アリババ・シニア・ディベロップメント・エンジニア Tang Yun (Chagan) 著、Flinkコミュニティ・ボランティア Zhang Zhuangzhuang 編著
この記事は、アリババ・シニア・ディベロップメント・エンジニアのTang Yun (Chagan)が、Apache Flinkシリーズのライブ・ブロードキャストをもとに編集したものです。この記事の主なトピックは以下の通りです。
- コンテナ管理システムの進化
- Flink on Kubernetesの紹介
- Flink on Kubernetesの実践
- hostPathの使用方法のデモ
本記事の前半では、コンテナ管理システムの進化について紹介します。第2部では、Flink on Kubernetesについて、デプロイメントモードやクラスタのスケジューリング原理などを紹介します。第3部では、過去1年間にKubernetes上のFlinkを使用した際に遭遇した問題や学んだ教訓など、我々の実践的な経験を紹介します。最後のパートでは、クラスターのデプロイとタスクの投入を実演します。
コンテナ管理システムの進化

まず、カーネルではないKubernetesの開発者の視点から、KubernetesとYARNの関係を探ってみましょう。ご存知のように、Apache Hadoop YARNは、おそらく中国で最も広く使われているスケジューリングシステムです。その主な理由は、Hadoop HDFSが中国で、あるいはビッグデータ業界全体で最も広く使われているストレージシステムだからです。そのため、Apache Hadoop YARNは、初期のHadoop MapReduceを含めて、自然と広く使われるスケジューリングシステムになっています。YARN 2.0以降のFrameworkの開放により、Spark on YARNやFlink on YARNもYARN上でスケジューリングできるようになりました。
もちろん、YARN自体にも一定の制限があります。
- 例えば、YARNはJavaをベースに開発されているため、ほとんどのリソースの分離には制限があります。
- YARN 3.0では、GPUのスケジューリングと管理をある程度サポートしています。しかし、それ以前のバージョンのYARNは、GPUをあまりサポートしていません。
Apache Software Foundationに加えて、Cloud Native Computing Foundation(CNCF)でも、ネイティブクラウドのスケジューリングをベースにしたKubernetesを開発しています。
開発者としては、Kubernetesの方が多くの機能を持つOSに近いと思います。YARNは主にリソースのスケジューリングに使われます。OS全体の中ではかなり小さい方です。ビッグデータのエコシステムの先駆者でもあります。次に、Kubernetesに焦点を当て、YARNコンテナからKubernetesコンテナ(またはポッド)への進化の過程で得られた経験と教訓について説明します。
Kubernetes上のFlinkの紹介
クラスタのデプロイメント
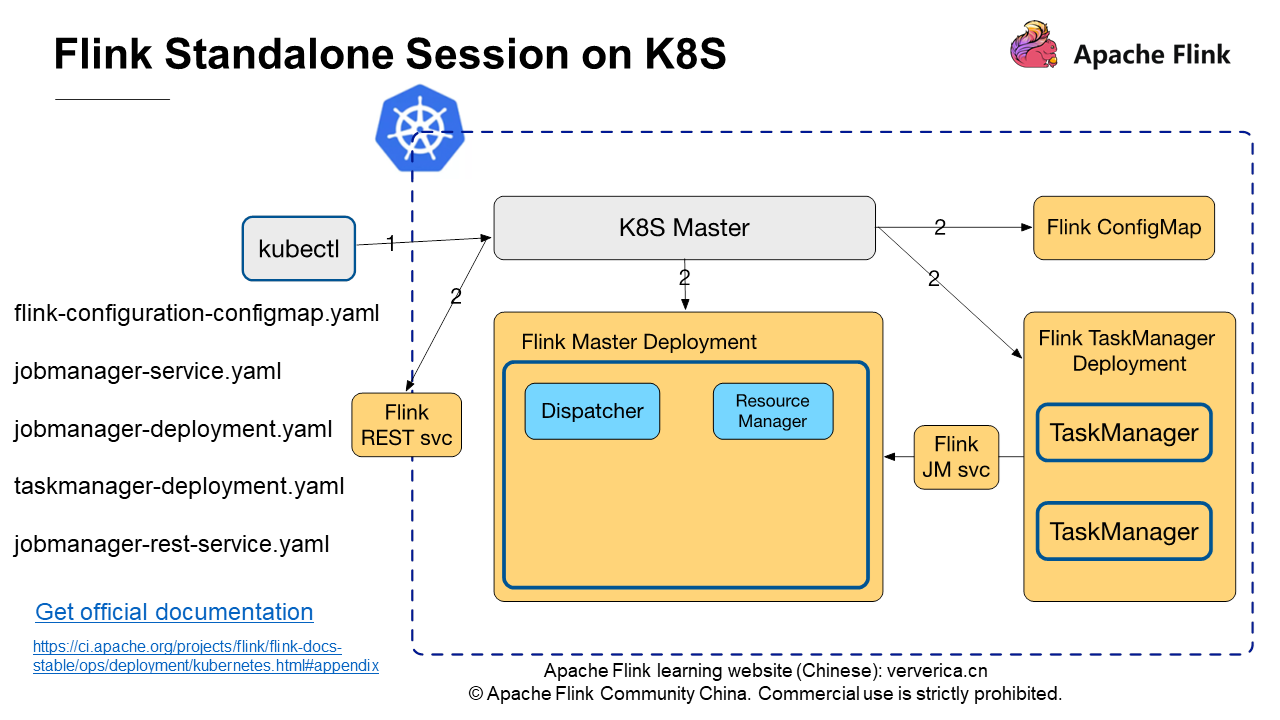
前述の図は、Kubernetes上のFlinkスタンドアロン・セッションクラスターにおけるスケジューリング・フローを示しています。青い破線のボックスはKubernetesクラスタ内で動作するコンポーネントで、灰色のボックスはkubectlやKubernetes MasterなどのKubernetesネイティブが提供するコマンドやコンポーネントです。左側には、Flinkの公式ドキュメントで提供されている5つのyamlファイルがリストアップされています。これらのファイルを使って、最もシンプルなFlinkのスタンドアロン・セッションクラスターをKubernetes上に展開することができます。
以下のkubectlコマンドを実行して、クラスタを起動します。
kubectl create -f flink-configuration-configmap.yaml
kubectl create -f jobmanager-service.yaml
