この記事では、トラブルシューティングを容易にし、合理化するために、Kubernetes Cluster Nodesのよくわからない問題やシステムコンポーネントを説明し、分析しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
常に発生する問題
NotReady
Alibaba Cloudには独自のKubernetesコンテナクラスタがあり、Kubernetesクラスタの出荷が急増する中、オンラインユーザーは非常に低い確率でノードがNotReady状態になっていることに気づきます。毎月1~2名のお客様がこの問題に遭遇しています。
ノードがNotReady状態にあると、クラスタ内のマスターノードは特定のノードを制御することができません。たとえば、新しいポッドを配信したり、ノード上で実行中のポッドに関するリアルタイムの情報を取得したりすることができます。

Kubernetesについての知識
Kubernetesクラスタの "ハードウェアベース "とは、シングルノードシステムの形をしたクラスタノードのことです。このようなノードは、物理マシンまたは仮想マシンのいずれかです。クラスタノードには、マスターノードとワーカーノードがあります。マスターノードはスケジューラやコントローラなどのクラスタ制御コンポーネントをロードし、ワーカーノードはビジネスを実行します。
Kubeletは各ノード上で動作するプロキシであり、制御コンポーネントと通信し、制御コンポーネントの命令に従ってワーカーノードを管理します。
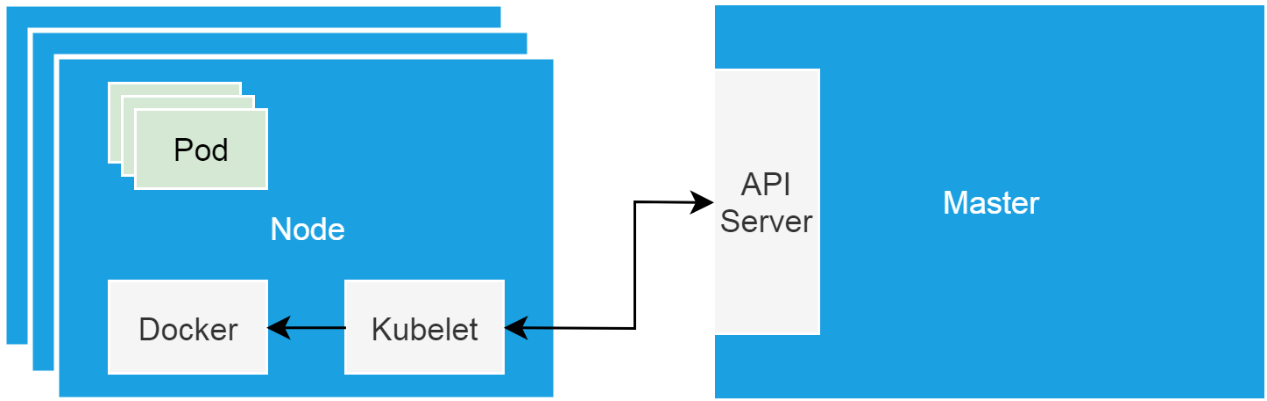
クラスタノードがNotReady状態になった場合、そのノードで実行しているkubeletが正常かどうかを確認してください。この問題が発生した場合、systemctlコマンドを実行してkubeletの状態を確認します。Systemd が管理するデーモンとして正常に動作することを確認してください。kubelet のログを見るために journalctl コマンドを実行すると、以下のようなエラーが発生します。

Podのライフサイクルイベントジェネレータ(PLEG)
