このチュートリアルでは、Apache Flink アプリケーションをゼロから数分で構築する方法を簡単に説明します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
開発環境の準備
Apache FlinkはLinux、Max OS X、Windowsで動作し、互換性があります。Flinkアプリケーションを開発するには、コンピュータ上でJavaバージョン8.0以降かMaven環境のいずれかを実行する必要があります。Java環境を使用している場合は、$java -versionコマンドを実行すると、使用しているバージョン情報が以下のように出力されます。
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
Maven環境を使用している場合、$ mvn -versionコマンドを実行すると、以下のようなバージョン情報が出力されます。
Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00)
Maven home: /Users/wuchong/dev/maven
Java version: 1.8.0_65, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_65.jdk/Contents/Home/jre
Default locale: zh_CN, platform encoding: UTF-8
OS name: "mac os x", version: "10.13.6", arch: "x86_64", family: "mac"
さらに、FlinkアプリケーションのIDEとしてIntelliJ IDEA(このチュートリアルではコミュニティフリー版で十分です)を使用することをお勧めします。Eclipseもこの目的で動作しますが、Eclipseは過去にScalaとJavaのハイブリッドプロジェクトに問題があったため、Eclipseを選択することはお勧めしません。
Mavenプロジェクトを作成する
このセクションの手順に従って、Flinkプロジェクトを作成し、IntelliJ IDEAにインポートすることができます。Flink Maven Archetypeを使用して、プロジェクト構造といくつかの初期デフォルトの依存関係を作成します。作業ディレクトリで、mvn archetype:generateコマンドを実行してプロジェクトを作成します。
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.6.1 \
-DgroupId=my-flink-project \
-DartifactId=my-flink-project \
-Dversion=0.1 \
-Dpackage=myflink \
-DinteractiveMode=false
上記の groupId、artifactId、および package は、任意のパスに編集することができます。上記のパラメータを使用して、Mavenは以下のようなプロジェクト構造を自動的に作成します。
$ tree my-flink-project
my-flink-project
├── pom.xml
└── src
└── main
├── java
│ └── myflink
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties
pom.xml ファイルには、必要な Flink の依存関係がすでに含まれており、いくつかのサンプルプログラムフレームワークが src/main/java に用意されています。
Flink プログラムをコンパイル
では、以下の手順に従って、独自のFlinkプログラムを作成してください。これを行うには、IntelliJ IDEAを起動し、Import Projectを選択し、my-link-projectのルートディレクトリの下にあるpom.xmlを選択します。その後、指示された通りにプロジェクトをインポートします。
src/main/java/myflinkの下にSocketWindowWordCount.javaファイルを作成します。
package myflink;
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
}
}
今のところ、このプログラムは基本的なフレームワークだけなので、一歩一歩コードを埋めていきます。なお、インポート文はIDEが自動的に追加してくれるので、以下では書かないことに注意してください。このセクションの最後に、完成したコードを表示します。以下のステップをスキップしたい場合は、最終的な完全なコードをエディタに直接貼り付けます。
Flinkプログラムの最初のステップはStreamExecutionEnvironmentの作成です。これは、パラメータの設定やデータソースの作成、タスクの投入などに使えるエントリークラスです。それでは、メイン関数に追加してみましょう。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
次に、ローカルポート 9000 のソケットからデータを読み込むデータソースを作成します。
DataStream text = env.socketTextStream("localhost", 9000, "\n");
これにより、文字列型のDataStreamが作成されます。DataStreamはFlinkのストリーム処理のコアAPIです。多くの一般的な操作(フィルタリング、変換、集約、ウィンドウ、アソシエーションなど)を定義しています。この例では、特定の時間ウィンドウ、例えば5秒のウィンドウ内での各単語の出現回数に興味があります。この目的のために、文字列データは、最初に単語とその出現回数(Tuple2<String, Integer>で表される)に解析され、最初のフィールドが単語、2番目のフィールドが単語の出現回数となります。発生回数の初期値は1に設定されています。1つのデータ行には複数の単語が存在する可能性があるため、解析を行うためにflatmapが実装されています。
DataStream> wordCounts = text
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) {
for (String word : value.split("\\s")) {
out.collect(Tuple2.of(word, 1));
}
}
});
次に、ワードフィールド(つまりインデックスフィールド0)に基づいてデータストリームをグループ化します。ここでは、keyBy(int index)メソッドを使用して、ワードをキーとするTuple2<String, Integer>データストリームを取得します。そして、ストリーム上で任意のウィンドウを指定し、ウィンドウ内のデータに基づいて結果を計算します。この例では、5 秒ごとに単語の出現を集約し、各ウィンドウはゼロからカウントされます。
DataStream> windowCounts = wordCounts
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
2 番目の .timeWindow() は、5 秒間のタンブル・ウィンドウを指定します。3番目の呼び出しは、各キーと各ウィンドウの合計集計関数を指定します。この例では、これは occurrences フィールド (つまり、インデックス・フィールド 1) によって追加されます。結果として得られるデータ・ストリームは、各単語の出現回数を5秒ごとに出力します。
最後に、データストリームをコンソールに出力し、実行を開始します。
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
実際のFlinkジョブを開始するには、最後のenv.execute呼び出しが必要です。すべてのOperator操作(ソース作成、集約、印刷など)は、内部のOperator操作のグラフを構築するだけです。execute()が呼び出されたときのみ、それらは実行のためにクラスタまたはローカルコンピュータに送信されます。
package myflink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
// Create the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Obtain the input data by connecting to the socket. Here you want to connect to the local 9000 port. If 9000 port is not available, you'll need to change the port.
