この記事は、北京で開催されたArchSummitでのAlibaba CloudのPrincipal EngineerであるJiang Jiangwei氏のスピーチに基づいています。
2009年から2016年まで、「W11ショッピングフェスティバル」の技術的な準備に8回参加しました。しかし2009年のW11については、あまり印象に残っていません。その主な理由は、当時の淘宝網はすでに非常に大きく、1日の取引量が数億元に達していたのに対し、Tmall W11の取引量は約5,000万元に過ぎず、比較的小さかったため、私にとってはあまり意味を持たないものでした。
それからの数年間は、監視やアラーム、キャパシティプランニング、依存度管理など、各フェスティバルの準備を数ヶ月かけて入念に行いました。さまざまな方法論を整理し、この過程で、私たちは非常に有意義なことをたくさん学びました。今日、もし誰かにW11やその他のプロモーションイベントの準備方法を聞かれたら、私は キャパシティプランニング、トラフィック規制、ダウングレードなどの非常にシンプルな方法を答えるでしょう。
2008年、私はタオバオに入社し、タオバオモールの研究開発に携わりました。タオバオモールは後にTMallになります。当時、タオバオモールの技術システム全体はタオバオとは全く異なり、完全に独立したシステムでした。会員、商品、マーケティング、クレジット、フォーラムなどはすべてタオバオとは別物でした。2つのシステムは完全に独立しており、唯一のつながりはすべての会員データを共有していることです。
2008年末、「Cobblestone Project」が開始され、2つのシステムのデータとビジネスがつながりました。このプロジェクトでは、ビジネスの展開を非常に柔軟にすることを目標としました。このプロジェクトは、タオバオモールの発展を大きく前進させました。その後、タオバオモールはTMallというブランドに移行しました。
さらに、このプロジェクトのもう一つの重要な成果は、アーキテクチャ、ビジネス、技術のスケーラビリティをスムーズに実現したことです。事業全体の完全なサービス化を実現し、会員システム、商品センター、取引センター、マーケティング、店舗、レコメンドなど、電子商取引に関わるすべての共通要素を抽出しました。このシステムをベースにして、「Juhuasuan」「3C」「Alitrip」などのサービスを非常に簡単に構築することができました。オリジナルのアーキテクチャを壊し、共通のサービスをすべて抽出したところ、上位のビジネスが高速に動作し、ビジネスのスケーラビリティの問題が解決されました。
このプロジェクトでは、初めてミドルウェアが大規模に利用され、HSF、Notify、TDDLの3大ミドルウェアは大きな革新を遂げ、広く使われるようになりました。分散システムの問題点は、多くのサブシステムに分割されることであり、これもスケーラビリティの問題につながっています。このプロジェクトは、技術的な進歩ももたらし、ビジネスの発展と技術的な拡張性の両方が新たな高みに到達しました。
なぜキャパシティプランニングなのか?
2012年以降、私はミドルウェア製品群と高可用性アーキテクチャチームを率いてきました。しかし、なぜキャパシティプランニングなのでしょうか? W11は、アリババの偉大な技術革新を促進しましたが、キャパシティプランニングは、その過程における革新のポイントです。
今年のW11の準備をしていたとき、上司から "今年はどんなリスクを想定しているのか?"と聞かれました。私は「確かに多くのリスクがありますが、最終的にシステムに問題が発生するとすれば、それはおそらくトランザクション関連のシステムでしょう」と話しました。アリババのシステムは、取引を促進するためのもの、例えばレコメンデーション、ショッピングガイド、検索、チャンネルなど、あらゆるマーケティングのためのものと、红包、割引などの取引のためのものに分かれています。
理由は簡単で、ショッピングガイドシステムは決断するための十分な時間を残してくれるからです。瞬時にアクセス数が増えるわけではないので、判断するための時間を30分残します。しかし、トレーディングシステムには決断のバッファがありません。トラフィックが開始されると、対応したり判断したりする時間はなく、すべてのアクションはシステムによって自動的に実行されます。このプロセスでは、キャパシティプランニングが非常に重要になります。
