今回はテスト環境の管理に焦点を当て、フィーチャー環境と呼ばれるアリババ独自の自己設計型仮想化技術を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
序文
アリババの多くのプラクティスは、一見単純に見えても、実際にはテスト環境の管理など、よく考えられた多くの概念に依存しています。
インターネット製品サービスは、通常、ウェブアプリケーション、ミドルウェア、データベース、そして多くのバックオフィスビジネスプログラムで構成されています。ランタイム環境は、自己完結型の小さなエコシステムです。最も基本的なランタイム環境はオンライン環境であり、正式にリリースされたバージョンの製品をデプロイしてユーザーに継続的かつ信頼性の高いサービスを提供します。
また、外部ユーザーに公開されていないランタイム環境も多数存在し、製品チームの日常的な開発や検証に利用されています。これらの環境を総称してテスト環境と呼びます。形式環境の安定性は、ソフトウェア自体の品質とは別に、主にホストやネットワークなどの実行インフラに関係していますが、テスト環境の安定性は人的要因の影響を大きく受けます。テスト環境の不具合は、頻繁なバージョン変更や未検証のコードのデプロイが原因で発生するのが一般的です。
適切なコード送信の習慣と適切な変更前のチェックは、障害の発生を減らすのに役立ちますが、障害を完全に排除することはできません。テスト環境のレプリカを複数増やすことで、フォールトの影響範囲を効果的にコントロールすることができます。しかし、企業のリソースは限られているため、コストの削減とテスト環境の安定性の向上は両立させるべき2つの目標となっています。
この分野で、アリババの研究開発効率化チームは「フィーチャー環境」と呼ばれるサービスレベルの再利用可能な仮想化技術を設計しましたが、そのアイデアは大変巧妙で印象的なものです。この記事では、テスト環境管理の話題に焦点を当てて、アリババの特徴を生かした働き方を論じていきます。
テスト環境管理の難しさ
テスト環境は広く利用されています。システム統合テスト環境、ユーザー受入テスト環境、リリース前テスト環境、段階的テスト環境などの一般的なテスト環境は、製品のデリバリーライフサイクルを反映しており、間接的にはチーム全体の組織構造を反映しています。
小規模なワークショップ形式の製品チームのテスト環境は、管理が非常にシンプルです。各エンジニアは、デバッグのためにソフトウェアコンポーネントのフルスイートをローカルで起動することができます。それでも安全ではないと思うのであれば、パブリックな統合テスト環境を追加すれば十分でしょう。

製品がスケールアップするにつれて、すべてのサービスコンポーネントをローカルで開始するのは時間と手間がかかります。エンジニアは、ローカルでデバッグする一部のコンポーネントのみを実行し、残りのコンポーネントをパブリックテスト環境で使用して完全なシステムを形成することができます。
さらに、チーム規模の拡大に伴い、各チームメンバーの責任がさらに細分化され、新たなサブチームが形成されるため、プロジェクトの通信コストが増大し、公開テスト環境の安定性の制御が困難になります。この過程で、テスト環境管理の複雑化の影響は、サービスの共同デバッグの煩雑さだけでなく、デリバリープロセスの変化やリソースコストの変化にもダイレクトに反映されます。
