この記事では、Alibaba Cloud Log ServiceとSplunkを統合して、コンプライアンス、監査、その他の関連ログをすべてSecurity Operation Center(Splunkなど)にインジェストできるようにする方法を説明します。
関連用語
1、ログサービス。Alibaba Cloud Log Service、別名Simple Log Service(SLS)。
2、SIEM:SplunkやQRadarなどのセキュリティ情報とイベント管理。
3、Splunk HEC:Splunk Http Event Collector、ログを受信するためのHTTP(s)インターフェース。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
監査関連ログ
以下の表は、ログサービスで利用可能なログのうち、セキュリティ運用チームに適用できる可能性のあるものを説明しています。

注:リージョンは定期的に更新されます。最新の状態については、製品ドキュメントを参照してください。
アリババクラウドログサービス
ログサービスはログデータのワンストップサービスとして、アリババグループの大規模ビッグデータシナリオを体験します。ログサービスを利用することで、ログデータの収集・消費・出荷・問い合わせ・分析を開発の必要なく迅速に完了させることができ、運用・保守(O&M)の効率化と業務効率の向上を実現し、DT(データテクノロジー)時代の大規模ログに対応できる処理能力を構築することができます。
アリババクラウドログサービスのアーキテクチャは以下の通りです。
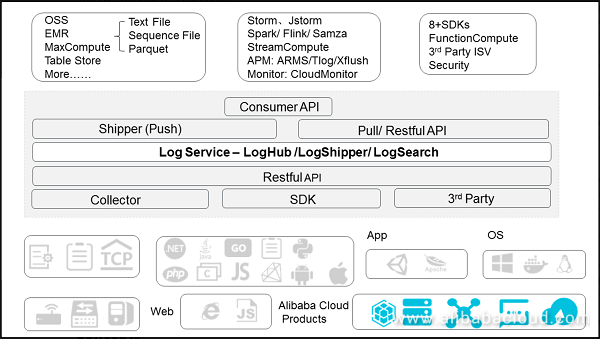
統合提案
概念
プロジェクト
プロジェクトとは、ログサービスのリソース管理単位であり、リソースの分離と制御に使用されます。
ログストア
ログストアは、ログデータの収集、保存、クエリを行うためのログサービスの単位です。各ログストアはプロジェクトに属し、各プロジェクトは複数のログストアを作成することができます。
シャード
Logstoreの読み書きログは、特定のシャードに格納する必要があります。各Logstoreは複数のシャードに分割されており、各シャードはMD5の左閉じ間隔と右開き間隔で構成されています。各間隔の範囲は他の間隔と重ならず、全ての間隔の合計範囲がMD5の値の範囲全体となります。
エンドポイント
ログサービスのエンドポイントは、プロジェクトやプロジェクト内のログにアクセスするために使用されるURLで、プロジェクトが存在するAlibaba Cloudのリージョンとプロジェクト名に関連付けられていますhttps://www.alibabacloud.com/help/doc-detail/29007.htm。
アクセスキー
Alibaba Cloud AccessKeyは、API(コンソールではなく)を利用してクラウドリソースにアクセスするために設計された「セキュアなパスワード」です。AccessKeyを利用して、ログサービスのセキュリティ認証を通過するためのAPIリクエストコンテンツに署名することができます。 https://www.alibabacloud.com/help/doc-detail/29009.htm。
前提条件
ユーザーのSIEM(Splunkなど)はクラウドではなくオンプレミスのEnvに配置されています。セキュリティを考慮して、外部EnvからSIEMにアクセスできるポートはありません。
概要
ログサービスからリアルタイムにログを消費し、Splunk API(HEC)を使ってSplunkに送信するSLS Consumer Groupでプログラムを構築するのがおすすめです。
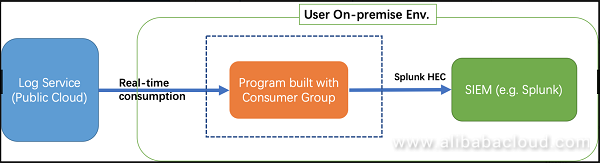
消費者グループとのプログラム
コンシューマライブラリは、Log Serviceにおけるログ消費の先進モードであり、消費側を抽象化して管理するためのコンシューマグループの概念を提供します。SDKを使って直接データを読み込むのに比べて、Log Serviceの実装の詳細や、コンシューマ間の負荷分散やフェイルオーバーなどを気にすることなく、コンシューマライブラリを使うことで、ビジネスロジックだけに集中することができます。
Spark Streaming、Storm、Flinkコネクタでは、コンシューマライブラリをベースとした実装を採用しています。
基本概念
コンシューマグループ
- コンシューマグループは複数のコンシューマで構成されます。同じコンシューマ・グループ内のコンシューマは、同じログストア内のデータを消費し、各コンシューマが消費するデータは異なります。
コンシューマ
- コンシューマは、コンシューマグループを構成する単位として、データを消費する必要があります。同じコンシューマグループ内のコンシューマの名前は一意でなければならない。
ログサービスでは、ログストアは複数のシャードを持つことができます。コンシューマライブラリは、コンシューマグループ内のコンシューマにシャードを割り当てるために使用されます。割り当てルールは以下の通りです。
各シャードは、1つのコンシューマにのみ割り当てることができます。
1つのコンシューマは同時に複数のシャードを持つことができます。
