もはやクリスマスが終わってしまいましたが、Advent Calendarの24日目です。
直前に書き始めた+文量があるので、読みにくい箇所があったらすいません!(何部作かに分けるべきだったか、、)
0. はじめに
この記事では、「Lambdaで確実に動くコンパイル済みライブラリが欲しいなら、Lambda自身に作らせてしまえばいいのでは?」というアイデアから始まり、AWS LambdaとAPI Gateway、S3を使ってLambda Layer用のPythonライブラリをLambda自身が生成してくれるAPIを作って素晴らしく快適なLambda生活が送れるようになったライフハック(?)を紹介します。
- M1 Macなどarm64アーキテクチャの上のDockerではx86_64用のLayerが作れない(逆も然り)
- 複数のライブラリを1つのLayerにまとめて、Layerの数を抑えたい
- 最新だけでなく、任意のバージョンのライブラリを使いたい
- Klayersでは、自動で旧バージョンのレイヤーが削除されて使えなくなってしまうため、Layerを自己管理下に置きたい
- 宗教上の理由でLambdaをSAMで管理していない
そんなあなたはぜひこのAPIを作ることをお勧めします!
もしくは、ニーズがあれば人数限定で自社内用に構築したAPIを叩けるAPI Keyを発行するので、最後に載せるGoogleフォームを入力してください!(流石にお金がかかるので、全員にとは言えないですが、、)
上記に当てはまる人以外でも、
- Layerを作ればいいのはわかったけど、作り方がわからない
- zipするときにディレクトリ構成をよく間違えて
Unable to import moduleが起きる - ローカル環境(Docker含む)で手作業で作るのが面倒くさい
という人にも参考になると思うので、ぜひ読んでいってください!!
1. 構築するAPIについて
Lambda上で使いたい外部ライブラリを、使用するランタイムに合わせたPythonバージョンとアーキテクチャとともにAPIのURL中で指定すると、自動でコンパイルしてDeploy Readyなzipファイルを生成し、それを保存したS3のURLを出力するAPIを作ります。
Layer作成時に、zipファイルの代わりにAPIが出力したS3 URLを指定することで、Layerを作成することができます。
[入出力イメージ]
$ curl -X GET https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prd/x86_64/py39/scipy==1.7.3&requests==2.26.0
> https://xxxxxxxx.s3.ap-northeast-1.amazonaws.com/xxxxxxxx/python.zip
1.1 求める機能
- 任意のアーキテクチャ、Pythonバージョンで作成できる
- 複数ライブラリを1つのzipにまとめることができる
- ライブラリのバージョン指定ができる
- S3のURL発行し、そのURLで直接Layerを作成できる
- GETリクエストで実装し、ブラウザ上から直接URLを入力してAPIリクエストできる
- 依存関係にあるライブラリは含まないでzipするオプションが選べる
1.2 AWSサービスの構成
- S3
- 生成したzipファイルをキャッシュするストレージ
- Lambda
- APIリクエストを受け取り、S3の保存先URLの発行とコンパイル用Lambdaを非同期で実行する関数
- 指定したライブラリをコンパイルし、zipしてS3にアップロードする関数
- API Gateway
- ユーザーからのリクエストを受け取ってLambdaに転送するAPI
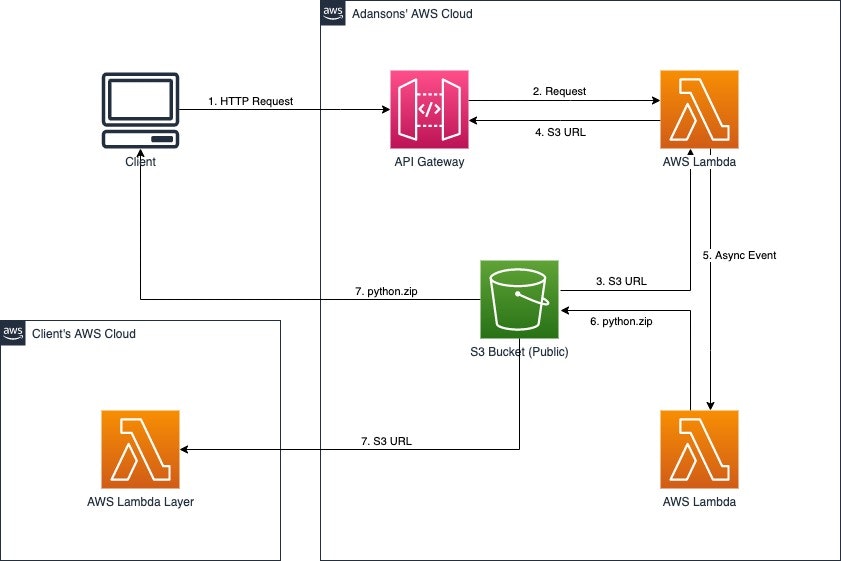
1.3 個人的に既存手法で生じていた課題(開発の背景)
- AWS公式のLayer
- 使いたいライブラリが用意されていない
- Klayers
- Python3.9に対応していない
- 使いたいライブラリが用意されていない
- 基本的に単一のライブラリに対してLayerが用意されているため、使いたいLayerの数がアタッチ上限数(5個)を超える
