本記事では、クラスタ内のGPUリソースの使用量を最適化する、Alibabaのオープンソースでプラグイン可能なGPU共有用スケジューリングツールを紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
クラスタのスケジューリング:KubernetesのGPU共有
クラスタスケジューリングのためのGPU共有は、より多くのモデル開発や予測サービスにGPUを共有させることで、クラスタ内のNvidia GPU利用率を向上させることを目的としています。そのためには、GPUリソースの分割が必要です。GPUリソースは、GPUビデオメモリとCUDAカーネルスレッドで分割されます。一般的に、クラスタレベルのGPU共有は、主に次の2つのことを行います。
-
スケジューリング
-
アイソレーション:この記事では主にスケジューリングについて説明します。アイソレーションソリューションでは、ユーザーは特定のアプリケーション制限パラメータを渡す必要があります(例えば、TensorFlowのper_process_gpu_memory_fractionを使用するなど)。将来的には、Nvidia MPSをベースにしたオプションが利用可能になる予定です。GPUソリューションも計画されています。
GPUカードの細かな粒度のスケジューリングについては、Kubernetesコミュニティでは現在のところ良い解決策がありません。というのも、KubernetesのGPUなどの拡張リソースの定義では、整数粒度の加減算しかサポートしておらず、複雑なリソースの割り当てには対応していないからです。例えば、Pod AでGPUカードの半分を占有したい場合、現在のKubernetesアーキテクチャの設計では、リソース割り当ての記録と呼び出しは実装できません。ここで、Multi-Card GPU Shareは実際のベクトルリソースに関するものであり、Extended Resourceはスカラーリソースを記述しています。
そこで、Kubernetesの既存のワーキングメカニズムに依存したアウトオブツリー型のShare GPU Schedulingソリューションを設計しました。
- 拡張リソース定義
- スケジューラエクステンダ機構
- デバイスプラグインの仕組み
- Kubectl拡張機構
このShare GPU Scheduling Extensionの利点は、API Server、Scheduler、Controller Manager、Kubeletなどのコアコンポーネントに侵襲性のないKubernetesの拡張機能とプラグインの仕組みを利用していることです。これにより、ユーザーはコードをリベースしたり、Kubernetesのバイナリパッケージを再構築したりすることなく、異なるバージョンのKubernetesにこのソリューションを簡単に適用することができます。
ユーザーシナリオ
- クラスタ管理者: "クラスタのGPU利用率を向上させたい。開発中は複数のユーザがモデル開発環境を共有する。”
- アプリケーション開発者:"Volta GPU上で複数のロジックタスクを同時に実行できるようにしたい”
Goal
- 利用者はAPIを介して共有リソースの申請を記述し、リソースのスケジューリングを行うことができること。
Non-Goal
- 共有リソースの分離はサポートされていない。
- オーバーセリングはサポートされていない。
設計原理
-
問題点を明確にし、設計を簡素化します。最初のステップではスケジューリングとデプロイのみを行い、その後にランタイムメモリの制御を実装します。
多くの顧客は、マルチAIアプリケーションを同じGPUにスケジューリングできるようにしたいという明確な要件を持っています。彼らはアプリケーションレベルからメモリのサイズを制御することを受け入れ、gpu_options.per_process_gpu_memory_fractionを使用してアプリケーションのメモリ使用量を制御することができます。最初に解決しなければならない問題は、メモリをスケジューリングスケールとして使用することを単純化し、メモリのサイズをパラメータの形でコンテナに転送することです。 -
