Alibaba CloudのシニアオフィサーであるDaonongが、Kubernetesの基本的なネットワークモデルの起源、進化、メリット、デメリットについて概要を説明します。
著者:アリババクラウドのシニアテクニカルエキスパートDaonong氏
この記事では、Kubernetesの基本的なネットワークモデルについて説明します。この記事は以下の部分に分かれています。(1) コンテナネットワーク開発の歴史を振り返り、Kubernetesのネットワークモデルの起源を分析、(2) Flannel HostGWの実装を探り、コンテナからホストにルーティングされる際にパケットがどのように変換されるかを示し、(3) ネットワークと密接に関係するサービスの仕組みや使い方を紹介し、簡単な例を挙げてサービスの仕組みを説明します。
Kubernetesネットワークモデルの進化
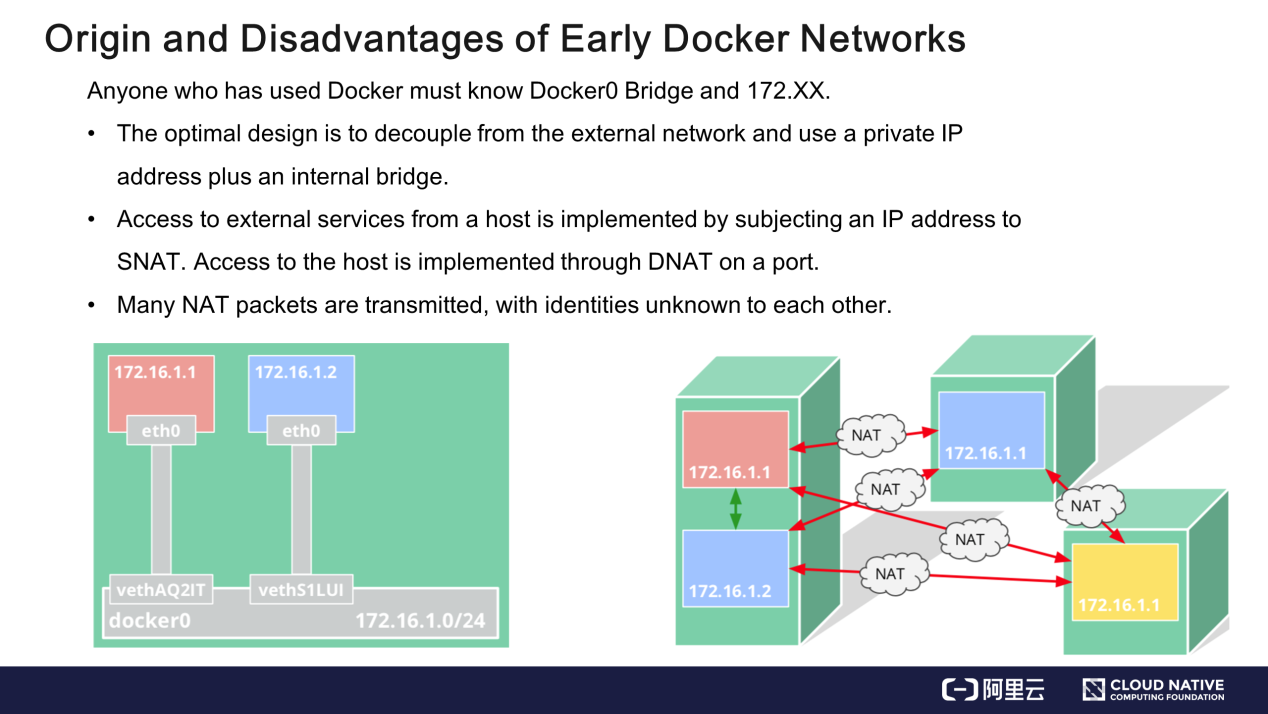
コンテナネットワークは、Dockerのネットワークが起源です。Dockerでは、内部ブリッジと内部で予約されたIPアドレスからなる比較的シンプルなネットワークモデルを採用しています。この設計では、コンテナネットワークは仮想化され、外部ネットワークから切り離されているため、ホストのIPアドレスやリソースを占有することはありません。コンテナネットワークは、ノードのIPアドレスにSNAT(Source Network Address Translation)を適用することで、外部のサービスにアクセスすることができます。コンテナは,宛先ネットワークアドレス変換(DNAT)によって外部にサービスを提供することができます。具体的には、ノード上でポートを有効にし、iptable などを介してコンテナのプロセスにトラフィックを誘導します。