納品プロセスの大きな変化としては、テスト環境の多様性の増大が挙げられます。エンジニアは、目的に応じてさまざまな専用のテスト環境を設計してきました。これらのテスト環境の組み合わせにより、各企業独自のデリバリプロセスが形成されています。次の図は、大規模プロジェクトの複雑なデリバリープロセスを示しています。
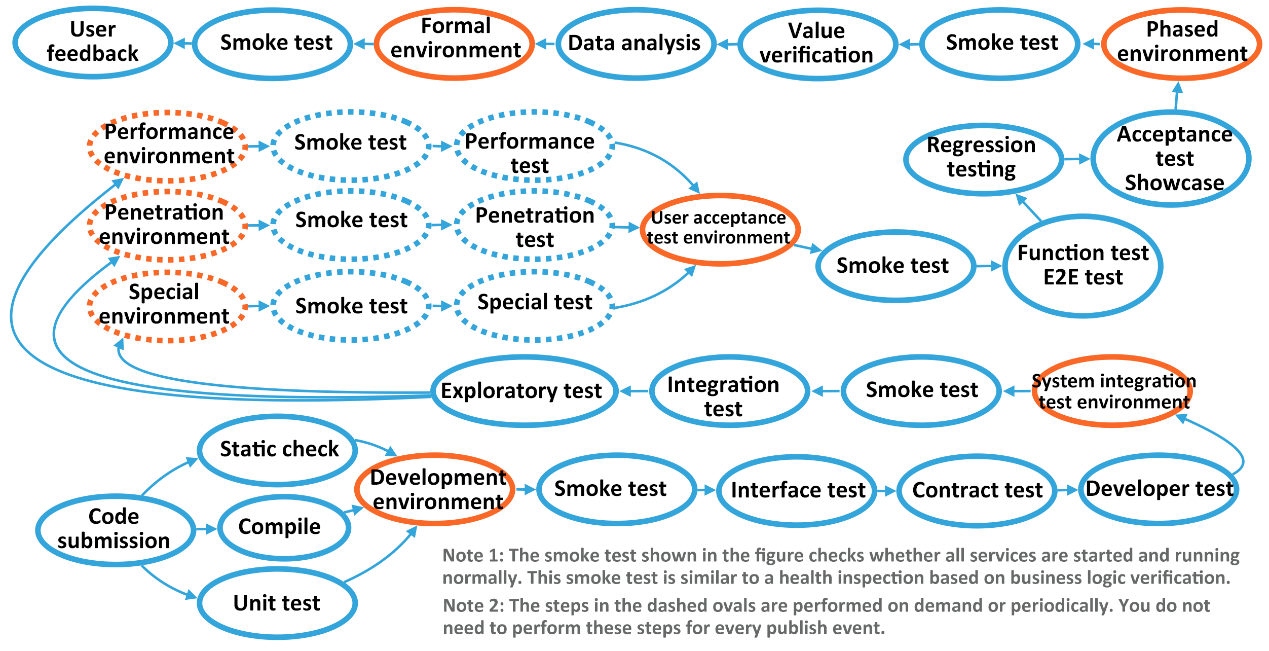
個々のサービスの観点からは、環境はパイプラインで接続され、自動テストや手動承認作業のレベルと相まって、環境間の移行を実現しています。一般的に、環境のレベルが高いほど、デプロイの頻度が低くなり、相対的な安定性が高くなります。逆に、低レベルの環境では、新しいデプロイメントがいつでも発生し、その環境を使用している他の人に影響を与える可能性があります。時には、特別な問題シナリオを再現するために、一部の開発者が操作を実行するためにサーバに直接ログオンしなければならないこともあり、環境の安定性と可用性にさらに影響を与えます。
いつでも崩壊する可能性のあるテスト環境に直面して、小規模企業は「ブロッキング」、つまりサービスの変更時間を制限して厳格な変更仕様を設定する方法を採用しようとしますが、大企業は「アンチョーク」、つまりテスト環境の複製を増やして障害の影響範囲を隔離することを得意としています。明らかに、「遮断」の方法が採用されている場合、圧倒されたテスト環境の状況は間違いなく悪化していきます。意図的な制御では、脆弱なテスト環境を救うことはできないのです。
近年、DevOps文化の台頭により、開発者の手がエンドツーエンドで解放されましたが、テスト環境の管理には諸刃の剣となっています。一方で、DevOps は開発者が O&M に参加して製品のライフサイクル全体を理解することを奨励し、不必要な O&M インシデントを減らすのに役立ちます。DevOpsによって、より多くの人がテスト環境にアクセスできるようになるため、より多くの変更やホットフィックスが発生するようになります。グローバルな視点で見ると、これらのプラクティスはデメリットよりもメリットの方が大きいのですが、テスト環境の安定性を向上させることはできません。単純なプロセスの「アンチョーク」も、脆弱なテスト環境を救うことはできません。
異なるチームが使用する低レベルのテスト環境を独立させ、各チームが直線的なパイプラインを作り、全体として見たときに以下の図のように川が収束するような形が現れるようにします。
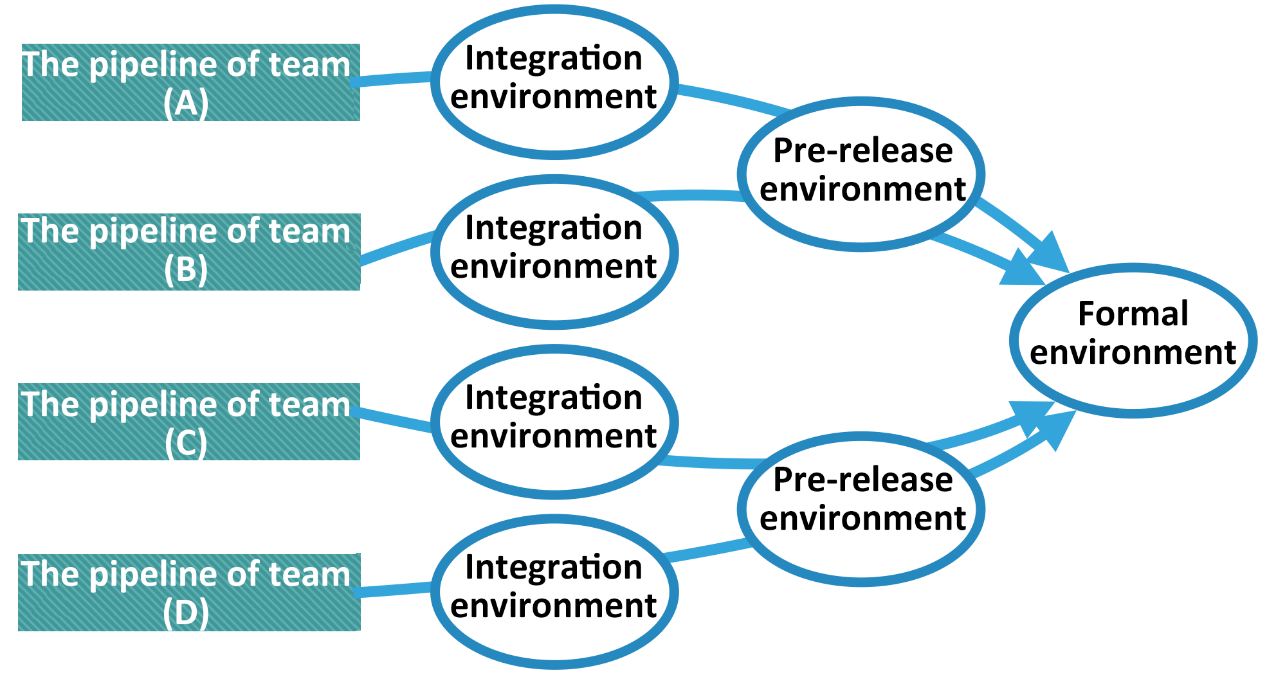
したがって、理想的には、各開発者は排他的で安定したテスト環境を手に入れ、干渉を受けることなく作業を完了させることが望ましいのです。しかし、現実にはコストの関係上、限られたテストリソースしかチーム内で共有することができず、テスト環境における異なるメンバー間の干渉が、ソフトウェア開発の品質に影響を与えかねません。テスト環境のレプリカを増やすことは、基本的には効率と引き換えにコストが増加します。
客観的な規模とボリュームの関係上、アリババのプロダクトチームも上記のようなテスト環境の管理に悩まされやすいのではないでしょうか。
最初のチャレンジ:テスト環境の種類の管理
