この記事で紹介すること
- いくつかのクラスタリング手法を併用しながらクラスタリングを進めてくれるパッケージの紹介
- ↑こういうクラスタリングのユースケース
- ↑こういうクラスタリングをやってみた実例
てか,なんでクラスタリング必要?
データに関わる研究やお仕事に関わっていると,新しいデータに出くわす場面はたくさんあります.
新しいデータというのは,そもそも中身がよくわからないわけですから,研究方針・分析方針などを考える前にまずはデータを理解しなくちゃいけません.
こういうときにクラスタリングは必要になります.1
私は調査業で自然言語処理の業務をやってきました.調査業でのNLPというと,テキストマイニングとも言えるかもしれません. 調査業での基本はデータ集計です.集計したデータと業界知識に基づいて,調査レポートを作成する・・・というのが,基本です. で,テキストデータももちろん集計しなくちゃいけません. 集計単位には「調査目的に適切なラベル」を使って集計することが多いです. 「調査目的に適切なラベル」がはじめからわかっているケースは,問題はありません. しかし,新しいテキストデータで「そもそもどんなラベルにしたらいいのか?わからへんがな」というケースはまずラベルを考えなくてはいけません. そんなケースではクラスタリングでデータをさらさら〜っと俯瞰できると,ラベルを考えるのが楽になります.例えばどんなクラスタリングのユースケースがあるの?
もちろん,クラスタリング以外のアプローチもできます. 例えば次のようなアプローチもありえます. それぞれに良し悪しがあるので,ユースケースに合った方法が一番いいと思います. が,私はそういうの考える面倒くさくなったときは「とりあえずクラスタリングで観察」という雑な考えです.クラスタリング以外の方法もあるんじゃないの?
クラスタリング?Kmeansとかでいいんじゃないの?
ベクトル化したテキスト+Kmeansの組み合わせは古くから使われてきた王道だと思います.
ただ,この組み合わせベストかというと,そういうわけでもありません.
- 「その他」みたいなでっかいクラスタが形成されちゃう.でも,クラスタの中身を見てみると,まだ分割できそうな気がする
- 最初からたくさんのクラスタ数でクラスタリングしたら,解釈が難しくなった.1回目はざくっと分けて,2回目はもう少し細かく分割できたらいいのに
- 「ここに注目してクラスタリングしてほしい」っていう特徴量がいくつかあって, 1回目のクラスタリングと2回目のクラスタリングで,別々の特徴量を見てくれたらいいのに
- クラスタリング後の解釈がめんどうくさい...いい感じに可視化してくれたらいいのに
「こうなるといいのにな〜」という部分を黒字で強調しました.
そんなクラスタリングを自分でプログラム書いていると割と手間です. 正直いって面倒くさい.
で,そんなクラスタリングをやってくれるパッケージを作りました.
flexible_clustering_treeの紹介
このパッケージは例えば,次のことをしてくれます.
- 1回目はざくっと分けて(クラスタ数=3)で,2回目のクラスタリングではもう少し細かく(クラスタ数=8)分ける
- 1回目はKmeansでざくっと決め打ちで分けて,2回目のクラスタリングではDBSCANで分布を考慮しながら分ける
- テキストデータセットがあって,1回目はタイトルの特徴量で分けて欲しい.2回目のクラスタリングでは,テキストの本文で分けて欲しい.