このモデルでは、外部ネットワークは、コンテナネットワークとそのトラフィックを、ホストネットワークとそのトラフィックから区別することができません。例えば、172.16.1.1と172.16.1.2というIPアドレスを持つ2つのコンテナ間で高可用性を実現するためには、それらのコンテナをグループに割り当てて外部にサービスを提供する必要があります。しかし、2つのコンテナは外部からは同じものに見え、IPアドレスはホストポートに由来するため、この操作は困難です。
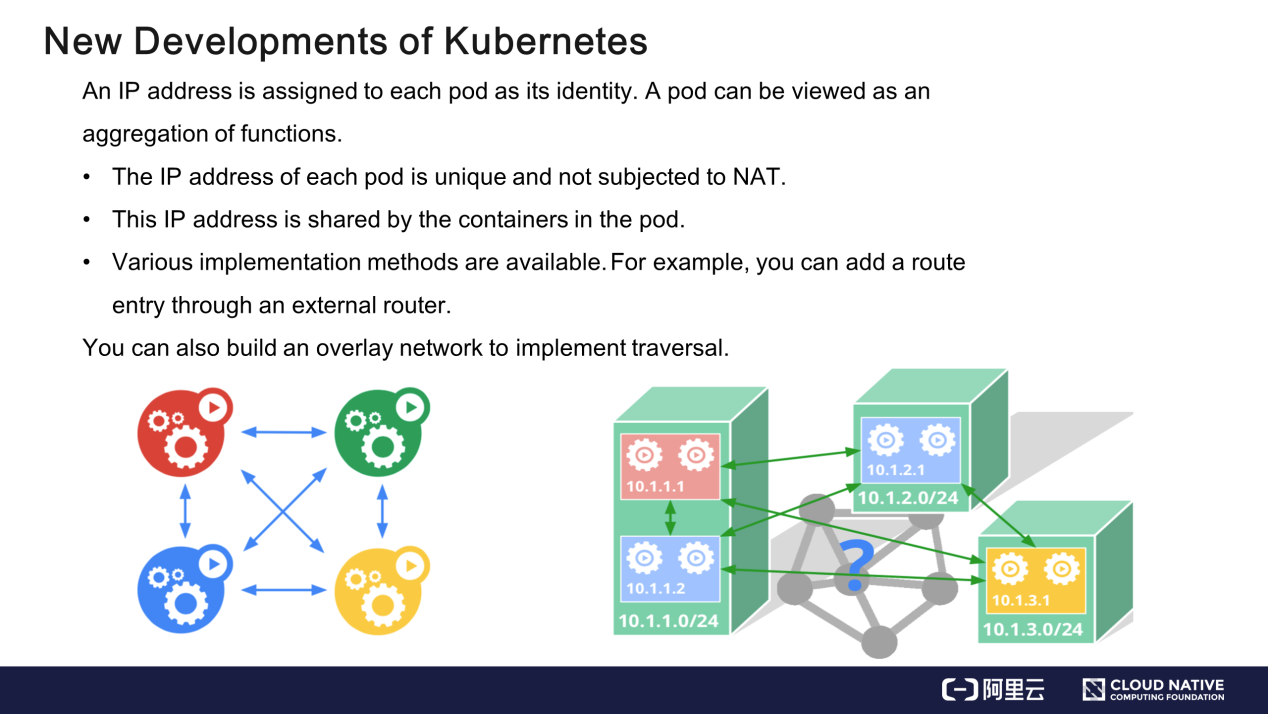
この問題を解決するために、Kubernetesでは機能の集合体である各PodにID(アイデンティティ)を割り当てています。このIDは、TCP(Transmission Control Protocol)スタックのIPアドレスです。
各Podは特定のIPアドレスを持ちます。このIPアドレスがどのように導かれるかは、外部ネットワークには関係ありません。このPodのIPアドレスへのアクセスは、Podのサービスへのアクセスと同等です。アクセス処理中にIPアドレスが変換されることはありません。たとえば、送信元IPアドレス10.1.1.1のアクセス要求が、送信元IPアドレスではなくホストIPアドレスであるIPアドレス10.1.2.1のPodに送信されたとします。これは許可されていません。PodはIPアドレス10.1.2.1を内部で共有し、機能集約を行ったコンテナをアトミックモードでデプロイできるようにしています。
コンテナをどのようにデプロイするのでしょうか? Kubernetesはモデルの実装に制限を設けていません。アンダーレイネットワークを介して外部ルータを制御することでトラフィックを誘導することができます。デカップリングを実装するには、オーバーレイネットワークを利用して、アンダーレイネットワークの上にネットワークを重ねることができます。目標は、モデルの要件を満たすことです。
Podはどのようにしてオンラインになるのか?