コンシューマグループに新しいコンシューマが追加された後、そのコンシューマグループのシャードの所属は、消費の負荷分散を達成するために調整されます。ただし,先行する割当ルールは変更さません。。割り当てプロセスはユーザにとって透過的です。
コンシューマライブラリはチェックポイントを保存することもでき、これはプログラム障害が解決された後にブレークポイントから始まるデータをコンシューマが消費することを可能にし、データが一度だけ消費されることを確実にします。
展開提案
ハードウエアの提案
ホストのスペック
プログラムを実行するためにはホストが必要ですが、ハードウェア仕様のLinux(例:Ubuntu x64)が推奨されます。
1、2.0+ GHZ X 8コア32G
2、1Gbps
3、2GB以上の空き容量がある場合、10GB以上の空き容量があることをお勧めします。
ネットワークのスペック
オンプレミスのエンベロープからアリババクラウドまでの帯域幅は、データ消費の速度がデータ生成の速度よりも遅くならないように十分な大きさである必要があります。
使用法 (Python)
ここでは、PythonでConsumer Groupを使ったプログラムを説明します。Javaの使い方については、こちらのドキュメントを参照してください。
注: すべての例を一つのファイルにまとめてGitHubで公開しています。
インストール
環境への配慮
1、CPythonではなくCPython3での実行を強く推奨します。
2、ログサービスのPython SDKがインストールできます。
python3 -m pip install aliyun-log-python-sdk -U
SLS Python SDKの詳しいガイドはこちらを参照してください。
プログラムの設定
以下のコードは、プログラムの設定方法を示しています。
1、診断目的のためのローカルデバッグローテーションログファイル(sync_data_to_splunk.log)
2、接続のための基本的なSLS接続とコンシューマグループのオプション
3、チューニングのための高度な消費者グループのオプション(ただし、推奨されていません)
4、SIEM(splunk)の設定と関連オプション
コメントをよく読んで、必要に応じて調整してください。
import os
import logging
from logging.handlers import RotatingFileHandler
root = logging.getLogger()
handler = RotatingFileHandler("{0}_{1}.log".format(os.path.basename(__file__), current_process().pid), maxBytes=100*1024*1024, backupCount=5)
handler.setFormatter(logging.Formatter(fmt='[%(asctime)s] - [%(threadName)s] - {%(module)s:%(funcName)s:%(lineno)d} %(levelname)s - %(message)s', datefmt='%Y-%m-%d %H:%M:%S'))
root.setLevel(logging.INFO)
root.addHandler(handler)
root.addHandler(logging.StreamHandler())
logger = logging.getLogger(__name__)
def get_option():
##########################
# Basic options
##########################
# load connection info env and consumer group name from envs
endpoint = os.environ.get('SLS_ENDPOINT', '')
accessKeyId = os.environ.get('SLS_AK_ID', '')
accessKey = os.environ.get('SLS_AK_KEY', '')
project = os.environ.get('SLS_PROJECT', '')
logstore = os.environ.get('SLS_LOGSTORE', '')
consumer_group = os.environ.get('SLS_CG', '')
##########################
# Some advanced options
##########################
# DON'T configure the consumer name especially when you need to run this program in parallel
consumer_name = "{0}-{1}".format(consumer_group, current_process().pid)
# This options is used for initialization, will be ignored once consumer group is created and each shard has been started to be consumed.
