このブログでは、新しい機械学習インターフェースやFlink-Pythonモジュールなど、Apache Flink 1.9.0について詳しく見ていきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
最も人気のあるプログラミング言語
下の画像はRedMonkプログラミング言語ランキングです。

上の画像のランキングトップ10は、GitHubやStack Overflowでの人気度に基づいています。
- JavaScript
- Java
- Python
- PHP
- C++
- C#
- CSS
- Ruby
- C
- TypeScript
3位にはPythonがランクインしています。他の人気プログラミング言語であるRとGoはそれぞれ15位と16位にランクインしています。この権威あるランキングは、Pythonのファン層の広さを十分に証明しています。プロジェクトにPythonのサポートを含めることは、そのプロジェクトのオーディエンスを拡大するための効果的な方法です。
インターネット業界のトレンド分野
ビッグデータコンピューティングは、現在のインターネット業界で最も注目されている分野の一つです。スタンドアロンコンピューティングの時代は終わった。スタンドアロンの処理能力は、データの成長に大きく後れを取っている。ビッグデータコンピューティングがインターネット業界で最も重要な分野の一つである理由を見てみましょう。
ビッグデータ時代の増え続けるデータ
クラウドコンピューティング、IoT、人工知能などの急速なITの発展により、データ量は大幅に増加しています。下の画像は、世界のデータ総量がわずか10年で16.1ZBから163ZBに増加すると予測されており、スタンドアロンのサーバーではもはやデータの保存と処理の要件を満たすことができないほどの大幅な増加となっています。
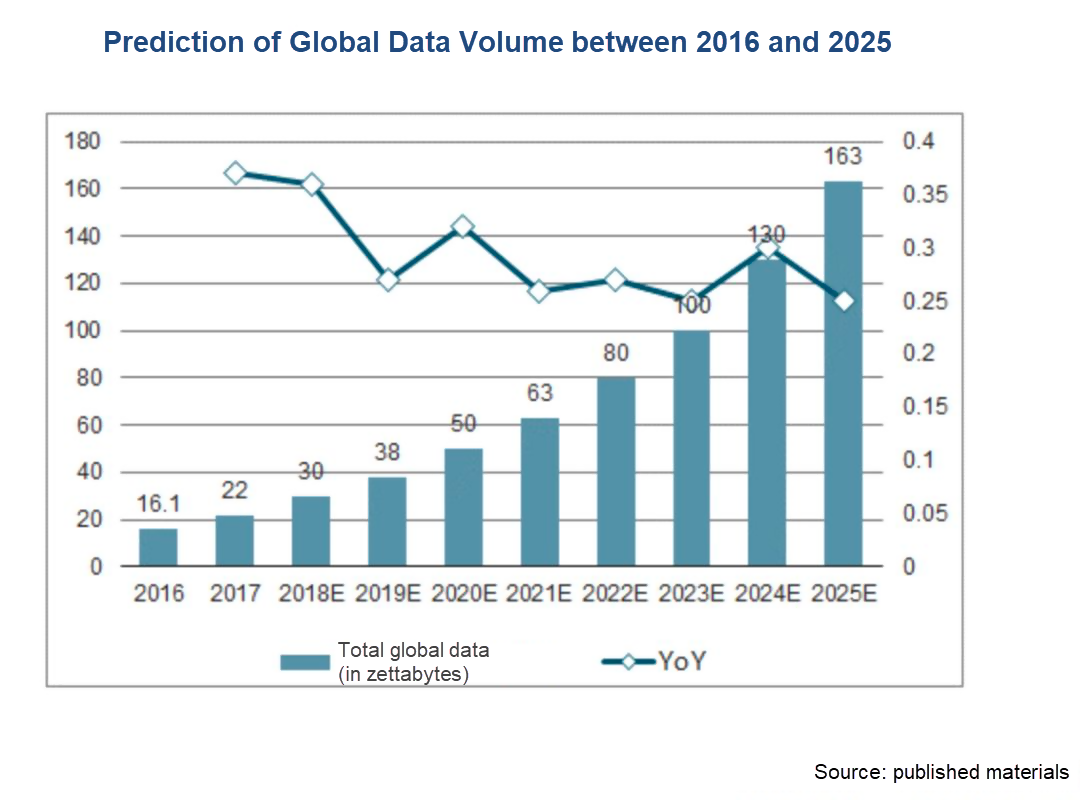
前の図のデータをZBとします。ここでは、データの統計的な単位を昇順に簡単に触れておきたいと思います。Bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DBです。これらの単位は以下のように変換されます。
- 1 Byte =8 bit
- 1 KB = 1,024 Bytes
- 1 MB = 1,024 KB
- 1 GB = 1,024 MB
- 1 TB = 1,024 GB
- 1 PB = 1,024 TB
- 1 EB = 1,024 PB
- 1 ZB = 1,024 EB
- 1 YB = 1,024 ZB
- 1 BB=1,024 YB
- 1NB = 1,024 BB
- 1 DB = 1,024 NB
