この記事では、アリババがCI/CDパイプラインを構築するためのツールや手順を紹介しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
著:華翔
本記事は「Kubernetes & Cloud Native Meetup - Guangzhou」での華翔氏の講演を元にしています。アリババがCI/CDパイプラインを構築するためのツールやステップを紹介しています。
皆さんこんにちは、アリババクラウドコンテナサービスチームのHua Xiangです。まず、Kubernetesとは何かを簡単に説明して理解を深めてもらいたいと思います。Kubernetesは、本番で利用できるコンテナオーケストレーションシステムです。Kubernetesは、すべてのNodeリソースをクラスタ内のリソースプールとし、そのスケジューリング単位をPodとしています。Podは複数のコンテナを持つことができます。ちょうど人が左手にECSリソースやコンピューティングリソースを持ち、右手にコンテナを持ち、その2つをマッチングさせているようなもので、このように人はコンテナオーケストレーションシステムの役割を果たしているのです。
しかし、最近はクラウドネイティブという概念がかなり頻繁に出てきて、クラウドネイティブとKubernetesの関連性について混乱している人が多いようです。では、どのようにしてアプリケーションがクラウドネイティブアプリケーションであるかどうかを判断すればよいのでしょうか?私の考えでは、3つの基準があります。
第一に、アプリケーションは、リソースをプールにすることができます。
第二に、アプリケーションは、プールのネットワークに素早くアクセスすることができます。Kubernetesは、独自の独立したネットワークの層を持っており、私はアクセスしたいサービス名を指定するだけで、つまり、それは迅速にサービスメッシュを介して様々なサービスの発見機能にアクセスすることができます。
第三に、アプリケーションにはフェイルオーバー機能があります。プールにホストが含まれていたり、ノードがダウンしてアプリケーション全体が利用できなくなった場合、それは間違いなくクラウドネイティブアプリケーションではありません。
以上の3点から、Kubernetesが非常にうまく機能していることがわかります。まず、リソースプールの概念を見てみましょう。大規模なKubernetesクラスタがリソースプールです。もはやアプリケーションのホストを気にする必要はありません。デプロイしたyamlファイルをKubernetesに公開するだけです。自動的にこれらのスケジュールを作成してくれるので、アプリケーション全体のネットワークに素早くアクセスすることができます。また、フェイルオーバーも自動で行われます。次に、KubernetesをベースにしたエラスティックCI/CDシステムの実装方法を紹介します。
CI/CD Status Quo
まず、CI/CDの現状を見てみましょう。CI/CDの概念は古くから提唱されてきました。しかし、技術の進化と新しいツールの継続的な導入により、CI/CDの全体のプロセスや実装方法は徐々に豊かになってきています。当初は、コードを提出し、イベントをトリガーにして、CI/CDシステム上で自動ビルドを行うのが一般的ですが、現在では、CI/CDを利用して、コードを提出し、イベントをトリガーにして、自動ビルドを行うようになっています。
下図はCI/CDの現状を示しています。
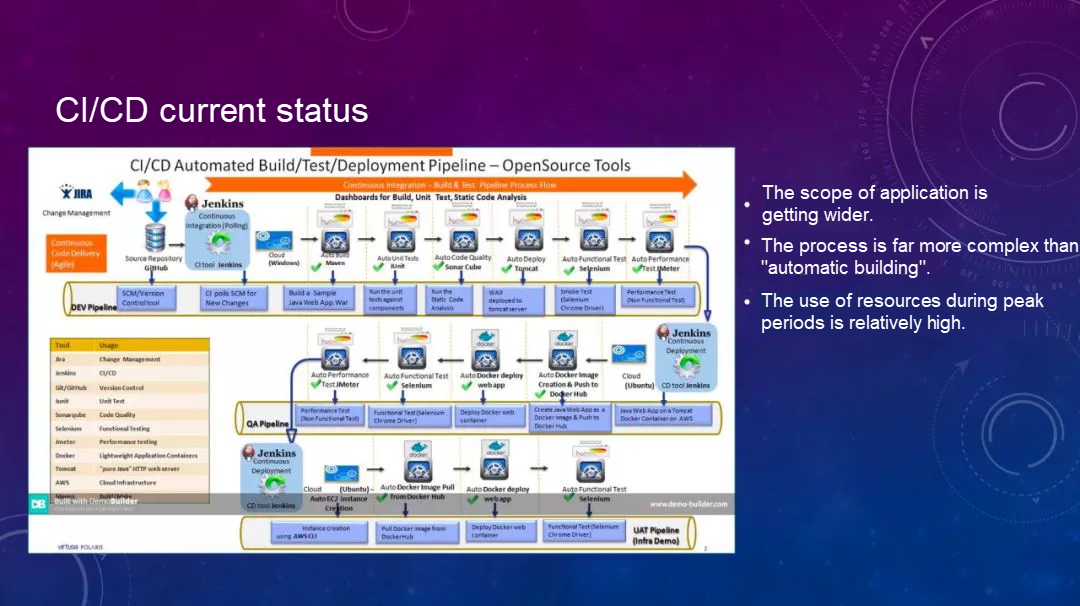