# Could be "begin", "end", "specific time format in ISO", it's log receiving time.
cursor_start_time = "2018-12-26 0:0:0"
# once a client doesn't report to server * heartbeat_interval * 2 interval, server will consider it's offline and re-assign its task to another consumer.
# thus don't set the heartbeat interval too small when the network bandwidth or performance of consumption is not so good.
heartbeat_interval = 20
# if the coming data source data is not so frequent, please don't configure it too small (<1s)
data_fetch_interval = 1
# create one consumer in the consumer group
option = LogHubConfig(endpoint, accessKeyId, accessKey, project, logstore, consumer_group, consumer_name,
cursor_position=CursorPosition.SPECIAL_TIMER_CURSOR,
cursor_start_time=cursor_start_time,
heartbeat_interval=heartbeat_interval,
data_fetch_interval=data_fetch_interval)
# Splunk options
settings = {
"host": "10.1.2.3",
"port": 80,
"token": "a023nsdu123123123",
'https': False, # optional, bool
'timeout': 120, # optional, int
'ssl_verify': True, # optional, bool
"sourcetype": "", # optional, sourcetype
"index": "", # optional, index
"source": "", # optional, source
}
return option, settings
データの消費と転送
以下のコードは、SLSから取得したデータを処理してSplunkに転送する方法を示しています。
from aliyun.log.consumer import *
from aliyun.log.pulllog_response import PullLogResponse
from multiprocessing import current_process
import time
import json
import socket
import requests
class SyncData(ConsumerProcessorBase):
"""
this consumer will keep sync data from SLS to Splunk
"""
def __init__(self, splunk_setting):
"""init the processor and verify connections with Splunk"""
super(SyncData, self).__init__() # remember to call base's init
assert splunk_setting, ValueError("You need to configure settings of remote target")
assert isinstance(splunk_setting, dict), ValueError("The settings should be dict to include necessary address and confidentials.")
self.option = splunk_setting
self.timeout = self.option.get("timeout", 120)
# Testing connectivity
s = socket.socket()
s.settimeout(self.timeout)
s.connect((self.option["host"], self.option['port']))
self.r = requests.session()
self.r.max_redirects = 1
self.r.verify = self.option.get("ssl_verify", True)
self.r.headers['Authorization'] = "Splunk {}".format(self.option['token'])
self.url = "{0}://{1}:{2}/services/collector/event".format("http" if not self.option.get('https') else "https", self.option['host'], self.option['port'])
self.default_fields = {}
if self.option.get("sourcetype"):
self.default_fields['sourcetype'] = self.option.get("sourcetype")
if self.option.get("source"):
self.default_fields['source'] = self.option.get("source")
if self.option.get("index"):
self.default_fields['index'] = self.option.get("index")
def process(self, log_groups, check_point_tracker):
logs = PullLogResponse.loggroups_to_flattern_list(log_groups, time_as_str=True, decode_bytes=True)
logger.info("Get data from shard {0}, log count: {1}".format(self.shard_id, len(logs)))
for log in logs:
# Put your sync code here to send to remote.
# the format of log is just a dict with example as below (Note, all strings are unicode):
# Python2: {u"__time__": u"12312312", u"__topic__": u"topic", u"field1": u"value1", u"field2": u"value2"}
# Python3: {"__time__": "12312312", "__topic__": "topic", "field1": "value1", "field2": "value2"}
event = {}
event.update(self.default_fields)
if log.get(u"__topic__") == 'audit_log':
# suppose we only care about audit log
event['time'] = log[u'__time__']
event['fields'] = {}
del log['__time__']
event['fields'].update(log)
data = json.dumps(event, sort_keys=True)
try:
req = self.r.post(self.url, data=data, timeout=self.timeout)
req.raise_for_status()
except Exception as err:
logger.debug("Failed to connect to remote Splunk server ({0}). Exception: {1}", self.url, err)
# TODO: add some error handling here or retry etc.
logger.info("Complete send data to remote")
self.save_checkpoint(check_point_tracker)
主制御
以下のコードは、プログラムの起動方法を示しています。
def main():
option, settings = get_monitor_option()
logger.info("*** start to consume data...")