世界的なデータの大きさに疑問を持ち、原因を掘り下げていくのは当たり前のことです。実際、私も統計を見て疑っていました。情報を集めて調べてみると、確かにグローバルデータは急激に増えていることがわかりました。例えば、Facebookには毎日何百万枚もの写真が投稿されていますし、ニューヨーク取引所では毎日TBもの取引データが作成されています。昨年のダブル11プロモイベントでは、取引額が2,135億元という記録的な規模となりましたが、この成功の裏には、アリババ社内の監視ログだけでも162GB/sのデータ処理能力があります。アリババのようなインターネット企業も、過去10年間のダブル11の取引額が示すように、データの急速な成長に貢献しています。

データ分析によるデータの価値
ビッグデータの価値を探るには間違いなく、ビッグデータの統計分析は、情報に基づいた意思決定を行うのに役立ちます。例えば、レコメンドシステムでは、購入者の長期的な購買習慣や購入履歴を分析して、その購入者の好みのアイテムを見つけ出し、さらに適切なレコメンドを提供することができます。前述したように、スタンドアロンのサーバーではこのような大量のデータを処理することはできません。では、限られた期間内に、どのようにしてすべてのデータを統計的に分析することができるのでしょうか?この点では、これら3つの有用な論文を提供してくれたGoogleに感謝する必要があります。
- GFS: 2003年にGoogleは、大規模な分散データ集約型アプリケーションのためのスケーラブルな分散fileシステムであるGoogle File Systemに関する論文を発表した。
- MapReduce:2004年、Googleはビッグデータのための分散コンピューティングについて述べたMapReduceの論文を発表した。MapReduceの主な考え方は、独立してあまり高いデータ処理能力を持たない複数のコンピューティングノード上で、タスクを分割し、分割されたタスクを同時に処理することです。MapReduceは、クラスタ上の並列分散アルゴリズムでビッグデータセットを処理し、生成するためのプログラミングモデルである。
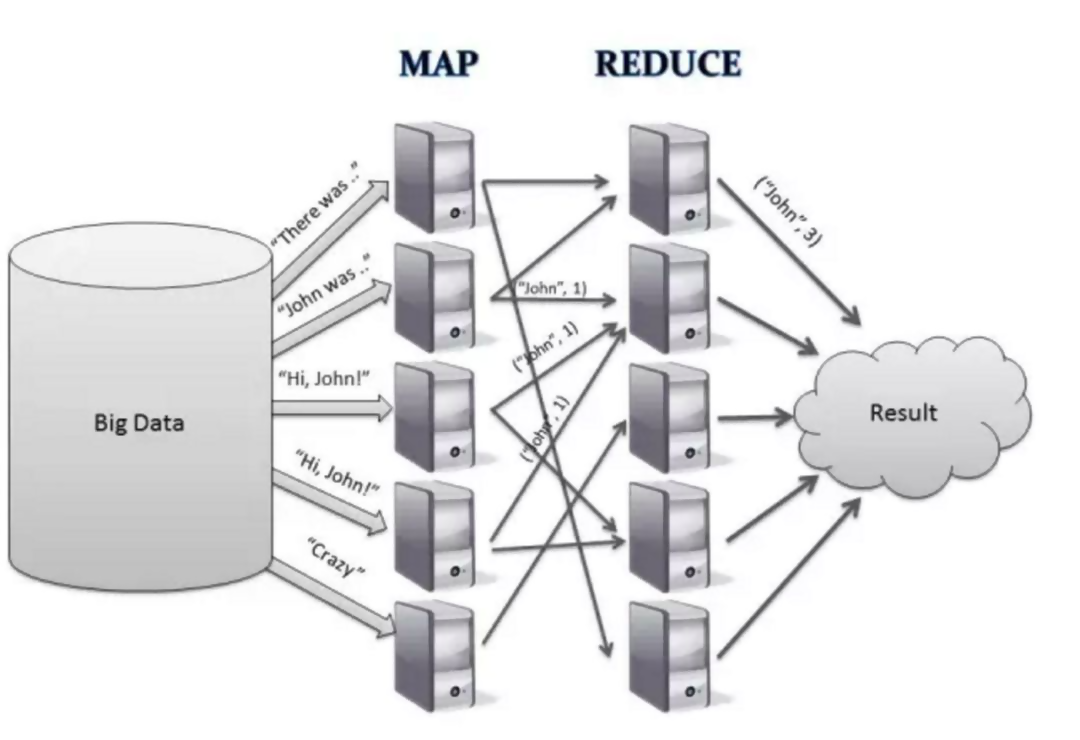
-
BigTable:2006年、GoogleはBigTableに関する論文を発表しました。
この3つのGoogleの論文のおかげで、オープンソースのApacheコミュニティは、HDFS、MapReduce(プログラミングモデル)、HBase(NoSQLデータベース)の3つのHadoopエコシステムを急速に構築しました。Hadoopエコシステムは、世界の学術界や産業界の注目を集め、瞬く間に人気を博し、世界中で応用されるようになりました。2008年、アリババはHadoopベースのYARNプロジェクトを立ち上げ、Hadoopをアリババの分散コンピューティングの中核技術システムとした。このプロジェクトでは、2010年には1000台のマシンのクラスターが稼働していました。下の写真は、アリババのHadoopクラスタの開発状況を示しています。