これには多くのプロセスが含まれています。パイプラインは、コード提出後にイベントをトリガーすることから始まります。そして、CI/CDシステムはMavenを介してレイヤー「Build」を構築し、ユニットテストを行い、コード仕様のスキャンを行い、サービスをデプロイします。次に、UIのエンドツーエンドテストを行い、UIのテストを自動で行う。
そして、開発環境とテスト環境のレベルでしか行われないストレステスト(パフォーマンスのストレステスト)を実行します。その後、QA環境、最終的にはUAT環境へと進んでいきます。このパイプラインは非常に長いプロセスです。CI/CDが広く使われています。コードの書き出しとコードリポジトリへの提出は、ITインフラ全体の出発点と取ることができます。ここからは、すべてのステップをCI/CDの範囲に含めることができます。しかし、その管理範囲が広がるにつれて、全体のプロセスが複雑化し、リソースを占有することにもなります。
C++を知っている人なら、C++がかつては非常に長いビルド期間を持つ有名な言語であったことを知っているかもしれません。C言語の著者でもあるGo言語の著者の一人は、コンパイルに時間のかかるコードを書く代わりに、単純にGo言語を書くことについて話していました。したがって、Go言語の大きな利点の1つは、コンパイル時間が非常に短いことです。確かにGoのコンパイル時間は非常に短いです。
I5ノートPCを使ってKubernetesのソースコードをコンパイルして完全にビルドしてみました。コンパイルには45分ほどかかりました。そのため、コンパイルプロセスが大幅に最適化されて改善されたとしても、プロジェクトが大規模である限り、その後の一部の自動テストはおろか、ビルドフェーズが長くなってしまいます。さらに、CI/CDプロセスは非常に多くのリソースを消費し、占有します。
CI/CDツールの選択
次に、CI/CDツールの選択と開発について見ていきましょう。まず、選択肢としてはJenkinsが最も定着しています。実際、コンテナ技術が登場する以前は、CI/CDはJenkinsとほぼ同等のものでした。しかし、コンテナ技術が登場してからは、完全にコンテナベースのCI/CDツールであるDroneなど、新しいCI/CDツールも多く登場しています。コンテナとの相性が良く、構築プロセスも完全にコンテナに実装されています。

また、GitLab CIもツールの一つです。これはGitlabのコード管理ツールとの連携を良くするために使われていました。その主な特徴は、Gitlabのコード管理ツールとの連携が良いことです。Jenkins 2.0では、Jenkinsファイルを自動生成できるPipeline as Code機能が導入されています。
Jenkins 1.0では、パイプラインを設定したい場合、Jenkinsにログオンしてプロジェクトを作成し、その中に何らかのシェルを記述する必要がありました。同じような効果は得られるものの、再現性や移行性があまり良くないのが最大の欠点です。しかも、これは当然DevOpsとは切り離されています。例えば、Jenkinsのシステムは一般的にO&M担当者が管理し、開発者がコードを書きます。しかし、そのコードをどのように構築し、どこで公開するかは開発者には全くわかりません。これが開発とO&Mの分離につながっています。しかし、Pipeline as Code方式が導入されてからは、Jenkinsファイルとソースコードを同じリポジトリに置くことができるようになりました。