- クラスタリング後にD3.jsでツリー構造を可視化するメソッド付き
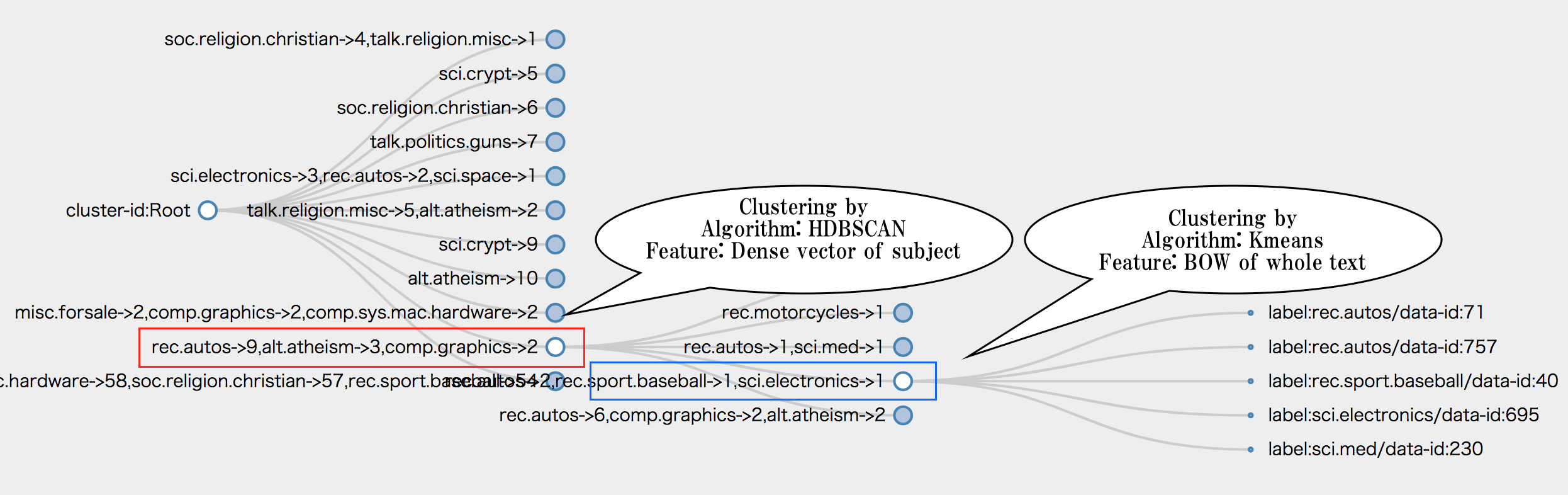
例えば,下の画像は次の条件でクラスタリングしたときの画像です.
- データセットは20-newsデータセット
- 1回目のクラスタリングはニューステキストのタイトルだけを特徴量(word embeddingの平均)にした.2回目のクラスタリングではニュース本文のBag-of-word特徴量を使った.
- 1回目のクラスタリングではHDBSCANを使った.2回目のクラスタリングではKmeansを使った.
- クラスタリング後にhtmlに出力して可視化.
ボトムアップの階層クラスタリングでも悪いことはないです. むしろ,ユースケースでは階層的クラスタリングの方がいいときもあります. ただ,ボトムアップ式の階層クラスタリングはデータ数が巨大になると,計算も実行も大変になるという特徴があります. このパッケージの発想はまだにボトムアップの階層クラスタリングの逆バージョンと言ってもいいです.ボトムアップの階層クラスタリングでいいんじゃないの?
ライブドアニュースコーパスでやってみた
株式会社ロンウィットさんが公開しているライブドアニュースコーパスというデータセットがあります.
ライブドアニュースコーパスはニュースカテゴリごとに分かれていますが,ここではカテゴリラベルはなかったことにして考えてみましょう.
ただ「やってみた」だけでは面白くないので,何か分析ストーリーがあると面白いと思いました. そこで,ビジネスユースケースに近い例として,次の例を考えてみました.
- あなたはWebサービスを運営してる企業のデータ分析的な何かをする人です.
- ある日,こんなお題がどこからか降ってきました.
- 運営してるニュースサービスの記事が溜まってきた.ユーザーが検索しやすくできるように,ニュース記事にタグをつけようと思う.
- でも,やたらめったらタグをつけてもユーザーを混乱させるだけになるかもしれない.