コンテナネットワークでは、パケットはどのように伝送されるのでしょうか?
この疑問は、次の2つの側面を考慮することで解決できます。
- プロトコル
- ネットワークトポロジー
第1の側面はプロトコルです。
プロトコルの概念は、TCPスタックの概念と同じで、下から順にレイヤ2、レイヤ3、レイヤ4で構成されています。パケットは右から左に向かって送信されます。アプリケーションデータはパケットにカプセル化され、TCPまたはUDP(User Datagram Protocol)のレイヤー4に送られた後、下位のレイヤーに送られます。パケットにはIPヘッダーとMACヘッダーが付加されてから送信されます。パケットは送信時とは逆の順序で受信されます。MAC ヘッダーと IP ヘッダーは、順番にパケットから取り除かれます。Rxポートは、プロトコルIDに基づいて、パケットを受信する必要のあるプロセスを探します。
2つ目の側面は、ネットワークトポロジーです。
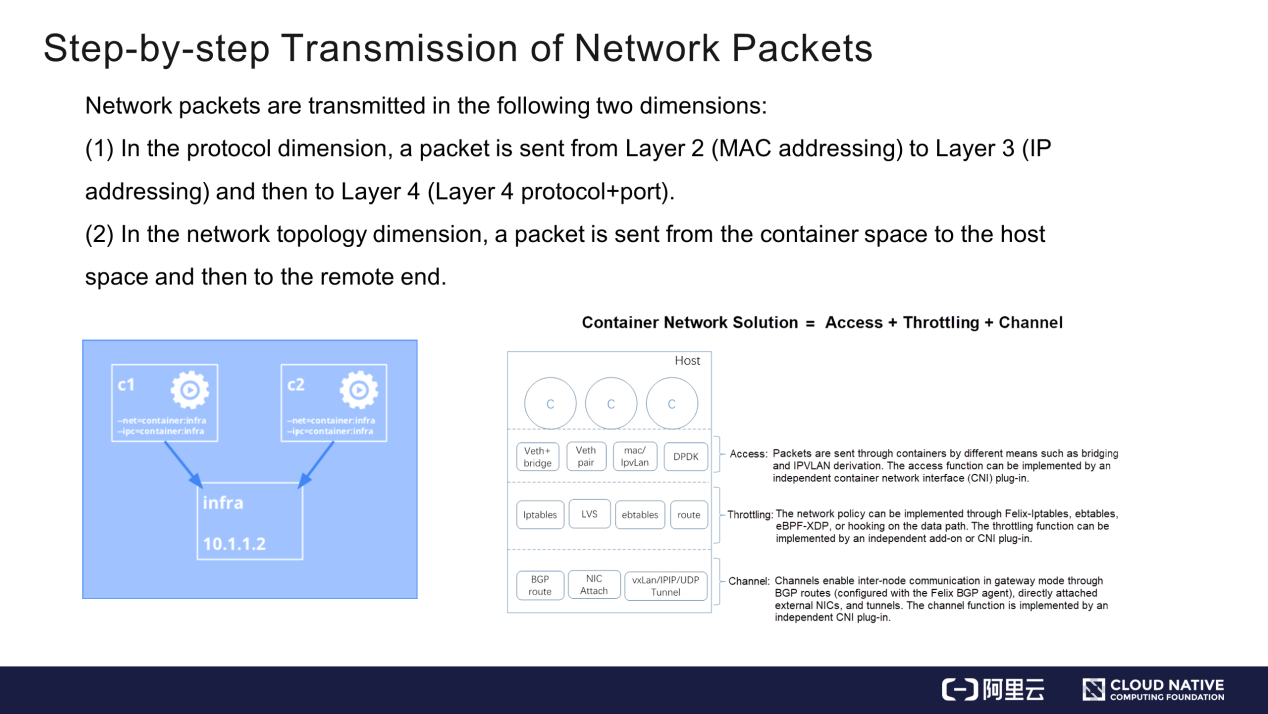
コンテナは2つのステップでパケットを送信します。(1) コンテナ空間(c1)からホスト空間(infra)にパケットを送信し、(2) ホスト空間からリモートエンドにパケットを転送します。
私の考えでは、コンテナネットワークは、パケット送信プロセスを3つの部分で実装しています。
- 最初の部分はアクセスで、コンテナがVeth+bridge、Veth+pair、MACVLAN、またはIPVLANを介してホストに接続し、パケットをホスト空間に送信します。Veth+bridgeとVeth+pairは古典的な接続モードですが、MACVLANとIPVLANは高度なカーネルバージョンでサポートされています。
- 2つ目はスロットリングです。パケット送信を制御するためのネットワークポリシーを実装するかどうかと、このポリシーをどのように実装するかを決定します。ネットワークポリシーは、データパスの主要なノードに実装する必要があります。フックがデータパスの外にある場合は、ネットワークポリシーは有効になりません。
- 3つ目はチャネル設定で、2つのホスト間でパケットを送信する方法を指定します。パケットはルーティングによって伝送されますが、ルーティングはBGP(Border Gateway Protocol)ルーティングとダイレクトルーティングに分けられます。パケットはルーティングによって伝送することができます。コンテナから相手側にパケットを送信するプロセスは、以下のようにまとめられます。(1) パケットがコンテナを離れ、アクセス層を経由してホストに到達。(2) パケットがホストのスロットリングモジュール(ある場合)とチャネルを通過してピアエンドに到達。