kubectl create -f jobmanager-deployment.yaml
kubectl create -f taskmanager-deployment.yaml
-
最初のコマンドは、Flink ConfigMapを作成するためのKubernetes Masterに適用されます。ConfigMapはflink-conf.yamlやlog4j.propertiesなど、Flinkクラスターを実行するために必要な設定を提供します。
-
2番目のコマンドでは、TaskManagerをJobManagerに接続するためのFlink JobManagerサービスを作成します。
-
3つ目のコマンドは、JobMasterを起動するためのFlink JobManager Deploymentを作成します。このデプロイメントには、DispatcherとResource managerが含まれます。
-
最後のコマンドでは、TaskManagerを起動するためにFlink TaskManager Deploymentを作成します。公式のFlink taskmanager-deployment.yamlインスタンスには2つのレプリカが指定されているため、図には2つのTaskManagerノードが表示されています。
また、JobManager RESTサービスを作成して、RESTサービスを通じてジョブを投入することもできます。
前述の図は、Flink Standalone Sessionクラスターの概念を示しています。
ジョブの投入
次の図は、Flinkクライアントを使用して、スタンドアロン・セッションクラスターにジョブを投入するプロセスを示しています。
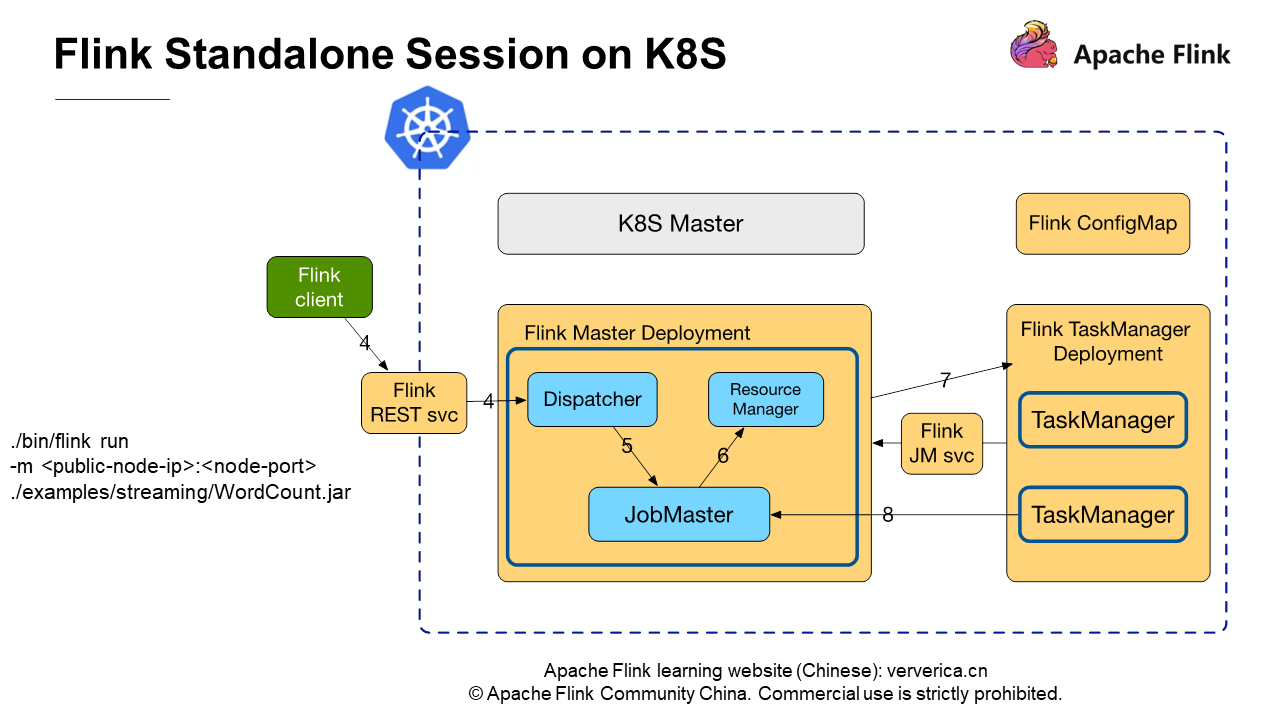
Flinkクライアントで、以下のコマンドを実行してジョブを投入します。
./bin/flink run -m : ./examples/streaming/WordCount.jar
ーmで必要なパラメータpublic-node-IPとnode-portは、jobmanager-service.yamlを通じて公開されるRESTサービスのIPアドレスとポートです。このコマンドを実行すると、Streaming WordCountジョブをクラスターに投入することができます。このプロセスは、Flink Standalone Sessionクラスターが実行されている環境に依存しません。クラスタがKubernetes上で動作しているか、物理マシン上で動作しているかに関わらず、ジョブの投入プロセスは同じです。
Kubernetes上でのStandalone Sessionのメリットとデメリットは以下の通りです。
-
メリット:クラスターを起動する前にいくつかのyamlファイルを定義するだけでよく、Flinkのソースコードを変更する必要がないこと。クラスタ間の通信はKubernetes Masterに依存しません。
-
デメリット:リソースを事前に要求する必要があり、動的に調整することができません。しかし、Flink on YARNでは、ジョブの投入時に、クラスターが必要とするJMやTMのリソースを宣言することができます。
Flink 1.10の開発過程では、スケジューリングを担当するアリババのエンジニアが、ネイティブコンピューティングモードのFlink on Kubernetesに貢献しました。
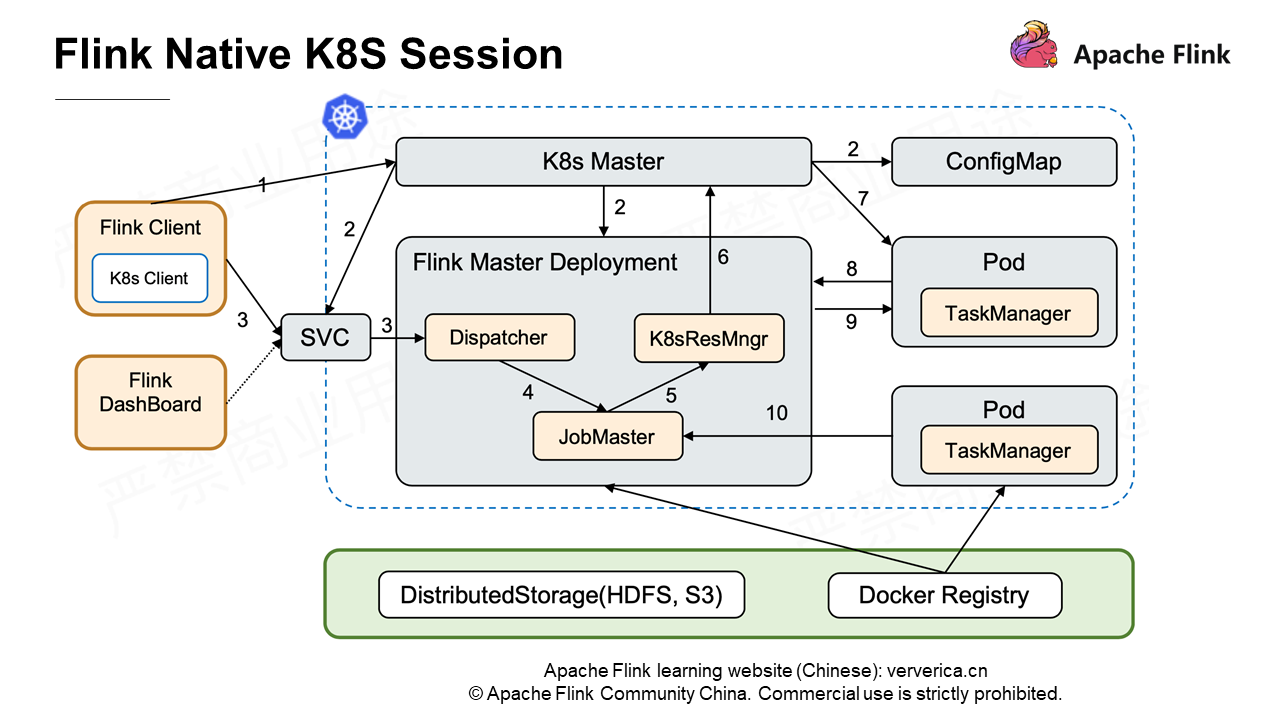
最も顕著な違いは、Flinkクライアントを介してジョブを投入すると、クラスタ全体のJobMasterがKubernetes ResourceManagerを介してKubernetes Masterにリソースを動的に申請し、TaskManagerを実行するポッドを作成することです。その後、TaskManagerとJobMasterは相互に通信を行います。ネイティブKubernetesの詳細については、Wang Yang氏が共有するRunning Flink on Kubernetes Nativelyを参照してください。
