この記事では、科学計算分野の研究者が大規模な多次元行列演算を解くのにMarsがどのように役立つかを論じています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
Python
Pythonは、科学計算や機械学習、ディープラーニングなどで広く採用され続けている定着した言語です。
ビッグデータ分野では、Hadoop、Spark、Javaがいまだに優勢です。しかし、SparkのWebサイトにはPySparkのユーザーも多数存在しています。
ディープラーニング分野では、ほとんどのライブラリ(TensorFlow、PyTorch、MXNet、Chainer)がPythonをサポートしています。
PythonユーザーはMaxComputeでも重要なグループとされています。
PyData (NumPy, SciPy, Pandas, scikit-learn, matplotlib, scikit-learn)
データサイエンス分野のPythonには様々なパッケージが用意されています。下の図はPythonのデータサイエンス技術スタックの全体像を示しています。
見ての通り、NumPyはその基盤であり、NumPyの上には科学と工学のためのSciPy、データ分析のためのPandas、機械学習ライブラリのscikit-learn、データの可視化のためのmatplotlibなどのライブラリが座っています。
NumPyでは、最も重要なコア概念はndarray(多次元配列)である。Pandasやscikit-learnなどのライブラリは、すべてこのデータ構造に基づいて構築されています。
既存のコンピューティングエンジンの問題点
前述の分野ではPythonの人気が高まり続けており、PyDataテクノロジースタックはDataFrame上での多次元行列の計算・解析や、2次元行列に基づく機械学習アルゴリズムをデータサイエンティストに提供しています。しかし、これらのPython用ライブラリは、いずれも1台のマシン上での計算に限定されています。ビッグデータの時代には、これらのライブラリでは、非常に大量のデータを扱うシナリオでの処理能力の要件を満たすことができません。
ビッグデータ時代には、SQLベースの計算エンジンが多く登場していますが、科学計算分野での大規模な多次元行列演算には適していません。一方で、かなりの数のユーザー、特にデータサイエンティストは、成熟したスタンドアロンライブラリに慣れてしまっています。彼らはその習慣を変えて、新しいライブラリや構文を一から学び始めようとはしません。
一方、ndarray/tensorも深層学習分野では最も基本的なデータ構造ではあるが、深層学習に限定されており、大規模な多次元行列演算には不向きです。
これらの懸念を踏まえて、テンソルベースのユニバーサル分散コンピューティングフレームワークであるMarsを開発しました。初期の段階では、いかにして最適なテンソル層を作るかに着目しました。
Marsの詳細分析
Marsのコアとなる部分はPythonで実装されています。これにより、Pythonコミュニティでの既存の実績を活用することができます。NumPy、CuPy、Pandasなどのライブラリを小さな計算単位としてフル活用することができるので、システム全体を素早く安定して構築することができます。また、Python自体はC/C++の継承が容易で、パフォーマンスホットスポットモジュールをC/Cythonで書き換えることができるので、Python言語自体の性能を気にする必要がありません。
次項ではマルステンソル、つまり多次元行列演算に焦点を当てます。
Numpy API
NumPyの成功の理由の一つは、そのシンプルで使いやすいAPIにあります。このAPIは、マーズテンソルの中で、我々のインターフェイスとして直接使用することができます。NumPy APIをベースに、ユーザーは柔軟にコードを書いてデータを処理し、さらには様々なアルゴリズムを実装することができます。
以下の2段落のコードは、それぞれNumPyとMarsテンソルを使って機能を実装したものです。
import numpy as np
a = np.random.rand(1000, 2000)
(a + 1).sum(axis=1)
import mars.tensor as mt
a = mt.random.rand(1000, 2000)
(a + 1).sum(axis=1).execute()
前述の例では、乱数の1000×2000の行列を作成し、各要素に1を加え、軸=1(行)に和演算を行います。
Marsは、一般的なNumPyのインターフェースの約70%を実装しています。
”import "行だけが置き換えられていることがわかります。ユーザーは明示的に計算を起動するために "execute "を呼び出す必要があるだけです。execute "を使って明示的に計算を開始する利点は、効率的に計算を行うために中間プロセスをより多く最適化できることです。
しかし、スタティックグラフの欠点は、柔軟性が低下し、デバッグの複雑さが増すことです。次のバージョンでは、各アクションをターゲットにした計算をトリガーするインスタント/イーガーモードを提供する予定です。これにより、ユーザーは効率的なデバッグを行うことができ、Python言語をサイクリングに利用することができます。ただし、それに伴いパフォーマンスは低下します。
コンピューティングにGPUを使用する
マーズテンソルはGPUコンピューティングもサポートしています。行列で作成されたインターフェースに対しては、GPUへの割り当てを指定するためにgpu=Trueオプションが利用できます。その行列の後続の計算はGPUで実行されます。
import mars.tensor as mt
a = mt.random.rand(1000, 2000, gpu=True)
(a + 1).sum(axis=1).execute()
前述の例では GPU に a を割り当てているため,後続の計算は GPU 上で実行されます.
