本記事では、アリババのオープンソースであるMarsで実装されている分散アーキテクチャを紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Marsがどのようなものかは以前の記事で紹介しましたが、社内システムでのテストを経てGitHub上でオープンソース化しています。本記事では、Marsで実装されている分散実行アーキテクチャを紹介します。
アーキテクチャの紹介
Marsはテンソルを分散実行するためのライブラリを提供します。このライブラリは、mars.actorsで実装されたアクターモデルを用いて書かれており、スケジューラ、ワーカー、ウェブサービスが含まれています。
クライアントからMars Web Serviceに提出されたグラフはテンソルで構成されています。ウェブサービスはグラフを受け取り、スケジューラに提出します。各ワーカーにジョブを投入する前に、Marsのスケジューラはテンソルグラフをチャンクとオペランドで構成されたグラフにコンパイルし、グラフを解析して分割します。次に、スケジューラは、一貫性のあるハッシュに基づいて、すべてのスケジューラで単一のオペランドの実行を制御する一連のOperandActorsを作成します。オペランドは、トポロジカルな順序でスケジューリングされます。すべてのオペランドが実行されると、図全体が完了としてマークされ、クライアントはWebから結果を引き出すことができます。全体の実行プロセスを下図に示します。
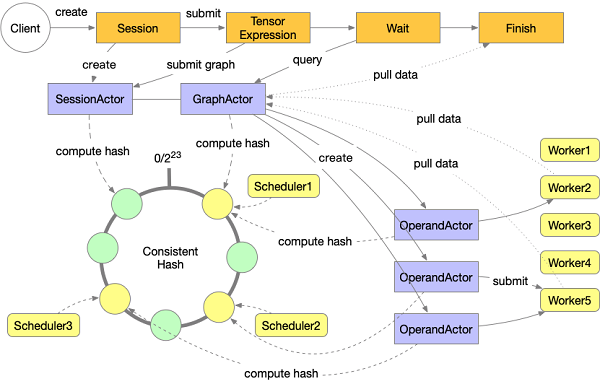
ジョブの送信
クライアントはRESTful APIを介してMarsサービスにジョブを送信します。クライアントはテンソルにコードを書き、session.run(tensor)を介してテンソル操作をテンソルで構成されたグラフに変換し、Web APIに送信します。その後、Web APIはジョブをSessionActorに送信し、クラスタ内にグラフ解析・管理用のGraphActorを作成します。クライアントは、実行が終了するまでの間、グラフの実行状態の問い合わせを開始します。
GraphActorでは、まずチャンクの設定に従ってテンソルグラフをオペランドとチャンクで構成されたグラフに変換します。この処理により、グラフをさらに分割して並列に実行することが可能となります。その後、グラフに対して一連の解析を行い、オペランドの優先度を求め、開始オペランドにワーカーを割り当てます。この部分については、「実行グラフを準備する」を参照してください。そして、各オペランドには、オペランドの具体的な実行を制御するためのOperandActorを作成します。オペランドがREADY状態(Operand stateの項で説明したように)になると、スケジューラはそのオペランドの対象ワーカーを選択し、実際の実行のためにそのワーカーにジョブを投入します。
実行の制御
オペランドがワーカーに送信されると、OperandActorはワーカーでのコールバックを待機します。オペランドが正常に実行されると、オペランドの後続がスケジュールされます。オペランドが実行に失敗した場合、OperandActorは数回試行します。失敗すると、実行は失敗としてマークされます。
ジョブをキャンセルする
クライアントはRESTful APIを使って実行中のジョブをキャンセルすることができます。キャンセル要求はグラフのステートストレージに書き込まれ、GraphActor上のキャンセルインターフェースが呼び出されます。ジョブが準備段階にある場合は、停止要求が検出された直後に終了し、そうでない場合は各オペランドアクタに要求が送信され、状態はCANCELLINGに設定されます。この時、オペランドが動作していない場合は、オペランドの状態は直接CANCELLEDに設定されます。オペランドが動作中であれば、ワーカーに停止要求が送られ、ExecutionInterruptedエラーが発生し、OperandActorに返されます。この時、オペランドの状態はCANCELLEDとしてマークされます。
実行グラフの準備
テンソルグラフをMarsスケジューラに投入すると、データソースに含まれるチャンクのパラメータに応じて、オペランドとチャンクで構成されるより細かいグラフが生成されます。
グラフの圧縮
チャンクグラフが生成された後、グラフ内の隣接ノードをフュージングすることで、グラフのサイズを縮小します。また、このフュージングにより、numexprのような高速化ライブラリをフルに活用して計算処理を高速化することができます。現在のところ、Marsは単一の連鎖を形成するオペランドのみをフュージングしています。例えば、以下のコードを実行した場合。