Flannel HostGW:ルーティングソリューション
Flannel HostGWでは、各ノードが排他的なCIDRブロックを占有し、各サブネットがノードにバインドされ、ゲートウェイがローカルまたはcni0ブリッジの内部ポートに設定されます。Flannel HostGWは管理が容易ですが、ノード間のPodマイグレーションには対応していません。IPアドレスやCIDRブロックがすでにノードに占有されている場合、他のノードに移行することはできません。
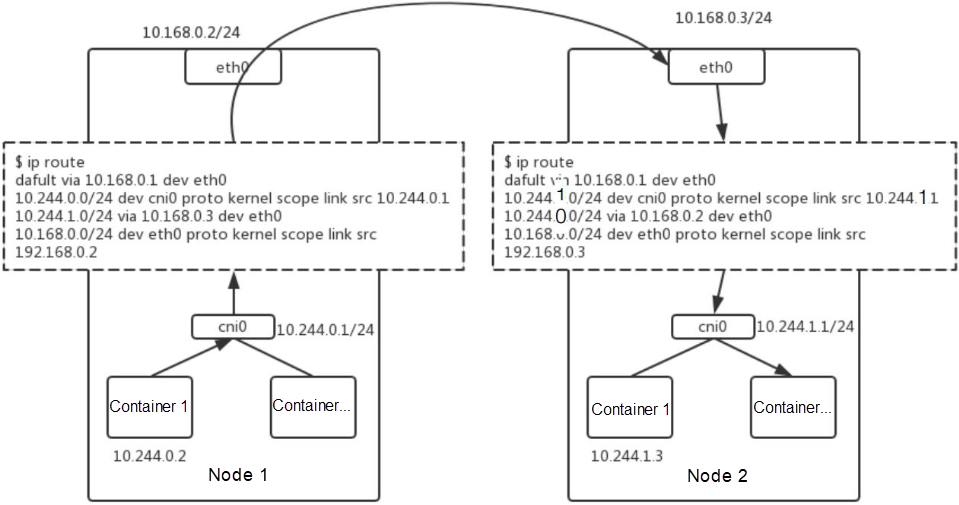
前述の図は、Flannel HostGWのルートテーブル設定を示したもので、以下のように説明されています。
- 最初のエントリーはシンプルで、NIC(Network Interface Controller)の設定に必要なものです。デフォルトルートのソースIPアドレスとデフォルトデバイスを指定します。
- 2 番目のエントリーでは、サブネットのルールフィードバックを指定します。例えば、CIDRブロック「10.244.0.0」は24ビットのマスクを持ち、ゲートウェイアドレス「10.244.0.1」がブリッジに配置されているとします。このCIDRブロックの各パケットは、ブリッジのIPアドレスに送信されます。
- 3番目のエントリーでは、ピアエンドへのフィードバックを指定します。たとえば、前出の図の左のサブネットは、CIDRブロック10.244.1.0に対応しています。ホストのNICのIPアドレス(10.168.0.3)は、ゲートウェイIPアドレスとして使用できます。10.244.1.0のCIDRブロック宛のパケットは、10.168.0.3のゲートウェイを経由して転送されます。
パケットの送信方法について説明します。
例えば、IPアドレスが10.244.0.2のコンテナが、10.244.1.3にパケットを送信したいとします。そのために、コンテナはローカルでTCPまたはUDPパケットを作成し、相手のIPアドレス、送信元のMACアドレス(ローカルイーサネットのMACアドレス)、および相手のMACアドレスを指定します。デフォルトルートはローカルに設定され、cni0のIPアドレスをデフォルトゲートウェイアドレスとして使用します。相手のMACアドレスはこのゲートウェイのMACアドレスです。このようにして、パケットをブリッジに送ることができます。CIDRブロックがブリッジ上にある場合、パケットはMAC層で変換されます。
