この4回シリーズの第1部では、MLパイプラインを探索し、手動による特徴抽出の課題を浮き彫りにしていきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババ・クラウド・コミュニティ・ブログ執筆者のAhmed F. Gad氏より
全4回のチュートリアルを通して、事前に学習したディープラーニングモデル(DL)、畳み込みニューラルネットワーク(CNN)の学習をKerasに移すことで抽出した特徴を用いて人工ニューラルネットワーク(ANN)を学習し、画像の分類を探って行きます。
チュートリアルでは、機械学習(ML)のパイプラインを探ることから始まります。特に大量のデータがある場合、手作業で特徴を設計するのは困難な作業であり、転移学習を用いた自動特徴抽出が好ましい方法であることを強調しています。その後、転移学習について紹介し、転移学習の利点とその利用条件を探って行きます。次に、本シリーズでは、Jupyterノートブックで実行されているKerasを用いて、ImageNetデータセットを用いて学習した事前学習済みモデル(MobileNet)を、Fruits360データセットである別のデータセットで使用するための転移学習を行います。その後、転移学習で得られたモデルから特徴量を抽出し、抽出した特徴量を解析して悪い特徴を除去し、最終的にその特徴量で学習されたANNを構築します。
このチュートリアルはその第1部で、手動による特徴抽出の課題を浮き彫りにするために、MLパイプラインを探ります。そして、それを理解するために転移学習の導入を行い、なぜ我々はそれを使用することができるのかを説明します。
このチュートリアルでカバーされているポイントは以下の通りです。
- 機械学習パイプラインを探る。
- マニュアルフィーチャーエンジニアリング
- ディープラーニングを使った特徴抽出の自動化
- 転移学習とは何か?
- なぜ転移学習なのか?
- 転移学習が有効なユースケース
- 転移学習の利用条件。
さっそく始めてみましょう。
機械学習のパイプラインを探る
事前に学習されたDLモデルの転移学習の利点を理解するために、MLパイプラインを議論して理解していきます。これにより、転移学習の核心的な利点を把握することができます。機械学習モデルを構築するパイプラインを次の図に示しています。パイプラインには他にも特徴量削減などのステップが追加される可能性があるわけではありませんが、モデルを構築するには以下のステップで十分です。ここでは、パイプラインの各ステップを簡単に説明し、フィーチャーエンジニアリングのステップに焦点を当ててみましょう。
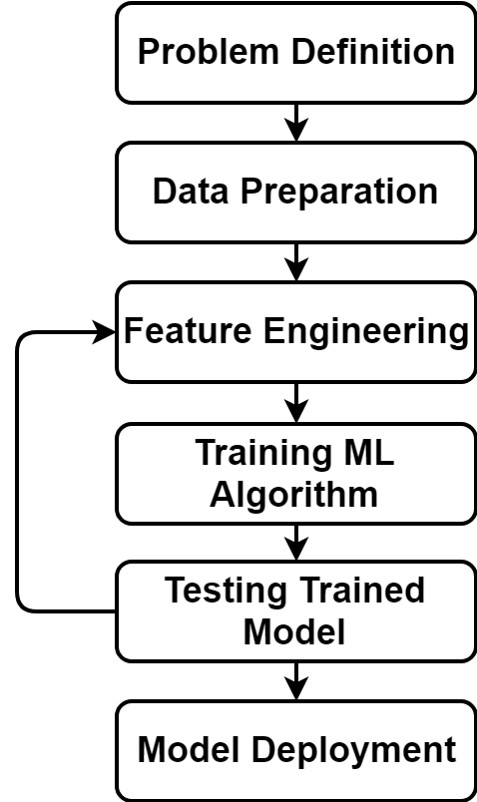
問題の定義とは,最適なML手法を見つけるために,解決しようとしている問題を理解することです。これは,問題の範囲を決めることから始まります.それは、監視された問題(分類または回帰)であるか、監視されていない問題(クラスタリング)であるかです。問題の範囲を定義した後,次にどのMLアルゴリズムを使用するかを決定します.例えば,監視された問題であれば,どのMLアルゴリズムを用いるかを決定します.線形か非線形か,パラメトリックかノンパラメトリックかなどです。
