成功したWebシステムで信頼できるプラットフォームモジュールを構築するには、データのセキュリティを確保し、比較的信頼できるフロントエンド環境を構築する必要があります。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。

序章
情報セキュリティ分野における魅力的な目的として、信頼されたシステムとは、特定のセキュリティポリシーを実行することで、一定の信頼性を実現するシステムのことを指します。
コンピュータでは、すでにTrusted Platform Module(TPM)が使用されており、Trusted Computing Group(TCG)が定めるTPMの仕様に準拠しています。TPMは、信頼されたシステムを実現するために設計された安全なチップです。TPMは信頼されたシステムの根幹であり、信頼されたコンピューティングのコアモジュールであり、コンピュータのセキュリティをしっかりと保護します。

私たちのWebシステムでは、「クライアントの入力を絶対に信用しない」というのがセキュリティの基本的なガイドラインであるのに対し、信頼できるシステムを構築することは擬似的な命題のように思えます。実際には、システムの信頼性が絶対的なセキュリティを意味するわけではなく、ウィキペディアは次のように説明しています:ユーザーにとって、「信頼される」というのは、実際には「信頼できる」という意味ではありません。正確には、設計者やソフトウェア開発者が禁止している動作を行うのではなく、信頼されたシステムの動作が完全に設計に沿ったものであることを完全に確信できるということです。
このような観点から、あなたはそれを魅力的なビジョンとして見ることができますし、あなたは単に悪意のある行動を低確率に制限するために、WebシステムにTPMを構築し、比較的信頼できるWebシステムを実装したいと願っているだけです。
信頼できるフロントエンド
信頼されたシステムでは、TPMの重要な特徴の一つは、端末が信頼されていることを保証するために、メッセージの真正性を識別することです。Webシステムでは、メッセージの発信元はユーザである。搾取データベースや悪意のある登録、解約の拡散に伴い、ユーザーデータを保護するために、様々なシナリオで真正なユーザーのリクエストデータ識別が必須になってきています。
WebシステムでTPMを成功させるためには、まず入力データが安全であることを確認し、比較的信頼できるフロントエンド環境を構築する必要があります。しかし、フロントエンドがデータ収集の最前線として機能している間、ウェブシステムはネイティブにオープンであるため、JavaScriptのコードは常に公開されています。このような状況では、悪意のある偽造を防ぐことが難しくなり、信頼できるフロントエンドの実装は難しいものとなります。
1. なぜJavaScriptを難読化するのか?
JavaScript難読化の導入は、明らかにフロントエンドのコードロジックを保護するためです。
Webシステム開発の初期段階では、JavaScriptはWebシステムで大きな役割を果たすことはなく、単にフォームを送信するだけでした。JavaScriptファイルは非常にシンプルで、特別な保護は必要ありませんでした。
JavaScriptファイルの量が急増すると、JavaScriptの量を減らし、HTTP転送効率を向上させるために、uglify、compressor、clouserなどのJavaScript圧縮ツールがいくつかリリースされました。これらのツールは以下のことができます。
· Merge multiple JavaScript files;
· Remove spaces and line breaks from JavaScript code;
· Compress variable names in JavaScript files;
· Remove annotations.
