この記事では、主に Luceneの基本的な概念やサポートされているインデックスの種類について説明します。
周 肇峰著
序文
Apache Lucene は、オープンソースの高性能でスケーラブルなデータ検索エンジンで、強力なデータ検索機能を備えています。Lucene は長年にわたって開発され、より強力な機能と洗練されたアーキテクチャを提供してきました。現在では、全文インデックスをサポートしているほか、さまざまな種類のクエリの要件を満たすために多くの種類のインデックスを提供しています。
多くのオープンソースプロジェクトが Lucene をベースにしています。最もよく知られているのはElasticsearchとSolrです。Elasticsearch と Solr を精巧に設計された高性能スポーツカーに例えるならば、Lucene は強力な推進力を提供するエンジンとなるでしょう。より速く、より安定した走りを実現するためには、そのエンジンを詳細に研究する必要があります。
本コラムでは以前、Elasticsearchのデータモデル、読み書きパス、分散アーキテクチャ、データ/メタの整合性を分析した記事を多数掲載してきました。今回の記事の後は、Luceneのデータモデルとデータの読み書きパスの完全な分析を行うために、Luceneの原理とソースコードについての一連の記事を計画しています。
Luceneは公式にいくつかのポイントでその利点をまとめています。
1、スケーラブルで高性能なインデックス作成
2、強力で正確かつ効率的な検索アルゴリズム
この一連の記事を通して、読者の皆さんが Lucene がどのようにしてこれらの目標を達成しているのかを理解していただけることを願っています。
全体の分析は Lucene 7.2.1 に基づいています。この記事を読む前に、基本的な検索やインデックスの原理、転置インデックスやトークン化、関連性などの概念を理解し、 Lucene の基本的な使用法である Directory, IndexWriter, IndexSearcher などを理解しておく必要があります。
基本的な概念
Lucene の詳細に入る前に、いくつかの基本的な概念と、その背後に隠されたいくつかの側面を知っておくと良いでしょう。
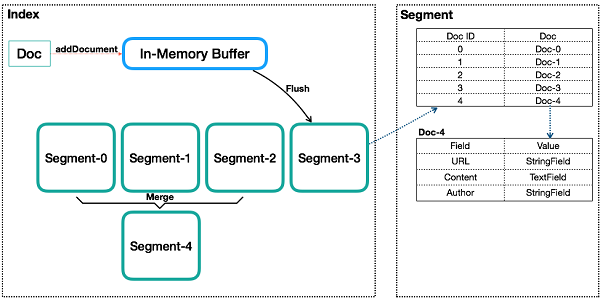
図はインデックスの基本的な内部構造を示しています。セグメント内のデータは、実際のデータ構造をリアルに表現するのではなく、抽象的に表現しています。
インデックス
これは概念的にはデータベースのテーブルに似ていますが、いくつかの重要な点で異なります。伝統的なリレーショナルデータベースやNoSQLデータベースのテーブルは、作成時に少なくともそのスキームを定義しておく必要があります。主キーやカラムなどの定義には明確な制約があります。しかし、Lucene インデックスにはそのような制約はありません。Lucene インデックスは、ドキュメントフォルダとして理解することができます。新しい文書をフォルダに入れることもできますし、文書を取り出すこともできますが、文書を修正したい場合は、まず文書を取り出して修正してからフォルダに戻さなければなりません。フォルダにはあらゆる種類の文書を入れることができ、Luceneではどんな内容の文書であってもインデックスをつけることができます。
ドキュメント
リレーショナルデータベースの行や文書データベースの文書と同様に、インデックスは複数の文書を含むことができます。インデックスに書き込まれた文書には一意のID、つまりシーケンス番号(通常はDocIdと呼ばれます)が割り当てられます。シーケンス番号については後ほど詳しく説明します。
フィールド
1 つのドキュメントは、1 つ以上のフィールドから構成されています。フィールドとは、Lucene におけるデータインデックスを構成する最小の定義可能な単位です。Lucene には、StringField、TextField、NumericDocValuesField など、さまざまなタイプのフィールドが用意されています。Luceneは、フィールドの種類(FieldType)に応じて、データに使用するインデックスの種類(Invert Index、Store Field、DocValues、N-dimensionalなど)を決定します。FieldとFieldTypeについては後ほど詳しく説明します。
用語と用語辞書
Luceneにおけるインデックスと検索の最小単位。フィールドは 1 つまたは複数の用語から構成されます。用語は、フィールドがアナライザ (トークナイザー) にかけられたときに生成されます。用語辞書は、用語の条件付き検索を行うための基本的なインデックスです。