一言で言えば、KubernetesをYARNと同じように使い、関連する設定項目をできるだけYARNと同じようにするということです。説明を簡単にするために、Standalone Sessionクラスターを使って説明します。以下のセクションで説明する機能の中には、Flink 1.10では実装されておらず、Flink 1.11で実装される予定のものもあります。
Kubernetes上のFlinkのプラクティス
ログの収集
Flink on Kubernetesでジョブを実行する際には、機能的な問題であるログを避けることはできません。このジョブをYARN上で実行すると、YARNがこれをやってくれます。例えば、Containerの実行が完了すると、YARNはログを収集してHDFSにアップロードし、後で確認することができます。しかし、Kubernetesではログの収集や保存は行いません。ログを収集して表示する方法はたくさんあります。ログは、ジョブの例外によってポッドが終了すると失われるため、トラブルシューティングが非常に困難になります。
このジョブをYARNで実行した場合、yarn logs -applicationIdというコマンドを使って関連するログを見ることができます。しかし、このジョブをKubernetes上で実行すると?
現在のところ、ログを収集するためにfluentdを使用するのが一般的であり、一部のユーザーの本番環境で使用されています。
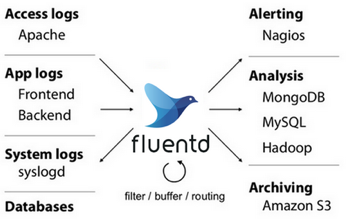
fluentdもCNCFのプロジェクトです。正規表現のマッチングなどいくつかのルールを設定することで、.log、.out、*.gcのログをHDFSなどの分散ストレージファイルシステムに定期的にアップロードし、ログ収集を実施することができます。つまり、TMやJMに加えて、fluentdプロセスを実行する別のコンテナ(sidecar)をポッドで起動する必要があります。
他の方法もあります。たとえば、logback-elasticsearch-appenderを使えば、コンテナを追加せずにログをElasticsearchに送ることができます。実装の原則は、Elasticsearch REST APIでサポートされているscoketストリームを使って、ログを直接Elasticsearchに書き込むことです。
fluentdと比較して、ログを収集するために別のコンテナを追加する必要がありません。ただし、System.outやSystem.errのログなど、log4j以外のログは収集できません。特に、ジョブ内でコアダンプやクラッシュダンプが発生した場合、関連するログがSystem.outやSystem.errに直接書き込まれます。このような観点から、logback-elasticsearch-appenderを使ってログをElasticsearchに書き込むことは、完璧な解決策とは言えません。これに対し、fluentdでは様々なポリシーを設定することで、必要なログを収集することができます。
メトリクス
ログは、特に問題が発生したときに、ジョブの実行状況を観察するのに役立ちます。発生シナリオを遡り、トラブルシューティングや分析を行うのに役立ちます。メトリクスとモニタリングは一般的でありながら重要な問題です。業界には、アリババで広く使われているDruid、オープンソースのInfluxDB、商用クラスタ版のInfluxDB、CNCFのPrometheus、UberのオープンソースM3など、多くの監視システムソリューションがあります。
続いて、Prometheusを例に挙げてみましょう。PrometheusとKubernetesはともにCNCFのプロジェクトであり、メトリクス収集の分野では固有の利点があります。ある程度、PrometheusはKubernetesにおける標準的な監視・収集システムです。Prometheusはアラームを監視するだけでなく、設定されたルールに基づいて多精度の管理を定期的に行うことができます。
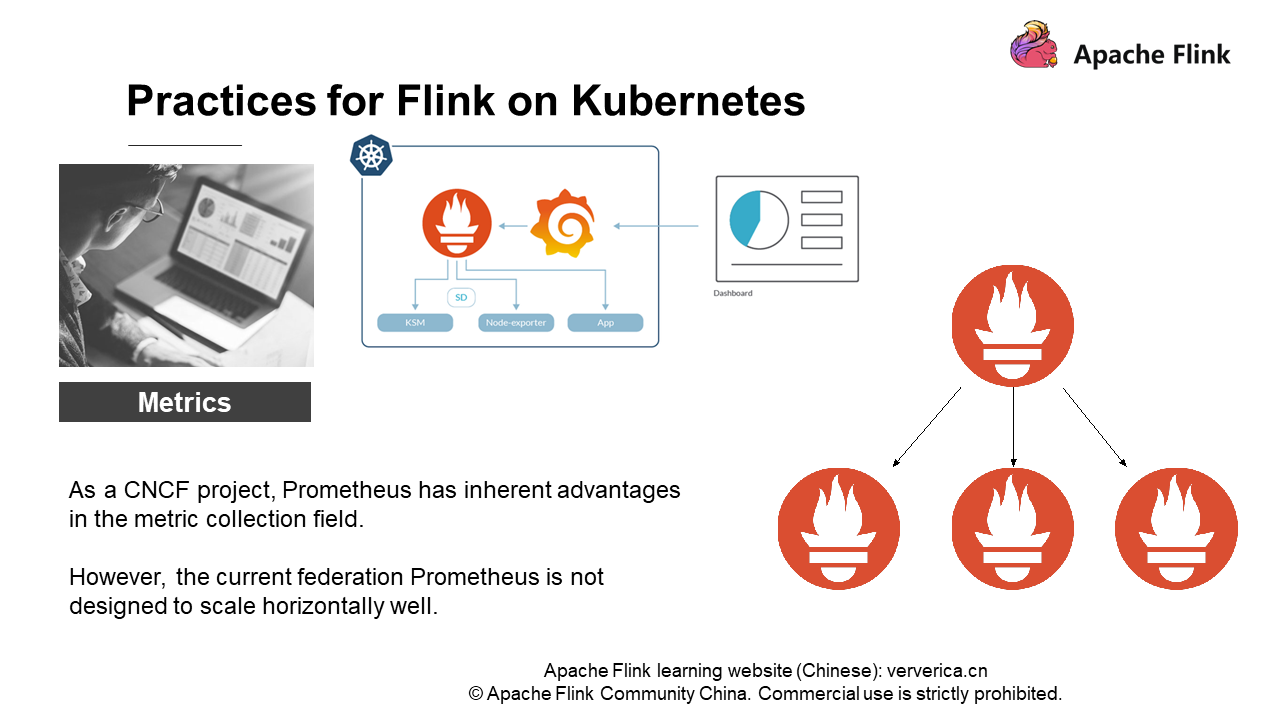