初期の頃は、ビジネスの自然な成長がとても早く、当時、お客様が買い物中に商品の詳細ページを開くと、しばらくの間、ページの負荷が比較的高くなっていたのが印象的でした。アリババは、仮想マシンのパフォーマンスを最大化するために、チューニングと最適化のスペシャリストを活用しましたが、結局、数日後にシステムがハングアップしてしまいました。幸いなことに、サイズ変更が完了した後、再起動するとシステムは元通りになりました。これは何を意味するのでしょうか?初期の頃のタオバオと似ています。容量の準備や見積もりという概念がなく、システム全体で必要な容量が不明だったのです。
新規事業が次々と立ち上がり、事業運営やプロモーションも非常に頻繁に行われていました。非常に大規模なプロモーションがあったことを覚えています。会員システムは非常に重要で、すべてのサービスが会員センターのユーザーデータ(買い手のデータ、売り手のデータ)にアクセスするからです。当時の物理マシン1台のキャッシュ能力は、1秒間に約8万リクエストでした。今にして思えば、とても物足りないですよね。しかし、ピーク時以外は1秒間に6万リクエストに達しており、非常に大きな容量となっていました。
キャパシティプランニングの3つのステージ
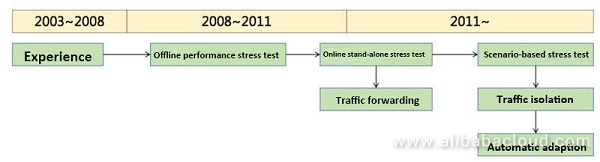
キャパシティプランニングは、7〜8年かけて、3つの段階を経て完成しました。
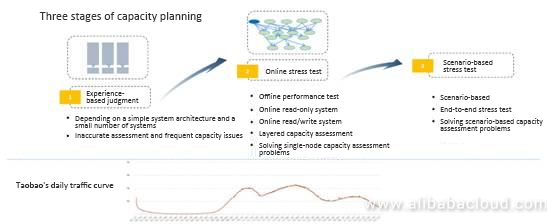
最初の段階では、経験に基づいて容量を評価していました。負荷やシステムの応答時間など、さまざまなパフォーマンスに応じて容量を決めていました。当時、ある幹部に "サーバーが十分かどうか、どのくらいのトラフィックをサポートできるかはどうやって判断すればいいのか?"と質問したことがあります。彼は経験的に、1台のサーバーが100万PVをサポートするという数字を教えてくれました。
当時のトラフィックカーブは、午前9時から10時、午後2時か3時から5時、午後8時から10時の3つのピークがありました。私たちは、半分のサーバーを無効にしてもオンラインのトラフィックをサポートでき、すべてのサーバーを有効にしてもピーク時のトラフィックをサポートできると期待していました。実際には、当時の経験値である320万PVを1台のマシンで支えることができました。
もちろん、当時はシステムアーキテクチャが単純だったので、この経験値は有効でした。タオバオのロジックやモジュールがすべて1つのシステムに集約されていたため、モジュールによってピーク時が異なっていたと理解できますが、これはOSレベルでサーバーの内部CPUを先取りしたり、スケジューリングすることで解決しました。
第2段階は、オンラインでのストレステストです。システムが分散しているため、問題が発生する可能性がありました。例えば、メンバーの呼び出しとトランザクションの呼び出しは元々1つのサーバーにありましたが、分離した後はトラフィックの比率が不明確になりました。そのため、ストレステストの仕組みを導入する必要がありました。ストレステストのために、市販のストレステストツールをいくつか導入しました。
当時の目的は2つありました。1つは、システムのリリース前にストレステストを行い、レスポンスタイムや負荷がリリース要件を満たせるかどうかを判断すること、もう1つは、ストレステストの結果に基づいて、何台のサーバーをオンラインにしなければならないかを正確に評価することです。2つ目の目的は、シミュレーションするのが難しく、パフォーマンスストレステストチームは、「オンライン/オフラインのキャパシティ関係」というプロジェクトも立ち上げたと記憶しています。オンライン/オフラインの環境やデータが全く異なるため、整合性が取れず、オフラインのストレステストの指標でオンラインのニーズを判断することはできません。