セグメント
インデックスは、1 つまたは複数のサブインデックスで構成されます。サブインデックスをセグメントと呼びます。Luceneにおけるセグメントの概念設計はLSMに似ていますが、いくつかの違いがあります。セグメントはLSMのデータ書き込みの利点を継承していますが、リアルタイムに近いクエリを提供するだけで、リアルタイムではありません。
Lucene がデータを書き込む際には、まずインメモリバッファ (LSM の MemTable に似ていますが、読み込みはできません) にデータを書き込みます。バッファ内のデータが一定量に達すると、それがフラッシュされてセグメントになります。各セグメントは独立したインデックスを持ち、独立して検索可能ですが、データを変更することはできません。この方式では、ランダムな書き込みを防ぐことができます。データはBatchまたはAppendとして書き込まれ、高いスループットを実現します。Segmentに書き込まれた文書は変更できませんが、削除は可能です。削除方法は、元の内部の場所にあるファイルを変更することはありませんが、削除する文書のDocIDを別のファイルで保存することで、データファイルが変更できないようにしています。インデックスクエリでは、削除された文書の処理だけでなく、複数のSegmentsをクエリして結果をマージする必要があります。クエリを最適化するために、Luceneは複数のセグメントをマージするポリシーを持っており、この点ではLSMのSSTableのマージと似ています。
セグメントがフラッシュされたりコミットされたりする前に、データはメモリに保存され、検索不可能な状態になります。これもLuceneがリアルタイムクエリではなく、ニアリアルタイムクエリを提供すると言われている理由の一つです。コードを読んでみてわかったのですが、検索可能なデータ書き込みが実装できないわけではなく、実装が複雑なだけです。その理由は、Luceneでのデータの検索はインデックスの設定に依存しており(例えば、転置インデックスはTerm Dictionaryに依存している)、Luceneでのデータインデックスの設定はSegment flush時に行われ、リアルタイムでは行われないからです。これは、最も効率的なインデックスを設定することを目的としています。当然のことながら、書き込み時にリアルタイムでインデックスを設定する別のインデックス機構を導入することもできますが、そのような機構の実装は、現在のセグメント内のインデックスとは異なり、書き込み時に余分なインデックスと余分なクエリ機構を導入する必要があり、ある程度の複雑さを伴うものとなってしまいます。
シーケンス番号
シーケンス番号 (以下 DocId) は Lucene では重要な概念です。データベースは主キーを使って行を一意に識別しますが、LuceneのインデックスはDocをDocIdで一意に識別します。ただし、以下の点に注意が必要です。
1、DocId はインデックスに固有のものではなく、セグメントに固有のものであるということです。これは主に書き込みや圧縮を最適化するために行われています。DocIdはセグメントにしか固有ではないので、インデックスレベルでDocを一意に識別するにはどうすればよいのでしょうか?解決策は簡単です。セグメントを順番に並べるのです。簡単な例を挙げると、あるインデックスには2つのセグメントがあり、それぞれのセグメントには100件のDocがあるとします。セグメント内のDocIdは0~100ですが、インデックスレベルに変換すると、2つ目のセグメントのDocIdの範囲は100~200に変換されます。
2、DocIdはSegment内で一意であり、0から順に番号が付けられています。ただし、DocIdは連続しているわけではありません。Docが削除されると空白ができます。
3、ドキュメントに対応するDocIdは、通常はSegmentがマージされたときに変更されることがあります。
Lucene の中核となる転置インデックスは、基本的に各 Term をその Term を含むドキュメントの DocId にマッピングしたリストです。ですから、Lucene が内部で検索を行う際には、二段階のクエリを行います。第一段階では、指定した Term を含む DocId をリストアップし、第二段階ではその DocId に基づいて Doc を検索します。Luceneには、Termによる検索だけでなく、DocIdに基づいて検索する機能もあります。