アリババでは、テスト環境にも多くの種類があります。様々なテスト環境の名称は、その機能と密接に関係しています。業界では一般的に使われている名称もありますが、権威ある命名基準は形成されていません。むしろ、環境の名称はあくまでも形にすぎません。重要なのは、様々なテスト環境がそれぞれ特定のアプリケーションシナリオに適応しなければならないという事実にあり、シナリオ間には多かれ少なかれ違いが存在するはずです。
違いのいくつかは、実行されるサービスの種類にあります。例えば、パフォーマンステスト環境は、ストレステストに関連して最もアクセス数の多い主要なサービスだけを実行する必要があるかもしれませんが、他のサービスを実行する場合は、リソースの無駄遣いにしかなりません。いくつかの違いは、アクセスデータのソースにあります。例えば、開発者テスト環境のデータソースと正式環境のデータソースは確実に異なるため、テストで使用される偽データがオンラインユーザーのリクエストを汚染することはありません。リリース前の環境(あるいはユーザ受入テスト環境)では、新機能の動作を実データに反映させるために、フォーマル環境と整合性のあるデータソース(あるいはフォーマルデータソースのレプリカ)を使用しています。自動テスト関連環境では、テスト中に他の手動操作との干渉を避けるために、テスト用のデータベースを別個に用意しています。
他のいくつかの違いは利用者にあります。例えば、フェーズド環境もプレリリース環境も形式的なデータソースを利用していますが、フェーズド環境の利用者は少数の実質的な外部利用者であるのに対し、プレリリース環境の利用者はすべて社内の担当者です。要するに、ビジネスに特化していないと、テストシナリオのためのテスト環境を作る必要がないということです。
グループレベルでは、アリババはパイプラインの形態について比較的緩やかな制約を設けています。客観的に見て、チームにとって最適なデリバリープロセスがどうあるべきかは、第一線の開発チームだけが知っています。アリババの開発プラットフォームは、開発者が構築できるいくつかの推奨パイプラインテンプレートを標準化しているだけです。以下に代表的なテンプレートの例をいくつか挙げておきます。

ここでは、外界ではあまり見かけない環境型の名称がいくつか登場するので、後ほど詳しく説明します。
第二の課題:テスト環境のコスト管理
コスト管理の問題はトリッキーであり、探求する価値があります。テスト環境に関連するコストには、主に環境の管理に必要な「人件費」とインフラの購入に必要な「資産費」があります。自動化ツールやセルフサービスツールを利用すれば、人件費関連のコストを効果的に削減することができます。また、自動化は大きなテーマです。これについては別の記事で解説するのが望ましいので、当分の間、ここでは掘り下げて説明しないことにします。
資産購入コストの削減は、技術の向上と進歩(大規模調達による価格変動要因を除く)に依存しますが、インフラ技術の開発履歴には、ハードウェアとソフトウェアの2つの大きな分野があります。ハードウェア開発によってもたらされる大幅なコスト削減は、通常、新材料、新生産プロセス、新ハードウェア設計のアイデアによって恩恵を受けます。しかし、現在、ソフトウェア開発によってもたらされたインフラコストの大幅な減少は、仮想化(つまり、リソースの分離と多重化)技術の躍進によるものがほとんどです。
