019年に最もアクティブなオープンソースプロジェクトです。
- 高い信頼性:オープンソースのプロジェクトとして、Flinkは長い間テストされ、ビッグデータ企業の生産環境に広く適用されてきました。
次に、Flinkが他の言語ではなくPythonをサポートしている理由を見てみましょう。統計によると、PythonはJava、Cに次ぐ人気言語で、2018年から急速に発展しています。JavaとScalaがFlinkのデフォルト言語ですが、Pythonをサポートするのは妥当なようです。
PyFlinkは関連技術の発展の必然的な産物です。しかし、最終的な目標はFlinkやPythonのユーザーに利益をもたらし、現実の問題を解決することなので、PyFlinkの意義を理解するだけでは十分ではありません。そのため、PyFlinkをどのように実装できるのか、さらに掘り下げていく必要があります。

PyFlinkアーキテクチャ
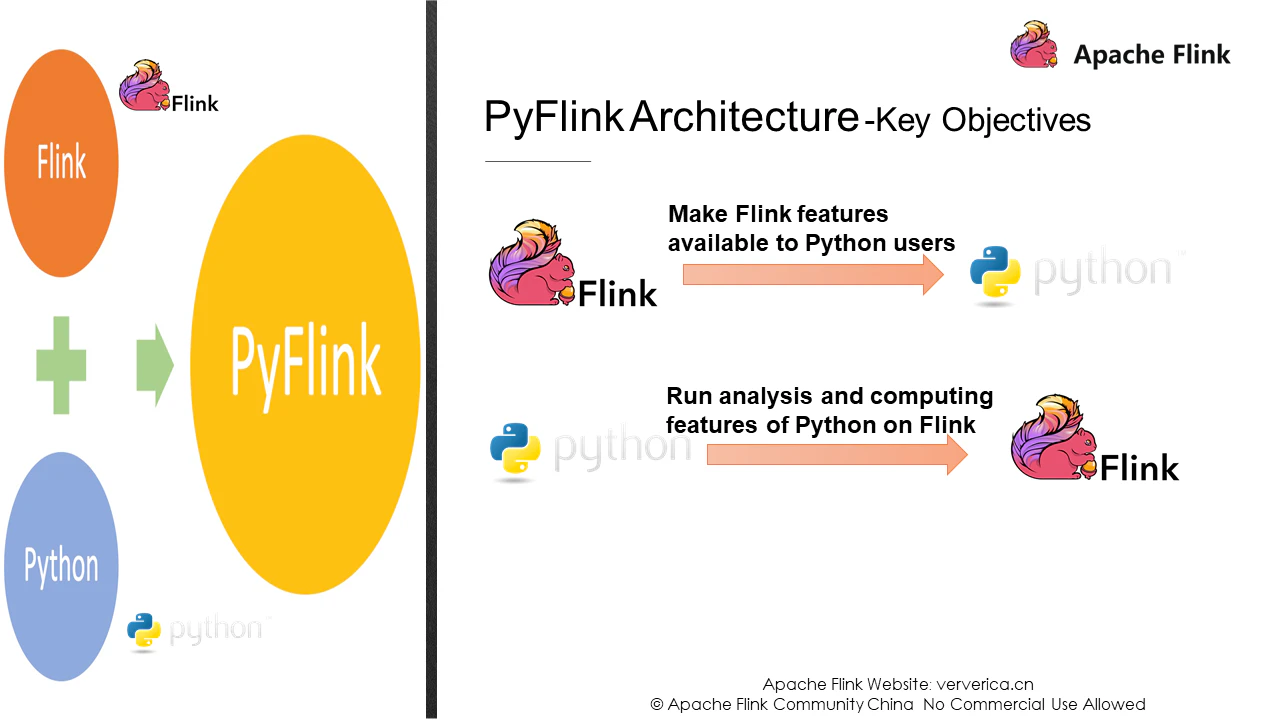
PyFlinkを実装するためには、達成すべき主要な目的と解決すべき核心的な課題を知る必要があります。PyFlinkの主な目的は何ですか?要するに、PyFlinkの主な目的は以下のように詳しく書かれています。
1、Flinkのすべての機能をPythonユーザーが利用できるようにします。
2、Flink上でPythonの分析・演算機能を実行することで、Pythonのビッグデータの課題解決能力を向上させることができます。
その上で、これらの目的を達成するために解決すべき重要な課題を分析してみましょう。
Flinkの機能をPythonユーザーが利用できるようにする
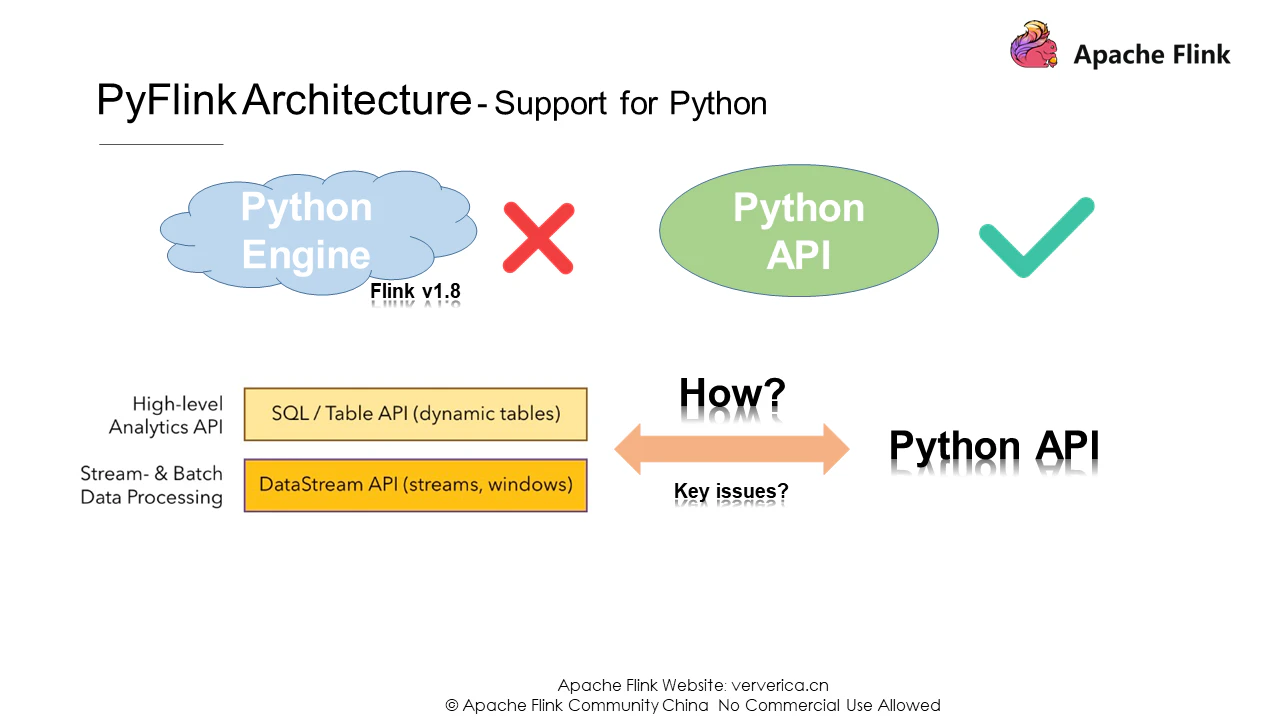
PyFlinkを実装するには、既存のJavaエンジンのようにFlink上でPythonエンジンを開発する必要があるのでしょうか?答えはノーです。Flinkのバージョン1.8以前で試みたが、うまくいかなかった。基本設計の原則は、与えられた目的を最小限のコストで達成することです。最もシンプルですが、Python APIの1つのレイヤーを提供し、既存のコンピューティングエンジンを再利用するのがベストな方法です。
では、FlinkにはどのようなPython APIを提供すればよいのでしょうか?ハイレベルなテーブルAPIやSQL、ステートフルなDataStream APIなど、身近な存在です。Flinkの内部ロジックに近づいてきたので、次はTable APIとPython用のDataStream APIを提供します。しかし、その時に残された重要な課題とは一体何なのでしょうか?
