モチベーション
色々とご縁があり、「生徒の回答が、金賞、銀賞、銅賞、圏外なのか?」を分類する、Text Classificationの問題を解くことになりました。
実務で、自然言語処理のタスクは、あまり解いた事がなかったので、とりあえずKaggleで盛り上がっていた「Sentiment Analayis 感情分析」の問題を解いてみて、練習する事にしました。
色々と試行錯誤する中で、(他のタスク以上に)自然言語処理のタスクでは、前処理(テキストの加工)が重要な事がわかったので、本記事にまとめようと思います。
データの概要説明
世界中の学生や実務家が、その実力を競い合っている、Kaggleというオンラインデータ分析コンペのサイトから、”Sentiment140 dataset with 1.6 million tweets”というデータセットが、共有されているので、そちらのデータを使用します。
こちらは、コンペティションで使用されたデータではなく、「感情分析に、是非役立ててください」と、Kaggleの有志が共有してくれたデータセットです。160万ものツイートが揃っており、かなりリッチなデータセットです。下記、データの概要を表で、共有します。

【データセットは、こちらから】:https://www.kaggle.com/kazanova/sentiment140
タスクは、text(tweet)が与えられた時、そのtweetがPositiveか?Negativeか?を予測する、分類問題(Binary Classification)の問題です。
モデリングの戦略
「モデルのアーキテクチャは固定させ、前処理を色々と変える」という方法を採用しました。
(本当は、色々試したのですが)本記事では、わかりすさを優先して、下記のようなフローで、簡潔に共有させて頂きます。
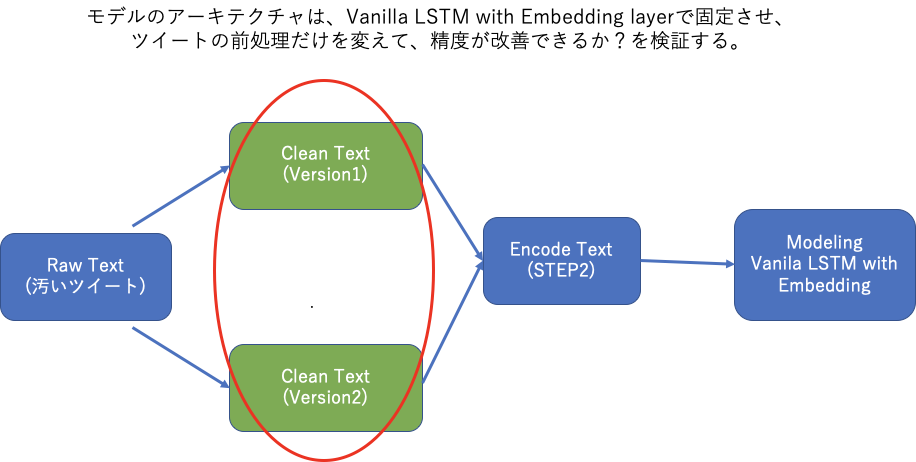
Vanila LSTMとは、もっとも基本的(古典的)な、LSTMのストラクチャーで、下記の特徴を備えたモデルです。
- 一つの隠れ層(LSTM Unit層)が一つ
- 出力のための全結合層(Dense Layer)が一つ
コード(Keras Sequential API)で示すと、下記のようになります。
model = Sequential()
model.add(LSTM(32, activation='tanh', input_shape=(n_steps, n_features)))
model.add(Dense(2,activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics = ['accuracy'])
[参考:https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/]
さて、下記から、実際に行った実装について、共有していきます。
まずは、必要なライブラリと、データのインポート
from collections import defaultdict, Counter
import time
import re
import string
import pandas as pd
import nltk
from nltk.corpus import stopwords
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Embedding,LSTM, Dense
from keras.callbacks import EarlyStopping
df = pd.read_csv("twitter_sentiment_kaggle.csv", encoding="latin-1",header=0,
names=['sentiment','id','date','flag','user','text'], usecols=["id", "sentiment", "text"])
print(df.head(2))
ここは、特に説明不要だと思いますので、次に行きます。
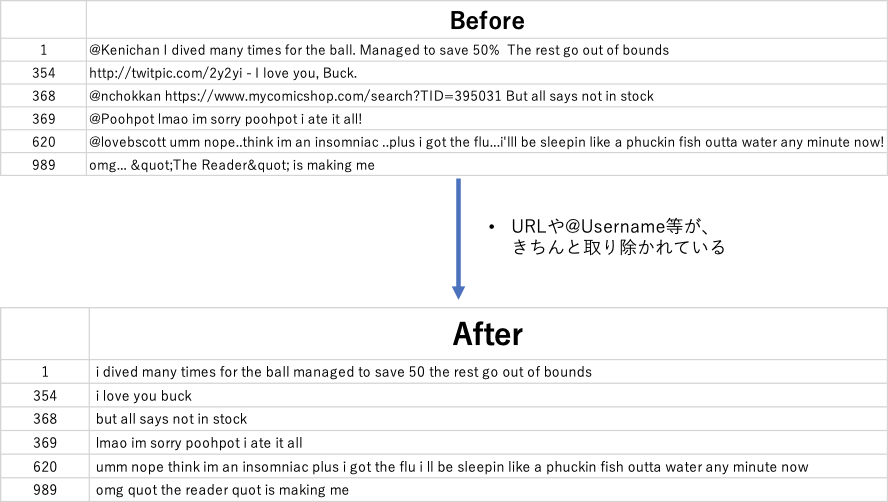
STEP1: ツイートを綺麗にする前処理 version1
ツイートを綺麗にするとはどういうことか?というと、「学習の妨げになる、文字や記号を削除する」作業のことです。
今回のタスクは、モデルが「ツイートから、感情を読み取る(紐ずける)」ことをしないといけなので、「@username」や「URL」の情報は、邪魔になるでしょう。
NLPのタスクでは、そういった、「モデルに学習させたくない記号や文字を削除する作業」を、一般に「前処理」と名付けています。
