モチベーション
2019年10月にSAS Japanさんから、"SAS Analytics Experience @ Milano"というカンファレンスに招待して頂き、Dr.Terisaさんという方から、Credit Score(信用スコア)についての講演を拝聴しました。

[2019年10月 SAS Analytics Experience @ Milanoに行った時の写真]
その公演では、大きく下記の3つのトピックについて、共有して頂き、仕組みはシンプルだが、大きなビジネスインパクトがあることを学びました。
- 信用スコアとはそもそも何なのか?
- 現在、主流で、最先端のアルゴリズムは? (機械学習, 深層学習, 強化学習を用いたもの)
- 信用スコアは「ローン貸付の与信の判断」以外だと、どんな場面で活用できそうか?
実務で信用スコアの作成に携わったないが、その技術的な背景は、とても直感的で理解しやすいものだったので、本記事にまとめておこうと思います。
ただ講演で、共有して頂いた手法そのものの解説は、Confidentialityの関係で、共有はできないので、簡易版というか、Dr.Terisaに勧めてもらった本に書いてある手法を代わりに解説します。
【参考:https://www.wiley.com/en-us/Credit+Risk+Scorecards%3A+Developing+and+Implementing+Intelligent+Credit+Scoring-p-9781119201731 】
この本に書いてある手法も、Dr.Terisaさんが、公演で解説してくれた(最先端の)手法と大きくは違わないし、欧米の多くの会社/スタートアップも、この本に書いてある手法を参考にしてるみたいなので、信用に値する手法だと言えるでしょう。
信用スコアとは何か?をまず整理する。
信用スコアとは、ある人がお金を借りたい!って思った時に、
その人が信用できるか?(返済の能力があるか?)を数値化したものです。
社会的信用の数値化・可視化ってことですね。
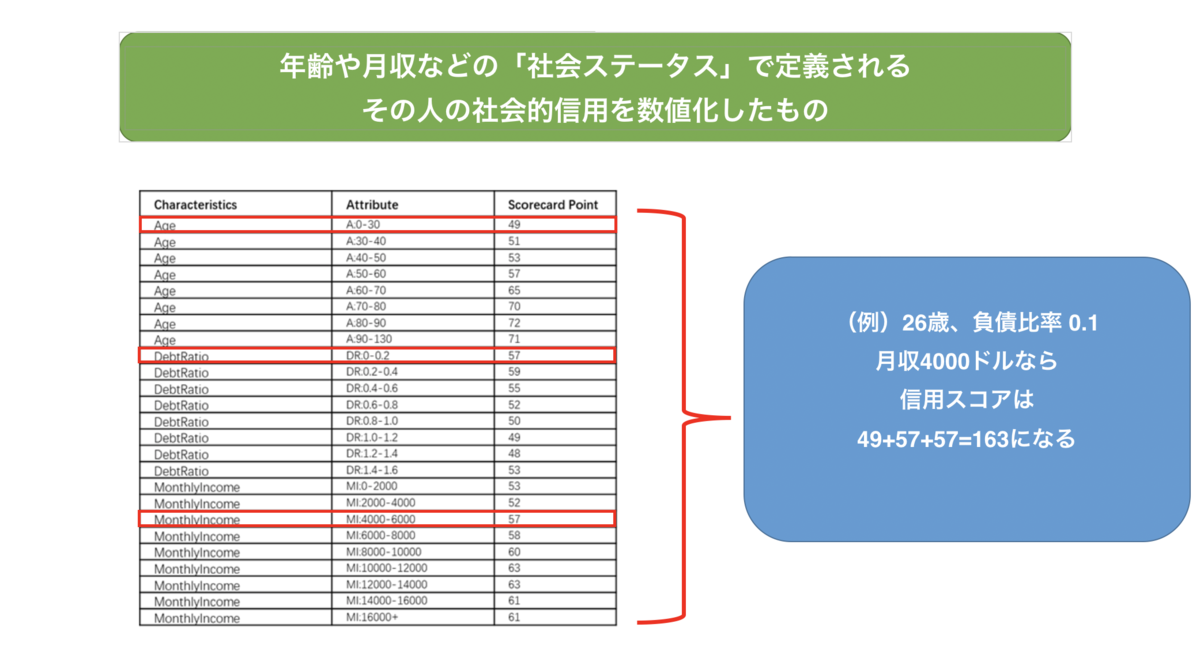
上記の図にある、ScoreCard Pointが、貴方の信用スコアを形成する数字になってます。
このScoreCard Pointを作成するために、Pythonで色々カキカキしていくことになります。
一見、難しそうなんだけど、やり方は非常にシンプルです。
下記の3ステップだけで、信用スコア作成できます。
- 信用スコア作成に使用するコラムの階層化(ビニング)
- 各コラムの各階層における、WoEの計算
- 各コラムの各階層における、ScoreCard Pointの計算
では、各ステップの中身を詳しく観ていきましょう!