この例のIPアドレスはローカルCIDRブロックに属していないので、ブリッジはパケットをホストのプロトコルスタックに送って処理します。プロトコルスタックは、相手のMACアドレスを識別し、10.168.0.3をゲートウェイとして使用します。MACアドレス10.168.0.3はARP(Address Resolution Protocol)のスヌーピングによって得られます。このパケットは、プロトコルスタックの各層でカプセル化された後、ローカルホストのeth0インターフェースから、ピアホストのeth0インターフェースに送信されます。相手ホストのNICのMACアドレスは、図の右に示すDst-MACとして指定されています。
暗黙の制限があります。指定されたMACアドレス(Dst-MAC)は、相手側で到達可能でなければなりません。ただし、2つのホストがレイヤ2で接続されていない場合や、2つのホスト間にゲートウェイや複雑な経路が存在する場合は、到達不可能となります。このような場合、Flannel HostGWは適用できません。パケットが対向MACアドレスに到達すると、対向ホストは、パケットの宛先MACアドレスが対向MACアドレスと同じだが、パケットの宛先IPアドレスが対向IPアドレスではないことを発見します。そして、ピアホストはパケットをプロトコルスタックに転送し、パケットは再びルーティングされます。10.244.1.0/24宛のパケットは、10.244.1.1ゲートウェイに送られなければならないので、cni0ブリッジに到達します。対向ホストは、10.244.1.3にマッピングされたMACアドレスを見つけ、ブリッジを介してそのコンテナにパケットを送信します。
このように、パケットの送信処理は、レイヤー2とレイヤー3で行われます。パケットはレイヤ2から送信されてからルーティングされます。送信処理は単純です。パケットがVXLANトンネルを介してルーティングされている場合は、ダイレクトルートをピアのトンネル番号に置き換えます。
Kubernetesのサービスの仕組み
Kubernetesのサービスでは、クライアント側でロードバランシングを実装しています。
仮想IPアドレス(VIP)から実在のサーバーIPアドレス(RIP)への変換は、NGINXやELB(Elastic Load Balancer)が判断することなく、クライアント側で行われます。
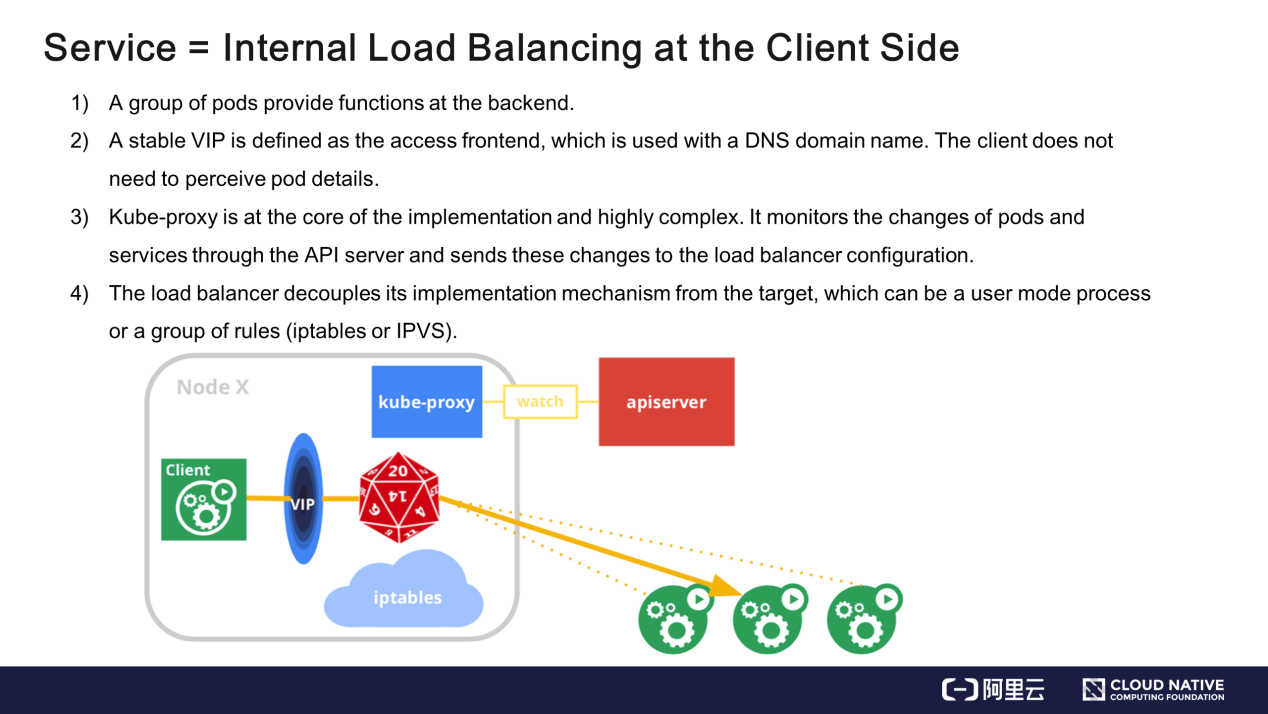