では、どうすればいいのでしょうか。まず、オンラインのストレステストを直接行いました。当時、この決断は非常にクレイジーなものでした。アリババを含め、どの企業もオンラインのストレステストを直接行ったことはありませんでした。私たちは、前日のログを抽出し、それをオンラインで再生するツールをコーディングしました。例えば、応答時間や負荷に応じてあらかじめ決められた値を設定し、その値が発動したときにQPSをチェックするなどです。
2つ目として、トラフィックを分割しました。アリババのアーキテクチャ全体は統一されており、すべて一連のミドルウェアに基づいています。ソフト的な負荷と比率の調整を通じて、例えば、オンラインのトラフィックを重みに応じてサーバーに移行し、オンラインのアプリケーション側とサーバー側のトラフィックを常に1つのサーバーに移行して重みを増していくと、その負荷は上昇し、QPSも上昇しました。その一部始終を記録しました。
このように、シミュレーションとログ再生の2つのシナリオがあります。もうひとつは、実際のトラフィックを使って、毎日自動でデータを生成することです。導入後は、オフラインのパフォーマンスストレステストで行っていたプロセスを置き換えました。これにより、各システムは毎日、独自にパフォーマンスメトリクスを得ることができました。プロジェクト・リリースや日常的なデマンド・リリースのパフォーマンス・メトリクスを直接見ることができました。その後、パフォーマンステストチームは解散しました。
問題なのはシナリオベースではないということでした。シナリオはとても重要です。例えば、ある服を買おうと思ったら、通常はウェブサイトの検索ボックスやカテゴリで検索し、ショッピングカートに入れて、支払いをします。W11は商品にフォーカスしており、一部のベストセラーは1つのチャンネルページとして別途紹介されることもあります。W12は、ショップに焦点を当てており、異なるKPIが適用されます。
W11では、商品に関連するサーバーのトラフィックが多く、商品に関連するサーバーを増やす必要があります。同様に、W12では、ショップ関連のサーバーを増やす必要があります。これは、通常のトラフィックのパフォーマンスとは異なります。また、シナリオベースのトラフィックを通常の容量で計算するのは不正確です。
また、エンド・ツー・エンドのストレステストという重要なことも行いました。これは2013年に始めたものですが、これまで公開されていませんでした。
2013年、エンド・ツー・エンドのストレステスト製品が導入された後、本質的な変化がありました。2013年、2014年ともにパフォーマンスは素晴らしいものでした。これが新しい時代の始まりでした。マーケティングやプロモーションにおいては、ピークがあり、その前はトラフィックが非常に少なく、その後突然トラフィックが増加します。このような状況に対応するためには、非常に効果的な方法です。
オフラインからオンラインへ:スタンドアロン型ストレステストのキャパシティ評価
オンラインのストレステストとシナリオベースのエンドツーエンドのストレステストが注目されています。
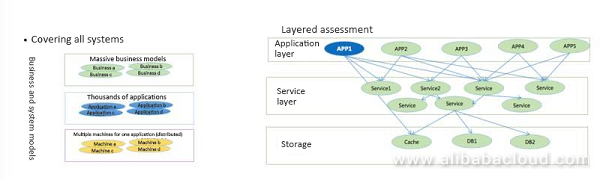
オンラインのストレステストは、主にタオバオのビジネスモデルの多様性に起因します。分散モデルを採用すると、さまざまなサービスが登場し、生産性を解放することができました。例えば、以前は1つのシステムを100人以上で開発するなど、非常に大変でした。分散化したことで、あらゆるサービスが抽出され、生産性が向上しました。
次に、各ビジネスマシンのサイズが非常に大きく、ビジネスごとのアプリケーション数も多いため、我々はシステムをレイヤー化し、システムの容量に応じたコンピューティングを行い、結果としてアリババのクラスター容量を実現しました。まず、アプリケーションシステムを作りました。そしてスプリットロードでトラフィックを取り込み、ロードが完了した後に計算しました。また、クラスター全体、例えば100台のサーバーがどれだけのトラフィックをサポートできるかを計算しました。もちろん、データベースの計算は難しく、事前に計画を立てていました。一般に、データベースの容量は何年も前から確保されているので、それが難しいのです。
