この記事では、サービスメッシュに関するあらゆる情報を簡単に紹介しています。
アリババでYixinの愛称で親しまれているPeng Jiahaoが執筆しました。PengはAlibaba Taobao Technology Departmentの開発エンジニアであり、クラウドコンピューティングの熱心な愛好家でもあります。
コンピュータ・ソフトウェア技術の急速な発展に伴い、ソフトウェア・アーキテクチャの世界全体が、開発者が大規模で複雑なアプリケーションを簡単かつ迅速に構築できるように、さまざまな新しい方法で進化しています。コンテナ技術は、ランタイム環境の不整合の問題を解決するために最初に開発されました。そして、コンテナ技術によってますます多くの新しい可能性が開かれてきました。
近年、この発展により、クラウドコンピューティング分野では、クラウドネイティブ、ファンクションコンピュート、サーバーレス、サービスメッシュなど、多くの新しいソフトウェアアーキテクチャモデルが登場しています。
マイクロサービスとサービスガバナンスとは
マイクロサービスが登場する以前のソフトウェア開発プロセスでは、すべてのモジュールが1つのアプリケーションに含まれ、コンパイル、パッケージ化、デプロイ、メンテナンスも一緒に行われることが多く、その結果、1つのアプリケーションに含まれるモジュールの数が多すぎることがよくありました。そして、このアプリケーションのモジュールが故障したり、アップデートが必要になったりした場合、アプリケーション全体を再デプロイしなければなりませんでした。この方法は、開発者、特にDevOps担当者にとって大きな頭痛の種となっていたのです。そしてもちろん、アプリケーションが複雑になるにつれ、より多くのオブジェクトが関係するようになりました。
開発者は、このプロセスに多くの欠点があることを発見しました。これらの問題に対処するため、開発者はサービスをグループ化し、大規模なアプリケーションを、アプリケーション間の呼び出し関係を持つ多くの小さなアプリケーションに分割するようになりました。異なる小さなアプリケーションは、異なる開発者によって管理、デプロイ、メンテナンスされました。これがマイクロサービスという概念が生まれた基本的な経緯です。
マイクロサービスのアプリケーションは、異なるホスト上に展開されます。つまり、サービスが互いに通信し、連携する方法を見つける必要があります。この状況は、単一のアプリケーションよりもはるかに複雑です。同じアプリケーション内の異なるメソッド間の呼び出しは、コードのコンパイルやパッケージ化の際に同じメモリにリンクされているため、アドレス指定が可能で高速です。しかし、マイクロサービス内の異なるサービス間の呼び出しには、異なるプロセスやホスト間の通信が含まれるため、一般的にはサードパーティ製のミドルウェアを介して仲介・調整する必要があります。
このような理由から、サービスガバナンス・フレームワークを含むマイクロサービス指向のミドルウェアが数多く開発されています。これらのサービスガバナンスツールは、統合されているすべてのアプリケーションを管理することができ、サービス間の通信や調整を簡素化し、高速化します。
コンテナとコンテナオーケストレーションとは
コンテナ技術は、アプリケーションの実行環境における矛盾を解決するために開発されたもので、ローカル環境やテスト環境では正常に動作していても、本番環境ではクラッシュしてしまうような状況を回避することができます。プログラムとその依存関係はコンテナによってイメージにパッケージ化され、コンテナサービスがインストールされたホスト上では、複数のコンテナが起動して実行されます。
各コンテナは、アプリケーション・ランタイム・インスタンスです。これらのインスタンスは、通常、同じ実行環境とパラメータを持っています。そのため、アプリケーションは異なるホストでも一貫したパフォーマンスを得ることができます。これにより、異なるホストで同じ実行環境を構築する必要がなく、開発、テスト、O&Mが容易になります。
イメージをイメージリポジトリにプッシュすることで、アプリケーションの移行やデプロイを容易にすることができます。数ある技術の中でも、Dockerは最も広く使われているコンテナ技術の一つです。現在、多くのアプリケーションがマイクロサービスとしてコンテナを使用してデプロイされており、これらの開発は時間の経過とともに増加する一方です。これらはすべて、ソフトウェア開発を大きく活気づけています。