最も古い仮想化技術は仮想マシンです。1950年代には、IBMがこのハードウェアレベルの仮想化手法を用いて、リソースの利用率を指数関数的に向上し始めました。仮想マシン上の異なる隔離された環境では、それぞれ完全なオペレーティングシステムが動作するため、隔離性が高く、普遍性が強いのですが、ビジネスサービスを稼働させるシナリオではやや煩雑です。2000年以降、KVMやXENなどのオープンソースプロジェクトは、ハードウェアレベルの仮想化を普及させました。
同時に、もう一つの軽量仮想化技術が登場しました。OpenVZやLXCに代表される初期のコンテナ技術は、オペレーティングシステムのカーネル上に構築されたランタイム環境の仮想化を実現し、独立したオペレーティングシステムのリソース消費を抑え、一定の分離を犠牲にして高いリソース利用率を得ました。
その後、イメージカプセル化やシングルプロセスコンテナの概念を持つDockerは、このカーネルレベルの仮想化技術を数百万人の人々に求められる高いレベルにまで昇華させました。アリババは技術の進歩に追随して、早くから仮想マシンとコンテナの利用を始め、2017年の「独身の日」に開催されたショッピングカーニバルでは、オンラインビジネスサービスのコンテナ化の割合が100%に達しました。しかし、次の課題はインフラリソースをより効率的に活用できるかどうかにあります。
仮想マシンのためのハードウェアコマンド変換やオペレーティングシステムのオーバーヘッドを取り払うことで、コンテナ内で動作するプログラムと通常のプログラムの間には、カーネルの名前空間の隔離という薄い層が存在するだけで、実行時のパフォーマンスの低下は全くありません。その結果、仮想化はこの方向では限界に達しているように思われます。汎用的なシナリオは置いておいて、テスト環境管理の具体的なシナリオに焦点を当てて、ブレイクスルーを求め続けるしかないのではないでしょうか。最後に、アリババはこの分野で新たな宝、サービスレベルの仮想化を発見しました。
いわゆるサービスレベルの仮想化とは、基本的には、クラスタ内の一部のサービスの再利用を実現するためのメッセージルーティングの制御に基づいています。サービスレベル仮想化の場合、一見大規模なスタンドアロンのテスト環境の多くは、実際には最小限の追加インフラリソースしか消費しません。したがって、各開発者に専用のテスト環境クラスタを提供することは、もはや大きな利点ではありません。
具体的には、アリババのデリバリープロセスには、「共有基本環境」と「機能環境」という2つの特殊なタイプのテスト環境が含まれており、アリババの特徴を持ったテスト環境の利用方法を形成しています。共有基本環境は、完全なサービス実行環境であり、一般的には比較的安定したサービスバージョンが実行されます。チームによっては、共有基本環境として、各サービスの最新バージョンを常にデプロイする低レベル環境を利用しているところもあります。
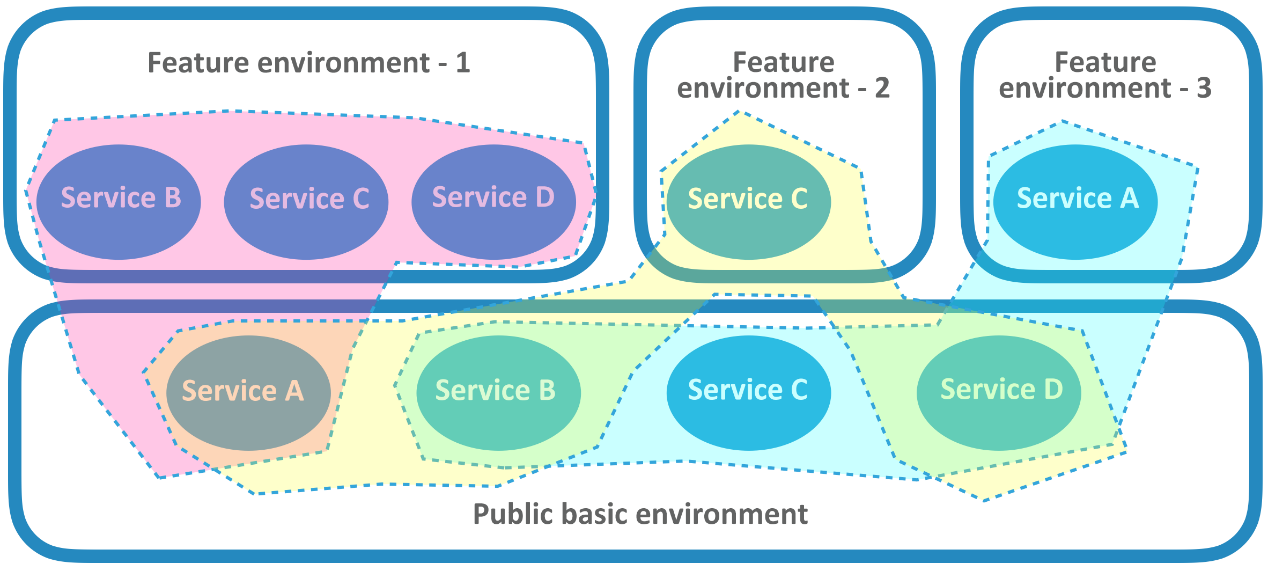