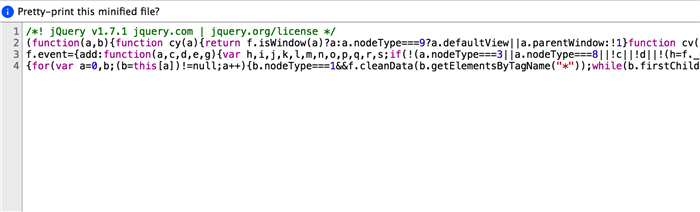
[圧縮コード]
圧縮ツールの設計は、JavaScriptファイルのサイズを小さくするのを助けることですが、圧縮されたコードは、はるかに低い可読性を作成し、副作用としてコードを保護します。そのため、JavaScriptファイルの圧縮は、フロントエンドの公開における標準的なステップとなります。しかし、ChromeやFirefoxなどの市場で利用可能な主流ブラウザが、圧縮されたJavaScriptコードを素早く再配列し、強力なデバッグ機能を提供するためのJavaScriptフォーマットのサポートを開始すると、この方法では悪意のあるユーザーに対する強固な保護を提供することはできなくなります。
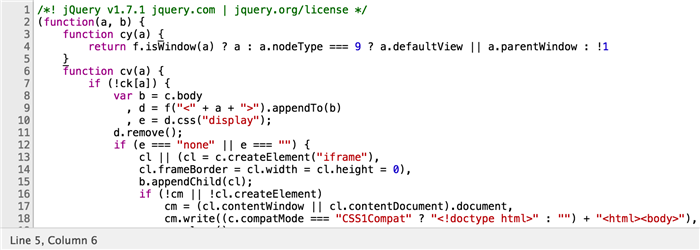
[Chrome開発者ツールでフォーマットされたコード]
ますます多くのウェブアプリケーションが登場し、ブラウザのパフォーマンスとネットワークアクセスの速度が向上する一方で、JavaScriptのワークロードシェアが高くなり、バックエンドのロジックの多くがフロントエンドに移行されています。一方で、より多くの犯罪者がそれを利用し始めています。ウェブモデルでは、通常、JavaScriptはそれらの犯罪者の突破口となる。フロントエンドのロジックを学ぶことで、犯罪者は一般的なユーザーとして悪意のある行動を行うことができます。その中で、重要なサービスやリスク管理システムのJavaScriptコードは、ログインページ、サインアップページ、決済ページ、トランザクションページなど、ハッキングに対する高いセキュリティが求められています。ここで、JavaScriptの難読化が明らかになります。
2. JavaScript難読化のロバスト性
JavaScript の難読化が十分に堅牢であるかどうかは、以前から話題になっていました。実際、コード難読化は、プログラマがコード難読化とシェル暗号化でほとんどのソフトウェアプログラムを再処理してコードを保護していたデスクトップソフトウェア時代に早くも登場しました。Javaと.NETはどちらも独自の難読化機能を持っています。ハッカーはこれをよく知っており、多くのウイルス対策プログラムは、ウイルス対策のために高度に難読化されています。しかし、JavaScriptは動的なスクリプト言語であり、HTTPでのソースコードの転送やリバースエンジニアリングは、コンパイルされたソフトウェアを解凍するよりもはるかに簡単であるため、多くのユーザーは難読化を冗長なものと見なしています。

[.NET難読化ツール、dotFuscator]
一方で、JavaScriptはソースコードを転送するため、難読化が必要であり、公開されたコードは常にリスクを伴います。一方で、精巧な難読化コードは悪意のあるユーザーには厳しく、開発者にとってはより多くの時間を節約することができます。クラッキングと比較して、難読化コードはより手頃な価格で、高強度のコード耐性でクラッカーの作業量を劇的に増加させ、防御的な役割を果たすことができます。このような観点から、鍵となるコードを難読化することは不可欠です。
3. JavaScriptの難読化方法
通常、JavaScriptの難読化装置は2つの分類に分けて存在します。
- 正規表現の置換によって実装された難読化ツール
- 構文ツリーの置換によって実装された難読化装置
前者のタイプの難読化装置は、低コストでありながら適度な機能を備えており、難読化を必要としないシナリオに適しています。後者のタイプの難読化装置は、コストは高いが柔軟性とセキュリティが高く、抵抗性の高いシナリオに最適です。次の図に後者のタイプの詳細を示します。構文ベースの難読化器はコンパイラによく似ており、どちらも基本的な原理は似ています。まず、コンパイラについて探っていきます。
用語と略語
トークン:トークンは、辞書的な単位(辞書的マーカーとして知られている)として、辞書解析器によって生成され、分割テキストストリームの最小単位となります。
AST:構文解析器は、抽象構文ツリーを生成し、ソースコードの抽象構文構造のツリー状の存在を持ちます。
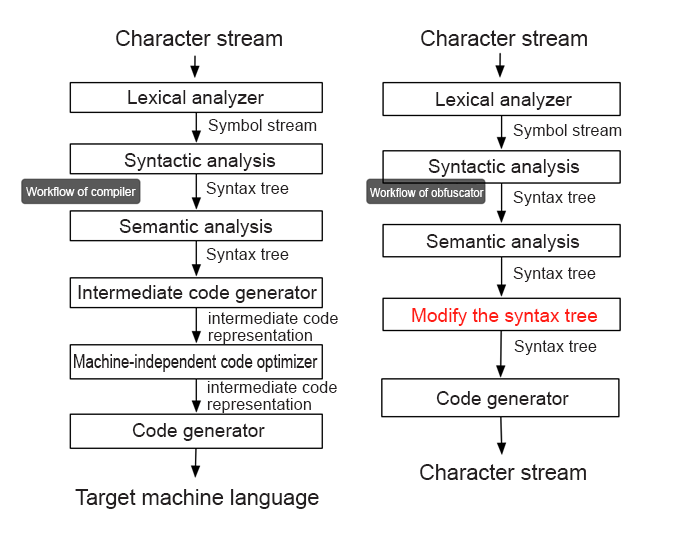
[コンパイラ vs. 難読化ツール]
コンパイラのワークフロー