鍵となる問題
明らかに重要な問題は、Python仮想マシン(PyVM)とJava仮想マシン(JVM)の間でハンドシェイクを確立することであり、これはFlinkが複数の言語をサポートするために不可欠です。この課題を解決するためには、適切な通信技術を選択する必要があります。さあ、行きましょう。
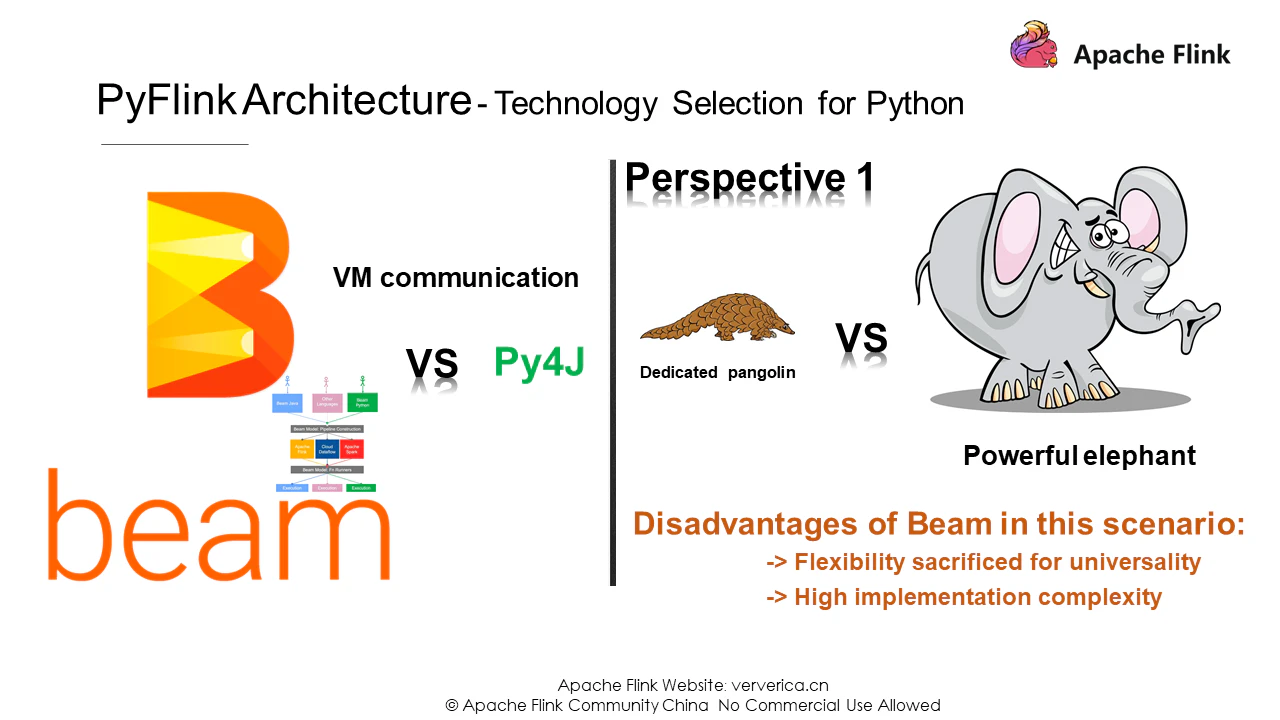
仮想マシン通信の技術選定
現在、PyVMとJVM間の通信を実装するためのソリューションは、Apache BeamとPy4Jの2つがあります。前者は多言語・マルチエンジン対応の有名なプロジェクトで、後者はPyVMとJVM間の通信に特化したソリューションです。Apache BeamとPy4Jの違いを理解するために、いくつかの異なる視点から比較対照することができます。まず、この例えを考えてみましょう。壁を越えるためには、Py4Jはモグラのように穴を掘り、Apache Beamは大きな熊のように壁全体を破壊します。このような観点から、Apache Beamを使ってVM通信を実装するのは少々複雑です。要するに、Apache Beamは普遍性を重視しており、極端なケースでは柔軟性に欠けているからです。
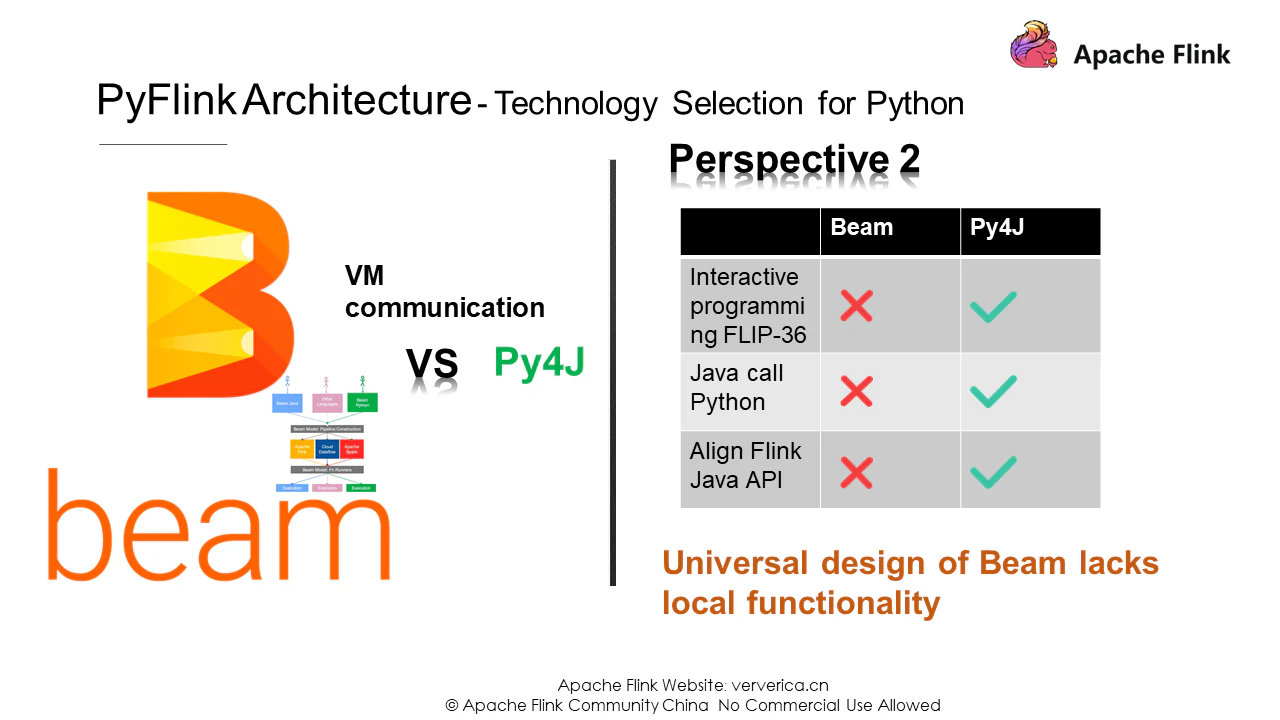
これに加えて、FlinkではFLIP-36のようなインタラクティブなプログラミングが必要になります。さらに、Flinkが正しく動作するためには、APIの設計、特に多言語サポートに関して、意味的な一貫性を確保する必要があります。Apache Beamの既存のアーキテクチャではこれらの要件を満たすことができないため、Py4JがPyVMとJVM間の通信をサポートするための最良の選択肢であることは明らかです。
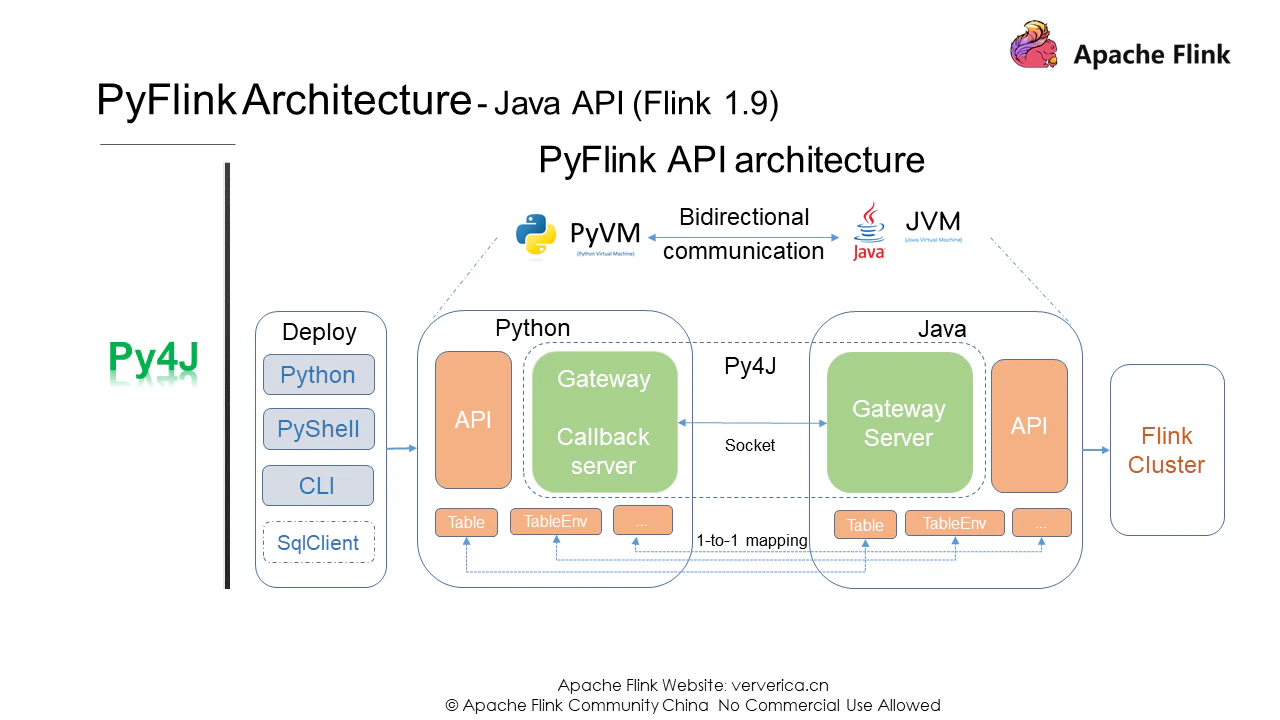
技術的なアーキテクチャ
PyVMとJVM間の通信を確立した後、Flinkの機能をPythonユーザが利用できるようにするための最初の目的を達成しました。これはFlinkバージョン1.9ですでに実現しています。それでは、Flinkバージョン1.9のPyFlink APIのアーキテクチャを見てみましょう。
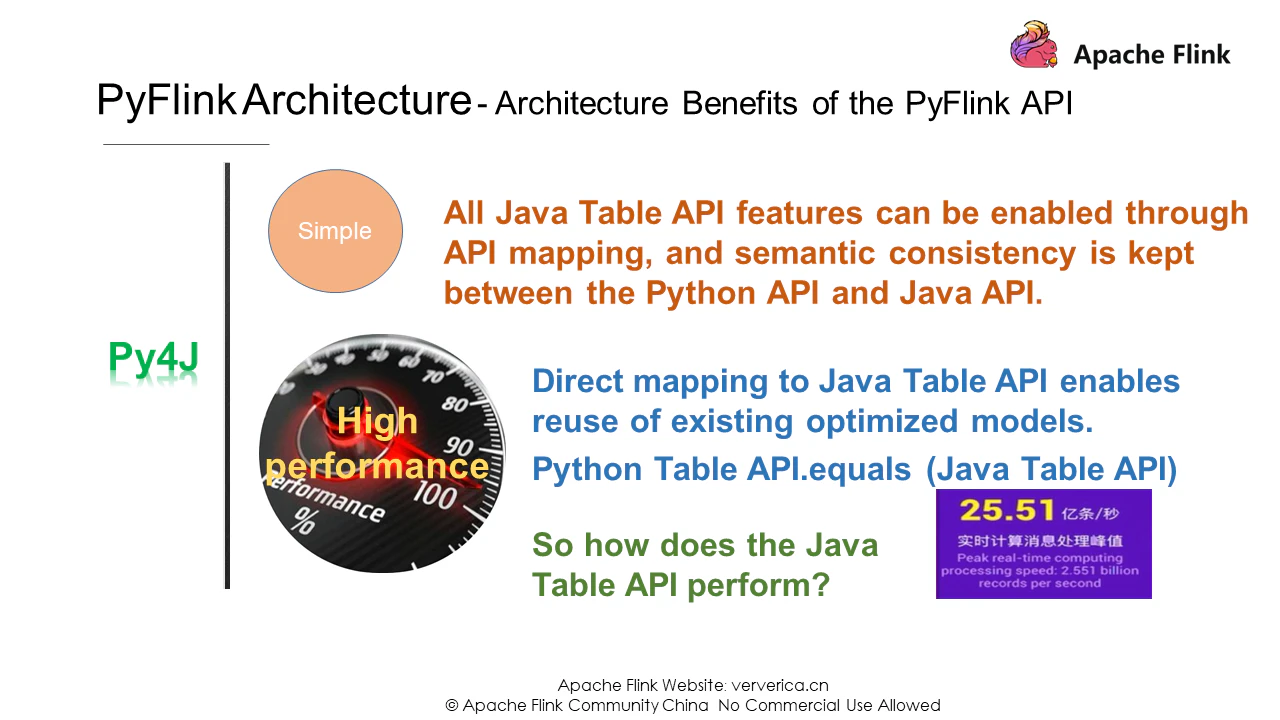
Flink バージョン1.9では、Py4Jを使って仮想マシン通信を実装しています。PyVM用のゲートウェイとJVM用のゲートウェイサーバを有効にして、Pythonのリクエストを受け付けるようにしました。また、Python APIではTableENVやTableなどのオブジェクトも提供しており、Java APIで提供されているものと同じです。そのため、Python APIを書く上での本質は、Java APIをどうやって呼び出すかということにあります。Flinkバージョン1.9では、ジョブの配置の問題も解決されました。Pythonコマンドを実行したり、PythonシェルやCLIを利用したりと、様々な方法でジョブを投入することができます。
しかし、このアーキテクチャにはどのようなメリットがあるのでしょうか?まず、アーキテクチャがシンプルであり、Python APIとJava APIの間のセマンティックな整合性を確保しています。第二に、Javaジョブに匹敵する優れたPythonジョブ処理性能を提供します。例えば、FlinkのJava APIは、昨年のダブル11の間、1秒間に25億5,100万件のデータレコードを処理することができました。
Flink上でPythonの解析・計算機能を実行する
前の項では、Flinkの機能をPythonユーザーが利用できるようにする方法を説明しました。ここでは、Flink上でPythonの関数を実行する方法を紹介します。一般的に、Flink上でPythonの関数を実行するには、以下の2つの方法があります。
1、**代表的なPythonクラスのライブラリを選択し、そのAPIをPyFlinkに追加します。**Pythonにはクラスライブラリが多すぎるので、このメソッドは時間がかかります。APIを組み込む前に、Pythonの実行を効率化する必要があります。
2、**既存のFlink Table APIとPythonクラスライブラリの特性を踏まえ、既存のPythonクラスライブラリの関数をすべてユーザー定義関数として扱い、Flinkに統合することができます。**Flinkのバージョン1.10以降でサポートされています。機能統合の重要課題とは?繰り返しになりますが、それはPythonのユーザー定義関数の実行にあります。