この方式の中で最も興味深いのが機能環境です。それは仮想環境です。表面的には、各機能環境はサービスのクラスタからなる独立した完全なテスト環境で、実際には現在の一部のユーザがテストしたいサービスとは別に、他のサービスはルーティングシステムやメッセージ指向ミドルウェアを介して仮想化され、共有された基本環境の中で対応するサービスを指し示しています。アリババの一般的な開発プロセスでは、開発タスクは機能ブランチ、リリースブランチ、および多くの関連リンクを経て、最終的にリリース、ローンチされる必要があります。ほとんどの環境はリリースブランチからデプロイされますが、この種の開発者向けの自己利用型仮想環境は、コードの機能ブランチのバージョンからデプロイされます。そのため、「フィーチャー環境」と呼ぶことができます(アリババでは「プロジェクト環境」と呼ばれています)。
例えば、トランザクションシステムの完全な展開は、認証サービス、トランザクションサービス、注文サービス、決済サービス、対応するデータベース、キャッシュプール、メッセージ指向ミドルウェアを含む十数個の小さなシステムで構成されています。そして、その共有基本環境は、基本的にすべてのサービスと周辺コンポーネントを含む完全な環境です。このとき、2つの機能環境が稼働しているとします。1つはトランザクションサービスのみを起動し、もう1つはトランザクションサービス、注文サービス、決済サービスを起動します。最初の機能環境のユーザにとっては、実際にはトランザクションサービス以外のすべてのサービスは共有の基本環境でプロキシされているものの、使用中はトランザクションサービスが完全な環境を所有しているように見えます。トランザクションサービスのバージョンを環境内で自由にデプロイしたり更新したり、他のユーザーに影響を与えることなくデバッグを行うことができます。第2の特徴環境の利用者に対しては、環境内に展開された3つのサービスを共同でデバッグ・検証することができます。シナリオで認証サービスを利用した場合、共有基本環境の認証サービスが応答します。
動的に変更されたドメイン名に対応したルーティングアドレス、メッセージの件名に対応した配信アドレスということになるのではないでしょうか?実際には、共有基本環境の経路は、特定の特徴環境に対しては変更できないので、それほど単純ではありません。そのため、オーソドックスなルーティング機構では、一方通行のターゲット制御、すなわち、フィーチャー環境のサービスが積極的に発呼を開始して正しいルーティングを確保することしか実現できません。リクエストの発呼元が共有基本環境にある場合、どのフィーチャー環境にリクエストを送ればよいのかを知ることができません。HTTP リクエストの場合、コールバックを処理することさえ困難です。共有基本環境にあるサービスがコールバックされた場合、ドメイン名解決は共有基本環境にある同名のサービスをターゲットにします。
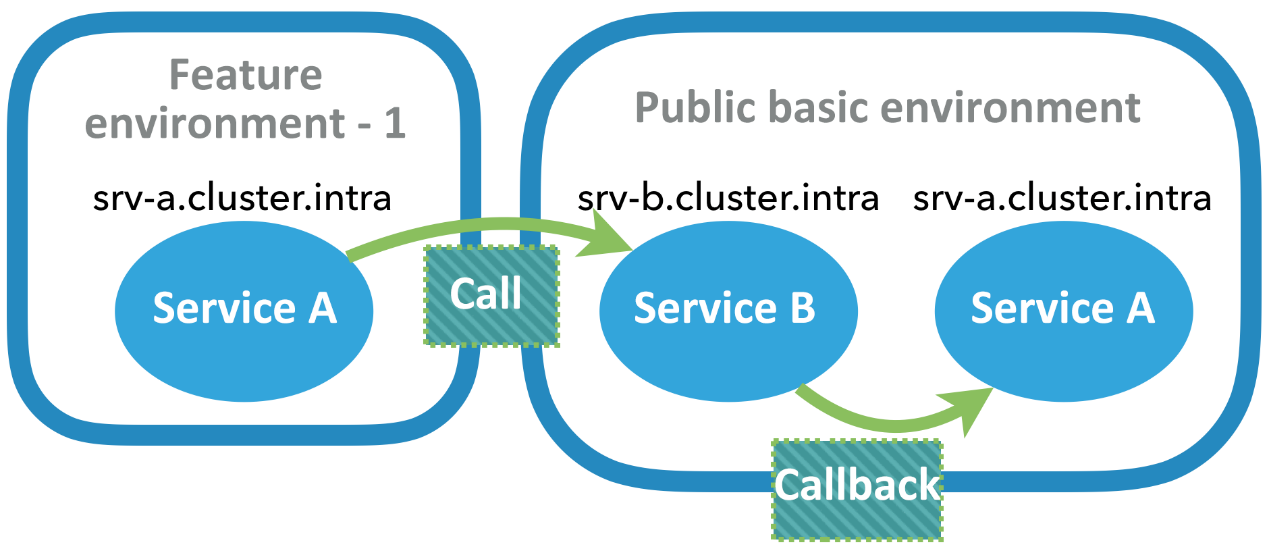
どのようにしてデータをルーティングし、両方の方法で正しく配信することができるでしょうか? 問題の本質に立ち返ってみましょう。リクエストがどの機能環境に入るべきかは、リクエストのイニシエータに関係します。したがって、双方向バインディングを実装するための鍵は、リクエストのイニシエータがいるフィーチャ環境を特定し、エンドツーエンドのルーティング制御を行うことにあります。このプロセスは「段階的リリース」にやや似ており、同様のアプローチで解決できます。