- 定期更新により旧バージョンのLayerが自動で削除されるため、突然Lambdaが動作しなくなる
- SAM(AWS Serverless Application Model)
- Terraform+lambrollで運用しているため、SAMを使えない(使いたくない)
- Docker or ローカル環境
- M1 Mac(arm64)をメインに使用しているため、x86_64用にコンパイルできない
- pipでインストールしたファイルリソースをzipする際に、たまにディレクトリ構成をミスして
Unable to import moduleが起きる
(参考)
- Klayers | Github
- レイヤーの構築 | AWS Serverless Application Model Document
- AWS SAM CLIでLambda Layersがビルドできるようになったよ | Qiita
- DockerでAWS LambdaのPython用Layerを作成する | Qiita
2. 実装解説(コンソール版)
ここでは、AWSのコンソール画面上で構築する際の解説をします。
実はTerraformで構築しているので、もしニーズがあればそのTerraformコードもGithubで公開します。
こちらも最後に載せるGoogleフォームから応募してください!
2.1 キャッシュ用のS3バケットを整備する
やることは以下の3つです。
- S3バケットを作る
- S3にアップロードされたファイルの自動削除設定をする
- LambdaからS3にアップロードするための権限を付与したIAMポリシーを作る
S3はファイルを保存しているだけでも、その時間分料金がかかってしまうので、アップロードされたzipファイルを自動で削除するためのライフサイクルルールの設定をします。
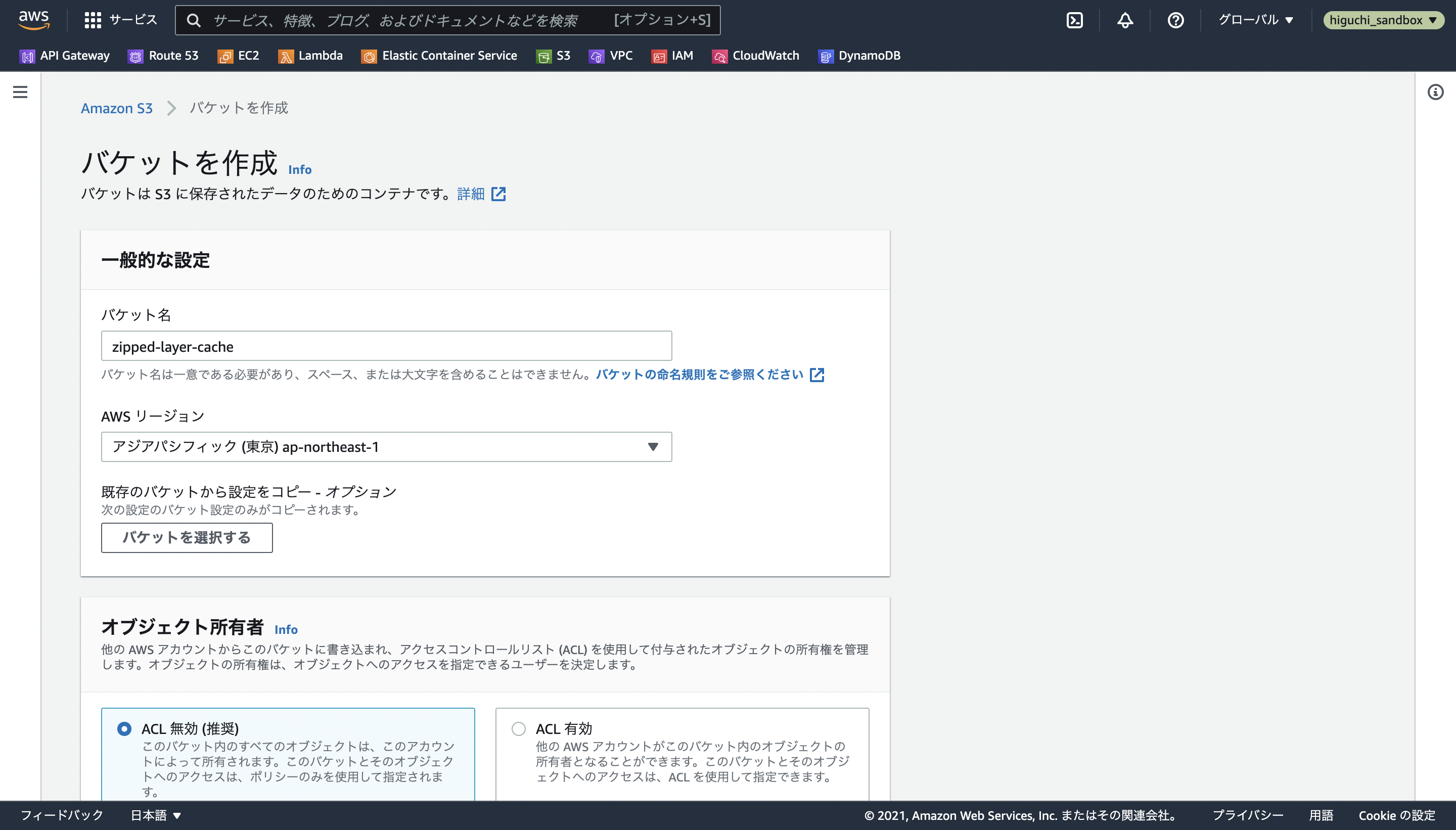
2.1.1 バケットの作成
S3のサービス画面を開き、バケットを作成を選択します。
バケット名とAWSリージョンを指定し、オブジェクト所有者の設定はデフォルトのACL 無効を選択します。
注意
S3のバケット名は、AWS全体(世界中)でユニークな値を指定する必要があります。
本記事ではzipped-layer-cacheをバケット名に使用していますが、同じ名前を使用することができないため、この記事を参考にAPIを構築する際は以降の文章中のzipped-layer-cacheを各自のS3バケット名に差し替えてください。
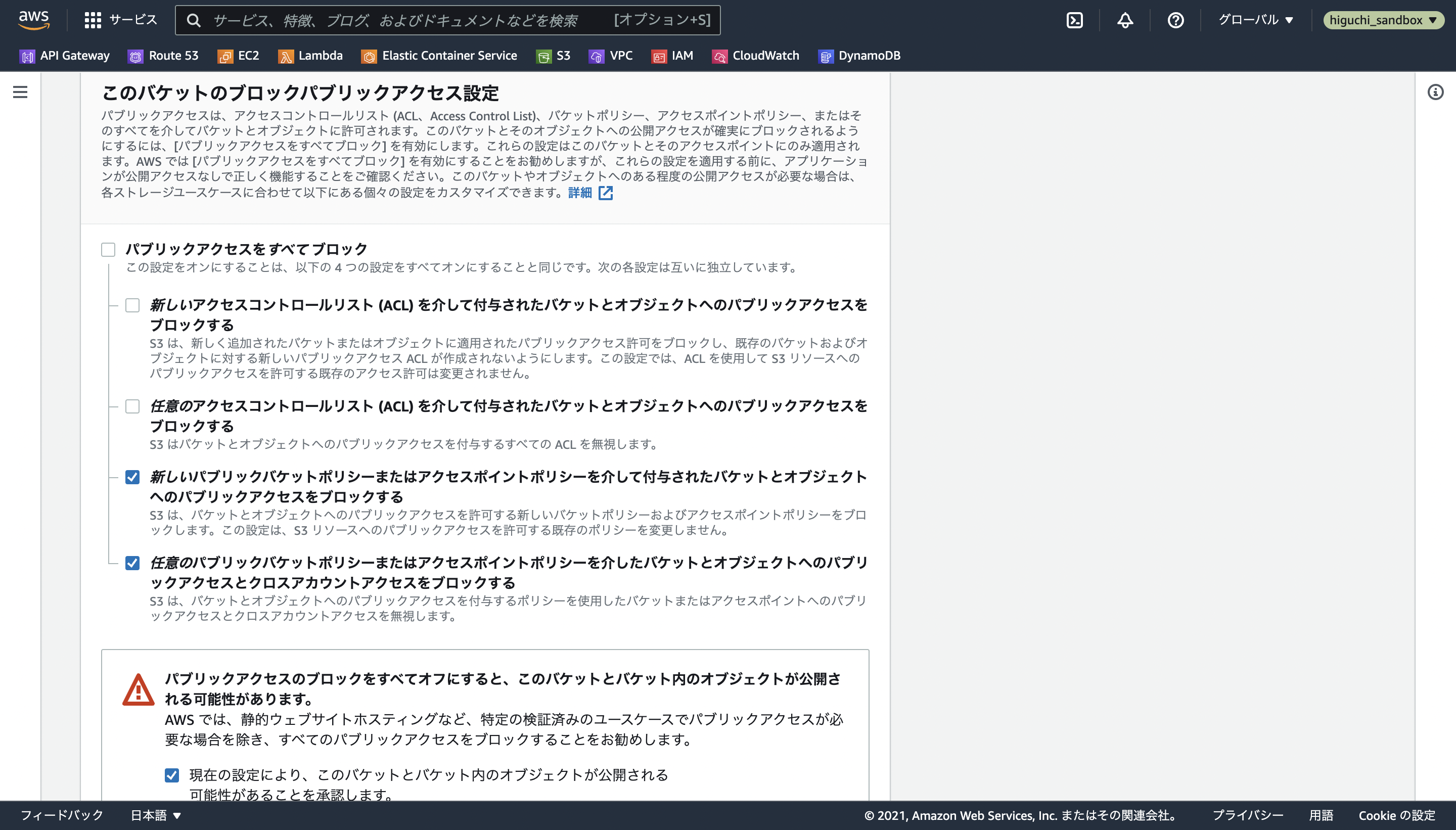
続いてこのバケットのブロックパブリックアクセス設定ですが、その名前の通り、これから作るバケットやその中のファイルオブジェクトに対する他者からのアクセス許可設定のことを意味します。
この説明文が非常に理解しにくいのですが、そこの解説はMasutaniYoshihiroさんの記事に任せて、今回は以下の設定にします。
- 新しいコントロールリスト(ACL)を介して...アクセスをブロックする
- 任意のコントロールリスト(ACL)を介して...アクセスをブロックする
- 新しいパブリックバケットポリシーまたは...アクセスをブロックする
- 任意のパブリックバケットポリシーまたは...アクセスをブロックする
要は、今後ACLで公開可能なオブジェクトを作れるようなアクセス許可設定にしています。
これは、生成したzipファイルをS3にアップロードする際に、ACLで公開可能オブジェクトとしてアップロードすることで、S3のバケットがあるAWSアカウント以外でもAPIが発行したS3 URLから直接Lambda Layerを作成できるようにするためです。
もし他のAWSアカウント上でLayerを作成する予定がない場合は、パブリックアクセスをすべてブロックしても問題ありません。
最後に、パブリックアクセスのブロックをオフにした場合にオブジェクトが公開されうることを承認すれば、ブロックパブリックアクセス設定は完了です。
その他の設定について、バケットのバージョニングは、今回のS3バケットはキャッシュするためだけに使うので、無効にするを選択し、暗号化については好みですが、有効にするに設定します。(無効でも問題ないです)
2.1.2 ライフサイクルルールの設定