しかし、Hadoopを利用してMapReduceアプリケーションを開発するには、開発者はJava言語に習熟し、MapReduceの仕組みをよく理解している必要があります。これにより、MapReduce開発の敷居が高くなります。MapReduceの開発を容易にするために、代表的なHiveプロジェクトを含め、いくつかのオープンソースのフレームワークがオープンソースコミュニティで作成されています。HSQLを使用すると、SQLに似た方法でMapReduceの計算を定義して記述することができます。例えば、かつては数十行、数百行のコードが必要だったWord Countの演算が、今ではSQL文1つで実装できるようになり、開発にMapReduceを使う敷居が大幅に下がりました。Hadoopのエコシステムが成熟するにつれ、ビッグデータ向けのHadoopベースの分散コンピューティングは業界全体に普及していきます。
データの最大値と適時性
各データエントリには、特定の情報が含まれています。情報の適時性は、情報源から情報を送信してから、情報を受信し、処理し、転送し、利用するまでの時間間隔と情報効率で測定されます。時間間隔が短いほど、情報の適時性が高く、一般的にタイムリー性が高いほど価値が高くなります。例えば、嗜好推薦のシナリオでは、購入者が蒸し器を購入してから数秒後にオーブンの特価品が購入者に推薦された場合、購入者がオーブンも購入する可能性が高く、蒸し器の購入行動の分析に基づいて、1日後にオーブンのお勧めが表示された場合は、購入者がオーブンを購入する可能性は低いのです。これは、Hadoopのバッチ計算のデメリットの1つであるタイムリー性の低さを露呈しています。ビッグデータ時代の要件を満たすために、いくつかの代表的なリアルタイムコンピューティングプラットフォームが開発されました。2009年、カリフォルニア大学バークレー校のAMPラボでSparkが誕生。2010年には、NathanがStormのコアコンセプトであるBackTypeを提案し、また、2010年にはドイツのベルリンで調査プロジェクトとしてFlinkを立ち上げました。
AlphaGoとAI
2016年に行われた囲碁の対局では、GoogleのAlphaGoが九段目の棋士で世界囲碁選手権の優勝者でもあるイ・セドル(4:1)を破りました。これにより、より多くの人がディープラーニングを新たな視点から見るようになり、AIの流行を挑発しました。百度百科事典に与えられた定義によると、人工知能(AI)は、人間の知能を刺激し、拡張し、拡張する理論、方法、技術、応用、システムを研究開発するコンピュータ科学の新しい枝である。
機械学習は、人工知能を探求するための手法やツールです。SparkやFlinkに代表されるビッグデータプラットフォームでは、機械学習の優先度が高く、Sparkは近年、機械学習に莫大な投資を行っています。PySparkは多くの優れたMLクラスライブラリ(例えば代表的なPandas)を統合しており、Flinkよりもはるかに包括的なサポートを提供しています。そのため、Flink 1.9では、その欠点を補うために、新しいMLインターフェースやflink-pythonモジュールの開発が可能になります。