DocId は基本的に 0 から始まる int32 の値であり、これは重要な最適化であり、データ圧縮やクエリの効率化にも反映されます。これには、データ圧縮のためのDeltaポリシー、ZigZagコード、転置インデックスリストで使用されるSkipListなどの最適化が含まれます。これらについては後ほど詳しく説明します。
インデックスの種類
Lucene は多くの種類のフィールドをサポートしており、各フィールドの種類によってサポートされるデータ型やインデックスモードが決まります。現在サポートされているフィールドの型は、LongPoint、TextField、StringField、NumericDocValuesField です。
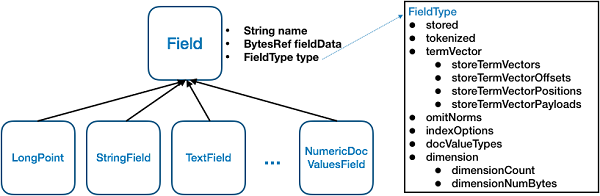
図は、Lucene における Field のさまざまな型の基本的な関係を示しています。すべての Field 型はクラス Field を継承しています。Fieldは、name(String)、fieldsData(BytesRef)、type(FieldType)の3つの主な属性を持っています。属性名はフィールドの名前、fieldsDataはフィールドの値です。すべてのタイプのフィールドの値は、最終的にはバイナリ・バイト・ストリームとして表現されます。属性typeはフィールドのタイプで、フィールドがどのようにインデックス化されるかを決定します。
FieldTypeは、多くの重要な属性を含む重要なクラスです。これらの属性の値によって、フィールドがどのようにインデックス化されるかが決まります。
Lucene には多くの異なるタイプの Field が用意されています。それらには2つの本質的な違いがあります: 1つ目の違いは、fieldDataの異なる型の値が異なる変換方法を定義していること、そして2つ目は、FieldTypeの異なる属性の異なる値の組み合わせを定義していることです。このモードでは、カスタムデータを使用して型をカスタマイズしたり、FieldTypeのインデックスパラメータを組み合わせたりすることができます。
FieldType の各属性の具体的な意味を理解するだけで、Lucene が提供できるインデックスモードを知ることができます。一つずつ見ていきましょう。
-
stored: フィールドを保存するかどうかを指定します。false を指定した場合、Lucene はフィールドの値を保存せず、クエリ結果に返されるドキュメントには保存されたフィールドのみが含まれます。
-
tokenized: トークン化するかどうかを表します。Lucene では、TextField フィールドのみをトークン化する必要があります。
-
termVector を使用しています。この記事では term vector の概念についてよく説明しています。簡単に言えば、用語ベクトルは用語に関連するすべての情報を保存するもので、用語の値、頻度、位置などが含まれます。これは文書ごとの転置インデックスであり、docidに従って文書内のすべての用語情報を検索する機能を提供します。短いフィールドに対して用語ベクトルを有効にすることは推奨されません。しかし、長いフィールドやトークン化のコストが高いフィールドに対しては、用語ベクトルを有効にすることを推奨します。用語ベクトルの用途は大きく分けて2つあります。1つはキーワードの強調表示、もう1つは文書間の類似度マッチング(more-like-this)です。
-
omitNorms:Norms は正規化の略です。Lucene では、すべてのドキュメントのすべてのフィールドに正規化係数を保存することができます。Norms の保存には 1 バイトしか必要ありませんが、文書の各フィールドには別の Norms が保存され、Norms のデータはすべてメモリに読み込まれます。そのため、Normsを有効にすると、追加のストレージスペースとメモリを消費してしまいます。しかし、Normsを無効にすると、インデックス時のブースト(elasticsearchは代わりにクエリ時にブーストを使用することを公式に推奨しています)と長さの正規化を使用することができません。
-
indexOptions:Luceneは転置インデックス用に5つのオプションパラメータ(NONE、DOCS、DOCS_AND_FREQS、DOCS_AND_FREQS_AND_POSITIONS、DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS)を提供しており、これらを使用してフィールドをインデックス化する必要があるかどうか、どのようなコンテンツをインデックス化するかを選択することができます。