まず、リリースプロセスをバージョン管理にも組み込むことができ、エラーのトレースが可能になるという大きなメリットがあります。これは大きな変化ですが、実際にユーザーとのやりとりを通して分かったことは、多くのユーザーがJenkinsを2.0にアップグレードしたにもかかわらず、その使い方が完全にバージョン1.0に囚われているということです。Jenkinsファイルの実装方法を使っていないユーザーが多いのです。もう一つのメリットは、コンテナのサポートです。2016年頃はコンテナのサポートが弱く、Jenkinsを実行したり、コンテナ内でビルドしたものをDockerで実行したりするのも面倒でした。
しかし、Doneは優れたコンテナサポートを提供しています。まず、完全にDockerモード、つまりビルド環境もコンテナ内で動作します。Dockerのビルドイメージをビルドして、それがプッシュアウトされると、それもコンテナ内で実行され、権限権限が必要になります。この方法にはいくつかの特別な利点があります。まず、ホストに一時ファイルを残さないことです。例えば、コンテナが破棄されると、ビルドで生成された中間ファイルは完全に削除されます。しかし、Jenkinsを使用している場合、多くの一時ファイルが蓄積され、Jenkinsは時間の経過とともにどんどんスペースを占有していきます。そのため、定期的にこれらのファイルをクリーンアップする必要があり、クリーンアップ中にワンクリックで直接クリアすることができず、非常に面倒です。
そして、プラグインの管理に関してですが、Jenkinsにはプラグインのアップグレードという重大な問題が存在します。まず、Jenkinsにログオンしてから、プラグインのアップグレードを行います。テストのために一時的にJenkinsを起動したり、新しい環境で何らかのデバッグを行いたい場合、新しい環境ができるたびにこれらのプラグインのアップグレードが必要になることがあります。また、Jenkinsで作成した設定をすべて再設定する必要があり、非常に面倒な作業になってしまいます。
しかし、Droneには、プラグインがすべてDockerコンテナであるという大きなメリットがあります。例えばパイプラインでプラグインを使う場合、プラグインのダウンロード先やインストール方法を管理する必要がなく、このプラグインを宣言するだけで済みます。ネットワークがプラグインのコンテナイメージにアクセスできる限り、完全に自動化されているので、非常に便利です。
エコシステムの構築についてですが、Jenkinsの最大のメリットは、プラグインがたくさんある、つまり使いたいものがすべて揃っているということで、基盤がしっかりしていれば、あなたのプラグインは非常に強力なものになります。例えばパイプライン。2.0で利用できるようになっていますが、完全にプラグインで実装されています。しかし、Jenkinsの開発は第二のピークを迎えているようです。Kubernetesへの対応が大幅に増えています。まず、JenkinsXを皮切りに、HarborやHelmなどのKubernetesエコシステム関連のツールが統合されています。これにより、Kubernetesクラスタ上でいくつかのビルドを行ったり、サービスを固めるためのオーケストレーションファイルをHelmに入れたりするのが非常に便利になりました。
さらに、新たに Config as Code というサブプロジェクトが追加され、すべての Jenkins ファイルにいくつかの設定を追加し、コードの形で出力できるようになりました。この改善により、Jenkinsの移行やレプリケーションが容易になりました。
上記のJenkinsの欠点があるにもかかわらず、実際には、最も重要なことはエコシステムの構築であり、Jenkinsはすでにこの面で非常に優れているので、我々は、最終的にはJenkinsを選択します。今日では、後述する弾力性のあるCI/CDシステムの実装のために、Jenkinsはすでに関連するプラグインを提供しています。しかし、Droneコミュニティでは、何人かの人が言及しているものの、まだ何も実現されていません。