次に、この重要課題の技術を選択してみましょう。
ユーザー定義機能を実行するための技術の選択
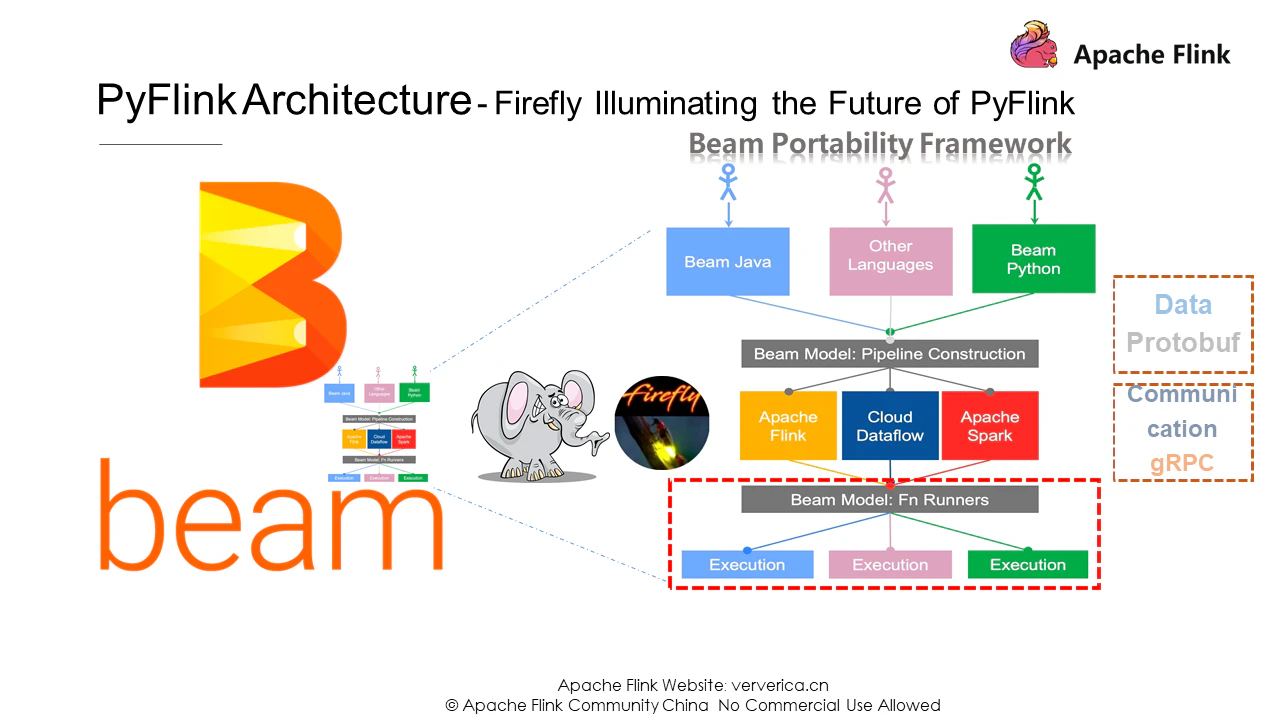
Pythonのユーザー定義関数の実行は、実はかなり複雑です。仮想マシン間の通信だけでなく、Pythonの実行環境の管理、JavaとPythonの間でやり取りされる業務データの解析、FlinkのステートバックエンドをPythonに渡すこと、実行状況の監視など、すべてに関わる。これだけ複雑なので、Apache Beamの出番です。複数のエンジンや言語をサポートしている大熊として、Apache Beamはこのような状況を助けるために多くのことを行うことができますので、Pythonのユーザ定義関数の実行をApache Beamがどのように扱うのかを見てみましょう。
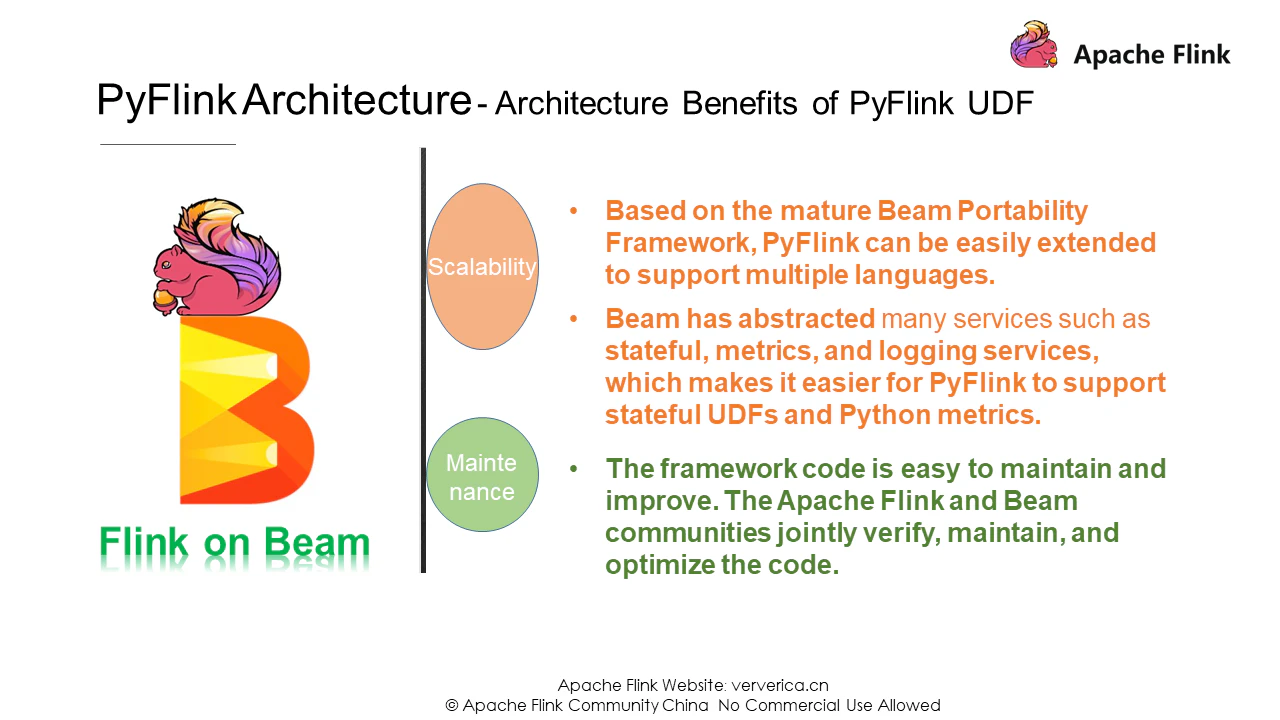
下に示したのはPortability Frameworkで、複数の言語やエンジンをサポートするように設計されたApache Beam用の高度に抽象化されたアーキテクチャです。現在、Apache BeamはJava、Go、Pythonを含むいくつかの異なる言語をサポートしています。図の下部にあるBeam Fn RunnersとExecutionは、エンジンとユーザー定義の機能実行環境を示しています。Apache BeamはProtobufとも呼ばれるプロトコルバッファを使用してデータ構造を抽象化し、gRPCプロトコル上での通信を可能にし、gRPCのコアサービスをカプセル化しています。この面では、Apache Beamはどちらかというと、PyFlinkにおけるユーザ定義関数の実行経路を照らすホタルのようなものです。興味深いことに、ホタルはアパッチビームのマスコットになっているので、偶然の一致ではないかもしれません。
次に、Apache Beamが提供するgRPCサービスを見てみましょう。
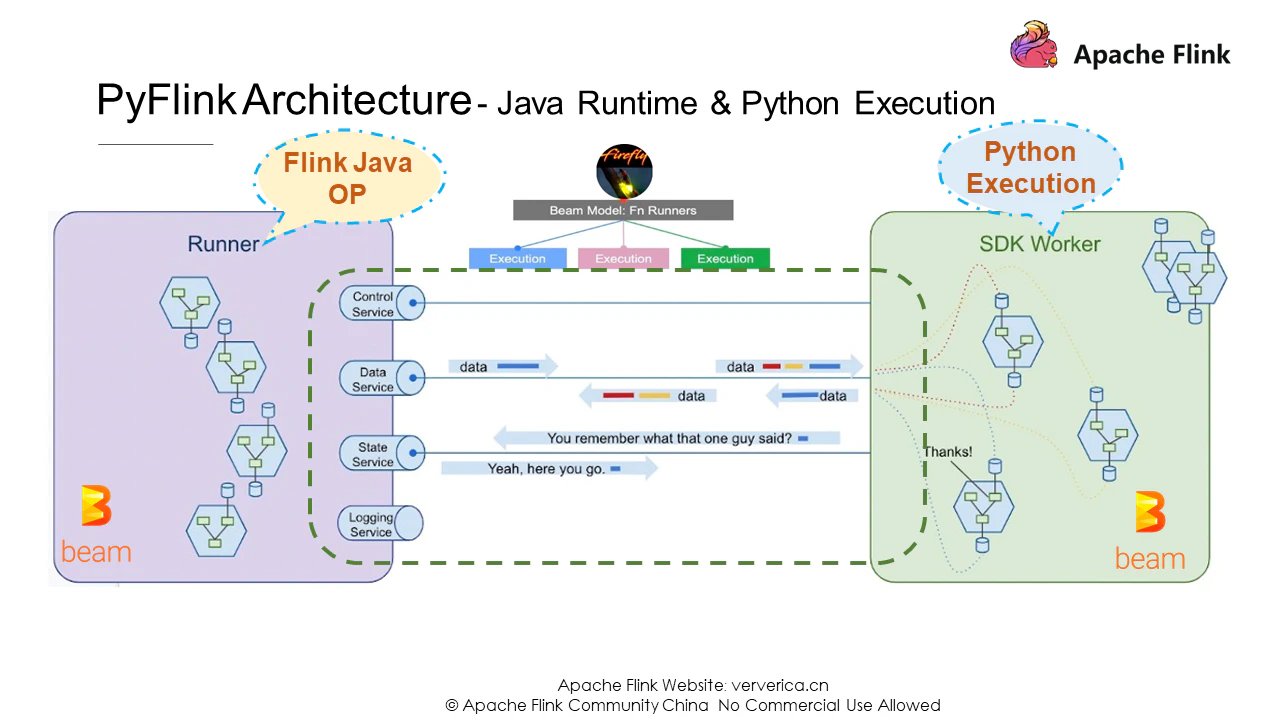
下の図では、ランナーはFlinkのJava演算子を表しています。ランナーは、Python実行環境のSDKワーカーにマッピングします。Apache Beamは、制御、データ、状態、ログなどの抽象化されたサービスを持っています。実は、これらのサービスは長い間、ビームフリンクランナーで安定的かつ効率的に運営されてきました。これにより、PyFlink UDF の実行が容易になります。さらに、Apache BeamはAPIコールとユーザ定義関数実行の両方のソリューションを持っています。PyFlinkは、APIレベルでの仮想マシン間の通信にPy4Jを使用し、ユーザ定義機能の実行環境の設定にはApache BeamのPortability Frameworkを使用しています。
このことは、PyFlinkが技術選択において、与えられた目的を最小限のコストで達成するという原則を厳格に守り、長期的な開発に最も適した技術アーキテクチャを常に採用していることを示しています。ところで、Apache Beamとの協力の間、私は20以上の最適化パッチをBeamコミュニティに提出してきました。
ユーザー定義機能アーキテクチャ
UDFアーキテクチャは、PyVMとJVM間の通信を実装するだけでなく、コンパイルと実行の段階で異なる要件を満たす必要があります。以下のPyLinkユーザ定義関数アーキテクチャ図では、JVMでの動作が緑色、PyVMでの動作が青色で示されています。コンパイル中のローカルデザインを見てみましょう。ローカルデザインは純粋なAPIマッピングコールに依存しています。VM通信にはPy4Jを使用しています。PythonのAPIを呼び出すたびに、対応するJavaのAPIが同期的に呼び出されます。
ユーザー定義関数をサポートするためには、ユーザー定義関数登録API(register_function)が必要です。Pythonのユーザー定義関数を定義する際には、いくつかのサードパーティ製のライブラリも必要になります。そのため、依存関係の追加にはadd_Python_file()のような一連の追加メソッドが必要になります。Pythonのジョブを書く際には、ジョブを投入する前にJavaのAPIも呼ばれてJobGraphを作成します。そして、CLIを介してのようないくつかの異なる方法でクラスタにジョブを投入することができます。