疎行列
マーズテンソルは疎な行列の作成をサポートしています(現在サポートされているのは2次元行列のみです)。例えば、疎な単位行列を作成するには、単にsparse=Trueと指定します。
import mars.tensor as mt
a = mt.eye(1000, sparse=True, gpu=True)
b = (a + 1).sum(axis=1)
前述の例では、GPU と Sparse オプションを同時に指定できることを示しています。
Marsテンソルに基づく超構造
Marsでは上部構造物は実装されていません。ここでは、Marsでの構築を目指しているコンポーネントについて説明します。
データフレーム
PyODPS DataFrameというライブラリをご存知の方もいらっしゃると思いますが、これは私たちの以前のプロジェクトの一つです。PyODPS DataFrameを使うと、Pandasの構文に似た構文を書き、ODPS上で計算を行うことができます。しかし、PyODPS DataFrameはODPS自体の限界があるため、Pandasの全ての機能(例えばインデックスなど)を実装することはできず、構文も異なっています。
Marsテンソルをベースに、Pandasの構文と100%互換性のあるDataFrameを提供しています。Mars DataFrameを使えば、ユーザーは1台のマシンのメモリに制限されません。これは次のバージョンでの主な目的の一つです。
機械学習
いくつかのscikit-learnアルゴリズムは2次元NumPy ndarraysの形で入力されます。また、分散機械学習アルゴリズムも提供します。大体3つの方法が用意されています。
1、scikit-learnアルゴリズムの中にはpartial_fitをサポートしているものもあるので、各ワーカーに直接scikit-learnアルゴリズムを起動する。
2、マーズベースのJoblibバックエンドを提供する。scikit-learnは並列化のためにJoblibを使用するので、分散したMars環境で直接scikit-learnアルゴリズムを実行するためにJoblibバックエンドを実装することができます。しかし、この方法ではまだNumPy ndarraysの入力が必要です。そのため、総データ入力量はやはりメモリによって制限されます。
3、Marsテンソルに基づく機械学習アルゴリズムを実装する。最も高い作業負荷が必要とされるにもかかわらず、この方法では、これらのアルゴリズムは、例えばGPUコンピューティングなどのMarsテンソルの能力を利用することができます。将来的には、より多くの皆さんにコードを投稿していただき、一緒にMarsの生態系を構築していただきたいと考えています。
詳細な関数とクラス
Marsのコアとなるのは、アクタ-ベースの微粒化スケジューリングエンジンです。そのため、ユーザは実際にいくつかの並列Pythonの関数やクラスを書いて、微粒化制御を実装することができます。以下のような種類のインタフェースを提供することがあります。
関数
ユーザーはPythonの一般的な関数を書いたり、mars.remote.spawnを使って関数をスケジュールしたりして、Mars上で分散して実行できるようにします。
import mars.remote as mr
def add(x, y):
return x + y
data = [