CI/CDシステムのビジネスシナリオ
ここでは、CI/CDシステムの業務シナリオを見てみましょう。典型的なシナリオと特徴:まず、開発者向けであることです。

2つ目は、時間的な有効性の要件があることです。コードが書かれて提出された後、このコードのビルドでキューを作り続けるのではなく、すぐにビルドを開始して十分なリソースを持つようにしたいのです。第三に、そのリソースが占める割合が非常に明白だということです。これは、開発者が常にコードを提出できるわけではないからです。1日に数回だけコードを提出する人もいれば、何度もコードを提出する人もいます。
ある人が会社のビルドタスクを反映したカーブを共有しているのを見たことがあります。その会社のコード提出量は、毎日15:00~16:00頃が最も多く、それ以外の時間帯は比較的フラットなカーブになっています。これは、その会社では、プログラマーは15時から16時の間に全員がコードを提出してから他のことを始めていることを示しています。CI/CDリソースの需要が高まる中、クラスターの構築は必須です。これにより、負荷能力が向上し、タスクの待ち時間が短縮されます。しかし、クラスタの欠点としては、マスターが1人しかいないことが挙げられます。しかし、これはプラグインによって改善することもできます。
多くの場合、マスターが一時的に利用できなくても、すぐに復旧できる場合も許容されるので、今日はここでは割愛します。また、CI/CDシステムは様々なビルドシナリオに対応する必要があります。企業によっては、誰もがJavaを使っているとはいえ、1.5、1.6、1.7とバージョンが異なるように、多くの開発環境を利用している場合があります。Javaを使わない場合は、PythonやGo、NodeJSなど、他にも多くの言語が多くのビルド環境で使われている可能性があります。また、コンテナを導入しなければ、これらのビルド環境を再利用することができず、1つのホストをPHPでしか利用できなくなってしまいます。
コンテナはCI/CDシステムに新しい能力、すなわち環境分離の能力を入れることができます。私たちはKubernetesを使ってCI/CDシステムにさらに多くの能力を注入することができますが、その際に競合が発生します。開発者は、CI/CDシステムがコード提出イベントに素早く対応できることを常に願っていますが、企業は無限のリソースを持っているわけではありません。前述したように、毎日15時や16時のピーク時にコードが提出される場合、ビルドタスクの要件を満たすために30台や40台のマシンが必要になる可能性があります。しかし、毎日15:00や16:00に1~2時間ビルドするためだけに、1日30台や40台のマシンを立ち上げるのは無理があります。
KubernetesはJenkinsに新しい機能を注入して、CI/CDシステムの弾力性を実現することができます。期待される目標は何でしょうか?ビルドタスクがあれば、リソースのために新しいマシンを自動的に追加したり、より多くの計算機能を追加したりすることができます。いずれにしても、必要なときには自動的にリソースの拡張を行い、必要でないときにはこれらのリソースを自動的に解放することができます。