信用スコア作成のために使用する、データセットの概要説明
世界中の学生や実務家が、その実力を競い合っている、Kaggleというオンラインデータ分析コンペのサイトから、”Give Me Some Credit”というデータセットが、共有されているので、そちらのデータを使用します。
これは、2011年にコンペで使用されていたものです。下記、データの概要を、表で共有します。
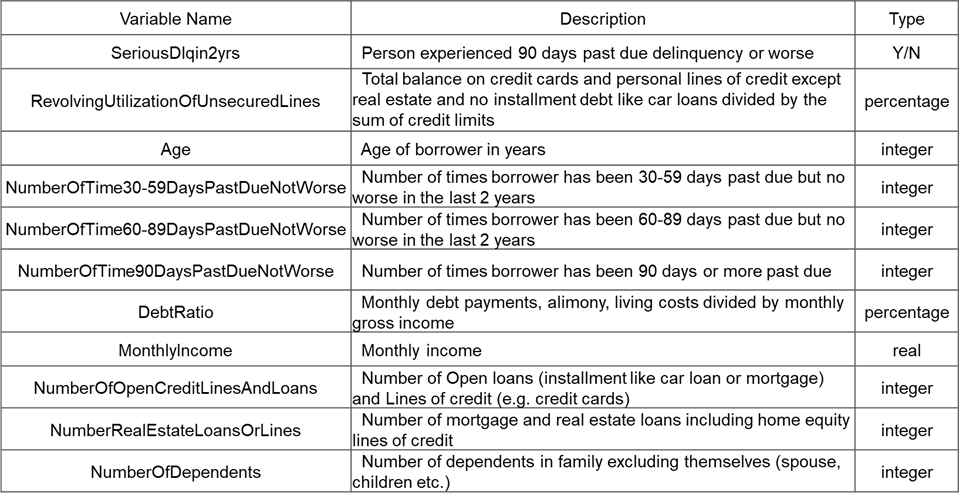
【データセットは、こちらから】https://www.kaggle.com/brycecf/give-me-some-credit-dataset
このデータセットを用いて、”SeriousDlpin2yrs”を、ターゲット変数(被説明変数)とした、ロジスティック回帰モデルを作成し、説明変数に付与された係数を、信用スコアの計算に用います。(後で、もっと詳しく解説します)
大事なポイントは、「信用スコアを、AIの学習によって作り出す」ってことなので、
当然必要なデータセットは、返済できたかどうか?/返済を遅延かどうか?