しかし、実際には、Prometheusは水平方向にうまくスケールするようには設計されていないことがわかります。前述の図の右に示すように、PrometheusのFederated分散アーキテクチャは、実際にはマルチレイヤー構造になっています。上位層のノードがルーティングやフォワーディングを行い、下位層の結果を照会します。当然のことながら、どれだけ多くのレイヤーを配置しても、上位のノードほどパフォーマンスのボトルネックになりやすく、クラスタ全体を配置することは困難です。ユーザー規模が大きくなければ、1台のPrometheusで監視要件を満たすことができます。しかし、ユーザー規模が大きくなると、例えば数百ノードのFlinkクラスターでは、1台のPrometheusがパフォーマンスの大きなボトルネックとなり、モニタリング要件を満たせなくなることがわかります。
この問題をどのように解決すればよいのでしょうか?
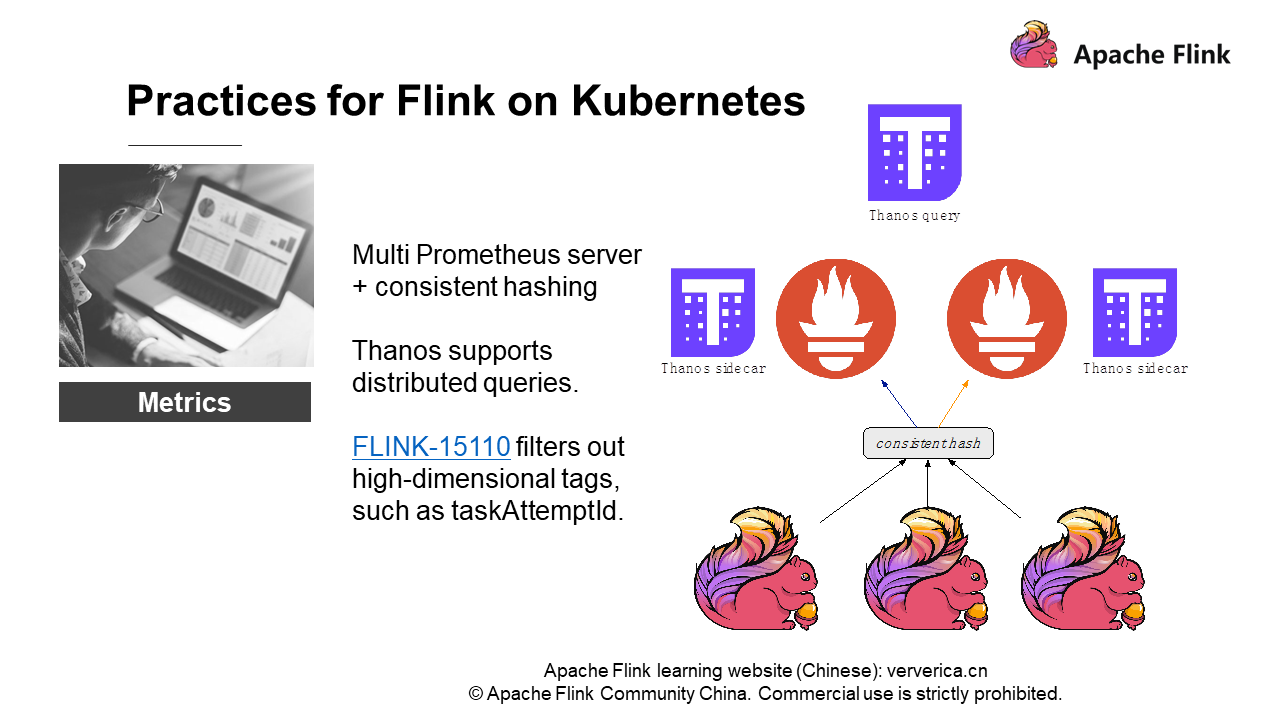
異なるFlinkジョブのメトリクスに対する一貫したハッシュを実装しています。もちろん、1つのジョブのメトリクスを1つのPrometheusインスタンスに送るわけではありません。代わりに、ジョブの異なるスコープのメトリクスを複数のPrometheusインスタンスに送信します。Flinkのメトリクスの強さは、大きいものから小さいものまであります。
- JobManager/TaskManager メトリクス
- ジョブ・メトリクス(チェックポイント数、サイズ、失敗回数)
- タスク・メトリクス
- オペレーター・メトリクス(1秒間に処理されるレコード数、受信バイト数)
さて、スコープに基づいてメトリクスに一貫したハッシュを実装し、ハッシュの結果を異なるPrometheusインスタンスに送信し、最後にThanosと連携します。Thanosとは、『アベンジャーズ3』に登場する悪役の名前です。Thanosは、Prometheusメトリクスの分散クエリをサポートする拡張コンポーネントです。そのため、Prometheusのアーキテクチャでは、単一のPrometheusインスタンスが配置されているコンテナにThanosのサイドカーを搭載することができます。
アーキテクチャ全体にはいくつかの制限があり、一貫したハッシュを作る必要があります。ThanosをPrometheusと一緒にデプロイすると、あるメトリクスデータが何らかの理由でPrometheus AとPrometheus Bの両方に存在することになります。そうすると、Thanosのクエリにはデータを放棄するための一定のルール、つまり一方を削除するともう一方のデータが優先されるというルールがあります。その結果、UI上のメトリクス・チャートのラインが断続的になり、不親切な体験を引き起こしています。そのため、Thanosによる一貫したハッシュ化と分散クエリを実装する必要があります。
しかし、ソリューション全体の適用において、いくつかのパフォーマンス問題が発生する可能性があります。Prometheusは、多くのサービスレベルのメトリクスでは良好なパフォーマンスを示すのに、なぜFlinkやジョブレベルでは良好なパフォーマンスを示さないのでしょうか?それは、ジョブメトリクスの急激な変化にあります。HDFSやHbaseのモニタリングに比べて、これらのコンポーネントのメトリクスは限られており、次元が低いのです。次元の概念を説明するために、クエリのシナリオを使ってみましょう。例えば、ホスト内のジョブに対するタスクのすべてのtaskmanager_job_task_buffers_outPoolUsageをクエリする必要があります。つまり、クエリのフィルタリングにタグを使用します。すると、FlinkのtaskAttempIdは不親切なタグであることがわかります。これはuuidで、ジョブが失敗するたびに変更されます。
ジョブが失敗し続けて新しいタグをPrometheusに永続化し、Prometheusに接続されているデータベースがタグのインデックスを作成する必要がある場合、大量のインデックスを作成する必要があります。例えば、InfluxDBに高い負荷がかかると、メモリやCPU全体が利用できなくなることがあります。これは想定外です。そのため、コミュニティにお願いして、レポートの中の高次元のタグをフィルタリングしてもらう必要もあります。興味のある方は、FLINK-15110をフォローしてください。