エラーは、コンテナランタイムが動作せず、Podのライフサイクルイベントジェネレータ (PLEG) が不健全であることを示しています。コンテナランタイムはdockerデーモンを示しています。Kubelet は docker デーモンを動作させることでコンテナのライフサイクルを制御します。PLEGはkubeletがコンテナランタイムをチェックするために使うヘルスチェックの仕組みです。また、ポーリングモードでkubeletを使用してコンテナランタイムをチェックします。
しかし、ポーリングモードにするとコストがかかります。そこで、PLEGを開発しました。PLEGはポーリングと割り込みの両方のメカニズムを使用していますが、"割り込み "モードでコンテナランタイムの健全性をチェックしています。
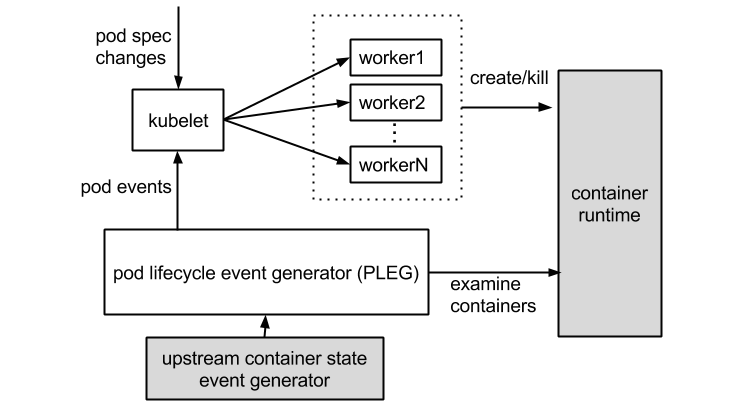
先行するエラーに応じて、コンテナ実行時に不具合があるかどうかを判断します。i新しいコンテナを実行するためにdockerコマンドを実行しても、コマンドが応答しない場合は、先行するエラーに関する仮定が正確であることを示しています。
コンテナのランタイム
Dockerデーモンコールスタックの分析
DockerはAlibaba Cloud Kubernetesクラスタで使用されるコンテナランタイムです。1.11以降のバージョンでは、OCI標準に適応するためにDockerを複数のコンポーネントに分割しています。分割後は、Dockerデーモン、containerd、containerd-shim、runCが含まれています。containerdコンポーネントはクラスタノード上のコンテナのライフサイクルを管理し、DockerデーモンのためのgRPCインターフェースを提供します。
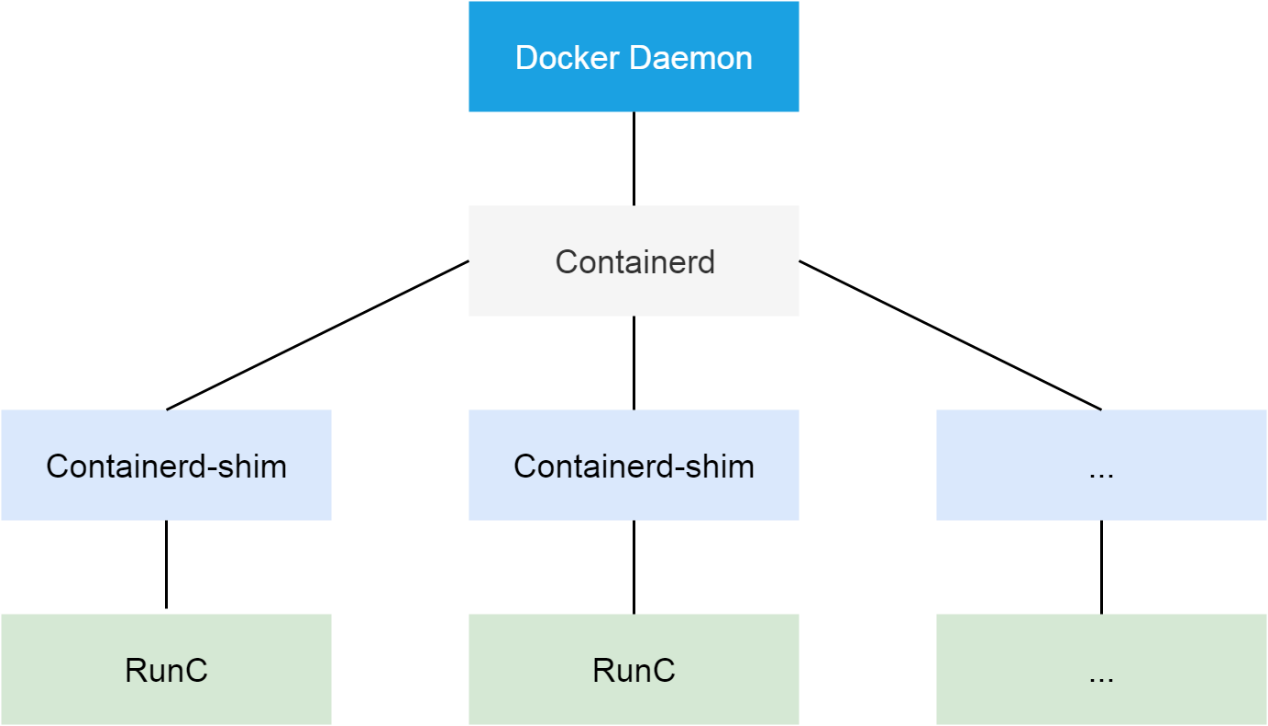
ここで、PLEGはコンテナが正常に動作していないと判断します。そのため、Docker デーモンから起動する必要があります。kill -USR1 <pid> コマンドを実行して、USR1 シグナルを Docker デーモンに送信します。シグナルを受信したDockerデーモンは、そのスレッドのコールスタックをすべてfile/var/run/dockerフォルダに出力します。
