kaggleのPelin AyさんのNotebookでアメリカのコロナ患者数予測モデルが作られており、
ここではこれを参考にして日本のコロナ患者数予測モデルを作っていきます。
https://www.kaggle.com/pelinay/covid19-forecasting/
これは以下のkaggleのコンペ(2020/5/12で終了)用に書かれたものです。
https://www.kaggle.com/c/covid19-global-forecasting-week-5
環境:
WindowsでAnacondaをインストールしたときに一緒にインストールされるJupyter Notebookを使用
使用するデータ
-
train.csv :トレーニングデータ
-
test.csv :テストデータ
-
submission.csv:コンペの提出用フォーマットファイル
データ提供元:
https://www.kaggle.com/c/covid19-global-forecasting-week-5/data
- Countries_usefulFeatures.csv :
各国の特徴的な情報が入っており、日本については以下のような情報になっている

データ提供元:
https://www.kaggle.com/ishivinal/covid19-useful-features-by-country
Jupyterのルートフォルダにkaggleフォルダを作り、その中でinputフォルダにデータを、codeフォルダにNotebookのファイルを置いています。
Juptyter Notebook上で以下のようにデータを読み込んでいます。
path = "../input/covid19-global-forecasting-week-5/train.csv"
path2 = "../input/covid19-global-forecasting-week-5/test.csv"
path3="../input/covid19-useful-features-by-country/Countries_usefulFeatures.csv"
path4="../input/covid19-global-forecasting-week-5/submission.csv"
df_train = pd.read_csv(path,encoding = 'unicode_escape')
df_test = pd.read_csv(path2,encoding = 'unicode_escape')
df_count_feat=pd.read_csv(path3,encoding = 'unicode_escape')
df_sub=pd.read_csv(path4,encoding = 'unicode_escape')
ライブラリのインポート
fbprophet、plotly、およびxgboostをそれぞれAnacona Promptで
conda install -c conda-forge fbprophet
pip install plotly
pip install xgboost
でインストールした上で、JupyterNotebook上で以下によりライブラリのインポートを行った。
import pandas as pd
import seaborn as sns
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
pd.pandas.set_option('display.max_columns', None)
