この記事では、時系列データの詳細な概要を説明し、時系列データベースエンジンのストレージと計算能力について解説しています。
周 肇峰著
時系列データとは
時系列データとは、時間によってインデックス化されたデータの集合です。簡単に言えば、このタイプのデータは、時間範囲の各時間点で測定された被験者の測定値を記述しています。
時系列データのモデル化には、3つの重要な部分が含まれます。このモデルを適用すると、日々の仕事や生活の中でこのタイプのデータと常に接触していることに気づくでしょう。
- あなたが株主であれば、株式の株価は時系列データの一種です。これは、各時点での株価を記録しています。
- あなたがO&M担当者であれば、監視データは時系列データの一種です。例えば、CPUの監視データは、各時点でのCPUの実際の使用状況を記録します。
世界はデータでできており、世の中のあらゆるモノが常にデータを生み出しています。このようなデータの搾取と利用は、この時代の人々のライフスタイルを静かに変えています。例えば、ウェアラブルデバイスのパーソナルヘルス管理機能の核となるのは、個人の健康データを継続的に収集することです。そのようなデータには、心拍数や体温などがあります。それらのデータを収集した後、デバイスはモデルを使ってあなたの健康状態を計算し、評価します。
視野と想像力を自由にすれば、日常生活のあらゆるデータが悪用され、利用できることに気づくでしょう。データを生成するオブジェクトには、携帯電話、車、エアコン、冷蔵庫などがあります。今話題のIoT(Internet of Things)技術の核となる考え方は、あらゆるオブジェクトから発生するデータを収集し、収集したデータの価値を搾取するネットワークを構築することです。このネットワークで収集されるデータは、代表的な時系列データです。
時系列データは、対象物の状態変化情報を過去の時間次元で記述するために用いられます。時系列データの分析は、変化の法則を理解し、マスターしようとするプロセスです。時系列データは、IoT、ビッグデータ、人工知能(AI)技術の発展に伴い、爆発的な成長を経験しています。このようなデータの保存と分析をより良くサポートするために、様々なデータベース製品が登場し、市場に出回っています。この種のデータベース製品の発明は、時系列データの保存と分析において、従来のリレーショナルデータベースの欠点や欠点を解決することを目的としています。これらの製品は、一律に時系列データベース(TSDB)に分類されます。
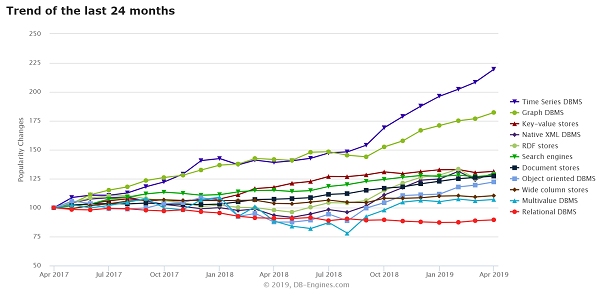
DB-Enginesのデータベース管理システムの人気ランキングを見てもわかるように、TSDBの人気はここ2年で高い伸び率を維持しています。
後日、いくつかの記事を書いて分析してみたいと思います。
1、モデル、特性、基本的なクエリ、処理操作を含む時系列データの基本的な概念。
2、いくつかの人気のあるオープンソースTSDBの基礎となる実装の分析。
時系列データの特徴
時系列データの特性分析を、データの書き込み、問い合わせ、保存の3つの次元から解説します。これらの特性を分析することで、時系列データベースの基本的な要件を把握します。
データの書き方の特徴
-
スムーズな連続性、高同時性、高スループットのデータ書き込みが可能です。時系列データの書き込みは、アプリケーションデータとは異なり、比較的安定しています。アプリケーションデータは、通常、アプリケーションのページビューに比例して、ピークとバレーがあります。時系列データは、通常、一定の時間頻度で生成され、他の要因に制約されません。データ生成速度は比較的安定しています。時系列データは、個々のオブジェクトごとに独立して生成されます。個別オブジェクトの数が多いと、特にIoTシナリオでは、データの書き込み同時実行性やスループットが相対的に高くなってしまいます。書き込みの同時性とスループットは、単純に個別オブジェクトの数とデータ生成の頻度で計算することができます。例えば、10秒ごとにデータを生成するオブジェクトが1000個あれば、1秒ごとの書き込み同時実行性とスループットは100になります。