- ニュース記事の内容を観察して,いいタグを考えてね.よろしく☆
- あなたは実は他の業務も持っていて,あんましこの降ってきたお題に時間を割いてる余裕がないです.
あ...このユースケースは私の実例だったような・・・
どんな手順で観察してみるか?
さっくり次の手順でいくことにします.
- データ前処理.単語分割とかします.
- テキストの特徴量化.
- クラスタリング実行.
- D3.jsのツリー構造で内容の可視化
- クラスタを説明するデータの用意
データ前処理と単語分割
ライブドアニュースコーパスは「タイトル」と「本文」の2種類のテキストがあります.
今回はこの2つを別々の特徴量として扱いましょう.
Mecabでさっくり単語分割します.このスクリプトが前処理をします.
テキストの特徴量化
ライブドアニュースコーパスは「タイトル」と「本文」の2種類のテキストがあります.
まずはタイトルテキスト. タイトルは短いテキストです. これくらいの短さならば,word embeddingの平均化でも問題ないでしょう.
次に本文.
本文はそれなりに長いです.この長さをword embeddingの平均化・・・というのは少し乱暴な気がします.
Doc2vecはモデルを作ってる時間と手間も惜しいです.
Bertをサクッと実行できるだけの計算機リソースの用意も面倒です.
他にも文書をベクトル埋め込みする手法は選択肢はありますが,何より時間がありません
そこで,古典的に単語頻度行列 & 行列圧縮 のアプローチにします.
全体の流れはこのスクリプトです.
クラスタリングの実行
ここはコードを示しながら説明します. 全体の流れはこのスクリプトです.
まずは特徴量行列をセットします.
1回目のタイトル行列は title_vectors です.
2回目の本文行列は low_dim_matrix です.
両方とも (文書数 * 特徴量次元数)の行列です.
flexible_clustering_tree.FeatureMatrixObject に行列をセットするときに level にセットしたい回数を指定します.
import flexible_clustering_tree
# ここらへんにいろいろ処理を省略
feature_1st_layer = flexible_clustering_tree.FeatureMatrixObject(level=0, matrix_object=numpy.array(title_vectors))
feature_2nd_layer = flexible_clustering_tree.FeatureMatrixObject(level=1, matrix_object=low_dim_matrix)
次に,この2つのFeatureMatrixObjectを1まとめにします.
dict_index2attributesにはデータの補助説明をできる情報を格納できます(option).
特徴量としては一切使われません.
後で可視化したツリーにこの情報が表示されるので,解釈が楽になります.
ここでは,タイトル・本文・カテゴリラベルを格納しておきます.
text_aggregation_fieldには 2次元リスト [[単語]] を格納できます(option).
この情報で単語集計して,可視化したツリーに集計情報が表示されるので,解釈が楽になります.
二次元リストは 文書数 * 単語数(可変でOK) です.
multi_matrix_obj = flexible_clustering_tree.MultiFeatureMatrixObject(
matrix_objects=[feature_1st_layer, feature_2nd_layer],
dict_index2label={i: label for i, label in enumerate(livedoor_labels)},
dict_index2attributes={i: {
'file_name': livedoor_file_names[i],
'document_text': ''.join(document_text[i]),
'title_text': ''.join(title_text[i]),
'label': livedoor_labels[i]
} for i, label in enumerate(livedoor_labels)},
text_aggregation_field=document_morphs_text_aggregation
)
次に,クラスタリング手法の指定をします.
1回目はHDBSCANで全体分布を考慮しながら分けてもらいましょう 2
HDBSCANにはクラスタ数指定がないので, n_cluster=-1の指定にします.
from hdbscan import HDBSCAN
clustering_operator_1st = flexible_clustering_tree.ClusteringOperator(level=0, n_cluster=-1, instance_clustering=HDBSCAN(min_cluster_size=3))
2回目は決め打ちで8個のクラスタに分けることにします.
from sklearn.cluster import KMeans
clustering_operator_2nd = flexible_clustering_tree.ClusteringOperator(level=1, n_cluster=8, instance_clustering=KMeans(n_clusters=8))
次にこの2つのClusteringOperatorを1つにまとめます.
multi_clustering_operator = flexible_clustering_tree.MultiClusteringOperator([clustering_operator_1st, clustering_operator_2nd])
で,クラスタリングを実行します.
max_depth=3を指定すると,深さ3まで分けられるだけ分けてくれます.分割できなくなると,自動的にストップします.