今回は、Layerを作るためのzipファイルを一時保管するためにS3を使用するので、過去の生成物が蓄積してAWSからとんでもない額を請求されないようにするために、アップロードから1日でファイルオブジェクトを削除するルールを設定します。
バケットを作成したのちに、設定画面の管理から、ライフサイクルルールの追加を選択します。
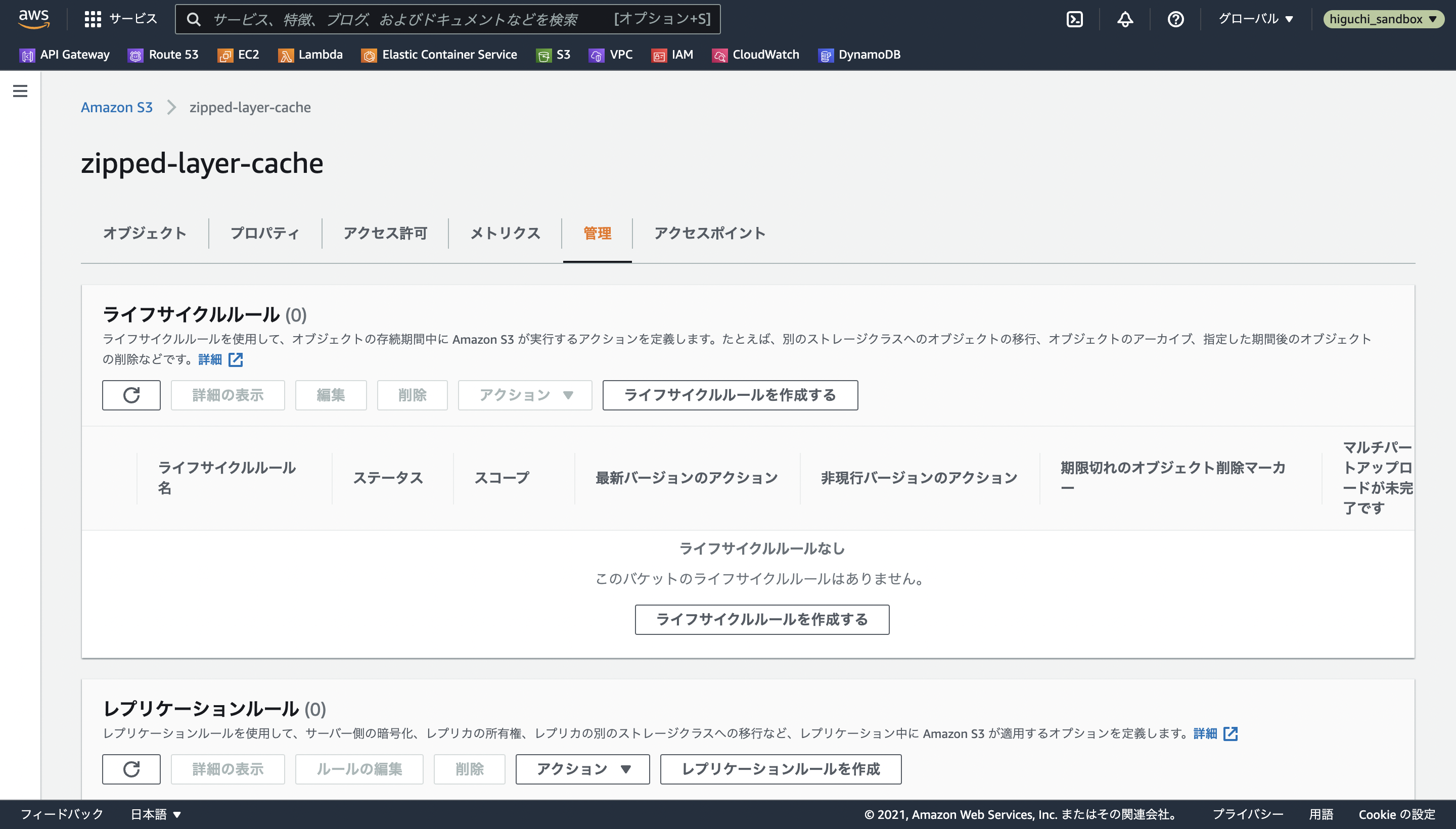
ルールの内容がわかるような名前を設定し、そのルールの適用範囲がバケット内のすべてのファイルオブジェクトになるように設定します。
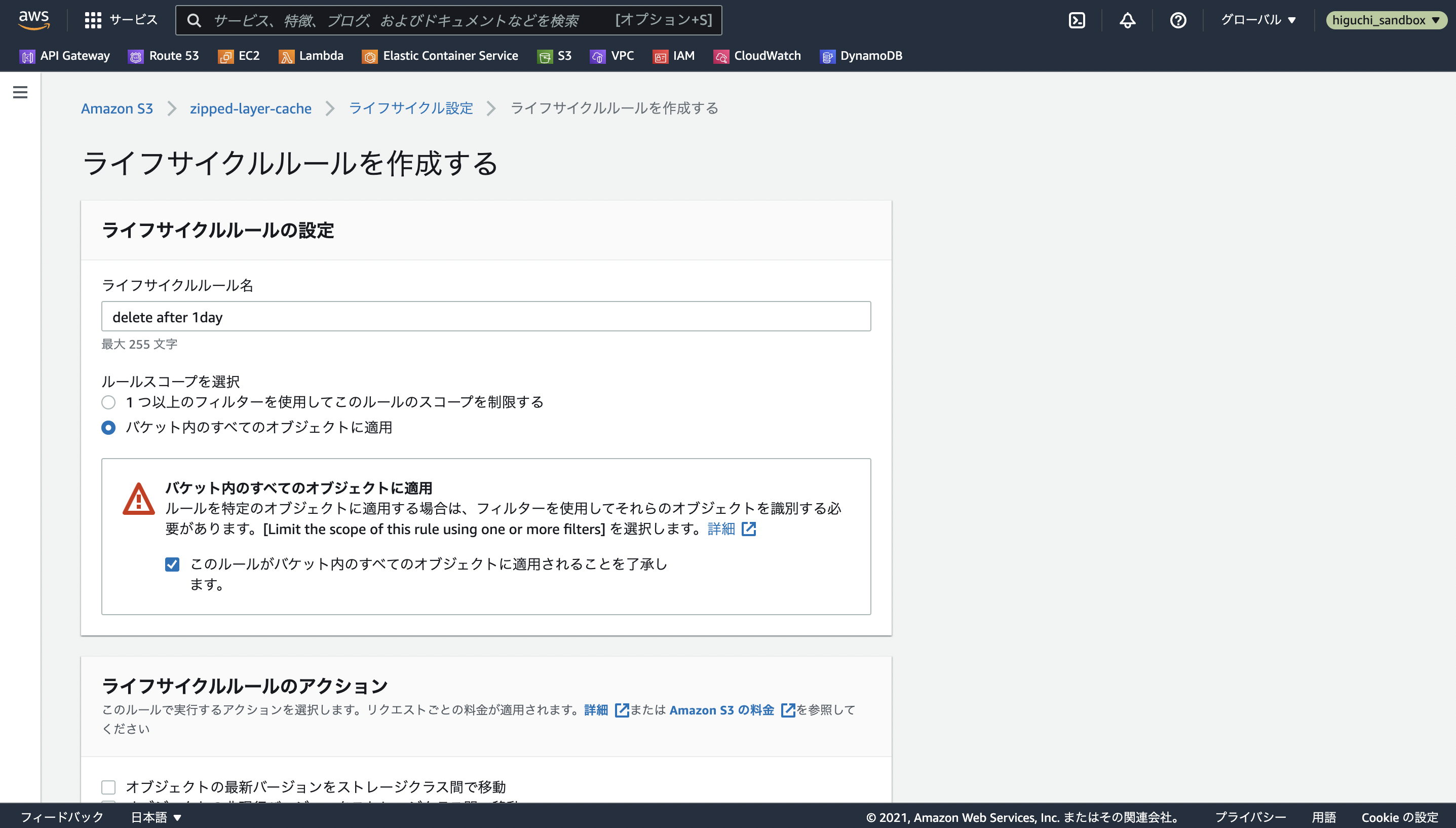
S3のオブジェクトの削除には、段階が2つあり、まずファイルが現行バージョンから非現行バージョンに移管されたあとに非現行バージョンを削除する必要があります。
例えるなら、まずFinder上でファイルをゴミ箱に入れてからゴミ箱内を削除するようなものです。
ただし、S3のバケット自体の設定で、バージョニングをオンにしていない場合は、そもそも非現行バージョンを保持する機能(ゴミ箱機能)がないため、現行バージョンでなくなった瞬間に削除されることになります。
ライフサイクルルールでは、バケットにアップロードされた現行バージョンのオブジェクトを自動で非現行バージョンに移管するための有効期限を設定することができるので、今回はライフサイクルルールのアクションでオブジェクトの現行バージョンを有効期限切れにするを選択し、その日数を最小の1日に設定します。
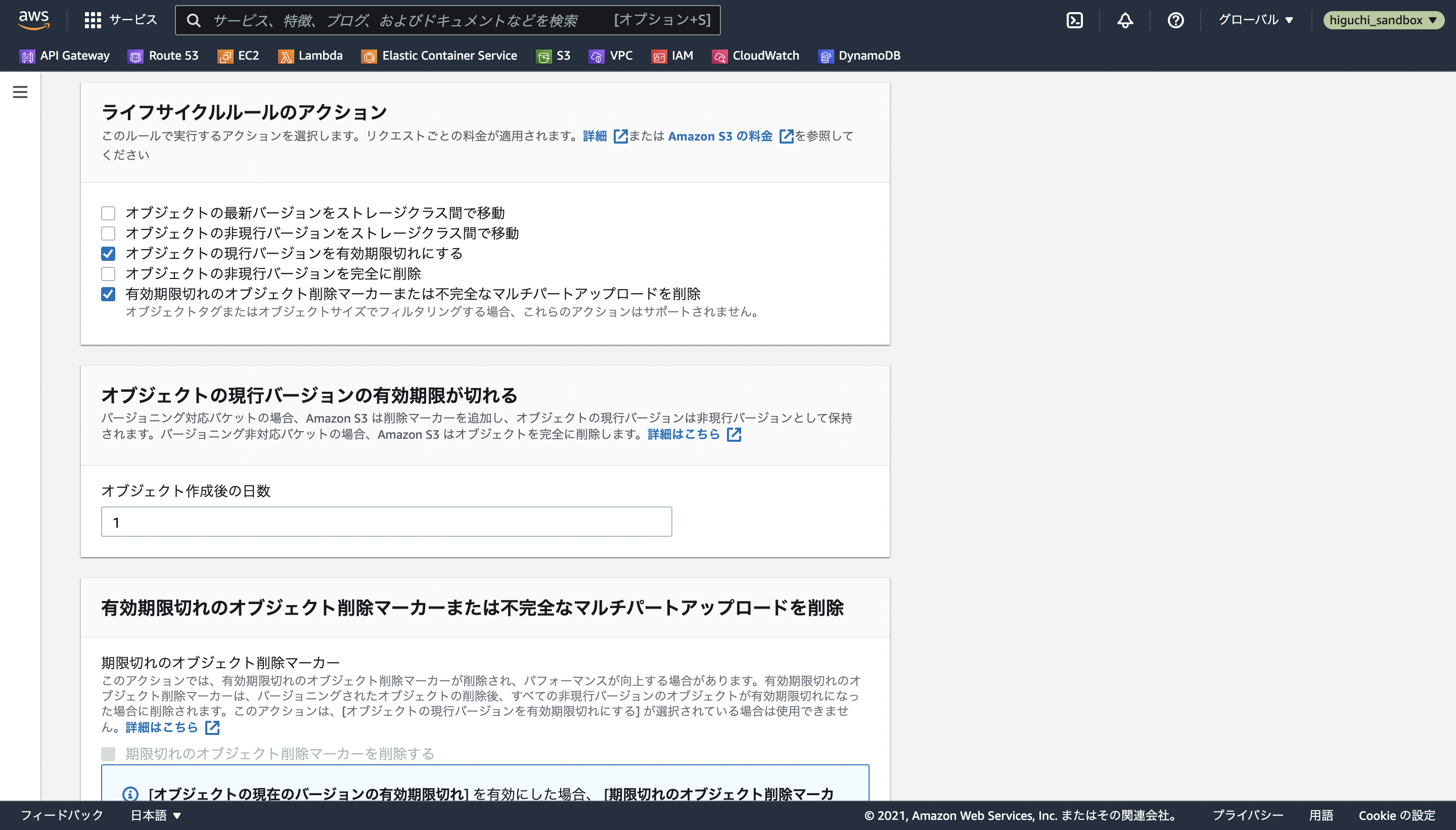
また、大きなファイルをS3にアップロードする際に、自動でファイルを複数に分割してアップロードされることがありますが、時々アップロードに失敗してファイルの一部の残骸がバケット上に残ってしまうことがあるので、それらも自動で削除されるように有効期限切れのオブジェクト削除マーカーまたは不完全なマルチパートアップロードを削除を選択して、その日数を最小の1日に設定します。
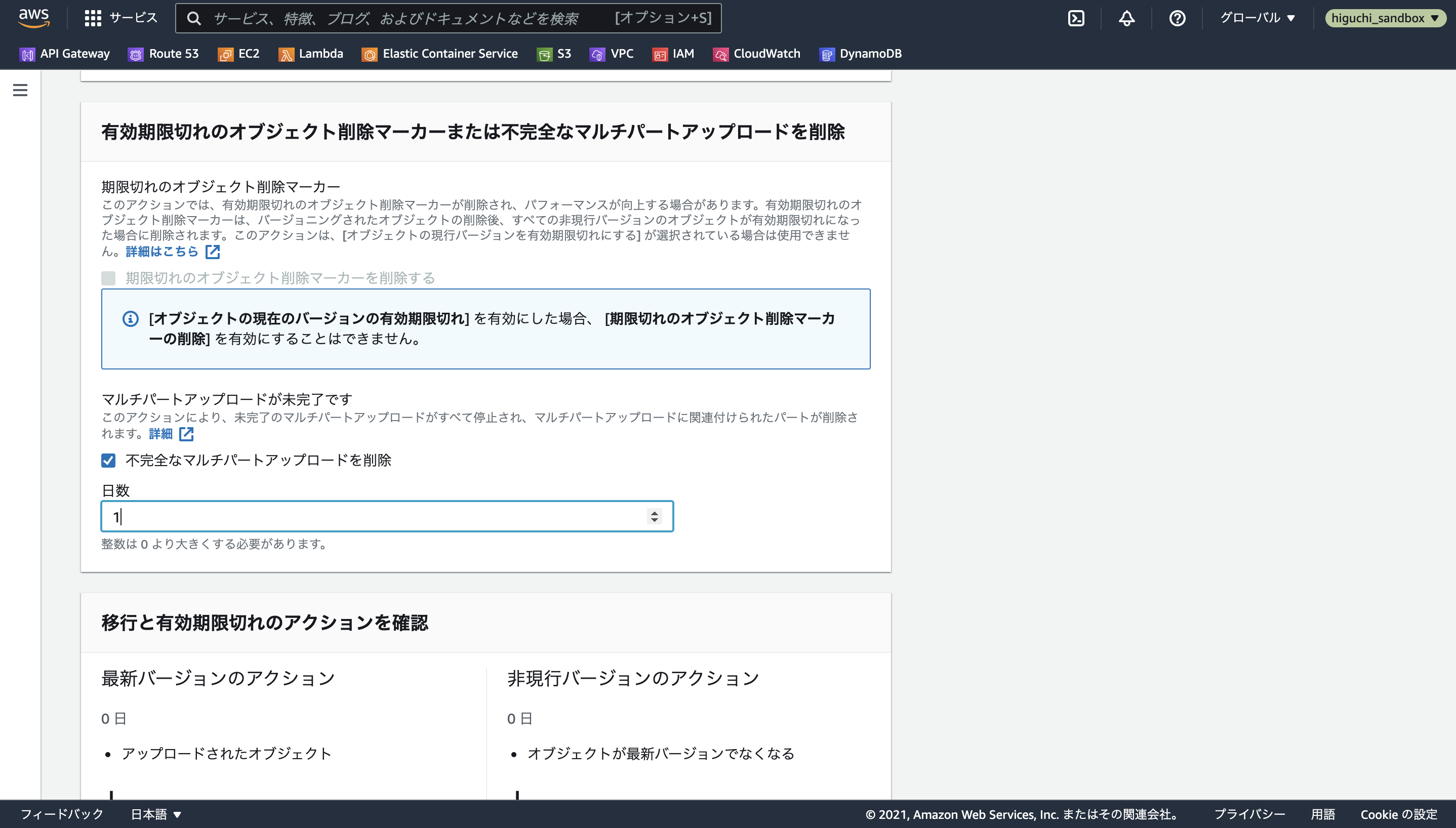
これでライフサイクルルールの設定は終わりです。
2.1.3 IAMポリシーの作成
S3バケット構築セクションの最後は、ここまでで作成したS3バケットに対して、これから構築するLambda関数がzipファイルをアップロードできるようにするためのIAMポリシーを定義します。
(釈迦に説法かとは思いますが、)IAMポリシーはAWS内の各種リソースに対するどんな操作を許可するか、といったことを定義した通行許可証のようなもので、IAMロール・IAMユーザーという実際にその操作を実行する主体(Lambda関数やコンソールを操作するユーザー自身)に付与するものです。
ここでは、zipファイルをアップロードするLambda関数がACLで公開可能オブジェクトとしてアップロードすることを前提として、s3:PutObjectとs3:PutObjectAclの操作を許可するポリシーを作成します。
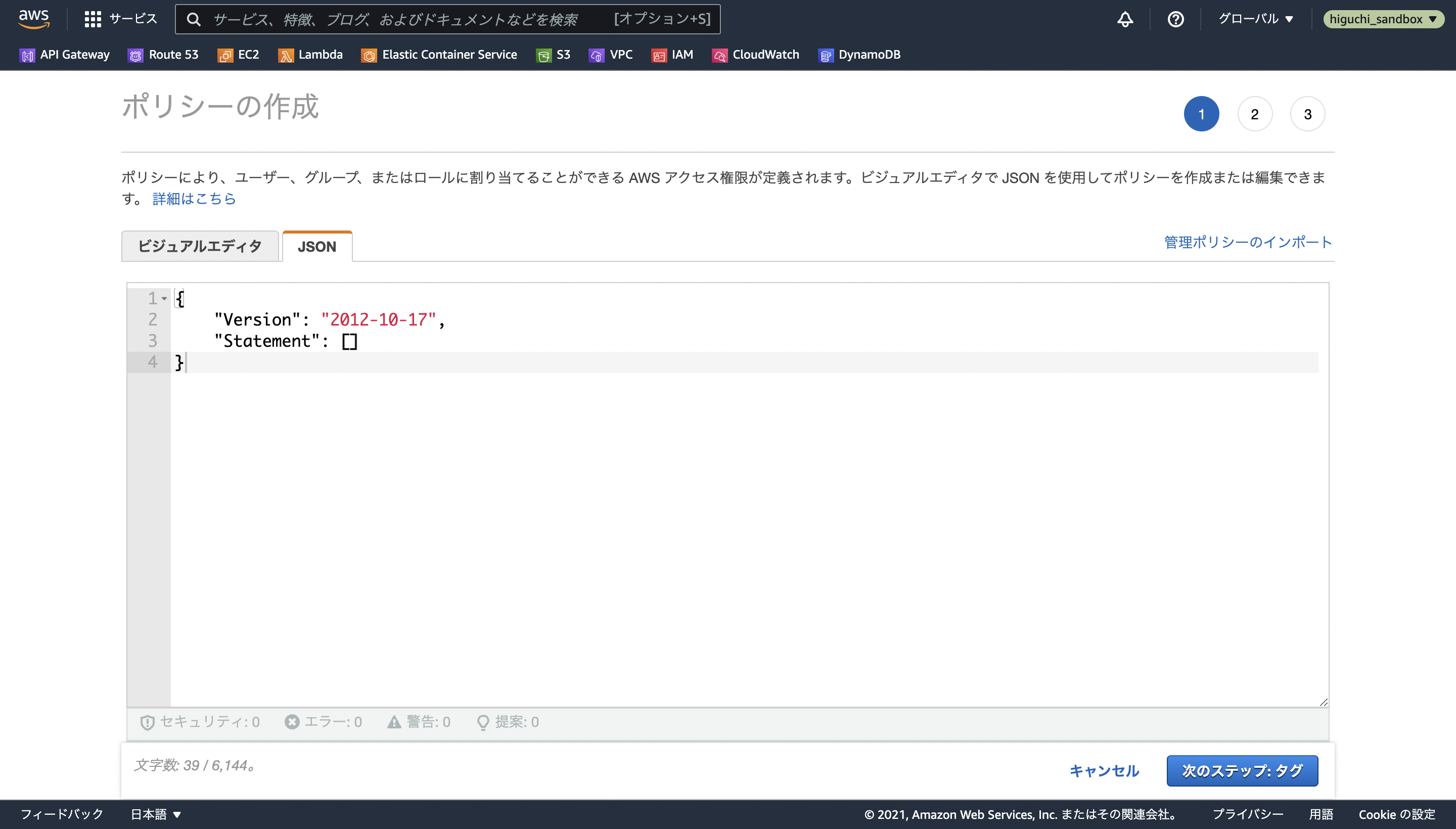
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ZippedLayerCacheAllowPutACL",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::zipped-layer-cache/*"
}
]
}
IAMポリシーのコンソールを開いたら、ポリシーを作成を選択して、JSONタブから上記の内容をコピペし、ポリシーの名前をSidと同じS3ZippedLayerCacheAllowPutACLにして作成します。
2.2 ライブラリをコンパイルするLambdaを定義する
2.1までで保存先のストレージを構築したので、次は肝心のライブラリをコンパイルするLambdaを作っていきます。
どうやってコンパイルするのかをネタバレすると、Lambda内でpipコマンドを実行しているだけです、笑
作る工程は3つに分かれていて、Lambda関数を作る際、最初にLambdaの実行IAMロールを選択する必要があるため、以下の順番で構築します。
- Lambdaの実行ログを保存するためのIAMポリシーの作成