また、コンテナを使用してデプロイされるアプリケーションが増えるにつれ、1つのクラスターで使用されるコンテナの数も時間の経過とともに大きく増加しています。しかし、これらのコンテナを手作業で管理・維持することは困難であるため、コンテナ間の関係を管理するためのオーケストレーションツールが数多く開発されています。これらのツールは、コンテナのライフサイクル全体を管理することができます。例えば、Docker社がリリースしているDocker ComposeやDocker Swarmは、コンテナを一括して起動し、オーケストレーションを行うことができます。しかし、これらは簡単な機能しか提供しておらず、大規模なコンテナクラスタには対応できません。
この問題を解決するために、Googleはコンテナ管理の豊富な経験をもとにKubernetesプロジェクトを開発しました。1週間に数億個のコンテナが投入されるGoogleクラスターのために設計されたKubernetesは、強力なコンテナオーケストレーション機能とさまざまな機能を備えています。Kubernetesでは多くのリソースが定義されており、これらのリソースは、宣言的に作成されます。リソースは、JSONやYAMLファイルで表現することができます。Kubernetesは複数のコンテナをサポートしており、その中でもDockerコンテナが最も一般的です。Kubernetesは、コンテナへのアクセスに関連する標準を提供し、その標準に準拠したあらゆるコンテナをオーケストレーションすることができます。
企業のすべてのアプリケーションがマイクロサービス化され、コンテナを使用してデプロイされた後、Kubernetesをクラスタにデプロイし、Kubernetesが提供する機能を使用してアプリケーションコンテナを管理し、KubernetesのO&Mオペレーションを行うことができます。最も広く使用されているコンテナオーケストレーションツールであるKubernetesは、コンテナオーケストレーションの標準となっています。しかし、アリババグループは、独自のコンテナとコンテナオーケストレーションツールを開発しています。さらに、業界全体では、Kubernetesに代表されるコンテナ管理手法から派生した新しい技術も出てきています。
クラウドネイティブとは
この2年間、クラウドネイティブは、クラウドコンピューティングやIT全般において、非常にホットな話題となってきました。CNCF(Cloud Native Computing Foundation)は、クラウドネイティブの定義を次のように述べています。
クラウドネイティブテクノロジーは、パブリッククラウド、プライベートクラウド、ハイブリッドクラウドなどのモダンでダイナミックな環境で、スケーラブルなアプリケーションを構築・実行することを可能にします。コンテナ、サービスメッシュ、マイクロサービス、不変のインフラ、宣言型APIなどがこのアプローチの例です。
これらの技術は、耐障害性、管理のしやすさ、観測のしやすさに優れた疎結合システムを構築することができます。堅牢な自動化と組み合わせることで、エンジニアは最小限の労力でインパクトの大きい変更を頻繁に、かつ予測可能に行うことができます。
クラウドネイティブとは、簡単に言えば、アプリケーションをマイクロサービスとして開発し、コンテナを使ってデプロイし、Kubernetesなどのコンテナオーケストレーションツールを使ってコンテナクラスタを管理し、開発やO&MをKubernetesに向かわせる行為を本質的に指します。クラウドネイティブが有用なのは、アプリケーションを簡単に構築し、包括的に監視し、トラフィックに応じて迅速にスケールアップ/ダウンすることができるからです。
これは下の画像のようなものです。
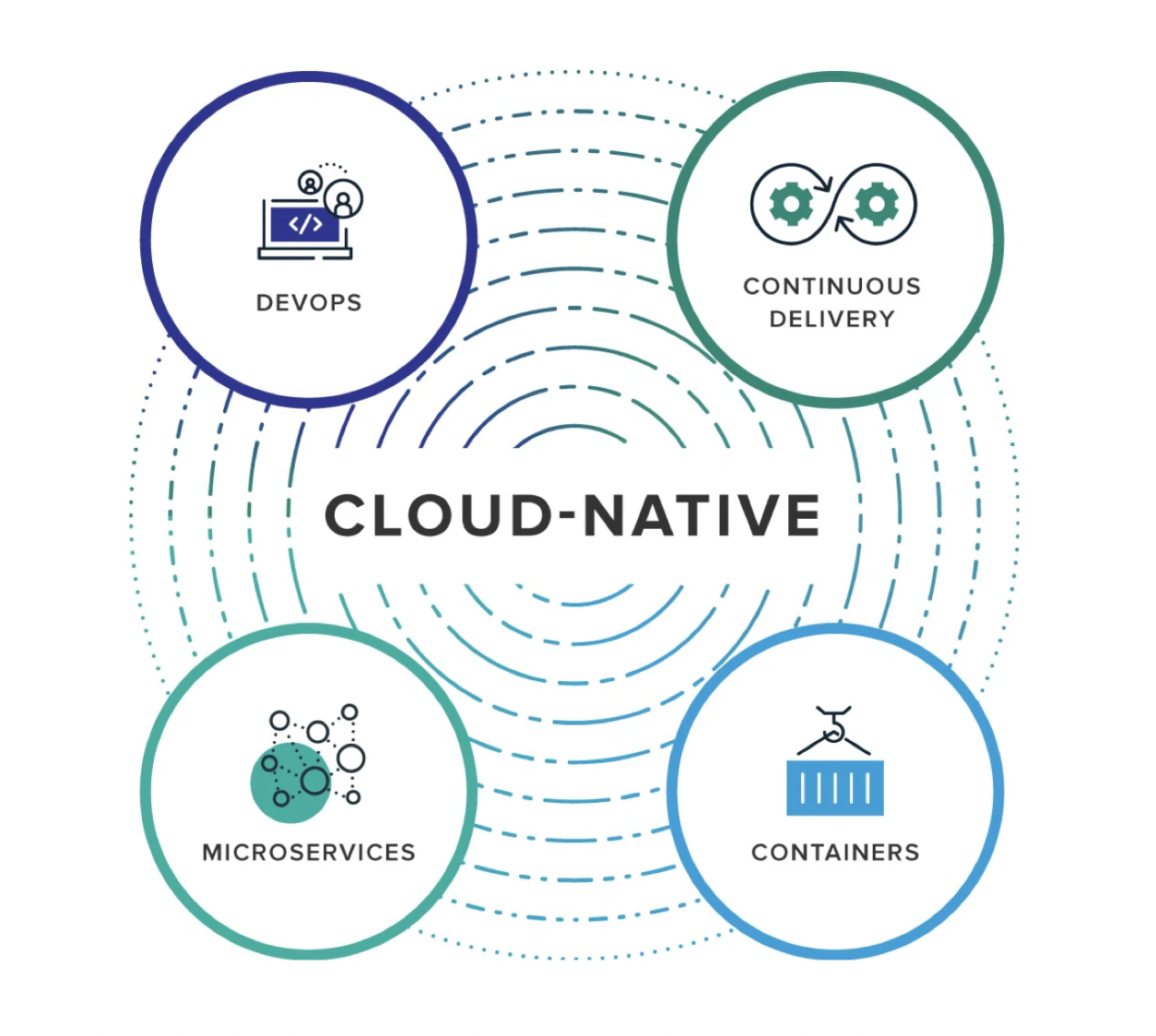
クラウドネイティブは、多かれ少なかれ、マイクロサービス、コンテナ、継続的インテグレーションとデリバリー、そしてDevOpsの4つの部分で構成されています。
サービスメッシュとは?