2回目以降のクラスタリングには,最後に指定されたクラスタリング条件が使われます.
つまり,本文特徴量をKmeansでクラスタリングします.
# run flexible clustering
clustering_runner = flexible_clustering_tree.FlexibleClustering(max_depth=3)
index2cluster_no = clustering_runner.fit_transform(multi_matrix_obj, multi_clustering_operator)
ツリー可視化をして,htmlに保存します.
html = clustering_runner.clustering_tree.to_html()
with open(PATH_OUTPUT_HTML, 'w') as f:
f.write(html)
後で,データ集計したいので,テーブルをtsvに出力しておきましょう.
# 集計目的のテーブル情報を取得できる
import pandas
table_information = clustering_runner.clustering_tree.to_objects()
pandas.DataFrame(table_information['cluster_information']).to_csv('cluster_relation.tsv', sep='\t')
pandas.DataFrame(table_information['leaf_information']).to_csv('leaf_information.tsv', sep='\t')
D3.jsのツリー構造で内容の可視化
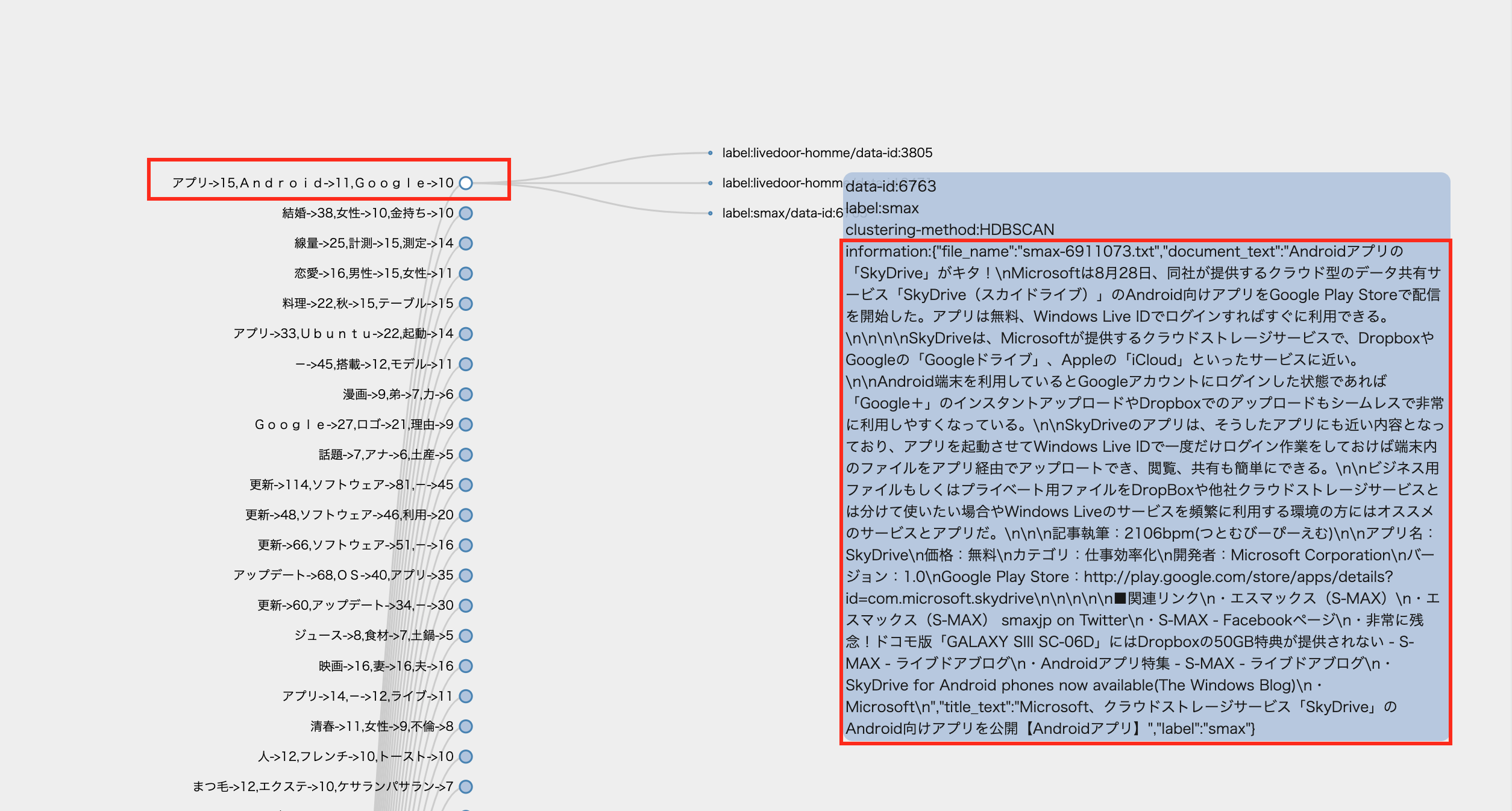
このクラスタはタイトルだけで分割された結果です. 赤枠のノード横に単語集計情報が出ています. アプリ・Android・Googleという内容からして,Androidスマホに関する話題のようですね.
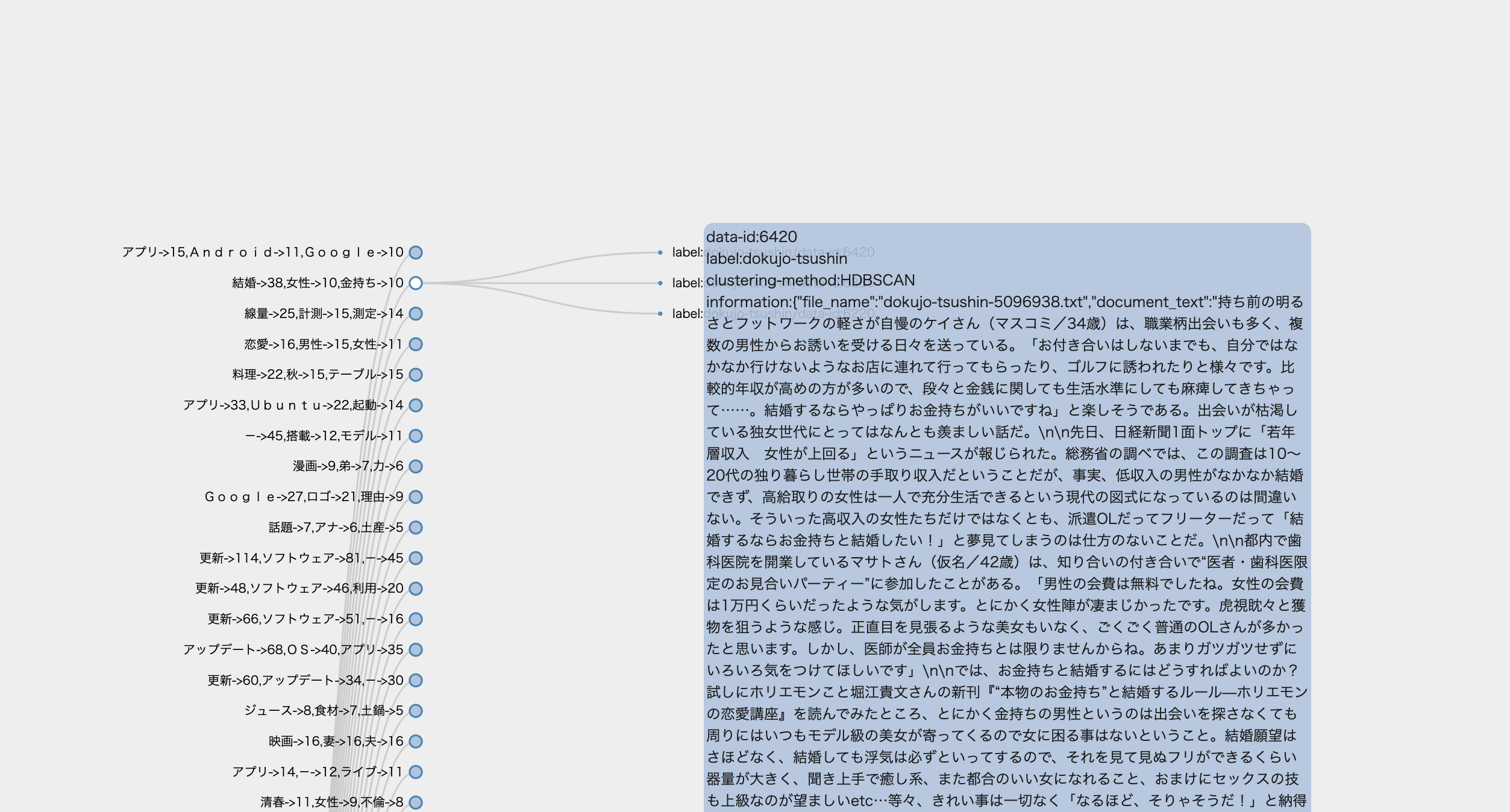
次にこのクラスタ・・・単語集計からもうかがいしれますが,やはり独女通信でしたね
#金持ちと結婚したい のようなタグがありえるかもしれません.
このツリーは上から下にクラスタの大きさ順にソートされています.
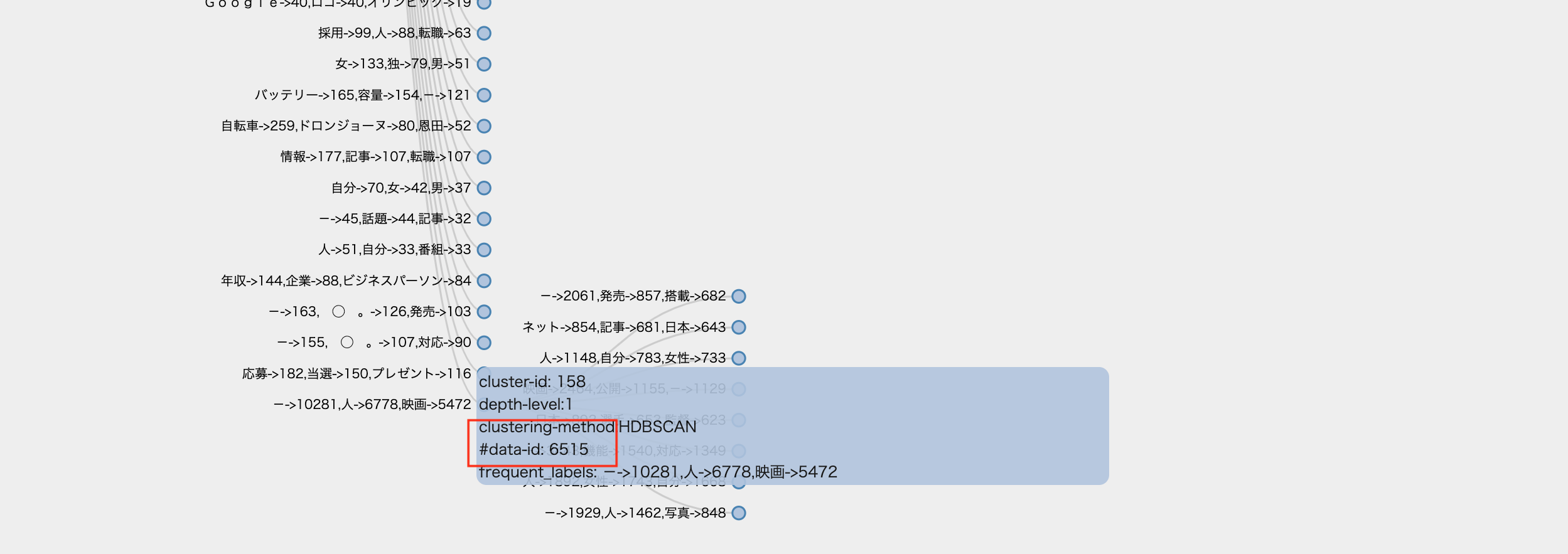
では,一番したのクラスタを見てみましょう.