(1, 2),
(3, 4)
]
for item in data:
mr.spawn(add, item[0], item[1])
mr.spawnを使うと、分散プログラムを簡単に構築することができます。また、関数の中で mr.spawn を使うことで、非常に細かい分散実行プログラムを書くことができます。
クラス
ステータスの更新などのアクションを行うために、ステートフルなクラスが必要になることがあります。これらのクラスは、MarsではRemoteClassesと呼ばれています。
import mars.remote as mr
class Counter(mr.RemoteClass):
def __init__(self):
self.value = 0
def inc(self, n=1):
self.value += n
counter = mr.spawn(Counter)
counter.inc()
現在、これらの関数やクラスは実装されておらず、構想段階にあります。したがって、先行するインタフェースは変更される可能性があります。
内部実装
このセクションでは、Marsテンソルの内部原理を簡単に説明します。
クライアント
クライアント上では実際の計算は行われません。ユーザがコードを書くときには、グラフを使ってそのユーザの操作をメモリに記録するだけです。
マーズテンソルには、オペランドとテンソルという2つの重要な概念があります(下図ではそれぞれ青い丸とピンクの立方体で示されています)。オペランドは演算子を表し、テンソルは生成された多次元配列を表します。
例えば、次の図のように、ユーザが次のコードを書くと、グラフ上に対応するオペランドとテンソルを順番に生成していきます。

そのユーザーが明示的に "execute “を呼び出すと、Marsの分散実行環境にグラフを投入します。
私たちのクライアントは言語に依存せず、同じテンソルグラフのシリアライズだけを要求します。したがって、どの言語での実装もサポートしています。ユーザーのニーズに応じて、次のバージョンでJava用のMarsテンソルを提供するかどうかを判断します。
分散実行環境
Marsは、基本的には微視的グラフの実行・スケジューリングシステムです。
Marsはテンソルレベルのグラフ(粗視化されたグラフ)を受け取り、チャンクレベルのグラフ(微視化されたグラフ)に変換しようとします。実行処理の間、メモリには各チャンクとその入力を格納できるようにしておく必要があります。この処理をTileと呼びます。
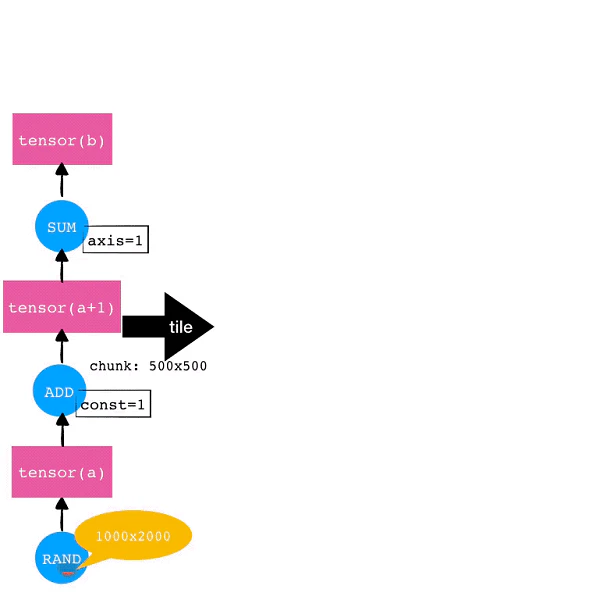
微細なチャンクレベルのグラフを受け取ると、そのグラフ上のオペランドが個々のワーカーに割り当てられて実行されます。
概要
Marsは2018年9月に初公開され、現在は完全オープンソース化されています。現在、オープンソースコードはGitHubで公開されています: https://github.com/mars-project/mars 私たちはただコードを公開しているのではなく、完全にオープンソース化された状態でプロジェクトを運営しています。
より多くの人がMarsコミュニティに参加し、一緒にMarsを作ってくれることを願っています。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