パフォーマンス
ネットワークパフォーマンス
まず、ネットワークパフォーマンスについて紹介します。Container Network Interface(CNI)やKubernetesのネットワークプラグインを使うにしても、ネットワークの性能低下は避けられません。一般的なフランネルでは、いくつかのテストプロジェクトで約30%のパフォーマンスロスが発生しています。あまり安定していません。ジョブではよく「PartitionNotFoundException Partition xx@host not found」が発生しますが、これはダウンストリームがアップストリームのPartitionを取得できないことを意味します。

Flinkレイヤーでネットワークのフォールトトレランスを向上させることができます。例えば、taskmanager.network.request-backoff.maxをデフォルトの10秒から300秒に設定し、Akkaのタイムアウト値をより大きな値に設定します。
もう一つ神経を使う問題があります。

ジョブが実行されているときに、ピアによるコネクション・リセットが報告されることがよくあります。これは、Flinkがネットワークの安定性に対して高い要求を持つように設計されているためです。正確に一度だけ保証するために、データ送信に失敗すると、タスク全体が失敗して再起動します。すると、ピアによる接続リセットが頻繁に報告されます。
私たちにはいくつかの解決策があります。
- 異種ネットワーク環境を避ける(クロスIDCアクセスをしない)。
- クラウドサービス事業者のマシンにマルチキューNICを設定する(インスタンス内のネットワーク遮断を異なるCPUに分散して処理することでパフォーマンスを向上させる)。
- Alibaba Cloud Terwayなどのクラウドサービスプロバイダーの高性能ネットワークプラグインを選択する。
- Kubernetesの仮想化ネットワークを避けてホストネットワークを選択する(一定の開発が必要)。
まず、クラスターが異種ネットワーク環境で動作しないようにする必要があります。Kubernetesのホストが異なるDCに配置されていると、IDC間のアクセス時にネットワークジッターが発生しやすくなります。次に、クラウド・サービス・プロバイダーからのマシンに、マルチキューのNICを設定しなければなりません。ECSの仮想マシンは、ネットワーク仮想化のために一定のCPUリソースを使用します。マルチキューNICが設定されていないと、仮想化では2つのコアの両方を使用するのに、NICは1つまたは2つのコアしか使用しないことがあります。この場合、パケットロスが発生し、「Connection Reset by peer」というエラーが報告されます。
もう一つの解決策は、クラウドサービスプロバイダーが提供する高性能なネットワークプラグインを選択することです。例えば、Alibaba Cloudが提供するTerwayは、ホストネットワークと同等のパフォーマンスをサポートしています。フランネルのようなパフォーマンスの低下は起こりません。
最後に、Terwayが利用できない場合は、ホストネットワークを使用してKubernetesの仮想化ネットワークを回避することができます。ただし、このソリューションはFlinkよりもいくつかの開発が必要です。Kubernetesを使用している場合、ある意味でホストネットワークを使用することに違和感があります。これはKubernetesのスタイルに適合していません。また、Terwayを使えないマシンもあり、同じ問題に遭遇します。対応するプロジェクトも用意しています。オーバーレイのフランネルの代わりにホストネットワークを使っています。
ディスク性能
次に、ディスク性能について説明します。前述したように、仮想化されたものはすべて何らかのパフォーマンス低下を引き起こします。RocksDBがローカルディスクを読み書きする必要がある場合、オーバーレイのファイルシステムでは約30%の性能低下が発生します。

ではどうすればいいのでしょうか?