問題を定義することは,MLパイプラインの次のステップであるデータの準備に役立ちます。機械は例を用いて学習します.各例は入力と出力を持ちます。例えば,問題が分類問題で,各サンプルを事前に定義されたカテゴリのいずれかに分類する場合,出力はラベルとなります.出力が連続線として表現される回帰問題であれば、出力はもはやラベルではなく数値です。このように、問題を定義することで、我々は適切な形でデータを準備することができます。
マニュアルフィーチャーエンジニアリング
データの準備ができたら、次のステップはフィーチャーエンジニアリングです。これは、従来の機械学習モデルを構築する上で最も重要なステップです。最初に、なぜフィーチャーエンジニアリングを行うのでしょうか?フィーチャーエンジニアリングとは、データを現在の形から、解決される問題に役立つ別の形に変換することを意味します。データはどのようにしてある形から別の形に変換されるのでしょうか?それは特徴記述子を使うことです。コンピュータビジョンといえば、画像をある形から別の形に変換するためのさまざまな特徴記述子があります。これらの記述子には、色、エッジ、テクスチャ、キーポイント記述子などがあります。
これらのカテゴリには、それぞれ異なるタイプの記述子があります。例えば、テクスチャディスクリプタには、グレーレベル共起行列(GLCM)や局所2値パターン(LBP)があります。また、キーポイント記述子として、スケール不変特徴変換(SIFT)、高速化ロバスト特徴変換(SURF)、ハリスなどがあります。ここでもう一つの疑問が出てきます。与えられた問題に対して、どのようなタイプの記述子を使用するのがベストなのか、ということです。
与えられた問題に特徴記述子を使うかどうかの判断は、データサイエンティストが手動で行います。データサイエンティストは、手元の問題を解決した経験に基づいて、使用する記述子をいくつか提案し始めます。選択された記述子に基づいて,画像から特徴量が抽出され,次にMLアルゴリズムのトレーニングとトレーニングされたモデルのテストの2つのステップに移ります。モデルは,アルゴリズムの学習後の結果であることに注意してください。
記述子の選択が正しくなく,訓練されたモデルのテスト誤差が大きくなる可能性があるため,データサイエンティストは誤差を減らすために最適な選択を見つけるまで記述子を変更しなければなりません。記述子を新たに選択するたびに,MLアルゴリズムは訓練され,再度テストしなければなりません。
誤差の他にも,計算量の複雑さなど,記述子を選択する際に考慮すべき要素があるかもしれません。確かに,特に何千,何百万もの画像を解析するような複雑なタイプの問題では,必要に応じて最適なディスクリプタを手動で選択するのは面倒です。
機能を選択するための例
それぞれが異なるクラスに対応していることを前提として、次の図に示す3つの画像を分類するための最適なタイプの特徴を選択するために、上記の説明を適用してみましょう。使用する特徴の中で最も適したカテゴリ(色、エッジ、テクスチャ、キーポイント)は何でしょうか?これら3つの画像の色が異なることは明らかなので、カラーヒストグラムのような色記述子を使うことができます。これで正確に目的を果たすことができます。正確なモデルを構築したら、パイプラインの最後のステップであるモデルの展開に移ります。

