本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
時系列データベースの最も重要な特徴の一つは、時間の経過に伴う圧縮です。例えば、最終日のデータは5分程度のポイントに圧縮され、最終週のデータは30分程度のポイントに圧縮されています。
PostgreSQLの圧縮アルゴリズムはカスタマイズ可能です。例えば、単純平均圧縮、最大圧縮、最小圧縮、または回転ドア圧縮アルゴリズムに基づく圧縮などです。
PostgreSQLにおける回転ドアデータ圧縮アルゴリズムの実装 - IoT、監視、センサーのシナリオにおけるストリーミング圧縮の応用
本記事では、RRDデータベースを時間次元に応じて平均、最大、最小、合計、レコード数などの次元に圧縮したような簡単な圧縮シナリオを紹介しています。
また、ウィンドウクエリ、前年比比較、期間比較UDF(KNN計算を含む)、時間単位での一律書き込みなどの高度なSQLの使い方も紹介しています。
デザイン
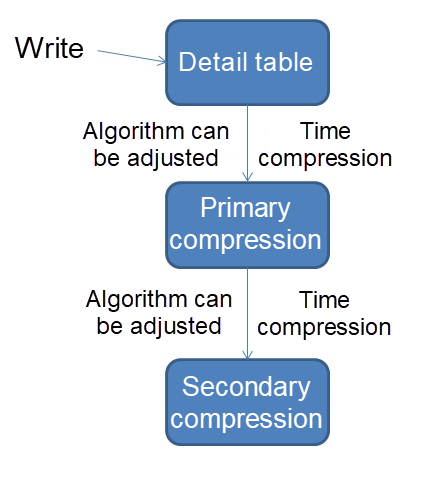
詳細テーブル
create table tbl (
id serial8 primary key, -- primary key
sid int, -- sensor ID
hid int, -- indicator D
val float8, -- collected value
ts timestamp -- acquisition time
);
create index idx_tbl on tbl(ts);
圧縮テーブル
1、 5分圧縮テーブル
create table tbl_5min (
id serial8 primary key, -- primary key
sid int, -- sensor ID
hid int, -- indicator ID
val float8, -- inheritance, average, easy to do ring analysis
ts timestamp, -- inheritance, start time, easy to do ring analysis
val_min float8, -- minimum
val_max float8, -- maximum
val_sum float8, -- and
val_count float8, -- number of acquisitions
ts_start timestamp, -- interval start time
ts_end timestamp -- interval end time
);
alter table tbl_5min inherit tbl;
2、 30分圧縮テーブル
create table tbl_30min (
id serial8 primary key, -- primary key
sid int, -- sensor ID
hid int, -- indicator ID
val float8, -- inheritance, average, easy to do ring analysis
ts timestamp, -- inheritance, start time, easy to do ring analysis
val_min float8, -- minimum
val_max float8, -- maximum
val_sum float8, -- and
val_count float8, -- number of acquisitions
ts_start timestamp, -- interval start time
ts_end timestamp -- interval end time
);
alter table tbl_30min inherit tbl;
3、5分間の圧縮文
with tmp1 as (
delete from only tbl where ts <= now()-interval '1 day' returning *
)
insert into tbl_5min
(sid, hid, val, ts, val_min, val_max, val_sum, val_count, ts_start, ts_end)
select sid, hid, avg(val) as val, min(ts) as ts, min(val) as val_min, max(val) as val_max, sum(val) as val_sum, count(*) as val_count, min(ts) as ts_start, max(ts) as ts_end from
tmp1
group by sid, hid, substring(to_char(ts, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts, 'yyyymmddhh24mi'), 11, 2)::int / 5) * 5)::text, 2, '0');
4、30分圧縮文
with tmp1 as (
delete from only tbl_5min where ts_start <= now()-interval '1 day' returning *
)
insert into tbl_30min
(sid, hid, val_min, val_max, val_sum, val_count, ts_start, ts_end)
select sid, hid, min(val_min) as val_min, max(val_max) as val_max, sum(val_sum) as val_sum, sum(val_count) as val_count, min(ts_start) as ts_start, max(ts_end) as ts_end from
tmp1
group by sid, hid, substring(to_char(ts_start, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts_start, 'yyyymmddhh24mi'), 11, 2)::int / 30) * 30)::text, 2, '0');
デモ
1、1億個の詳細なテストデータを10日間で書き込んで配布。
insert into tbl (sid, hid, val, ts) select random()*1000, random()*5, random()*100, – 1000 sensors and 5 indicators per sensor.