画像参照
https://yqintl.alicdn.com/a72ad37ed976e62edc9ba8dcb027bf61be8fe3f3.gif
では、このアーキテクチャでPython APIとJava APIがどのように機能するのかを見てみましょう。Java側では、JobMasterは一般的なJavaジョブと同様にTaskManagerにジョブを割り当て、TaskManagerはJVMとPyVMの両方で演算子の実行を伴うタスクを実行します。Pythonのユーザ定義関数演算子では、JVMとPyVM間の通信のための各種gRPCサービス、例えばビジネスデータ通信のためのDataServiceや、Javaのステートバックエンドを呼び出すためのPython UDFのためのStateServiceなどを設計します。その他にも、ロギングやメトリクスなど多くのサービスが提供されます。
これらのサービスはBeamのFn APIに基づいて構築されています。ユーザー定義関数は最終的にPythonワーカーで実行され、対応するgRPCサービスはJVM内のPythonユーザー定義関数演算子に結果を返します。Pythonワーカーはプロセスとして、Dockerコンテナ内で、さらには外部のサービスクラスタでも実行できます。この拡張メカニズムは、PyFlink を他の Python フレームワークと統合するための強固な基盤を築いています。さて、PyFlink 1.10で導入されたPythonのユーザー定義関数アーキテクチャについて基本的な理解ができたので、そのメリットを見ていきましょう。
まず、成熟した多言語対応フレームワークであること。ビームベースのアーキテクチャは、他の言語をサポートするために簡単に拡張することができます。第二に、ステートフルなユーザー定義関数のサポート。Beamはステートフルなサービスを抽象化し、PyFlinkがステートフルなユーザ定義関数をサポートするのを容易にします。3つ目は、簡単なメンテナンス。2つのアクティブなコミュニティ-Apache BeamとApache Flinkは、同じフレームワークを維持し、最適化します。
PyFlink の使い方
PyFlink のアーキテクチャとその背後にある考え方を理解した上で、PyFlink の具体的なアプリケーションシナリオを見てみましょう。
PyFlinkのアプリケーションシナリオ
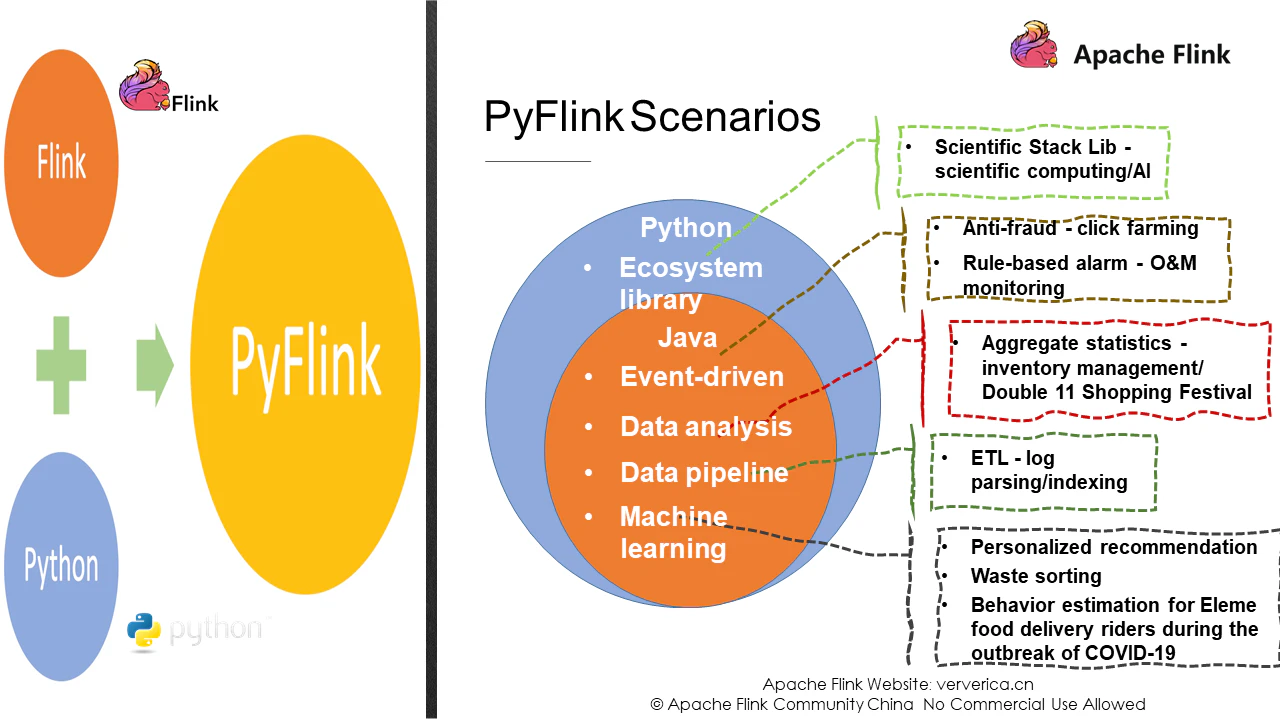
PyFlinkがサポートするビジネスシナリオとは?その応用シナリオを2つの視点から分析することができます。PythonとJava。PyFlink は Java が適用できるすべてのシナリオに適していることを覚えておいてください。
1、クリック農園やモニタリングなどのイベント駆動型のシナリオ。
2、在庫管理やデータの可視化などのデータ分析。
3、ログ解析などのETLシナリオとしても知られるデータパイプライン。
4、的を絞ったレコメンドなどの機械学習。
これらすべてのシナリオでPyFlinkを使うことができます。PyFlink は、科学的なコンピューティングなど、Python に特化したシナリオにも適用されます。これだけ多くのアプリケーションシナリオがあると、具体的にどのようなPyFlink APIが利用できるのか疑問に思うかもしれません。ということで、その質問も今から調べてみましょう。
PyFlink のインストール
APIを使う前に、PyFlinkをインストールする必要があります。現在、PyFlinkをインストールするには、次のコマンドを実行します。
PyFlink API
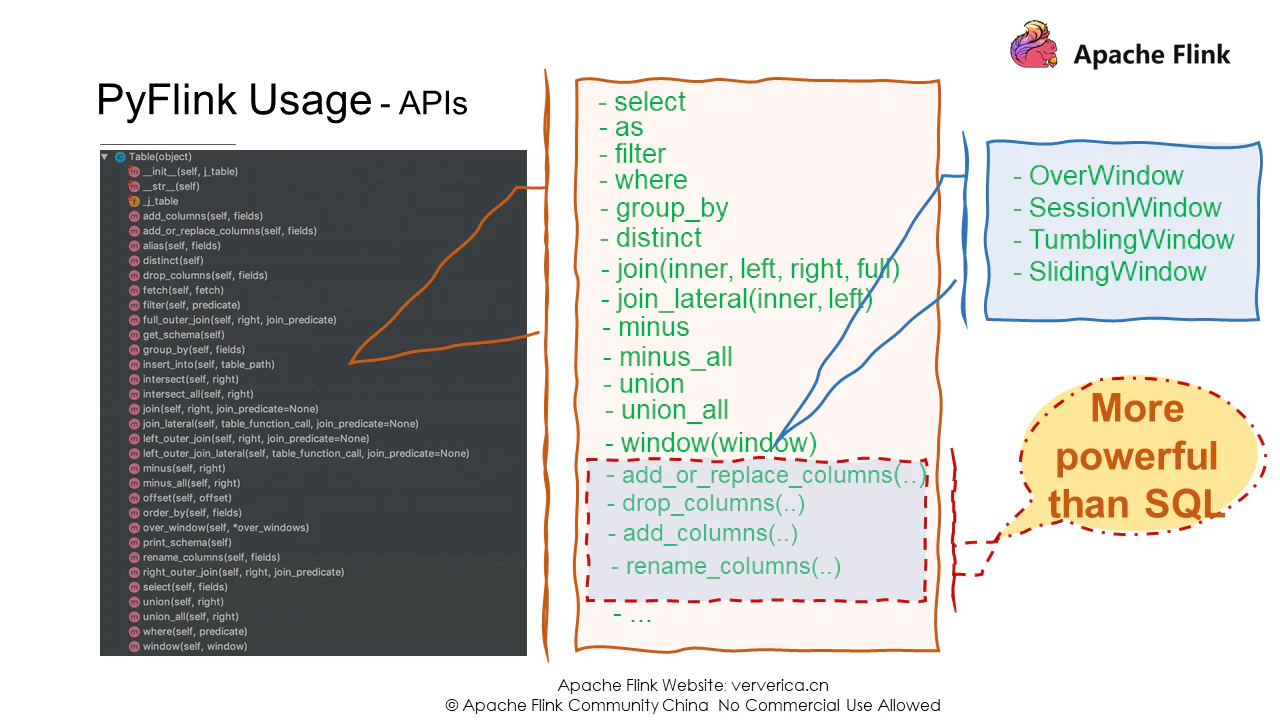
PyFlink API は Java Table API と完全に連携しており、様々なリレーショナル操作やウィンドウ操作をサポートしています。使いやすいPyFlink APIの中には、カラム操作に特化したAPIなど、SQL APIよりもさらに強力なものもあります。APIに加えて、PyFlinkはPythonのUDFを定義するための複数の方法を提供しています。
PyFlink でのユーザ定義関数の定義