- コンパイル用Lambdaの実行ロールの作成
- コンパイル用Lambdaの作成
ただし、3のLambdaを作成する際は、自分がLambdaの実行環境として使用したいアーキテクチャとPythonバージョンの組み合わせの数だけ定義する必要があります。(それぞれの実行環境で立ち上げたLambda上でpip installしているので、仕方ないですね)
2.2.1 IAMポリシーの作成
2.1.3で、S3バケットにアップロードするポリシーは作ってあるので、ここではLambda関数の実行ログをCloudWatchに保存するためのLambdaBasicExecutionという名前のポリシーを作成します。
もし手元のAWS環境で構築している場合は、{account_id}の部分をアカウントエイリアスナンバーに差し替えてください。
コンパイル用Lambdaは、S3以外のAWSリソースを操作しないので、S3ZippedLayerCacheAllowPutACLとLambdaBasicExecutionの2つのポリシーを付与されたIAMロールで十分になります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LambdaBasicExecution",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:{account_id}:*:*"
]
}
]
}
ちなみにAWS公式が用意しているAWSLambdaBasicExecutionRoleでも同等のポリシーが定義されているので、LambdaBasicExecutionポリシーを作らずに、そちらを使っても問題ありません。
2.2.2 IAMロールの作成
S3ZippedLayerCacheAllowPutACLとLambdaBasicExecutionの2つのポリシーを付与されたIAMロールを作成します。
IAMロールのコンソールを開いたら、ロールを作成を選択して、ユースケースの選択肢からLambdaを選択します。
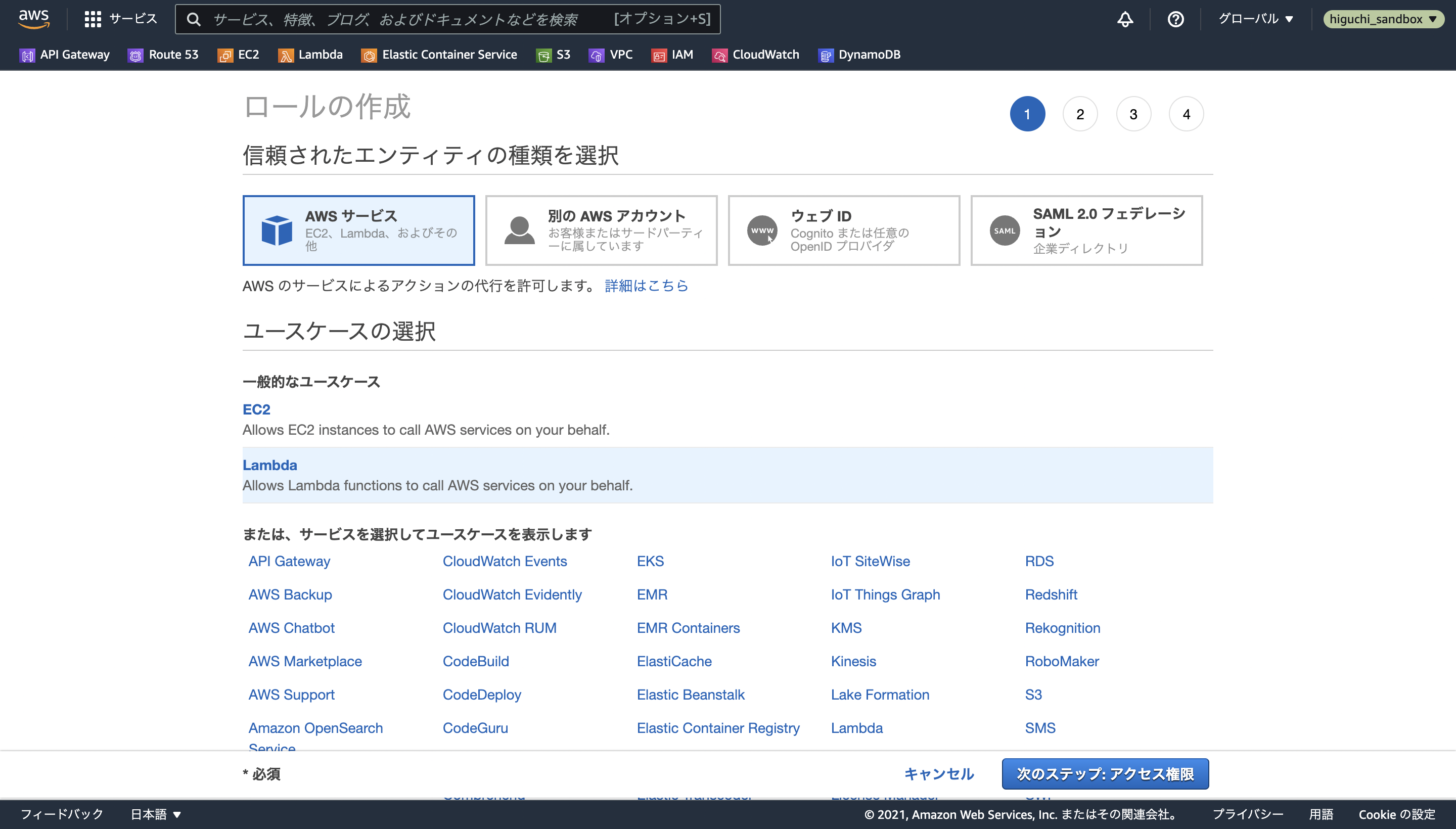
次の画面で、S3ZippedLayerCacheAllowPutACLとLambdaBasicExecutionの名前で検索し、ロールに付与する(アタッチする)ポリシーを選択します。
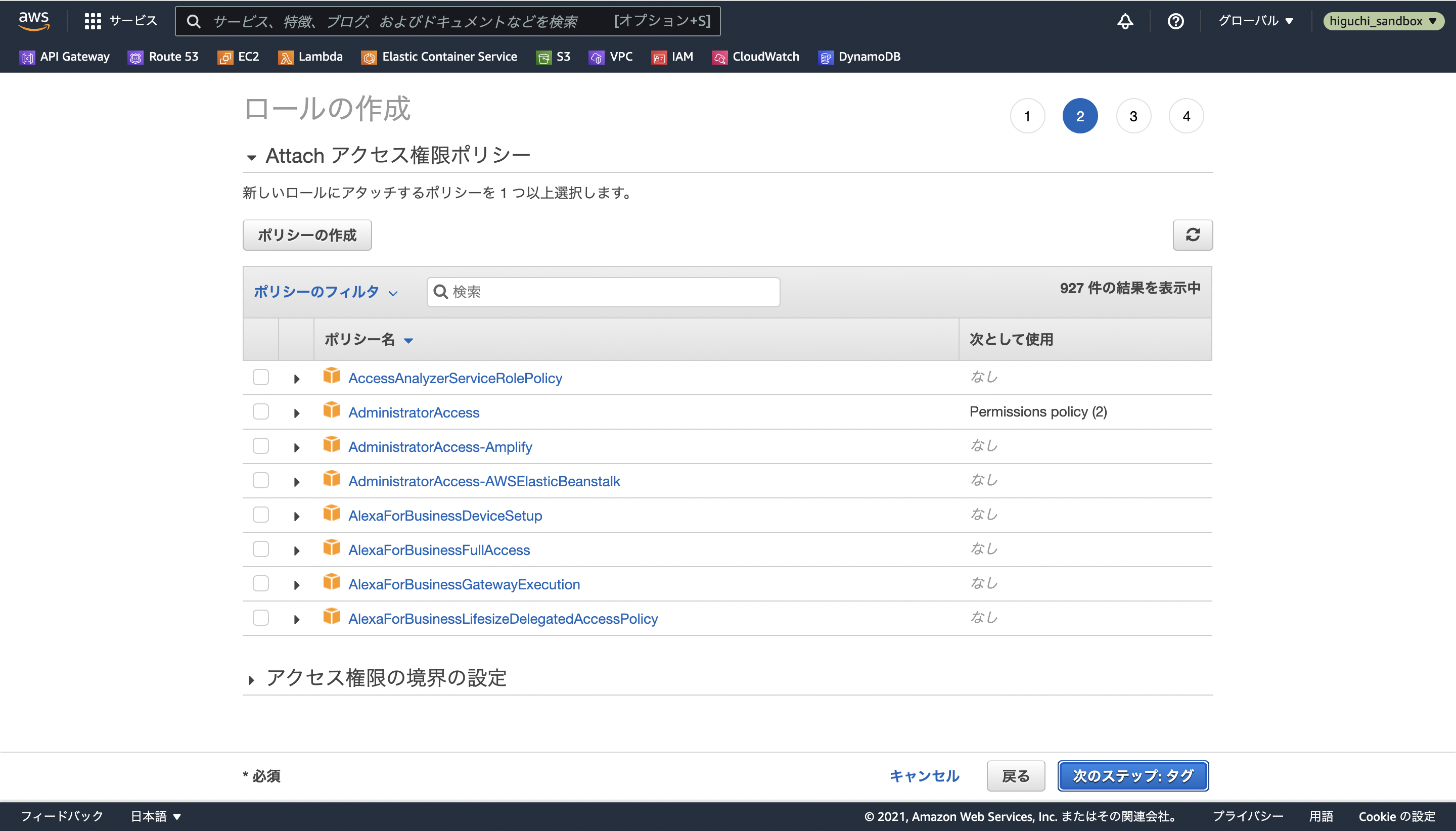
あとはロールに名前をつけて完成です。
ここでは、今回構築するコンパイル用Lambdaが非同期で実行されることから、LambdaZippedLayerAsyncという名前にしました。
2.2.3 Lambda関数の作成
IAMロールを作成したので、最後に実際にライブラリをコンパイルして、必要なファイルをzipし、S3バケットにアップロードするLambda関数を定義します。
関数のコードは以下の通りです。
多少実装時のコードをいじっているので、もし動かなかったらコメントください🙏
# -*- coding: utf-8 -*-
# Copyright 2021 Kenichi Higuchi
import os
import shutil
import logging
import subprocess
import urllib.parse
import boto3
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
S3_BUCKET_NAME = os.environ["S3_BUCKET_NAME"]
s3 = boto3.resource("s3")
bucket = s3.Bucket(S3_BUCKET_NAME)
def lambda_handler(event, context):
"""
Parameter
---------
event : dict
request parameters
[keys]
- packages : str
package request for compile. each package identifier will be joined by "&"
format : event["packages"] -> package1==0.1.0&package2=1.0.1&...