機械学習とPythonの関係は?また、機械学習で最もポピュラーな言語は何なのか、統計データを見てみましょう。
IBMのデータサイエンティストであるJean-Francois Puget氏は、かつて興味深い分析を行ったことがある。彼は有名な就活サイトから求人条件の変化に関する情報を集め、当時最も人気のあるプログラミング言語を探し出しました。機械学習を検索することで、彼も同様の結論に達しました。

そして、当時、機械学習のプログラミング言語として最も普及していたのはPythonであることがわかったそうです。この調査は2016年に行われたものですが、Pythonが機械学習において重要な役割を果たしていることを証明するには十分なものであり、前述のRedMonkの統計データからもそれをさらに示すことができます。
調査だけでなく、Pythonの特徴や既存のPythonエコシステムからも、Pythonが機械学習に最適な言語である理由が見えてきます。
Pythonは、1989年にオランダのプログラマーであるGuido van Rossumによって作成され、1991年に初めてリリースされたインタープリタ型・オブジェクト指向のプログラミング言語です。インタプリタ型言語は動作が非常に遅いですが、Pythonの設計思想は「唯一の方法」です。新しいPythonの構文を開発し、多くの選択肢がある場合、Pythonの開発者は通常、曖昧さがない、あるいはほとんどない明確な構文を選択します。そのシンプルさから、Pythonは多くのユーザーを抱えています。また、NumPy、SciPy、Pandas(構造化データを処理するための)など、多くの機械学習クラスライブラリがPythonで開発されています。Pythonの豊富なエコシステムが機械学習に大きな利便性を提供しているため、Pythonが機械学習用のプログラミング言語として最も人気のある言語になったのは当然のことです。
概要
今回の記事では、Apache FlinkがPython APIのサポートを追加した理由を理解することを試みました。具体的な統計を見ると、ビッグデータの時代に突入していることがわかります。データの価値を探るには、ビッグデータ分析が必要です。データの適時性は、有名なストリームコンピューティングプラットフォームであるApache Flinkを生み出しました。
ビッグデータコンピューティングの時代、AIは熱い開発トレンドであり、機械学習はAIの重要な側面の一つです。Python言語の特徴とエコシステムの利点から、Pythonは機械学習に最適な言語です。これが、Apache FlinkがPython APIのサポートを計画している重要な理由の一つです。Apache FlinkがPython APIをサポートすることは、ビッグデータ時代の要件を満たすためには避けて通れないトレンドです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