ScalarFunctionは、より多くの補助機能を提供するために(例えば、メトリックを追加することによって)拡張することができます。また、PyFlink のユーザ関数は、ラムダ関数、名前付き関数、呼び出し可能な関数など、Python がサポートしているすべてのメソッド定義をサポートしています。
これらのメソッドを定義したら、PyFlink Decoratorsを使ってタグ付けを行い、入出力データ型を記述します。また、型の導出のために、Pythonの型ヒント機能を利用して、後のバージョンをさらに合理化することもできます。以下の例では、ユーザー定義関数の定義方法をよりよく理解することができます。

Pythonのユーザ定義関数を定義した一例
この例では、2つの数字を足し算します。そのために必要なクラスをインポートし、前述の関数を定義します。これはかなりわかりやすいので、実際のケースに進んでみましょう。

PyFlinkの場合:アリババクラウドCDNのリアルタイムログ解析
ここでは、Alibaba Cloud Content Deliver Network (CDN) のリアルタイムログ解析機能を例に、PyFlink を使って実務上の問題を解決する方法を紹介します。リソースのダウンロードを高速化するためにアリババクラウドCDNを利用しています。一般的に、CDNのログは一般的なパターンで解析されます。まず、エッジノードからログデータを収集し、そのデータをメッセージキューに保存します。第二に、メッセージキューとリアルタイムコンピュートクラスタを組み合わせて、リアルタイムログ解析を実行します。3つ目は、分析結果をストレージシステムに書き込むことです。この例では、アーキテクチャがインスタンス化され、メッセージキューとしてKafkaが使用され、リアルタイムコンピューティングにはFlinkが使用され、最終的なデータはMySQLデータベースに格納されています。
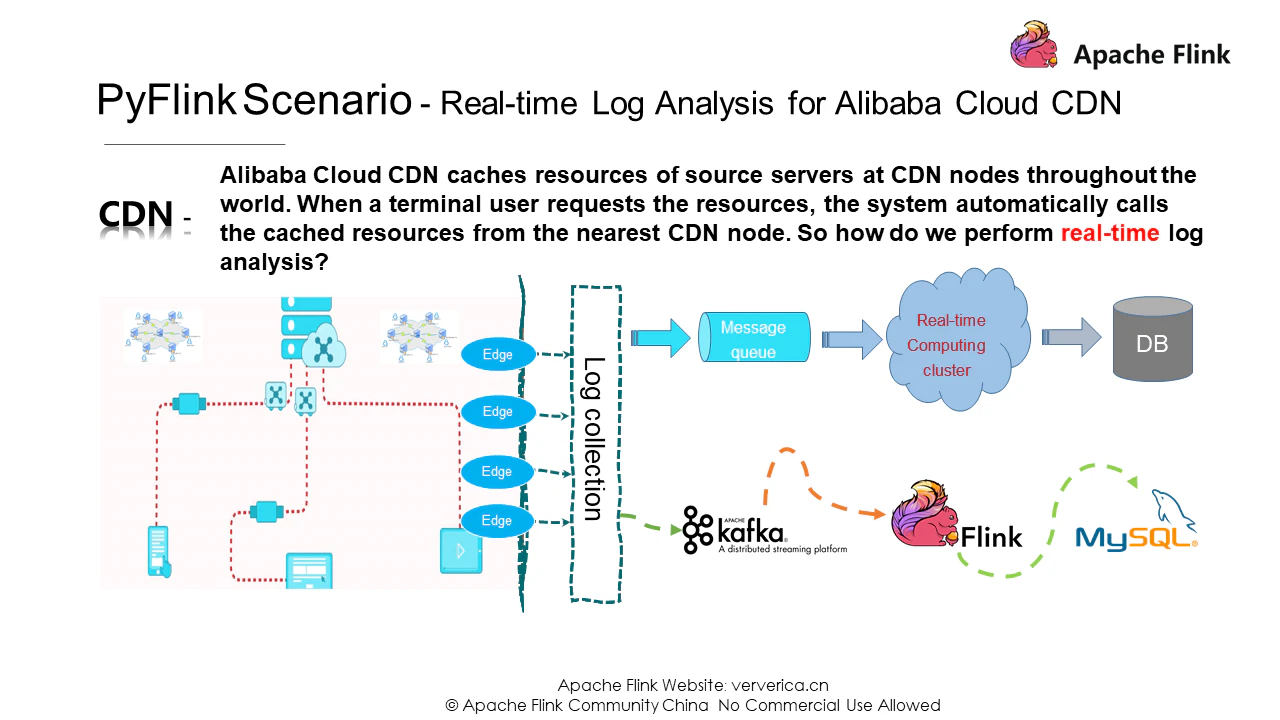
必要条件
便宜上、実際の業務統計上の要件を簡略化しております。この例では、ページビュー、ダウンロード、ダウンロード速度の統計を地域別に収集しています。データ形式としては、コアフィールドのみを選択しています。例えば、uuidは一意のログID、client_ipはアクセス元、request_timeはリソースのダウンロード時間、response_sizeはリソースのデータサイズを示します。ここでは、地域別の統計を収集する必要があるにもかかわらず、元のログには地域フィールドが含まれていません。そこで、各データポイントの領域をclient_ipに応じて問い合わせるためのPython UDFを定義する必要があります。ユーザー定義関数の定義方法を分析してみましょう。
ユーザー定義機能定義
ここでは、ユーザ定義関数であるip_to_province()の名前関数が定義されています。入力はIPアドレス、出力は地域名の文字列です。ここでは、入力型と出力型の両方が文字列として定義されています。ここでのクエリサービスはデモ用です。本番環境では、信頼性の高いリージョンクエリサービスに置き換える必要があります。
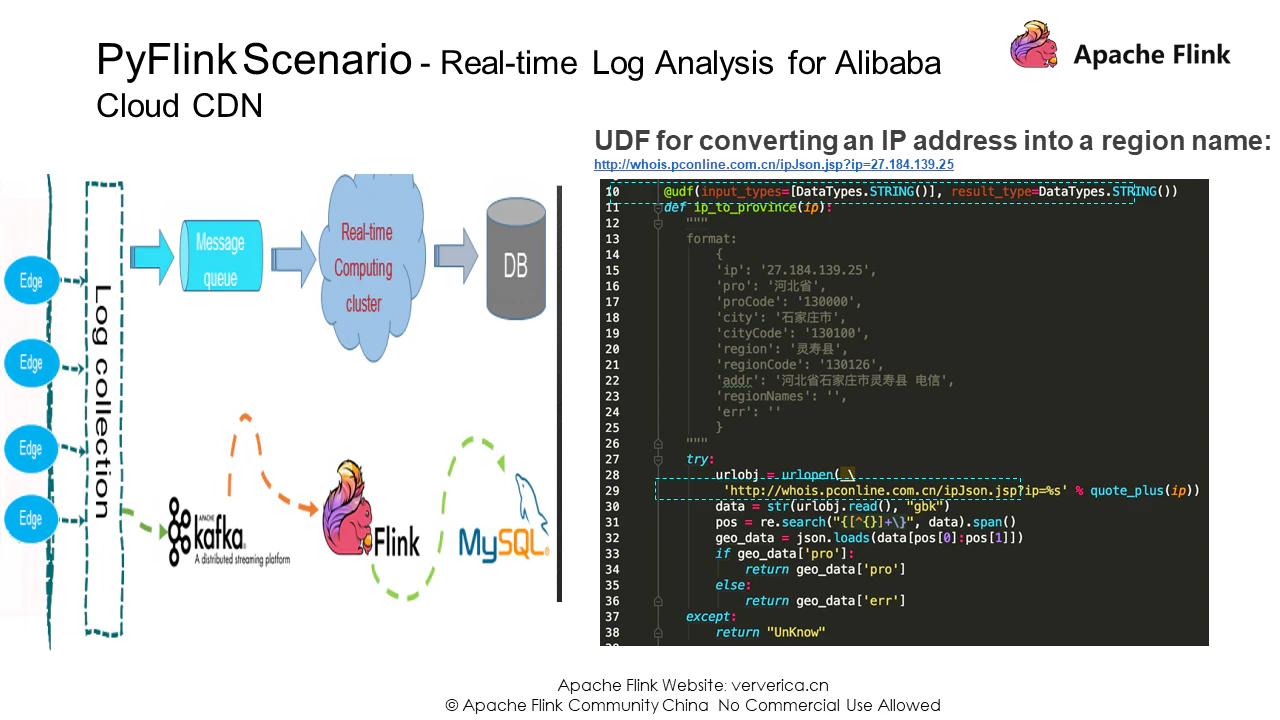
import re
import json
from pyFlink.table import DataTypes
from pyFlink.table.udf import udf
from urllib.parse import quote_plus
from urllib.request import urlopen
@udf(input_types=[DataTypes.STRING()], result_type=DataTypes.STRING())
def ip_to_province(ip):
"""
format:
{
'ip': '27.184.139.25',
'pro': '河北省',
'proCode': '130000',
'city': '石家庄市',
'cityCode': '130100',
'region': '灵寿县',
'regionCode': '130126',
'addr': '河北省石家庄市灵寿县 电信',
'regionNames': '',
'err': ''
}
"""
try:
urlobj = urlopen( \
'http://whois.pconline.com.cn/ipJson.jsp?ip=%s' % quote_plus(ip))