これが期待されていることです。そして、Kubernetesはこの機能をJenkinsで実現することができます。コンテナオーケストレーションシステムとして、Kubernetesは、いくつかの新しいインスタンスを素早く生成し、リソースプールとして機能するアイドルマシンに自動的にスケジュールし、リソースプール内のタスクをスケジュールする機能を提供することができます。タスクが完了した後、リカバリー操作を実行することができます。Jenkins MasterもKubernetes上にデプロイされている場合、KubernetesはMasterのフェイルオーバーを実行できます。つまり、システムがこれに耐えられるのであれば、マスターが死んでしまっても、別のマシンに素早くスケジューリングすることもできるので、レスポンスが遅くなることはありません。
Kubernetes-plugin
また、Kubernetes-pluginというプラグインを使って実装されています。このプラグインは、Kubernetesクラスタを直接管理する機能を提供します。プラグインをJenkinsにインストールすると、Jenkinsのビルドタスクをリッスンすることができます。ビルドタスクでは、リソースを待っているときに、プラグインはKubernetesから新しいリソースを申請したり、新しいPodを申請して自動ビルドを実行したりすることができます。ビルドが完了すると自動的にクリーンアップを行います。

以上、その能力について簡単に紹介しました。また、プラグインをインストールした後には、パイプラインの構文にも手を加えています。後ほど例を見てみましょう。しかし、この時点でもまだ実現性はありません。まず、Kubernetesクラスタの計画性に問題が残っています。例えば、クラスタが30ノードあって、その上に本当のMasterをデプロイして、プラグインをインストールするとします。何らかの管理の後、新しいタスクが到着すると、新しいポッドを開始してビルドタスクを完了することがわかります。
実行後、クラスタリソースを占有しないようにPodは自動的に破棄されます。通常の時間帯にこのクラスタ上でビルドタスクを実行しないときは、このクラスタ上で他のタスクを実行することができますが、これにはやはり欠点があります。計画するこのクラスターの規模はどのくらいなのかということです。他のタスクを実行していて、突然いくつかのビルドタスクが来た場合には、リソースの競合が発生する可能性があります。

一般的には、まだいくつかの不完全さが残っています。上述の問題を解決するために、Kubernetesのあまり一般的ではない機能をいくつか利用することができます。この2つの機能は、それぞれAutoscalerとVirtual nodeと呼ばれています。まずはAutoscalerについて見ていきましょう。AutoscalerはKubernetesの正式なコンポーネントです。Kubernetesグループの下で3つの機能がサポートされています。
- ノード数を自動でスケーリングできる「Cluster Autoscaler」
- クラスタのPodの縦方向のリソースをスケーリングできる「Vertical Pod Autoscaler」。Kubernetes自体にはHPAがあります。HPAを使うことで、水平方向のPodのスケーリングとノード数のスケーリングが可能になります。この機能はまだ本番では利用できません。
- Ingress ControllerやDNSなどのKubernetesアドオンのAddon Resizerは、ノード数に応じてリソースの割り当てを調整することができます。
クラスタオートスケーラー
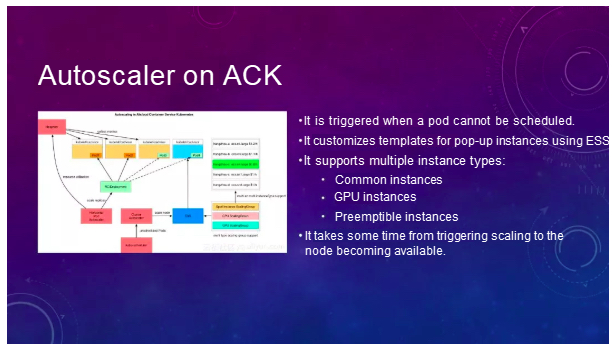
今回は、クラスタ内のノード数を上下にスケーリングするCluster Autoscalerについてお話したいと思います。まず、以下の図はAlibaba Cloud Container ServiceにAutoscalerを実装する方法の1つです。この図を見てみましょう。HPAとAutoscalerを併用した場合のシナリオです。