import mars.tensor as mt
a = mt.random.rand(100, chunks=100)
b = mt.random.rand(100, chunks=100)
c = (a + b).sum()
MarsはADDとSUMのオペランドをFUSEノードに融合させます。ランドのオペランドは、ADDとSUMで単純な直線を形成しないので、融合しません。
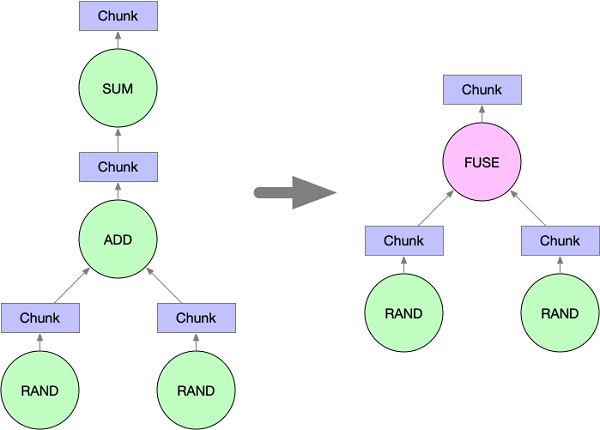
初期ワーカーの割り当て
グラフ実行のパフォーマンスを向上させるためには、オペランドにワーカーを割り当てることが重要です。初期のオペランドをランダムに割り当てると、ネットワークのオーバーヘッドが大きくなり、異なるワーカー間でジョブの割り当てが不均衡になる可能性があります。初期ノード以外のノードの割り当ては、その前駆体が生成するデータの物理的な分布や各ワーカーのアイドル状態に応じて容易に決定することができます。したがって、実行グラフの準備段階では、初期オペランドの割り当てのみを考慮します。
初期ワーカーの割り当てについては、いくつかの原則に従わなければなりません。まず、各ワーカーに割り当てられるオペランドは、可能な限りバランスをとる必要があります。これにより、計算クラスタは、実行フェーズ全体の間、より高い利用率を持つことができ、これは実行の最終フェーズで特に重要です。第2に、最初のノード割り当ては、後続のノードが実行されるときに最小限のネットワークトラフィックを必要とします。言い換えれば、初期ノード割り当ては、原則に完全に従うべきなのです。
上記の原則が互いに矛盾する場合があることに注意してください。ネットワークトラフィックが最小限の割り当てソリューションは非常に歪んでいる可能性があります。2つの目標のバランスをとるためのヒューリスティックアルゴリズムを開発しました。アルゴリズムは次のように説明されます。 :
1、最初の初期ノードとリストの最初のマシンが選択されます。
2、オペランドグラフから変換された無向グラフでは、そのノードから深さ優先探索を開始します。
3、オペランド・グラフから変換された無向グラフでは、そのノードから深さ優先探索を開始;別の未割り当ての初期ノードがアクセスされた場合は、ステップ1で選択されたマシンに割り当てます。
4、また、オペランドグラフを変換したグラフから深さ優先探索を開始します。
5、オペランドを割り当てられていないワーカーが残っている場合は、ステップ1に進みます。オペランドが割り当てられていないワーカーが残っている場合は、ステップ1に進みます。
スケジューリングポリシー
オペランドで構成されたグラフが実行される場合、適切な実行順序は、クラスタ内に一時的に保存されるデータ量を減らし、その結果、データがディスクにダンプされる可能性を減らすことができます。適切なワーカーは、実行中の総ネットワークトラフィックを減らすことができます。
オペランドの選択方針
適切な実行シーケンスは、クラスタ内に一時的に格納されるデータの総量を大幅に削減することができます。次の図は、ツリー削減の例を示しています。丸はオペランド、四角はチャンク、赤はオペランドが実行中、青はオペランドが実行可能、緑はオペランドによって生成されたチャンクが格納された、グレーはオペランドとその関連データが解放されたことを表しています。2人のワーカーがいて、それぞれのオペランドが同量のリソースを使用していると仮定して、異なるポリシーで5時間単位で実行した場合の状態を示したのが下の図です。左の図は階層に従って実行されていることを示し、右の図は深さ優先の順に実行されていることを示しています。左のグラフでは6つのチャンクのデータを一時的に保存する必要があり、右のグラフでは2つのチャンクのデータのみを保存する必要があります。
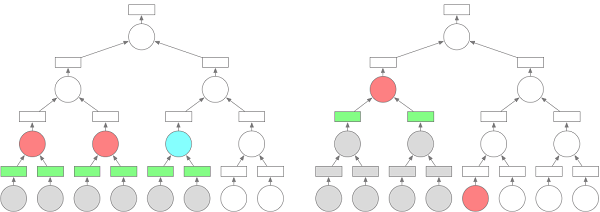
私たちの目標は、クラスタ内に保存されるデータの総量を減らすことなので、READY状態のオペランドに優先順位を設定しています。
1、深さの大きいオペランドを最初に実行する必要があります。
2、より深いオペランドに依存しているオペランドは、最初に実行される必要があります。
3、出力サイズが小さいノードを最初に実行する必要があります。
労働者の選定方針