-
読み取りよりも書き込みの方が多いです。時系列データに対する操作の95~99%は書き込みです。これはデータの特性によって決まります。モニタリングデータを例にとると、多くのモニタリング項目があるかもしれませんが、そのうちのいくつかの項目にしか関心を持っていません。通常は、いくつかの重要なメトリクスのデータだけを読み込んだり、特定のケースだけを読み込んだりします。
-
最新のデータはリアルタイムで生成され、更新されることはありません。時系列データはリアルタイムで書き込まれ、その都度書き込まれるデータが最新のデータとなります。これは、このようなデータは時間をかけて生成され、リアルタイムで新しいデータが書き込まれるため、データ生成特性によって決定されます。データは書き込まれても更新されません。時間次元では、時間が経過するにつれて、書き込まれたデータはすべて新しいものとなります。既存のデータは、手動での修正を除いて更新されません。
データの問い合わせと分析の特徴
-
データは期間ごとに読み込まれます。一般的には、特定の時点のデータではなく、ある期間のデータが必要になります。そのため、時系列データは基本的に時間範囲で読み込まれます。
-
最近のデータほど読まれる可能性が高く、最近のデータであればあるほど、データの読み込み可能性は高くなります。モニタリングデータを例にとると、1ヶ月前や1年前に何が起こったかよりも、ここ数時間やここ数日に何が起こったかにしか興味がないのが普通です。
-
多精度クエリ:時系列データの精度は、データ点の密度によって区別されます。例えば、隣接する2つのデータ点間の時間間隔が10秒の場合、時系列データの精度は10秒となります。また、時間間隔が30秒であれば、精度は30秒になります。時間間隔が短いほど精度は高くなります。精度が高ければ高いほど、復元された歴史的状態をより詳細かつ正確に把握することができます。しかし、精度が高いということは、保存するデータポイントが増えるということでもあります。これは、写真の解像度と非常によく似ています。解像度が高ければ高いほど画像が鮮明になり、ファイルサイズも大きくなります。時系列データの問い合わせは、必ずしも高い精度が必要なわけではありません。クエリの精度は、実際のニーズとコストによって共同で決定されます。繰り返しになりますが、モニタリングデータを例に考えてみましょう。通常、モニタリングデータは折れ線グラフの形で表示され、データの変化を自分の目で観察することができます。この場合、単位長で表示するデータポイントが密集しすぎると、観察するのに不便になってしまうのが実際のニーズです。もう一つのトレードオフは、1ヶ月などのより長い時間範囲でクエリを行う場合、精度を10秒に設定した場合、クエリは259,200データポイントを返さなければならないということです。精度を60秒に設定した場合、クエリは43,200個のデータポイントを返すだけで済みます。これがクエリの効率性を定義しています。コスト面では、精度が高ければ高いほど、保存するデータ量が多くなり、コストが高くなります。一般的に、過去のデータについては、高精度は必要ありません。データの問い合わせや処理の面では、一般的にデータの精度は時間範囲の長さで決まります。ヒストリカルデータの保存という点では、通常はダウンサンプリングされたデータを利用することになります。
-
多次元分析:時系列データは、異なる属性を持つ異なる個々のオブジェクトから生成されます。そのような属性は、同じ次元のものであっても、そうでないものであっても良いです。ここでも、モニタリングデータを例にしてみましょう。クラスタ内の各マシンのネットワーク・トラフィックを監視するとき、特定のマシンのネットワーク・トラフィックを問い合わせることができます。これは、1 つのディメンジョンのデータ・クエリとみなすことができます。クラスタ全体のネットワーク・トラフィックを照会すると、別の次元のデータ照会になります。
-
データマイニング:ビッグデータや人工知能技術の発展により、データストレージ、コンピューティングリソース、クラウドコンピューティングが高度に発達しているため、付加価値の高いデータマイニングの敷居はそれほど高くなくなっています。時系列データには高い価値が含まれており、活用する価値があります。