worker = ConsumerWorker(SyncData, option, args=(settings,) )
worker.start(join=True)
if __name__ == '__main__':
main()
起動
プログラムが "sync_data.py "として保存されているとすると、"sync_data.py "として起動することができます。
export SLS_ENDPOINT=<Endpoint of your region>
export SLS_AK_ID=<YOUR AK ID>
export SLS_AK_KEY=<YOUR AK KEY>
export SLS_PROJECT=<SLS Project Name>
export SLS_LOGSTORE=<SLS Logstore Name>
export SLS_CG=<Consumer Group Name, could just be "syc_data">
python3 sync_data.py
制限と制約#####
各ログストアは最大10個のコンシューマグループを作成することができます。その数が上限を超えた場合、エラーCunsermaumerGroupQuotaExceedが報告されます。
モニター
ログサービスを使用してログを監視することができます。消費者グループのステータスを表示したり、消費者グループの監視アラームを作成することができます。
パフォーマンスの考察
複数の消費者の実行
複数の消費者が並行して処理するために、複数回分のプログラムを立ち上げることができる。
nohup python3 sync_data.py &
nohup python3 sync_data.py &
nohup python3 sync_data.py &
...
注: すべてのコンシューマは同じコンシューマグループ名を使用し、異なるコンシューマ名を使用する必要があります。1枚のシャードを消費できるのは1人の消費者だけなので、10枚のシャードを持っているとすると、最大10人の消費者が並行して消費することができます。
HTTPS
エンドポイントが https:// のように接頭辞 https://cn-beijing.log.aliyuncs.com で設定されている場合、接続は自動的に https で暗号化されます。
aliyuncs.comの証明書はGlobalSignで、デフォルトではほとんどのLinux/Windowsマシンはすでにそれを信頼しているはずです。お使いのマシンがそれを信頼していない場合は、証明書をダウンロードして、プログラムを実行しているマシンにインストールして信頼することができます。
詳細はこちらのガイドを参照してください。
スループット
テストをベースに、ネットワーク帯域のボトルネックや受信機側の速度制限(Splunk側の速度制限)がないことを確認した上で、上記の例をpython3を使用して、推奨されるハードウェア仕様で起動してみました。各コンシューマは、1つのCPUコアの20%以下のCPUコアを使用して、生のログサイズで最大2MB/sを消費することができます。したがって、理論的には1CPUコアあたり50MB/s、つまり1CPUコアあたり約0.9TB/日ということになります。
注: これは、帯域幅、ハードウェアの仕様、SIEM (Splunk など) がデータを受信する速度、およびシャードの数に大きく依存します。
高可用性
コンシューマグループはサーバ側のチェックポイントを節約するので、サーバ側のチェックポイントを節約することができます。1つのコンシューマが停止すると、他のコンシューマがそのシャードを引き継いで継続的に消費します。
また、別のマシンでコンシューマを起動して、あるマシンが停止したり壊れたりしたときに、別のマシンのコンシューマが自動的にタスクを引き継ぐようにすることもできます。
バックアップのために、シャードの数よりも多くのコンシューマーを起動することができます。
参考
1、ログサービス製品ページ ログサービスの公式製品ページです。
2、ログサービスのラーニングパスでは、ログサービスの利用開始方法や、本製品の人気機能、ドキュメントを掲載しています。
3、ログサービス公式ドキュメントには、ログサービスに関連するすべての技術文書が掲載されています。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
[アリババクラウドジャパン公式ページ] (https://www.alibabacloud.com/ja)