それぞれの画像が異なるクラスに対応していることを考えると,以下のようにデータセットにさらに多くの画像を追加するとどうなるでしょうか? 異なる画像が似たような色を持っていることは明らかであり,カラーヒストグラムだけを使っても目的を果たさないかもしれません。そこで,他のタイプのディスクリプタを探す必要があります。
ディスクリプタXが選択され、以下の画像の違いを捉えるのにうまく機能したと仮定します。ディスクリプタXでは区別がつかないような他の画像を使用することも可能です。そのため,ディスクリプタXの代わりに,差分をとらえることができるディスクリプタXを見つけなければなりません.この処理は,画像が増えれば増えるほど繰り返されます。

上の議論では、手動のフィーチャ・エンジニアリングは面倒だということが強調されていました。もし、与えられた問題に対して手動での特徴付けが面倒だとしたら、代替案は何でしょうか?それがディープラーニング、略してDLです。
ディープラーニングを用いた特徴抽出の自動化
DLは、従来の機械学習の自動化であり、使用する特徴量の最適な種類を機械自身が決定します。次の図は、従来のMLとDLのパイプラインを比較したものです。MLのパイプラインではフィーチャーエンジニアリングを行うのではなく、DLのパイプラインでは、人間がDLのアーキテクチャを構築する際にスーパービジョンを行うだけです。その後,誤差を極力減らすために最適な特徴量を自動的に見つけるための学習を開始します。画像などの多次元データの認識に用いられるDLアルゴリズムは、畳み込みニューラルネットワーク(CNN)です。
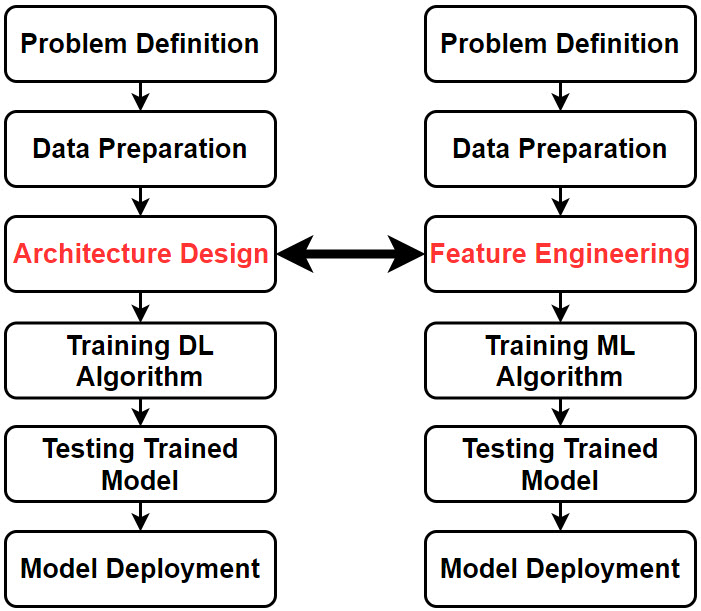
DLすると使い勝手の良いタイプの機能を見つけるのが格段に楽になりますが、気をつけないといけないことがあります。CNNが自動的に最適な特徴を見つけるために自分自身を適応させるためには、何千もの使用画像がなければなりません。例えばMobileNetは、100万以上のサンプルを含む地球上で最大の画像認識データセットであるImageNetを使って訓練されたCNNモデルです。このように、豊富なデータがMobileNetを構築する原動力となっています。もしそのような大規模なデータセットが利用できないのであれば、MobileNetは作られるべきではありませんでした。ここで重要な疑問が生じます。もし、一からDLモデルを構築するための大規模なデータセットがなく、従来のMLモデルを構築するために異なる特徴記述子を試す時間を節約したい場合、特徴を自動的に抽出するためにはどうすればよいのでしょうか?答えは転移学習です。
DLを利用するために、一からDLモデルを構築する必要はありません。事前に学習したDLモデルの学習を利用して,それを自分の問題に移植することができます。次のセクションでは、転送学習について説明します。
転移学習とは?