の情報が含まれているデータセットが必要です。
STEP1と2の解説と実装
ステップ1と2は、信用スコアを作る上での、前処理みたいな位置づけです。
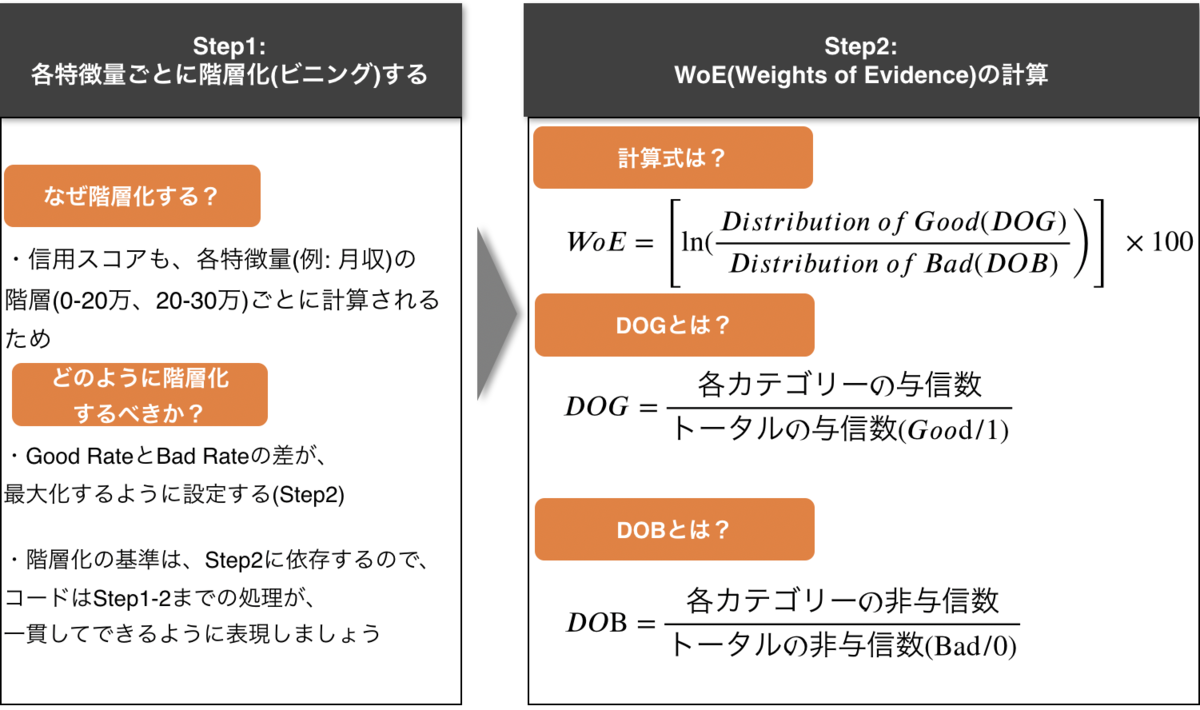
STEP1から、詳しく見ていく
ここの作業は、結構、大変(泥臭い)です。
信用スコア作成に使用する、特徴量(例えば、月収)を、階層化(ビニング)しないといけないんです。
10-20万、20-30万みたいに。
**なぜ階層化しなければいけないのか?**と言うと、
上記の「信用スコアとは、何か?をまず整理する」で解説したように、
信用スコアって、月収が10-20万の人は50点!、20-30万の人は55点!みたいに計算されますよね。それって、データを準備する側に視点で考えると、「特徴量を階層化する」っていう前処理をしてるってことなんです。
**「じゃあ、どう階層化すればいいの?」**っていう疑問が出てくると思います。
Step2で後述しますが、
アカデミックな世界だと、階層化の基準は「DOGとDOBの差が最大化するように設定する」って言われてます。【参考:https://www.wiley.com/en-us/Credit+Risk+Scorecards%3A+Developing+and+Implementing+Intelligent+Credit+Scoring-p-9781119201731 】
ただ、信用スコア作成の実務家の方々の多くは、**「Try and Error」**で判断しているそうです。Dr.Terisaさんが、そう仰っていました。
Try and Errorで判断すると言うのは、
**「一旦、階層を自分で指定してみて、信用スコアを出し、ドメインと常識に照らし合わせて、その信用スコアがMake Senseかどうか?を判断する」**って言うことです。
自分なら、「DOGとDOBの差が最大化するような、最適化問題で定式化する」としたいのですが、このTry and Errorの方法論というのは、結構納得がいきます。
なぜなら、信用スコア作成の実務の世界でご活躍されている方々は、階層化の感覚が秀でていると思うからです。収入や年齢をどこのラインで区切ればいいのか?などは、彼/彼女等の経験から、信用スコア作成が上手くいく感覚値が、きっとあると思います。