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
from sklearn.linear_model import Lasso
from sklearn.feature_selection import SelectFromModel
pd.pandas.set_option('display.max_columns', None)
import matplotlib.pyplot as plt
from fbprophet import Prophet
import plotly.express as px
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from sklearn.metrics import accuracy_score
from sklearn import metrics
from sklearn.model_selection import ParameterGrid
from tqdm import tqdm
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
Prophet
ProphetはFacebookが開発した時系列予測のライブラリで詳細は以下に書かれてます。
https://facebook.github.io/prophet/docs/quick_start.html
特徴:
- Prophetの入力は列がdsとyのデータフレームである必要がある
- dsはデータフレーム、yは予測を行いたい数値測定データ
データ解析
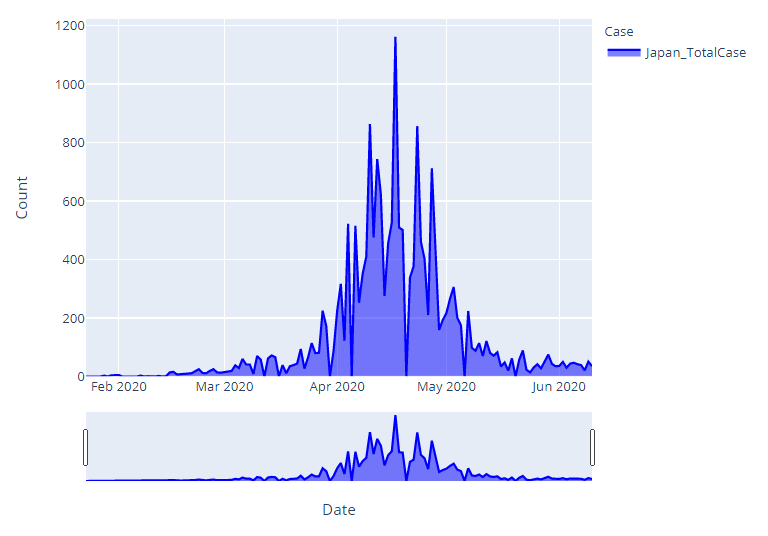
AyさんのIn[15]ではUS,Brazil,Russiaの3か国のグラフを表示しているが、ここでは日本について解析するので以下のように変更した。
df_Jap=df_train[df_train['Country_Region']=='Japan']
df_Jap=df_Jap[df_Jap['Target']=='ConfirmedCases']
df_Jap=df_Jap.rename(columns={"Date":"Date","TargetValue": "Japan_TotalCase"})
df_Jap=df_Jap[["Date","Japan_TotalCase"]]
df_plot=df_Jap.rename(columns={"Date":"Date","TargetValue": "Jap_TotalCase"})
df_plot=df_plot[["Date","Japan_TotalCase"]]
(記事作成中)
df_Jap=df_train[df_train['Country_Region']=='Japan'][df_train['Target']=='ConfirmedCases']
plt.figure(figsize=(20, 10))
sns.lineplot(data=df_Jap[df_Jap['Date']<"2020-05-01"], x="Date", y="TargetValue")
plt.xticks(rotation=90);
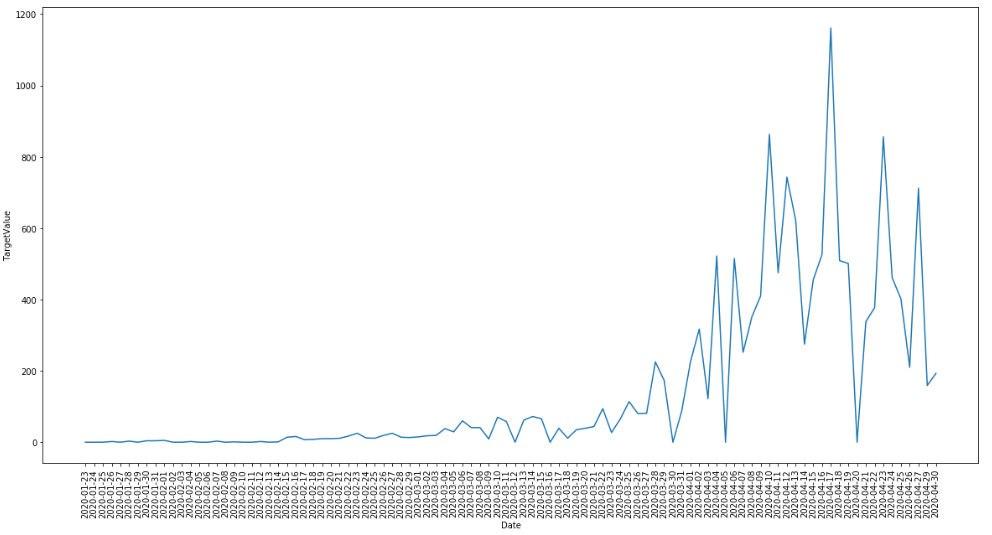
2020/5/12の前のデータをトレーニングデータ、後のデータをテストデータとします:
Train_Jap=df_Jap[df_Jap["Date"]<"2020-05-12"]
Test_Jap=df_Jap[df_Jap["Date"]>="2020-05-12"]