data = str(urlobj.read(), "gbk")
pos = re.search("{[^{}]+\}", data).span()
geo_data = json.loads(data[pos[0]:pos[1]])
if geo_data['pro']:
return geo_data['pro']
else:
return geo_data['err']
except:
return "UnKnow"
コネクタの定義
ここまでで、要件を分析し、ユーザー定義機能を定義してきましたので、次はジョブ開発を進めていきましょう。一般的なジョブ構造では、Kafkaデータを読み込むためのソースコネクタと、演算結果をMySQLデータベースに保存するためのシンクコネクタを定義する必要があります。最後に、統計的なロジックを書くことも必要です。
PyFlink は SQL DDL ステートメントもサポートしており、シンプルな DDL ステートメントを使ってソースコネクタを定義することができます。必ず connector.type を Kafka に設定してください。また、DDL ステートメントを使用して Sink コネクタを定義し、 connector.type を jdbc に設定することもできます。ご覧のように、コネクタの定義のロジックは非常にシンプルです。次に、統計学の核となるロジックを見てみましょう。
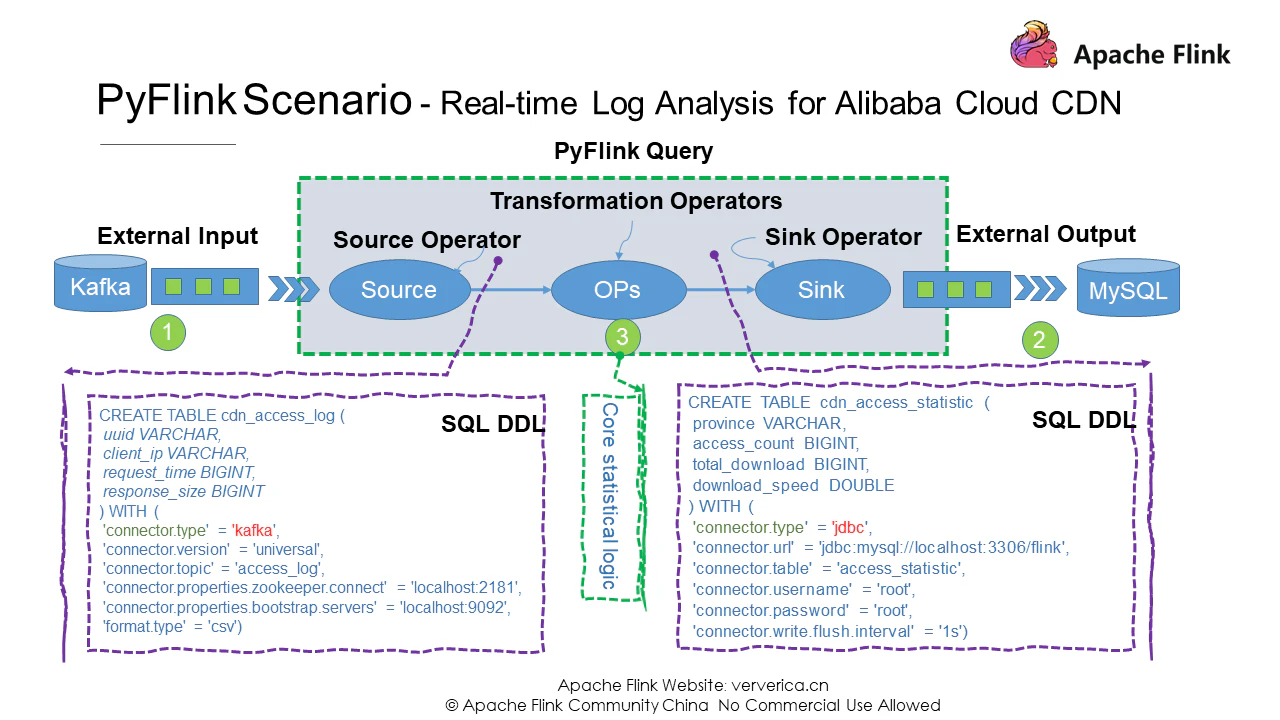
kafka_source_ddl = """
CREATE TABLE cdn_access_log (
uuid VARCHAR,
client_ip VARCHAR,
request_time BIGINT,
response_size BIGINT,
uri VARCHAR
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'access_log',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'format.type' = 'csv',
'format.ignore-parse-errors' = 'true'
)
"""
mysql_sink_ddl = """
CREATE TABLE cdn_access_statistic (
province VARCHAR,
access_count BIGINT,
total_download BIGINT,
download_speed DOUBLE
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/Flink',
'connector.table' = 'access_statistic',
'connector.username' = 'root',
'connector.password' = 'root',
'connector.write.flush.interval' = '1s'
)
"""
コア統計論理学
この部分では、まずデータソースからデータを読み込んでから、ip_to_province(ip)を使ってclient_ipを特定の地域に変換する必要があります。次に、地域別のページビュー、ダウンロード、ダウンロード速度の統計を収集します。最後に、統計結果を結果テーブルに格納します。この統計ロジックでは、Pythonのユーザー定義関数だけでなく、Flinkに組み込まれた2つのJava AGG関数であるsumとcountを使用しています。
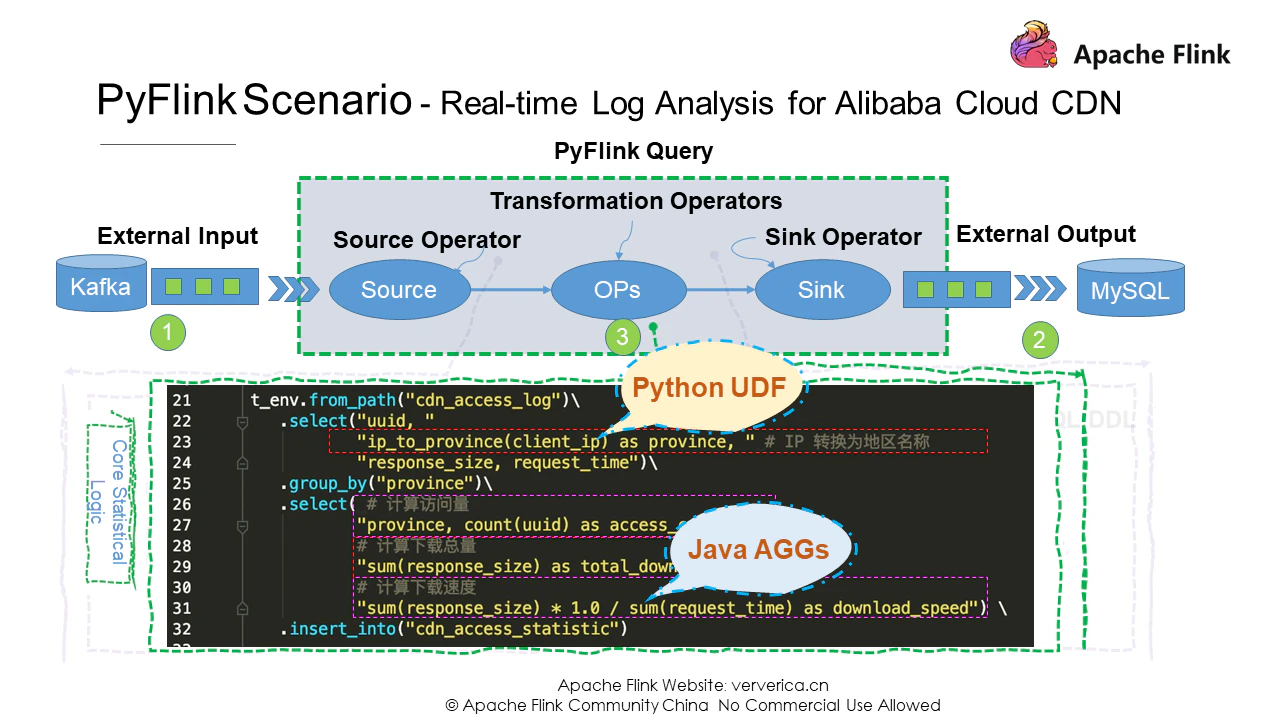
# 核心的统计逻辑
t_env.from_path("cdn_access_log")\
.select("uuid, "
"ip_to_province(client_ip) as province, " # IP 转换为地区名称
"response_size, request_time")\
.group_by("province")\
.select( # 计算访问量
"province, count(uuid) as access_count, "
# 计算下载总量
"sum(response_size) as total_download, "
# 计算下载速度
"sum(response_size) * 1.0 / sum(request_time) as download_speed") \