私は、その感覚値がまだないのですが、Try and Errorでやりました。とりあえず、信用スコア作成の実務家のWorkflowを実感したかったので。
次は、Step2を、詳しく見ていく
Step2を理解するためには、下記の二つの概念を理解する必要があります。
1. WoE(Weight of Evidence)とは?
- 「Good CustomerとBad Customer、どっちを予測するのに役立つの?」を知らせる指標
この定義で出てくる、
Good Customerとは、「過去に、借入の返済の遅延、債務不履行になったことが”ない”人」を指し、Bad Customerとは、「過去に、借入の返済を遅延した人、債務不履行になったことが”ある”人」を指します。
プラスの値は、Good Customerの予測に役立ち、マイナスの値は、Bad Customerの予測に役立ちます。下記に、実際に計算したWoEのイメージをご覧いただくと、より理解できます。

DebtRatio(負債比率)は、あなたが持っている資産に対して、どのくらい負債・借金があるのか?を示す指標です。(DP = 負債/資産)
上記の図をご覧いただくと、DeptRatioが高くなればなるほど、WoEの値が小さくなってますよね。つまり、**「資産に対して、負債が大きなっている人ほど、債務不履行になっている」**というメッセージが読み取れます。これは、直感的で、わかりやすいと思います。
2. DOG/DOBとは?
上記のStep1&2の説明のスライドをもう一回見て見ましょう。Step2のDOGとDOBの計算式に注目してください。
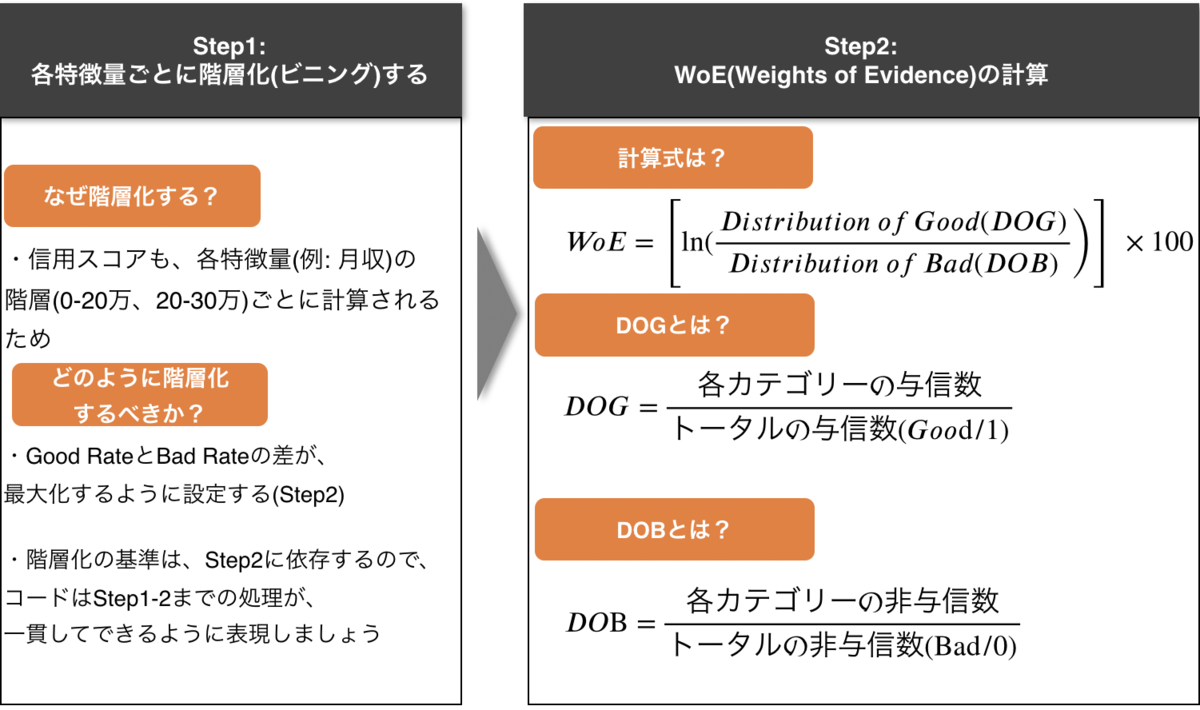
ここの式にある、「各カテゴリーの与信数/非与信数」というのは、例えば、「月収20-30万円のカテゴリーで何人がGood/Bad Customerなのか?」を示します。
「トータルの与信数/非与信数」は、「データセット全体で、何人がGood/Bad Customerなのか?」を示します。
今回使用しているデータセットのコラムでいうと、"SeriousDlqin2yrs"= 0/1であるときの数です。
言葉だけでイメージするの難しいと思うので、下記の図もご覧ください。
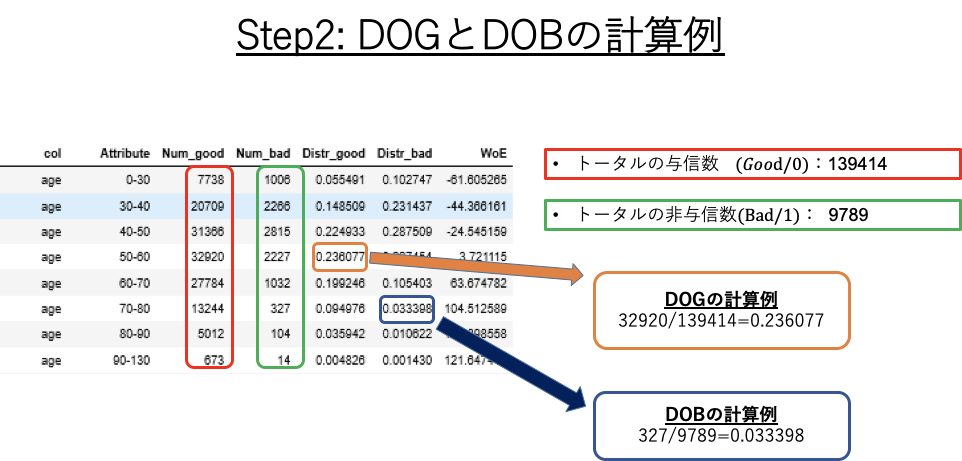
どうです? 理解できました?
もし、わかりずらい箇所があったら、遠慮なく質問してくださいね:)
最後に、Step1-2までの実装方法(python)を下記に共有します。
# binningを定義する
def binning(col, list_bins_func):
binned_df_list = []
for each in list_bins_func:
binned_df_list.append(df[(df[col]>=each[0])&(df[col]<each[1])])
return binned_df_list
# BinningとWoEの計算を実行する関数を定義する
def calc_woe_runner(col, list_bins):
#実際にbinningを実行する
list_binned_df = binning(col, list_bins)
each_num = np.zeros(len(list_binned_df))
dist_good = np.zeros(len(list_binned_df))
dist_bad = np.zeros(len(list_binned_df))
good_number = np.zeros(len(list_binned_df))
bad_number = np.zeros(len(list_binned_df))
# DOGとDOBを計算する
for i, each in enumerate(list_binned_df):
each_num[i] = len(each)
good_number[i] = len(each[each["SeriousDlqin2yrs"] == 0])
bad_number[i] = len(each[each["SeriousDlqin2yrs"] == 1])
dist_good = good_number/good_number.sum()
dist_bad = bad_number/bad_number.sum()
dist_total = (good_number + bad_number)/len(df)
# WOE(Weight of Evidence)を計算する
woe = np.log(dist_good/dist_bad)*100
return col,woe,dist_total, good_number.sum(), good_number, bad_number.sum(),bad_number, dist_good, dist_bad
# 上記を実行する
# binning関数で使われる変数の定義
col_list = ["age", "DebtRatio", 'MonthlyIncome']
age_bin_list = [[0,30], [30,40], [40,50],
[50,60], [60,70], [70,80],
[80,90], [90,130]]
deptRatio_bin_list = [[0,0.2], [0.2,0.4], [0.4,0.6],
[0.6,0.8], [0.8,1.0], [1.0,1.2],
[1.2,1.4], [1.4,1.6]]
monthlyIncome_bin_list = [[0,2000], [2000,4000], [4000,6000],