さて、今回私が最初に試した、前処理を下記に記載しました。特別なものはなく、どれも基本的な前処理です。
【実施した前処理】
- 単語を全て小文字にする
- URLを削除する
- 絵文字をエンコードする
- モデリングに不必要な記号を、空白""に、置き換える
- @usernames
- 数字とアルファベット以外
- 3つ以上連続している文字を2つに省略する ( e.g. "awwwww" ---> "aww" ) - ツイートをトークン化し、ストップワードと句読点を削除する
def clean_text(text_data):
# エンコーディング、正規表現、ストップワード、句読点の定義 ---> ネットで有志が定義してくれてるので、拝借しましょう。
URL_PATTERN = r"((http://)[^ ]*|(https://)[^ ]*|( www\.)[^ ]*)"
EMOJI_ENCODER_DICT = {':)': 'smile', ':-)': 'smile', ':))': 'smile', ';d': 'wink', ':-E': 'vampire', ':(': 'sad', ':-(': 'sad', ':-<': 'sad', ':P': 'raspberry', ':O': 'surprised',
':-@': 'shocked', ':@': 'shocked',':-$': 'confused', ':\\': 'annoyed', ':#': 'mute', ':X': 'mute', ':^)': 'smile', ':-&': 'confused',
'$_$': 'greedy','@@': 'eyeroll', ':-!': 'confused', ':-D': 'smile', ':-0': 'yell', 'O.o': 'confused','<(-_-)>': 'robot', 'd[-_-]b': 'dj',
":'-)": 'sadsmile', ';)': 'wink', ';-)': 'wink', 'O:-)': 'angel','O*-)': 'angel','(:-D': 'gossip', '=^.^=': 'cat'}
USER_NAME_PATTERN = r'@[^\s]+'
NON_ALPHA_PATTERN = r"[^A-Za-z0-9]"
SEQUENCE_DETECT_PATTERN = r"(.)\1\1+"
SEQUENCE_REPLACE_PATTERN = r"\1\1"
ENGLISH_STOPWORDS = stopwords.words('english')
PUNCTUATIONS = string.punctuation.split()
############################### ツイートの前処理を実施する ########################################
clean_tweets = []
for each_tweet in text_data:
# 文字を全て、小文字にする
each_tweet = each_tweet.lower()
# URLを消去する
each_tweet = re.sub(URL_PATTERN, "", each_tweet).strip()
# 3つ以上連続している文字を2つに省略する
each_tweet = re.sub(SEQUENCE_DETECT_PATTERN, SEQUENCE_REPLACE_PATTERN, each_tweet)
# 絵文字をエンコードする
for key in EMOJI_ENCODER_DICT.keys():
each_tweet = each_tweet.replace(key, " EMOJI " + EMOJI_ENCODER_DICT[key])
### モデリングに必要ない、各種記号を削除する ###
# ”@usernames”を削除する
each_tweet = re.sub(USER_NAME_PATTERN, "", each_tweet)
# 数字とアルファベット以外を削除する
each_tweet = re.sub(NON_ALPHA_PATTERN, " ", each_tweet)
### ツイートをトークン化(要素が各単語のリスト、にする)し、ストップワードと句読点を削除する ###
tokenizer = nltk.TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True)
