python-pptxでPowerPointのレポートを操作したい時、事前にテンプレートを用意しておいて文字のフォーマットはそのままで内容の一部を変更したいことがあります。思ったよりも面倒でしたので、こちらの備忘録として残します。
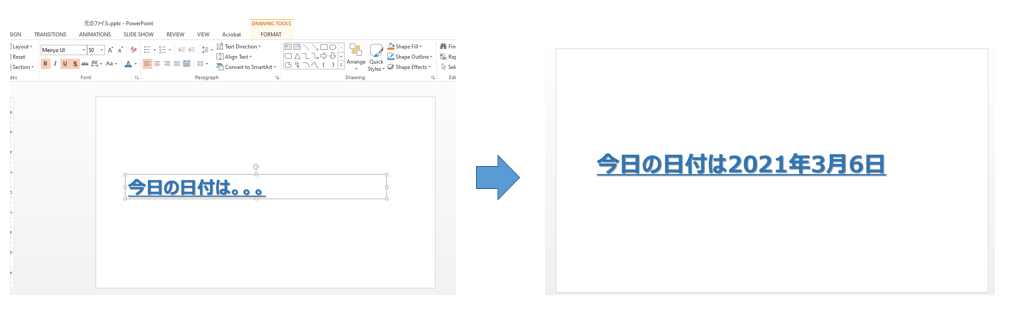
動作を確認するために、以下のようにフォーマットされた文字列のあるPPTファイルの一部(「。。。」)を今日の日付(2021/3/6)で変換するコードを書いてみました。元の文字は影をつけたり、下線をつけたりと、いろいろと装飾してあります。コードを実施される方は"元のファイル.pptx"というファイルを作ってコードと同じディレクトリに保存してください。
なお、既存の文字を置き換える方法は、python-pptxの作者であるScannyさんがこちらで説明していますので、その関数(モジュール)はそのまま利用します。
https://github.com/scanny/python-pptx/issues/285
replace_paragraph_text_retaining_initial_formattingという名前の長い関数がそうです。
私が工夫したポイントとしては、元のファイルの中から該当するparagraphオブジェクトを探すところです。このオブジェクトの関係がいろいろとややこしいのですが、こちらを参考にさせていただきました。この階層のどちらが上だったか、ぜんぜん記憶することができません。。。

import pptx, re
from pptx.util import Cm, Pt, Inches
def replace_paragraph_text_retaining_initial_formatting(paragraph, new_text):
p = paragraph._p # the lxml element containing the <a:p> paragraph element
# remove all but the first run
for idx, run in enumerate(paragraph.runs):
if idx == 0:
continue
p.remove(run._r)
paragraph.runs[0].text = new_text
prs = pptx.Presentation("元のファイル.pptx")
slide=prs.slides[0] #先頭のページを選択
for shp in slide.shapes:
if shp.has_text_frame:
if "日付は" in shp.text: #変更する文字列の一部でマッチさせる
new_text=re.sub('。。。', '2021年3月6日', shp.text) #置き換え
replace_paragraph_text_retaining_initial_formatting(shp.text_frame.paragraphs[0], new_text)
prs.save('変更後のファイル.pptx')