Dockerデーモンのコールスタックは比較的簡単に解析できます。ほとんどのコールスタックは下図のようなものであることに注意してください。
スタック上の各関数の名前と、その関数が配置されているファイルやモジュールの名前によると、コールスタックの下半分は、受信したHTTPリクエストをルーティングする処理です。前半は実際の処理関数です。最後に、処理関数は待ち状態に入り、ミューテックスインスタンスを待ちます。
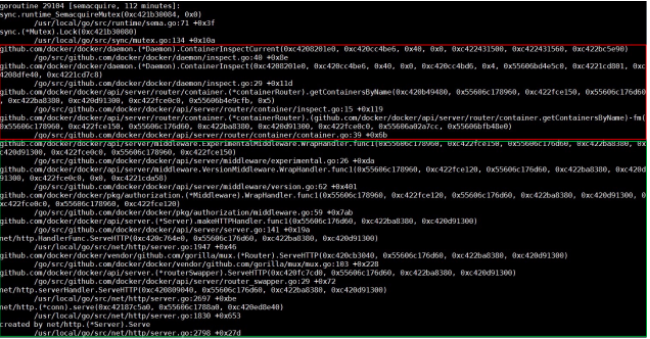
では、ContainerInspectCurrent関数の実装を確認してみましょう。この関数の最初のパラメータがミューテックスポインタであることを理解することが重要です。このポインタを使ってコールスタックファイル全体を検索し、ミューテックスポインタ上で待機しているすべてのスレッドを見つけます。また、次の図に示すスレッドを参照してください。
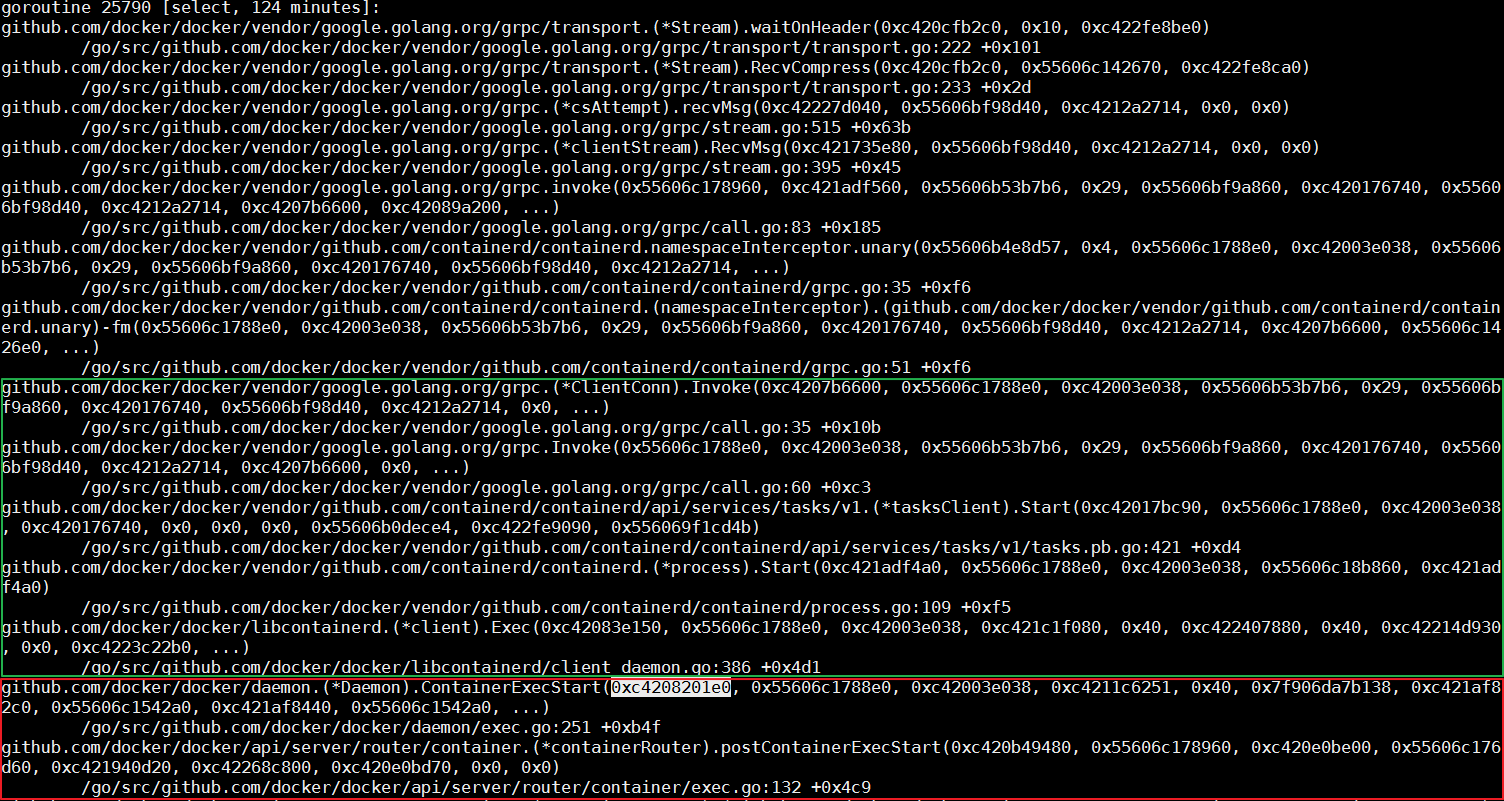
スレッド内では、ContainerExecStart関数は特定のリクエストを処理している間にmutexパラメータを受け取ります。しかし、ContainerExecStart関数はMutexを待たずにMutexの所有権を取り、実行ロジックをcontainerd呼び出しに回しています。コードを使用して、同じことを検証してください。
前述したように、containerdはdockerデーモンのためのgRPCインターフェースを提供しています。呼び出しスタックの前半は、dockerデーモンがgRPCリクエストを介してcontainerdを呼び出していることを示しています。
コンテナドのコールスタックの解析
Dockerデーモンと同様に、kill -SIGUSR1 <pid>コマンドを実行すると、containerdのコールスタックが出力されます。違いは、コールスタックはメッセージログに出力されますが、フォルダには出力されない点です。