.insert_into("cdn_access_statistic")
リアルタイムログ解析のための完全なコード
では、もう一度コードを確認してみましょう。まず、コアの依存関係をインポートし、次にENVを作成し、最後にプランナーを設定する必要があります。現在、FlinkはFlinkプランナーとBlinkプランナーをサポートしています。ブリンクプランナーの利用をおすすめします。
次に、DDL文を実行して、先ほど定義したKafkaのソーステーブルとMySQLの結果テーブルを登録します。3つ目は、PythonのUDFを登録します。APIリクエストでUDFの他の依存ファイルを指定し、ジョブと一緒にクラスタに送信することができることに注意してください。最後に、コアとなる統計ロジックを書き、実行者を呼び出してジョブを投入します。ここまでで、アリババクラウドCDNのリアルタイムログ解析ジョブを作成しました。では、実際の統計結果を確認してみましょう。
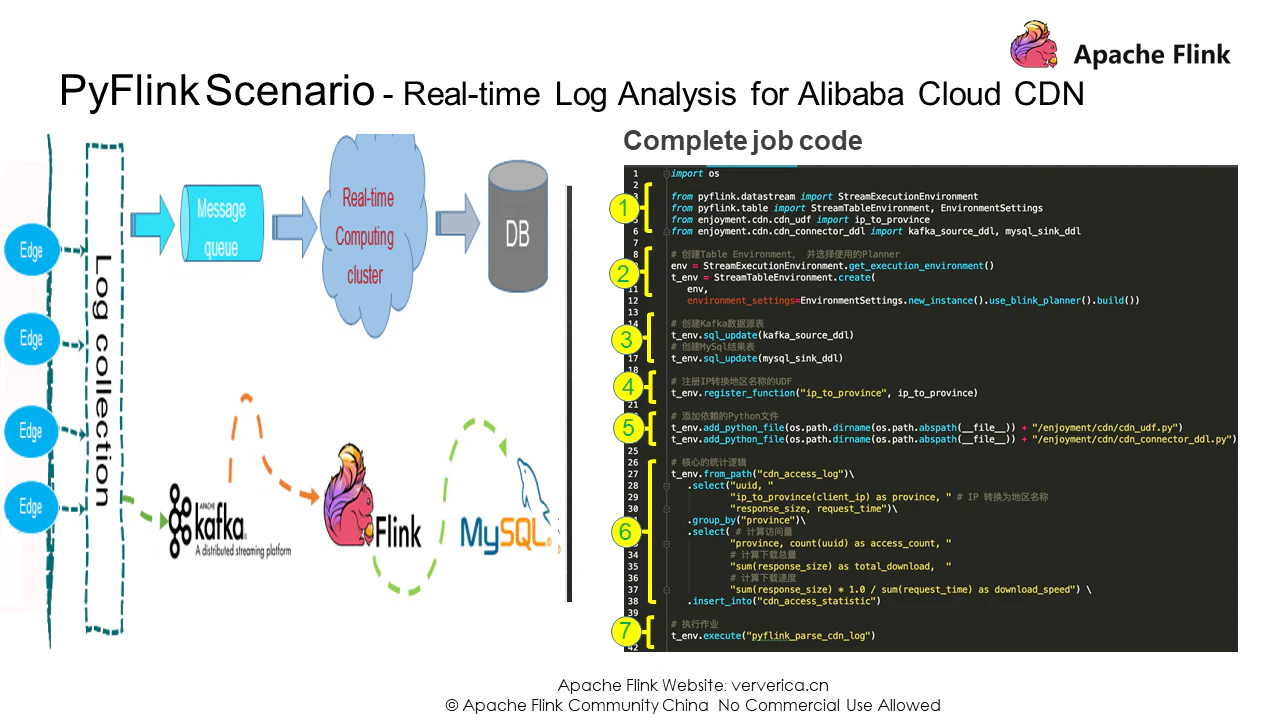
import os
from pyFlink.datastream import StreamExecutionEnvironment
from pyFlink.table import StreamTableEnvironment, EnvironmentSettings
from enjoyment.cdn.cdn_udf import ip_to_province
from enjoyment.cdn.cdn_connector_ddl import kafka_source_ddl, mysql_sink_ddl
# 创建Table Environment, 并选择使用的Planner
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())
# 创建Kafka数据源表
t_env.sql_update(kafka_source_ddl)
# 创建MySql结果表
t_env.sql_update(mysql_sink_ddl)
# 注册IP转换地区名称的UDF
t_env.register_function("ip_to_province", ip_to_province)
# 添加依赖的Python文件
t_env.add_Python_file(
os.path.dirname(os.path.abspath(__file__)) + "/enjoyment/cdn/cdn_udf.py")
t_env.add_Python_file(os.path.dirname(
os.path.abspath(__file__)) + "/enjoyment/cdn/cdn_connector_ddl.py")
# 核心的统计逻辑
t_env.from_path("cdn_access_log")\
.select("uuid, "
"ip_to_province(client_ip) as province, " # IP 转换为地区名称
"response_size, request_time")\
.group_by("province")\
.select( # 计算访问量
"province, count(uuid) as access_count, "
# 计算下载总量
"sum(response_size) as total_download, "
# 计算下载速度
"sum(response_size) * 1.0 / sum(request_time) as download_speed") \
.insert_into("cdn_access_statistic")
# 执行作业
t_env.execute("pyFlink_parse_cdn_log")
リアルタイムログ解析の出力結果
モックデータをCDNログデータとしてKafkaに送信しました。下の図の右側には、ページビュー、ダウンロード、ダウンロード速度の統計が地域別にリアルタイムで収集されています。
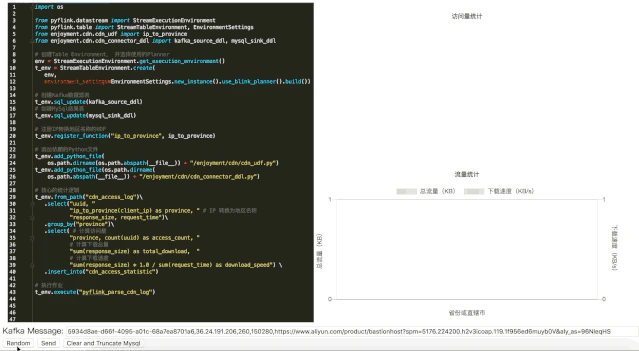
解析結果参照https://yqintl.alicdn.com/e05da15f039d8331896ee1e7f294585416809ad9.gif
PyFlinkの今後の展望は?