実装:バックエンドではPod群が機能を提供し、フロントエンドでは仮想IPがアクセスポータルとして定義されます。仮想IPアドレスは、DNSのドメイン名にマッピングされます。このドメイン名でアクセスすると、クライアントは仮想IPアドレスを取得し、実在のIPアドレスに変換します。サービスやPodの追加など、APIサーバーを通じてPodやサービスの変更を監視し、その変更をローカルルールやユーザーモードのプロセスに送信するKubernetesのネットワークプロキシ(kube-proxy)は、実装の中核であり、非常に複雑です。
LVSサービス
ここでは、Linux Virtual Server(LVS)のサービスを開発する方法を説明します。LVSは、ロードバランシングのためのカーネルメカニズムを提供します。LVSはレイヤー4で動作し、iptableよりも優れたパフォーマンスを発揮します。
例えば、kube-proxyは、次の図のように、あるサービスの設定を取得します。このサービスは、クラスターのIPアドレスが9376番ポートにマッピングされており、コンテナの80番ポートにフィードバックを送ります。機能的には3つのPodが存在し、IPアドレスは10.1.2.3、10.1.14.5、10.1.3.8となっています。
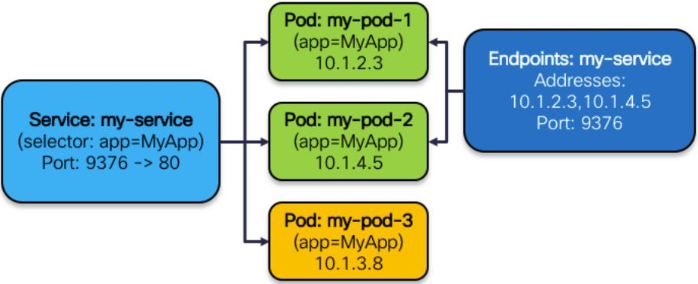
このサービスでは、以下のステップを実行します。

-
ステップ1: VIPをローカルにバインドします(カーネルを欺くため)。
LVSはレイヤ4で動作し、IP転送には関係しないため、サービスはカーネルにVIPを持っていることを伝えます。サービスは、VIPが自分のものであると信じている場合にのみ、TCPまたはUDPレイヤにトラフィックを転送します。ステップ1では、サービスがVIPを持っていることを示すために、サービスはVIPをカーネルに設定します。カーネルにVIPを設定するには、「ip route」に「local」を追加するか、ダミーのデバイスを介してVIPを追加します。 -
ステップ2: VIP用のIPバーチャルサーバー(IPVS)を作成します。
このステップでは、VIPに対してロードバランシングを実装する必要があることを示します。配信ポリシーには以下のパラメータが含まれます。IPVSのIPアドレスは、クラスタのIPアドレスです。 -
ステップ3:IPVS用のリアルサーバーを作成します。