containerdはgRPCサーバとして、Dockerデーモンからのリモートリクエストを受けてから処理を行うスレッドを作成します。ここではgRPCについての詳細に注目する必要はありません。リクエストのクライアントコールスタック上で、コールのコア関数がStartプロセスであることを確認します。containerdのコールスタックでStart、Process、process.goなどのフィールドを検索しながら、下図のようなスレッドを簡単に見つけることができます。
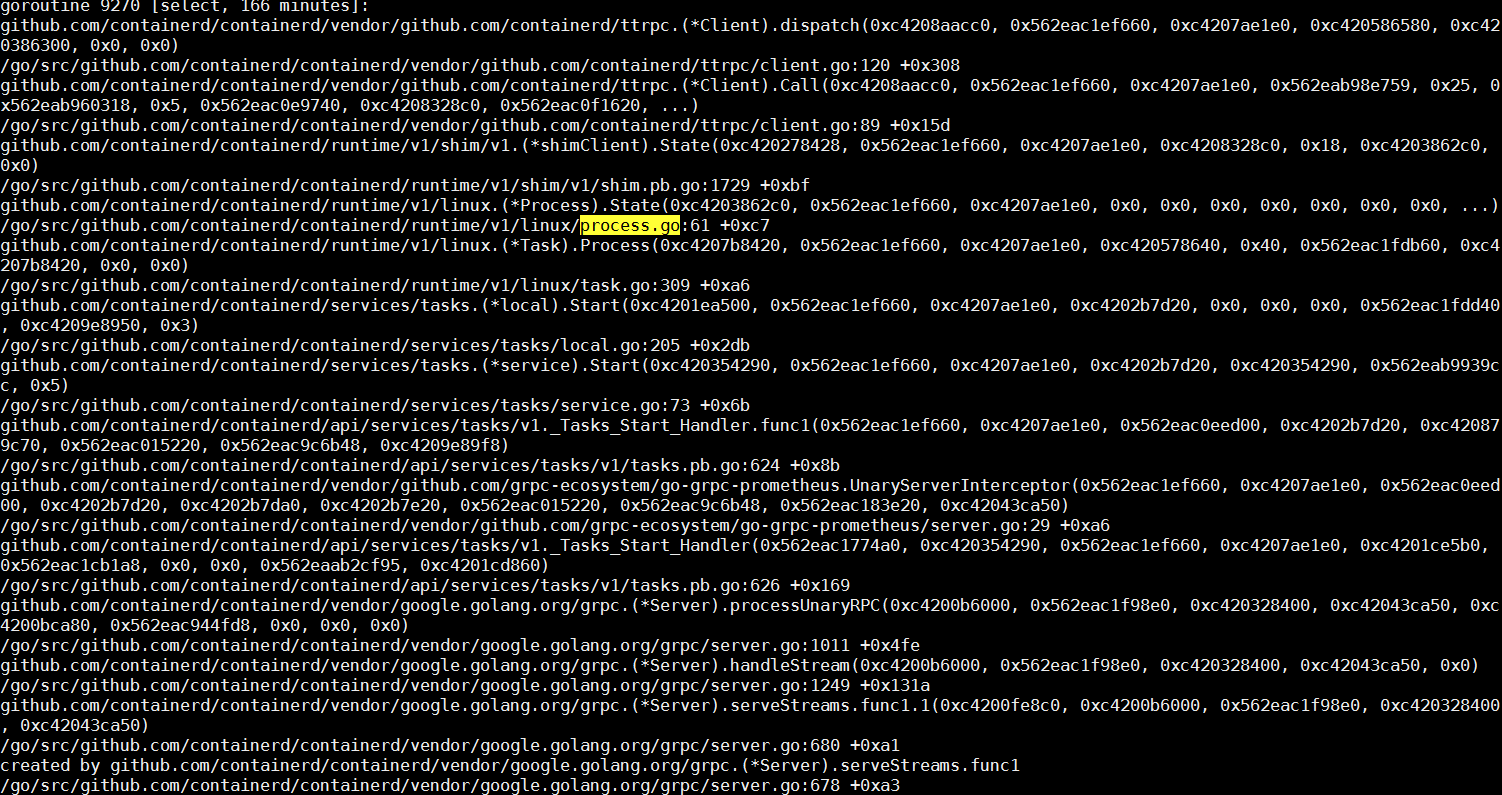
このスレッドの中心的なタスクは、runCに依存してコンテナプロセスを作成することです。コンテナが起動した後、runCプロセスは終了します。次に、runCが正常にタスクを完了したかどうかを確認します。プロセスリストの中には、システム内でまだ動いているrunCプロセスがいくつかありますが、これは想定外です。
コンテナの起動にかかる時間は、プロセスの起動にかかる時間とほぼ同じです。runCプロセスがシステム内で実行されている場合、runCはコンテナを起動することができません。
D-Bus
runC D-Busを要求する
コンテナランタイムのrunCコマンドは、libcontainerを簡単にカプセル化したものです。このツールは、コンテナの作成やコンテナの削除など、1つのコンテナを管理します。前節の最後に、runCではコンテナを作成できないことを述べました。対応するプロセスをキルしてから、コマンドラインで同じコマンドを実行してコンテナを起動し、straceを使って全体のプロセスを追跡します。
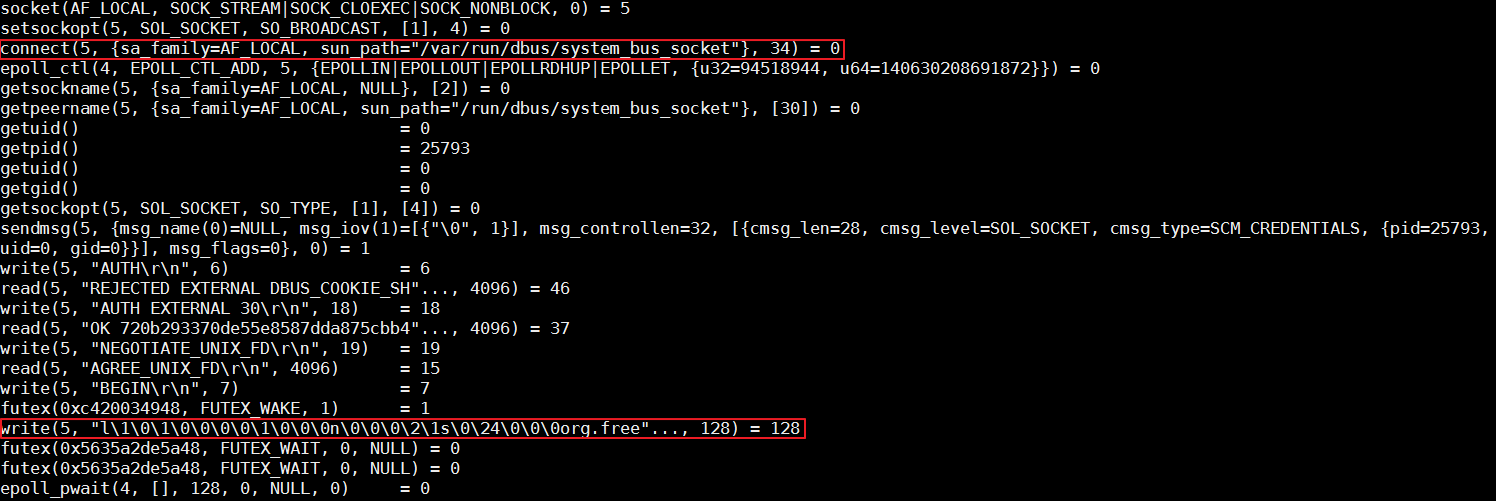
解析によると、runCはorg.free fieldでD-Busへのデータ書き込みを停止しています。Linuxでは、D-Busはプロセス間メッセージングの仕組みです。
busctlコマンドを実行して、システム内の既存のバスをすべてリストアップします。この問題が発生すると、Nameで指定されたクラスタノード番号が非常に大きくなります。そのため、Name のようないくつかの D-Bus データ構造が排出され、この問題が発生します。
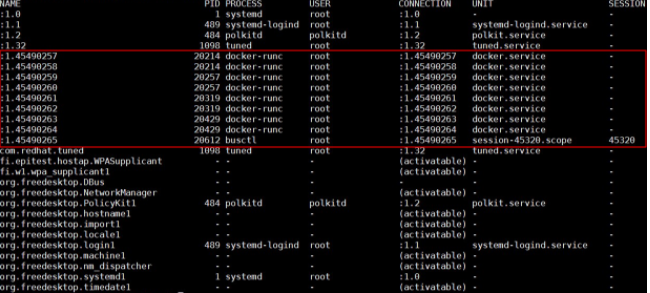