クラスタの容量とサイズの計算には問題がある可能性があります。なぜなら、一度分割されたシステムは複数回分割される可能性があるからです。システムの依存関係はツールで整理することができますが、今回のシナリオでは小さな問題をクラスター全体でトラブルシューティングする時間がありませんでした。一度小さな問題が発生すると、クラスタ全体がダウンしてしまい、それを避けることができませんでした。
このシステムは2013年まで継続して使用されました。各システムの容量を計算し、次に各クラスタの容量を計算し、次に大規模なクラスタの容量を計算するという、非常に合理的なものでした。しかし、これはあまり良い解決策ではありませんでした。このシステムの利点の 1 つは、システム容量を計算するために毎日自動的に実行され、システムと日々のパフォーマンス指標が破損しないようにできることでした。
ストレステストプラットフォームのアーキテクチャ
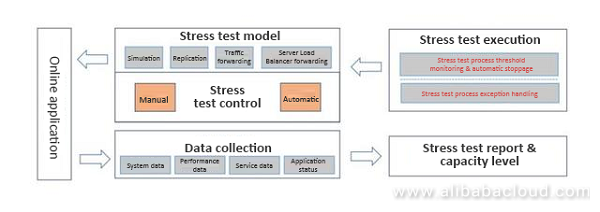
このシステムは、2013年の「W11」を支えました。このシステムは、シミュレーション、トラフィックの複製、トラフィックの転送、トラフィックの負荷分散など、いくつかの方法で実装されました。システム全体は自動化されており、1週間ごとに実行されました。リリースの前日と翌日の結果データをもとに、パフォーマンスの低下が見られないかどうかのレポートを作成しました。イベントに必要なトラフィックは、計算された値に基づいて準備されました。毎月5日間、自動ストレステストを実施していたというデータがあります。この場合、自動化されているため、手動でパフォーマンスのストレステストを行うことはできませんでした。
また、いくつかの欠点についてもお話しました。全体のキャパシティは、各ポイントのキャパシティに基づいて見積もられていました。最大の問題は、全体のアーキテクチャがどのようになっているのか誰も把握しておらず、システム全体でいくつかの依存関係が見落とされると、全体的な崩壊が起こることでした。
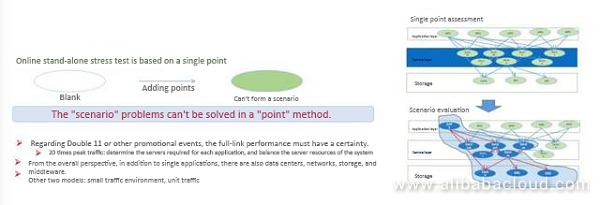
なぜシナリオベースのキャパシティ評価を行ったのか?
シナリオベースのストレステストを行う必要があったもう一つの理由は、バックグラウンドのトラフィックがほとんど分割されていたため、実際のトラフィックを使用していたことです。実際のトラフィックは、イベント時のトラフィックに比べて非常に少ない量でした。バックグラウンドトラフィックがなければ、データセンターのネットワーク機器やスイッチは最大の負荷で動作することができないため、こうした問題が露呈することはありませんでした。2つ目の問題は、シナリオの確実性です。それぞれに異なる買い物のプロセスがあります。最少のサーバー台数で最大のトラフィックをサポートするためには、プロセスごとにシステムリソースを決めなければなりません。
これを踏まえて、シナリオベースのストレステストをどのように行うのがベストかを議論しました。最初の方法は、タオバオから小さな環境を切り離し、そこに100台以上のシステムを導入することでした。そして、その環境にトラフィックを導入し、クラスターを最大負荷で稼働させました。これで依存関係の問題は解決され、環境側では依存関係の問題があるかどうかを検証することができました。しかし、環境の問題は解決できませんでした。ある年、当社のある企業が、このソリューションではなく、小さな環境に似たソリューションを採用した結果、イングレス・スイッチに最大の負荷がかかるようになってしまったのです。
シナリオベースのキャパシティ評価
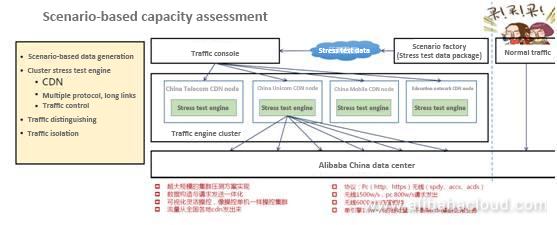
よりシンプルで信頼性の高い評価ツール、それがシナリオベースのエンド・ツー・エンドのストレステストツールでした。2013年から使用しています。まずはデータを生成し、より実情に近いトラフィックを生成する必要があります。先ほどのピークに関しては判断がつかないので、どうすればいいでしょうか。0時台のピークを事前にシミュレーションすることは可能でしょうか?理想的なアーキテクチャではありますが、課題もたくさんあります。