このリアルサーバーがサービスプロビジョニングのバックエンドとなります。例えば、前図の3つのPodのIPアドレスをIPVSに設定することで、PodとIPアドレスを1対1で対応させることができます。 kube-proxyも同様に動作しますが、kube-proxyはPodの変更も監視します。例えば、podの数が5つになると、ルールの数も5つになります。Podが死んだり、キルされたりすると、ルールの数が1つ減り、また、サービスがリボークされると、すべてのルールが削除されます。以上が「kube-proxy」の管理作業です。
内部ロードバランサーと外部ロードバランサー
サービスは以下の4種類に分けられます。
クラスターIP
クラスタには、多くのサービスのグループPodにバインドされた内部VIPがあります。ClusterIP はデフォルトのサービスタイプです。このタイプのサービスは、ノードまたはクラスター内でのみ使用できます。
NodePort
NodePortタイプのサービスは、クラスターによる外部呼び出しのみを目的としています。これらのサービスは、サービスとポート番号を1対1でマッピングして、ノードのスタティックポートに展開できます。これにより、クラスター外部のユーザーは、<NodeIP>:<NodePort>を指定してサービスを呼び出すことができます。
LoadBalancer
LoadBalancerは、クラウドベンダー向けの拡張インターフェースです。Alibaba CloudやAmazonのようなクラウドベンダーは、成熟したロードバランシングメカニズムを持っており、大規模なクラスタによって実装されている場合があります。クラウドベンダーは、LoadBalancerインターフェイスを通じてこれらのメカニズムを拡張することができます。LoadBalancerインターフェースでは、NodePortとClusterIPが自動的に作成され、クラウドベンダーはこれらにLoadBalancerを直接取り付けることができます。また、クラウドベンダーはPodのRIPをELBのバックエンドにアタッチすることもできます。
ExternalName
このサービスタイプは、内部のメカニズムではなく、外部のデバイスに依存します。例えば、各サービスをドメイン名にマッピングすることで、ロードバランシングを外部から実装することができます。
以下はその例です。前述の図は、ClusterIPやNodePortなどの複数のタイプのサービスと、クラウドベンダーのELBを組み合わせた、柔軟でスケーラブルな本番対応のシステムです。
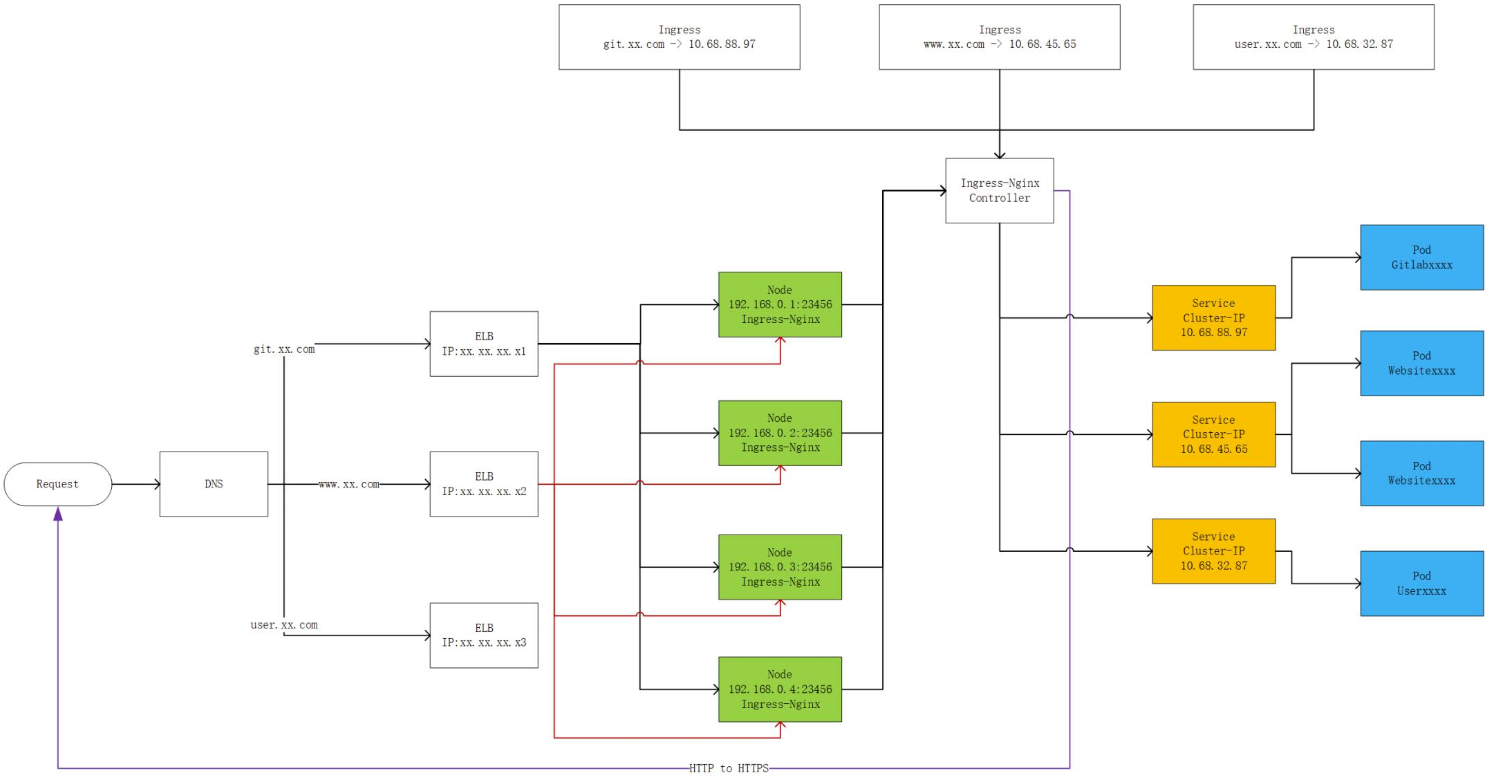
ClusterIPは、機能的なPodのサービスポータルの実装に使用されます。3種類のPodが存在する場合は、3つのサービスクラスターIPアドレスがこれらのPodのサービスポータルとして使用されます。サービスポータルはクライアント側で実装され、制御はサーバー側で以下のように実装されます。