この記事では、マイクロサービス、コンテナ、コンテナオーケストレーション、クラウドネイティブについて説明してきました。これらはすべて、本記事のメイントピックであるサービスメッシュの背景となるものです。一言で言えば、サービスメッシュはクラウドネイティブなマイクロサービスガバナンスソリューションと言えるでしょう。
コンテナを使ってマイクロサービスとしてKubernetes上にアプリケーションをデプロイした後、サービスメッシュは、サービス間コールとガバナンスのための新しい透明なソリューションを私たちとアプリケーションに提供します。このソリューションは、従来のマイクロサービスガバナンスフレームワークに依存することから解放されます。
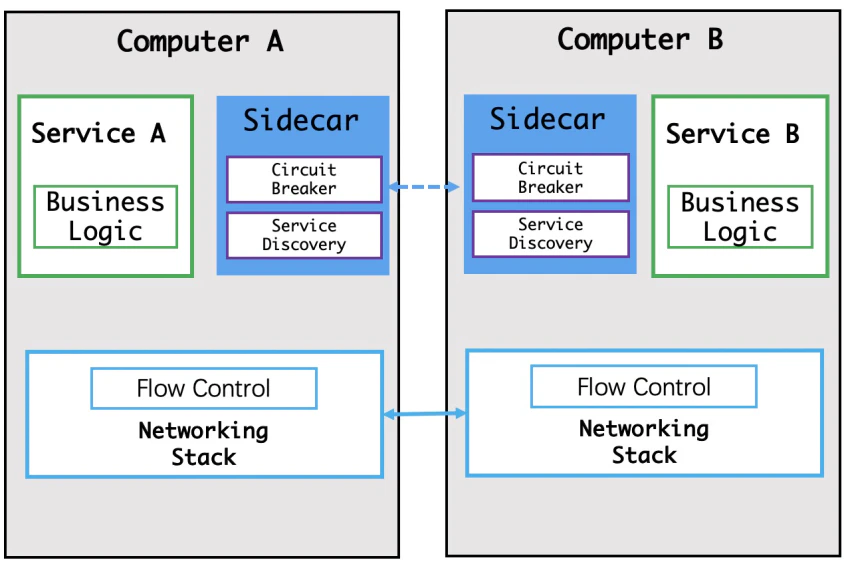
サービスメッシュの仕組みは、アプリケーションの透過的なプロキシとして、ポッド内の各アプリケーションにSidecarを起動します。そして、アプリケーションのインバウンドとアウトバウンドのトラフィックはすべてそのSidecarを経由します。サービス間のコールはSidecar間のコールとなり、サービスのガバナンスはSidecarのガバナンスとなります。
サービスメッシュでは、Sidecarは透明で、開発者には気づかれません。これまでは、アプリケーションを発見して呼び出すためには、必ずライブラリを導入したり、サービスを登録したりしなければなりませんでした。しかし、サービスメッシュにおけるアプリケーションは、開発者にとって完全に透過的です。
この実装では、コンテナオーケストレーションツールを利用しています。Kubernetes上での継続的なアプリケーションの統合と配信において、アプリケーションのポッドが起動した後、そのサービスはすでにYAMLファイルでKubernetesに登録され、サービス間の関係が宣言されています。サービスメッシュはKubernetesと通信することでクラスタ内のすべてのサービス情報を取得し、Kubernetesを通じた開発者への透明性を実現します。
下の画像は、データプレーンとコントロールプレーンを含むService Meshの基本構造を示したものです。
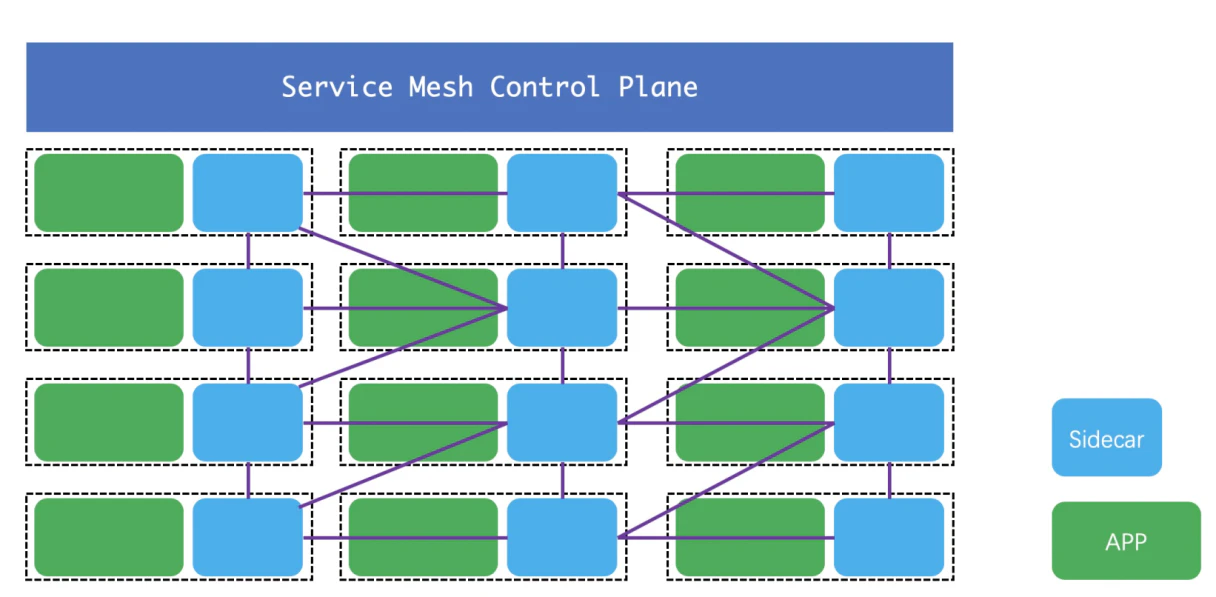
このモードには多くの利点があります。このモードで使用される言語は、サービスガバナンスのプロセスに影響を与えません。サービスメッシュは、ポッドまたはポッド内のコンテナインスタンスにのみ関心があり、コンテナ内のアプリケーションの実装言語には関心がありません。サイドカーは、管理するコンテナと同じポッドに配置されます。
サービスメッシュは、従来の多くのサービスガバナンスフレームワークの大きな欠点である、クロスランゲージサポートを実装することができます。また、従来のサービスガバナンスを使用すると、アプリケーションの依存関係が大きくなり、依存関係の競合が発生する可能性があります。アリババグループは、Pandoraを使ってアプリケーションの依存関係を分離しています。さらに、従来のサービスガバナンスは難しく、開発者がアーキテクチャ全体についてある程度の知識を持っている必要があります。