一般的に、PyFlinkを使ったビジネス開発は簡単です。基礎となる実装を理解しなくても、SQLやテーブルAPIを介してビジネスロジックを簡単に記述することができます。PyFlinkの全体的な見通しを見てみましょう。
目的に応じたロードマップ
PyFlinkの開発は、Flinkの機能をPythonユーザーが利用できるようにすることと、Pythonの関数をFlinkに統合することを目標にしてきました。以下に示すPyFlinkロードマップによると、まず、PyVMとJVMの間で通信を確立した。そして、Flink 1.9では、既存のFlink Table APIの機能をPythonユーザーに開放したPython Table APIを提供しました。Flink 1.10では、Apache Beamの統合、Pythonのユーザー定義関数実行環境の設定、Pythonの他クラスライブラリへの依存関係の管理、Pythonのユーザー定義関数をサポートするためのユーザー定義関数APIの定義などを行い、Pythonの関数をFlinkに統合するための準備を行いました。
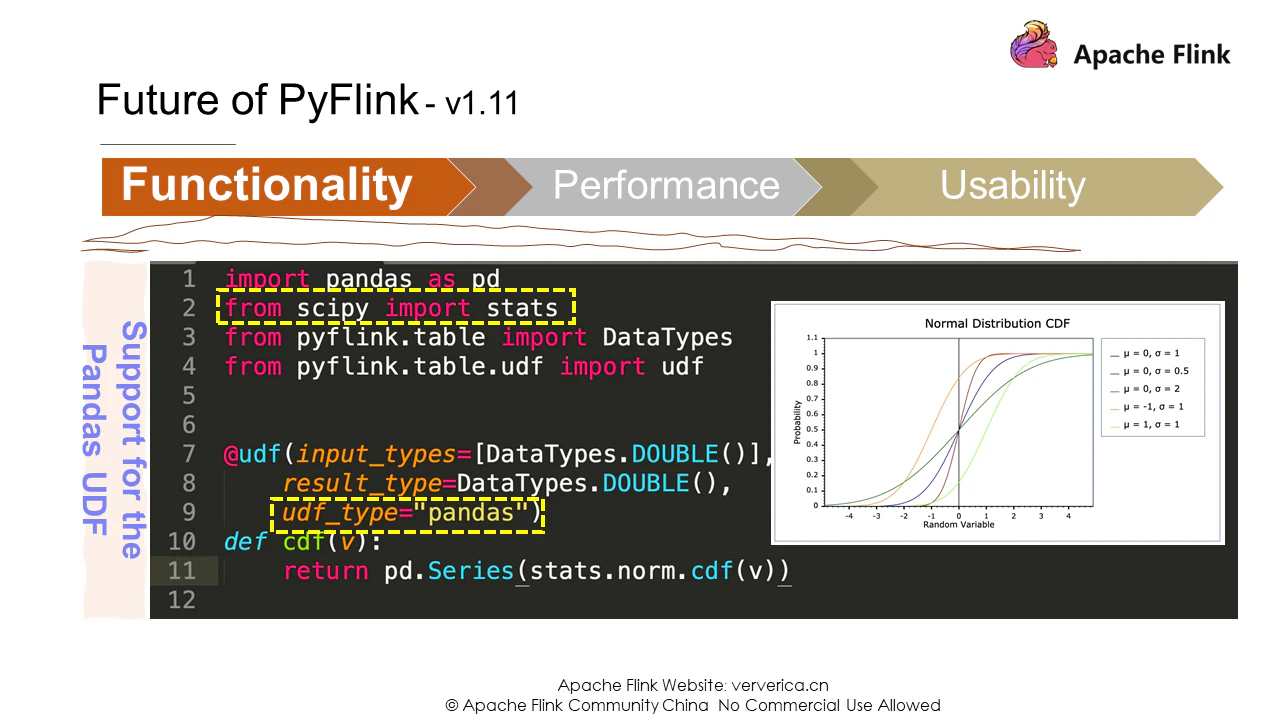
分散Pythonの機能を拡張するために、PyFlinkではPandas SeriesやDataFrameをサポートしており、Pandasのユーザー定義関数をPyFlinkで直接利用できるようになっています。また、将来的にはSQLクライアント上でPythonのユーザー定義関数を有効化し、PyFlinkをより使いやすくする予定です。また、PythonユーザーがPyFlinkを機械学習で利用できるようにするためのPython MLパイプラインAPIも提供する。Pythonのユーザー定義機能の実行に関する監視は、実際の本番や業務では非常に重要です。そのため、PyFlinkはPythonのユーザー定義関数のメトリック管理をさらに提供します。これらの機能はFlink 1.11に組み込まれます。
しかし、これらはPyFlinkの今後の開発計画の一部に過ぎません。PyFlinkのパフォーマンスの最適化、グラフコンピューティングAPIの提供、Pandas on FlinkのPandasネイティブAPIのサポートなど、今後もやるべきことはたくさんあります。Flinkの既存機能を継続的にPythonユーザーが利用できるようにし、Pythonの強力な機能をFlinkに統合することで、Pythonエコシステムの拡大という当初の目標を達成していきます。
画像参照
https://yqintl.alicdn.com/f85ba5bd5d24a01558e751bcdc8887b3f5d565ca.gif
PyFlink 1.11 プレビュー
バージョンアップしたFlink 1.11でのPyFlinkのポイントを簡単に見てみましょう。
機能性
では、Flink 1.11 をベースにした PyFlink のコア機能を詳しく見ていきましょう。PyFlinkの機能性、性能、使いやすさに力を入れており、Pandasのユーザー定義関数のサポートをPyFlink 1.11で提供する予定です。このように、Pandasの実用的なクラスライブラリの機能は、累積分布関数のようにPyFlinkで直接使うことができます。
また、PyFlinkにML Pipeline APIを統合して、機械学習シナリオでのビジネスニーズに対応します。ここでは、PyFlinkを使ってKMeansの手法を実装した例を紹介します。

パフォーマンス
また、PyFlinkのパフォーマンス向上にも力を入れていきたいと思います。Codegen、CPython、最適化シリアライズ、デシリアライズによりPython UDFの実行性能の向上を試みます。予備的な比較では、PyFlink 1.11の性能がPyFlink 1.10と比較して約15倍になることがわかります。

使いやすさ
PyFlinkをより使いやすくするために、Pythonのユーザー定義関数をSQL DDLやSQLクライアントでサポートします。これにより、様々なチャンネルでPyFlinkを利用できるようになります。

PyFlinkのロードマップ、ミッション、ビジョン
すでにPyFlinkを定義し、その意義、APIアーキテクチャ、ユーザー定義関数アーキテクチャ、そしてアーキテクチャの背後にあるトレードオフとそのメリットについて説明してきました。Flink 1.11でのCDNのケース、PyFlinkのロードマップ、PyFlinkのポイントなどを見てきました。しかし、それ以外に何が必要なのか?
最後にPyFlinkの未来を見てみましょう。Flinkの機能をPythonユーザーが利用できるようにし、Flink上でPythonの関数を動かすという使命に駆られて、PyFlinkはどのような展望を持っているのでしょうか。ご存知かもしれませんが、PyFlink は Apache Flink の一部であり、ランタイムと API レイヤーを含んでいます。
この2つのレイヤーでPyFlinkはどのように発展していくのでしょうか?ランタイム的には、JVMとPyVM間の通信のためのgRPC一般サービス(Control, Data, Stateなど)をPyFlinkが構築します。このフレームワークでは、Java Pythonのユーザー定義関数の演算子を抽象化し、Pythonの実行コンテナを構築してPythonの実行を複数の方法でサポートします。例えば、PyFlinkはプロセスとして、Dockerコンテナ内で、さらには外部のサービスクラスタでも実行することができます。特に、外部サービスクラスタで実行している場合は、ソケットという形で無制限の拡張機能が有効になります。これはすべて、その後のPythonの統合において重要な役割を果たしています。
APIに関しては、PythonベースのAPIをFlinkで利用できるようにしてミッションを達成していきます。これもPy4J VM通信フレームワークに依存しています。PyFlinkでは、FlinkのJava API(Python Table API、UDX、ML Pipeline、DataStream、CEP、Gelly、State APIなど)や、Pythonユーザーに最も人気のあるPandas APIなど、徐々に多くのAPIをサポートしていく予定です。これらのAPIをベースに、PyFlinkは今後も他のエコシステムと統合し、開発を容易にするために、例えば、Notebook、Zeppelin、Jupyter、Alink、Alibabaのオープンソース版Flinkなどと連携していきます。現在のところ、PyAlinkの機能は完全に組み込まれています。PyFlinkは、よく知られているTensorFlowのような既存のAIシステムプラットフォームとも統合される予定です。
そのためには、ミッションに基づいた力がPyFlinkを存続させていくことがわかります。繰り返しになりますが、PyFlinkのミッションは、Flinkの機能をPythonユーザーが利用できるようにし、Flink上でPythonの解析や計算機能を実行することです。現在、PyFlinkのコアコミッターは、このミッションを掲げてコミュニティで頑張っています。

画像参照
https://yqintl.alicdn.com/908ea3ff2a2fc93d3fe2797bbe9c302ad83c0581.gif
PyFlink のコアコミッター
最後に、PyFlink のコアコミッターを紹介します。
- Fu Dian: Flink と他の 2 つのトップレベルの Apache プロジェクトのコミッター。Fu は PyFlink に多大な貢献をしています。
- Huang Xingbo: 専用の PyFlink UDF パフォーマンスオプティマイザ。Huang氏は、かつてアリババのセキュリティアルゴリズムチャレンジ大会で優勝し、AIやミドルウェアのパフォーマンス大会で数々の好成績を残しています。
- Cheng Hequn: Flink コミュニティの有名なコミッター。チェンは何度も非常に有益な情報を共有してきました。多くのユーザーはまだ彼のFlink Knowledge Mapを覚えているかもしれません。
- Zhong Wei: PyFlink のユーザー定義関数の依存性管理と使いやすさの最適化に注力してきたコミッター。中さんは多くのコードを投稿しています。
最後のコミッターは私です。私の紹介は、この投稿の最後にあります。PyFlink について質問がある場合は、遠慮なく私たちのコミッターチームに連絡してください。

一般的な問題については、Flinkのユーザーリストに登録されている方にメールを送信して共有することをお勧めします。緊急の問題が発生した場合は、コミッターにメールを送ることをお勧めします。しかし、効果的な蓄積と共有のためには、Stackoverflowで質問をすることができます。ご質問を上げる前に、まずはご質問の内容を検索して、回答されているかどうかを確認してみてください。そうでない場合は、質問内容を明確に記述してください。最後に、質問にPyFlinkタグを追加することを忘れないでください。

概要
今回の記事では、PyFlinkを深く分析してみました。PyFlink APIアーキテクチャでは、PyVMとJVM間の通信にPy4Jを使用し、PythonとJavaのAPI間のセマンティックな整合性を保ちながら設計しています。Pythonユーザー定義関数アーキテクチャでは、Apache BeamのPortability Frameworkが統合されており、効率的で安定したPythonユーザー定義関数を提供しています。また、建築の背景にある思いや技術的なトレードオフ、既存建築のメリットなども解釈されています。
続いて、PyFlinkに適用可能なビジネスシナリオを紹介し、Alibaba Cloud CDNのリアルタイムログ解析を例に、PyFlinkが実際にどのように機能するかを紹介しました。
その後、PyFlinkのロードマップを見て、Flink 1.11のPyFlinkのポイントをプレビューしました。PyFlink 1.11では、PyFlink 1.10と比較して15倍以上の性能向上が期待できます。最後に、PyFlinkのミッションである「PyFlinkをPythonユーザが利用できるようにすること」「Pythonの解析・計算機能をFlink上で実行すること」を分析しました。
著者について
この記事の筆者である孫金城は、2011年にアリババに入社した。孫氏は、アリババでの9年間の勤務で、アリババグループの行動ログ管理システム、アリラン、クラウドトランスコードシステム、文書変換システムなど、多くの社内基幹システムの開発をリードしてきました。彼は2016年初頭にApache Flinkコミュニティを知った。最初は開発者としてまちづくりに参加。その後、特定のモジュールの開発を主導し、Apache Flink Python API(PyFlink)の構築を担当。現在はApache FlinkとALC(北京)のPMCメンバーであり、Apache Flink、Apache Beam、Apache IoTDBのコミッターを務めている。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