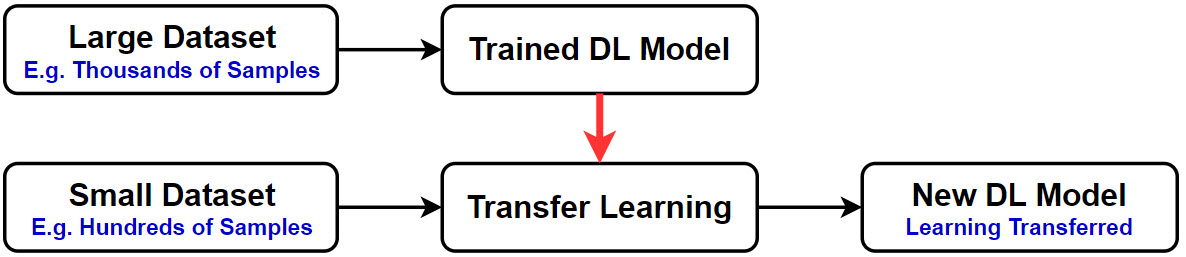
転移学習とは、創造よりも適応です。モデルはゼロから作成されるのではなく、事前に学習したモデルを新しい問題に適応させただけのものです。ゼロからDLモデルを構築するには十分ではない小さなデータセットがある場合、移動学習は自動的に特徴を抽出するためのオプションです。次の図はそのことを強調しています。
転移学習の前に、数千から数百万のサンプルが存在する大規模なデータセットでDLモデルを学習します。このように訓練されたDLモデルの学習は、転移学習を使って転送され、DLモデルが数百または数千の画像だけの別の小さなデータセットで動作するようになります。
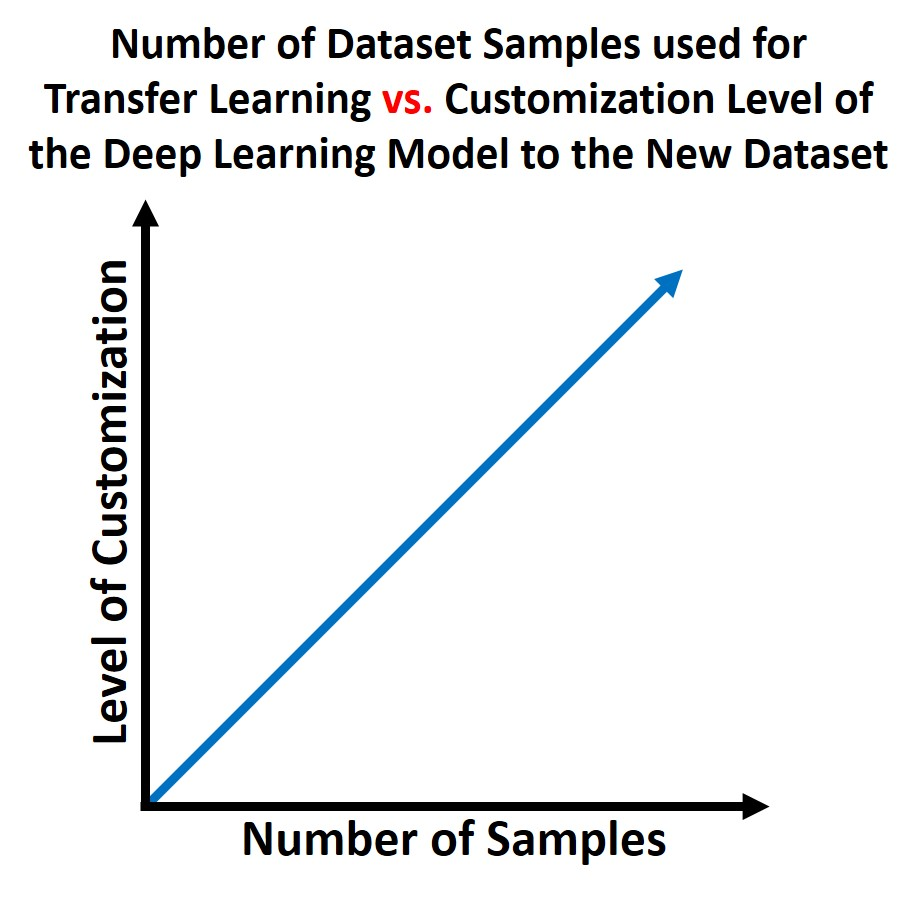
私は多くの人から、サンプル数が少ないデータセットでもディープラーニングを使用できるのかという質問を受けます。このような質問に対する明確な答えはありませんが、私が言えることは、新しいデータセットのサンプル数が増えるにつれて、転移学習から作成されたモデルの精度が向上するということです。新しいデータセットは、DLモデルの学習に用いた元のデータセットのように大きくなくてもよいですが、サンプル数が多ければ多いほど良いです。次の図に示すように、新しいデータセットのサンプル数が多いほど、新しいデータセットで動作するようにモデルがカスタマイズされます。その理由は、サンプル数が多いほど、事前に学習されたモデルのパラメータは新しいデータセットに対してより多くのカスタマイズを受けるからです。その結果、転移学習によって得られたモデルは、サンプル数の少ないモデルと比較して、より正確な予測を行うことができるようになります。
転送学習について多くの知識を得るために、次のセクションでは、転送学習を使用する理由について説明します。
なぜ転移学習をするのか?