now()-interval '10 day' + (id * ((10*24*60*60/100000000.0)||' sec')::interval) – push back for 10 days as the starting point + (id * time taken for each record)
from generate_series(1,100000000) t(id);
2、 5分間の圧縮スケジューリング。最終日のデータについては、以下のSQLを1時間ごとにスケジューリングしています。
with tmp1 as (
delete from only tbl where ts <= now()-interval '1 day' returning *
)
insert into tbl_5min
(sid, hid, val, ts, val_min, val_max, val_sum, val_count, ts_start, ts_end)
select sid, hid, avg(val) as val, min(ts) as ts, min(val) as val_min, max(val) as val_max, sum(val) as val_sum, count(*) as val_count, min(ts) as ts_start, max(ts) as ts_end from
tmp1
group by sid, hid, substring(to_char(ts, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts, 'yyyymmddhh24mi'), 11, 2)::int / 5) * 5)::text, 2, '0');
3、 30分の圧縮スケジューリング。直近1週間のデータについては、以下のSQLを1時間ごとにスケジューリングしています。
with tmp1 as (
delete from only tbl_5min where ts_start <= now()-interval '1 day' returning *
)
insert into tbl_30min
(sid, hid, val_min, val_max, val_sum, val_count, ts_start, ts_end)
select sid, hid, min(val_min) as val_min, max(val_max) as val_max, sum(val_sum) as val_sum, sum(val_count) as val_count, min(ts_start) as ts_start, max(ts_end) as ts_end from
tmp1
group by sid, hid, substring(to_char(ts_start, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts_start, 'yyyymmddhh24mi'), 11, 2)::int / 30) * 30)::text, 2, '0');
概要
1、 時間を間隔でグループ化し、整数の除算+乗算を使用します。
例えば
5分の場合:
substring(to_char(ts, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts, 'yyyymmddhh24mi'), 11, 2)::int / 5) * 5)::text, 2, '0');
30分の場合:
substring(to_char(ts_start, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts_start, 'yyyymmddhh24mi'), 11, 2)::int / 30) * 30)::text, 2, '0')
2、 均等に分散した時系列データを生成します。PGのintervalとgenerate_seriesを使うことで、対応するintervalに書き込み時間を均等に分散させることができます。
insert into tbl (sid, hid, val, ts) select random()*1000, random()*5, random()*100, – 1000 sensors and 5 indicators per sensor.
now()-interval '10 day' + (id * ((10*24*60*60/100000000.0)||' sec')::interval) – push back for 10 days as the starting point + (id * time taken for each record)
from generate_series(1,100000000) t(id);
3、 時系列データベースの最も重要な特徴の一つは、時間の経過とともに圧縮されることです。例えば、最終日のデータは5分のポイントに圧縮され、最終週のデータは30分のポイントに圧縮されます。
PostgreSQLの圧縮アルゴリズムはカスタマイズ可能です。例えば、単純平均圧縮、最大圧縮と最小圧縮、あるいは回転ドア圧縮アルゴリズムに基づいた圧縮などです。
この記事では、RRDデータベースを時間次元に応じて平均、最大、最小、合計、レコード数、その他の次元に圧縮したような単純な圧縮シナリオを紹介します。
スケジューリングを追加します。
PostgreSQL Oracle互換性- DBMS_JOBS - 日々のメンテナンス - タイミングタスク (pgagent)
4、 圧縮後、間隔、最大値、最小値、平均値、ポイントの値が含まれています。これらの値は、グラフィックスを描画するために使用することができます。
5、PGのウィンドウ機能と組み合わせることで、前年比グラフや周期を超えたグラフを簡単に描くことができます。SQLの例は以下の通りです。
指数と加速度
create index idx_tbl_2 on tbl using btree (sid, hid, ts);
create index idx_tbl_5min_2 on tbl_5min using btree (sid, hid, ts);
create index idx_tbl_30min_2 on tbl_30min using btree (sid, hid, ts);
複合型で、周期と周期の比較の値を返します。
create type tp as (id int8, sid int, hid int, val float8, ts timestamp);
KNNアルゴリズムを含む、特定の時点の近くの指定されたSIDおよびHIDのレコードを返す、期間ごとの値関数を取得します。
create or replace function get_val(v_sid int, v_hid int, v_ts timestamp) returns tp as
$$
select t.tp from
(
select
(select (id, sid, hid, val, ts)::tp tp from only tbl where sid=1 and hid=1 and ts>= now() limit 1)
union all
select
(select (id, sid, hid, val, ts)::tp tp from only tbl where sid=1 and hid=1 and ts< now() limit 1)
) t
order by (t.tp).ts limit 1;
$$
language sql strict;
前年比、週比、月比(これらの値は、各クエリでの計算を避けるために自動的に生成することもできます)。
select
sid,
hid,
val,
lag(val) over w1, -- 同比
get_val(sid, hid, ts-interval '1 week'), -- 周环比
get_val(sid, hid, ts-interval '1 month') -- 月环比
from tbl -- where ... ,时间区间打点。
window w1 as (partition by sid, hid order by ts)
6、 PGの線形回帰と組み合わせることで、予測指標を描くことが出来ます。以下の例では、これについて詳しく説明します。
PostgreSQLの線形回帰分析を使用して予測を行う-例2は次の数日の株価終値を予測
PostgreSQLで線形回帰分析を使用する - データ予測の実装
7、 開発を容易にするために、圧縮テーブルを詳細テーブルに継承しています。これにより、UNION SQLを書く必要がなくなり、DETAILテーブルを調べるだけで、すべてのデータ(圧縮データを含む)を取得することができます。
関連事例
タイムアウト・ストリーミング - 受信メッセージのデータ例外監視を行わない
HTAPデータベースPostgreSQLのシナリオと性能テスト - 第27回 (OLTP) IoT - FEEDログ、ストリームコンピューティング、アトミック性を持つ非同期バッチ消費 (CTE)