data-idのフィールドにクラスタサイズが書いてあります. 6,515もの文書がこのクラスタに入っているようです.
これは「その他」クラスタのようですね.HDBSCANのような密度型クラスタリングにはよくあることです.
では,「その他」クラスタを分割してみましょう.Kmeansで分割されています.
画像は部分はスポーツニュースが多いクラスタです.単語からして「日本代表スポーツニュース」といった内容と推測できます.
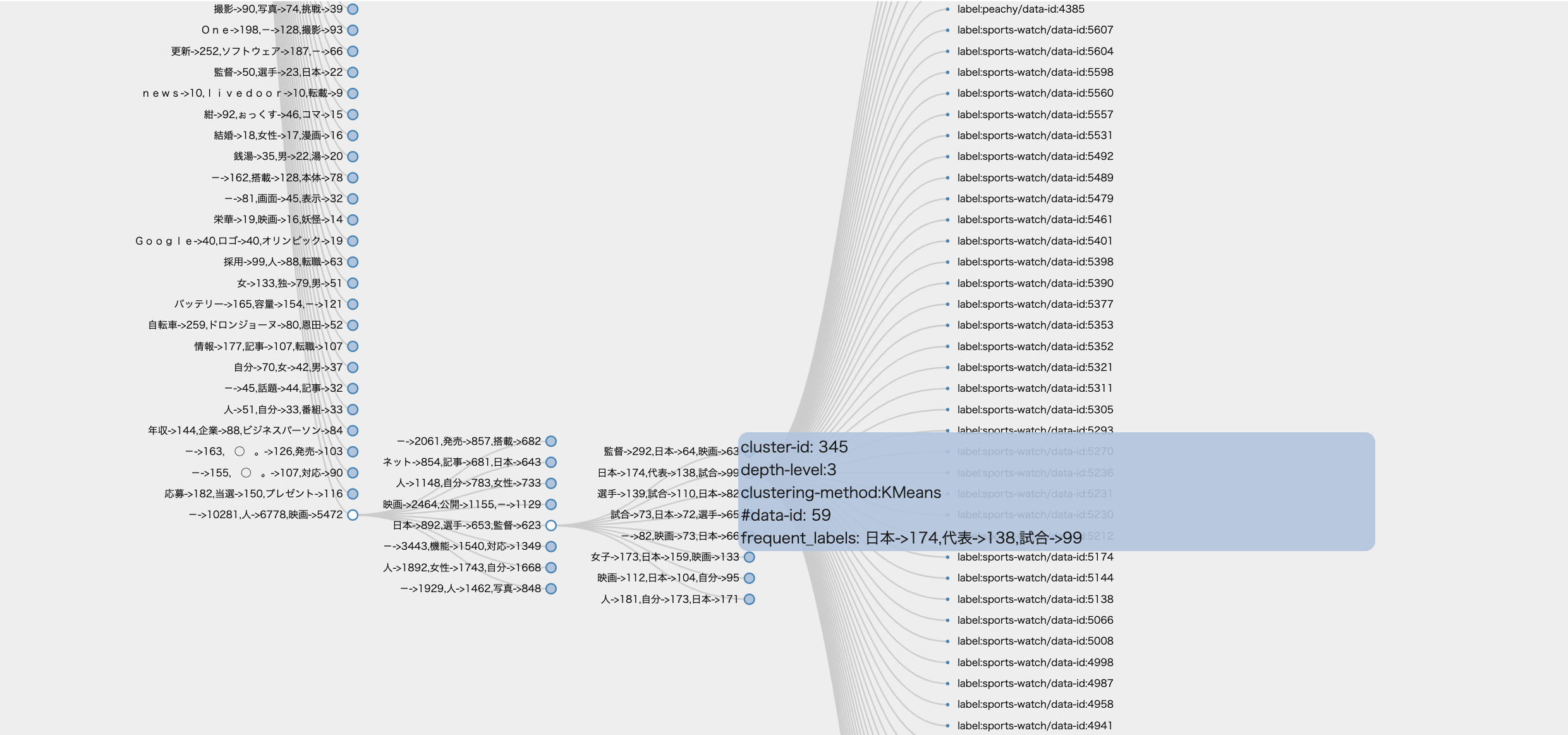
と,まぁ,こんな様子でまずはクラスタリング結果のざっくりとした内容は確認できました.
クラスタを説明するデータの用意
ツリーを目で見ていってもいいですが,さすがにちょっとしんどい感じもあります.目的はタグを考案することですから,タグを考えるためにいい情報が必要です.
さらに今回のお題文脈からして,「サービス運営チームがタグの理由を理解できるだけのデータor資料」を求められる可能性が高いです.
あなたはデータ分析的な何かをする人なわけですから,タグの理由をサービス運営チームに尋ねられて「勘っすかね〜」というわけにもいきません.「このデータに基づいて」(メガネクイッッッ)と行きたいところです.
そこで,次の作戦を考えます.
- クラスタごとにTF-IDFで特徴単語を得る.Excelファイルに書き出す.
- 特徴量単語から推測される適切なタグをExcelファイルに記載していく(手作業)
まずは,TFIDF重み付けの結果をcsvに書き出しました.labelがクラスタ番号です.