押し付けがましい修正をしない
本設計では、拡張リソースの設計、スケジューラの実装、デバイスプラグインの仕組み、Kubeletの関連設計など、Kubernetesの以下の設計の核となる部分は変更しません。拡張リソースを再利用して、共有リソースのためのアプリケーションAPIを記述します。ユーザーがネイティブのKubernetes上で利用できるポータブルなソリューションを提供できるという利点があります。 -
メモリベーススケジューリングとカードベーススケジューリングのモードは、クラスタ内で共存することができます。しかし、同一ノード内では互いに排他的であり、共存はできません。この場合、リソースはカード数またはメモリ数のどちらかで割り当てられます。
詳細設計
前提:
-
Kubernetesの拡張リソースの定義はそのまま使用しますが、次元を測る最小単位がGPUカード1枚からGPUメモリのMiBに変更されています。ノードが使用するGPUが1枚カード16GiBのメモリで、それに対応するリソースが16276MiBだとします。
-
シェアGPUに対するユーザーの需要は、モデル開発やモデル予測のシナリオにあります。したがって、この場合、ユーザが適用するGPUリソースの上限は1枚を超えることはできない、すなわち、適用されるリソースの上限は1枚です。
まず、我々のタスクは、2つの新しい拡張リソースを定義することです:1つ目はGPUメモリに対応するgpu-memで、2つ目はGPUカードの枚数に対応するgpu-countです。ベクトルリソースは、この2つのスカラーリソースで記述されており、これらを組み合わせることで、Share GPUをサポートする仕組みを提供します。基本的なアーキテクチャ図は以下の通り。
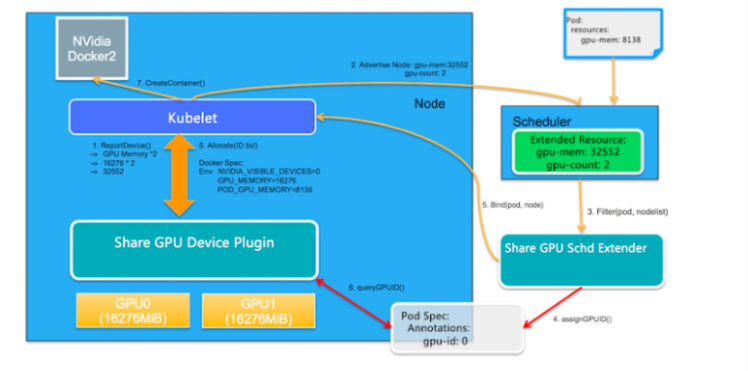
コア機能モジュール
- GPU共有スケジューラエクステンダー:Kubernetesのスケジューラ拡張機構を利用して、グローバルスケジューラがフィルタリングしてバインドした際に、ノード上の1枚のGPUカードが十分なGPU Memを提供できるかどうかを判断し、その後のフィルタリングで割り当て結果を確認するためのバインド時のアノテーションを介して、GPU割り当て結果をPod Specに記録します。
- GPU Share Device Plugin:ノード上のKubeletから呼び出されるDevice Pluginの仕組みを利用して、Scheduler Extenderのアロケーション結果に基づいてGPUカードを割り当てて実行します。
処理の詳細は以下の通りです。
- リソースレポート
GPU Share Device Pluginはnvmlライブラリを利用してGPUカードの枚数と各GPUカードのメモリを照会し、ノード上のGPUの総メモリ(数量メモリ)を拡張リソースとしてListAndWatch()を介してKubeletに報告します。そして、KubeletはそれをKubernetes API Serverに報告します。例えば、ノードに2枚のGPUカードがあり、各カードに16276MiBが含まれている場合、ノードのGPUリソースは16276 2 = 32552となり、ノード上のGPUカードの枚数が2枚であることも、ユーザーから見て追加のExtended Resourceとして報告されます。
- 拡張スケジューリング
GPU Share Scheduler Extenderは、Podへのgpu-memの割り当て中にPod Specにアノテーションの形で割り当て情報を予約し、この情報に基づいてフィルタリング時に各GPUカードに十分な利用可能なgpu-memの割り当てがあるかどうかを判断することができます。