アリババのミドルウェア分野での技術蓄積とEagleEyeなどのトレースツールの普及により、リクエストイニシエータの特定やコールバックリンクのトレースが容易になっています。このようにして、ルーティング制御が簡単になりました。フィーチャー環境を使用する場合、ユーザは環境に「参加」する必要があります。この操作は、ユーザの識別情報(IPアドレスやユーザIDなど)を指定されたフィーチャ環境に関連付けるものです。各ユーザは一度に1つのフィーチャ環境にしか所属できません。データ要求がルーティングミドルウェア(メッセージキュー、メッセージゲートウェイ、HTTPゲートウェイなど)を通過する際に、要求の開始者が現在の機能環境にいることが確認されると、要求はその環境のサービスにルーティングされます。環境がターゲットと同じサービスを持っていない場合、リクエストはルーティングされるか、共有された基本環境に配信されます。
機能環境は単独では存在しません。コンテナ技術の上に構築することで柔軟性を高めることができます。仮想マシン上にコンテナを構築することでインフラ取得の利便性が得られるように、フィーチャ環境では、コンテナを介したサービスの迅速かつ動的なデプロイは、ユーザーがいつでもフィーチャ環境に修正やデバッグが必要なサービスを追加したり、環境内のサービスを破棄したりすることができ、共有された基本環境が自動的にそれを置き換えることができることを意味しています。
もう一つの問題は、サービスクラスタのデバッグです。
AoneFlowのフィーチャブランチの仕組みと連動して、複数のサービスの異なるサービスブランチを同じフィーチャ環境にデプロイしておけば、複数のフィーチャをリアルタイムで共同デバッグすることができ、フィーチャ環境を統合テストに利用することができます。しかし、フィーチャ環境は作成コストが低くても、サービスはテストクラスタ上にデプロイされます。そのため、コードを修正するたびにパイプラインが構築されてデプロイされるのを待つ必要があり、スペースオーバヘッドは節約できますが、時間オーバヘッドを短縮することはできません。
アリババのチームメンバーは、さらなるコスト削減と効率化を図るために、機能環境にローカルの開発マシンを追加するという別のアイデアを思いつきました。グループ内では、開発マシンとテスト環境の両方がイントラネットのIPアドレスを使用しているため、多少の変更を加えれば、特定のテスト環境からのリクエストを開発マシンに直接ルーティングすることは難しくありません。つまり、機能環境のユーザが実際に共有基本環境から来ているサービスにアクセスしたとしても、その後の処理リンク上のサービスの一部が機能環境から来ている場合もあれば、ローカル環境から来ている場合もある。このようにして、テスト環境全体がローカルで実行されているかのように、パイプラインの構築に長時間待たされることなく、クラスタ内のサービスをデバッグすることが簡単になります。
フィーチャー環境を自分で構築する
サービスレベルの仮想化はニッチで一般の開発者には手の届かないものだと思っていませんか?そうではありません。すぐに自分で機能環境を構築して試してみることができます。
アリババ機能環境では、HTTPコール、RPCコール、メッセージキュー、メッセージ通知など、さまざまな一般的なサービス通信方式を含む双方向ルーティングサービスレベルの仮想化が実装されています。このような完全な機能テスト環境を完成させるのは難しいかもしれません。汎用的な観点からは、最も一般的なHTTPプロトコルから始めて、一方通行ルーティングをサポートするシンプルな機能環境を構築することができます。