私たちはhostPathを使うことにしました。簡単に言うと、ポッドはホストの物理ディスクにアクセスできるということです。前述の図の右にあるhostPathの定義を参照してください。もちろん、Flinkイメージのユーザーが、ホストのディレクトリにアクセスする権限を持っていることを事前に確認する必要があります。したがって、ディレクトリのパーミッションを777または775に変更しておいたほうがいいでしょう。
この機能を使いたい場合は、ポッドテンプレートを提供しているFlink-15656をご覧ください。自分で調整することができます。Kubernetesは様々な複雑な機能を提供しており、すべての機能に対してFlinkを調整するのは実現不可能であることがわかっています。テンプレートにhostPathを定義しておけば、書いたポッドがテンプレートのhostPathに基づいてディレクトリにアクセスできるようになります。
OOM killed
OOM killedも神経をすり減らす問題です。コンテナ環境でサービスを展開する際には、あらかじめポッドが必要とするメモリやCPUのリソースを設定しておく必要があります。するとKubernetesは、関連するノード(ホスト)のリソースをスケジューリングするために適用する設定を指定します。要求パラメータの指定に加えて、要求するメモリやCPUリソースを制限するための制限パラメータの設定も必要です。
例えば、あるノードの物理メモリが64GBで、8つのポッドが要求され、それぞれが8GBのメモリを持っているとします。問題ないように見えます。しかし、8つのポッドに制限がない場合はどうでしょうか。各ポッドは10GBのメモリを使用する可能性があるため、リソースを奪い合う必要があります。その結果,あるポッドは正常に動作し、別のポッドは突然キルされる可能性があります。そのため,メモリの上限を設定する必要があります。メモリ制限が原因でポッドが不可解に終了することがあります。Kubernetesのイベントを確認すると、OOMのためにpodがキルされていることがわかります。Kubernetesを使ったことがある人なら、この問題に遭遇したことがあるはずです。
どのように解決すればよいのでしょうか?

第一の解決策は、JVMのネイティブ・メモリ・トラッキングを有効にして、定期的にメモリをチェックすることです。この方法では、JVMによって要求されたネイティブメモリ(Metaspaceを含む)のみをチェックすることができ、JVMによって要求されていないメモリをチェックすることはできません。もう一つの解決策は、Jemallocとjeprofを使って定期的に分析用のメモリをダンプすることです。
正直なところ、2つ目の解決策を使うことはほとんどありません。以前はこの解決策をYARNに適用していましたが、一部のジョブが巨大なメモリを占有していることがわかったからです。JVMは最大のメモリを制限するので、ネイティブ・メモリに何か問題があるはずです。そこで、Jemallocとjeprofを使ってメモリを分析し、正確なネイティブメモリを見つけることができるのです。例えば、あるユーザーは設定ファイルを自分で解析します。彼らはファイルを解析する前に毎回ファイルを解凍し、ついにはメモリを使い果たしてしまいます。
これがOOMの原因となるシナリオです。ネイティブメモリを節約するステートバックエンドであるRocksDBを使用している場合、RocksDBがOOMを引き起こす可能性が高くなります。そこで、私たちはFlink 1.10の機能をコミュニティに提供しました。この機能は、RocksDBのメモリを管理し、state.backend.rockdb.memory.managedパラメータによって制御されます。この機能は、デフォルトで有効になっています。
次の図は何についてのものですか?