2.1. デフォルトのKubernetesスケジューラは、すべてのフィルタアクションが実行された後、http経由でGPU Share Scheduler ExtenderのFilterメソッドを呼び出します。これは、デフォルトのスケジューラは、リソースの総量が需要を満たす空きリソースを持っているかどうかを判断することしかできず、拡張リソースを計算する際に、1枚のカードで需要が満たされているかどうかを具体的に判断することができないためです。そのため、1枚のカードに空きリソースがあるかどうかを確認するのは、GPU Share Scheduler Extenderに任されています。
以下の図を例に説明します。2枚のGPUカードを含む3ノードで構成されるKubernetesクラスタにおいて、ユーザーがgpu-mem=8138を申請すると、デフォルトのスケジューラーは全ノードをスキャンし、N1の残りのリソースが16276 * 2 - 16276 -12207 = 4069となり、リソース要求を満たしていないことが判明したため、N1ノードはフィルタリングアウトされます。
N2、N3ノードの残りリソースはともに8138MiBで、全体のスケジューリングの観点からはデフォルトスケジューラの条件を満たしています。このとき、デフォルトスケジューラは GPU Share Scheduler Extender に二次フィルタリングを委託しています。2次フィルタリングでは、GPU Share Scheduler Extenderは、シングルカードがスケジューリングの条件を満たしているかどうかを判断する必要があります。N2ノードの場合、8138MiBの利用可能なリソースを持っていることがわかりますが、各GPUカードから見た場合、GPU0とGPU1の利用可能なリソースは4069MiBしかなく、1枚のカードでは8138MiBの要求を満たすことができません。N3ノードも合計8138MiBの利用可能なリソースを持っていますが、これらの利用可能なリソースはすべてGPU0に属しており、シングルカードのスケジューリングの需要を満たしています。その結果、GPU Share Scheduler Extender のフィルタリングにより、精密な条件付きフィルタリングが可能となりました。
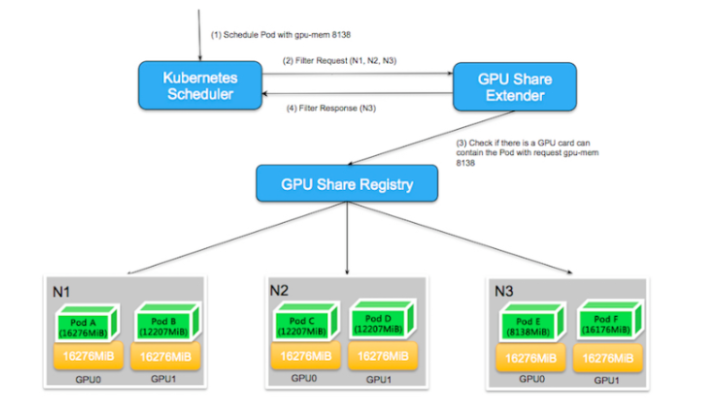
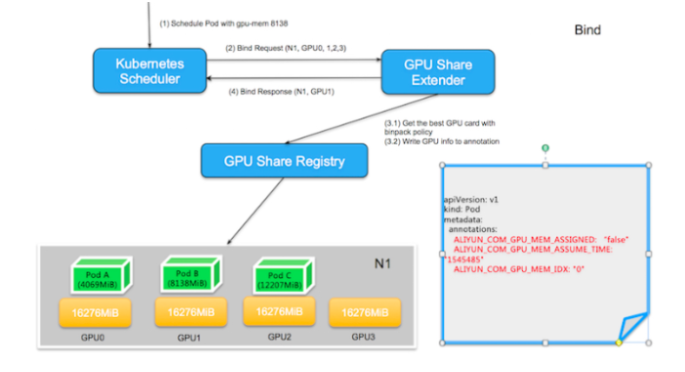
2.2. スケジューラは条件を満たすノードを見つけると、GPU Share Scheduler ExtenderのbindメソッドにノードとPodのバインドを委託します。ここで、Extenderは2つの操作を行う必要があります。
- binpackポリシーに従ってノード内の最適なGPUカードIDを見つけること。ここでいう「ベスト」とは、同一ノード内の異なるGPUカードに対して、binpackポリシーを決定条件とし、残りリソースが少なく、条件を満たす空きリソースを持つGPUカードを優先的に選択し、Podのアノテーションに
ALIYUN_COM_GPU_MEM_IDXとして保存することを意味します。また、Pod のアノテーションには、Pod が適用した GPU メモリもALIYUN_COM_GPU_MEM_PodとALIYUN_COM_GPU_MEM_ASSUME_TIMEとして保存し、この時点で選択したノードに POD をバインドします。
注:ALIYUN_COM_GPU_MEM_ASSIGNEDのPodアノテーションも保存され、"false "に初期化されます。これは、スケジューリング中にGPUカードにPodが割り当てられていることを意味しますが、実際にはノード上にPodが作成されていないことを意味します。ALIYUN_COM_GPU_MEM_ASSUME_TIMEは割り当てられた時間を表します。
割り当てられたノード上に条件を満たすGPUリソースがない場合、スケジューラはこの時点でバインディングを実行せず、エラーを報告せずに直接終了します。デフォルトのスケジューラは、assumeがタイムアウトした後にリスケジュールを行います。