HPAは監視対象のイベントを監視し、リソース使用量が一定レベルに達したことを検知すると、自動的にワークロードに通知して新しいPodを立ち上げるようにします。このとき、クラスタリソースが不足している可能性があるため、ここでPodが保留されている可能性があります。これがAutoscalerイベントのトリガーとなり、Autoscalerが設定したESSテンプレートに基づいて新しいノードを生成し、自動的にそのノードをクラスタに追加してくれます。ESSテンプレートのカスタマイズ機能を利用しており、コモンインスタンス、GPUインスタンス、プリエンプティブルインスタンスなど複数のノードインスタンスタイプをサポートしています。
仮想ノード
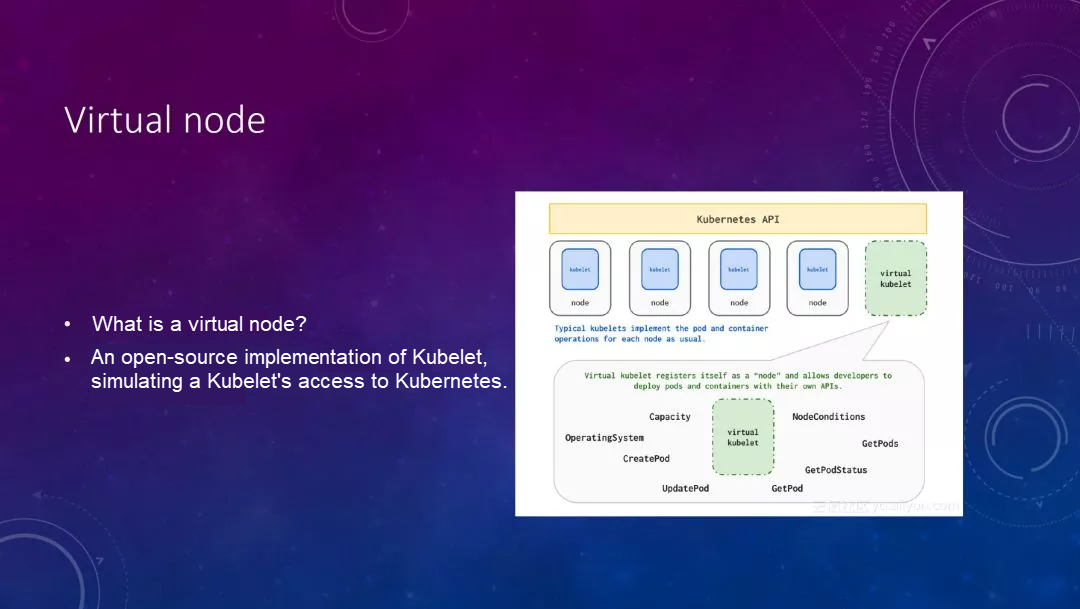
2つ目は、MicrosoftのオープンソースのVirtual Kubeletプロジェクトをベースに実装されたVirtualノードです。これは仮想Kubeletを実装し、Kubernetesクラスタに登録します。理解の便宜上、MySQLプロキシがMySQLサーバを装っていると想像してください。バックエンドは多数のMySQLサーバを管理し、SQLクエリを自動的にルーティングしたり、スプライスしたりすることができるかもしれません。
仮想kubeletは似たようなことをしていて、つまり自分自身をKubernetesのノードとして登録しているのですが、実はバックエンドでパブリッククラウド上の多くのリソースを管理していたり、パブリッククラウド上のいくつかのECI、あるいはこれらのVPCとインターフェースを取っていたりすることがあります。以下に一般的な回路図を示します。
Alibaba Cloud上では、Alibaba Cloud上のECIとインターフェイスしてエラスティックコンテナインスタンスを作り、クラスタにノードを追加する必要がないため、非常に高速に応答します。毎分100 Pods程度のパフォーマンスを実現することができます。また、そのようなリソースの使用量をPod上で宣言することも可能です。レスポンスが非常に速いです。
あとは、この2つの方法を使えば、弾力性のあるCI/CDシステムの クラスタのスケールをあまり早く計画する必要がなく、必要に応じて自動的にスケールさせることができます。上記の操作を全て行った後に、新たにいくつかのしきい値が導入されています: docker-outsid-of-docker と docker in docker です。

私たちは通常、2つの方法のうちの1つでJenkinsをDockerで実行します。1つは、ホストのdocker.sockをコンテナにマウントして、Jenkinsがこのファイルを介してローカルのdockerデーモンと通信できるようにする方法です。その後、dockerビルドイメージが作成されたり、これらのイメージがリモートリポジトリにプッシュされたりするので、途中で生成されたイメージがすべてローカルマシンにスタックされてしまうという問題があります。
Serverlessのシナリオによっては、Serverless自体がソケットファイルのマウントを許可していないため、多少の制限があります。もう一つはDocker-in-Docker方式です。その利点は、コンテナ内で新しいDockerデーモンを起動することです。中間コンポーネントやビルド関連のコンポーネントはすべてコンテナと一緒に削除されます。ただし、権限が必要です。