環境管理を容易にするためには、コンテナを実行できるクラスタを用意するのがベストです。オープンソースコミュニティでは、フル機能のKubernetesが良い選択です。Kubernetesでのルーティング制御に関連するいくつかの概念は、ユーザーにリソースオブジェクトとして表示されます。
簡単に言うと、Namespace オブジェクトはサービスのルーティングドメインを分離することができますが、これはコンテナの分離に使用されるカーネルの Namespace とは異なります。この2つを混同しないでください。Service オブジェクトは、サービスのルーティングターゲットと名前を指定するために使用されます。Deployment オブジェクトは、実際にデプロイされたサービスに対応します。ClusterIP型のServiceオブジェクト(NodePort型とLoadBalancer型は今のところ無視されています)は、同じNamespace内の実際のサービスをルーティングすることができ、ExternalName型のServiceオブジェクトは、現在のNamespace内の外部サービスのルーティングプロキシとして使用することができます。これらのリソースオブジェクトの管理は、YAML形式のファイルを使用して記述することができます。これらを学んだ後は、機能環境の構築に取り掛かります。
インフラやKubernetesクラスタの構築作業はスキップします。本題に入りましょう。まず、本格的なテスト環境であるルーティングバックアップ用のパブリックインフラ環境を用意し、テスト対象のサービスやその他のインフラを全て含めた環境を用意します。外部からのアクセスはとりあえず考慮しません。共有基本環境内の全てのサービスの対応するServiceオブジェクトはClusterIP型を使用することができ、これらのオブジェクトが pub-base-envという名前のNamespaceに対応していると仮定します。このようにして、Kubernetesはこの環境の各サービスに、Namespaceで利用可能なドメイン名「service name.svc.cluster」とクラスタグローバルドメイン名「service name.pub-base-env.svc.cluster」を自動的に割り当てます。バックアップが保証された状態で、フィーチャ環境の構築を開始することができます。最も単純なフィーチャ環境では、実際のサービス(trade-serviceなど)を1つだけ含めることができ、他のすべてのサービスは、ExternalName型のServiceオブジェクトを使用して、パブリックインフラストラクチャ環境にプロキシされます。環境が feature-env-1 という名前の名前空間を使用していると仮定し、その名前空間の YAML は以下のように記述されています(キーフィールド以外の情報は省略します)。
kind: Namespace
metadata:
name: feature-env-1
________________________________________
kind: Service
metadata:
name: trade-service
namespace: feature-env-1
spec:
type: ClusterIP
...