Prophetでデータを使用するために"Date"列を"ds"に、"TargetValue"列を"y"にリネームします:
Train_Jap=Train_Jap[["Date","TargetValue"]].rename(columns={"Date":"ds","TargetValue":"y"})
Test_Jap=Test_Jap[["Date","TargetValue"]].rename(columns={"Date":"ds","TargetValue":"y"})
Prophetによる学習を実行するのですが、growth='linear'(線型)とgrowth='logistic'(ロジスティック関数)を選択できます。以下、両パターンについて記載します。
Prophet: growth='linear'の場合
model=Prophet(growth='linear',changepoint_prior_scale=60)
model.fit(Train_Jap)
forecast = model.predict(Test_Jap)
fig = model.plot_components(forecast)
Prophetのplot_componentsメソッドは予測結果をtrend(week周期とyear周期を除いた傾向)、weekly(week周期)、yearly(year周期)を表示してくれます。ここではテストデータが一年分ないのでyearlyは表示されません。

予測結果の表示:
plot = model.plot(forecast)
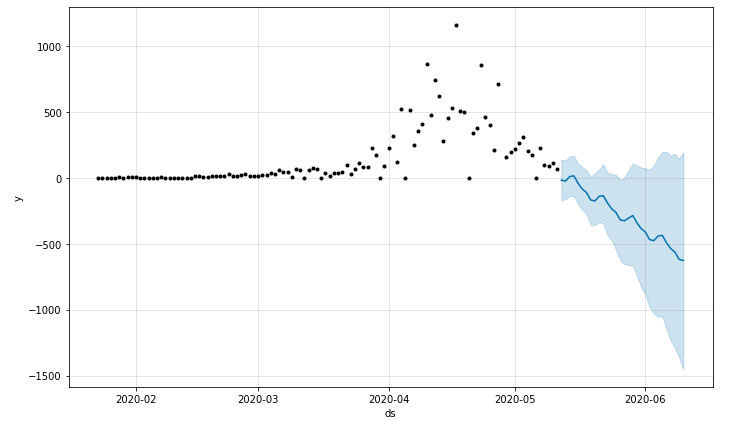
日本の5/12までのデータでgrowth='linear'の場合、予測感染者数がマイナスになってしましました。
0以下にならないようにするにはgrowth='logistic'を使う必要があるとわかったので、以下growth='logistic'でやっていきます。
Prophet: growth='logistic'の場合
"logistic"ではデータに'cap'(環境収容力)列が必要になる。環境収容力はyの限界値を表すが、ここでは日本人の人数の概算値1億2千万を入れてみます。また、yの最小値は'floor'列で指定でき、デフォルト0だそうですが、ここでは明示的に0を入れておきます。
Train_Jap['cap']=120000000
Test_Jap['cap']=120000000
Train_Jap['floor']=0
Test_Jap['floor']=0
model=Prophet(growth='logistic',changepoint_prior_scale=60)
model.fit(Train_Jap)
forecast = model.predict(Test_Jap)
fig = model.plot_components(forecast)
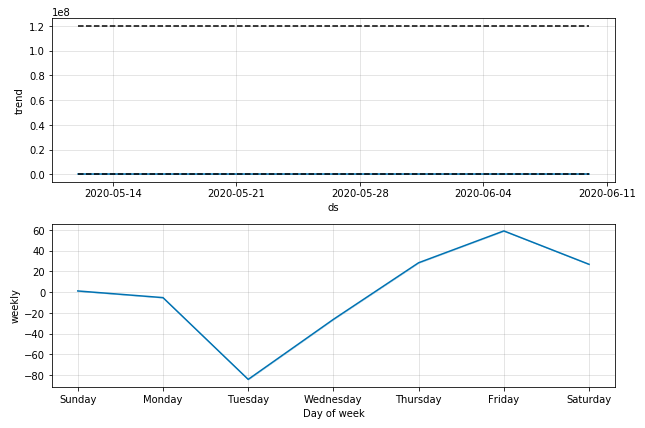
モデルの実行ですが、そのままではcapの値によってy軸の幅が大きくなってしまうのでylimで制限します:
plot = model.plot(forecast)
plt.ylim([-100, 1300])
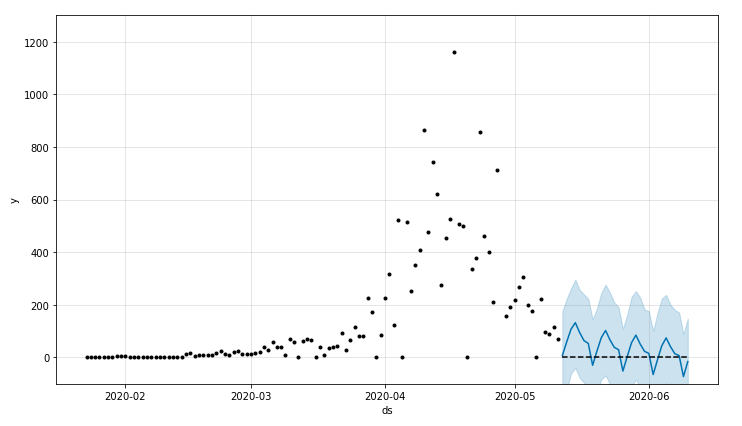
linearのときより良い感じですが、0を下回っているところがあります。
trendの値は0以上にできてもweeklyの寄与があるせいですね。
改善方法がみつかれば更新します。
今回は勉強用に少し古いデータを使ってみましたが、コロナ患者数の最新データでまた解析しようと思います。