転移学習を行う理由はいくつかあります。ここでは、その重要な理由をいくつかまとめてみました。
1、ゼロからモデルを構築するための訓練データやテストデータが不足しています。
2、データセットを拡大するためにデータにラベルを付ける必要がありません。
3、データの分布が不均衡。
4、学習データが十分であっても、ゼロからDLモデルを学習するには、通常、高い処理能力が必要であり、時間がかかります。
5、また,学習データが十分であっても,テストデータが学習データと似ていなかったり,学習データではカバーしきれなかった新しいケースがテストデータに含まれていたりすることがあります.そのような新しいケースをカバーするために、新しいサンプルでモデルを再訓練しなければなりません。
6、ゼロからモデルを構築するには、問題を研究し、物事の仕組みを深く理解する必要があります。
これらの点について議論してみましょう。
1. スクラッチからモデルを構築するための訓練データとテストデータの不足
予測モデルを構築する場合、MLエンジニアが最初に考える作業は、さまざまなケースに対応できる正確なモデルを構築するために、できるだけ多くのデータを収集することです。機械学習アルゴリズムであるパラメトリックなものは、データから学習すべきパラメータの数が多く、いくつかのタスクでは、アルゴリズムがこれらのパラメータを正しく学習するのに役立つ十分なデータがありません。
転移学習は、アルゴリズムがモデルを構築するためにゼロから訓練されないため、多くのデータを必要としません。むしろ、これらのパラメータを事前に学習した事前学習モデルが使用されます。手元の問題に合わせて訓練されたモデルを適応させるためには、少量のデータが必要です。
2. データセットを拡大するためにデータをラベル付けする必要がない
機械学習アルゴリズムの訓練とテストに使用されるデータセットが、モデルがしっかりとした学習状態に到達することを保証するのに十分大きくない場合、一部の機械学習エンジニアは、さまざまな方法でそのようなデータセットを拡大する傾向があります。最も好ましい方法は、より現実的なサンプルを集め、アルゴリズムの訓練に使用するためにそれらにラベルを付けることです。手動でラベリングを行うことは容易ではなく、自動ラベリングでは十分な精度が得られない可能性があります。
いくつかのタイプの問題では、ラベリングは問題ではないかもしれません。インスタンスのラベル付けは、インスタンス自体が利用可能になった後に行われます。問題によっては、インスタンスの数が限られていて、それ以上のインスタンスを簡単に作成することができないものもあります。医用画像の場合、実験にデータを利用するには患者の許可が必要であり、すべての患者が同意しているわけではありません。これ以上インスタンスを作成する方法がない場合は、画像データの増強などのテクニックが役立つかもしれませんが、それはまだあまり目的を果たしていません。これは、同じインスタンスを変換(回転など)して、より多くの画像を生成しているだけだからです。
転移学習は、ゼロからモデルを構築する必要がないため、多くのデータを必要としないため、この問題に取り組んでいます。事前に学習したモデルを微調整するだけの少量のデータで済みます。モデルの微調整に使用するデータを増やすことが好ましいですが、できなければそれでも大丈夫です。
3. データの不均衡な分布
前のポイントでは,データセットはバランスが取れているが,すべてのクラスのサンプル数が少ないという問題について述べました。バランスが取れているというのは,データセット全体のデータのうち,すべてのクラスがほぼ等しく,どのクラスも他のクラスよりも顕著にサンプル数が多いということを意味します。
他の問題では,あるクラスが他のクラスよりもサンプル数が多い場合があるかもしれません.この場合,データセットはクラス分布に不均衡があるとされます。その結果,機械学習モデルは,このクラスに強く偏り,他のクラスと比較してより重要性を与えます。このクラスラベルに従って入力サンプルを分類する確率は,他のクラスよりも高くなります.サンプルの比率が高いクラスは多数派クラスと呼ばれ,他のクラスは少数派クラスと呼ばれます。技術者はこの問題を様々な方法で処理しなければなりません。
少数クラスのサンプル数が少なくても,機械学習モデルを構築するのに十分な数であれば,多数派クラスのすべてのサンプルを使用するのではなく,その中から均等な比率のサンプルを選択して,バランスのとれたデータセットを得ることができます.