DataStream text = env.socketTextStream("localhost", 9000, "\n");
// Parse the data, group by word, and perform the window and aggregation operations.
DataStream> windowCounts = text
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) {
for (String word : value.split("\\s")) {
out.collect(Tuple2.of(word, 1));
}
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
// Print the results to the console. Note that here single-threaded printed is used, rather than multi-threading.
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
}
プログラムの実行
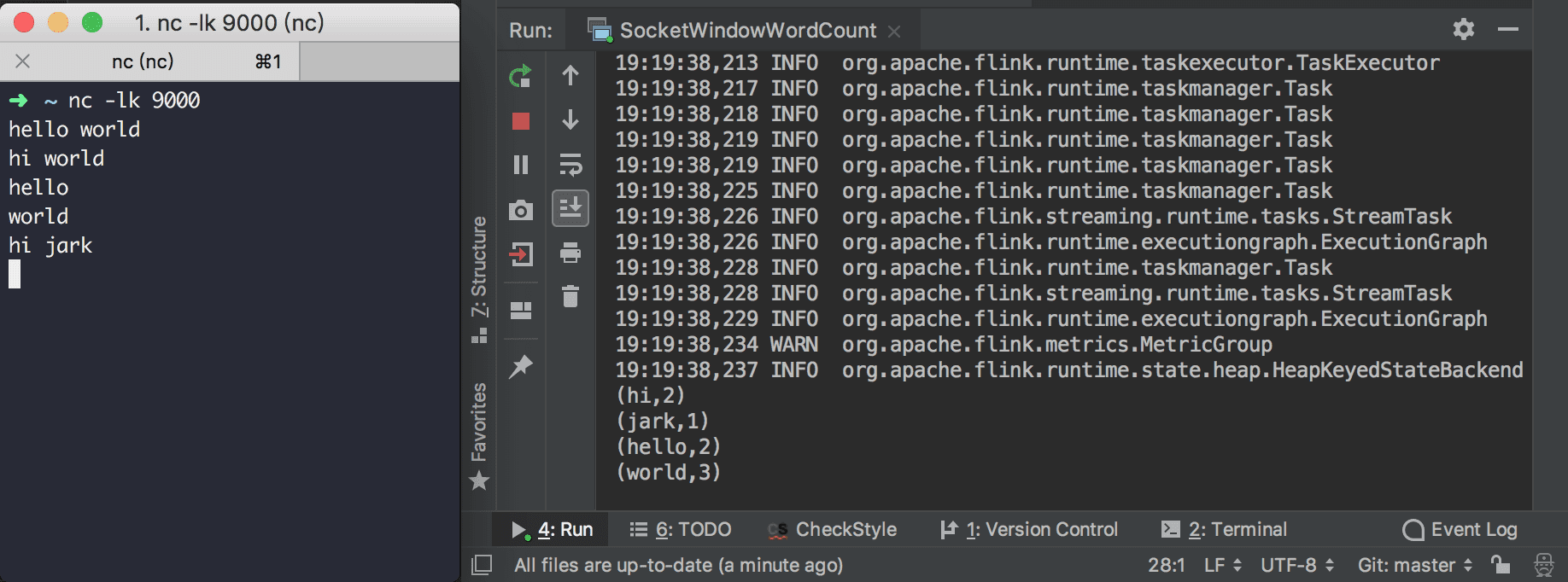
サンプルプログラムを実行するには、端末上でNetCatを起動して入力ストリームを取得します。
nc -lk 9000
Windowsの場合は、NMAPを介してNcatをインストールし、実行することができます。
ncat -lk 9000
そして、SocketWindowWordCountのメインメソッドを直接実行します。
NetCatのコンソールに単語を入力するだけで、SocketWindowWordCountの出力コンソールに各単語の出現頻度の統計が表示されます。1以上のカウントを見たい場合は、5秒以内に同じ単語を繰り返し入力してください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