tweet_tokens = tokenizer.tokenize(each_tweet)
# ストップワードと句読点を削除
clean_tweet_sentence = ' '
for word in tweet_tokens: # 1単語ずつ見ていく
if (word not in ENGLISH_STOPWORDS and word not in PUNCTUATIONS):
clean_tweet_sentence += (word+' ')
clean_tweets.append(clean_tweet_sentence)
return clean_tweets
#########################################################################################
# ツイートを綺麗にする
t = time.time()
clean_tweets_list = clean_text(df["text"])
print(f'ツイートが綺麗になりました。')
print(f'コード実行時間: {round(time.time()-t)} seconds')
# 綺麗にしたツイートを、'clean_tweet'として、新たな列に追加する
df["clean_text"] = clean_tweets_list
# 結果の表示
print(df[["text", "clean_text"]].head(2))
綺麗にした後の結果: URLや@Usernameが適切に取り除かれています。
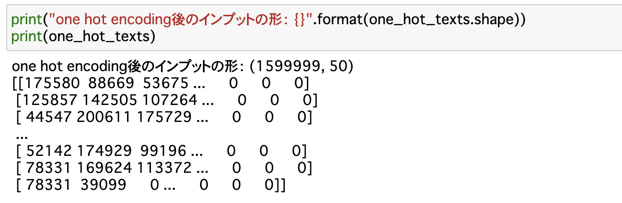
Step2: 文字をエンコードする
上記のSTEP1で、ツイートを綺麗にした後は、ツイートをモデルに学習させるための処理をします。つまり、ツイートに含まれるそれぞれの文字(英単語)を、数字で表します。モデルは、数字しか認識できないので、当然必要になってくる作業ですよね。
具体的に行った作業を下記にまとめます。
-
ツイートに含まれる文字をそれぞれ、ハッシュ化(One Hot Encoding)する
- ハッシュ化とは、「文字一つ一つにインデックス番号を割り当てる」ことです。
- 例えば、「I love LSTM」が、[100, 240, 600]に変換されます。
- この前処理は、のちに後述するEmbedding関数を正しく実行する際に、必要になります。
- また、keras one_hot関数で入力を要求される、引数nとは"語彙数"のことです。
- 今回、"語彙数"nは、clean_tweetの語彙(Number of unique words)の数にしました。
- 例えば、clean_tweetの語彙の数が、10万後なら、n=100000と入力します。
- この語彙数nは、Embedding関数の引数である、input_dimと同じに設定するのが通常のpracticeです。
- keras.preprocessing.text.one_hot関数についてのドキュメント:https://keras.io/ja/preprocessing/text/
-
ハッシュ化されたツイートに対して、Padding/Truncatingを施す
- Padding/Truncatingとは、簡潔にいうと、「リストの要素数を統一する」ということです。
- 例えば、「I love LSTM」と「I prefer GRU over LSTM」という、二つのツイートが、[100, 240, 600] と「100,250,900,760,600」にそれぞれ、ハッシュ化されたとします。
- これだと、要素数(Sequenceの数)が合わないので、LSTMでの学習が困難になります。
- なので、要素数を、指定した数(例えば、5つ)に揃えるために、Padding/truncatingをする必要があるのです。
- Paddingは、指定した数(e.g.5つ)に足りなければ、0で穴埋めする、というものです。I love LSTMの例で例示すると、[100, 240, 600, 0, 0] もしくは [0, 0, 100, 240, 600]になります。
- truncatingは、指定した数(e.g.3つ)を上回っていたら、余分な要素を削除する、というものです。I prefer GRU over LSTMの例で例示すると、「100,250,900」もしくは「900,760,600」になります。
- keras.preprocessing.sequecne.pad_sequences関数についてのドキュメント:https://keras.io/ja/preprocessing/sequence/