スケジューラがグラフを実行する準備ができたら、最初のオペランドのワーカーが決定されています。入力データがあるワーカーに基づいて、後続のオペランドのワーカーを割り当てます。入力データのサイズが最も大きいワーカーがあれば、そのワーカーが後続のオペランドを実行するために選択されます。同じ入力データサイズのワーカーが複数存在する場合、各候補ワーカーのリソース状態が決定的な役割を果たします。
オペランドの状態
Marsの各演算子は、OperandActorによって個別にスケジューリングされています。実行処理は状態遷移の処理です。OperandActorでは、各状態に入る過程での状態遷移関数を定義しています。初期化時には初期オペランドはREADY状態、非初期オペランドはUNSCHEDULED状態となります。指定された条件が満たされると、オペランドは別の状態に遷移し、対応する操作が実行されます。状態遷移のプロセスを次の図に示します。
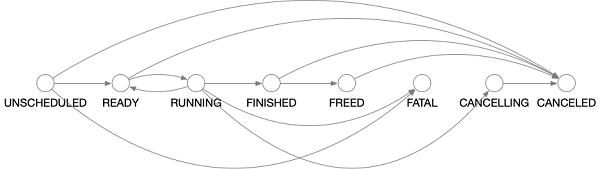
以下では、それぞれの状態の意味と、これらの状態でMarsが行うオペレーションについて説明します。
-
UNSCHEDULED:オペランドのアップストリームデータの準備ができていないときの状態です。
-
READY:オペランドは、そのオペランドのアップストリームデータの準備ができていない状態にあります。このような場合には、「プロパティー」を使用して、「プロパティー」の値を変更します。 スケジューラは、他のワーカーに停止メッセージを送信し、ワーカーにメッセージを送信してジョブの実行を開始します。
-
RUNNING:オペランドは、その実行が開始されたときに、この状態になります。この状態になると、OperandActorは、ジョブが投入されたかどうかをチェックします。この状態になると、OperandActorはジョブが投入されているかどうかをチェックします。その後、OperandActorはワーカーにコールバックを登録し、ジョブが完了したことを示すメッセージを取得します。
-
FINISHED:オペランドがこの状態になると、グラフ全体の実行が終了したかどうかを判断するためのメッセージが GraphActor に送信されます。オペランドがこの状態になり、後継者がいない場合、グラフ全体の実行が終了したかどうかを判断するためのメッセージが GraphActor に送信されます。同時に、OperandActorは、その前駆体と後継体に、実行が完了したことを示すメッセージを送信します。メッセージを受信した前駆体は、すべての後継者の実行が終了したかどうかを確認します。その場合、現在のオペランドのデータを解放することができます。後継者がメッセージを受信した場合、すべての前駆者が完了したかどうかをチェックします。もしそうであれば、後継者の状態をREADYに遷移させることができます。
-
FREED:オペランドは、すべてのデータが解放されたときに、この状態になります。
-
FATAL:オペランドは、そのデータがすべて解放されたときにこの状態にあります。オペランドは、すべての再実行の試みが失敗したときにこの状態になります。オペランドがこの状態になると、オペランドは同じ状態を後継ノードに渡します。
-
CANCELLING:オペランドがキャンセルされているとき、この状態になります。オペランドが実行中であれば、ワーカーに実行をキャンセルするためのリクエストを送信します。
-
CANCELLED: オペランドがキャンセルされているときの状態です。オペランドがキャンセルされ、実行が停止しているときの状態です。実行がこの状態に入ると、OperandActorはすべての後続の状態をCANCELLINGに移行しようとします。
ワーカーの内容
Marsワーカーは、実行時のGILの影響を軽減するために複数のプロセスを含んでいます。特定の実行は独立したプロセスで完結します。不要なメモリコピーやプロセス間の通信を減らすために、マースワーカーは共有メモリを使用して実行結果を保存します。
ワーカーにジョブが投入されると、まず、メモリの割り当てを待つキューに入れられます。メモリが割り当てられると、他のワーカー上のデータや、現在のワーカー上のディスクにダンプされているデータがメモリに再ロードされます。この時点で既に計算に必要なデータは全てメモリに入っており、実際の計算処理を開始する準備ができています。計算が完了すると、ワーカーはジョブを共有ストレージに入れます。4つの実行状態の遷移関係を下図に示します。

実行の制御
マーズワーカーは、ExecutionActorを通じてワーカー内のすべての演算子の実行を制御します。Actor自身は実際の操作やデータ転送には関与せず、他のActorにタスクを提出するだけです。