ほとんどの場合は使わないようにしています。また、ホストコンピュータ上にdockerビルドイメージを作成できる場合で、すでにイメージが存在する場合は、そのイメージをそのまま利用することになります。しかし、Docker-in-Docker方式の場合は、毎回イメージを引っ張ってくることになり、これも様々な利用シーンによっては時間がかかります。
新しいビルドツール - Kaniko
このタイミングで、オープンソースのGoogleツール「Kaniko」が登場しました。これはDocker-in-Docker方式を採用しています。その大きな利点の一つは、Dockerに依存しないため、ユーザーモードでコンテナ内のDockerイメージを権限権限なしで完全にビルドできることです。ユーザーモードでDockerfileコマンドを実行すると、完全にイメージをビルドすることができます。
これが期待される弾力的なCI/CDシステムです。この場合、実ノードから基底層までの計算資源は弾力的にスケーリングされ、デリバリー要件を満たしているので、我々のリソースは非常に洗練された方法で管理することができます。
デモ
デモを見てみましょう: https://github.com/hymian/webdemo
ここでは、私が用意した例を紹介します。注目はこのJenkinsfileファイルで、エージェントのPodテンプレートを定義しており、Golangビルド用とイメージビルド用の2つのコンテナが入っています。
そして、ビルドを開始します。ビルド開始時には、この環境ではMasterが1つしかないので、ビルドノードは存在しません。見ての通り、これで新しいPodが起動し、ノードとして追加されました。しかし、私はこのPodテンプレートにラベルを定義しているので、このノードは存在せず、Podの状態は保留中です。そのため、ビルドログに表示されているエージェントノードはオフラインになっています。
しかし、このクラスタではAutoscalerを定義しています。ノードが存在しない場合、自動的に新しいノードを割り当てて追加します。ノードが追加されていることがわかります。これが終わるまでしばらく待ちます。これには1分か2分かかるでしょう。
ノード数が足りない場合は、自動的にノード数をスケーリングしてクラスタに追加することができますが、これには少し時間がかかります。これはポーリングの時間差があるスケーリングを最初にトリガーするためです。全体で3分くらいかかるかもしれません。さて、サーバーを見てみましょう。ちょうど3台のサーバーがありました。これが先ほど追加したものです。
これは例外で、ノードがクラスタに追加されているので、まだ表示されていないはずです。コマンドラインを見ると、ノードが追加されてすでに4つのノードになっていることがわかります。この時点では、エージェントでPodが作成されていることがわかります。0/3はPodに3つのコンテナがあることを示していますが、上で定義したのは、Podには2つのコンテナしか存在していないことを示しているという細かい点に注意してください。
JNLPコンテナは、プラグインによって自動的に追加されるコンテナです。このコンテナを使って、ビルドの中間状態をリアルタイムにマスターに報告します。ログをマスターに送信します。 これはエージェントノードの初期化処理です。この時点ですでにスレーブノードが稼働しています。出力を終えて、ビルドが完了しました。
作者について
アリババでソリューションアーキテクトを務めるHua Xiang氏は、ビジネスコンテナ化、Kubernetes管理、DevOpsプラクティスなどの分野に注力しています。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