def encode_with_oneHot(text, total_vocab_freq, max_tweet_length):
# One HotエンコーディングとPadding/Truncatingを実施する
encoded_tweets_oneHot = []
for each_tweet in text:
each_encoded_tweet = one_hot(each_tweet, total_vocab_freq)
encoded_tweets_oneHot.append(each_encoded_tweet)
each_encoded_tweets_oneHot_pad = pad_sequences(encoded_tweets_oneHot, maxlen=max_tweet_length,
padding="post", truncating="post")
return each_encoded_tweets_oneHot_pad
###################################################################################################
### 綺麗にしたツイートをエンコーディングする ###
# 単語の出現回数を把握する
vocab_dict = defaultdict(int)
for each_t in df["clean_text_after_others"]:
for w in each_t.split():
vocab_dict[w] += 1
total_vocab_freq = len(vocab_dict.keys())# 総単語総数のカウント
# 文章の長さを把握する
sentence_length_dict = defaultdict(int)
for i, each_t in enumerate(df["clean_text_after_others"]):
sentence_length_dict[i] = len(each_t.split())
max_tweet_length = max(sentence_length_dict.values())# 一番長い文章のカウント
# 実行
t = time.time()
one_hot_texts = encode_with_oneHot(df["clean_text"], total_vocab_freq, max_tweet_length)
print(f'ツイートのワンホット・エンコーディングが終わりました')
print(f'コード実行時間: {round(time.time()-t)} seconds')
実行結果:ツイートが、一行一行、それぞれ適切にハッシュ化されています。
STEP3: モデリング
STEP2で、ツイートをハッシュ化(数値化=One Hotエンコーディング化)できたので、モデリングの準備が整いました。
下記に、コードの共有をします。
embedding_length = 32
model = Sequential()
model.add(Embedding(input_dim=total_vocab_freq+1, output_dim=embedding_length, input_length=max_tweet_length, mask_zero=True))
model.add(LSTM(units=32))
model.add(Dense(2,activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics = ['accuracy'])
print(model.summary())
先程"モデリングの戦略"でお示ししたように、これは古典的なLSTMのストラクチャーである、"Vanilla LSTM"です。
ただ、LSTM層の前に、Embedding layerを付けました。なぜかというと、ハッシュ化されたツイートだけでは、Semanticな意味を読み取ることができないからです。
この、Embeddingは、ハッシュ化させた単語をkeyとして、任意の次元の行列を返す関数です。この行列のそれぞれの要素には、semanticな意味が、付与されています。
つまり、どういうことか?というと、単語同士で、「王様-男+女=女王」のような演算が可能になるのです。
大事なので繰り返しますが、単語一つ一つに、行列表現(Semantic Meaning)が付与されたので、このような演算が可能になります。
これで、単語同士の関連性を、LSTMが学習できるようになりました。