簡単に言えば、システムが文字列テキスト(ソースコード)を読み込むと、字句解析器はそれを小さな単位(トークン)に分割します。例えば、一桁の数字1はトークンであり、文字列 "abc "は別のトークンです。次に、構文解析器は、これらの小さな単位を、異なるトークンの構成関係を表すツリー(AST)に整理します。例えば、中央のトークンが加算を示す一方で、左右のノードがトークン-1とトークン-2である加算ツリーとして「1+2」を表示することができる。そして、コンパイラは、生成されたASTに基づいて中間コードを生成し、最終的にマシンコードに変換します。
難読化装置のワークフロー
コンパイラはソースコードを中間コードやマシンコードに翻訳する必要がありますが、難読化ツールの出力はJavaScriptのコードのままであり、構文解析に続くステップを必要としません。また、ここでの目的は、元の JavaScript コードの構造を変更することです。この構造は何に対応しているのでしょうか?それはASTに対応しており、正しく開発されたJavaScriptコードであれば、どのようなものでもASTを構築することができます。同様に、ASTは異なるトークンの論理関係を表しているので、JavaScriptコードを生成することもできます。このように、ASTを構築するだけで任意のJavaScriptコードを生成することができます。上図の右手は難読化処理の様子を示しています。
ASTを修正することで、新しいJavaScriptコードに対応したASTを作成することができます。
企画・設計
難読化のプロセスを学ぶと、設計と計画が最も重要な部分になります。前述したように、ASTを生成することで、元のコードとは異なるJavaScriptのコードが生成されます。しかし、難読化は元のコードの実行結果を崩してはいけません。したがって、難読化ルールは、コードの実行結果が変わらない間、コードが読みにくくなることを確実にしなければなりません。
開発者は、文字列や配列を分割したり、無駄なコードを追加するなど、特定の要件に応じて難読化ルールをカスタマイズすることができます。

実装
字句解析や構文解析は、コンパイルの原理を深く理解する必要があるため、このステップは多くのユーザーにとって困難なものになるかもしれません。それを理解するためのツールに頼ることができます。そのようなツールを使えば、ASTを修正するという最後のステップに直接進むことができます。
多くの市販のJavaScript字句解析・構文解析ツールは、v8、SpiderMonkey for Mozilla、esprimaなど、簡単にアクセスできます。以下では、nodejsベースのパーサーである推奨のuglifyについて説明します。このツールには以下のような機能があります。
· Parser - which can parse JavaScript code as the AST
· Code generator - which can generate code by using the AST
· Scope analyzer - which can analyze definitions of variables
· Tree walker - which can traverse tree nodes
· Tree transformer - which can change tree nodes
上で提供された難読化器の設計スケッチを確認すると、構文ツリーを変更しただけであることがわかります。
例
難読化ツールの設計方法を理解するために、以下の簡単な例では、「var a = 1」の「1」という数字を難読化ルールで16進数に変換する方法を詳しく説明しています。まず、ソースコードに対して字句解析と構文解析を行い、uglifyメソッドを使って簡単に構文ツリーを生成します。次に、シンタックスツリーから数字を探し出し、以下のように16進数に変換します。
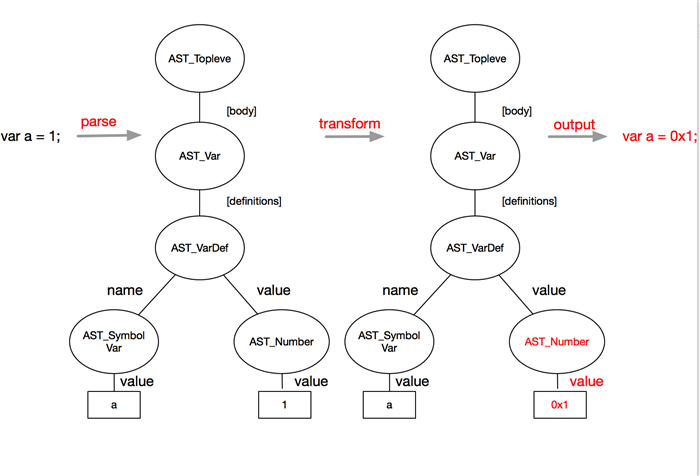
例のコード
var UglifyJS = require("uglify-js");
var code = "var a = 1;";
var toplevel = UglifyJS.parse(code); //toplevel is actually the syntax tree.