従来のサービスガバナンスのフレームワークでは、問題のトラブルシューティングが困難です。また、開発とO&Mの境界が曖昧になってしまいます。しかし、サービスメッシュでは、開発者はコードを提供するだけでよく、O&M担当者はKubernetesをベースにしたコンテナクラスタ全体を維持することができます。
サービスメッシュの発展の経緯
サービスメッシュという言葉は2016年に初めて登場し、この2年間で非常に普及しました。Ant FinancialはSOFAMeshという完全なサービスメッシュのサービスフレームワークを持っており、Alibabaの他の多くのチームもこれに続いています。
ここ数年で多くの変化があったにもかかわらず、プログラム開発はよりシンプルになっています。例えば、アリババでは、完成された技術システムと強力な技術力のおかげで、1秒間に多くのクエリをサポートするサービスを簡単に構築できるようになりました。
では、アプリケーション開発のプロセスを見てみましょう。
1ステージ:ホスト間の直接接続
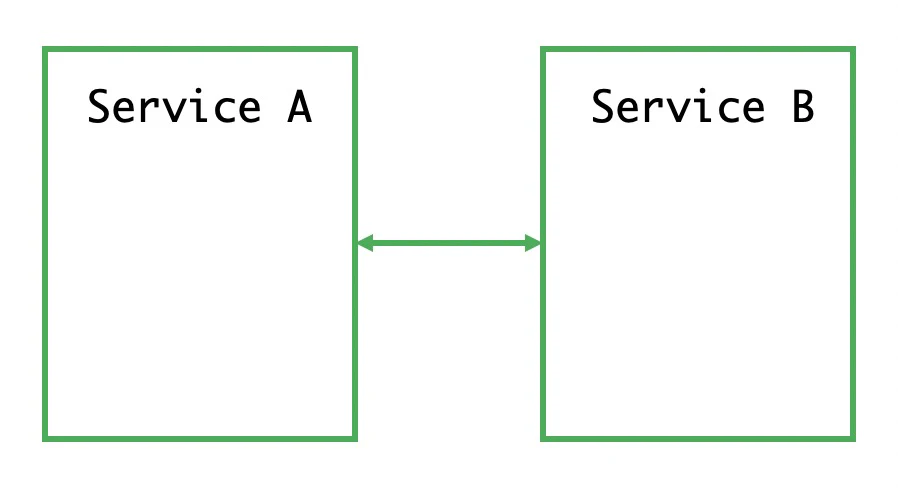
上の図は一番古い段階です。この段階では、2つのホストがネットワークケーブルで直接接続されており、1つのアプリケーションに2つのホストの接続管理を含むすべての機能が含まれていました。この頃は、まだネットワークという概念ができておらず、結局、ネットワークケーブルで直接接続されたホスト同士しか通信できなかったのです。
2ステージ:ネットワーク層の登場
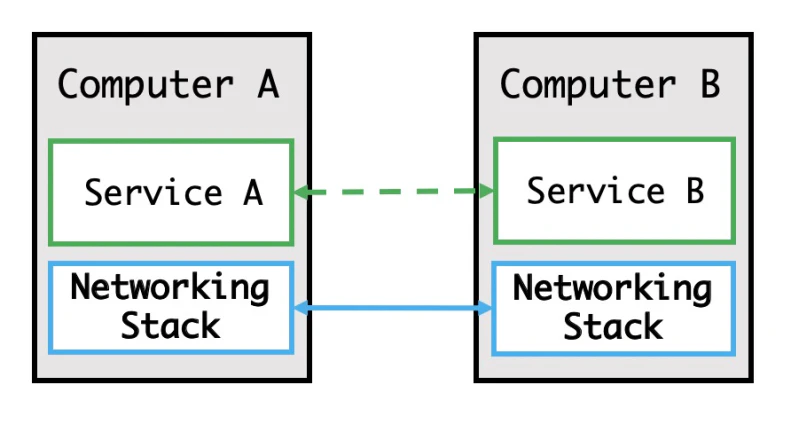
この段階では、いくつかの新しい技術の開発に伴い、ネットワーク層が登場しました。ホストは、ネットワークを介して、ホストに接続されている他のすべてのホストと通信することができます。
ステージ3:アプリケーションに組み込まれたスロットル機能
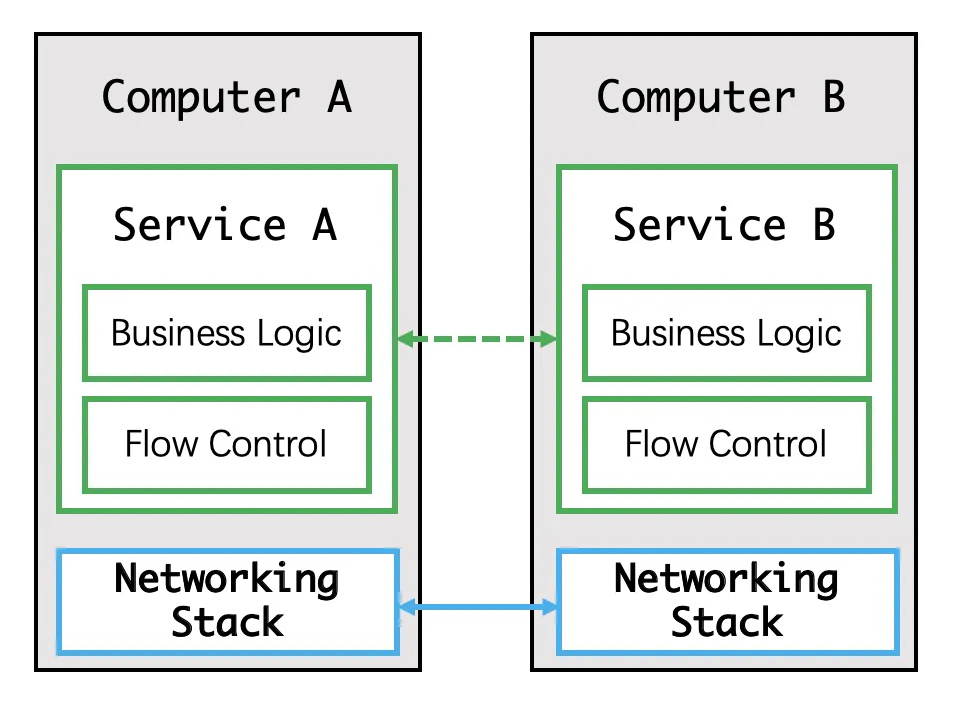
この段階では、各アプリケーションの環境やホストの構成によって、トラフィックを受信できるかどうかが変わってきます。例えば、アプリケーションAから送られてくるトラフィックがアプリケーションBの許容量を超えると、受信できないデータパケットが発生し、結果的に廃棄されてしまいます。このような問題があるため、トラフィックを制御する必要がありました。この段階では、スロットリングはアプリケーション側で行い、ネットワーク層はアプリケーションからのデータパケットのみを送受信していました。
ステージ4:ネットワーク層によるスロットリングの実現
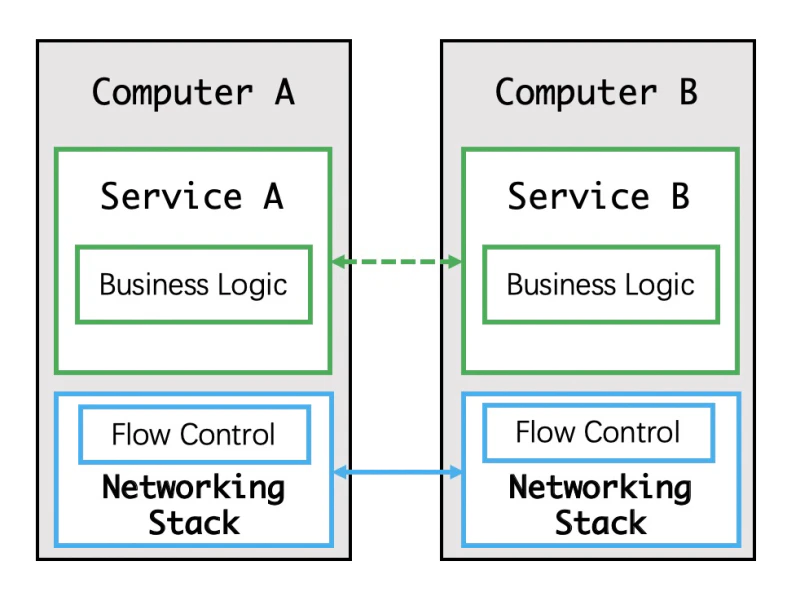
だんだんと、この段階になると、上の図のように、アプリケーションでのネットワークスロットルをネットワーク層で実装できることがわかってきました。もちろん、ネットワーク層でのスロットリングとは、ネットワーク通信の信頼性を確保するために行われたTCPスロットリングのことです。