- hash : str
hash of api requested timestamp. Upload Key for S3 Bucket will be create based on this hash.
format : event["hash"] -> 249984c70fdbc79789246c5aa4290966
- no_deps : bool
option if user want to get compiled package without dependencies
"""
logger.debug(f"event: {event}")
packages = []
# parse package request
for package in event["packages"].split("&"):
if "%" in package:
package = urllib.parse.unquote(package)
packages.append(package)
logger.debug(f"packages: {packages}")
timestamp_hash = event["hash"]
logger.debug(f"timestamp_hash: {timestamp_hash}")
no_deps = event["no_deps"]
logger.debug(f"no_deps: {no_deps}")
# create target directory for `pip install`
# in Lambda, users only can write on /tmp
package_dir = os.path.join("/tmp", timestamp_hash, "python")
logger.debug(f"package_dir: {package_dir}")
os.makedirs(package_dir)
try:
# compile packages
cmds = ["pip", "install", "-t", package_dir]
if no_deps:
cmds += ["--no-deps"]
res = subprocess.run(cmds + packages, stdout=subprocess.PIPE)
logger.debug("successfully compiled")
# archive compiled source
# include python directory for Lambda Layer
shutil.make_archive(
package_dir,
format="zip",
root_dir=os.path.dirname(package_dir),
base_dir="python"
)
logger.debug("successfully archived")
# upload s3 with public-read ACL
bucket.upload_file(
package_dir + ".zip",
f"{timestamp_hash}/python.zip",
ExtraArgs = {
"ACL": "public-read"
}
)
logger.debug("successfully uploaded")
except Exception as e:
logger.debug(f"error: {e.__class__.__name__}>> {str(e)}")
return {
"statusCode": 500,
"body": "sorry, something went wrong..."
}
else:
logger.debug("success!")
return {
"statusCode": 200,
"body": "now you can get zipped layer!"
}
コードの解説(後日書きます、、ごめんなさい!)
Lambdaのコンソールを開いたら、関数の作成を選択し、一から作成オプションで名前とランタイム、アーキテクチャ、実行ロールを指定します。
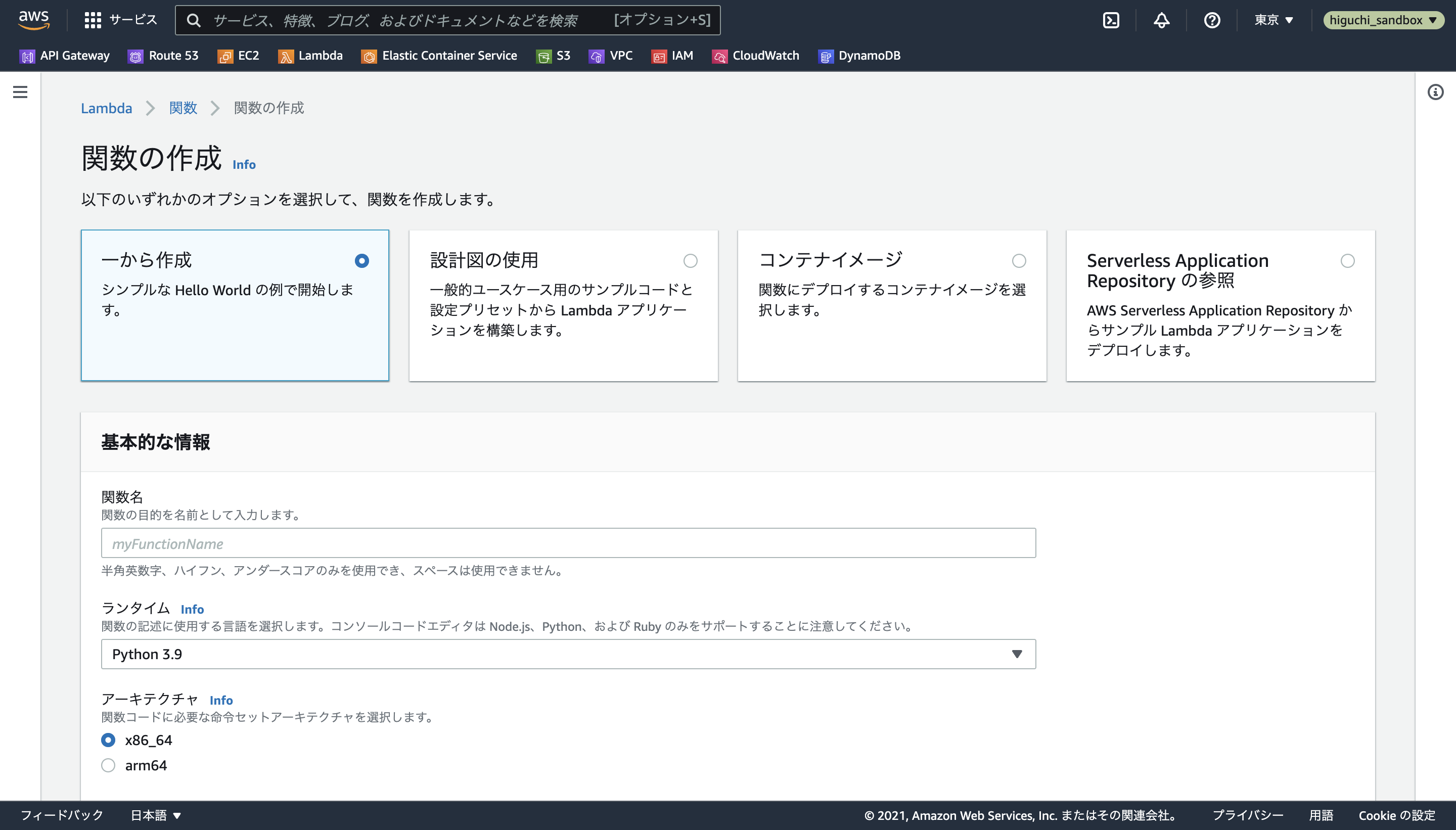
今回は、Lambdaの動作環境の候補として、x86_64アーキテクチャでPython3.7〜3.9をarm64アーキテクチャでPython3.8〜3.9(3.7はサポート外)を選択できるAPIを作るため、以下の命名規則で合計で5つのLambda関数を定義していきます。
[関数名の命名規則]
- ZippedLayer_{arch}_{runtime}
arch : [x86_64, arm64]
runtime : [py39, py38, py37]
ex) ZippedLayer_x86_64_py39, ZippedLayer_arm64_py38
この関数名は、2.3で定義する非同期呼び出し元のLambdaが呼び出すコンパイル用Lambdaの種類を特定するために必要なので、上記のようなルールを作っておく必要があります。
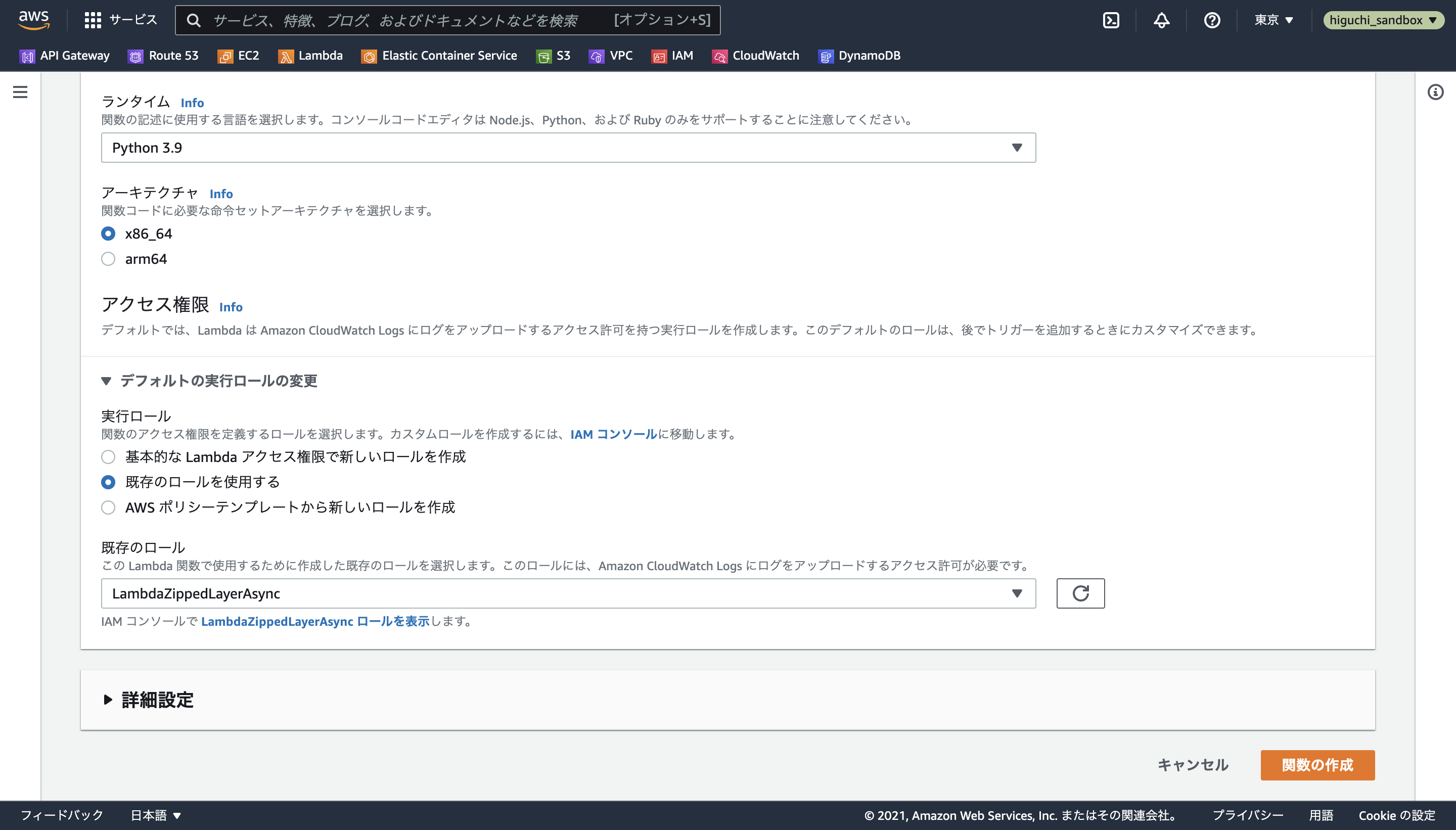
実行ロールは、既存のロールを使用するを選択し、5つとも2.2.2で作成したLambdaZippedLayerAsyncを使用します。
関数が問題なく生成されると、以下のような画面が表示されます。