データストレージの特徴
- 大量のデータ:モニタリングデータを例に考えてみましょう。収集した監視データの時間間隔を1秒とすると、1つの監視項目で毎日86,400点のデータが生成されます。この数字は、10,000個の監視項目がある場合、単純に足し算すると864,000,000個になります。IoTシナリオでは、この数字はさらに大きくなります。データサイズはTBやPBで計測されることがあります。
- コールドデータとホットデータの分離: 時系列データは、非常に典型的なホットとコールドの特性を持っています。データが古くなればなるほど、クエリや分析の対象になりにくくなります。
- タイムリー性:時系列データは時間に敏感です。TSDBには通常、保存期間があります。この保持ウィンドウを超えたデータは非アクティブとみなされ、安全に削除することができます。それは、古いデータは通常あまり価値がないので、価値の低いデータを削除することでストレージコストを節約しなければならないからです。
- 多精度データの保存: 前述したように、時系列データの保存コストと問い合わせ効率を考慮すると、多精度の問い合わせが必要です。実際には、多精度データ保存も必要になります。
TSDBの基本要件
以上のような時系列データの特徴をデータの書き込み、問い合わせ、保存の観点から分析した結果、TSDBに求められる基本的な要件をまとめると以下のようになります。
- 同時性が高く、スループットの高い書き込みに対応できること:前述したように、時系列データは読み込みよりも書き込みの方が多く、操作の95~99%が書き込みです。そのため、TSDBの書き込み能力に注目する必要があります。ほとんどの場合、TSDBは高連続性と高スループットのデータ書き込みをサポートしなければなりません。
- インタラクティブな集約クエリ:インタラクティブなクエリのレイテンシは、クエリされたデータが膨大なサイズ(TB単位で測定)であっても、非常に低くなければなりません。
- 大量のデータを保存できること:データサイズはシナリオの特性によって決まります。ほとんどの場合、時系列データはTB、さらにはPBで計測されます。
- 高可用性:オンラインサービスは通常、高い可用性が要求されます。
- 分散アーキテクチャ:データの書き込みとストレージの要件を考慮すると、基礎となる層は分散アーキテクチャでなければなりません。
時系列データの特性とTSDBの基本要件の分析によると、LSMツリーベースのストレージエンジン(HBase、Casandra、Alibaba Cloud TableStoreなど)を使用したNoSQLデータベースは、B+ツリーベースのリレーショナルデータベース管理システム(RDBMS)を使用したデータベースと比較して大きな優位性を持っています。ここでは、LSMツリーの基本理論については説明しません。LSMツリーは、書き込み性能を最適化するように設計されています。LSMツリーを用いたTSDBの書き込み性能は、B+ツリーを用いたTSDBの10倍以上です。しかし、読み出し性能はB+ツリーベースのTSDBよりもはるかに劣ります。したがって、LSMツリーベースのTSDBは、読み取りよりも書き込みが多いシナリオに特に適しています。現在、いくつかのよく知られたオープンソースのTSDBのうち、OpenTSDBは基礎となるストレージエンジンとしてHBaseを使用し、BlueFloodとKairosDBはCassandraを使用し、InfluxDBはLSMに似た自社開発のTSMストレージエンジンを使用し、PrometheusはLevelDBベースのストレージエンジンを直接使用しています。主流のTSDBはすべて、基礎となるストレージにLSMツリーベースの分散アーキテクチャを使用していることがわかります。違いは、既存の成熟したデータベースを直接使用している製品もあれば、自社開発のデータベースやLevelDBベースのデータベースを使用している製品もあることです。