[6000,8000], [8000,10000], [10000,12000],
[12000,14000], [14000,160000]]
list_combined = [age_bin_list, deptRatio_bin_list, monthlyIncome_bin_list]
# Actually calculate woe
col_list_for_df = []
woe_list_for_df = []
iv_list_for_df = []
df_woe_list = []
good_list_sum = []
good_list_each = []
bad_list_sum = []
bad_list_each = []
dist_good_list = []
dist_bad_list = []
total_dist_list = []
df_woe_concat = pd.DataFrame()
i = 0
for col, each_bin_for_col in zip(col_list,list_combined):
col_list_for_df, woe_list_for_df, total_dist_list, good_list_sum, good_list_each, bad_list_sum, bad_list_each, dist_good_list, dist_bad_list = calc_woe_runner(col, each_bin_for_col)
col_df = pd.DataFrame(data=[col_list_for_df]*len(list_combined[0]), columns=["col"])
woe_list_for_df = pd.DataFrame(data=woe_list_for_df, columns=["WoE"])
good_list_df = pd.DataFrame(data=good_list_each, columns=["Num_good"], dtype=int)
bad_list_df = pd.DataFrame(data=bad_list_each, columns=["Num_bad"], dtype=int)
dist_good_df = pd.DataFrame(data=dist_good_list, columns=["Distr_good"])
dist_bad_df = pd.DataFrame(data=dist_bad_list, columns=["Distr_bad"])
total_dist_df = pd.DataFrame(data=total_dist_list, columns=["Distr_total"])
l = []