できるだけ正確にデータを生成し、クーポンの利用状況、ショッピングカートの中の商品の割合、1回の注文で何個の商品が置かれたか、アリペイに何個の商品が提出されたかなど、さまざまなシナリオをシミュレーションしなければなりません。データの量は年々増えています。例えば、2015年には約1TBのデータがありました。この1TBのデータは、データセンターに転送された後、ストレステスト用のノードに転送されました。これがストレステスト用のクラスターです。これはクラスタのストレステストツールで、W11のデータ量に合わせて非常に大きなトラフィックを発生させることができます。
クラスタはCDNノード上に配置し、大量のトラフィックを発生させました。技術的なポイントがいくつかあります。ストレステストツールは HTTPS などの複数のプロトコルをサポートしているため、パフォーマンスの向上が必要です。また、さまざまなシナリオに基づいてトラフィックを調整するために、トラフィック制御が必要です。3つ目は、トラフィックを区別する必要があることです。右の写真は、すべてオンラインである実際のトラフィックを反映しています。この環境をオフラインでシミュレートすることはできません。そうしないと、通常のオンライン・トラフィックに影響を与えることになりますので、通常のトラフィックとストレステストのトラフィックは完全に分離する必要があります。4つ目は、トラフィックの分離です。トラフィックの分離ができないと、0時以降にあまりトラフィックがないときにしかシステムの問題を特定できませんが、これは非常に難しいことです。トラフィック・アイソレーションは、チームの作業負担を軽減するために、2年目に開始されました。
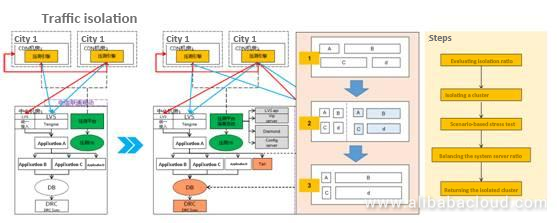
トラフィック・アイソレーションとは、サーバー・ロード・バランサーを介して、元のオンライン・クラスターからクラスターを隔離することです。もちろん、隔離されるクラスターのサイズは非常に大きく、元のクラスターの10%から90%を占めることもあります。例えば、元々10万台のサーバーがあった場合、9万台のサーバーを隔離することができます。例えば、プロモーションの準備をしているとき、W11のトラフィックは通常の20倍以上になりますから、そのトラフィックを隔離しても、既存のトラフィックに影響を与えることはありません。
全体の流れはどうなっているでしょうか?図を例にとると、4つのシナリオがあります。本来はシナリオCの方がより多くのサーバーを必要とするのですが、ストレステストの結果、BとDの方がより多くのサーバーを必要とすると判断されました。このプロセスはすべて自動化されています。自動化されているため、非常に効率的で、早朝に実行する必要はありません。最後に、孤立したクラスターを元のオンライン・クラスターに戻し、元のサーバー比率に戻すことで、翌日からの挑戦を再開することができます。
トラフィック評価プロセス
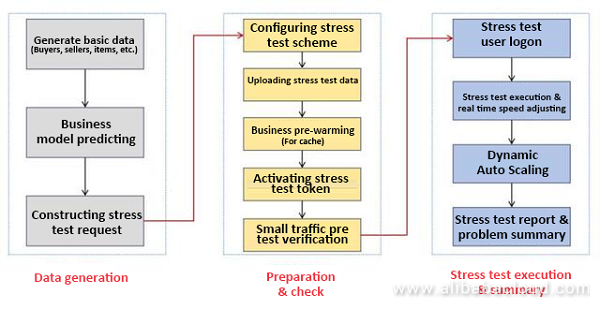
データの構築からトラフィックまでの容量評価の間には、ある目的があります。例えば、1秒間に約50,000件のトランザクションが発生するイベントを開催したいとします。50,000という値を入力すると、システム全体でストレステスト、フレキシブル・スケジューリング、アイソレーションを開始します。これが自動化されたプロセスです。キャパシティは予測することはできますが、計画することはできず、制限することしかできません。W11のトラフィック量、ユーザー数、ピーク値などは正確に予測できます。
しかし、この予測にはあまり価値がありません。私たちにできることは、トランザクションの数を制限することです。例えば、2016年には1秒間に17万5,000件のトランザクションを達成しましたが、制限値はすべてのシステムで17万2,000件に設定されました。これだけしかできません。実際のトラフィック量はこれよりもはるかに大きいため、実際のトラフィックをサポートするためのコストは非常に高くなります。