Embeddingについては、@9ryuuuuuさんの記事がとてもわかりやすいので、ぜひ参考にしてみてください。https://qiita.com/9ryuuuuu/items/e4ee171079ffa4b87424
では、データの整形をして、モデルの学習を開始します。
# データの整形
y = pd.get_dummies(df["sentiment"]).values
X_train, X_test, y_train, y_test = train_test_split(one_hot_texts, y, test_size = 0.2, random_state = 123, stratify=y)
print(X_train.shape,y_train.shape)
print(X_test.shape,y_test.shape)
# 学習開始
batch_size = 256
callback = [EarlyStopping(monitor='val_loss', patience=2, verbose=1)]
hist = model.fit(X_train, y_train, epochs=5, batch_size=batch_size, callbacks=callback, verbose=1, validation_split=0.1)
# 検証データに対する精度を表示
import numpy as np
print("Validation Accuracy:",round(np.mean(hist.history['val_accuracy']), 4))
検証データに対する精度の確認
78%でした。この数値は、kaggleの他のDL実装勢と、同じくらいの精度です。

tf-idf+n-gramsをインプットに使用した、機械学習勢は、もう少し精度が劣ります。
観察の範囲だと、だいたい68~78%くらい。
なので、このモデルだと、だいたい、偏差値55~60くらいの成績です。(推測)
【参考:https://www.kaggle.com/kazanova/sentiment140/notebooks】
ここから、モデルのアーキテクチャーは変更せずに、前処理だけをアップデートして、再度実装を試みます。
改善点は、大きく二つありました。
改善点1
改善点の一つ目は、「Stop Words」の扱いです。
Stop Wordsとは、例えば、「not」「no」「up」などの単語のことで、自然言語処理の世界では、慣例的に消去されることが多い、単語群のことです。
ただ、下記の例のように、"no"を削除した結果、ツイートの意味が大きく異なってしまう、という現象が発生してしまったので、stop wordsの削除を行わない、前処理に変更しました。

改善点2
二つ目の改善点は、「ツイートの単語数」についてです。
前処理後に、ツイートが、「play」だけになってしまった、みたいな一単語のみのツイートが存在するので、そのようなデータは削除しました。
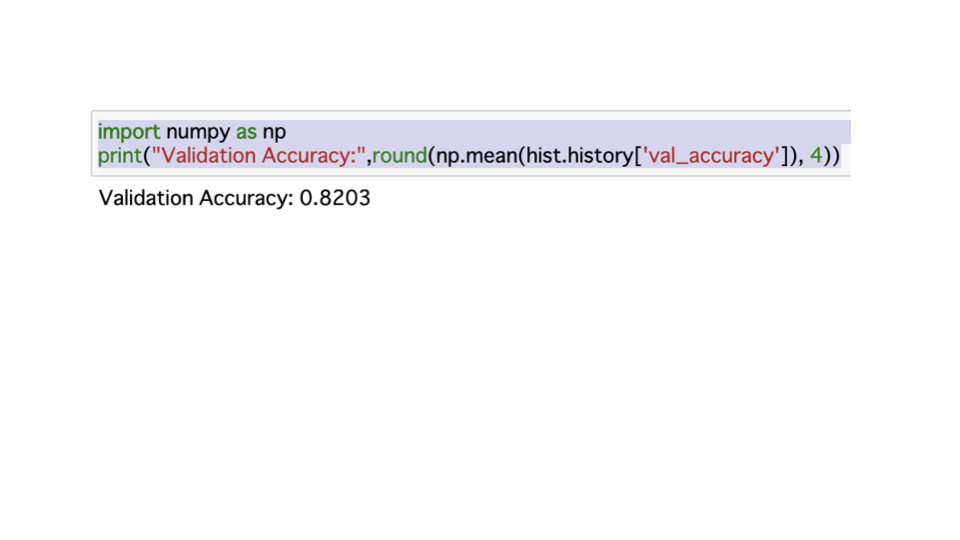
改善後の結果
精度、上がりました。検証データに対して、82%の結果です。
これは、DL実装上位勢くらいの結果(偏差値60~65くらい?)なので、嬉しいです。
今後の方針
ブロンズマスターやグランドマスターレベルになると、88~92%くらいの成績を叩き出しているので、
まだまだ、私にも、改善余地があります。グランドマスターの方は、CNN+LSTMで実装している方が多いなぁと思いました。
ただ、自分は、このタスクでは、前処理を徹底的にする方針で、十分精度が9割に到達すると思っています。
なぜなら、まだまだ、前処理で改善しなければいけない箇所がたくさんあるからです。
例えば、下記のような前処理です。

でもこれ、実は結構難しんですよね。
ツイート一つ一つに対して、英語か?の判定をしないといけないのですが、判定してくれるライブラリの精度が、すこぶる悪くて、使い物にならないのです。
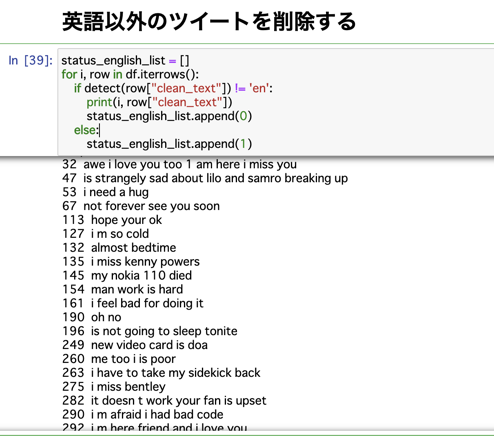
これ、出力されているのが、langdetect.detect関数で、「英語ではない」と判定された文章なのですが、明らかに英語である文章が含まれています。
なので、automationが難しく、この前処理に関して、どうすればいいか?保留中です。
kagglerもこの点が難しいと感じてるのか、(私の観察の範囲では)誰もこの前処理をやってないです。
なので、引き続き、検証を続けて、記事をアップデートできればいいなぁと思っております。
ここまで、見ていただき、ありがとうございました。