D-Busメカニズムの実装はdbus-daemonコンポーネントに依存します。D-Busデータ構造が枯渇した場合、問題を解決するためにデーモンを再起動します。しかし、問題はそれほど単純ではありません。dbus-daemonコンポーネントが再起動された後も問題は継続します。
runCをトレースするためにstraceが使用されている前の図では、org.freeフィールドを持つバスでrunCのデータ書き込みがブロックされています。busctlコマンドのバスリスト出力では、フィールドのあるバスはSystemdで使用されています。
その後、Systemdを再起動するためにsystemctl daemon-reexecコマンドを実行すると、issueは消えます。このように、Systemdに関連した問題である可能性があると判断されました。
タフなSystemdの問題
Systemdは、特に開発作業をしたことがない人にとっては非常に複雑なコンポーネントです。基本的にSystemdのトラブルシューティングには、デバッグログ、コアダンプ、コード解析、ライブデバッグの4つの方法があります。
無駄なコアダンプから始めて、デバッグログ、コード解析、ライブデバッグに応じて、問題の原因を探ってみましょう。
役に立たないコアダンプ
この問題は、D-BusとSystemdを通信に使用しているときにrunCが応答しないことを示しており、Systemdの再起動で解決します。そのため、まず、Systemdに関連する重要なスレッドがロックされているかどうかを確認します。コアダンプで全てのスレッドを確認します。
以下のスレッドだけが使用されていますが、ロックされていません。D-Busイベントの応答を待っています。

散在する情報
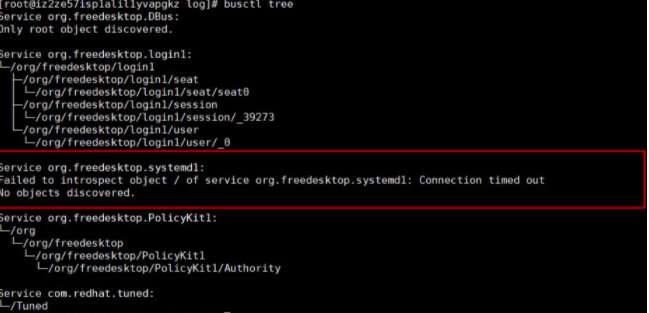
busctl tree コマンドを実行して、すべてのバスの公開インターフェースを出力します。出力によると、 org.freedesktop.systemd1 バスはインターフェースの問い合わせ要求に応答できません。
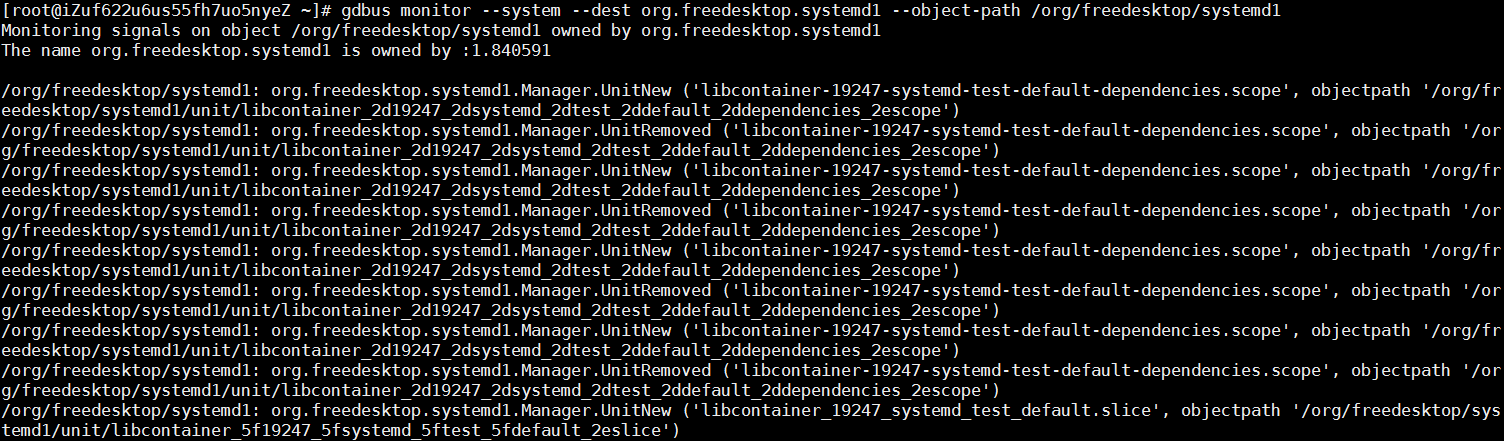