for e in np.array(list_combined[i]):
l.append(str(e[0]) + "-" + str(e[1]))
bin_value_df = pd.DataFrame(data=l, columns=["Attribute"])
df_woe_concat = pd.concat([col_df, bin_value_df,good_list_df,
bad_list_df,dist_good_df, dist_bad_df,
woe_list_for_df, total_dist_df], axis=1)
df_woe_list.append(df_woe_concat)
i += 1
df_woe = pd.concat(df_woe_list, axis=0)
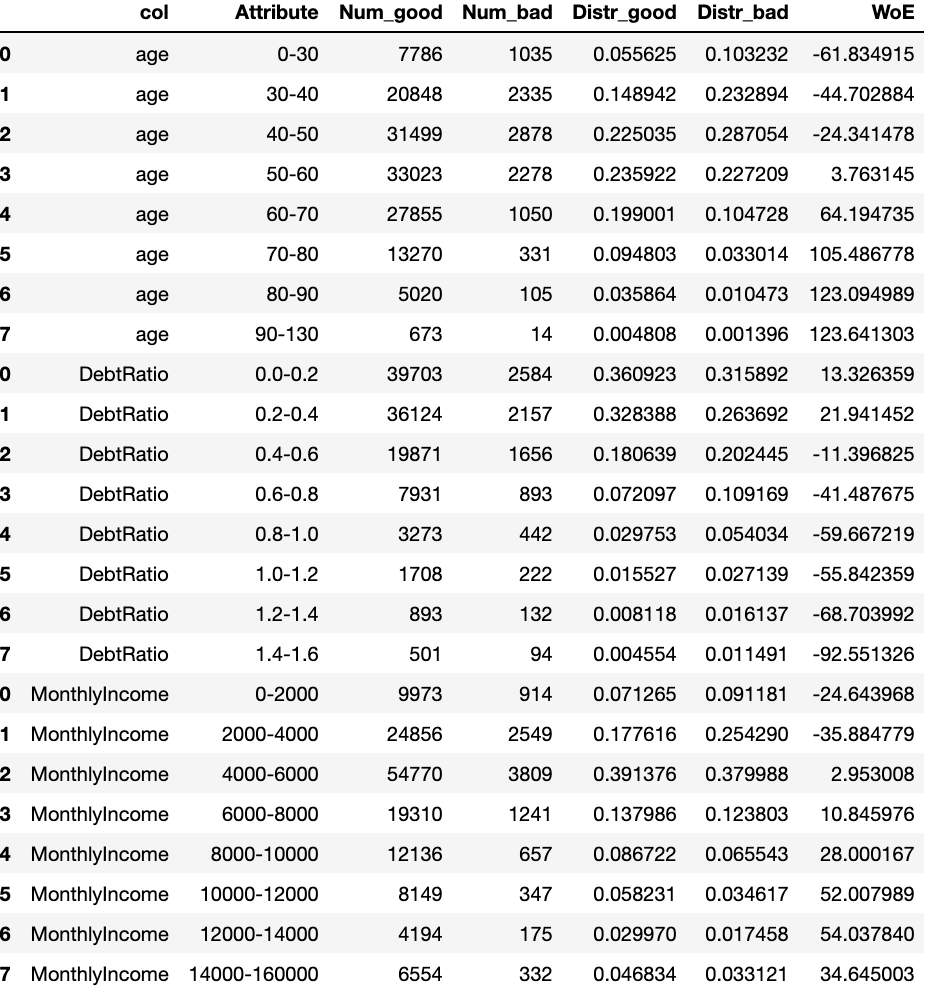
上記のコードを実行すると、下記のようなOutputが出てくるはずです。
ステップ3の解説と実装
Step3では、実際に信用スコア(Scorecard Point)の計算をします。
計算式は、下記の通り。
Scorecard Point = (β×WoE+ α/n)×Factor + Offset/n
ここで出てくる、下記の項(Terms)は、すでに計算不要です。
- WoEは、Step2で計算済み。
- Factorは、Scaling Factorなので、定数。
- Offsetは、Scaling Factorなので、定数。
- nは、SeriousDlqin2yrsの予測に使う特徴量の数なので、定数。
なので、計算するべき項は、βとαだけになります。
このβとαは、ロジスティック回帰でモデリングした後、算出されます。
つまり、今回使用しているデータセットを例にすると、
- "SeriousDlqin2yrs" をターゲット変数として、ロジスティック回帰でモデリング
- モデリング後に、Scorecard Pointで使用する変数(今回は、age, DebtRatio, Monthly Income)の係数と切片項をそれぞれ取得
- その係数が、βになり、その切片項が、αになる
つまり、ステップ3は、ロジスティック回帰でモデリングをする、という作業のみになり、モデリング後に係数と切片をそれぞれ取得すれば良いということになります。
最後にStep3の実装方法を、下記に共有します。
# ロジスティック回帰モデルを学習させる
lr = LogisticRegression()
lr.fit(X_train, y_train)
print("AUC:{}".format(roc_auc_score(lr.predict(X_test), y_test)))
# 実際に信用スコアを算出する: Score = (β×WoE+ α/n)×Factor + Offset/n
df_woe_with_score = df_woe.reset_index().copy()