ステージ5:サービスディスカバリーとサーキットブレーカーのアプリケーションへの統合
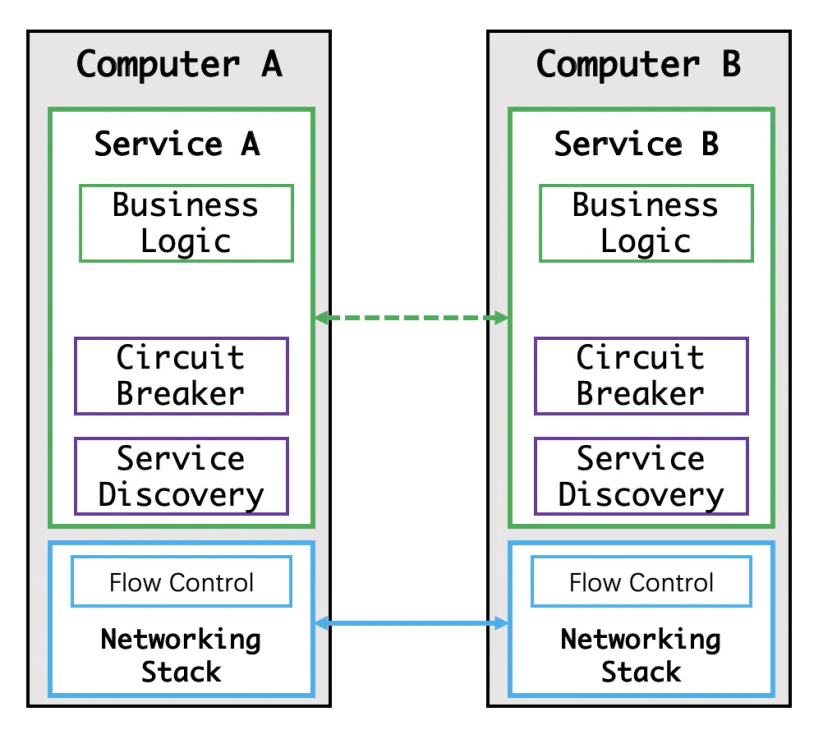
開発者はこの段階で、自分のコードモジュールにサービスディスカバリーとサーキットブレーカーを実装し始めました。
ステージ6:サービスディスカバリーとサーキットブレーカーに特化したソフトウェアパッケージとライブラリ

開発者はこの段階で、サードパーティの依存関係を参照することで、サービスディスカバリーやサーキットブレーカーを実装できるようになりました。
ステージ7: サービスディスカバリーとサーキットブレーカーに特化したオープンソースソフトウェア
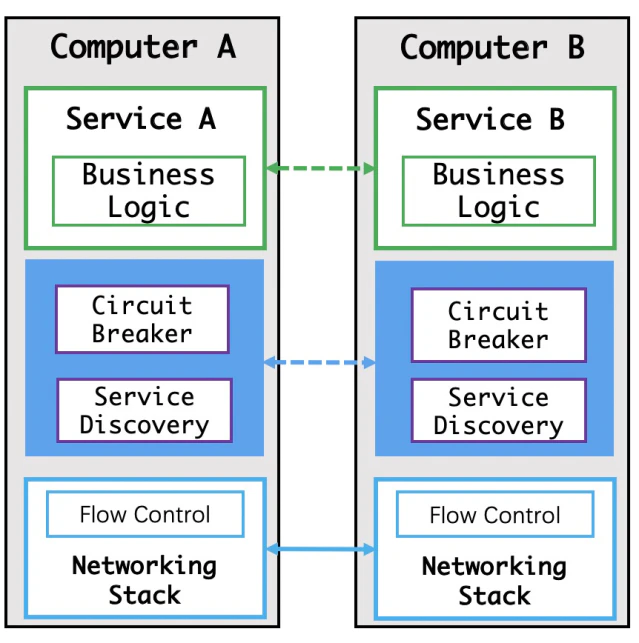
この段階では、様々なミドルウェアをベースに、サービスディスカバリーやサーキットブレーカーが実装されます。
ステージ8: サービスメッシュの登場
サービスメッシュの登場により、ソフトウェアのライフサイクル全体での生産性の向上と効率化がさらに進みました。
市場での競争
サービスメッシュが一般的なソリューションになったのは、2017年末のことでした。この人気に伴い、マイクロサービス市場では競争が激化し始めました。しかし、現実にはサービスメッシュは2016年の初めには登場していました。
2016年1月、インフラエンジニアのWilliam MorganとOliver Gouldは、Twitterを退社した後、Linkerd 0.0.7をGitHubで公開しました。これにより、業界初のサービスメッシュプロジェクトが誕生しました。Twitterのオープンソースプロジェクト「Finagle」をベースにしたLinkerdは、Finagleのクラスライブラリを再利用しながらも、ユニバーサルな機能を実現し、業界初のサービスメッシュプロジェクトとなりました。
Envoyは、2番目に登場したサービスメッシュプロジェクトです。Linkerdとほぼ同時期に開発され、どちらも2017年にCNCFのプロジェクトとなりました。
2017年5月24日、Istio 0.1がリリースされました。GoogleとIBMが注目度の高いスピーチで発表し、コミュニティは熱狂的に反応し、多くの企業がプロジェクトへの支援を表明しました。
Istioのリリース後、LinkerdはすぐにIstioの影に隠れてしまいました。業界で2つしかないプロダクションレベルのサービスメッシュ実装の1つとして、Linkerdは、Istioが本格的に成熟するまでは、もちろん市場での競争力を維持することができました。
しかし、Istioが着実に進化・成熟していく中で、IstioがLinkerdに取って代わるのは時間の問題でした。
Linkerdとは対照的に、Envoyは2016年からIstioのSidecarとして機能することを決断しました。Envoyはデータプレーンで動作し、ほとんどの作業はIstioのコントロールプレーンで完結できるため、多くの機能を必要としませんでした。そのため、Envoyをサポートするチームは、データプレーンの詳細な改善に集中することができました。Linkerdとは全く異なる性質を持つEnvoyは、ニッチな存在となり、主要なサービスメッシュの市場における激しい競争の対象ではなくなりました。