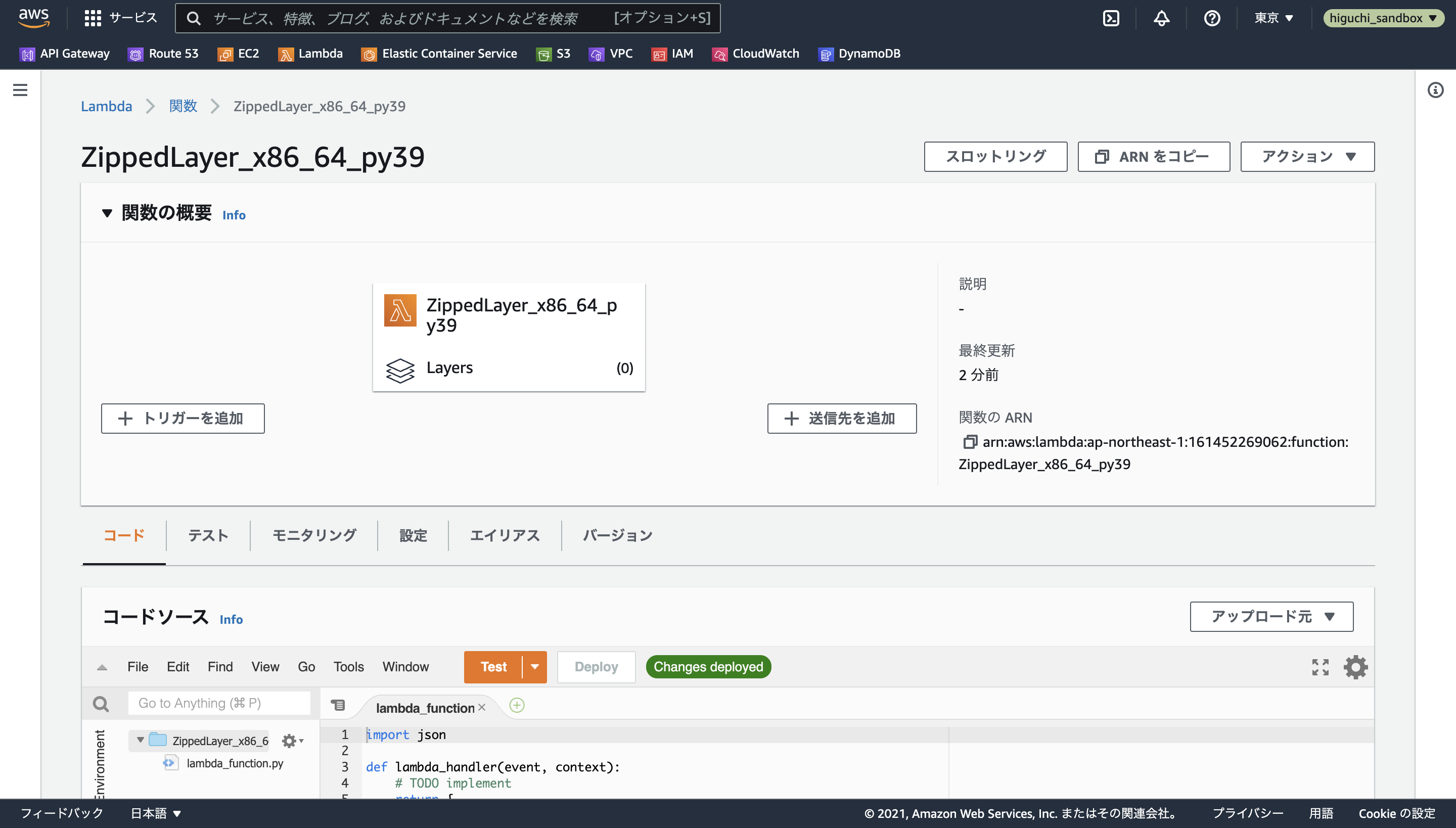
このままではコードが初期の"Hello World"状態なので、上記のコードをコピペしたのちにDeployボタンを押し、緑色でChanges deployedと表示されることを確認します。
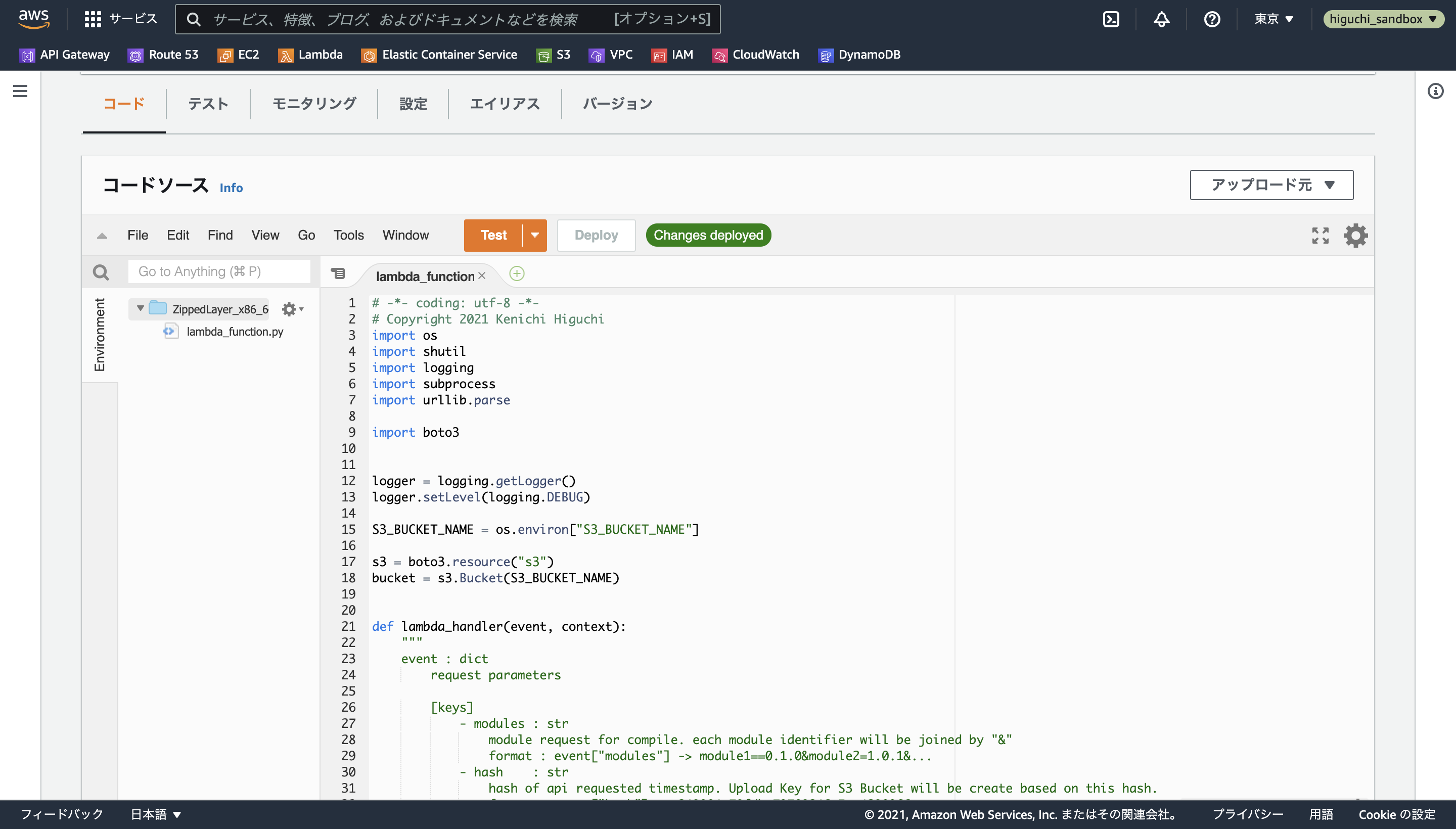
最後に重要な設定として、下の画像のように、設定タブから実行時間・メモリ制限と環境変数を設定します。
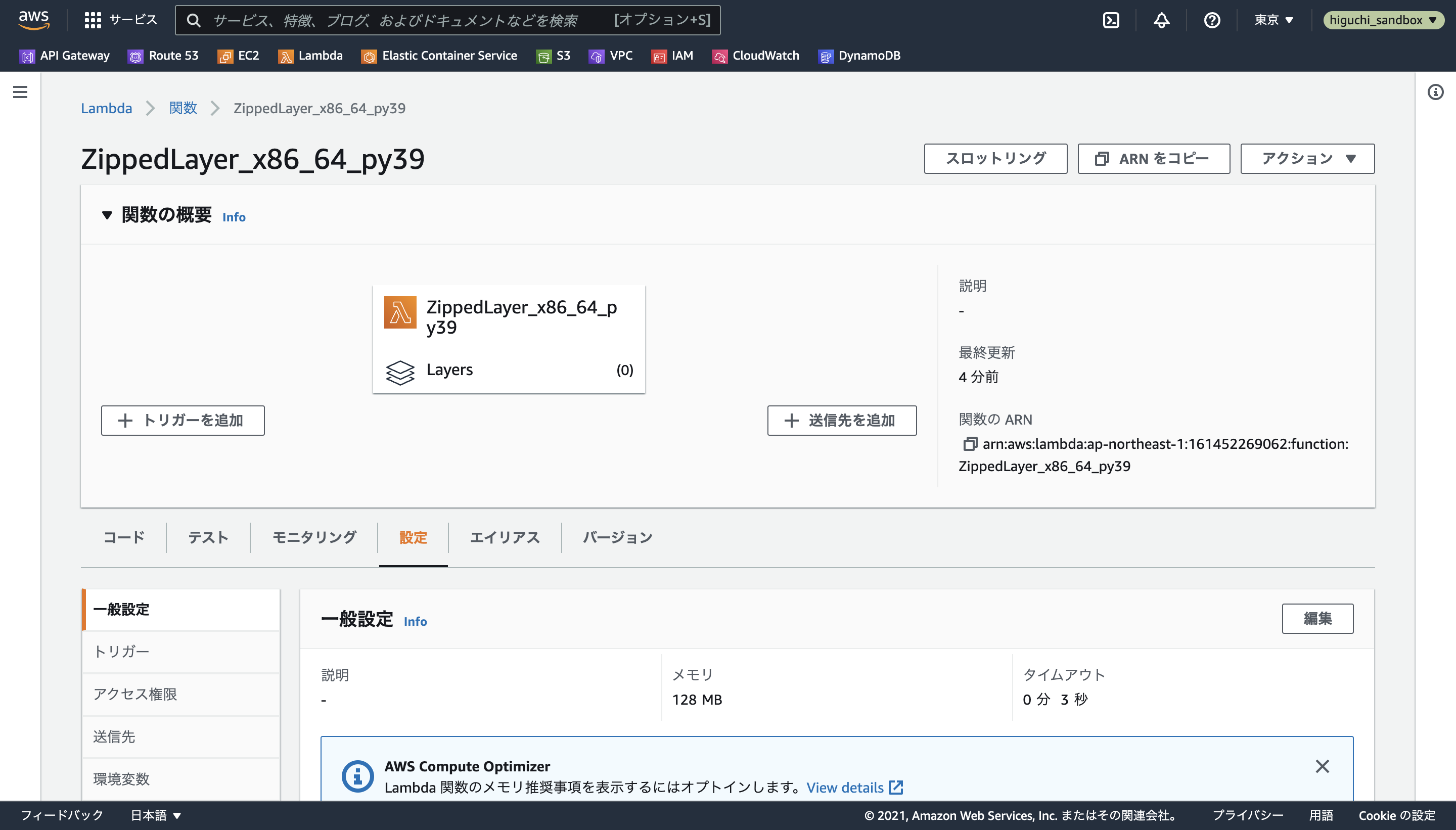
まず実行時間・メモリ制限については、一般設定の編集からメモリを512MB、タイムアウトを最大の5分に設定します。
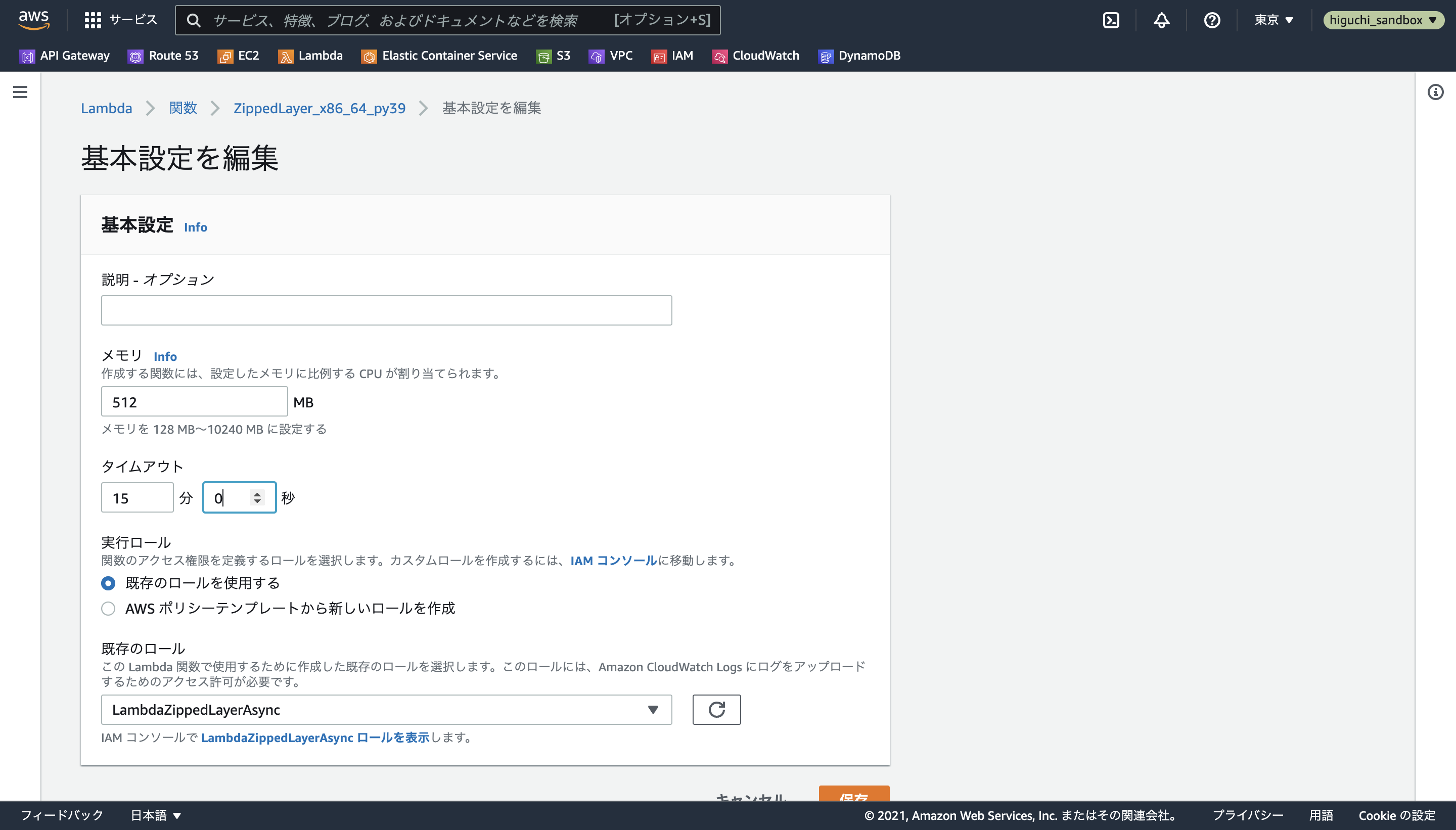
環境変数については、関数のコード中でS3バケット名を環境変数S3_BUCKET_NAMEとして読み込んでいる部分があるため、環境変数の編集からキーがS3_BUCKET_NAME、値がzipped-layer-cacheになるようにして保存します。
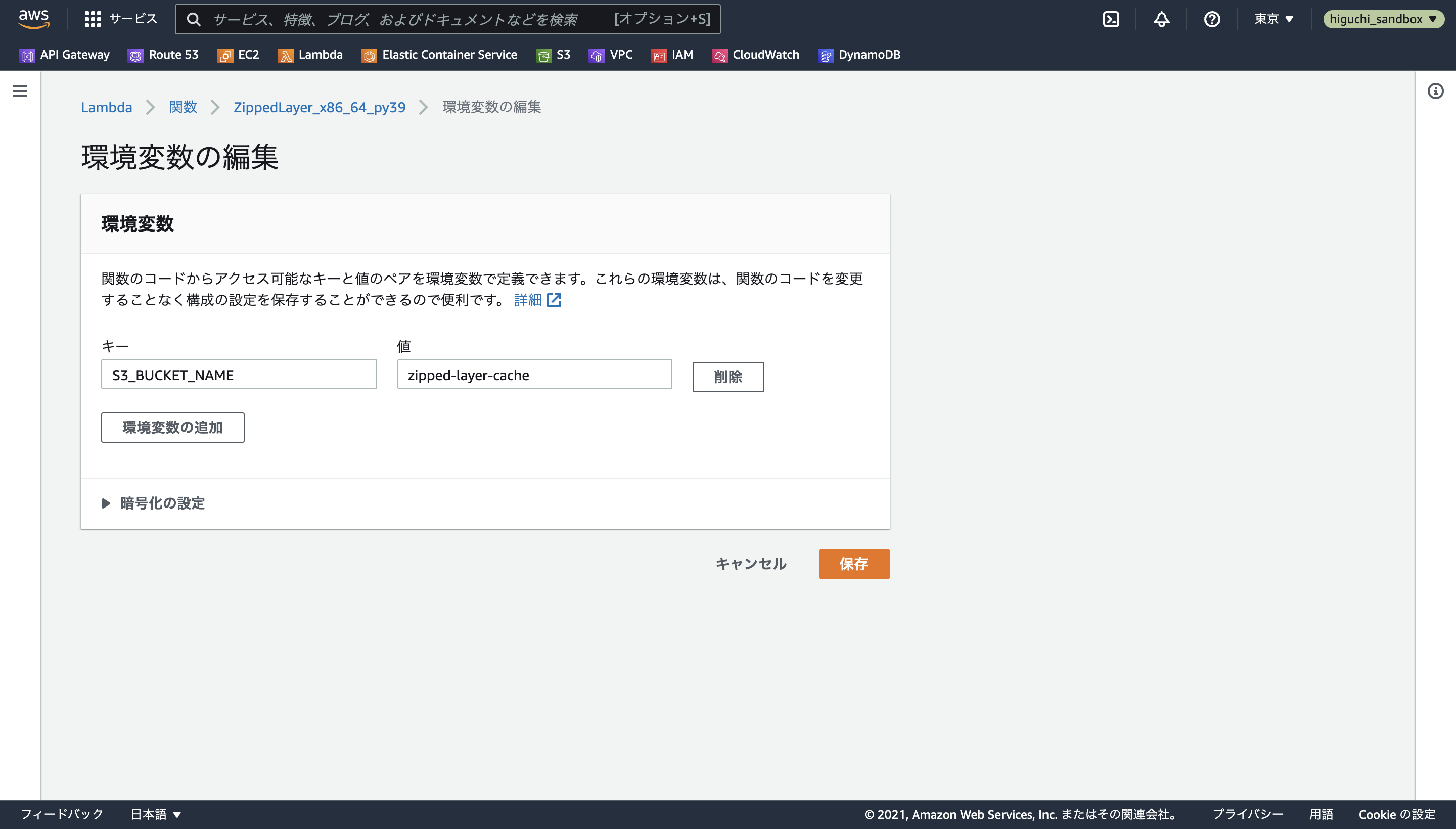
あとはこれを全ての動作環境の組み合わせ分、繰り返します...。(1,2個で収まらないなら、Terraformで構築するのがおすすめ)
長くなりましたが、これでコンパイル用のLambdaの構築は完了です。
2.3 APIリクエストを受け取るLambdaを整備する
続いて、ユーザーからのAPIリクエストを受け取って、zipファイルの保存先であるS3 URLを発行し、コンパイル用のLambdaを非同期で呼び出すLambda関数を定義します。
このLambdaも2.2同様に、以下の3つの工程で作成します。
- コンパイル用LambdaをAPI用Lambda内で呼び出すためのIAMポリシーの作成
- API用Lambdaの実行ロールの作成
- API用Lambdaの作成
ただし、2.2の時とは違って、リクエストパラメータに合わせて呼び出しLambdaを振り分ける役割を持つので、今回作るLambda関数は1つだけです。
2.3.1 IAMポリシーの作成
2.2.1でLambdaの実行ログを保存するLambdaBasicExecutionポリシーは作ってあるので、ここではコンパイル用のLambda関数をLambda内からboto3を介して実行するための権限を付与するLambdaBasicInvocationという名前のポリシーを作成します。
こちらも2.2.1同様に、手元のAWS環境で構築している場合は、{account_id}の部分をアカウントエイリアスナンバーに差し替えてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LambdaBasicInvocation",
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:ap-northeast-1:{account_id}:function:*"
}
]
}
2.3.2 IAMロールの作成
API用Lambdaは、コンパイル用のLambdaの非同期実行を行うので、実行ログを保存するためのLambdaBasicExecutionに合わせて、2.3.1で作ったLambdaBasicInvocationの2つをアタッチしたIAMロールを作ります。
2.2.2の時と同様に、IAMロールのコンソールからLambdaZippedLayerという名前で作成します。
2.3.3 Lambda関数の作成
API用Lambdaの関数のコードは以下の通りです。
# -*- coding: utf-8 -*-
# Copyright 2021 Kenichi Higuchi
import os
import json
import time
import logging
import hashlib
import boto3
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
ARCHs = ["x86_64", "arm64"]
RUNTIMEs = ["py39", "py38", "py37"]
AWS_REGION = os.environ["S3_REGION"]
S3_BUCKET_NAME = os.environ["S3_BUCKET_NAME"]
def lambda_handler(event, context):
"""
Parameter
---------
event : dict
lambda proxy
API Usage
---------
Users will call like below.
>> https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/{arch}/{runtime}/{packages}
if they want to get without dependencies
>> https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/{arch}/{runtime}/{packages}?no-deps=1
"""
logger.debug(f"event: {event}")
# get unix timestamp when api called
timestamp = str(time.time())