________________________________________
kind: Deployment
metadata:
name: trade-service
namespace: feature-env-1
spec:
...
________________________________________
kind: Service
metadata:
name: order-service
namespace: feature-env-1
spec:
type: ExternalName
externalName: order-service.pub-base-env.svc.cluster
...
________________________________________
kind: Service
...
サービスorder-serviceには、現在の機能環境Namespaceでローカルドメイン名order-service.svc.clusterを使用してアクセスでき、要求はグローバルドメイン名order-service.pub-baseにルーティングされることに注意してください。 サービスによって構成されたenv.svc.cluster、つまり、処理のためにパブリックインフラストラクチャ環境内の同じ名前のサービスにルーティングされます。名前空間内の他のサービスは、この違いを認識しません。代わりに、すべての関連サービスがこのネームスペースに配備されていると仮定することができます。
開発者が機能環境の開発中にオーダーサービスを変更した場合、変更されたバージョンを環境に追加する必要があります。必要なのは、Kubernetesのパッチ操作を使ってorder-serviceのServiceオブジェクトプロパティを修正し、ClusterIP型に変更し、現在のNamespaceにDeploymentオブジェクトを作成して関連付けるだけです。
変更された Service オブジェクトは、対応する名前空間 (つまり、対応するフィーチャ環境) 内のサービスに対してのみ有効であり、パブリック・インフラストラクチャ環境から呼び出されたリクエストには影響しないため、ルートは一方通行になります。この場合、機能環境には、テスト対象のコールリンクのポータルサービスと、コールバック操作を含むサービスが含まれていなければなりません。例えば、テスト対象のフィーチャーはインタフェース操作によって起動され、ユーザインタフェースを提供するサービスはポータルサービスです。サービスが変更されていない場合でも、そのサービスのメインライン版を機能環境に展開しておきます。
このような仕組みにより、クラスタサービスを部分的にローカルサービスに置き換えてデバッグや開発を行う機能を実装することは難しくありません。クラスタとローカルホストの両方がイントラネット内にある場合は、ExternalName型のServiceオブジェクトにローカルのIPアドレスとサービスポートを指定するだけです。そうでない場合は、ローカルサービスのためにパブリックネットワークルーティングを追加し、ダイナミックドメイン名解決によってこの機能を実装する必要があります。
YunxiaoはKubernetesベースの機能環境ソリューションを徐々に改良しており、より包括的なルーティング分離のサポートを提供する予定です。特筆すべきは、パブリッククラウドの特殊性から、共同デバッグ時にローカルホストをクラウド上のクラスタに結合することは、克服しなければならない課題です。そこでYunxiaoでは、トンネルネットワーク+kube-proxyのルーティング機能を利用して、共同デバッグ時にローカルのLANホスト(パブリックIPアドレスなし)を別のイントラネットにあるKubernetesクラスタに結合する方法を実装しました。技術的な詳細については、近日中にYunxiao公式WeChatアカウントでも発表されるとのことなので、期待していてください。
概要
多くの人が仮想マシンやコンテナに続く仮想化技術の次の波の到来を待ち望んでいる中、アリババはすでに答えを出しています。イノベーションを制限するのは技術ではなく想像力です。サービスレベル仮想化の概念は、従来の環境レプリカの認知を打ち破り、テスト環境のコストと安定性のバランスの問題を独自の視点で解決します。
アリババ・Yunxiaoは、大型製品の協力に対処するための方法論で多大な貢献をしてきました。アジャイルで迅速な製品イテレーション、膨大な量のホストデータ、効果的なテストツール、分散型の第2レベル構造、大規模なスコープのクラスタ展開リリースなどの工業的なタスクや技術的な課題は、社内のアリババグループチーム、エコシステムパートナー、クラウド開発者によって提供されています。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