日常的に使用するサーバーの数は少なく、W11では、基本的にAlibaba Cloudのサーバーを使用するため、コストが大幅に削減されます。そのため、キャパシティプランニングで、例えば1秒間に17万トランザクションという制限を設けた場合、来年には20万、25万となる可能性があります。この値に基づいて、シナリオベースのエンドツーエンドのストレステストツールを通じて、システム全体のキャパシティが計算され、サーバーリソースの占有率がバランスされます。これにより、最小限のリソースでイベントを成功させることができます。
シナリオベースのキャパシティ評価性能

2013年以降、私たちはこの技術を使って多くの問題を発見しました。これらの問題は、デイリーテストや機能テスト、一部のツールテストでは発見できないものです。ハードウェア、ネットワーク、OSなど、これまで発生しなかった問題がすべて明らかになりました。高負荷時には、非常に奇妙な問題も発生しました。
もし、これらの問題がW11で発生したら、大惨事になるかもしれません。2013年を終えてみると、2012年や2011年の問題が見えてきます。イベントのピーク時のトラフィックが通常のピーク値の数倍以上であれば、間違いなく問題が発生します。なぜなら、多くの問題は、何らかの論理や思考では発見できず、あらゆるシナリオのトラフィックをシミュレートした実環境で発見しなければならないからです。
キャパシティ評価の概要
キャパシティプランニングは、長期にわたるプロセスです。当初、性能のストレステストには市販のソフトウェアが使用されていましたが、これはうまく機能しており、全体のキャパシティを計算することにも対応していました。現在でも、多くの企業が性能評価のために同様のソフトウェアを使用しており、継続的に進化しています。その後、実際のキャパシティとストレステストの評価結果の間に大きなギャップがあることが判明したため、様々なノードを経由するトラフィックを評価するために、オンライン・ストレステスト、トラフィック・スプリッティング、トラフィック・レプリケーション、ログ・プレイバックなどを導入しました。
このシステムはすごいと思いました。当時、このシステムは技術部門全体のイノベーション賞を受賞しました。そして、このシステムがあれば、今後、W11などの心配をしなくて済むと考えたのです。実際には、まだまだ開発が必要なシステムでした。そして、シナリオシミュレーションに基づいてクラスタ全体をテストするエンドツーエンドのストレステストを実施しました。
振り返ってみると、例えばCSPの「デイリーストレステストプラットフォーム」は中国の多くの製品よりも先を行ってはいますが、現状に満足せず、まだまだ前進し続けることができることを忘れてはいけません。
我々はW11のキャパシティプランニングを行ったばかりです。アリババの技術アーキテクチャ全体が統一されています。エンド・ツー・エンドのストレステストの後、アリペイなど多くのビジネスユニットが同じ手法を利用できるため、コストが大幅に削減されます。研究開発、学習、O&Mプロセス、O&M製品ラインのコストを削減できます。その結果、我々のチームはかなり小規模なものとなり、フルラインのストレステストに取り組んでいるのは4、5人だけとなりました。それでもグループ全体で100以上のチームにサービスを提供することができているのは、これも体制の均一性の賜物です。
今年のW11の後、CTOからは次のW11に向けてコストを下げるという新たな課題も提示されました。エンド・ツー・エンドのストレステストは、問題点を探すのではなく、日々のシステムを検証するものですが、このシステムをより自動化、インテリジェント化できることを期待しています。
著者について

Xiaoxieの名で知られるJiang Jiangweiは、アリババの研究者です。2008年にタオバオに入社し、ビジネスシステムの研究開発に参加。2012年からは、アリババのミドルウェア技術製品と高可用性アーキテクチャを担当。ミドルウェア製品は、アリババの電子商取引をはじめとする分散アーキテクチャの基本的な技術要素であり、さまざまなビジネスシステムが高可用性分散アーキテクチャクラスタを迅速に構築できるようにします。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