timestamp_hash = hashlib.md5(timestamp.encode()).hexdigest()
logger.debug(f"timestamp: {timestamp}, hash: {timestamp_hash}")
# parse parameters
arch = str(event["pathParameters"]["arch"])
logger.debug(f"arch: {arch}")
runtime = str(event["pathParameters"]["runtime"])
logger.debug(f"runtime: {runtime}")
packages = str(event["pathParameters"]["packages"])
logger.debug(f"packages: {packages}")
no_deps = False
if event["queryStringParameters"] and "no-deps" in event["queryStringParameters"]:
no_deps_tmp = event["queryStringParameters"]["no-deps"]
try:
no_deps = bool(int(no_deps_tmp))
except Exception as e:
logger.debug(f"error: {str(e)}")
return {
"statusCode": 400,
"body": json.dumps({"message": f"ValueError: not allowed no-deps value '{no_deps_tmp}' was specified."}),
}
# validation
if arch not in ARCHs:
return {
"statusCode": 400,
"body": json.dumps({"message": f"ValueError: not allowed architecture '{arch}' was specified."})
}
if runtime not in RUNTIMEs:
return {
"statusCode": 400,
"body": json.dumps({"message": f"ValueError: not allowed runtime '{runtime}' was specified."})
}
if arch == "arm64" and runtime == "py37":
return {
"statusCode": 400,
"body": json.dumps({"message": f"ValueError: runtime '{runtime}' does not supported on '{arch}'."})
}
for s in packages:
# exclude "_", "-", "." "a-z", "A-Z", ">", "~", "&"
if s in '!"#$\'()*,:/;?@[\\]^`{|}':
return {
"statusCode": 400,
"body": json.dumps({"message": f"ValueError: not allowed symbol '{s}' was found."})
}
try:
# issue S3 URL for Download
download_url = f"https://{S3_BUCKET_NAME}.s3.{AWS_REGION}.amazonaws.com/{timestamp_hash}/python.zip"
# invoke lambda function for compile
response = boto3.client("lambda").invoke(
FunctionName = f"ZippedLayer_{arch}_{runtime}",
InvocationType = "Event", # "Event" means we call this lambda asynchronously
Payload = json.dumps({
"packages": packages,
"hash": timestamp_hash,
"no_deps": no_deps
})
)
except Exception as e:
logger.debug(f"error: {e.__class__.__name__}>> {str(e)}")
return {
"statusCode": 500,
"body": json.dumps({"message": f"{e.__class__.__name__}: {str(e)}"}),
}
else:
logger.debug(f"response: {str(response)}")
logger.debug(f"download_url: {str(download_url)}")
return {
"statusCode": int(response["ResponseMetadata"]["HTTPStatusCode"]),
"body": download_url
}
コードの解説(後日書きます、、ごめんなさい!)