- Kubernetes APIを呼び出して、ノードとPodのバインディングを実行する。
次の図に示すように、GPU Share Scheduler Extenderがgpu-mem 8138を持つPodを選択したノードN1にバインドすると、まずGPU0(12207)、GPU1(8138)、GPU2(4069)、GPU3(16276)の異なるGPUの利用可能なリソースを比較します。GPU2は、残りのリソースが要件を満たしていないために廃棄されます。条件を満たす他の3つのGPUのうち、空きリソースが条件を満たしている中でリソースの残量が最も少ないGPUカードがGPU1であるため、GPU1が選択される。
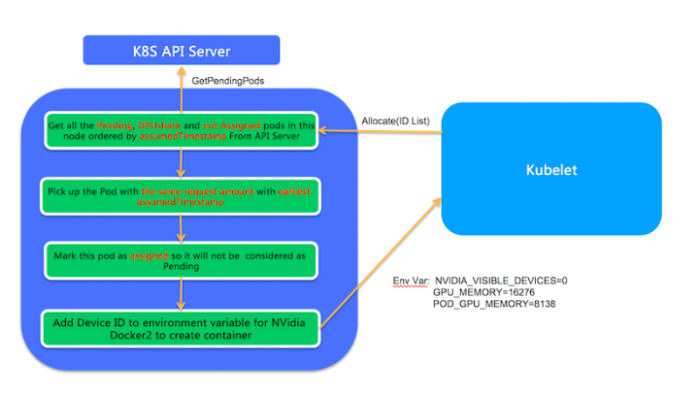
- ノード上での実行
PodがノードにバインドされているというイベントをKubeletが受信すると、Kubeletはノード上に実在のPodエンティティを作成します。この処理では、KubeletはGPU Share Device PluginのAllocateメソッドを呼び出し、AllocateメソッドのパラメータはPodが適用するgpu-memとします。Allocateメソッドでは、GPU Share Scheduler Extenderのスケジューリング決定に従って、対応するPodが実行されます。
- このノードのGPU共有Podのうち、Pending状態で
ALIYUN_COM_GPU_MEM_ASSIGNEDがfalseになっているものがすべてリストアップされます。 -
ALIYUN_COM_GPU_MEM_POD(ポッドアノテーションの)とAllocate applicationsが同じ数のポッドが選択されます。複数のPodが条件を満たす場合、最も早いALIYUN_COM_GPU_MEM_ASSUME_TIMEを持つPodが選択されます。 - ポッドアノテーションの
ALIYUN_COM_GPU_MEM_ASSIGNEDがtrueに設定され、ポッドアノテーションのGPU情報が環境変数に変換されてKubeletに戻され、真にポッドが作成されます。
関連プロジェクト
現在、プロジェクトはgithub.comでオープンソース化されています。
デプロイ
Deployment documentationを参照してください。
テストサンプル
- まず、
aliyun.com/gpu-memを使用するアプリケーションを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: binpack-1
labels:
app: binpack-1
spec:
replicas: 1
selector: # define how the deployment finds the pods it manages
matchLabels:
app: binpack-1
template: # define the pods specifications
metadata:
labels:
app: binpack-1
spec:
containers:
- name: binpack-1
image: cheyang/gpu-player:v2
resources:
limits:
# MiB
aliyun.com/gpu-mem: 1024
使用方法
Usage documentationを参照してください。
ビルド
ビルド方法を参照してください。
ロードマップ
- オプションでNvidia MPSのサポートはDevice Pluginで利用可能です。
- ソリューションは、kubeadmによって開始されたKubernetesクラスタに自動的にデプロイすることができます。
- Scheduler Extenerの可用性が向上します。
- GPU、RDMA、フレキシブルネットワークカードに対応した一般的なソリューションが提供されています。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