-
docValuesType:DocValueはLucene 4.0で導入されたフォワードインデックス(docidからフィールドカラムストア)で、ソート、ファセット、アグリゲーションの効率を大幅に向上させます。DocValuesは強力なスキーマを持つストレージ構造であるため、DocValuesを有効にしたすべてのフィールドはまったく同じ型を持つ必要があります。現在のところLuceneでは、NUMERIC、BINARY、SORTED、SORTED_NUMERIC、SORTED_SETの5種類しか提供されていません。
dimension:Lucene は多次元データのインデックス作成をサポートしており、多次元データのクエリを最適化するための特殊なインデックス作成を採用しています。このタイプのデータの最も典型的な使用シナリオは、地理的な場所のインデックスです。これは、緯度・経度データに一般的に用いられるインデックス作成方法です。
LuceneでのStringFieldの定義を見てみましょう。

StringFieldは2種類のインデックスを定義しています。TYPE_NOT_STOREDとTYPE_STOREDです。唯一の違いは、フィールドを保存する必要があるかどうかだけです。StringField に omitNorms を選択した場合、トークン化を行わない反転インデックスが必要であることは、他の属性からも解釈できます。
Elasticsearch のデータ型
Elasticsearchでユーザが入力したドキュメント内のFieldsのインデックス化モードもLuceneのインデックス化モードに合わせて提供されています。Elasticsearchには、ユーザ定義のフィールドの他に、特定の特別な目的のために予約された独自のシステムフィールドがあります。これらのフィールドは、実質的にはLuceneのFieldsであるものにマッピングされており、ユーザ定義のFieldsと同じです。しかし、Elasticsearchでは、これらのシステムフィールドの目的に応じて、異なるインデックス作成方法が定式化されています。
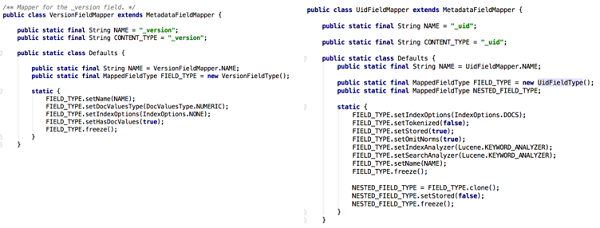
例えば、上の図は、Elasticsearchの2つのシステムフィールドのうち、_versionと_uidのFieldTypeでの定義を示しています。それぞれのインデックス作成方法を解読してみましょう。Elasticsearch は _uid フィールドでドキュメントを一意に識別し、_version フィールドでドキュメントの現在のバージョンを記録します。これら2つのフィールドのFieldTypeの定義から、_uidフィールドは転置インデックスによってインデックス化され、トークン化を必要とせず、格納する必要があることがわかります。versionフィールドは転置インデックスでインデックス付けされる必要はなく、格納する必要はありませんが、フォワードインデックスを必要とします。これは、_uidは検索されなければなりませんが、_versionは検索されないので、理解がしやすいです。ただし、_versionはdocIdによってクエリされる必要がありますが、ElasticsearchのversionMapはdocIdによって多数のクエリを実行する必要がありますが、必要なのは_versionフィールドのみです。これにより、_versionはフォワードインデックスに最も適していると言えます。
Elasticsearchにおけるシステムフィールドの完全な分析については、次の記事を参照してください。
まとめ
この記事では、主に Lucene の基本的な概念の一部と、サポートされているインデックスの種類を扱います。今後の連載では、Lucene の一部である IndexWriter の書き込み方法や、 メモリ内バッファの構造、永続化後のインデックスファイルの構造などを分析し、 Lucene がどのようにしてこのような高効率なデータインデックスを実現しているのかを理解していきたいと考えています。また、クエリを最適化するためのいくつかの特殊なデータ構造に加えて、IndexSearcher のクエリ処理についても見ていき、Lucene がなぜこのような高効率な検索とクエリを提供しているのかを理解していきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