少数派クラスのサンプル数が少なく、そのような数では機械学習モデルを構築するのに十分でない場合、少数派クラスのいくつかの新しいサンプルを追加しなければなりません。前述したように、最も好ましい方法は、少数派クラスのより現実的なデータを収集することです。適用できない場合は、いくつかの新しいサンプルを作成するために、いくつかの構文的なテクニックが利用可能です。これらの技術の一つは、SMOTE (Synthetic Minority Over-sampling Technique) と呼ばれるものです。問題は、このように生成されたサンプルは現実的ではないということです。非現実的なサンプルが使用されればされるほど、学習プロセスは悪化します。
転移学習は、先に述べた理由でこの問題を克服します。少ない現実的なサンプルを使ってモデルを微調整すればよいのです。もちろん、この作業を行うためには、より多くのサンプルが好まれますが、サンプルがあまりない場合は、スクラッチから学習するよりも転移学習の方が好ましいオプションです。
4. スクラッチからDLモデルをトレーニングするには、高い処理能力が必要であり、多くの時間がかかる
これまでの指摘は、データ量が不足しているからといって、ゼロからモデルを構築して転移学習を利用するという発想を否定しています。データが多すぎると仮定した場合、それはゼロからモデルを構築して転移学習を使わないことを意味するのでしょうか?それは間違いなくNOです。転移学習はデータ量が少ないときだけに選択されるのではなく、ゼロからモデルを構築するには、処理能力の高い機械や大容量のRAMが必要になるからです。そのようなスペックを持った機械が全ての人に使えるとは限りません。クラウドコンピューティングが利用できたとしても、人によってはコストがかかるかもしれません。そのため、十分なデータ量があっても、転移学習が使われるかもしれません。十分なデータ量があれば、モデルをうまく微調整して、解決したい問題に適応させることができるかもしれません。
モデルは汎用的なものを想定し、エンジニアはそれを解決しようとしている問題に適応させます。これは、一般的なケースから目的に合ったより具体的なケースに移行することです。もちろん、微調整は、ゼロからモデルを構築するときに使用されるような大量のデータを必要としないかもしれませんが、それでも問題にモデルをうまく適応させるのに役立ちます。
5. 新しいテストサンプルはトレーニングデータには含まれていない
機械学習を用いて解決された問題のほとんどは,訓練データとテストデータが類似しており,同じ分布に由来しています。このデータに基づいて生成されたモデルは、訓練されたデータに似たサンプルによってテストされることが難しいとは思われません。問題は、いくつかの新しいサンプルが訓練データと類似しておらず、少し異なる分布をたどる可能性があることです。
機械学習のエンジニアは、このような新しいサンプルを扱う新しいモデルを構築することで、この問題に対処します。数えられないので、訓練で使用されたものとは異なる特性を持つサンプルのグループごとに、事前に訓練されたモデルの動作を変更することはできません。事前に訓練されたモデルは,本番で使用されることがあり,いくつかの新しいサンプルが利用可能になるたびに変更を加えることはできません。
転移学習を使用すると,事前学習されたモデルは,テストデータに存在する可能性のある多くのケースをカバーする数千から数百万のサンプルをすでに見ています。将来的に見慣れないサンプルを見てしまう可能性が低下します。
6. スクラッチからモデルを構築するには、問題の調査と物事の仕組みを深く理解する必要がある
研究者が深層畳み込みニューラルネットワーク(DCNN)を構築する場合、最初のステップは、人工ニューラルネットワーク(ANN)がどのように機能するかをしっかりと理解していることです。ANNの拡張として、研究者はCNNがどのように機能するか、そしてその異なるタイプの層をよく理解していなければなりません。また、研究者は、異なる層を積み重ねることによって、解決しようとしている問題のためのCNNアーキテクチャを作成しなければなりません。これは非常に挑戦的な作業であり,最良のCNNアーキテクチャを導き出すためには多くの時間と努力が必要です。