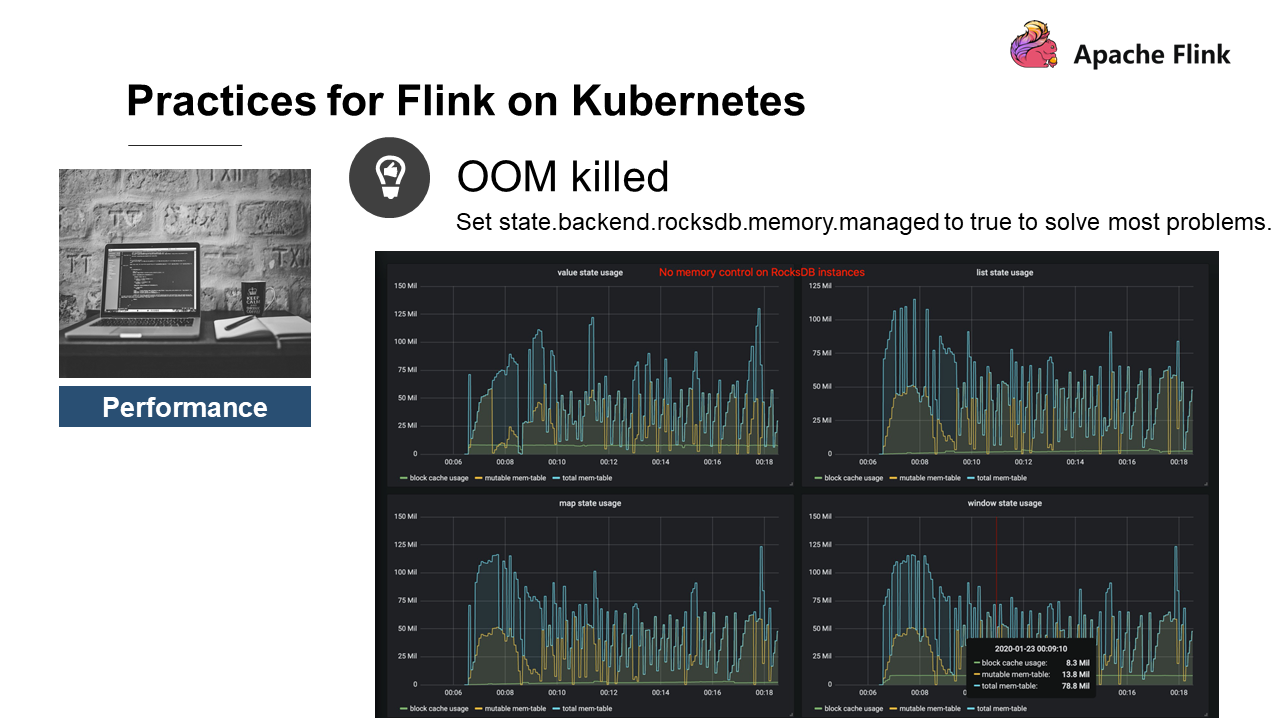
RocksDBにはメモリ制御がありません。状態はvalue、list、map、windowの4つです。一番上の行には、現在RocksDBが使用している総メモリのサイズが記載されており、これはブロックキャッシュの使用量とRocksDBの書き込みバッファを加えたもので、4つの状態の総メモリ使用量が400MB以上であることがわかります。
これは、Flink RocksDBが現在、ステートの数を制限していないためです。ステートとは、書き込みバッファとブロックキャッシュを排他的に占有するColumn Familyのことです。デフォルトでは、カラムファミリーは最大で2つの64MBのライトバッファと1つの8MBのブロックキャッシュを占有できます。1つのステートで136MB、4つのステートで544MBを使用します。
state.backend.rockdb.memory.managed を有効にすると、4つのステートは基本的に同じ傾向でブロックキャッシュを使用します。
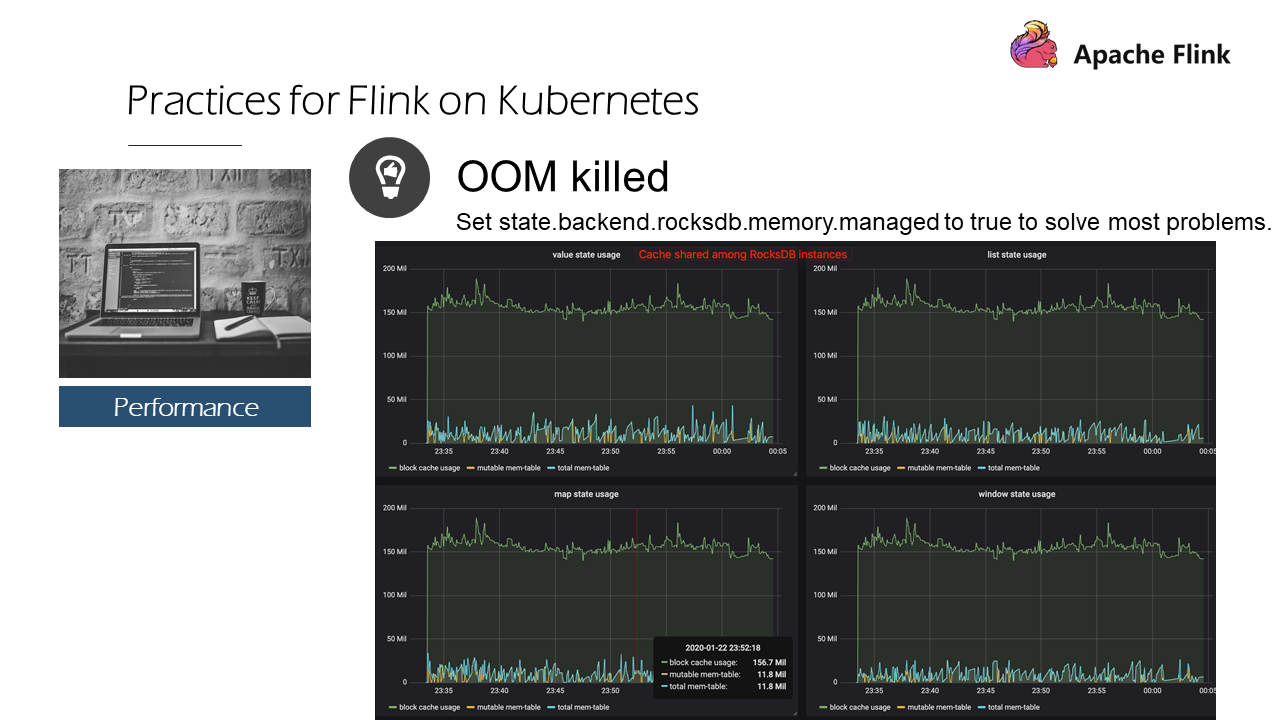
なぜでしょうか?それは、キャッシュ共有機能が使われているからです。つまり、LRUキャッシュがステートに作成され、どのような状況であってもメモリを分散してスケジューリングし、最も最近使用されたメモリを解放するようになっています。そのため、Flink 1.10以降のバージョンでは、state.backend.rockdb.memory.managedを有効にすることで、ほとんどの問題を解決することができます。

しかし、開発中にRocksDBのキャッシュ共有があまりうまく設計されていないことがわかりました。これには、厳密なキャッシュを実装できないなど、いくつかの実装上の問題があります。RocksDBのキャッシュ共有を有効にすると、奇妙なNPE問題が発生する可能性があります。つまり、RocksDBのキャッシュ共有は、特定のシナリオではうまく機能しないということです。このような場合には、taskmanager.memory.task.off-heap.sizeを増やしてバッファスペースを確保する必要があるかもしれません。
もちろん、まずは使用しているメモリを知る必要があります。先ほどのメモリ監視チャートでは、パラメータ state.backend.rockdb.metrics.block-cache-usage を true に設定する必要があります。そうすれば、メトリクス監視図で関連するメトリクスを取得し、メモリの使いすぎの大きさを観察することができます。例えば、1GBのステートTMのデフォルトのマネージャーは294MBを使用しています。
マネージャは時折、300MBや310MBを占有することがあります。この場合、taskmanager.memory.task.off-heap.size(デフォルト値は0)というパラメータを調整して、64MBのメモリなど、いくつかのメモリを増やすことができます。これは、Flinkが要求するオフヒープに余分なスペースが作られ、RocksDB用のバッファが追加されることを意味し、OOMのためにキルされることはありません。これは、現在使用できるソリューションです。しかし、根本的な解決のためには、RocksDBコミュニティと協力する必要があります。
もし同じような問題に遭遇した場合は、私たちに連絡してください。私たちは喜んで、関連する問題を追跡します。
デモ
最後に、hostPathの使い方をデモします。ほとんどのyamlファイルは、コミュニティのインスタンスと同じです。タスクマネージャーのyamlファイルを以下のように変更する必要があります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
containers:
- name: taskmanager
image: reg.docker.alibaba-inc.com/chagan/flink:latest
workingDir: /opt/flink
command: ["/bin/bash", "-c", "$FLINK_HOME/bin/taskmanager.sh start; \
while :;
do
if [[ -f $(find log -name '*taskmanager*.log' -print -quit) ]];
then tail -f -n +1 log/*taskmanager*.log;
fi;
done"]
ports:
- containerPort: 6122
name: rpc
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
- name: state-volume
mountPath: /dump/1/state
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j.properties
path: log4j.properties
- name: state-volume
hostPath:
path: /dump/1/state
type: DirectoryOrCreate
よくある質問
1、 FlinkはKubernetesのポッドを使ってどのようにHDFSとやりとりするのですか?