GoogleとIBMが共同で発表したIstioは、その後も常に脚光を浴びており、Service Meshの愛好家から広く賞賛されています。次世代のService Meshとして、IstioはLinkerdよりも明らかに優れています。また、プロジェクトのロードマップでは、今後さまざまな新機能がリリースされる予定です。私たちはそれを楽しみにしています。
Istioとは
Istioは、オープンソースのService Meshプロジェクトの中でも最も人気のあるプロジェクトですが、その概要は以下の通りです。データプレーンとコントロールプレーンに分かれています。Istioはクラウドネイティブなマイクロサービスガバナンスを実装しており、サービスディスカバリー、スロットリング、セキュリティモニタリングなども実装できます。Istioは、アプリケーションとSidecarをポッドで起動することで、透過的なプロキシサービスを提供します。Istioは、Kubernetesをはじめ、Mesosなどのリソーススケジューラーに対応した拡張性の高いフレームワークです。下図にIstioのアーキテクチャを示します。
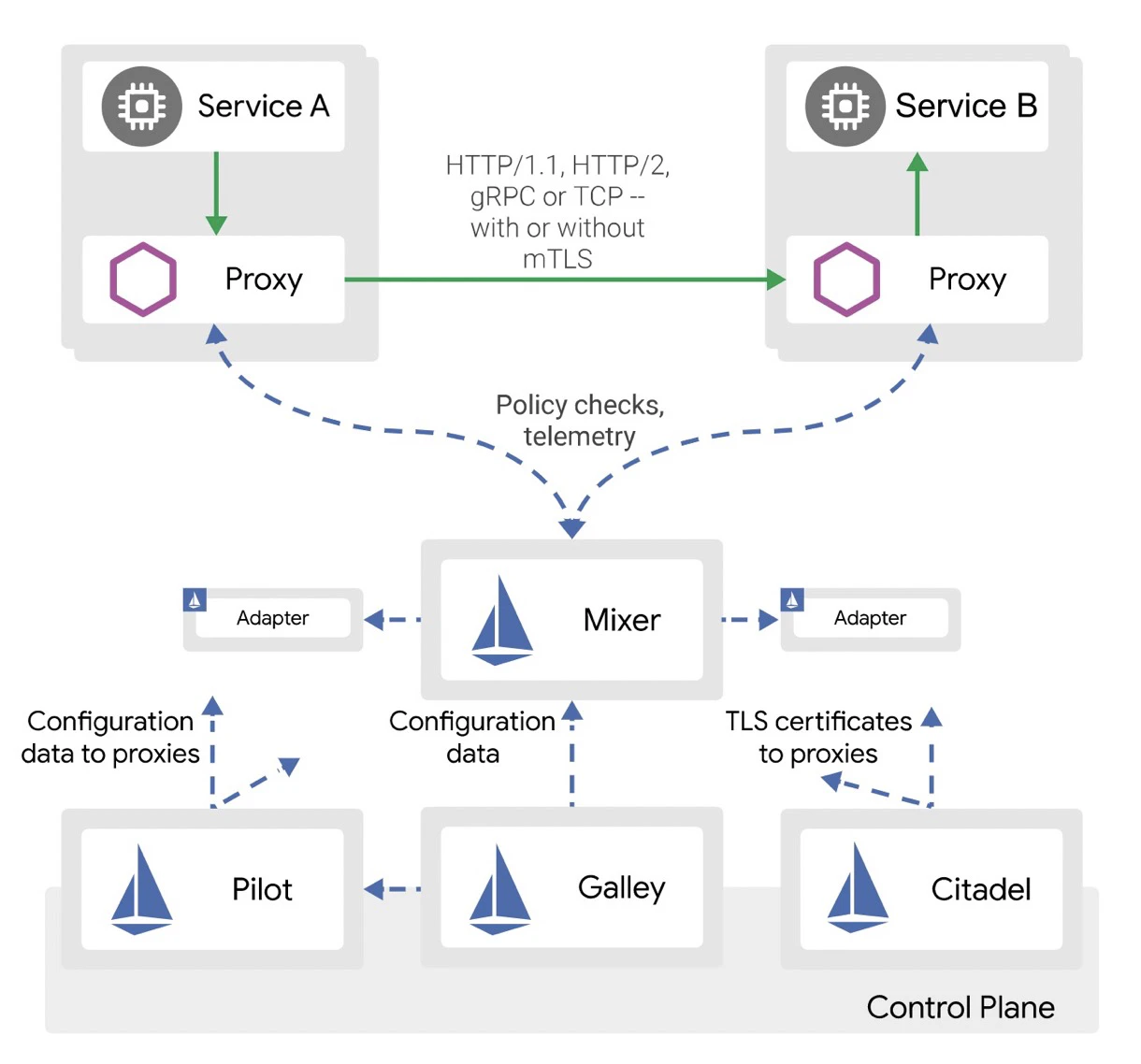
- Istioは論理的に、図の上側のデータプレーンと、図の下側のコントロールプレーンに分かれています。
- データプレーンは、サイドカーモードで配置されたインテリジェントプロキシ(Envoy)のグループで構成されています。これらのプロキシは、マイクロサービスとMixer間のすべてのネットワーク通信を調整・制御することができます。
- コントロールプレーンは、トラフィックをルーティングするためのプロキシの管理と設定を行います。さらに、コントロール・プレーン上でMixerが構成され、ポリシーの実行やテレメトリー・データの収集を行います。
- Pilotは、アーキテクチャにおける抽象化層であり、Kubernetesなどのリソーススケジューラの接続処理を抽象化し、アダプタとして提示し、ユーザーやSidecarsと対話します。
- Galleyはリソースの設定を検証します。
- Citadelは、IDを生成し、鍵や証明書を管理します。
- コア機能としては、スロットリング、セキュリティコントロール、オブザーバビリティ、マルチプラットフォーム対応、カスタマイズなどがあります。
Mixerとは
Mixerは、Istioのスケーラブルなモジュールです。リモートセンシングデータを収集し、いくつかのBaaS(Backend-as-a-Service)モジュールを統合しています。Sidecarは継続的にトラフィックをMixerに報告し、Mixerはトラフィック情報をまとめて表示します。サイドカーは、Mixerが提供する認証、ログオン、ロギングなどのBaaS機能を呼び出すことができます。Mixerはアダプタを介して様々なBaaSモジュールに接続します。