スケジューラのOperandActorは、ExecutionActorのenqueue_graph呼び出しを通してワーカーにジョブをサブミットします。ワーカーはオペランドの投入を受け入れ、キューにキャッシュします。このとき、ワーカーは、ワーカーのオペランドの投稿を受け入れ、キューにキャッシュします。スケジューラは、現在のワーカー上でオペランドの実行を決定すると、start_executionメソッドを呼び出し、add_finish_callbackを通してコールバックを登録します。この設計により、実行結果を複数の場所で受け取ることができるので、障害回復に役立ちます。
ExecutionActorは、複数のオペランドからの実行要求を同時に処理するために、mars.promiseモジュールを使用します。特定の実行ステップは、Promiseクラスの "then "メソッドを介してリンクされています。最終的な実行結果が格納されると、以前に登録されたコールバックがトリガーされます。前の実行ステップのいずれかでエラーが発生した場合、そのエラーはcatchメソッドで登録されたハンドラ関数に渡されて処理されます。
オペランドのソート
このような場合には、スケジューラが選択したワーカーに送信されるオペランドの数が多くなります。したがって、実行時間のほとんどの場合、ワーカーに提出されるオペランドの数は、通常、ワーカーが扱うことができるオペランドの総数よりも多くなります。ワーカーは、オペランドをソートし、その中から実行するオペランドの一部を選択する必要があります。このソート処理は、オペランドに関する情報を格納する優先度キューを維持するTaskQueueActorで実行されます。同時に、TaskQueueActorは定期的にジョブ割り当てタスクを実行し、オペランドを実行するための追加のリソースがなくなるまで、優先度キューの最上位にあるオペランドに実行リソースを割り当てます。この割り当て処理は、新しいオペランドが投入されたとき、またはオペランドの実行が完了したときにもトリガーされます。
メモリ管理
マーズワーカーはメモリの2つの側面を管理しています。最初の部分は各ワーカープロセスのプライベートメモリで、各プロセス自身が保持しています。もう一つは全プロセスで共有されるメモリで、Apache Arrowでは plasma_storeによって保持されています。
プロセスメモリのオーバーフローを避けるために、プロセスメモリを割り当てるワーカーレベルの QuotaActor を導入しています。オペランドの実行を開始する前に、オペランドは入力と出力のチャンクのためのメモリ要求のバッチを QuotaActor に送ります。残りのメモリ空間が要求を満たすことができれば、その要求はQuotaActorによって受け入れられます。そうでなければ、リクエストは空きリソースを待つためにキューに入れられます。関連するメモリが解放されると、要求されたリソースも解放される。この時点で、QuotaActorは他のオペランドにリソースを割り当てることができます。
共有メモリは plasma_store によって管理され、通常は総メモリの 50% を占有します。オーバーフローの可能性がないため、この部分のメモリは、QuotaActorを経由せずに、関連する plasma_store メソッドを介して直接割り当てられます。共有メモリを使い切ると、マーズワーカーは未使用のチャンクをディスクに捨てて、新しいチャンクのためのスペースを空けようとします。
共有メモリからディスクにダンプされたチャンク内のデータは、後続のオペランドによって再利用される可能性がありますが、ディスクから共有メモリにデータを再ロードすることは、特に共有メモリが枯渇し、ロードされたチャンクを収容するために他のチャンクをディスクにダンプする必要がある場合には、非常にIOリソースを必要とする可能性があります。そのため、データ共有が必要ない場合(例えば、チャンクが1つのオペランドでしか使用されない場合など)は、共有メモリではなく、プロセスのプライベートメモリに直接チャンクをロードします。これにより、ジョブの総実行時間を大幅に短縮することができます。
今後の作業
Marsは現在、急速にイテレーションが進んでいます。近い将来、ワーカーレベルのフェイルオーバーやシャッフルサポートの実装を検討しており、スケジューラレベルのフェイルオーバーも計画中です。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