IngressPodは,NodePortサービスのIPアドレスに対して,起動, 整理,公開されます。Ingressは、Kubernetesの新しいタイプのサービスです。IngressPodは基本的に同種のPodの集まりです。これにより、Kubernetesのタスクが完了します。
ポート23456を持つPodを宛先とするアクセスリクエストは、ingressサービスにルーティングされます。ingressサービスの背後には、サービスのIPアドレスとingressバックエンドを管理するコントローラがあります。その後、リクエストはClusterIPサービスに転送され、さらに機能的なPodに転送されます。クラウドベンダーのELBに接続する場合は、各クラスタノードのポート23456をリッスンするようにELBを設定することができます。ポート23456に存在するサービスは、実行状態のingressインスタンスとみなされます。
トラフィックは、外部のドメイン名に基づいて解析され、ELBに誘導されます。ELBはロードバランシングを実装し、NodePortモードでトラフィックをingressにルーティングします。最後に、イングレスはClusterIPモードでバックエンドの適切なPodにトラフィックをルーティングします。このシステムは、機能的に多様で堅牢です。システムの各リンクは単一障害点(SPOF)から解放され、管理とフィードバックを実装しています。
まとめ
今回の記事で学んだことをまとめてみましょう。
- この記事では、Kubernetesのネットワークモデルの進化と、PerPodPerIPの目的について説明しました。
- Kubernetesのネットワークモデルでは、上から順にレイヤー4からパケットが送信されます。パケットが相手側で受信されると、MACヘッダーとIPヘッダーがパケットから取り除かれます。このパケット送信プロセスは、コンテナネットワークにも適用できます。
- ingressメカニズムは、サービス-ポートマッピングを実装し、クラスターの外部サービスプロビジョニングを設定することができます。本稿では、実現可能な導入例を示すことで、ingress、クラスタIPアドレス、PodIPアドレスなどの概念を関連付け、Kubernetesコミュニティで導入された新しいメカニズムやオブジェクトリソースを理解できるようにしています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