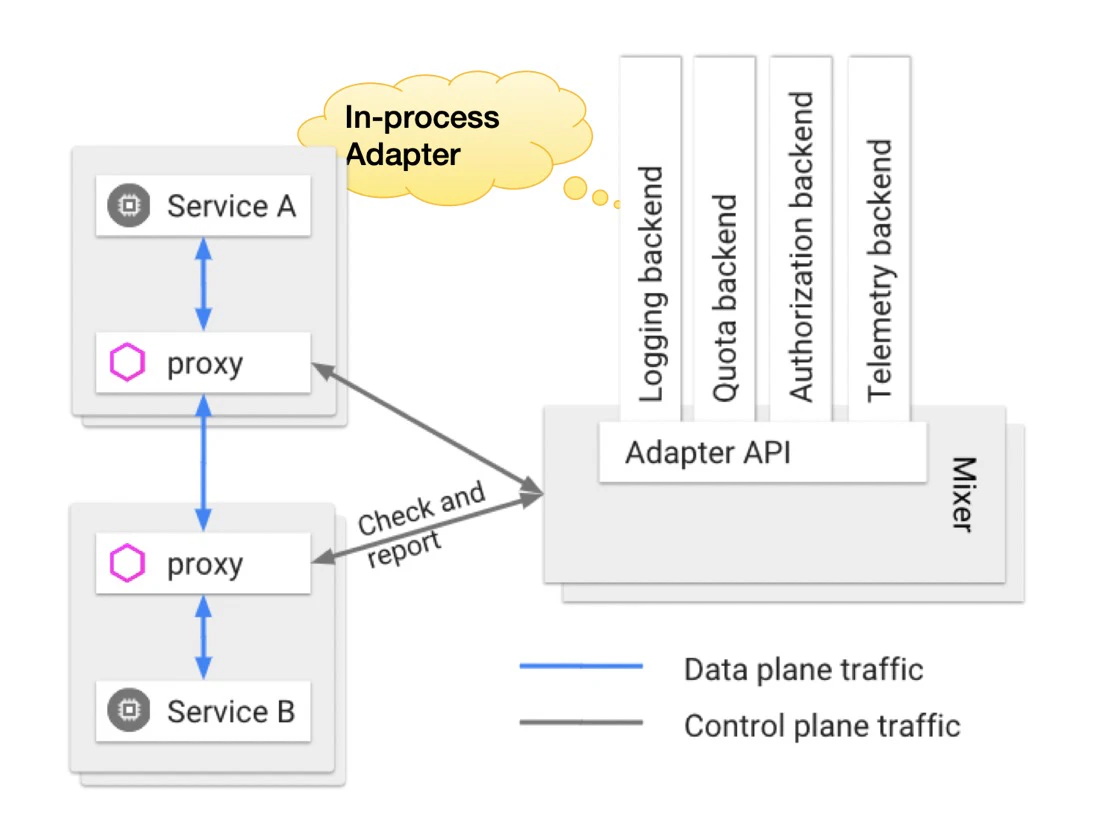
インプロセス・アダプターとは
Istioの初期のバージョンでは、BaaSアダプターはMixerに統合されていました。このモードでは、メソッドの呼び出しは同じプロセス内で高速に行われますが、1つのBaaSアダプターの障害がMixer全体に影響を与えます。
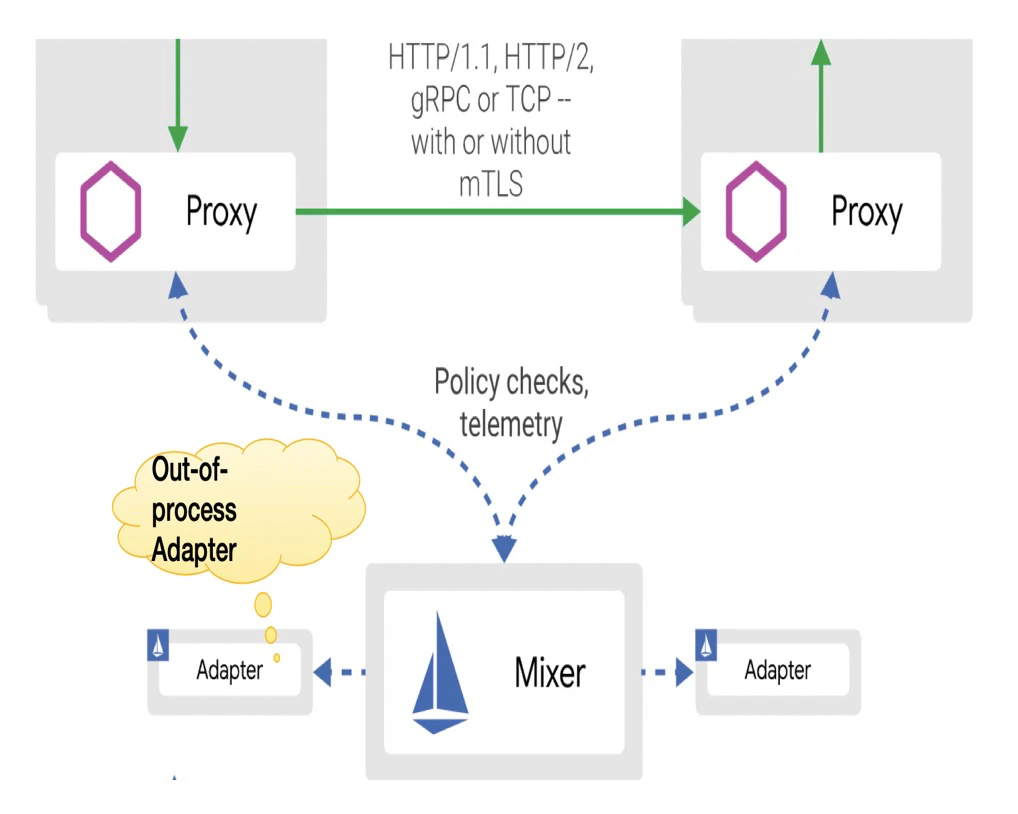
アウトオブプロセス・アダプターとは
Istioの最新バージョンでは、アダプタがMixerの外に移動し、Mixerとアダプタが切り離されました。つまり、アダプタが故障してもMixerには影響しないということになります。しかし、アダプタとMixerの間の呼び出しはRPC(リモート・プロシージャ・コール)で実装されており、同一プロセス内のメソッド呼び出しよりもはるかに遅いというデメリットがあります。そのため、パフォーマンスに影響が出ます。
パイロットとは
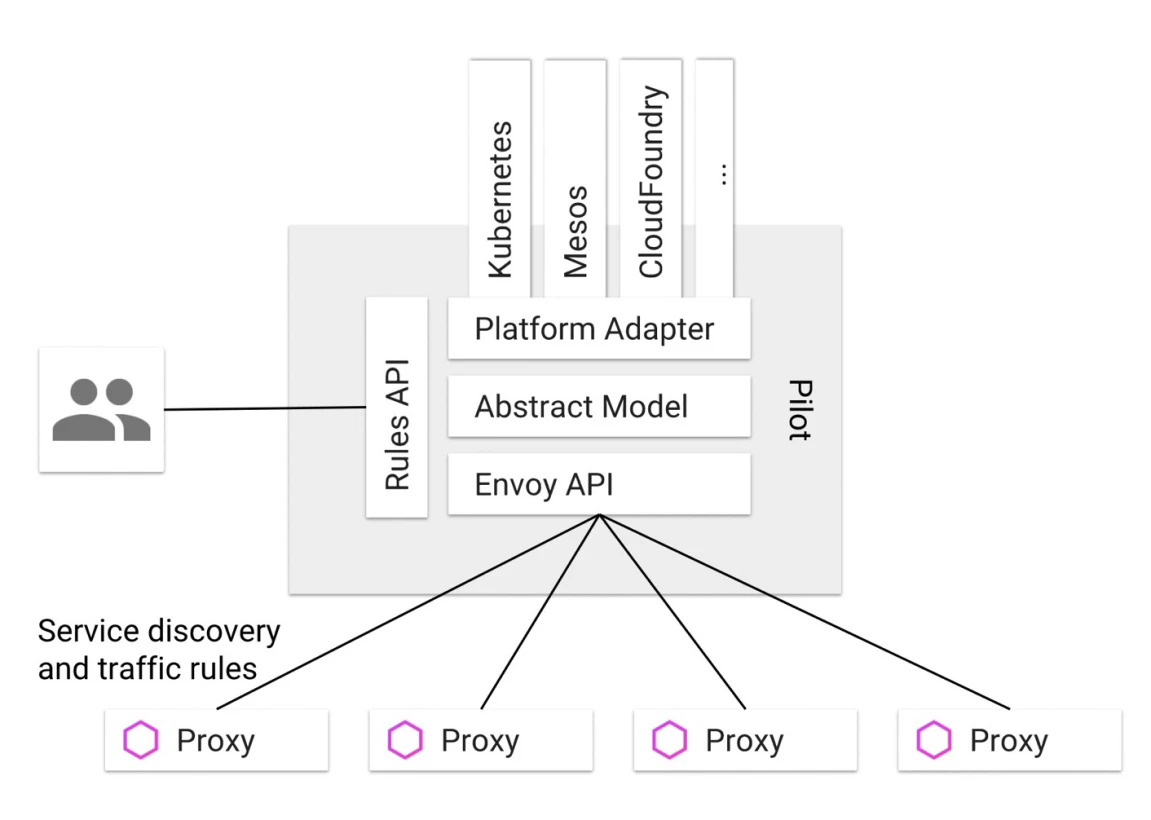
- Envoy API は、サービスの発見情報とスロットリングルールを Envoy に送信します。
- 抽象モデルは、特定のプラットフォームの詳細を切り離し、クロスプラットフォームのサポートを提供するためにPilotによって定義されます。
- Platform Adapterは、この抽象モデルの実装版であり、KubernetesやMesosなどの異なる外部プラットフォームに接続します。
- Rules APIは、外部システムがPilotを管理できるように提供されており、Istio CLI(istioctl)や、将来登場する可能性のあるサードパーティの管理インターフェースなどが含まれます。
Galleyとは
Galleyは、Istioのコントロールパネルの一部です。もともとGalleyは設定の検証のみを行っていました。しかし、Istioのバージョン1.1からは、Galleyがコントロールプレーン全体の構成管理センターとして機能し、構成の管理や配布もできるようになりました。Galleyは、Mesh Configuration Protocolを使って、他のコンポーネントとコンフィグレーションを交換します。
Istioには50以上のCustom Resource Definitions(CRD)があります。Kubernetes指向のプログラミングは、YAML指向のプログラミングに似ているという声も多いです。初期の頃、Galleyはランタイム中にコンフィグレーションを検証するだけで、Istioコントロールプレーンの各コンポーネントは対応するコンフィグレーションをリストアップしたり、ウォッチしたりしていました。しかし、コンフィグレーションの数の増加と複雑化は、Istioユーザーに多くの不便をもたらしました。
- 設定はまとめて管理されておらず、コンポーネントは別々にサブスクリプションを行い、統一されたロールバックメカニズムはありません。このため、コンフィギュレーションの問題を特定することが困難です。