FlinkとHDFSの相互作用は簡単です。関連する依存関係をイメージにコピーするだけです。flink-shaded-hadoop-2-uber-{hadoopVersion}-{flinkVersion}.jar を flink-home/lib ディレクトリに置き、hdfs-site.xml や core-site.xml などのいくつかの Hadoop 設定をアクセス可能なディレクトリに置いてください。すると、FlinkはHDFSにアクセスできるようになります。このプロセスは、HDFSを持たないクラスタのノードからHDFSにアクセスする場合と同じです。
2、Kubernetes上のFlinkはどのようにしてHAを確保するのですか?
FlinkクラスターのHAは、FlinkがKubernetes上で動作するかどうかとは関係ありません。コミュニティのFlinkクラスターのHAは、ZooKeeperのサポートを必要とします。HAではZooKeeperがチェックポイントIDカウンター、チェックポイントストップ、ストリーミンググラフストップを実装する必要があります。そのため、Kubernetesクラスタ上のFlinkにZooKeeperサービスを提供することがHAのコアとなります。ZooKeeperクラスタは、Kubernetes上にも物理ホスト上にもデプロイできます。一方、コミュニティでは、Kubernetesにetdを使ってHAソリューションを提供する試みも行われています。現在のところ、産業グレードのHAを提供できるのはZooKeeperのみです。
3、Flink on KubernetesとFlink on YARNのどちらが良いのでしょうか?どうやって選択するのですか?
Flink on YARNは、現時点では比較的成熟したシステムですが、クラウドネイティブではありません。サービスをクラウドに移行する流れの中で、Flink on Kubernetesは明るい未来があると思います。Flink on YARNは成熟したシステムでしたが、新しいニーズや課題には対応できないかもしれません。例えば、GPUのスケジューリングやパイプラインの作成は、YARNよりもKubernetesの方が性能が高いです。
ジョブを実行するだけであれば、比較的成熟しているFlink on YARNでも安定して実行することができます。対して、Flink on Kubernetesは新しくて人気があり、イテレーションもしやすいです。しかし、Flink on Kubernetesは学習曲線が険しく、健全なKubernetes O&Mチームのサポートを必要とします。また、Kubernetesの仮想化では、どうしてもディスクやネットワークに一定のパフォーマンスロスが発生してしまいます。これは若干のデメリットと言えます。もちろん、仮想化(コンテナ化)はより明白なメリットをもたらします。
4、どのように/etc/hostsファイルを設定しますか?HDFSと対話するためには、HDFSノードのIPアドレスとホストを/etc/hostsファイルにマッピングする必要があります。
Volumeを介してConfigMapコンテンツをマウントし、/etc/hostsにマッピングすることもできますし、/etc/hostsを変更せずにCoDNSに頼ることもできます。
5、Flink on Kubernetesをうまくトラブルシューティングするには?
まず、トラブルシューティングの観点から、Flink on KubernetesとFlink on YARNの違いを把握する必要がありますね。Kubernetes自体に何か問題があるのかもしれませんが、それはちょっと困りますね。Kubernetesは、多数の複雑なコンポーネントを持つOSとみなすことができます。YARNは、Javaベースのリソーススケジューラーです。クラスタの例外の多くは、ホストの障害が原因です。私の考えでは、YARNよりもKubernetesのトラブルシューティングの方が難しいと思います。Kubernetesには多くのコンポーネントがあります。DNSの解析がうまくいかない場合は、CoDNSのログを確認します。ネットワークやディスクのエラーについては、kubeのイベントをチェックする必要があります。ポッドが異常終了した場合、イベントポッドがなぜ終了するのかを把握する必要があります。正直なところ、サポート、特にO&Mサポートが必要です。
Flinkのトラブルシューティングについては、KubernetesやYARNでもトラブルシューティングの方法は同じです。
- 例外が発生していないかログを確認する。
- パフォーマンスの問題については、jstackを使ってCPUとコールスタックに例外がないかチェックする。
- OOMリスクが常に存在したり、フルGCが発生しやすかったりする場合は、jmapを使ってメモリを占有するブロックを確認したり、メモリリークがないか分析する。
これらのトラブルシューティング方法は、プラットフォームに依存せず、すべてのシナリオに適用されます。なお、ポッドイメージには、一部のデバッグツールがない場合があります。Flink on Kubernetesクラスターを構築する際には、プライベート・イメージを作成し、対応するデバッグ・ツールをインストールすることをお勧めします。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