転移学習を使えば、研究者はすべてを知る必要はありません。微調整するパラメータの数を気にするだけでよいのです。
転移学習が有益なユースケース
猫と犬の2つのクラスのデータセットがあり、その分類タスクのためにCNNを作成するとします。高い分類精度を達成するためのアーキテクチャを作るのに時間と労力がかかるかもしれない。馬とロバの2つのクラスのデータセットを分類するタスクがある場合、猫と犬の分類のために同じ作業を繰り返すのは疲れてしまいます。このような場合には、転移学習が有効です。猫と犬のデータセットで学習したCNNから学習したことを、馬とロバの分類という別のタスクに移すことができます。これにより、最初からやり直す時間を大幅に節約することができます。
転移学習の利用条件
転移学習は正しい使い方をすれば、大きな成果を得ることができます。しかし、転移学習には誤用もあります。したがって、事前に訓練されたDLモデルに転送学習を使うかどうかを決めるための主な条件を強調することが重要です。議論されている条件は以下の通りです。
1、データ型の整合性
2、問題領域の類似性
この2つの条件について考えてみましょう。
1. データ型の整合性
ある問題から別の問題に学習を移す前に、使用するデータに関して2つの問題が一致している必要があります。データの種類とは、画像、音声、テキストなどを意味します。
DLモデルの構築に画像が使われている場合、そのようなモデルの学習を新しい問題に移す際にも画像が使われなければなりません。画像を用いて学習したものを、音声データを用いた新しい課題に移行するのは正しくありません。画像から学習した特徴は、音声信号から学習すべきものとは異なるものであり、その逆もまた然りです。
2. 問題領域の類似性
データの整合性は、転送学習の前に有効でなければならない非常に重要な要素です。その他の要因は、転送学習を利用するメリットを最大化することに寄与します。2つの問題の領域間に類似性があることが好ましいのです。データの種類だけでなく、2つの問題がどれだけ類似しているかについても話します。1つの問題は、猫と犬の分類に関するものかもしれません。この問題から得られた学習は、馬やロバなどの他の2種類の動物を分類する別の問題にも当てはまるようです。
問題の領域が異なっていても、2種類の腫瘍を分類する問題にこのような学習を移すことは可能でありますが、能力に限界があります。2種類の腫瘍を分類する問題に画像データを使用した場合でも、問題の領域が異なっているため、転移学習は適用可能ですが、その能力は限られています。CNNでは、いくつかの層がどんなタイプの問題にも適用できる汎用的な特徴を学習しています。CNNをさらに深く掘り下げていくことで、層は解決されるタスクに特化していきます。猫と犬のデータセットは馬と猿のデータセットと領域が似ているので、どちらかで学習したモデルで学習した特徴の多くは他の問題にも適用できます。言い換えれば,類似性はCNNの中でより深いレベルにまで及びますが,そのような学習を別の領域の問題に移すと浅いレベルになるのに対し,CNNではより深いレベルにまで及びます。
結論
このチュートリアルでは、まず従来の機械学習パイプラインについて説明し、特に大規模で複雑なデータセットの場合、手動での特徴抽出は困難であることを強調しました。ディープラーニングを使えば、特徴抽出は自動化されます。しかし、ゼロからディープラーニングモデルを構築するためには、大規模なデータセットが必要です。小さなデータセットからの自動特徴抽出のためにディープラーニングを使用するには、転送学習が選択肢となります。
次回のチュートリアルであるPart2では、Fruits360データセットの内容をダウンロードし、準備し、分析するところから実践的な部分を紹介します。パート2の終わりまでに、クラスラベルに加えて、すべてのデータセットの画像データを保持するためのNumPy配列が作成されます。このようなデータは、後にMobileNetに供給され、移動学習後に特徴を抽出します。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