LSM-treeベースの分散アーキテクチャは、時系列データの書き込み要件を容易に満たすことができますが、データの問い合わせという点ではやや弱いです。これらのデータベースは、少量のデータの多次元集計検索のニーズを満たすことができます。しかし、インデックスを持たない大量のデータの多次元集計クエリでは、その性能はやや劣ります。そこで、オープンソースの世界では、このような問い合わせや分析の問題を解決することに焦点を当てた製品が他にも存在します。例えば、Druidは主に時系列データのOLAP要件の解決に焦点を当てており、事前集計なしで大量のデータの高速なクエリ分析を可能にしています。また、任意のディメンションでのドリルダウンにも対応しています。また、私たちのコミュニティでは、分析志向のシナリオのためのElasticSearchベースのソリューションも提供しています。
要するに、多様化したTSDBにはそれぞれのメリットとデメリットがあります。すべてのシナリオに対応する最適なソリューションはありません。サービスのニーズに最も適したものを選択するしかありません。
時系列データモデル
時系列データのデータモデルは、主に以下の部分から構成されます。
- 被験者(Subject):測定される主題。被測定体は、複数の次元を持つ属性を持つことができます。サーバの状態監視を例にとると、測定対象はサーバであり、その属性にはクラスタ名、ホスト名などが含まれます。
- 測定値:被測定体は、特定のメトリックに対応する1つまたは複数の測定値を持つことができます。サーバーステータス監視の場合、測定されたメトリックにはCPU使用率とIOPSが含まれる場合があります。CPU使用率の値はパーセンテージであり、IOPSの値は測定期間中のI/Oの数です。
- タイムスタンプ:測定レポートには、時刻を示すタイムスタンプ属性が必ず添付されています。
現在主流のTSDBでは、データソースによるモデリングとメトリクスによるモデリングの2つのモデリング方法を使用しています。この2つの方法の違いを2つの例を使って説明します。
データソースによるモデリング
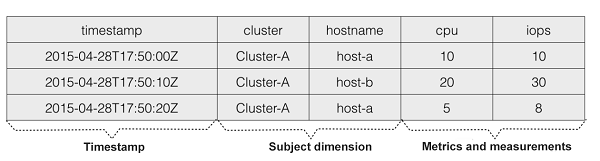
上記は、データソースによるモデリングの例です。ある時点での同一データソースのすべてのメトリクスの測定値が同じ行に格納されています。このモデルはDruidやInfluxDBで使用されています。
メトリクスによるモデリング
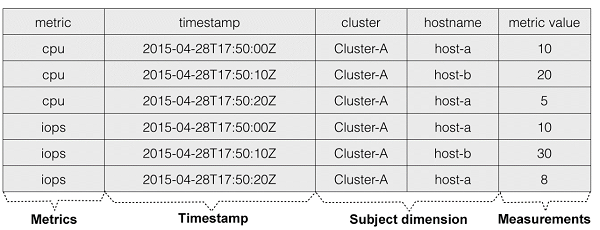
上記はメトリクスによるモデリングの例で、データの各行は、ある時点でのデータソースのあるメトリクスの測定値を表しています。このモードはOpenTSDBとKairosDBで使用されています。
これら2つのモデルの間には明確な区別はありません。基礎となるレイヤアーキテクチャがカラム型ストレージを採用しており、各カラムにインデックスがある場合は、データソースによるモデリングの方が良いかもしれません。基盤となるレイヤ・アーキテクチャがHBaseやCassandraに似ている場合、複数のメトリック値を同じ行に格納すると、いずれかのメトリックのクエリやフィルタの効率に影響を与える可能性があります。そのため、一般的にはメトリクスごとにモデル化することを選択します。
時系列データの処理
ここでは主に時系列データの処理について説明します。TSDBでは、基本的なデータの書き込みと保存に加えて、クエリと解析が最も重要な機能となります。時系列データの処理には、主にフィルタ、集計、GroupBy、ダウンサンプリングが含まれます。GroupByクエリをより良くサポートするために、一部のTSDBではデータを事前に集計します。ダウンサンプリングはロールアップによって行われます。より高速でリアルタイムなロールアップをサポートするために、TSDBは通常、自動ロールアップをサポートしています。
Filter
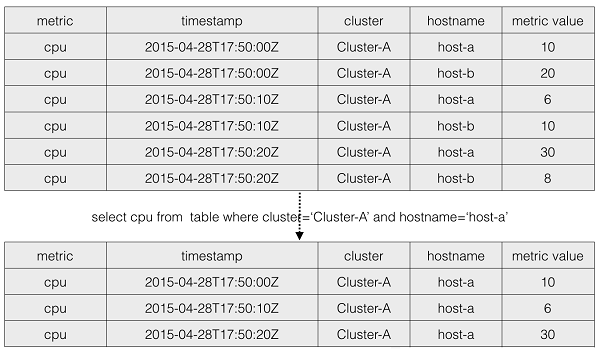
上記は単純なフィルタ処理です。簡単に言えば、異なる次元の与えられた条件を満たす全てのデータを対象に問い合わせを行います。時系列データ分析のシナリオでは、フィルタは通常、高次元からスタートし、より詳細な次元条件に基づいて、より詳細なクエリとデータの処理を実行します。