374クラスタはどうやら衣類関係の内容である可能性が高いです.

そこで,tag列に「衣類」と書いておきます.

この作業を繰り返していけばよいわけです.
実際に私がやってみると,1クラスタあたり20~30秒でタグの推測ができました.
今回は348クラスタありますから,348クラスタ*30秒=10440秒=178分でこの作業は完了します.
Youtube見る時間 休憩時間を考えても,4-6時間でタグ推測作業は終了します.
と,なると,あなたは作業スケジュールが立てやすいですし,「Hey上司っち〜.タグ付け作業に8時間くらいの工数かかるからよろぴこ(作業時間+バッファ時間+サボり時間)」という交渉もしやすくなります.
タグ推測作業後は,いい感じにスライド資料でも作ってサービス運営チームに渡してあげれば,きっと感謝されるでしょう〜
以上,私の脳内ポエムでした.
というところで,flexible_clustering_treeパッケージの紹介をしました.
脳内ポエムに使ったコードはこのリポジトリにあります.
このパッケージのまだいけてないところ
このパッケージにはまだ改善の余地がたくさんあります.PRは大歓迎です.
例えば,
- クラスタ数が大量発生すると,処理が遅くなる.幅優先探索処理をwhile文で書いているので,クラスタ数に比例して,時間がめっちゃかかる傾向があります.
- D3.jsベースのツリー可視化がいまいち.私はフロントエンドに弱いので,いい感じのツリーが作れないという事情があります.