以下のコマンドを実行して、org.freedesktop.systemd1で受信したすべてのリクエストを確認します。正常なシステムでは大量のユニット作成・削除操作を示すメッセージが表示されますが、障害のあるシステムではバス上にメッセージは表示されません。
gdbus monitor --system --dest org.freedesktop.systemd1 --object-path /org/freedesktop/systemd1
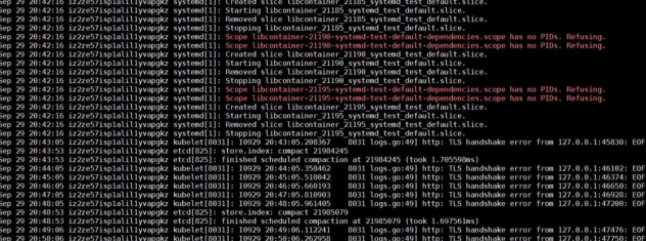
問題発生前後のシステムログを解析すると、runCがlibcontainer_%d_systemd_test_default.sliceテストを繰り返し実行していることがわかります。このテストは非常に頻繁に実行されていますが、問題が発生すると停止します。そのため、この問題はテストが大きく関係している可能性があります。
さらに、Systemdは、Systemd-analyzeコマンドを実行中に「Operation not supported」エラーを報告し、Systemdのデバッグログにアクセスします。
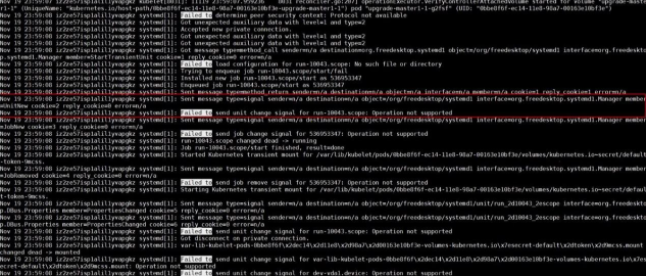
先の散らばった情報によると、大量の単位作成・削除操作の後、org.freedesktop.systemd1バスが応答しないと結論づけられています。頻繁な単位作成・削除操作の間、runCのチェックインは、Systemdのいくつかの機能が利用可能かどうかをテストするために、UseSystemd関数を書き換えます。UseSystemd 関数は、コンテナの作成中やコンテナのパフォーマンスの表示中など、多くの状況で呼び出されます。
コード解析
この問題は、すべてのオンラインKubernetesクラスタで月に2回程度の頻度で発生します。この問題は継続しており、問題が発生した後にSystemdを再起動するだけで解決することができますが、これは非常にリスクが高いです。
バグはSystemdとrunCのコミュニティにそれぞれ投稿することができます。しかし、これらのコミュニティにはAlibaba Cloudのようなオンライン環境がなく、この問題が再現される確率はほぼゼロに近い。そのため、コミュニティに頼るのではなく、自分の力で解決するように努力してください。