集計
集計は、時系列データの問い合わせや分析の最も基本的な機能です。時系列データには、元の状態変化情報が記録されています。しかし、時系列データの問い合わせや分析を行う際には、通常、元の情報は必要ありません。その代わりに、元の情報に基づいた統計量が必要となります。集計には、統計量のためのいくつかの基本的な計算が含まれます。最も一般的な計算は、SUM、AVG、Max、およびTopNです。例えば、サーバーのトラフィックを分析する場合、平均トラフィック量、総トラフィック量、またはピーク時のトラフィックが気になります。
GroupByと事前集計
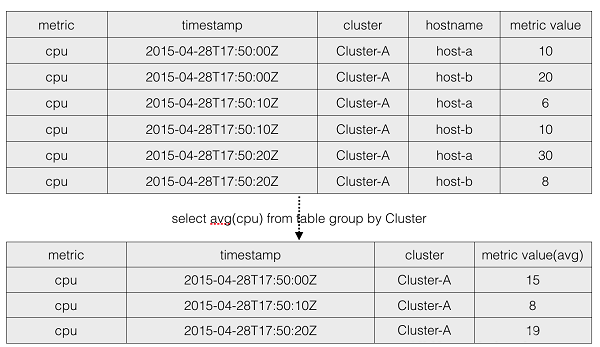
GroupByとは、低次元の時系列データを高次元の統計量に変換する処理のことです。上記はGroupByの簡単な例です。GroupByは通常、クエリ中に実行されます。元のデータをクエリーした後、リアルタイム計算で結果を取得します。この処理は、元々クエリーされたデータのサイズによっては、非常に時間がかかる場合があります。主流のTSDBは、事前集計によってこのプロセスを最適化しています。リアルタイムでデータを書き込んだ後、与えられたルールに従ってGroupBy後の結果を生成するために事前集計を行います。これにより、再計算なしで直接結果を問い合わせることができます。
ダウンサンプリング、ロールアップ、自動ロールアップ
ダウンサンプリングとは、高解像度の時系列データを低解像度の時系列データに変換する処理です。この処理をロールアップといいます。GroupByと似ていますが、両者は異なります。GroupByは、同じ時間粒度に基づいて、異なる次元のデータを同じ時間レベルで集約することです。変換されたデータの時間粒度は変わりませんが、ディメンションが高くなります。ダウンサンプリングは、同じディメンジョンのデータを異なる時間レベルで集約することです。変換されたデータの時間粒度は粗くなりますが、次元は変わりません。

上記は、10秒分解能のデータを30秒分解能のデータに集約して統計平均を求めるダウンサンプリングの簡単な例です。
ダウンサンプリングは、ストレージダウンサンプリングとクエリダウンサンプリングに分けられます。ストレージダウンサンプリングは、データ、特にヒストリカルデータの保存コストを削減するためのものです。クエリのダウンサンプリングは、主に時間範囲の広いクエリで、返されるデータポイントを減らすためです。ストレージ・ダウンサンプリングとクエリ・ダウンサンプリングの両方にオートロールアップが必要です。オートロールアップは、クエリを待っているときではなく、データのロールアップを自動的に行います。プレアグリゲーションと同様に、この処理を行うことで、クエリの効率を効果的に向上させることができます。また、現在主流となっているTSDB向けに設計されている、または設計される予定の機能でもあります。現在、Druid、InfluxDB、KairosDBは自動ロールアップをサポートしています。OpenTSDBは自動ロールアップをサポートしていませんが、外部で自動ロールアップを行った後の結果のインポートをサポートするAPIを提供しています。
まとめ
本記事では、主に時系列データの特徴、モデル、基本的な問い合わせ・処理操作を分析し、TSDBの基本的な要件を明らかにしています。次の記事では、いくつかの人気のあるオープンソースのTSDBの実装を分析します。多くのTSDBが存在するものの、基本的な機能は似通っていることに気づくかもしれません。すべてのTSDBはそれぞれの特徴や実装方法を持っていますが、時系列データの書き込み、保存、クエリ、分析などの次元からトレードオフに基づいて設計されています。すべての潜在的な問題を解決できるワンサイズフィットオールのTSDBは存在しません。ビジネスの観点から最適なTSDBを選択することが重要です。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