- コンフィギュレーションの再利用性は比較的低く、例えば、1.1バージョン以前は、Mixerアダプターごとに新しいCRDを定義する必要がありました。
- 設定の分離、ACL(Access Control List)、一貫性、抽象化、シリアル化の性能はまだ満足できるものではありません。
Istioのさらなる進化に伴い、IstioのCRDの数は増え続けていくでしょう。コミュニティでは、Galleyを強化して、Istioのコンフィグレーション・コントロール・レイヤーにすることを計画しています。Galleyは設定の検証だけでなく、入力、変換、配布、そしてIstioのコントロールプレーンに適したMCP(Mesh Config Protocol)などの設定管理パイプラインを提供する予定です。
Citadelとは
では、Istioのセキュリティ面であるCitadelについて説明します。サービスをマイクロサービスに分割することは、さまざまなメリットをもたらす一方で、より多くのセキュリティ要件を課すことになります。なにしろ、異なる機能モジュール間のメソッドコールが、マイクロサービス間のリモートコールに変わったのですから。
- 暗号化:情報漏洩を防ぎ、中間者攻撃から保護するために、サービス間の通信を暗号化する必要があります。
- アクセス制御:すべてのサービスにアクセスできるわけではありません。そのため、双方向のTLS(Transport Layer Security)やきめ細かなアクセスポリシーなど、柔軟なアクセス制御が必要です。
- 監査:システムにおけるユーザーの操作を監査するための監査機能が必要です。
Citadelは、Istioのセキュリティコンポーネントです。しかし、Citadelは他の複数のコンポーネントと連携する必要があります。
- Citadelは、鍵や証明書を管理し、Envoyなどの通信や転送を担当するコンポーネントにそれらを提供します。
- EnvoyはCitadelから配信された鍵と証明書を使って、サービス間通信のセキュリティを確保する。アプリケーションと Envoy の間では Localhost を使用するため、暗号化は必要ありません。
- Pilot は認可ポリシーとセキュアなネーミング情報を Envoy に送信します。
- Mixer は認証を管理し、監査を行います。
Istioは、以下のセキュリティ機能をサポートしています:
- トラフィックの暗号化:Istioは、サービス間の通信トラフィックを暗号化します。
- ID認証:Istioは、送信認証や送信元認証などのIDおよびクレデンシャル管理を内蔵しており、サービス間およびエンドユーザーの強力なID認証機能を提供します。また、双方向のTLSにも対応しています。
- 権限付与と認証:Istioは、ロールベースのアクセスコントロール(RBAC)に加えて、ネームスペース、サービス、メソッドレベルでのアクセスコントロールを提供します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