df_woe_with_score.iloc[:, 3:-1] = df_woe_with_score.iloc[:, 3:-1].astype(float)
# Scaling factorを定義する
n = len(default_features_list)
alpha = lr.intercept_[0]
beta_age = lr.coef_[0][0] # Ageコラムの係数
beta_dept = lr.coef_[0][1] # DebtRationの係数
beta_income = lr.coef_[0][2] # MonthlyIncomeの係数
# Scorecard Pointの合計の最大値を600にするためのスケーリング
factor = 20/np.log(2)
offset = 600-factor*np.log(20)
print("factor:{0}, offset:{1}".format(factor, offset))
# Scorecard Pointの計算
df_woe_with_score["score"] = None
score_list = []
for i in range(len(df_woe)):
woe = df_woe_with_score["WoE"].iloc[i]
if df_woe_with_score.iloc[i]["col"] == "age":
score = (beta_age*woe+(alpha/n))*factor + (offset/n)
df_woe_with_score["score"].iloc[i] = round(score, 1)
elif df_woe_with_score.iloc[i]["col"] == "DebtRatio":
coef = beta_dept.copy()
score = (beta_dept*woe+(alpha/n))*factor + (offset/n)
df_woe_with_score["score"].iloc[i] = round(score, 1)
elif df_woe_with_score.iloc[i]["col"] == "MonthlyIncome":
coef = beta_income.copy()
score = (beta_income*woe+(alpha/n))*factor + (offset/n)
df_woe_with_score["score"].iloc[i] = round(score,1)
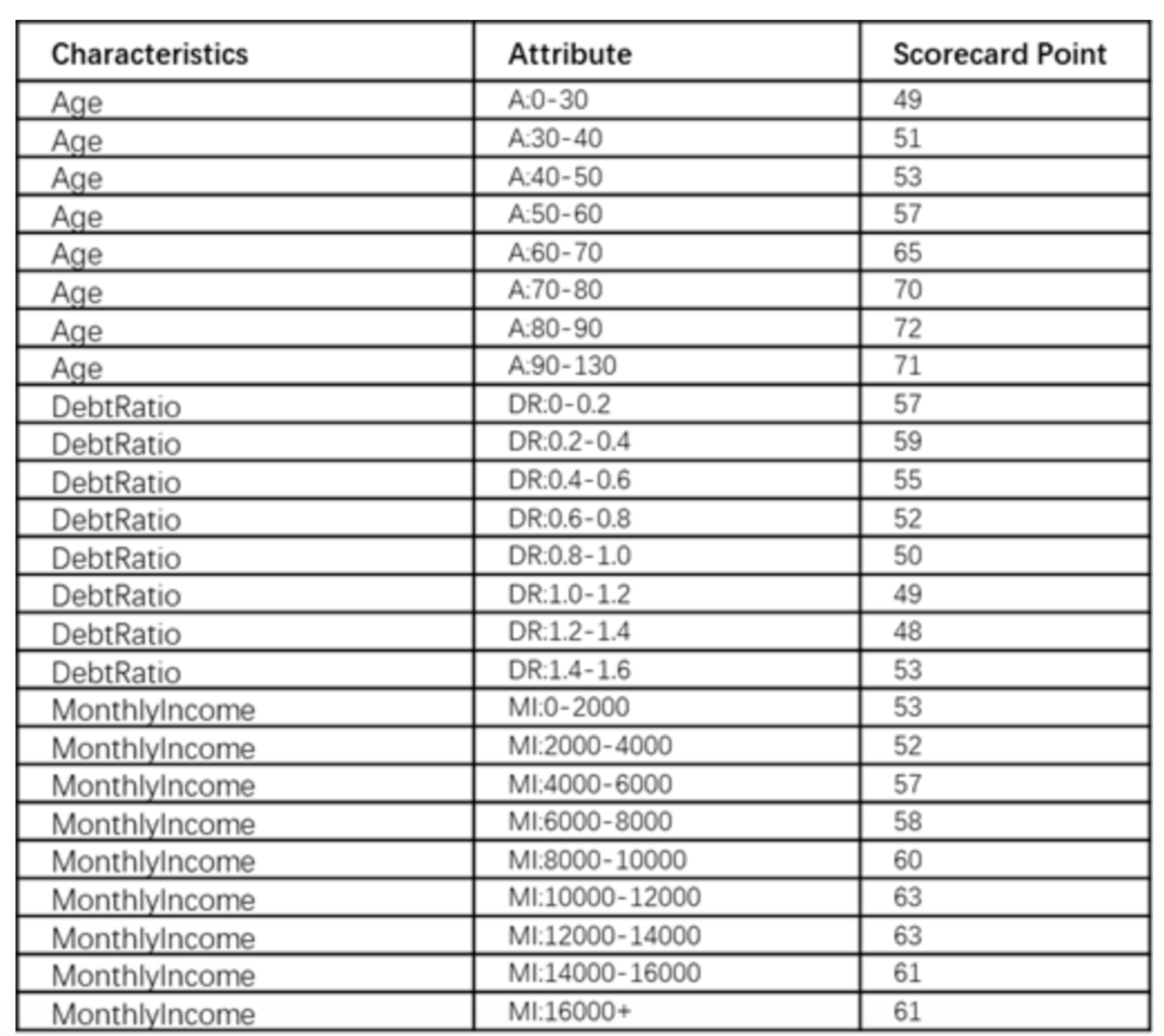
そして、無事、信用スコア作成できました!
ここまで、読んで頂きありがとうございました。