コンパイル用Lambdaの時と同様に、Lambdaのコンソールから関数の作成を選択し、関数名をZippedLayer、実行ロールを2.3.2で作成したLambdaZippedLayerを選択して関数を作ります。
ランタイムとアーキテクチャに関しては、何を使っても違いはありませんが、x86_64のPython3.9を選びました。
タイムアウトは30秒に設定し、環境変数にはS3_REGIONにap-northeast-1を、S3_BUCKET_NAMEにzipped-layer-cacheを設定すれば、API用Lambdaの構築は完了です!
2.4 API Gatewayを整備する
最後に、2.3で作成したAPI用LambdaとAPI Gatewayの繋ぎ込みを行えば、本記事のAPIは完成です。(ここまで超長かった...)
繋ぎこむLambdaはたった1つしかなく、一瞬で終わるので、ラストまでお付き合いお願いします!
API Gatewayのコンソールを開いたら、APIを作成を選択し、REST APIを新しいAPIとして構築します。
API名はなんでも良いですが、ここではZippedLayerAPIにします。
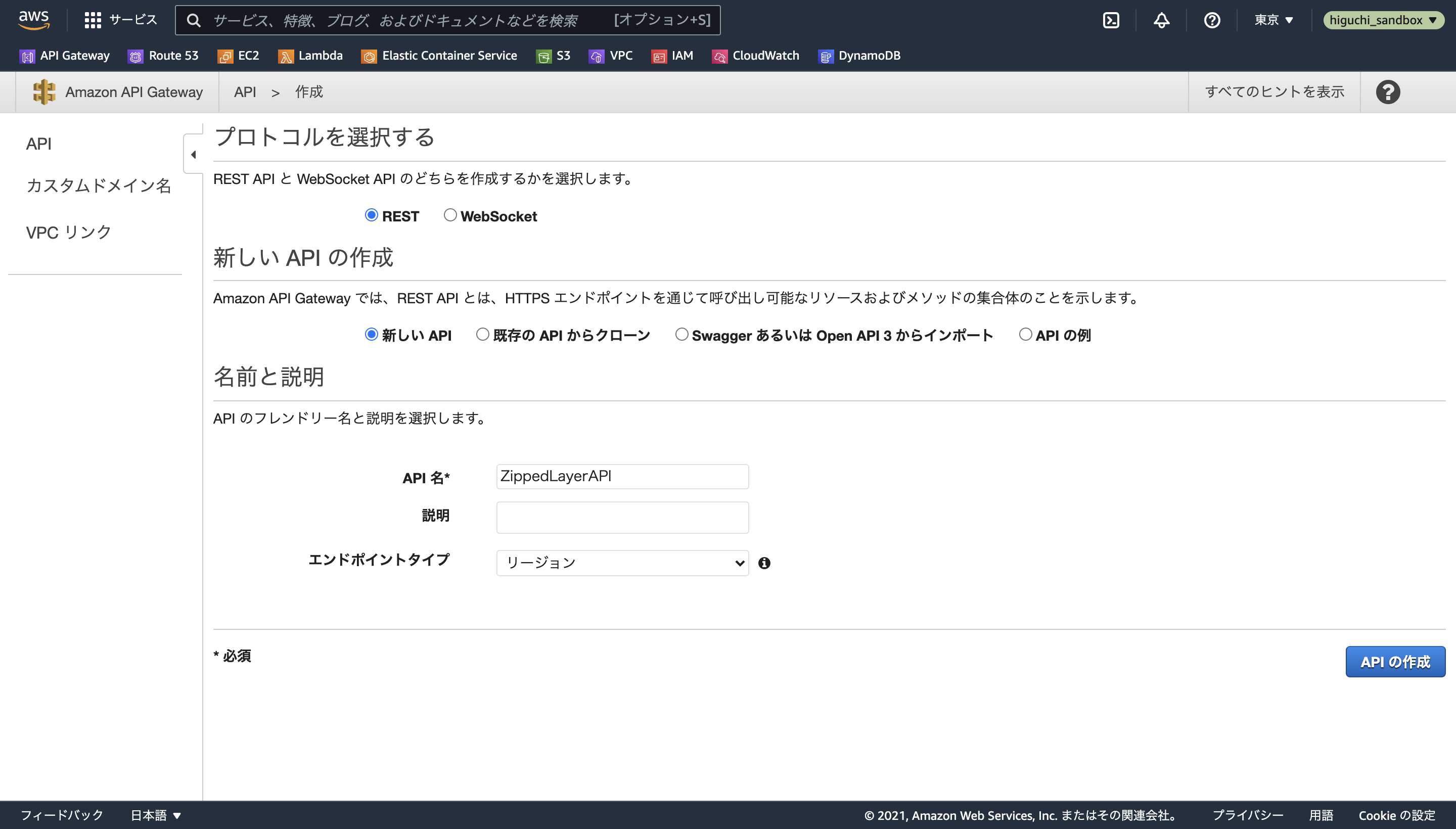
APIを作成したら、アクションのリソースの作成から、以下のように階層のあるリソースを定義します。
/
/{arch}
- プロキシリソース : オフ
- リソース名 : arch
- リソースパス :{arch}
- CORS : オン
/{runtime}
- プロキシリソース : オフ
- リソース名 : runtime
- リソースパス : {runtime}
- CORS : オン
/{packages}
- プロキシリソース : オフ
- リソース名 : packages
- リソースパス : {packages}
- CORS : オン
ここで各リソースパスを{}で囲い、Lambdaを紐付ける際にLambdaプロキシ統合をオンにすることで、API用Lambda上でパスパラメーターとして取得できるようになります。
次に、/{packages}リソースを選択した状態でアクションのメソッドの作成を選択し、プルダウンからGETを選択します。
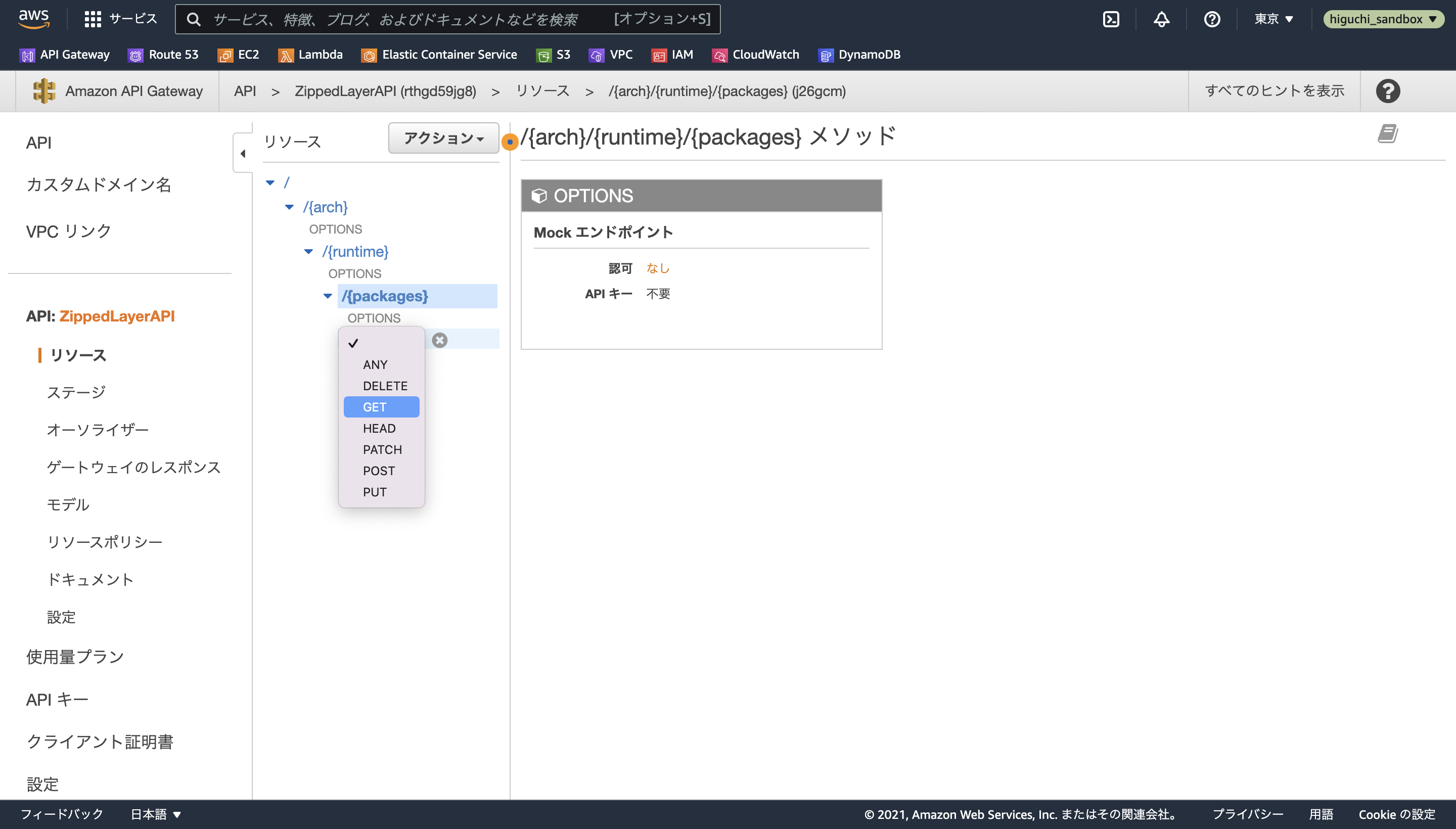
チェックマークを押したら、Lambda プロキシ統合の使用をオンにし、Lambda関数で2.3で作成したZippedLayerを指定すれば、API GatewayとLambdaの紐付けは完了です。
あとは、アクションからAPIのデプロイを選択し、prdという新しいステージを作成してデプロイが終わればAPIの完成です!
3. APIの使い方
URLを直接ブラウザで開いたり、curlコマンドを使用することで、S3 URLが出力され、それをコピペしてLayerを作ることができます。
生成できるライブラリは、pypiに公開されていて、pipコマンドでインストールできるものに限ります。
今後、Lambdaにgitコマンドをインストールすれば、Githubなどからも直接インストールできるようになると思います。
注意点としては、pandasなどpip installに時間がかかるライブラリは、S3 URLが出力されてからそのS3にzipファイルのアップロードが完了するまでに時間がかかることがあるため、少し待ってからS3 URLを使用することをお勧めします。
バージョン指定なし
$ curl -X GET https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prd/x86_64/py39/scipy
バージョン指定あり
$ curl -X GET https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prd/x86_64/py38/scipy==1.7.3
複数ライブラリの指定
&で入れたいライブラリの識別子同士を結合する。
$ curl -X GET https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prd/arm64/py39/scipy==1.7.3&requests==2.26.0&pandas
依存ライブラリを除く
no-depsオプションに1を指定する。
$ curl -X GET https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prd/arm64/py38/scipy?no-deps=1
もし、作成したLayerを他のAWSアカウントからも使えるように公開する場合は、以下の記事を参考にしてください!
(参考)
4. おわりに
最後まで読んでくださってありがとうございます。
正直このAPIにどのぐらいニーズがあるのか分からないのですが、もし使ってみたい方がいれば、公開しようかと思っているのでぜひGoogleフォームを入力してください。
Terraformのコードも見てみたいって方は、それもGoogleフォームから教えてください🙏
https://forms.gle/sTHQJpLSG6m1XfWt5
それでは良いお年を!🎍