var transformer = new UglifyJS.TreeTransformer(function (node) {
if (node instanceof UglifyJS.AST_Number) { //Locate the leaf node that needs to be modified.
node.value = '0x' + Number(node.value).toString(16);
return node; //A new leaf node is returned to replace the original leaf node.
};
});
toplevel.transform(transformer); //Traverse the AST.
var ncode = toplevel.print_to_string(); //Restore to strings from the AST.
console.log(ncode); // var a = 0x1;
上の簡単なコードを見ると、まず構文ツリーをparseメソッドを使って構築し、TreeTransformerを使ってツリーをなぞる必要があることが理解できると思います。UglifyJS.AST_Number型のノードをたどると(AST型の完全なリストはASTを参照)、このノードのトークンには "value "という属性があり、数値型の特定の値が格納されています。そして、値を16進数形式に変更し、"return node "を実行して元のノードを新しいノードに置き換えます。
結果
以下に難読化前と難読化後のコードを示します。

4. 難読化がパフォーマンスに与える影響
無駄なコードが追加されると、元のASTが変更され、難読化がパフォーマンスに影響を与えます。にもかかわらず、難読化ルールを使用して影響を最小限に抑えることができます。
· Reduce cyclic obfuscation as too many obfuscations can impact code execution efficiency
· Avoid too many concatenated strings as string concatenation imposes performance issues in earlier versions of IE
· Control code volume - Specifically, control the proportion of inserted waste code as an oversized file can exhaust network request and code execution performance.
難読化ルールを使用することで、パフォーマンスへの影響を合理的な程度に絞り込むことができます。実際、難読化ルールの中にはコードの実行を高速化するものさえあります。例えば、変数名と属性名の圧縮難読化はファイルサイズを小さくすることができ、グローバル変数の複製はアクションスコープのルックアップを最小限に抑えることができます。最近のブラウザでは、難読化はコードにほとんど影響を与えず、合理的な難読化ルールを導入した後は自信を持って難読化を使用することができます。
5. 難読化のセキュリティ
難読化の目的は、元の機能を損なうことなくコードを保護することです。
難読化後のASTは元のASTとは異なるが、難読化後のファイルと元のファイルの実行結果は同じでなければならないことを考えると、コードの実行を中断することなく十分な難読化強度を確保するにはどうすればよいのでしょうか?この問題を解決するためには、カバレッジの高いテストが必要です。
· Develop detailed unit tests for obfuscators
· Perform high-coverage functional tests on obfuscation target code to ensure that the execution results of the pre- and post-obfuscation code are consistent
· Perform multi-sample tests to obfuscate the class libraries complemented by unit tests, such as obfuscating jQuery and AngularJS. Then, perform those unit tests again using the obfuscated code and ensure that the execution results are the same before and after the obfuscation.
概要
どのような企業にとっても、信頼できるWebシステムを構築することはビジョンの一部であり、信頼できるフロントエンド環境を構築することは、信頼できるWebシステムの要件です。そのためには、コード耐性のための JavaScript 難読化が必要であり、難読化装置の実装は実行可能なプロセスです。また、難読化のパフォーマンスへの影響をコントロールできるため、信頼されたWebシステムを構築しやすくなるのでおすすめです。
参考文献
https://en.wikipedia.org/wiki/Trusted_Platform_Module
https://en.wikipedia.org/wiki/Trusted_system
http://lisperator.net/uglifyjs
http://esprima.org
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