前節の最後に、問題が発生したときにSystemdが「操作がサポートされていません」というエラーを報告しています。このエラーは、問題とは全く関係ないように見えますが、問題に一番近いところで発生しています。そこで、なぜエラーが報告されるのかを調べてみましょう。Systemdのコード量が多いので、このエラーは多くの箇所で報告されているかもしれません。
ライブデバッグ
お客様の同意を得て、Systemdのデバッグシンボルをダウンロードし、Systemdにクラウドグラフデータベース(GDB)をアタッチし、不審な関数の下でブレークポイントを実行し、実行を継続します。
複数回の検証を行った結果、Systemdがsd_bus_message_seal関数でEOPNOTSUPPに踏み込んでエラーを報告することが確認されました。
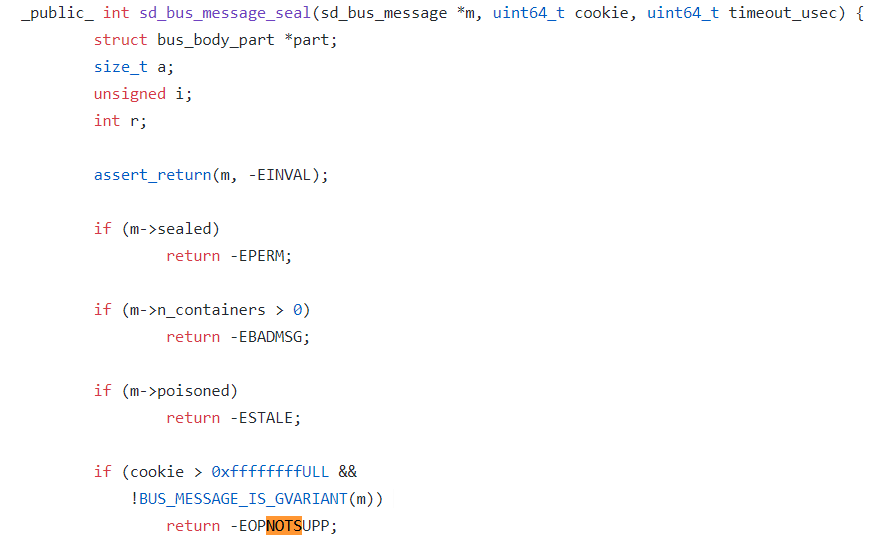
このエラーが報告されるのは、Systemd が処理するすべての D-Bus メッセージを追跡するためにクッキー変数を使用しているからです。毎回新しいメッセージを追加するとき、Systemd は最初にクッキーの値を 1 つ増やしてから、クッキーの値を新しいメッセージにコピーします。
GDB を使用してクッキー値を印刷すると、その値が 0xffffffff よりも大きいことが観察されます。そのため、この問題は、クッキー値の32ビットオーバーフローと、Systemdでメッセージを追加しすぎた後の新規メッセージ追加の失敗が原因のようです。

また、結論を証明するために、通常のシステムではGDBを使ってクッキーの値を0xffffffffに近い値に設定し、クッキーの値がオーバーフローしたときに問題が発生することを観察します。
クラスタノードのNotReady状態が原因かどうかの判断
障害のあるノードにGDBとSystemdをインストールし、gdb /usr/lib/systemd/systemd 1コマンドを実行してGDBをSystemdにアタッチし、sd_bus_send関数にブレークポイントを設定してから実行を継続します。
Systemdがブレークポイントを設定した後、p /x bus->cookieコマンドを実行して、対応するクッキーの値を表示します。
値が0xffffffffより大きい場合、クッキーはオーバーフローします。この場合、ノードは NotReady 状態になります。確認後、quit コマンドを実行してデバッガを切り離します。
問題の修正
この問題を修正するのはそれほど簡単ではありません。その理由の一つは、Systemdがdbus1とdbus2との互換性を保つために同じクッキー変数を使用していることです。dbus1の場合、クッキーの値は32ビットです。この値は、Systemdが3~5ヶ月間、頻繁にユニットを作成したり削除したりすると確実にオーバーフローしてしまいます。dbus2 の場合、クッキーの値は 64 ビットです。この値がオーバーフローすることはありません。
もう一つの理由は、オーバーフロー問題を解決するためにクッキーの値を戻すことができないことです。クッキー値を戻すと、Systemdは同じクッキー値を使って異なるメッセージを追加することがあり、これは悲惨です。
最終的な解決策は、dbus1とdbus2の両方に32ビットのクッキー値を使用することです。また、クッキー値が0xfffffffに達した後、次のクッキー値は0x80000000です。最上位ビットはクッキーがオーバーフロー状態にあることを示すために使用されます。クッキーがこの状態にあるとき、次のクッキーが他のメッセージで使用されているかどうかをチェックして、クッキーの競合を防ぎます。
追記
この記事で考えられている問題は、Systemdに起因するものです。しかし、runCのUseSystemd関数では、Systemd関数のテストにお粗末な方法を使用しています。コンテナのライフサイクル全体の管理プロセスの間、この関数の頻繁なトリガーが低確率の問題を発生させます。Systemd のトラブルシューティングは Red Hat に受け入れられています。
近日中に Systemd をアップグレードすることで、この問題が解決することを期待しています。最近のアップデートについては、こちらのページを参照してください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